Flink常见问题总结
Flink 问题总结
作业运行流程
新增的 operator 会被 transform 封装,例如 map(udf) -> OneInputTransformation,里面有序列化的 udf和operator配置(名称、uid、并行度等),并记录前一个 transformation 作为输入。
当 execute 被调用,client 先遍历 transformation 构造 StreamGraph -> JobGraph -> 合并 chain 最后到达 JM。JM 将其翻译为 ExecutionGraph。ExecutionJobVertex 有一个或多个并行度且可能被调度和执行多次,其中一个并行度的一次执行称为 Execution,JobManager 的 Scheduler 会为每个 Execution 分配 slot。
Watermark
基础
Process 和 Event 的选择:是否需要重现。
watermark代表了 timestamp 数值,表示以后到来的数据已经再也没有小于或等于这个时间的了。
生成方式:
- SourceFunction:collectWithTimestamp 或 emitWatermark
- Stream:assignTimestampsAndWatermarks
- 定期
- 数据特征
传播方式:广播,单输入取其大,多输入取其小(因此多次输入相同的 watermark,并不会影响当前的 watermark)
缺陷:对于同一个流的不同 partition,我们对他做这种强制的时钟同步是没有问题的,因为一开始就把一条流拆散成不同的部分,但每一个部分之间共享相同的时钟(多输入取其小)。但是 JOIN 流中,多流强制同步时钟,对于快慢流关联就要求快流缓存大量数据等待慢流。
watermark处理:operator 先更新 watermark,然后遍历计时器触发 trigger,watermark 发送下游。
Table API 中的时间
- processing time 可以从一个 DataStream,把增加一列为时间来转化成一个 Table,或直接通过 TableSource 定义 DefinedRowtimeAttributes 生成
- event time:需要保证 DataStream 中已经存在 Record Timestamp 和 watermark,从 TableSource 生成,也需要已经有 long 字段。
操作:over window、group by、window join、order(对一个 DataStream 转化成 Table 进行排序的话,只能是按照时间列进行排序,当然同时也可以指定一些其他的列,但是时间列这个是必须的,并且必须放在第一位)。这些操作在flink底层都是按照时间列扫描计算的,这也是流处理的特点或者相对于批处理的劣势。扫描过程中积累的状态不能无限增长是流处理的前提(其实批处理也一样,但批处理模型在这方面的性能应该好些)。
原理扩展
在 event-time 场景下,如果 source 没有收到数据,那么 watermark 就有可能停滞,这里有两种情况:
-
source 某个 partition 没有新数据
此时 source function 可以调用 sourceContext.markAsTemporarilyIdle() 来把该 partition 设置为 idle,在这之后的 watermark 生成机制就不会考虑这个停滞了的当前 watermark,进而让 operator 随着 active partition 的最小 watermark 继续推进。
源码可参考:
SourceFunction.markAsTemporarilyIdle(), StreamStatus, StreamTaskNetworkInput.processElement, StatusWatermarkValve.inputStreamStatus 和 inputWatermark -
整个 source 没有数据
这种情况就要考虑 AssignerWithPeriodicWatermarks,用户自己判断多久的 idle 后,把 event-time 改为某种 process-time 形式的推进。
参考:
State
基础
| state分类 | operator | keyed |
|---|---|---|
| 存储对象是否 on heap | 是 | 是/否(RocksDB) |
| 是否手动编写快照(snapshot)和恢复 (restore) | 是 | 不用 |
| 数据规模 | 通常小 | 通常大 |
backend分类
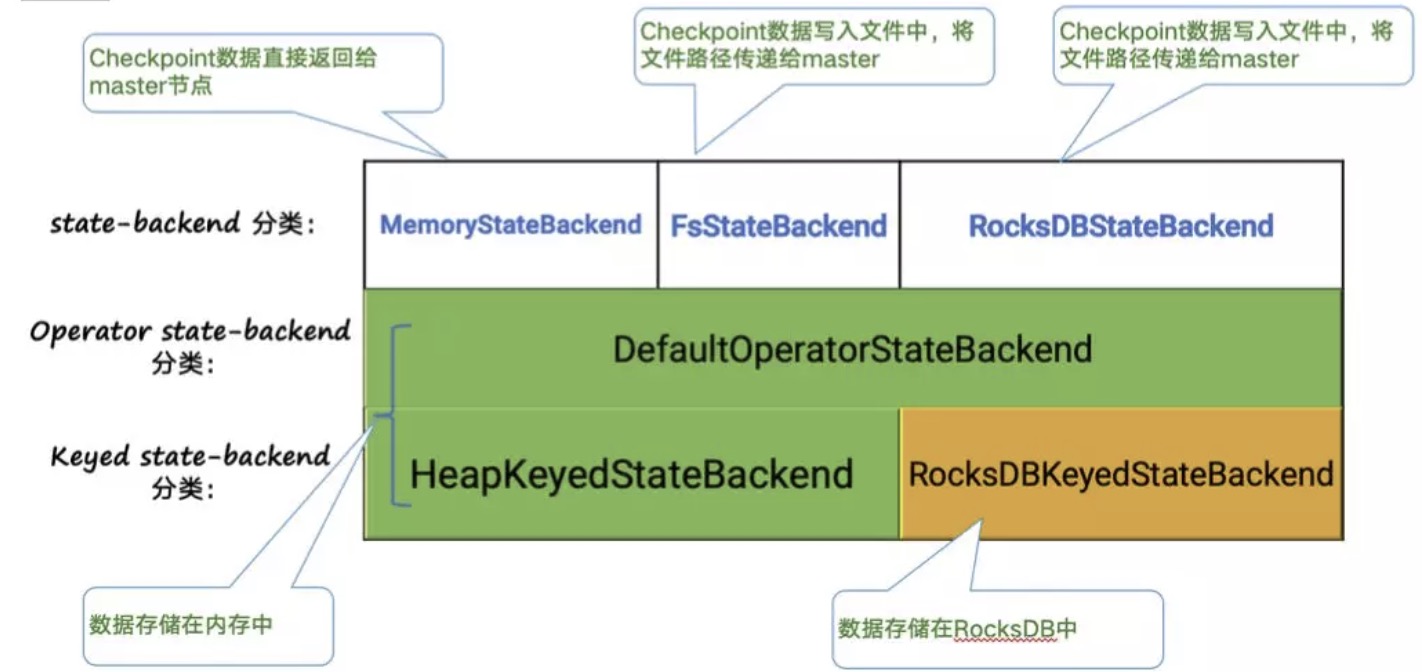
默认使用 memory backend,不管运行state还是 checkpoint 数据都存储在 JM heap(如果JM挂了,连 cp 都不存在了),生产环境正常情况只考虑 file 和 rocksdb backend。其中 file 运行时 state 存储在 heap,性能更好,但有 OOM 风险,且不支持增量 checkpoint;rocksdb 不管运行还是最终 checkpoint 数据都在数据库中,无需担心 OOM。
- HeapKeyedStateBackend 有两种实现:
- 支持异步 Checkpoint(默认):存储格式 CopyOnWriteStateMap
- 仅支持同步 Checkpoint:存储格式 NestedStateMap
- RocksDBKeyedStateBackend,每个 state 都存储在一个单独的 column family 内,其中 keyGroup,Key 和 Namespace 进行序列化存储在 DB 作为 key。
RocksDB StateBackend 概览和相关配置讨论
所有存储的 key,value 均被序列化成 bytes 进行存储。
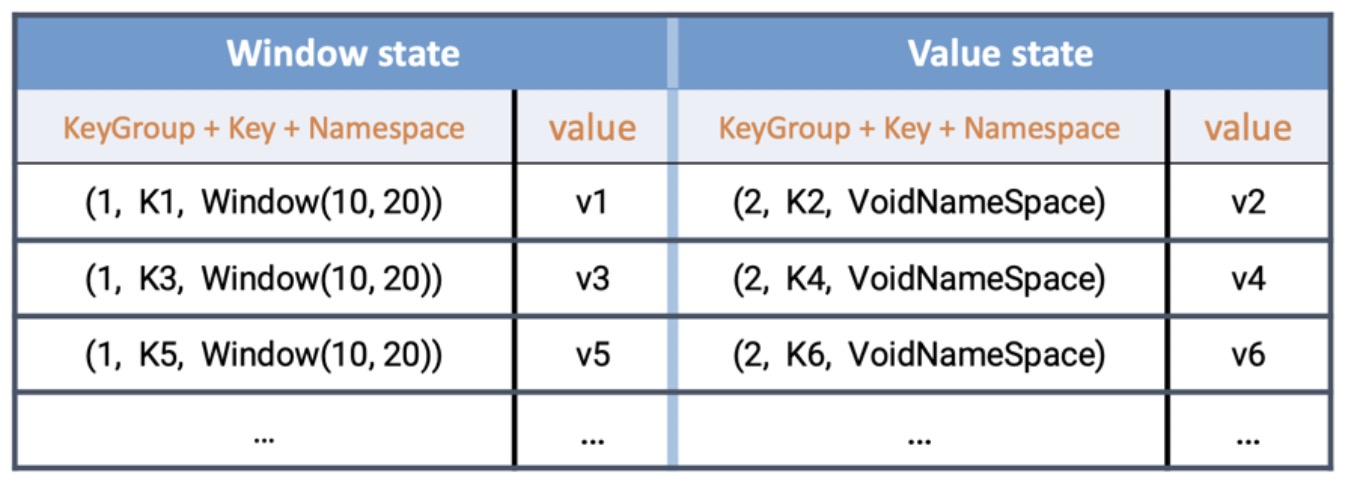
在 RocksDB 中,每个 state 独享一个 Column Family,而每个 Column family 使用各自独享的 write buffer 和 block cache,上图中的 window state 和 value state实际上分属不同的 column family。
对性能比较有影响的参数配置
| state.backend.rocksdb.thread.num | 后台 flush 和 compaction 的线程数. 默认值 ‘1‘. 建议调大 |
|---|---|
| state.backend.rocksdb.writebuffer.count | 每个 column family 的 write buffer 数目,默认值 ‘2‘. 如果有需要可以适当调大 |
| state.backend.rocksdb.writebuffer.size | 每个 write buffer 的 size,默认值‘64MB‘. 对于写频繁的场景,建议调大 |
