
Flink之Window Operation
本文API基于1.4以上
Configuring Time Characteristics
非key Stream的window operator并行度为1
Process Time
所有operator会按照系统时间来判断是否触发计算。如果作业是在9:15am开始的,且设置了1h的间隔,那么第一次计算涉及的范围是9:15am到10:00am,下一次就是10:00am~11:00am(不包含后边界)
Timestamps and watermarks for event-time applications
timestamps and watermarks可以从SourceFunction或者用户定义的timestamp assigner和watermark generator产生。第一种就在sourceFunction的run方法中 SourceContex.collectWithTimestamp()和 emitWatermark() 来产生。下面介绍第二种:
如果使用timestamp assigner,所有已存在的timestamp和watermark会被覆盖。
DataStream API提供TimestampAssigner 接口来提取数据的时间戳。timestamp assigner通常会在source function之后调用,除非assign timestamp之前不对流进行重新划分,如keyBy、rebalance等,因之后timestamp就不好处理。assign即使能延后,但也必须在event-time dependent transformation之前,如第一个event-time window。
val readings: DataStream[SensorReading] = env
.addSource(new SensorSource)
// assign timestamps and generate watermarks
.assignTimestampsAndWatermarks(new MyAssigner())
上面的MyAssigner可以是AssignerWithPeriodicWatermarks or AssignerWithPunctuatedWatermarks,两个都继承自TimestampAssigner 。产生的新WM都必须大于之前的WM。
ASSIGNER WITH PERIODIC WATERMARKS
// 添加下面设置后,AssignerWithPeriodicWatermarks就会每个隔5s调用一次getCurrentWatermark()。如果该方法返回一个non-null值,且该值的timestamp大于前一个WM,那么新的WM就会被发送。注意,这必须假设数据的event time时间戳(不是数据时间戳)是递增的,否则方法返回null,没有新WM。
env.getConfig.setAutoWatermarkInterval(5000) // 默认200ms
// 下面产生WM是按照当前所接收到的数据中timestamp最大值-1m,即比最大值小一分钟的数据依然能近窗口,多于1分钟的就要另外处理了。
class PeriodicAssigner
extends AssignerWithPeriodicWatermarks[SensorReading] {
val bound: Long = 60 * 1000 // 1 min in ms
var maxTs: Long = Long.MinValue // the maximum observed timestamp
override def getCurrentWatermark: Watermark = {
// generated watermark with 1 min tolerance
new Watermark(maxTs - bound)
// 下面这个就变成依据process time来创建WM了
new Watermark(System.currentTimeMillis() - bound)
}
override def extractTimestamp(r: SensorReading, previousTS: Long): Long = {
// update maximum timestamp
maxTs = maxTs.max(r.timestamp)
// return record timestamp
r.timestamp
}
}
// 这个是上面的简化版
val output = stream.assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor[MyEvent](
Time.seconds(60))(_.getCreationTime)
// 如果数据的时间戳不是乱序的,可以用下面方法直接按当前时间作为WM的时间戳
val withTimestampsAndWatermarks = stream
.assignAscendingTimestamps(_.getCreationTime)
ASSIGNER WITH PUNCTUATED WATERMARKS
// 这个就不需要setAutoWatermarkInterval了,PunctuatedAssigner 对每个数据都先调用extractTimestamp 后调用 checkAndGetNextWatermark 来判断是否产生WM
class PunctuatedAssigner
extends AssignerWithPunctuatedWatermarks[SensorReading] {
val bound: Long = 60 * 1000 // 1 min in ms
// 在extractTimestamp之后调用
override def checkAndGetNextWatermark(
r: SensorReading,
extractedTS: Long): Watermark = {
if (r.id == "sensor_1") {
// emit watermark if reading is from sensor_1
new Watermark(extractedTS - bound)
} else {
// do not emit a watermark
null
}
}
override def extractTimestamp(
r: SensorReading,
previousTS: Long): Long = {
// assign record timestamp
r.timestamp
}
}
Process Functions
如果需要access keyed state and timers 就用PF(v1.4之前有问题)
PF都是实现了RichFunction接口,所以都有开关方法。另外两个重要方法(他们同步执行,防止并发访问和修改state)是:
- processElement(v: IN, ctx: Context, out: Collector[OUT]):对每条数据调用。它可以通过Context来访问数据的timestamp和任务的TimerService,而且还可以释放记录到其他出口。
- onTimer(timestamp: Long, ctx: OnTimerContext, out: Collector[OUT]):一个回调方法,当之前登记的timer被触发时调用。OnTimerContext和上面的Context类似,它还返回trigger的time domain(processing or event time)
The TimerService and Timers
上面两个的TimerService(即context)有4个方法:
-
currentProcessingTime(): Longreturns the current processing time. -
currentWatermark(): Longreturns the timestamp of the current watermark. -
registerProcessingTimeTimer(timestamp: Long): Unitregisters a processing time timer. The timer will fire when the processing time of the executing machine reaches the provided timestamp. -
registerEventTimeTimer(timestamp: Long)上面的register只针对key streams。To use timers on a non-keyed stream, you can create a keyed stream by using a
KeySelectorwith a constant dummy key. Note that this will move all data to a single task such that the operator would be effectively executed with a parallelism of 1.
