基于Flink的视频直播案例(下)
直播数字化运营
业务目标
- 全站观看直播总人数以及走势
- 房间直播总人数以及走势
- 热门直播房间及主播Top10,分类目主播Top10
// 开始和上一个业务一样,创建cleanMapFun来提取需要的数据属性,这里只需要时间戳、roomid和userid三个属性
// 第二个功能:先计算每5分钟各房间的人数,这样能同时为总人数的计算进行预聚合。这里直接利用ProcessWindowFunction进行计算,而不是先aggregate后再进行process计算。这里想的是由于窗口变小,所以积聚的数据可能不会太多,而且得到数据后一次性计算要更快。
SingleOutputStreamOperator<Tuple3<Long, Integer, Set<Long>>> visitorsPerRoom = cleanStream
.keyBy(OperationRecord::getRoomid)
.window(TumblingEventTimeWindows.of(Time.minutes(5)))
.process(new ProcessWindowFunction<OperationRecord, Tuple3<Long, Integer, Set<Long>>, Integer,
TimeWindow>() {
@Override
public void process(Integer integer, Context context, Iterable<OperationRecord> elements,
Collector<Tuple3<Long, Integer, Set<Long>>> out) {
int key = 0;
HashSet<Long> set = new HashSet<>();
Iterator<OperationRecord> iter = elements.iterator();
if (iter.hasNext()) {
OperationRecord next = iter.next();
key = next.getRoomid();
set.add(next.getUserid());
}
while (iter.hasNext()) {
set.add(iter.next().getUserid());
}
out.collect(new Tuple3<>(context.window().getStart(), key, set));
}
});
// 第一个功能实现,全网观看人数。由于经过了上一步的预聚合,这里就可以直接用windowAll来聚合了。
//当然,如果全网人多确实很多,那么下面实现并不可行,毕竟set会变得很大。更可行的方法在后面的第二种思路。
//另外,下面是一种连续窗口的实现,即上一步[00:00:00~00:05:00)的结果会被发到这里的[00:00:00~00:05:00)窗口
SingleOutputStreamOperator<Tuple2<Long, Integer>> totalVisit = visitorsPerRoom
.windowAll(TumblingEventTimeWindows.of(Time.minutes(5)))
.process(new ProcessAllWindowFunction<Tuple3<Long, Integer, Set<Long>>, Tuple2<Long, Integer>,
TimeWindow>() {
@Override
public void process(Context context, Iterable<Tuple3<Long, Integer, Set<Long>>> elements,
Collector<Tuple2<Long, Integer>> out) throws Exception {
HashSet<Long> set = new HashSet<>();
Iterator<Tuple3<Long, Integer, Set<Long>>> iter = elements.iterator();
while (iter.hasNext()) {
set.addAll(iter.next().f2);
}