| state.backend.rocksdb.block.cache-size | 每个 column family 的 block cache大小,默认值‘8MB’,如果存在重复读的场景,建议调大 |
实践
小心存储大量元素到 operator state
operator state 的结构是一个 list,由于没有 key group,为了实现改并发恢复的功能,需要对 operator state 中的每一个序列化后的元素存储一个位置偏移 offset。这个 offset 是一个 long 数组,但数量一大,这个 offset 数据就会很大。在 checkpoint 的时候,JM 需要接收这个 offset 数组作为原数据,进而引起 JM 的内存超用问题。
UnionListState的使用
从检查点恢复之后每个并发 task 内拿到的是原先所有operator 上的 state。切记恢复的 task 只取其中的一部分进行处理和用于下一次 snapshot,否则有可能随着作业不断的重启而导致 state 规模不断增长。
keyed state 的清空
state.clear() 实际上只能清理当前 key 对应的 value 值,如果想要清空整个 state,需要借助于 applyToAllKeys 方法。如果需求中只是对 state 有过期需求,借助于 state TTL 功能来清理会是一个性能更好的方案。
RocksDB运行
默认使用 Flink managed memory 方式的情况下,state.backend.rocksdb.metrics.block-cache-usage ,state.backend.rocksdb.metrics.mem-table-flush-pending,state.backend.rocksdb.metrics.num-running-compactions 以及 state.backend.rocksdb.metrics.num-running-flushes 是比较重要的相关 metrics。
Flink-1.10 之后,由于引入了 RocksDB 的内存托管机制,在绝大部分情况下, RocksDB 的这一部分 native 内存是可控的,不过受限于 RocksDB 的相关 cache 实现限制,在某些场景下,无法做到完美控制,这时候建议打开上文提到的 native metrics,观察相关 block cache 内存使用是否存在超用情况,可以将相关内存添加到 taskmanager.memory.task.off-heap.size 中,使得 Flink 有更多的空间给 native 内存使用。
大状态
大状态基本只考虑 RocksDB。
-
将state进行拆分,使用 MapState 来替代 ListState 或者 ValueState,因为RocksDB 的 map state 并不是将整个 map 作为 value 进行存储,而是将 map 中的一个条目作为键值对进行存储。
-
SSD磁盘
-
多硬盘分担压力(单块磁盘的多个目录无意义):在
flink-conf.yaml中配置state.backend.rocksdb.localdir参数来指定 RocksDB 在磁盘中的存储目录。当一个 TaskManager 包含 3 个 slot 时,那么单个服务器上的三个并行度都对磁盘造成频繁读写,从而导致三个并行度的之间相互争抢同一个磁盘 io,这样务必导致三个并行度的吞吐量都会下降。Flink 的 state.backend.rocksdb.localdir 参数可以指定多个目录,一般大数据服务器都会挂载很多块硬盘,我们期望同一个 TaskManager 的三个 slot 使用不同的硬盘从而减少资源竞争。state.backend.rocksdb.localdir: /data1/flink/rocksdb,/data2/flink/rocksdb对于硬盘较少的情况,flink 默认的随机策略容易碰撞,考虑采用自定义磁盘选择策略,比如轮训。具体参考下面的 flink 大状态优化。
参考:
CheckPoint/SavePoint
基础
flink 的一致性快照,实际是当前 state 的数据快照。
flink 会周期性地进行 cp,且过程是异步的,所以 cp 期间仍可以处理数据。 cp 数据根据 statebackend 的不同会存储到不同的地方。
原理:失败/暂停重启时,flink 会根据最新成功 cp 的数据来初始化重启的 state,这个 state 包括 source 中记录的消费位移,从而让整个 flink 状态回到该 cp 完成的那一刻。
分布式快照
- JM 的 Checkpoint Coordinator 向所有 source 节点 trigger Checkpoint
- source 接收到 cp barrier 后,触发本地 state 的 cp,将数据存储到持久存储,将备份数据的地址(state handle)通知给 Checkpoint coordinator,然后广播 cp barrier 到下游。当下游获得其中一个CB时,就会暂停处理这个CB对应的数据,并将这些数据存到缓冲区,直到其他相同ID的CB都到齐(checkpoint barrier 对齐),就会触发本地 state 的 cp,并广播 cp barrier,然后处理缓存的数据。最后,当所有 task 的 state handle 都被 Checkpoint Coordinator 收集,本次 cp 就算是完成了,最后向持久化存储中再备份一个 Checkpoint meta 文件。
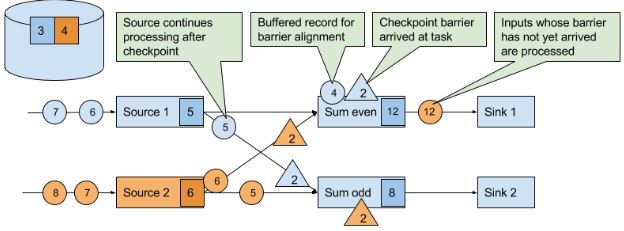
优化:
- RocksDB的异步checkpoint:首先 RocksDB 会全量刷数据到磁盘上,然后 Flink 框架会从中选择没有上传的文件进行持久化备份。后台线程异步发送快照到远程storage。
- 如果是 at-least-once,就不会进行 checkpoint barrier 对齐。
checkpoint 和 savepoint
| checkpoint | savepoint |
|---|---|
| 用户触发和删除 | 配置自动触发,默认只保留最新 |
| 标准化格式存储,允许作业升级、bug修复,A/B Test等场景,需要用户指定路径 | 作业 failed 或者 canceled 后重启,不需指定路径 |
| 全量,每次的时间较长,数据量较大 | 增量,每次的时间较短,数据量较小 |
配置
- 间隔不宜太短,默认情况,如果一个 cp 时间超过 cp 触发间隔,那么这个 cp 一旦完成,就会马上出发下一次 cp。可以考虑设置
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(milliseconds) - 大 state 要适当增加超时时间(默认10min)
实践
cp 失败排查
-
cp webui 界面
