Spark底层原理简化版
Spark SQL/DF的执行过程
将上层的SQL语句映射为底层的RDD模型。

- 写代码(DF/Dataset/SQL)并提交
- Parser解析后得到unresolved logical plan(代码合法但未判断data是否存在、数据类型)
- Analyzer分析对比Catalog(里面绑定了数据信息)后得到 analyzed logical plan(有数据类型的计划)。
- Optimizer根据预定的逻辑优化得到optimized logical plan。这些逻辑为Rule,例如PushdownPredicate(即提前filter,需要storage支持,如mysql)、ConstantFolding(将常量合并,如1+1直接变为2)、ColumnPruning(减少读取的列,根据select判断,同样需要storage支持,如Parquet、ORC)等
- Query Planner从optimized locical plan中得出不同的物理执行策略
Iterator[PhysicalPlan] - CBO利用Cost Model得出最优physical plan(截止2.2还没实现),它包含一系列RDDs和transformation,即UI显示的DAG。
- 提交前准备,如确保分区操作正确、物理算子树节点重用、Code Generation等,得到Prepared SparkPlan
- 得到QueryExecution
- 在集群执行(执行过程通过生成本地Java字节码去除整个tasks或者stages来进一步优化)。Adaptive Execution还会根据信息动态调整执行计划。
上述除了第一步和最后一步,其他都在driver中完成。
Catalog主要用于各种函数资源信息和元数据信息的统一管理,包括全局的临时视图管理、函数资源加载器、函数注册接口、外部系统Catalog(数据库)、配置。
集群运行部分
- Driver进程执行代码,当发现action时,会调用sc.runJob() -> dagScheduler.runJob()。
- DAGScheduler通过submitJob将job提交到任务队列eventProcessLoop中。然后DAGScheduler通过doOnReceive对任务队列中的信息进行模式匹配,如果匹配到JobSubmitted,就通过handleJobSubmitted,从job中创建ResultStage,然后调用submitStage。这个函数会通过getMissingParentStages,从ResultStage的rdd开始沿着rdd的依赖遍历,遇到ShuffleDependency,则创建ShuffleMapStage。然后对这些MissingParentStages调用submitMissingTasks。里面会根据Stage的类型创建相应的Task并放进一个taskSet中。然后调用taskScheduler.submitTasks(taskSet)
- taskScheduler的这个函数根据taskSet新建TaskSetManager(包含taskset),并将manager放入schedulableQueue。然后调用CoarseGrainedSchedulerBackend的reviveOffers,发送ReviveOffers给自己。
- 当CoarseGrainedSchedulerBackend接收到这个信息后就会调用makeOffers,筛选出activeExecutors,然后调用TaskScheduler的resourceOffers获取TaskDescription,记录task要被发送给哪个executor、jar包地址等信息。接着把TaskDescription作为参数调用launchTasks。这个函数会根据将序列化后的task创建LaunchTask,并send到相应的executor。这样,任务就被发送到集群。各个方法后续都有获取结果的代码返回给runJob。在任务执行期间,Driver继续执行代码,遇到action就重复上述步骤。
一个job结束后会进行checkpoint。
- ExecutorBackend调用receive,如果匹配到LaunchTask,就会调用executor的launchtask,该函数根据任务创建taskrunner,并放入线程池中执行。
Aggregation
AggregateFunction抽象类,它有两个子抽象类:ImperativeAggregate命令式和DeclarativeAggregate声明式。AggregateExpression是AggregateFunction的封装。