对每个key可以登记多个timer,timestamp只有一个。登记后不能删除(1.6后可以)。PF内有所有timer的时间,存放在堆的权重队列,并将它们作为持久化的function state。timer通常用来根据一段时间后清除key state或者实现自定义time-based windowing逻辑。每个key与timestamp组合的timer只能有一个,比如key1 1:00:00如果重复了,只会执行这种timer一次。这里涉及timer的登记技巧,将timer的时间round为秒,这样就不会因数据过多时,每秒产生多个timer。event-time就round为当前WM+1
// 登记
// coalescing到1秒,避免timer频繁登记
val coalescedTime = ((ctx.timestamp + timeout) / 1000) * 1000
// 针对WM的coalescing
val coalescedTime = ctx.timerService.currentWatermark + 1
ctx.timerService.registerProcessingTimeTimer(coalescedTime)
// 删除
ctx.timerService.deleteProcessingTimeTimer(timestampOfTimerToStop)
ctx.timerService.deleteEventTimeTimer(timestampOfTimerToStop)
Timers会被checkpoint(1.5同步,1.6异步checkpoint,除非涉及RocksDB backend / with incremental snapshots / with heap-based timers,最后一个1.7解决),当从失败重启,过其的timer会被马上触发。
val warnings = readings
.keyBy(_.id)
// apply ProcessFunction to monitor temperatures
.process(new TempIncreaseAlertFunction)
// =================== //
/** Emits a warning if the temperature of a sensor
* monotonically increases for 5 second (in processing time).
*/
class TempIncreaseAlertFunction
extends KeyedProcessFunction[String, SensorReading, String] {
// hold temperature of last sensor reading
lazy val lastTemp: ValueState[Double] = getRuntimeContext.getState(
new ValueStateDescriptor[Double]("lastTemp", Types.of[Double]))
// hold timestamp of currently active timer
lazy val currentTimer: ValueState[Long] = getRuntimeContext.getState(
new ValueStateDescriptor[Long]("timer", Types.of[Long]))
override def processElement(
r: SensorReading,
ctx: KeyedProcessFunction[String, SensorReading, String]#Context,
out: Collector[String]): Unit = {
// get previous temperature
val prevTemp = lastTemp.value()
// update last temperature
lastTemp.update(r.temperature)
// 假设温度都在0度以上。prevTemp == 0.0 为了处理prevTemp初始化时为0的问题,避免一开始就判断递增。
if (prevTemp == 0.0 || r.temperature < prevTemp) {
// temperature decreased. Invalidate current timer
currentTimer.update(0L)
}
else if (r.temperature > prevTemp && currentTimer.value() == 0) {
// temperature increased and we have not set a timer yet.
// set processing time timer for now + 1 second
val timerTs = ctx.timerService().currentProcessingTime() + 5000
ctx.timerService().registerProcessingTimeTimer(timerTs)
// remember current timer
currentTimer.update(timerTs)
}
// 如果前后温度相等、递增但是已经登记了一个timer(即currentTimer.value() != 0)就什么都不干,避免过多timer,等timer的processtime过了1s后调用下面的onTimer
}
override def onTimer(
ts: Long, // timer的timestamp
ctx: KeyedProcessFunction[String, SensorReading, String]#OnTimerContext,
out: Collector[String]): Unit = {
// check if firing timer is current timer
if (ts == currentTimer.value()) {
out.collect("Temperature of sensor '" + ctx.getCurrentKey +
"' monotonically increased for 1 second.")