Acknowledged一列表示有多少个 subtask 对这个 Checkpoint 进行了 ackLatest Acknowledgement表示该 operator 的所有 subtask 最后 ack 的时间;End to End Duration表示整个 operator 的所有 subtask 中完成 snapshot 的最长时间;State Size表示当前 Checkpoint 的 state 大小 -- 主要这里如果是增量 checkpoint 的话,则表示增量大小;Buffered During Alignment表示在 barrier 对齐阶段积攒了多少数据,如果这个数据过大也间接表示对齐比较慢); -
失败原因
-
Checkpoint Decline
// JM日志 Decline checkpoint 10423 by task 0b60f08bf8984085b59f8d9bc74ce2e1 of job 85d268e6fbc19411185f7e4868a44178 // 可以从 JM日志 查找 0b60f08bf8984085b59f8d9bc74ce2e1 被分到哪个 TM org.apache.flink.runtime.executiongraph.ExecutionGraph - XXXXXXXXXXX (100/289) (87b751b1fd90e32af55f02bb2f9a9892) switched from SCHEDULED to DEPLOYING. org.apache.flink.runtime.executiongraph.ExecutionGraph - Deploying XXXXXXXXXXX (100/289) (attempt #0) to slot container_e24_1566836790522_8088_04_013155_1 on hostnameABCDE // 从上面日志可以确定被调度到 hostnameABCDE 的 container_e24_1566836790522_8088_04_013155_1 slot,当相应 TM 查看日志。 -
Checkpoint cancel
当前 Flink 中如果较小的 Checkpoint 还没有对齐的情况下,收到了更大的 Checkpoint,则会把较小的 Checkpoint 给取消掉。
-
Checkpoint Expire
// 由下面日志可知,参考上面 Checkpoint Decline 的方法找到对应的 TM 日志。 Received late message for now expired checkpoint attempt 1 from 0b60f08bf8984085b59f8d9bc74ce2e1 of job 85d268e6fbc19411185f7e4868a44178.开启debug后,可以通过日志分析出慢在哪个阶段。
// barrier 对齐后,准备 cp Starting checkpoint (6751) CHECKPOINT on task taskNameWithSubtasks // 同步阶段 org.apache.flink.runtime.state.AbstractSnapshotStrategy - DefaultOperatorStateBackend snapshot (FsCheckpointStorageLocation {fileSystem=org.apache.flink.core.fs.SafetyNetWrapperFileSystem@70442baf, checkpointDirectory=xxxxxxxx, sharedStateDirectory=xxxxxxxx, taskOwnedStateDirectory=xxxxxx, metadataFilePath=xxxxxx, reference=(default), fileStateSizeThreshold=1024}, synchronous part) in thread Thread[Async calls on Source: xxxxxx _source -> Filter (27/70),5,Flink Task Threads] took 0 ms. // 异步阶段 ... asynchronous part) in thread Thread[pool-48-thread-14,5,Flink Task Threads] took 369 ms分析原因:
-
source trigger 慢
- 抢不到锁:一般不会,在旧版可能因为抢不到锁,如果对应 TM 没有 准备 cp 日志,则可以考虑这种情况,并用 jstack 分析锁情况。在新版已经使用 mailBox 优化。
- 反压或数据倾斜
- 主线程cpu消耗太高:在 task 端,所有的处理都是单线程的,数据处理和 barrier 处理都由主线程处理,如果主线程在处理太慢(比如使用 RocksDBBackend,state 操作慢导致整体处理慢),导致 barrier 处理的慢,也会影响整体 Checkpoint 的进度,在这一步我们需要能够查看某个 PID 对应 hotmethod。使用工具 AsyncProfile dump 一份火焰图,查看占用 CPU 最多的栈
-
同步阶段慢
同步阶段一般不会太慢,但是如果我们通过日志发现同步阶段比较慢的话,对于非 RocksDBBackend 我们可以考虑查看是否开启了异步 snapshot,如果开启了异步 snapshot 还是慢,需要看整个 JVM 在干嘛,也可以使用前一节中的工具。对于 RocksDBBackend 来说,我们可以用
iostate查看磁盘的压力如何,另外可以查看 tm 端 RocksDB 的 log 的日志如何,查看其中 SNAPSHOT 的时间总共开销多少。 -
异步慢
对于异步阶段来说,tm 端主要将 state 备份到持久化存储上,对于非 RocksDBBackend 来说,主要瓶颈来自于网络,这个阶段可以考虑观察网络的 metric,或者对应机器上能够观察到网络流量的情况(比如
iftop)。对于 RocksDB 来说,则需要从本地读取文件,写入到远程的持久化存储上,所以不仅需要考虑网络的瓶颈,还需要考虑本地磁盘的性能。另外对于 RocksDBBackend 来说,如果觉得网络流量不是瓶颈,但是上传比较慢的话,还可以尝试考虑开启多线程上传功能
-
-
cp 超时的排查(可以结合下面反压的排查思路)
- Barrier对齐,由于某些
- 查看 JM 日志,看是哪些 task 的问题,有可能是数据倾斜等原因。
- 状态大,异步状态遍历和写hdfs耗时:考虑使用 RocksDB 的增量 cp,考虑 state 是否可以用 mapstate 优化。
cp 执行情况
- 通过 ui 可以计算公式 end_to_end_duration - synchronous_duration - asynchronous_duration = checkpoint_start_delay。如果计算结果通常比较大,那说明 checkpoint barrier 不能畅通地流经所有的 operator,有可能有反压存在。
- 对于 exactly-once,如果缓存队列在 cp 时很高,那说明 operator 处理数据的效率不均,可能数据倾斜。