out.collect(new Tuple2<>(context.window().getStart(), set.size()));
}
});
// 在实现第三个功能前先进行一下数据清洗。
SingleOutputStreamOperator<Tuple3<Long, Integer, Integer>> visitPerRoom = visitorsPerRoom
.map(new MapFunction<Tuple3<Long, Integer, Set<Long>>, Tuple3<Long, Integer, Integer>>() {
@Override
public Tuple3<Long, Integer, Integer> map(Tuple3<Long, Integer, Set<Long>> elem) {
return new Tuple3<>(elem.f0, elem.f1, elem.f2.size());
}
});
// 第三个功能,观看人数最多的前10个房间
SingleOutputStreamOperator<Tuple3<Long, Integer, Integer>> topnRoom = visitPerRoom
.windowAll(TumblingEventTimeWindows.of(Time.minutes(5)))
.aggregate(new TopK2AllAggFunc(), new ProcessAllWindowFunction<Integer[][],
Tuple3<Long, Integer, Integer>, TimeWindow>() {
@Override
public void process(Context context, Iterable<Integer[][]> elements,
Collector<Tuple3<Long, Integer, Integer>> out) {
Iterator<Integer[][]> iter = elements.iterator();
while (iter.hasNext()) {
Integer[][] next = iter.next();
for (Integer[] room2visit : next) {
out.collect(new Tuple3<>(context.window().getStart(), room2visit[0], room2visit[1]));
}
}
}
});
// TopK2AllAggFunc的中间结果这里利用优先队列来存储。
public class TopK2AllAggFunc implements AggregateFunction<Tuple3<Long, Integer, Integer>, PriorityQueue<Integer[]>,
Integer[][]> {
/**
* 0 => timestamp
* 1 => roomid
* 2 => num of visitor
*/
@Override
public PriorityQueue<Integer[]> createAccumulator() {
return new PriorityQueue<>(10, Comparator.comparing((elem) -> elem[1]));
}
@Override
public PriorityQueue<Integer[]> add(Tuple3<Long, Integer, Integer> value, PriorityQueue<Integer[]> accumulator) {
if (accumulator.size() < 10) {
Integer[] room2visit = new Integer[2];
room2visit[0] = value.f1;
room2visit[1] = value.f2;
accumulator.add(room2visit);
} else {
Integer[] tmp = accumulator.poll();
if (tmp[1] < value.f2) {
Integer[] room2visit = new Integer[2];
room2visit[0] = value.f1;
room2visit[1] = value.f2;