// reset current timer
currentTimer.update(0)
}
}
}
// 另一个例子。
// 计算每个key的数据的数量,如果一分钟(event time)内不再更新数据,则释放key-count对
val result: DataStream[Tuple2[String, Long]] = stream
.keyBy(0)
.process(new CountWithTimeoutFunction())
/**
* The data type stored in the state
*/
case class CountWithTimestamp(key: String, count: Long, lastModified: Long)
/**
* The implementation of the ProcessFunction that maintains the count and timeouts
*/
class CountWithTimeoutFunction extends ProcessFunction[(String, String), (String, Long)] {
/** The state that is maintained by this process function */
lazy val state: ValueState[CountWithTimestamp] = getRuntimeContext
.getState(new ValueStateDescriptor[CountWithTimestamp]("myState", classOf[CountWithTimestamp]))
override def processElement(value: (String, String), ctx: Context, out: Collector[(String, Long)]): Unit = {
// initialize or retrieve/update the state
val current: CountWithTimestamp = state.value match {
case null =>
CountWithTimestamp(value._1, 1, ctx.timestamp)
case CountWithTimestamp(key, count, lastModified) =>
CountWithTimestamp(key, count + 1, ctx.timestamp)
}
// write the state back
state.update(current)
// schedule the next timer 60 seconds from the current event time
ctx.timerService.registerEventTimeTimer(current.lastModified + 60000)
}
override def onTimer(timestamp: Long, ctx: OnTimerContext, out: Collector[(String, Long)]): Unit = {
state.value match {
case CountWithTimestamp(key, count, lastModified) if (timestamp == lastModified + 60000) =>
out.collect((key, count))
case _ =>
}
}
}
Emitting to Side Outputs
side output多个流,且可以不同类型,由OutputTag [X]对象标识。
能够使用该功能的函数有:ProcessFunction、CoProcessFunction、ProcessWindowFunction、ProcessAllWindowFunction
// define a side output tag
val freezingAlarmOutput: OutputTag[String] =
new OutputTag[String]("freezing-alarms")
// =================== //
val monitoredReadings: DataStream[SensorReading] = readings
// monitor stream for readings with freezing temperatures
.process(new FreezingMonitor)
// retrieve and print the freezing alarms
monitoredReadings
.getSideOutput(freezingAlarmOutput)
.print()
// print the main output
readings.print()
// =================== //
class FreezingMonitor extends ProcessFunction[SensorReading, SensorReading] {
override def processElement(
r: SensorReading,
ctx: ProcessFunction[SensorReading, SensorReading]#Context,
out: Collector[SensorReading]): Unit = {
// emit freezing alarm if temperature is below 32F.
if (r.temperature < 32.0) {
ctx.output(freezingAlarmOutput, s"Freezing Alarm for ${r.id}")
}
// forward all readings to the regular output
out.collect(r)
}
}
The CoProcessFunction
// 下面代码的结果是,只有sensor_2和sensor_7的信息输出,而且输出时间只持续10s和1m
// ingest sensor stream
val sensorData: DataStream[SensorReading] = ...
// filter switches enable forwarding of readings
val filterSwitches: DataStream[(String, Long)] = env
.fromCollection(Seq(
("sensor_2", 10 * 1000L), // forward sensor_2 for 10 seconds
("sensor_7", 60 * 1000L)) // forward sensor_7 for 1 minute
)
val forwardedReadings = readings
.connect(filterSwitches)
.keyBy(_.id, _._1) // 将两个stream的信息联系起来了
.process(new ReadingFilter)
// =============== //
class ReadingFilter
extends CoProcessFunction[SensorReading, (String, Long), SensorReading] {
// switch to enable forwarding
lazy val forwardingEnabled: ValueState[Boolean] =
getRuntimeContext.getState(
new ValueStateDescriptor[Boolean]("filterSwitch", Types.of[Boolean])
)
// hold timestamp of currently active disable timer
lazy val disableTimer: ValueState[Long] =
getRuntimeContext.getState(
new ValueStateDescriptor[Long]("timer", Types.of[Long])
)
override def processElement1(
reading: SensorReading,
ctx: CoProcessFunction[SensorReading, (String, Long), SensorReading]#Context,
out: Collector[SensorReading]): Unit = {
// check if we may forward the reading
if (forwardingEnabled.value()) {
out.collect(reading)
}
}
override def processElement2(
switch: (String, Long),
ctx: CoProcessFunction[SensorReading, (String, Long), SensorReading]#Context,
out: Collector[SensorReading]): Unit = {
// enable reading forwarding
forwardingEnabled.update(true)
// set disable forward timer
val timerTimestamp = ctx.timerService().currentProcessingTime() + switch._2
ctx.timerService().registerProcessingTimeTimer(timerTimestamp)
disableTimer.update(timerTimestamp)
}
override def onTimer(
ts: Long,
ctx: CoProcessFunction[SensorReading, (String, Long), SensorReading]#OnTimerContext,
out: Collector[SensorReading]): Unit = {
if (ts == disableTimer.value()) {
// remove all state. Forward switch will be false by default.