聚合缓冲区(AggregateBuffer)与聚合模式(AggregateMode)
AggregateBuffer每个key一个,保存中间结果。一个共享区,能多个聚合函数访问。
聚合模式有4种:
- Final模式和Partial模式一般都是组合使用。Partial模式可以看作是局部数据的聚合,返回的是聚合缓冲区中的中间数据。而Final模式所起到的作用是将聚合缓冲区的数据进行合并,然后返回最终的结果。
- Complete模式不进行局部聚合计算
- PartialMerge:对聚合缓冲区进行合并,但还不是最终结果,主要用于distinct语句中,相当耗时。
执行
RDD的每个partition作为InputIterator,经过AggregateExec得到相应的AggregationIterator。
HashAggregateExec、SortAggregateExec和ObjectHashAggregateExec分别创建TungstenAggregationIterator、SortBasedAggregationIterator和ObjectAggregationIterator。
通常用HashAggregate,但在一些情况下会变为SortAggregate:
- 查询中存在不支持Partial方式的聚合函数
- 聚合函数结果不支持Bufer方式,例如collect_set和collect_list函数
- 内存不足imperative
SortAggregateExec:如果有partial agg,在map端,SortAggregateExec在进行聚合之前会在分区内排序(从而达到分组的目的),然后再聚合。在reduce端一样。
HashAggregateExec:构建一个Map,将数据保存到map中并进行聚合计算。
Window的执行
WindowExec规定了数据的分布和有序性,所以在执行前要用exchange和sort完成重分区和分区内数据的排序。而WindowExec根据窗口的定义又不同的执行方式。
window的这一操作就少了partial agg,shuffle的数据量大。
Join
Join策略:广播、ShuffledHashJoinExec、SortMergeJoinExec(最常见)、其他不包含join条件的语句。
-
广播:当一个大表和一个小表进行Join操作时,为了避免数据的Shuffle,可以将小表的全部数据分发到每个节点上。
在Outer类型的Join中,基表不能被广播,例如当A left outer join B时,只能广播右表B。
-
ShuffledHashJoinExec:先对两个表进行hash shuffle,然后把小表变成map完全存储到内存,最后进行join。
开启条件:spark.sql.join.preferSortMergeJoin为false;小表的大小 小于 广播阈值 * 默认分区数;小表3倍小于另一个表。不适合两个表都很大的情况,因为其中一个表的hash部分要全部放到内存。
-
SortMergeJoinExec:先hash shuffle将两表数据数据相同key的分到同一个分区,然后sort,最后join。由于排序的特性,每次处理完一条记录后只需要从上一次结束的位置开始继续查找。适合大表join大表。
Shuffle
shuffle是根据partitioner(key或ranger)将不同节点上的数据移动到其对应的(同hash划分或range范围)节点上,便于同类数据的聚合或join等计算。这个过程中,map side组织数据,如果shuffle的数据过大,会把数据溢出到磁盘,reduce side拉取数据。ByKey类shuffle的性能消耗更大,它们会在两端为每类key创建聚合对象(同样内存不够进磁盘,等GC删除)。
以上为官网内容,下面为底层实现部分。
从2.0开始,Spark就只有Tungsten Sort Shuffle。在实现层面,Spark在启动时会创建ShuffleManager来管理Shuffle,默认情况下SortShuffleManger(tungstensort对应)是ShuffleManager的具体实现。ShuffleMapTask从SortShuffleManger中获得ShuffleWriter。下游的task获取ShuffleReader。
ShuffleWriter的具体实现:
当ShuffleDependency注册一个Shuffle时就会得到一个ShuffleHandle对象,根据它获取相应的writer。