accumulator.add(room2visit);
} else accumulator.add(tmp);
}
return accumulator;
}
@Override
public Integer[][] getResult(PriorityQueue<Integer[]> accumulator) {
List<Integer[]> list = new ArrayList<>(10);
list.addAll(accumulator);
Integer[][] res = new Integer[list.size()][2];
res = list.toArray(res);
return res;
}
@Override
public PriorityQueue<Integer[]> merge(PriorityQueue<Integer[]> acc1, PriorityQueue<Integer[]> acc2) {
List<Integer[]> list = new ArrayList<>(10);
list.addAll(acc2);
Integer[][] acc2list = new Integer[list.size()][2];
acc2list = list.toArray(acc2list);
for (int i = 0; i < acc2list.length; i++) {
Integer[] curArr = acc2list[i];
if (acc1.size() < 10) {
acc1.add(curArr);
} else {
Integer[] tmp = acc1.poll();
if (tmp[1] < curArr[1]) {
acc1.add(curArr);
} else acc1.add(tmp);
}
}
return acc1;
}
}
// 第四个功能,分类别的top10实现。这里需要引入外部的维度数据,给每个房间加上类别标签。
// 这个维度表预先存储在redis中,通过自定义sourcefunction来获取,并利用broadcast来让这个表存储在每个operator中,这样就类似spark中的广播变量了,每条需要处理的数据都能获取到这个表的数据,实现如下。
DataStreamSource<String> room2cat = env.addSource(new MyRedisSource());
room2cat.name("RedisSource");
MapStateDescriptor<Integer, String> roomId2catDescriptor =
new MapStateDescriptor<Integer, String>(
"RoomId2catBroadcastState",
BasicTypeInfo.INT_TYPE_INFO,
BasicTypeInfo.STRING_TYPE_INFO);
BroadcastStream<String> bc = room2cat.broadcast(roomId2catDescriptor);
SingleOutputStreamOperator<Tuple5<Long, Integer, String, Integer, Integer>> top2cat = visitPerRoom.connect(bc)
.process(new Room2CatBCFunc())
.keyBy(elem -> elem.f1)
.window(TumblingEventTimeWindows.of(Time.minutes(5)))
.process(new TopK2CatProcFunc());
public class Room2CatBCFunc extends BroadcastProcessFunction<Tuple3<Long, Integer, Integer>, String,
Tuple3<Integer, String, Integer>> {
/**
* 0 => timestamp 去掉
* 1 => roomid
* 2 => room_cat_name
* 3 => num of visitors
*/