forwardingEnabled.clear()
disableTimer.clear()
}
}
}
与join结合
For example, you might be joining customer data to financial trades, while keeping state for the customer data. If you care about having complete and deterministic joins in the face of out-of-order events, you can use a timer to evaluate and emit the join for a trade when the watermark for the customer data stream has passed the time of that trade.
Window Operators
Defining Window Operators
keyed window可以并行,non-keyed window只能单线程。实现window operator需要下面两个组件:
- Window Assigner:决定数据如何被分组。它会产生WindowStream(keyed)或AllWindowedStream(non-keyed)
- Window Function:应用到上面两个产物,并处理被分配到window的数据
Built-in Window Assigners
根据数据的event-time或者processing time来将数据分配到对应的window。当第一个数据分到window时,window才会被创建。window有开始和结束(不包含)timestamp。
Count-based Windows:结果是non-deterministic的。另外,如果没有自定义Trigger来废弃incomplete and stale的windows,会出问题。
// tumbling
val avgTemp = sensorData
.keyBy(_.id)
// group readings in 1s event-time windows
// start at 00:15:00, 01:15:00, 02:15:00, etc
// 中国调整时区Time.hours(-8)
.window(TumblingEventTimeWindows.of(Time.hours(1), Time.minutes(15))) // TumblingProcessingTimeWindows也可
.process(new TemperatureAverager)
// sliding 如果slide大于window interval,部分数据会被drop
// create 1h event-time windows every 15 minutes
.window(SlidingEventTimeWindows.of(Time.hours(1), Time.minutes(15)))
// session
// assigner 开始时将所有数据映射到自己的window,以数据的timestamp为开始窗口,session gap作为window大小,最后再融合所有重叠的窗口。也有动态gap可选,就是自定义逻辑来判断gap长度
.window(EventTimeSessionWindows.withGap(Time.minutes(15)))
Applying Functions on Windows
Incremental Aggregation Functions只保留一个值, ReduceFunction and AggregateFunction实际上这类函数会马上计算并把计算结果存储到window,trigger只是出发结果的发送。当这类函数需要window信息时,可以与下面函数组合,详细看下面第4个例子。
Full Window Functions保留所有数据,当计算时,遍历所有数据,ProcessWindowFunction
ReduceFunction:输入和输出类型相同
val minTempPerWindow: DataStream[(String, Double)] = sensorData
.map(r => (r.id, r.temperature))
.keyBy(_._1)
.timeWindow(Time.seconds(15))
.reduce((r1, r2) => (r1._1, r1._2.min(r2._2)))
AggregateFunction :比上面灵活,类似spark的aggregator
val avgTempPerWindow: DataStream[(String, Double)] = sensorData
.map(r => (r.id, r.temperature))
.keyBy(_._1)
.timeWindow(Time.seconds(15))
.aggregate(new AvgTempFunction)
// ========= //
class AvgTempFunction
extends AggregateFunction[(String, Double), (String, Double, Int), (String, Double)] {
override def createAccumulator() = {
("", 0.0, 0)
}
override def add(in: (String, Double), acc: (String, Double, Int)) = {
(in._1, in._2 + acc._2, 1 + acc._3)
}
override def merge(acc1: (String, Double, Int), acc2: (String, Double, Int)) = {
(acc1._1, acc1._2 + acc2._2, acc1._3 + acc2._3)
}
override def getResult(acc: (String, Double, Int)) = {
(acc._1, acc._2 / acc._3)
}
}
ProcessWindowFunction
public abstract class ProcessWindowFunction<IN, OUT, KEY, W extends Window>
extends AbstractRichFunction {
// Evaluates the window
void process(KEY key, Context ctx, Iterable<IN> vals, Collector<OUT> out) throws Exception;
// Deletes 所有 custom per-window state when the window is purged. 如果要使用下面的windowState就要实现这个方法
public void clear(Context ctx) throws Exception {}
// The context holding window metadata.