- BypassMergeSortShuffleHandle(可以获得BypassMergeSortShuffleWriter),即可以忽略掉聚合排序的Shuffle过程(从Shuffle数据读取任务看来,数据文件和索引文件的格式和内部是否做过聚合排序是完全相同的。),直接将每个分区写入单独的文件,并在最后做一个合并处理,并创建一个index索引文件来标记不同分区的位置信息。适合数据量少的情况。
- SerializedShuffleHandle(可以获得UnsafeShuffleWriter),对应Tungsten方式的Shuffle过程,这种情况下ShuffleMapTask的输出数据能够先序列化为二进制数据存储在内存中,再执行相关的操作,在内存使用上是一种更高效的方式。
- BaseShuffleHandle(可以获得SortShuffleWriter),在不满足上面两种handle条件时获得BaseShuffleHandle对象,意味着以反序列化的格式处理Shuffle输出数据。过程是创建ExternalSorter对象,将全部数据插入该对象,生成Shuffle数据文件和索引文件,最后创建MapStatus对象,将数据和索引进行传输。关键实现在于外部排序器,根据是否需要聚合采用不同的map数据结构,当数据量过大,便会溢出到磁盘。
ShuffleReader的具体实现
BlockStoreShuffleReader方面,根据上述map信息对ShuffleBlockFetcherIterator进行不同的封装,得到相应的iterator。
writer和reader都会根据是否有aggregator、ordering进行相应的处理。writer还有partitioner参数。这些对于shuffle都是optional。
Tungsten
内存管理机制
Executor中对象的处理实际由JVM执行,Spark的统计数据无法准确计算数据量的大小,所以无法避免OOM。
Tungsten的内存管理(需要设置ofHeap.enabled和ofHeap.size)让Spark直接操作二进制数据而不是JVM对象,从而提升内存使用率。
内存管理器
内存管理由MemoryManager通过MemoryPool管理。MP根据heap和ofheap分为两大类。每类再分为execration和storage。
MemoryManager的具体实现有1.6之前的StaticMemoryManager和之后的UnifiedMemoryManager。任务通过这些manager来完成内存申请或释放操作。下图为统一内存管理器的所管理的内存结构。其中Reserved用于Spark系统内部,应用内存为用户程序中的数据结构。
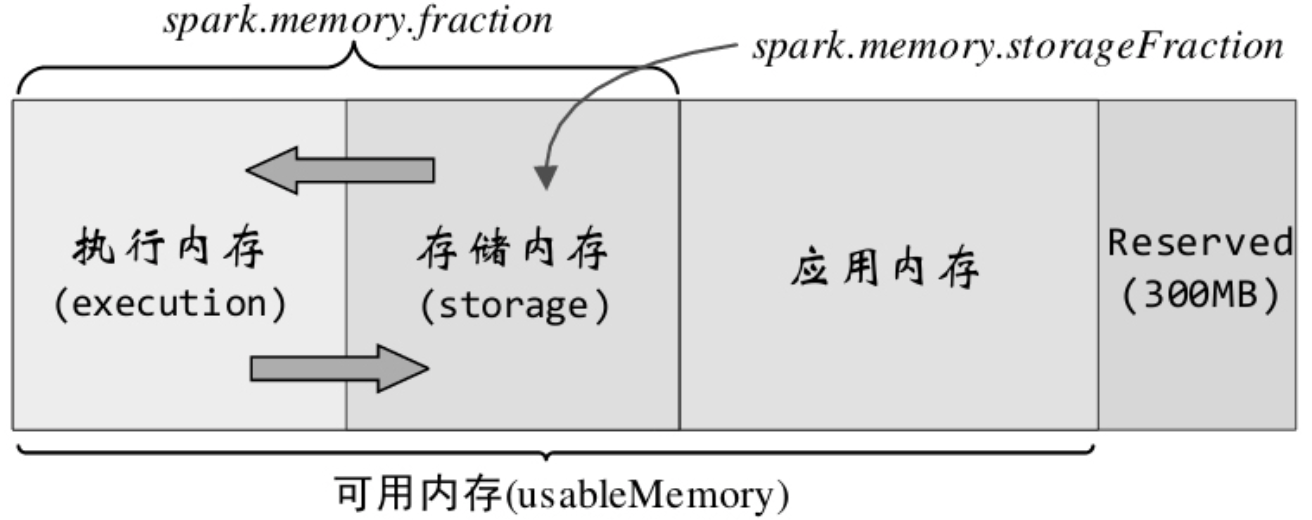
执行内存和存储内存之间能互相借用(当空间不足,即放不下一个完整的block,且对方有空余时。),归还时可让对方多占用的部分转到磁盘,但有些复杂的因素会导致无法归还。
存储内存
如上面所说,存储内存管理器为StorageMemoryPool,它的使用者是存储模块,具体实现是BlockManager。它负责管理计算过程中产生的各种数据,可以看作是一个独立的分布式存储管理系统。Driver端的为主BlockManagerMaster,负责对全部数据块的元数据信息进行管理和维护,Executor端将数据块的状态上报到driver端,并接收住节点的相关操作命令。
在rdd被缓存到存储内存之前,它是属于应用内存部分的,而且是不连续的,上层通过迭代器访问。持久化后才到存储内存,且连续。而根据持久化的级别,是否序列化,会采用不同的数据结构。如果有新的block需要缓存而没有足够的存储内存,BlockManager会分局LRU淘汰Block,这个淘汰要么删除,要么溢出到磁盘,看被淘汰的block是否设置了usedisk的持久化。
执行内存
主要用于满足shuffle、join、sort、agg等计算过程对内存的需求。
内存管理最底层实现
内存分配管理的基础是MemoryAllocator,manager通过它来申请和释放内存。其实现包括HeapMemoryAllocator和UnsafeMemoryAllocator。
Tungsten使用另外的一些数据结构和方法来实现其计算。例如重新实现的ByteArray、LongArray、UTF8String、BytesToMap等。
缓存敏感计算(Cacheaware computation)
通过设计缓存友好的数据结构来提高缓存命中率和本地化的特性。
动态代码生成(Code generation)
代码生成能够去掉原始数据类型的封装和多态函数调度。
参考
Spark 2.2.2 源码
Spark SQL 内核剖析

 浙公网安备 33010602011771号
浙公网安备 33010602011771号