上面两个数值如果一直高,那很可能是 cp 本身的问题。
Tuning Checkpoints and Large State(未完)
原理扩展
增量 checkpoint
Flink 的增量 checkpoint 以 RocksDB 的 checkpoint 为基础。RocksDB 把所有的修改保存在内存的可变缓存中(称为 memtable),所有对 memtable 中 key 的修改,会覆盖之前的 value,当前 memtable 满了之后,RocksDB 会将所有数据以有序的写到磁盘。当 RocksDB 将 memtable 写到磁盘后,整个文件就不再可变,称为有序字符串表(sstable)。RocksDB 的后台压缩线程会将 sstable 进行合并,就重复的键进行合并,合并后的 sstable 包含所有的键值对,RocksDB 会删除合并前的 sstable。
在这个基础上,Flink 会记录上次 checkpoint 之后所有新生成和删除的 sstable,另外因为 sstable 是不可变的,Flink 用 sstable 来记录状态的变化。为此,Flink 调用 RocksDB 的 flush,强制将 memtable 的数据全部写到 sstable,并硬链到一个临时目录中。这个步骤是在同步阶段完成,其他剩下的部分都在异步阶段完成,不会阻塞正常的数据处理。
Flink 将所有新生成的 sstable 备份到持久化存储(比如 HDFS,S3),并在新的 checkpoint 中引用。Flink 并不备份前一个 checkpoint 中已经存在的 sstable,而是引用他们。Flink 还能够保证所有的 checkpoint 都不会引用已经删除的文件。
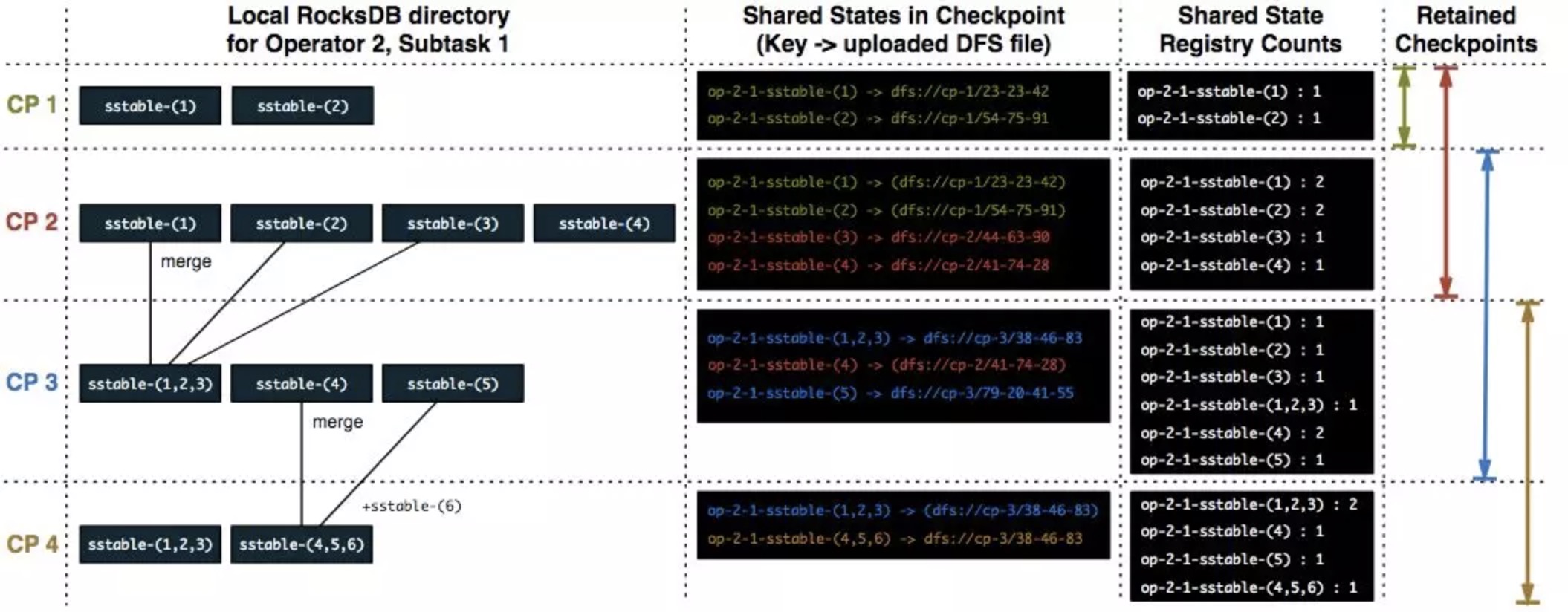
增量 checkpoint 可以减少 checkpoint 的总时间,但是也可能导致恢复的时候需要更长的时间。(从上面的流程可知,被持久化的sstable会包含未被删除等多余数据,所以在恢复时,TM 下载的state数据量更大,再要经过一次全体的merge才能做到去重,才能最终用于state的初始化)
checkpoint源码
- JM CheckpointCoordinator trigger checkpoint
- Source 收到 trigger checkpoint 的 PRC,并往下游发送 barrier,自己开始做 snapshot。
- 下游接收 barrier(需要 barrier 都到齐才会开始做 checkpoint)
- Task 开始同步阶段 snapshot
- Task 开始异步阶段 snapshot
- Task snapshot 完成,汇报给 JM
ExecutionGraphBuilder.buildGraph() {
if config checkpoint {
executionGraph.enableCheckpointing() {
checkpointCoordinator.createActivatorDeactivator
}
}
}
// ActivatorDeactivator 这个对象在 JobStatus 变为 RUNNING 时会调用
coordinator.startCheckpointScheduler(){
scheduleTriggerWithDelay(){
return timer.scheduleAtFixedRate(new ScheduledTrigger()...) // 返回一个 ScheduledFuture
}
}
// 上面的 ScheduledTrigger 会在设置的时候执行 run 方法,这个方法就是 triggerCheckpoint
// CheckpointCoordinator 在实例化时就被传入下面三个数组(buildGraph时生成)
/** Tasks who need to be sent a message when a checkpoint is started. */
private final ExecutionVertex[] tasksToTrigger;
/** Tasks who need to acknowledge a checkpoint before it succeeds. */
private final ExecutionVertex[] tasksToWaitFor;
/** Tasks who need to be sent a message when a checkpoint is confirmed. */
private final ExecutionVertex[] tasksToCommitTo;
{
检查 tasksToTrigger、tasksToWaitFor 数组,看 task 是否都符合 checkpoint 条件
for execution {
triggerCheckpoint(checkpointID, timestamp, checkpointOptions) {
taskManagerGateway.triggerCheckpoint(){
taskExecutorGateway.triggerCheckpoint(){ // rpc调用,tm 封装了 te
task.triggerCheckpointBarrier(){
invokable.triggerCheckpointAsync
}
}
}
}
}
}
// source function
SourceStreamTask.triggerCheckpointAsync(){
mailboxProcessor.getMainMailboxExecutor().submit(() -> triggerCheckpoint(){
StreamTask.performCheckpoint(){
prepareSnapshotPreBarrier()
broadcastCheckpointBarrier()
checkpointState(){
storage = checkpointStorage.resolveCheckpointStorageLocation
new CheckpointingOperation.executeCheckpointing {
// synchronous checkpoints
for (StreamOperator<?> op : allOperators) {
checkpointStreamOperator(op);
}
// asynchronous part
StreamTask.asyncOperationsThreadPool.execute(new AsyncCheckpointRunnable);
}
}
}
});
}
// non-source function. The CheckpointedInputGate uses CheckpointBarrierHandler to handle incoming CheckpointBarrier from the InputGate.