public abstract class Context implements Serializable {
// Returns the metadata of the window
public abstract W window();
// Returns the current processing time.
public abstract long currentProcessingTime();
// Returns the current event-time watermark.
public abstract long currentWatermark();
// State accessor for per-window state.
public abstract KeyedStateStore windowState();
// State accessor for per-key global state.
public abstract KeyedStateStore globalState();
// Emits a record to the side output identified by the OutputTag.
public abstract <X> void output(OutputTag<X> outputTag, X value);
}
}
// 例子
// output the lowest and highest temperature reading every 5 seconds
val minMaxTempPerWindow: DataStream[MinMaxTemp] = sensorData
.keyBy(_.id)
.timeWindow(Time.seconds(5))
.process(new HighAndLowTempProcessFunction)
// ========= //
case class MinMaxTemp(id: String, min: Double, max:Double, endTs: Long)
class HighAndLowTempProcessFunction
extends ProcessWindowFunction[SensorReading, MinMaxTemp, String, TimeWindow] {
override def process(
key: String,
ctx: Context,
vals: Iterable[SensorReading],
out: Collector[MinMaxTemp]): Unit = {
val temps = vals.map(_.temperature)
val windowEnd = ctx.window.getEnd
out.collect(MinMaxTemp(key, temps.min, temps.max, windowEnd))
}
}
Incremental Aggregation and ProcessWindowFunction
当使用incremental aggregation时需要用到window元数据或者state时,可以如下使用
input
.keyBy(...)
.timeWindow(...)
.reduce(incrAggregator: ReduceFunction[IN],
function: ProcessWindowFunction[IN, OUT, K, W])
input
.keyBy(...)
.timeWindow(...)
.aggregate(incrAggregator: AggregateFunction[IN, ACC, V],
windowFunction: ProcessWindowFunction[V, OUT, K, W])
// 下面代码实现了和上面例子一样的功能,但不需要保存5秒内的所有窗口数据
val minMaxTempPerWindow2: DataStream[MinMaxTemp] = sensorData
.map(r => (r.id, r.temperature, r.temperature))
.keyBy(_._1)
.timeWindow(Time.seconds(5))
.reduce(
// incrementally compute min and max temperature
(r1: (String, Double, Double), r2: (String, Double, Double)) => {
(r1._1, r1._2.min(r2._2), r1._3.max(r2._3))
},
// finalize result in ProcessWindowFunction
new AssignWindowEndProcessFunction()
)
// ========= //
case class MinMaxTemp(id: String, min: Double, max:Double, endTs: Long)
class AssignWindowEndProcessFunction
extends ProcessWindowFunction[(String, Double, Double), MinMaxTemp, String, TimeWindow] {
override def process(
key: String,
ctx: Context,
minMaxIt: Iterable[(String, Double, Double)],
out: Collector[MinMaxTemp]): Unit = {
val minMax = minMaxIt.head
val windowEnd = ctx.window.getEnd
out.collect(MinMaxTemp(key, minMax._2, minMax._3, windowEnd))
}
}
Consecutive windowed operations
来自第一次操作的时间窗口[0,5]的结果也将在随后的窗口化操作中以时间窗口[0,5]结束。 这允许计算每个key window的和,然后在第二个操作中计算同一窗口内的前k个元素。
val input: DataStream[Int] = ...