private static final MapStateDescriptor<Integer, String> roomId2catDescriptor =
new MapStateDescriptor<>(
"RoomId2catBroadcastState",
BasicTypeInfo.INT_TYPE_INFO,
BasicTypeInfo.STRING_TYPE_INFO);
@Override
public void processElement(Tuple3<Long, Integer, Integer> value, ReadOnlyContext ctx,
Collector<Tuple3<Integer, String, Integer>> out) throws Exception {
ReadOnlyBroadcastState<Integer, String> bcState = ctx.getBroadcastState(roomId2catDescriptor);
String cat = bcState.get(value.f1);
if (cat != null) {
out.collect(new Tuple3<>(value.f1, cat, value.f2));
} else out.collect(new Tuple3<>(value.f1, "UNK", value.f2));
}
@Override
public void processBroadcastElement(String value, Context ctx,
Collector<Tuple3<Integer, String, Integer>> out) throws Exception {
String[] split = value.split("=");
ctx.getBroadcastState(roomId2catDescriptor)
.put(Integer.parseInt(split[0]), split[1]);
}
}
public class TopK2CatProcFunc extends ProcessWindowFunction<Tuple3<Integer, String, Integer>,
Tuple5<Long, Integer, String, Integer, Integer>, String, TimeWindow> {
/**
* input
* 0 => roomid
* 1 => room_cat_name
* 2 => room_visitors_cnt
* <p>
* output
* 0 => timestamp
* 1 => roomid
* 2 => room_cat_name
* 3 => room_visitors_cnt
* 4 => rangking
*/
@Override
public void process(String s, Context context, Iterable<Tuple3<Integer, String, Integer>> elements,
Collector<Tuple5<Long, Integer, String, Integer, Integer>> out) {
PriorityQueue<Tuple3<Integer, String, Integer>> pq = new PriorityQueue<>(10, Comparator.comparing(e -> e.f2));
elements.forEach(elem -> {
if (pq.size() < 10) {
pq.add(elem);
} else {
Tuple3<Integer, String, Integer> tmp = pq.poll();
if (tmp.f2 < elem.f2) {
pq.add(elem);
} else {
pq.add(tmp);
}
}
});
List<Tuple3<Integer, String, Integer>> list = new ArrayList<>(10);
list.addAll(pq);
Tuple3<Integer, String, Integer>[] top10 = (Tuple3<Integer, String, Integer>[])new Object[10];