pollNext(){
if (bufferOrEvent.getEvent().getClass() == CheckpointBarrier.class) {
CheckpointBarrierAligner.processBarrier() {
// regular case
onBarrier(channelIndex) {
blockedChannels[channelIndex] = true;
}
// 判断是否已经全部对齐
notifyCheckpoint() {
toNotifyOnCheckpoint.triggerCheckpointOnBarrier() {
performCheckpoint() //
}
}
}
}
}
参考:
Apache Flink 进阶(三):Checkpoint 原理剖析与应用实践
《Stream Processing with Apache Flink》
Apache Flink 管理大型状态之增量 Checkpoint 详解
Tuning Checkpoints and Large State
Back Pressure
基础
概念:数据管道中某个节点处理速率跟不上上游发送数据的速率,而对上游,直到数据源,进行限速。
原理:Flink 拓扑中每个节点(Task)间的数据都以阻塞队列的方式传输,下游来不及消费导致队列被占满后,上游的生产也会被阻塞,最终导致数据源的摄入被阻塞。

影响:
- 潜在的性能瓶颈,可能导致更大的数据延迟。
- 增加 checkpoint 时长,因为 checkpoint barrier 不会超过普通数据,而数据的阻塞也导致 barrier 的阻塞。
- 在 exactly-once 下,state 变大,因为 checkpoint barrier 需要对齐,导致快的节点要等慢的节点,此时快的节点可能已经处理了很多数据,这些数据在慢节点完成 checkpoint 前都要被缓存加到 state 中。(对于 heap-base statebackend 影响更大,可能 oom)
处理
-
定位:
-
基于网络的反压 metrics 并不能定位到具体的 Operator,只能定位到 Task。
![]()
-

TaskManager 传输数据时,不同的 TaskManager 上的两个 Subtask 间通常根据 key 的数量有多个 Channel,这些 Channel 会复用同一个 TaskManager 级别的 TCP 链接,并且共享接收端 Subtask 级别的 Buffer Pool。在接收端,每个 Channl 在初始阶段会被分配固定数量的 Exclusive Buffer,这些 Buffer 会被用于存储接受到的数据,交给 Operator 使用后再次被释放。Channel 接收端空闲的 Buffer 数量称为 Credit,Credit 会被定时同步给发送端被后者用于决定发送多少个 Buffer 的数据。在流量较大时,Channel 的 Exclusive Buffer 可能会被写满,此时 Flink 会向 Buffer Pool 申请剩余的 Floating Buffer。这些 Floating Buffer 属于备用 Buffer,哪个 Channel 需要就去哪里。而在 Channel 发送端,一个 Subtask 所有的 Channel 会共享同一个 Buffer Pool,这边就没有区分 Exclusive Buffer 和 Floating Buffer。
| Metris | 描述 |
| :--------------------------------- | :------------------------------- |
| outPoolUsage | 发送端 Buffer 的使用率 |
| inPoolUsage | 接收端 Buffer 的使用率 |
| floatingBuffersUsage(1.9 以上) | 接收端 Floating Buffer 的使用率 |
| exclusiveBuffersUsage (1.9 以上) | 接收端 Exclusive Buffer 的使用率 |
inPoolUsage = floatingBuffersUsage + exclusiveBuffersUsage
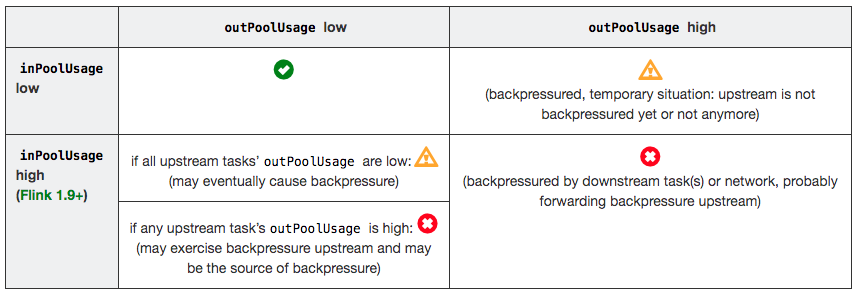
当 outPoolUsage 和 inPoolUsage 使用率同低正常,同高被下游反压,不同时,要么是反压传递阶段,要么就是反压根源。如果一个 Subtask 的 outPoolUsage 是高,通常是被下游 Task 所影响,所以可以排查它本身是反压根源的可能性。如果一个 Subtask 的 outPoolUsage 是低,但其 inPoolUsage 是高,则表明它有可能是反压的根源。反压有时是短暂的且影响不大,比如来自某个 Channel 的短暂网络延迟或者 TaskManager 的正常 GC。
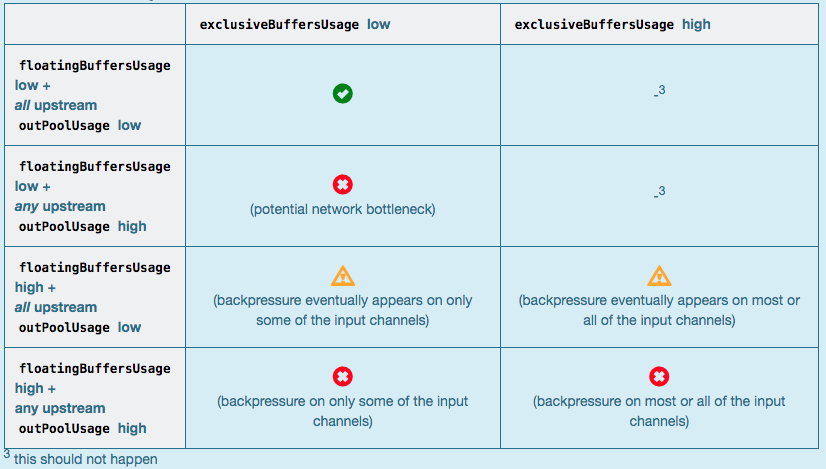
通常来说,floatingBuffersUsage 为高则表明反压正在传导至上游,而 exclusiveBuffersUsage 则表明了反压是否存在倾斜(floatingBuffersUsage 高、exclusiveBuffersUsage 低为有倾斜,因为少数 channel 占用了大部分的 Floating Buffer)。
-
Web UI:提供了 SubTask 级别的反压监控。
通过周期性对 Task 线程的栈信息采样,得到线程被阻塞在请求 Buffer(意味着被下游队列阻塞)的频率来判断该节点是否处于反压状态。默认配置下,这个频率在 0.1 以下则为
OK,0.1 至 0.5 为LOW,而超过 0.5 则为HIGH。问题有两种可能:- 节点的发送速率跟不上它的产生数据速率(如 flatmap 中一条输入产生多条输出)
- 下游节点反压导致。反压面板监控的是发送端,如果某个节点是性能瓶颈并不会导致它本身出现高反压,而是导致它的上游出现高反压。
如果我们找到第一个出现反压的节点,那么反压根源要么是就这个节点,要么是它紧接着的下游节点。区分这两种状态需要结合上面的 metrics。
如果作业的节点数很多或者并行度很大,由于要采集所有 Task 的栈信息,反压面板的压力也会很大甚至不可用。
-
分析
- Web UI 各个 SubTask 的 Records Sent 和 Record Received