val resultsPerKey = input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.reduce(new Summer())
val globalResults = resultsPerKey
.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)))
.process(new TopKWindowFunction())
3> (1,2,2)
3> (1,7,2)
3> (1,12,2)
4> (2,3,1)
4> (2,5,1)
Customizing Window Operators
A window operator with an incremental aggregation function(IAF):数据 => WindowAssigner => IAF => 所属window => 结果
A window operator with a full window function(FWF):数据 => WindowAssigner => 所属window => FWF => 结果
A window operator with IAF and FWF:数据 => WindowAssigner => IAF => 所属window => FWF => 结果
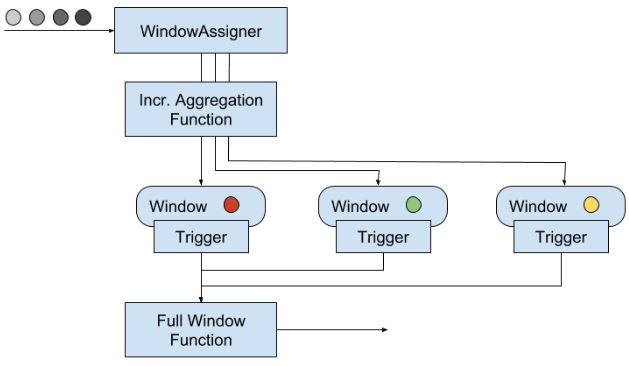
trigger 是window的组件,定义什么时候计算window和发送结果。每当数据进入window都会被传到trigger。所以可以根据被分配的elements或者登记的timer来触发对window数据的计算。
Evictor是FWF的可选组件,用了IAF就不能用。在函数的调用前、后调用,可以遍历window中的元素。通常用在GlobalWindow。更多看官网
上图的一切都可能是在一个大window里,即tumbling window之类的。
// define a keyed window operator,non-keyed去掉keyBy即可
stream
.keyBy(...) // versus non-keyed windows
.window(...) // "assigner"
[.trigger(...)] // "trigger" (覆盖 default trigger)
[.evictor(...)] // "evictor" (else no evictor)
[.allowedLateness(...)] // "lateness" (else zero)
[.sideOutputLateData(...)] // "output tag" (else no side output for late data)
.reduce/aggregate/fold/apply() // required: "function"
[.getSideOutput(...)] // optional: "output tag"
Window Lifecycle
A window is created when a WindowAssigner assigns the first element to it. window包含以下内容:
- content存IAF的结果或者FWF的待计算数据
- object(即window本身):WindowAssigner 会返回零、一个、多个objects。window operator根据这些objects来划分数据,因为这些object区分了不同的window,且记录了window何时可以被删除
- trigger的timer:用来在达到timer时点时回调计算window或者清空window content。timer由window operator维护
- 自定义trigger的state:完全由trigger控制,与window operator无关。当window被删除时,trigger记得要调用.clear()来清除这部分state。
window operator在window的end time(event还是process time取决于WindowAssigner.isEventTime)时删除window,自动删除window content和所有登记在该window的timer。
Window Assigners
// a custom assigner for 30 seconds tumbling event-time window
class ThirtySecondsWindows
extends WindowAssigner[Object, TimeWindow] {
val windowSize: Long = 30 * 1000L
override def assignWindows(
o: Object,
ts: Long,
ctx: WindowAssigner.WindowAssignerContext): java.util.List[TimeWindow] = {
// rounding down by 30 seconds
val startTime = ts - (ts % windowSize)
val endTime = startTime + windowSize
// emitting the corresponding time window 每30秒一个新window
Collections.singletonList(new TimeWindow(startTime, endTime))
}
override def getDefaultTrigger(
env: environment.StreamExecutionEnvironment): Trigger[Object, TimeWindow] = {
EventTimeTrigger.create()
}
override def getWindowSerializer(
executionConfig: ExecutionConfig): TypeSerializer[TimeWindow] = {
new TimeWindow.Serializer
}
override def isEventTime = true
}
还有MergingWindowAssigner ,之前提到的sessionwindow就用到这个接口,下面有更详细的说明。
When merging windows, you need to ensure that the state of all merging windows and their triggers is also approriately merged. The Trigger interface features a callback method that is invoked when windows are merged to merge state that is associated to the windows.