top10 = list.toArray(top10);
Arrays.sort(top10, Comparator.comparingLong(elem -> - elem.f2));
for (int i = 0; i < top10.length; i++) {
Tuple3<Integer, String, Integer> cur = top10[i];
Tuple5<Long, Integer, String, Integer, Integer> res = new Tuple5<>(context.window().getStart(), cur.f0, cur.f1, cur.f2, i + 1);
out.collect(res);
}
}
}
第二部分的DAG如下,图标不能移动只能将就一下了。
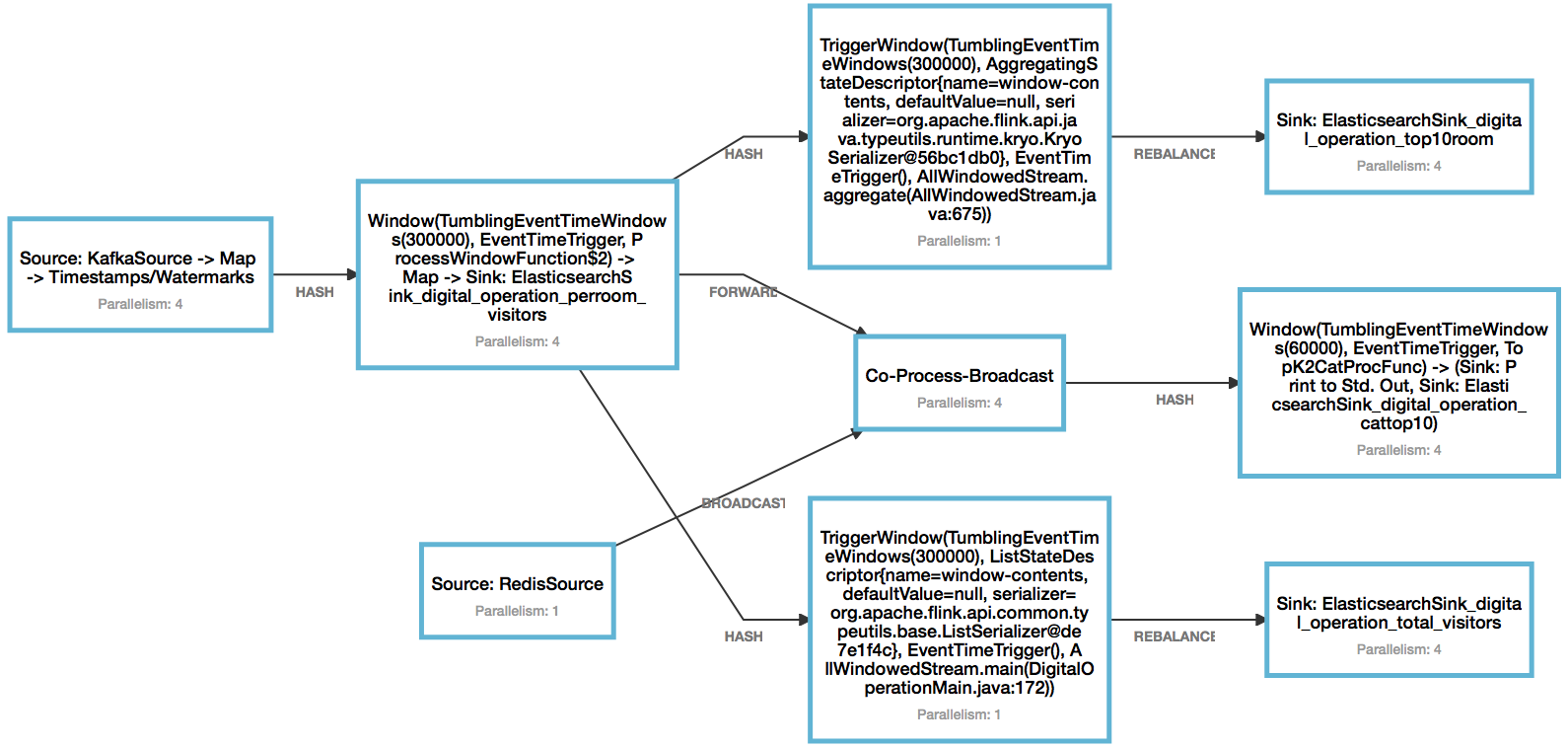
结果写入Elasticsearch
写入Elasticsearch的代码都是一个样式,所以在这里统一放出。
ArrayList<HttpHost> httpHosts = new ArrayList<>();
httpHosts.add(new HttpHost("localhost", 9200, "http"));
ElasticsearchSink.Builder<Tuple5<Long, Integer, String, Integer, Integer>> esSinkBuilder4 =
new ElasticsearchSink.Builder<>(httpHosts,
new ElasticsearchSinkFunction<Tuple5<Long, Integer, String, Integer, Integer>>() {
public IndexRequest createIndexRequest(Tuple5<Long, Integer, String, Integer, Integer> element) {
/**
* 0 => timestamp
* 1 => roomid
* 2 => category_name,
* 3 => app_room_user_cnt,
* 4 => rangking
*/
Map<String, Object> json = new HashMap<>();
json.put("timestamp", element.f0);
json.put("roomid", element.f1);
json.put("cat", element.f2);
json.put("roomuser", element.f3);
json.put("rank", element.f4);
String date = INDEX_FORMAT.format(element.f0);
// 唯一id
String id = Long.toString(element.f0) + element.f2 + element.f4;
return Requests.indexRequest()
// index 按天来划分
.index("digital_operation_cattop10-" + date)
.type("cattop10")
.id(id)
.source(json);
}
@Override
public void process(Tuple5<Long, Integer, String, Integer, Integer> element,
RuntimeContext ctx, RequestIndexer indexer) {
indexer.add(createIndexRequest(element));
}
}
);
//设置批量写数据的缓冲区大小,实际工作中的时间这个值需要调大一些
esSinkBuilder4.setBulkFlushMaxActions(100);
top2cat.addSink(esSinkBuilder4.build()).name("ElasticsearchSink_digital_operation_cattop10");
第二种思路