- Checkpoint detail 里不同 SubTask 的 State size
- 对 TaskManager 进行 CPU profile,从中我们可以分析到 Task Thread 是否跑满一个 CPU 核,是的话,是哪个函数效率低;不是的话,哪里阻塞。
未来的版本 Flink 将会直接在 WebUI 提供 JVM 的 CPU 火焰图。
- 如果是内存或GC相关,可以启动G1优化,加上
-XX:+PrintGCDetails来观察日志。
原理扩展
首先 Producer Operator 从自己的上游或者外部数据源读取到数据后,对一条条的数据进行处理,处理完的数据首先输出到 Producer Operator 对应的 NetWork Buffer 中。Buffer 写满或者超时或者特殊事件(如 checkpoint barrier)后,就会触发将 NetWork Buffer 中的数据拷贝到 Producer 端 Netty 的 ChannelOutbound Buffer(严格来讲,Output flusher 不提供任何保证——它只向 Netty 发送通知,而 Netty 线程会按照能力与意愿进行处理,所以即便触发了 flush,也不一定发送数据),之后又把数据拷贝到 Socket 的 Send Buffer 中,这里有一个从用户态拷贝到内核态的过程,最后通过 Socket 发送网络请求,把 Send Buffer 中的数据发送到 Consumer 端的 Receive Buffer。数据到达 Consumer 端后,再依次从 Socket 的 Receive Buffer 拷贝到 Netty 的 ChannelInbound Buffer,再拷贝到 Consumer Operator 的 NetWork Buffer,最后 Consumer Operator 就可以读到数据进行处理了。这就是两个 TaskManager 之间的数据传输过程,我们可以看到发送方和接收方各有三层的 Buffer。
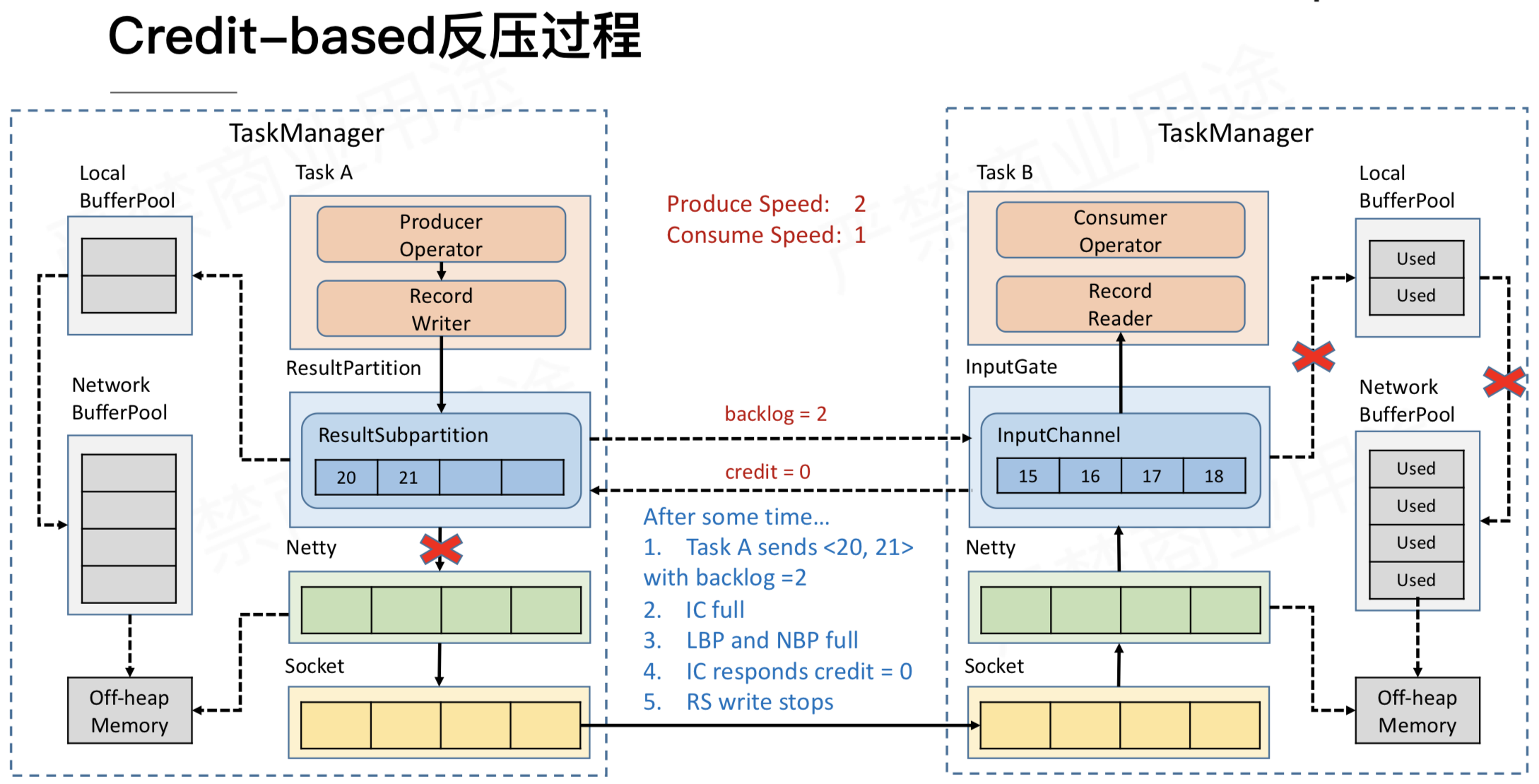
每个 Operator 计算数据时,输出和输入都有对应的 NetWork Buffer,这个 NetWork Buffer 对应到 Flink 就是图中所示的 ResultSubPartition 和 InputChannel。ResultSubPartition 和 InputChannel 都是向 LocalBufferPool 申请 Buffer 空间,然后 LocalBufferPool 再向 NetWork BufferPool 申请内存空间。这里,NetWork BufferPool 是 TaskManager 内所有 Task 共享的 BufferPool,TaskManager 初始化时就会向堆外内存申请 NetWork BufferPool。LocalBufferPool 是每个 Task 自己的 BufferPool,假如一个 TaskManager 内运行着 5 个 Task,那么就会有 5 个 LocalBufferPool,但 TaskManager 内永远只有一个 NetWork BufferPool。Netty 的 Buffer 也是初始化时直接向堆外内存申请内存空间。虽然可以申请,但是必须明白内存申请肯定是有限制的,不可能无限制的申请,我们在启动任务时可以指定该任务最多可能申请多大的内存空间用于 NetWork Buffer。
Flink 1.5 后才用 credit 反压机制,例如,上游 SubTask A.2 发送完数据后,还有 5 个 Buffer 被积压,那么会把发送数据和 Backlog size = 5 一块发送给下游 SubTask B.4,下游接受到数据后,知道上游积压了 5 个Buffer,于是向 Buffer Pool 申请 Buffer,由于容量有限,下游 InputChannel 目前仅有 2 个 Buffer 空间,所以,SubTask B.4 会向上游 SubTask A.2 反馈 Channel Credit = 2。然后上游下一次最多只给下游发送 2 个 Buffer 的数据,这样每次上游发送的数据都是下游 InputChannel 的 Buffer 可以承受的数据量。当可发数据为0时,上游会定期地仅发送 backlog size 给下游,直到下游反馈大于0的 credit。
当然,有了这个机制也并不代表 Flink 能解决外部的反压问题。比如 Flink 写入 ES,而 ES 没有反馈机制,那么就会导致 ES 的 socket 被塞满,甚至响应 timeout,结果任务就失败了。Kafka 有反馈功能。
参考
语义/exactly-once
基础
-
AT-MOST-ONCE:do nothing,数据丢失,适合准确度要求不高的。
-
AT-LEAST-ONCE:保证没有数据丢失,即便对数据进行重复处理。适合计算最值的情况。
-
EXACTLY-ONCE:没有数据丢失、事件只会产生一次最终结果。本质还是处理多次,但之前的处理被抹去。
end-to-end exactly-once 原理:
前提:end-to-end exactly-once 需要外部组件提供 commit 和 roll back 功能。二阶段提交是兼容这两个功能的常用方案。下面以 kafka - flink - kafka 为例。数据的输出必须全部在一个 transaction 里,commit 包含两个 cp 间的所有数据,这样来保证数据输出能够 roll back。在分布式的场景下,commit 和 rollback 需要整体的 agree,这里就要使用 2pc 了。
过程:开始 cp 表示 pre-commit,JM 发送 checkpoint barrier 来对数据进行分割,barrier 前面为本次 cp 数据,后面为下次 cp 数据。barrier 经过 operator 时会触发该 operator 的 state backend 快照它的 state。当所有 operator 的快照完成,包括 pre-committed external state,这时 cp 就完成了。下一步 JM 通知所有 operators cp 完成,但实际上只有 sink 需要响应,即进行最终 commit。
这个过程的 pre-commit 如果有失败,整个 cp 都是失败,马上进行回滚。另外,在 commit 阶段,必须在 kafka transaction timeout 内正常完成(期间可能出现网络异常、flink重启等),否则会丢失该批 commit 数据的结果。