Global Windows:将所有elements都放到同一个全局window,且NeverTrigger。这种window需要自定义trigger或者加上evictor来选择除去window state中的什么element。另外,如果运用到keyedStream,还要注意window会为每个key留下state。
Trigger
Triggers define when a window is evaluated and its results are emitted. A trigger can decide to fire based on progress in time or data-specific conditions. Triggers have access to time properties, timers, and can work with state. 所以它可以根据一些条件,如某个数据的某个特定值、两个数据同时出现在5秒钟内、先提前显示结果等。每当trigger被调用,都会产生一个TriggerResult,它的选项有:CONTINUE, FIRE, PURGE, FIRE_AND_PURGE。PURGE指清理window的内容,而不是整个window。
删除window前要清楚所有的state,之后就不行了。在MergingWindowAssigner 中,要实现canMerge()和onMerge()
/** A trigger that fires early. The trigger fires at most every second. */
class OneSecondIntervalTrigger
extends Trigger[SensorReading, TimeWindow] {
override def onElement(
r: SensorReading,
timestamp: Long,
window: TimeWindow,
ctx: Trigger.TriggerContext): TriggerResult = {
// firstSeen will be false if not set yet. 这个PartitionedState是对应key和window的state
val firstSeen: ValueState[Boolean] = ctx.getPartitionedState(
new ValueStateDescriptor[Boolean]("firstSeen", createTypeInformation[Boolean]))
// register initial timer only for first element
if (!firstSeen.value()) {
// compute time for next early firing by rounding watermark to second
val t = ctx.getCurrentWatermark + (1000 - (ctx.getCurrentWatermark % 1000))
ctx.registerEventTimeTimer(t)
// register timer for the window end
ctx.registerEventTimeTimer(window.getEnd)
firstSeen.update(true)
}
// Continue. Do not evaluate per element
TriggerResult.CONTINUE
}
override def onEventTime(
timestamp: Long,
window: TimeWindow,
ctx: Trigger.TriggerContext): TriggerResult = {
if (timestamp == window.getEnd) {
// 由于覆盖了默认,所以这里要手动清空
TriggerResult.FIRE_AND_PURGE
} else {
// register next early firing timer
val t = ctx.getCurrentWatermark + (1000 - (ctx.getCurrentWatermark % 1000))
if (t < window.getEnd) {
ctx.registerEventTimeTimer(t)
}
// fire trigger to evaluate window
TriggerResult.FIRE
}
}
override def onProcessingTime(
timestamp: Long,
window: TimeWindow,
ctx: Trigger.TriggerContext): TriggerResult = {
// Continue. We don't use processing time timers
TriggerResult.CONTINUE
}
override def clear(
window: TimeWindow,
ctx: Trigger.TriggerContext): Unit = {
// clear trigger state. This method is called when a window is purged
val firstSeen: ValueState[Boolean] = ctx.getPartitionedState(
new ValueStateDescriptor[Boolean]("firstSeen", createTypeInformation[Boolean]))
firstSeen.clear()
}
}
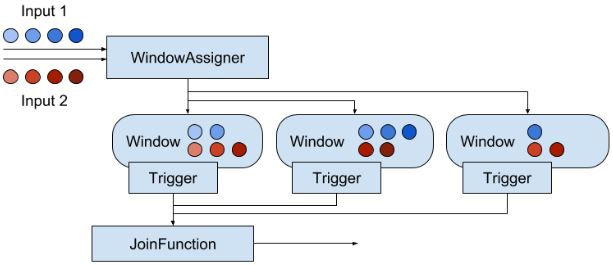
Joining Streams on Time(v1.5)
input1.join(input2)
.where(...) // specify key attributes for input1
.equalTo(...) // specify key attributes for input2
.window(...) // specify the WindowAssigner
[.trigger(...)] // optional: specify a Trigger
[.evictor(...)] // optional: specify an Evictor
.apply(...) // specify the JoinFunction
当Trigger.FIRE,JoinFunction就会被调用。JF会对每一对events进行join,而CoGroupFunction会针对整个window,用迭代器来完成join。
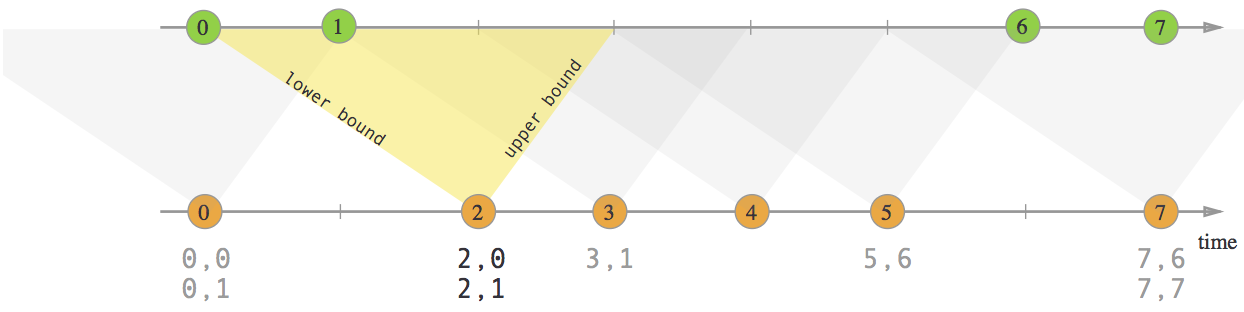
those elements that do get joined will have as their timestamp the largest timestamp that still lies in the respective window. For example a window with [5, 10) as its boundaries would result in the joined elements having 9 as their timestamp.