上面实现计算全站观看人数统计时提到,如果数据量过大,用一个set是不好去重的。其实也可以直接把每个set的size加总。(同一个user同时观看几个主播的情况应该不多吧)如果确实要全局去重,可以尝试下面结合timer的process function来模仿window计算。但在离线测试时结果会受各种因素影响,详细看后面的总结。
下面只展示计算每分钟各房间的人数,全站人数可以模仿这种方法,利用mapstate进行最终的加总。
// 计算每分钟各房间的人数
SingleOutputStreamOperator<Tuple3<Long, Integer, Integer>> visitorsPerRoom = cleanStream
.keyBy(OperationRecord::getRoomid)
.process(new DistinctVisitorsProcFunc());
// 下面利用mapstate进行统计,这个state能够存储到rockdb,所以能够接受更大量的数据。
public class DistinctVisitorsProcFunc extends KeyedProcessFunction<Integer, OperationRecord, Tuple3<Long, Integer, Integer>> {
// 存储当前roomid的unique visitors
MapState<Long, Void> uniqueVisitorState = null;
private static FastDateFormat TIME_FORMAT = FastDateFormat.getInstance("yyyy-MM-dd'T'HH:mm:ss.SSS");
@Override
public void open(Configuration parameters) throws Exception {
MapStateDescriptor<Long, Void> uniqueVisitorStateDescriptor =
new MapStateDescriptor<>(
"UniqueVisitorState",
BasicTypeInfo.LONG_TYPE_INFO,
BasicTypeInfo.VOID_TYPE_INFO);
uniqueVisitorState = getRuntimeContext().getMapState(uniqueVisitorStateDescriptor);
}
@Override
public void processElement(OperationRecord value, Context ctx, Collector<Tuple3<Long, Integer, Integer>> out) throws
Exception {
// 第一个条件针对第一条数据,实际中可以省去,忽略第一条数据
if (ctx.timerService().currentWatermark() == Long.MIN_VALUE ||
value.getTimestamp() >= ctx.timerService().currentWatermark() - 10000L) {
if (!uniqueVisitorState.contains(value.getUserid())) {
uniqueVisitorState.put(value.getUserid(), null);
}
// 一分钟登记一次
long time = (ctx.timestamp() / 60000 + 1) * 60000;
ctx.timerService().registerEventTimeTimer(time);
}
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<Tuple3<Long, Integer, Integer>> out) throws Exception {
int cnt = 0;
List<Long> arr = new ArrayList<>();
for (Map.Entry<Long, Void> entry : uniqueVisitorState.entries()) {
cnt++;
arr.add(entry.getKey());
}
// roomid及其在线人数