消费端注意:isolation.level 为 read_committed
使用
TwoPhaseCommitSinkFunction
1. beginTransaction - to begin the transaction, we create a temporary file in a temporary directory on our destination file system. Subsequently, we can write data to this file as we process it.
2. preCommit - on pre-commit, we flush the file, close it, and never write to it again. We’ll also start a new transaction for any subsequent writes that belong to the next checkpoint.
3. commit - on commit, we atomically move the pre-committed file to the actual destination directory. Please note that this increases the latency in the visibility of the output data.
4. abort - on abort, we delete the temporary file.
原理扩展
public abstract class TwoPhaseCommitSinkFunction<IN, TXN, CONTEXT>
extends RichSinkFunction<IN>
implements CheckpointedFunction, CheckpointListener {
// 首先在 initializeState 方法中开启事务,对于 Flink sink 的两阶段提交.
// 第一阶段就是执行 CheckpointedFunction#snapshotState 当所有 task 的 checkpoint 都完成之后,每个 task 会执行 CheckpointedFunction#notifyCheckpointComplete 也就是所谓的第二阶段。
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
// this is like the pre-commit of a 2-phase-commit transaction
// we are ready to commit and remember the transaction
long checkpointId = context.getCheckpointId();
// 第一次调用的事务都在 initializeState 方法中
preCommit(currentTransactionHolder.handle);
// 保存了每个 checkpoint 对应的事务
pendingCommitTransactions.put(checkpointId, currentTransactionHolder);
// 下一次的事务处理者
currentTransactionHolder = beginTransactionInternal();
state.clear();
state.add(new State<>(
this.currentTransactionHolder,
new ArrayList<>(pendingCommitTransactions.values()),
userContext));
}
@Override
public final void notifyCheckpointComplete(long checkpointId) throws Exception {
// the following scenarios are possible here
//
// (1) there is exactly one transaction from the latest checkpoint that
// was triggered and completed. That should be the common case.
// Simply commit that transaction in that case.
//
// (2) there are multiple pending transactions because one previous
// checkpoint was skipped. That is a rare case, but can happen
// for example when:
//
// - the master cannot persist the metadata of the last
// checkpoint (temporary outage in the storage system) but
// could persist a successive checkpoint (the one notified here)
//
// - other tasks could not persist their status during
// the previous checkpoint, but did not trigger a failure because they
// could hold onto their state and could successfully persist it in
// a successive checkpoint (the one notified here)
//
// In both cases, the prior checkpoint never reach a committed state, but
// this checkpoint is always expected to subsume the prior one and cover all
// changes since the last successful one. As a consequence, we need to commit
// all pending transactions.