Sliding Join
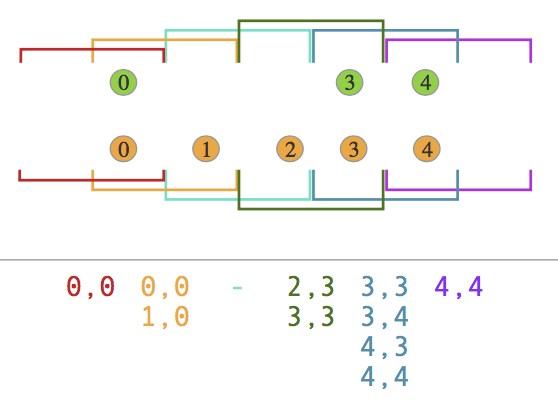
Interval Join
join之后的时间戳为两个element中最大的那个
在tumbling中用join,由于window是一刀切的,即使定义了join条件为相隔1s,有时两个events还是会被分到不同window而不能实现join。但可以尝试用CoProcessFunction来实现自定义join逻辑。
Handling Late Data
三种处理方式:drop(event-time window operator的默认实现,如果是非window operator,就用process function来判断是否超时,然后作出相应的处理)、发送到其他流、更新原结果
// redirect:在process前插入一个.sideOutputLateData(OutputTag),然后就可以对结果流调用.getSideOutput(OutputTag)
// define an output tag for late sensor readings
val lateReadingsOutput: OutputTag[SensorReading] =
new OutputTag[SensorReading]("late-readings")
val readings: DataStream[SensorReading] = ???
val countPer10Secs: DataStream[(String, Long, Int)] = readings
.keyBy(_.id)
.timeWindow(Time.seconds(10))
// emit late readings to a side output
.sideOutputLateData(lateReadingsOutput)
// count readings per window
.process(new CountFunction())
// retrieve the late events from the side output as a stream
val lateStream: DataStream[SensorReading] = countPer10Secs
.getSideOutput(lateReadingsOutput)
// 也可以直接在Process Function中处理
class LateReadingsFilter
extends ProcessFunction[SensorReading, SensorReading] {
override def processElement(
r: SensorReading,
ctx: ProcessFunction[SensorReading, SensorReading]#Context,
out: Collector[SensorReading]): Unit = {
// compare record timestamp with current watermark
if (r.timestamp < ctx.timerService().currentWatermark()) {
// this is a late reading => redirect it to the side output
ctx.output(lateReadingsOutput, r)
} else {
out.collect(r)
}
}
}
Updating Results by Including Late Events
allowedLateness,并在接下来的ProcessWindowFunction中判断是否为第一个答案(用window的state来存储flag)
下面同样可以通过Process Function实现
val readings: DataStream[SensorReading] = ???
val countPer10Secs: DataStream[(String, Long, Int, String)] = readings
.keyBy(_.id)
.timeWindow(Time.seconds(10))
// process late readings for 5 additional seconds 这样window不会被删除,其state会被保留。与延长watermark相比,这个会发送多个结果,因window到时间时已近fire了,但late数据的到来又会触发fire。
.allowedLateness(Time.seconds(5))
// count readings and update results if late readings arrive
.process(new UpdatingWindowCountFunction)
// =================== //
/** A counting WindowProcessFunction that distinguishes between
* first results and updates. */
class UpdatingWindowCountFunction
extends ProcessWindowFunction[SensorReading, (String, Long, Int, String), String, TimeWindow] {
override def process(
id: String,
ctx: Context,
elements: Iterable[SensorReading],
out: Collector[(String, Long, Int, String)]): Unit = {
// count the number of readings
val cnt = elements.count(_ => true)
// state to check if this is the first evaluation of the window or not.
val isUpdate = ctx.windowState.getState(
new ValueStateDescriptor[Boolean]("isUpdate", Types.of[Boolean]))
if (!isUpdate.value()) {
// first evaluation, emit first result
out.collect((id, ctx.window.getEnd, cnt, "first"))
isUpdate.update(true)
} else {
// not the first evaluation, emit an update
out.collect((id, ctx.window.getEnd, cnt, "update"))
}
}
}
notice
Flink creates one copy of each element per window to which it belongs. 所以a sliding window of size 1 day and slide 1 second might not be a good idea.
参考
Stream Processing with Apache Flink by Vasiliki Kalavri; Fabian Hueske

 浙公网安备 33010602011771号
浙公网安备 33010602011771号