out.collect(new Tuple3<>(timestamp, ctx.getCurrentKey(), cnt));
// 本房间在线人数列表,通过sideoutput放出
OutputTag<List<Long>> outputTag = DigitalOperationMain.getOutputTag();
ctx.output(outputTag, arr);
uniqueVisitorState.clear();
}
}
Flink实现总结
-
编写前,在确定好输入输出后还要对总体实现有一个较为详细的规划,比如用什么函数实现什么功能,有些实现可以结合一次处理。
-
每个功能的实现要写一个后马上检查,免得把错误或不合理的代码运用到后面的功能。
-
flink离线测试的结果会受到下面几个因素的影响(如果用windowfunction,那一般不会有影响,有问题的是和ontime相关的操作。但onetime真正实时处理的结果一般不会有问题,这主要是因为真正实时处理时每条数据的时间跨度不会很大,即连续数据的时间戳相差很小,而如果有点大,那这段时间的空档也足够超过buffer的timeout,从而flink能在这段空隙间完成watermark的更新)。
-
时间语意:
-
process time:每条数据被打上到达flink时的时间戳,不考虑数据到达的顺序,没有迟到数据。如果source的parallelism为1,且数据发送顺序不变,那么结果是确定的、可复现的。但如果source的parallelism不是1,导致数据顺序不确定,那么结果则是不确定的。
-
event:每条数据被打上自身的时间戳(避免map后丢失了时间戳属性),并利用这些时间戳来推动watermark,此时需要考虑数据到达的顺序,结果一般是确定的、可复现的(使用process function 的 ontime除外)。
理解watermark的前进需要先理解Periodic Watermarks和Punctuated Watermarks。
-
Periodic通过实现
AssignerWithPeriodicWatermarks来抽取数据时间戳和产生watermark,它会周期性地调用getCurrentWatermark检查watermark是否需要前进,通过env.getConfig().setAutoWatermarkInterval(0L);配置。注意是检查,并不代表调用
getCurrentWatermark后watermark就会前进,取决于具体实现。例如BoundedOutOfOrdernessTimestampExtractor的实现就是按照currentMaxTimestamp - maxOutOfOrderness来设置watermark的,所以如果有一条比后来数据提早很多的数据出现,即其时间戳比其他数据大很多,那么watermark也会有一段时间停止不前。如果
setAutoWatermarkInterval设置过大,在数据乱序严重的情况,如未排序的离线数据,会出现大量大于watermark的数据进入flink,但watermark并不前进,因为还没到下一个检查周期。另外,即便把它设置得足够小,它也不可能像Punctuated那样做到紧跟在每条数据后面,它需要等一批数据(buffer)处理完后才能调用。 -
Punctuated通过
AssignerWithPunctuatedWatermarks实现,与前者的不同是,它会针对每一条数据都会调用checkAndGetNextWatermark来检查是否需要产生新的watermark。 -
注意新的watermark会跟在当前数据的后面(watermark本身就是一条含有时间戳的数据),所以会发现在后续operator计算中,即便watermark更新了,也只是前面的operator更新了,后面的还没有更新。
-
-
-
并发度:测试先用1个并发度比较好理解。
-
窗口函数和结合timer的process function(第二种思路)