//
// (3) Multiple transactions are pending, but the checkpoint complete notification
// relates not to the latest. That is possible, because notification messages
// can be delayed (in an extreme case till arrive after a succeeding checkpoint
// was triggered) and because there can be concurrent overlapping checkpoints
// (a new one is started before the previous fully finished).
//
// ==> There should never be a case where we have no pending transaction here
//
Iterator<Map.Entry<Long, TransactionHolder<TXN>>> pendingTransactionIterator = pendingCommitTransactions.entrySet().iterator();
Throwable firstError = null;
// 全部事务提交
while (pendingTransactionIterator.hasNext()) {
Map.Entry<Long, TransactionHolder<TXN>> entry = pendingTransactionIterator.next();
Long pendingTransactionCheckpointId = entry.getKey();
TransactionHolder<TXN> pendingTransaction = entry.getValue();
if (pendingTransactionCheckpointId > checkpointId) {
continue;
}
logWarningIfTimeoutAlmostReached(pendingTransaction);
try {
commit(pendingTransaction.handle);
} catch (Throwable t) {
if (firstError == null) {
firstError = t;
}
}
pendingTransactionIterator.remove();
}
if (firstError != null) {
throw ...
}
}
}
参考:
An Overview of End-to-End Exactly-Once Processing in Apache Flink
资源管理
Flink 的内存管理也主要指 TaskManager 的内存管理。TM 的资源(主要是内存)分为三个层级,分别是最粗粒度的进程级(TaskManager 进程本身),线程级(TaskManager 的 slot)和 SubTask 级(多个 SubTask 共用一个 slot)。
-
进程:
- Heap Memory: 由 JVM 直接管理的 heap 内存,留给用户代码以及没有显式内存管理的 Flink 系统活动使用(比如 StateBackend、ResourceManager 的元数据管理等)。
- Network Memory: 用于网络传输(比如 shuffle、broadcast)的内存 Buffer 池,属于 Direct Memory 并由 Flink 管理。
- Cutoff Memory: 在容器化环境下进程使用的物理内存有上限,需要预留一部分内存给 JVM 本身,比如线程栈内存、class 等元数据内存、GC 内存等。
- Managed Memory: 由 Flink Memory Manager 直接管理的内存,是数据在 Operator 内部的物理表示。Managed Memory 可以被配置为 on-heap 或者 off-heap (direct memory)的,off-heap 的 Managed Memory 将有效减小 JVM heap 的大小并减轻 GC 负担。目前 Managed Memory 只用于 Batch 类型的作业,需要缓存数据的操作比如 hash join、sort 等都依赖于它。
-
线程:
TaskManager 会将其资源均分为若干个 slot (在 YARN/Mesos/K8s 环境通常是每个 TaskManager 只包含 1 个 slot),没有 slot sharing 的情况下每个 slot 可以运行一个 SubTask 线程。除了 Managed Memory,属于同一 TaskManager 的 slot 之间基本是没有资源隔离的,包括 Heap Memory、Network Buffer、Cutoff Memory 都是共享的。所以目前 slot 主要的用处是限制一个 TaskManager 的 SubTask 数。默认情况下, Flink 允许多个 SubTask 共用一个 slot 的资源,前提是这些 SubTask 属于同一个 Job 的不同 Task。这样能够节省 slot(线程数),且有效利用资源(比如在同一个 slot 的 source 和 map,source 主要使用网络 IO,而 map 可能主要需要 cpu)
目前 Flink 的内存管理是比较粗粒度的,资源隔离并不是很完整,而且在不同部署模式下(Standalone/YARN/Mesos/K8s)或不同计算模式下(Streaming/Batch)的内存分配也不太一致,为深度平台化及大规模应用增添了难度。
目前 Flink 的资源是预先静态分配的,也就是说 TaskManager 进程启动后 slot 的数目和每个 slot 的资源数都是固定的而且不能改变,这些 slot 的生命周期和 TaskManager 是相同的。Flink Job 后续只能向 TaskManager 申请和释放这些 slot,而没有对 slot 资源数的话语权。
Flink 1.10 的改进
-
统一内存配置
![]()
-
动态 slot:目前涉及到 Managed Memory 资源,TaskManager 的其他资源比如 JVM heap 还是多个 slot 共享的。
-
细粒度的算子资源管理:
- 户使用 API 构建的 Operator(以 Transformation 表示)会附带
ResourceSpecs,描述该 Operator 需要的资源,默认为unknown。 - 当生成 JobGraph 的时候,StreamingJobGraphGenerator 根据
ResourceSpecs计算出每个 Operator 占的资源比例(主要是 Managed Memory 的比例)。 - 进行调度的时候,Operator 的资源将被加总成为 Task 的
ResourceProfiles(包括 Managed Memory 和根据 Task 总资源算出的 Network Memory)。这些 Task 会被划分为 SubTask 实例被部署到 TaskManager 上。 - 当 TaskManager 启动 SubTask 的时候,会根据各 Operator 的资源占比划分 Slot Managed Memory。划分的方式可以是用户指定每个 Operator 的资源占比,或者默认均等分。
- 户使用 API 构建的 Operator(以 Transformation 表示)会附带

Mechine Learning/AI
基础
流批统一框架

- 首先是数据的管理和获取阶段(Data Acquisition),在这个阶段 Flink 提供了非常丰富的 connector(包括对 HDFS,Kafka 等多种存储的支持),Flink 目前还没有提供对整个数据集的管理。
- 下一个阶段是整个数据的预处理(Preprocessing)及特征工程部分,在这个阶段 Flink 已经是一个批流统一的计算引擎,并且提供了较强的 SQL 支持。
- 之后是模型训练过程(Model Training),在这个过程中,Flink 提供了 Iterator 的支持,并且有如 Alink,MLlib 这样丰富的机器学习库支持,且支持 TensorFlow,Pytorch 这样的深度学习框架。
- 模型产出之后是模型验证和管理阶段(Model Validation & Serving),这个阶段 Flink 目前还没有涉足。
- 最后是线上推理阶段(Inference),这个阶段 Flink 还没有形成一套完整的方案。同时形成了 Flink ML Pipeline,以及目前正在做的 Flink AI Flow。
上面框架涉及到两个开源项目
https://github.com/alibaba/Alink
https://github.com/alibaba/flink-ai-extended
Flink ML Pipeline
Pipeline 主要涉及两个抽象,第一个是 Transformer 抽象,是对数据预处理和在线推理的抽象。第二个抽象是 Estimator 抽象,主要是对整个模型训练的抽象。两个抽象最大的差异是 Transformer 是将一份数据转化为另一份处理后的数据,而 Estimator 是将数据进行训练转化为模型。
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号