- window函数主要有三种,reduce、aggregate和processwindow,前两者只存储一个数据,本质分别是ReducingState和AggregatingState,都类似于ListState。由于不需要存储整个窗口的数据,而是每当数据到达时就进行聚合,所以比processwindow更有效率地利用内存。但reduce的限制是input和output需要相同类型,而aggregate可以不同,但存储中间结果的数据结构需要比较普通的,比如Tuple。曾经尝使用Tuple2<Long, HashSet>来存储中间结果来实现去重,结果报错,但如果直接存HashSet应该没问题。然后是processwindow,操作比较简单,因为数据都存储好了,只等待调用iterator来取。此时新建HashSet也能实现去重,这种方法的不足就是flink需要存储触发processwindow前的所有数据,而且这个processwindow需要一次性处理完数据,这个计算过程没有checkpoint。不过如果窗口跨度不大,影响应该不大。
- 结合timer的process function同样可以实现类似window的功能,而且能够使用state,进而也能实现更多功能,比如针对某个用户,如果访问次数达到阈值别不在处理其数据,又或者多维度去重等。但这种函数比window更复杂。在利用它实现类似窗口计算的功能时会出现一些瑕疵。正如上面所说,产生新watermark的数据会在此watermark的前面。假设设定了1分钟的timer来实现1分钟的窗口计算,那么如果有两条连续数据被这个timer的时间戳分开,那么后面一条数据也会被算进这个“窗口”,这是因为后面数据更新的时间戳跟在它的后面,在触发timer计算前这条数据已经被处理了。如果在多线程环境下,瑕疵会更多,例如一堆数据被处理了,但依然没有触发ontimer。这是因为processelement和ontimer并非连续执行,如果时间变化加大的数据被分到同一buffer,那么就可能遇到处理的数据已经跨过1小时,但设定1分钟后触发的timer并没有被调用的情况。不过这一般只出现非生产环境下,因为在buffer不大,timeout不长的情况下,很难会出现一个buffer有这么大的时间跨度,更一般的情况是处理完一个buffer,watermark才前进1s。当然,如果需要极为严格的处理,window函数就不会出现这种情况,因为window函数会根据数据的时间戳进行划分。
- 总体来说window更容易实现,特别在简单聚合方面效率还很好。而结合timer的process function比较复杂,虽然模拟窗口计算可能会有瑕疵,但如果不要求绝对精确,那么其复杂聚合的效率应该比window好(涉及processwindow的)。
-
Elasticsearch部分
先创建index templates,这里针对“分类目主播Top10”功能的templates进行展示,因为上面的elasticsearch展示的也是这个功能。注意下面编号部分要与前面的elasticsearchsink一致。
PUT _template/digital_operation_cattop10_template
{
"index_patterns": ["digital_operation_cattop10-*"], // 1
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
},
"mappings": {
"cattop10": { // 2
"properties": {
"roomid": { // 3
"type": "integer"
},
"cat": { // 4
"type": "keyword"
},
"roomuser": { // 5
"type": "integer"
},
"rank": { // 6
"type": "integer"
},
"timestamp": { // 7
"type": "date",
"format": "epoch_millis"
}
}
}
}
}
Kibana部分
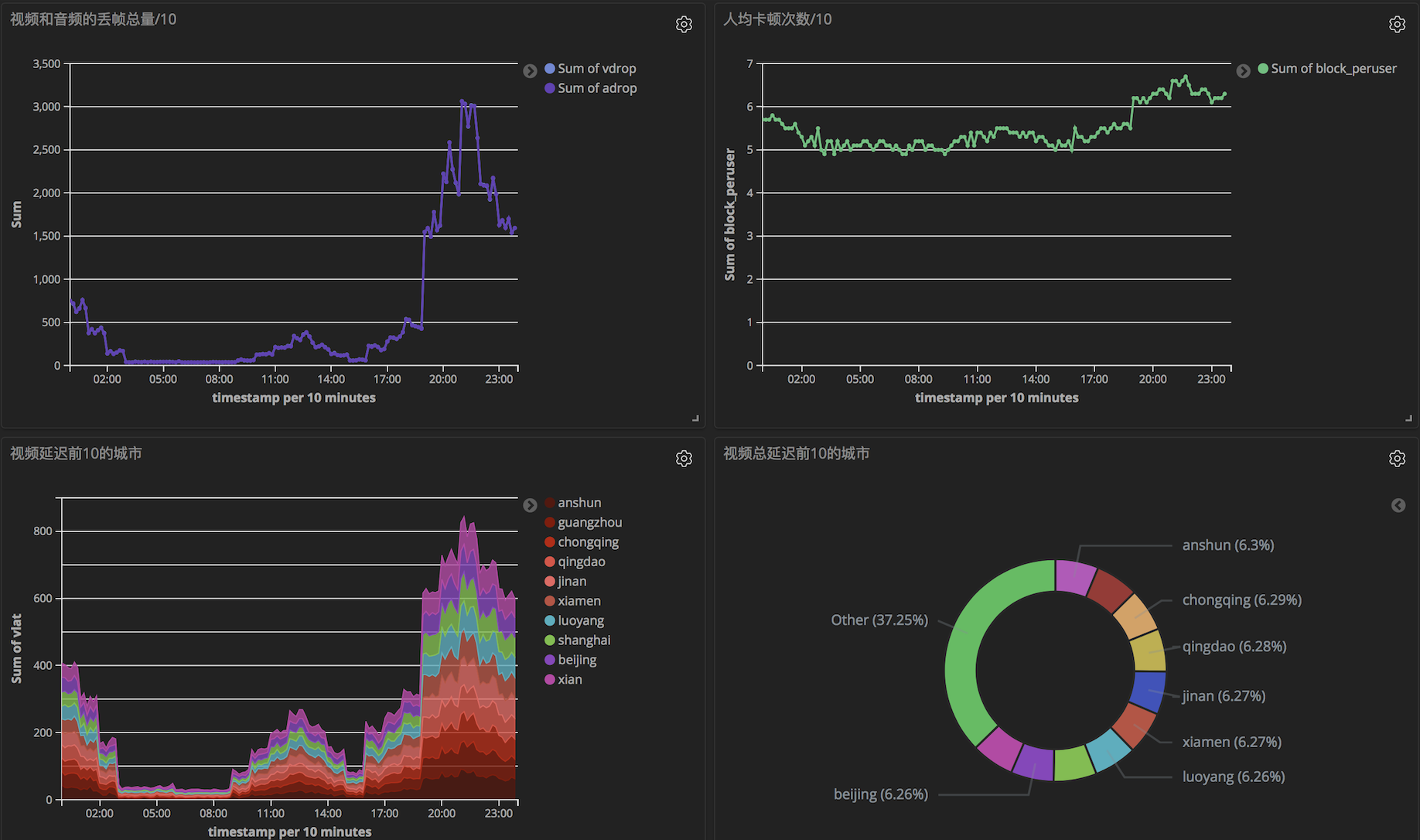
视频核心指标监控
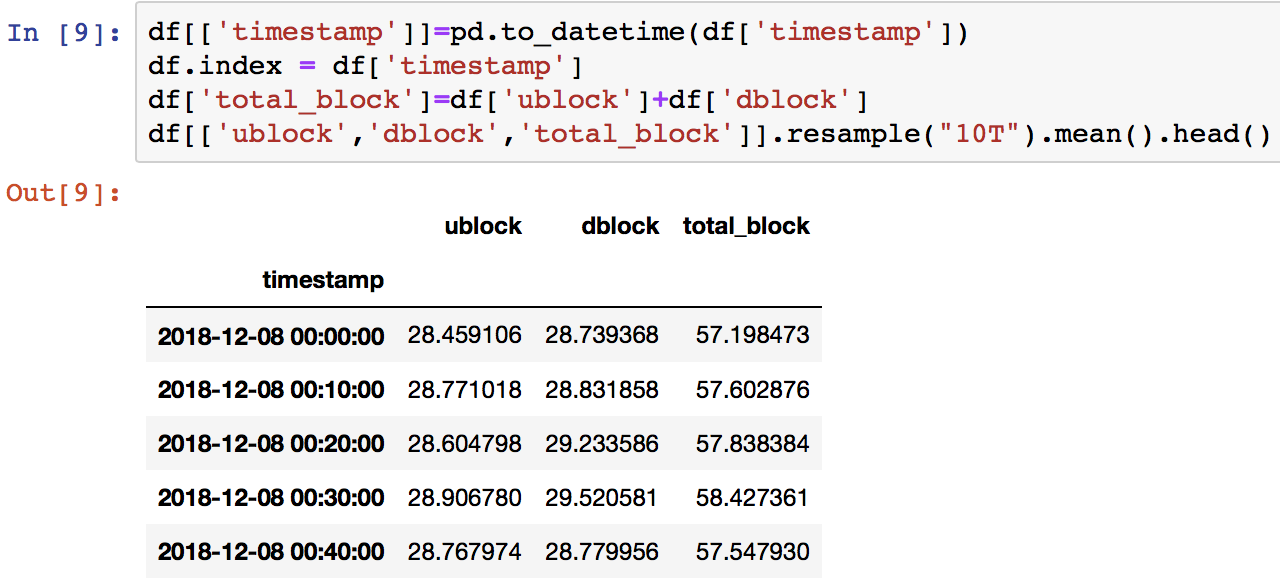
人均卡顿次数有点多,这与模拟数据有关,大部分结果都用python的pandas进行了的验证。
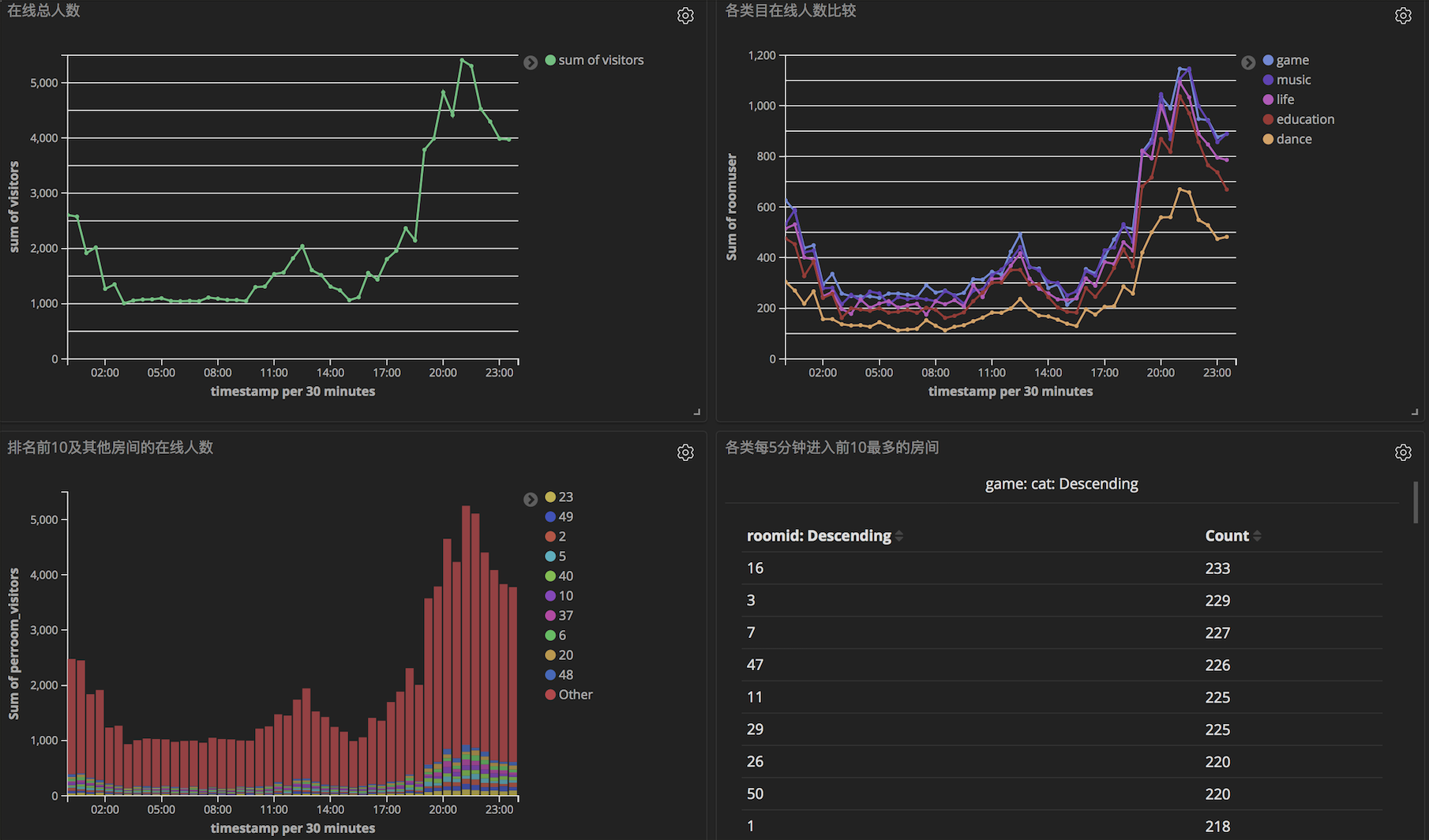
直播数字化运营

 浙公网安备 33010602011771号
浙公网安备 33010602011771号