selenium webdrive使用
一、selenium浏览器驱动的下载与调用
1、安装三大浏览器驱动driver
①chrome的驱动chromedriver 下载地址:
https://code.google.com/p/chromedriver/downloads/list
http://chromedriver.storage.googleapis.com/index.html
https://npm.taobao.org/mirrors/chromedriver/
②IE的驱动IEdriver 下载地址:
http://www.nuget.org/packages/Selenium.WebDriver.IEDriver/
http://selenium-release.storage.googleapis.com/index.html
③Firefox的驱动geckodriver
selenium 3.0版本调用firefox的时候要用geckodriver.exe,selenium2无需驱动包。下载地址:
https://github.com/mozilla/geckodriver/releases/
④其他浏览器驱动 :
selenium还支持 Android(AndroidDriver)和 iPhone(IPhoneDriver) 的移动应用测试。
https://www.npmjs.com/package/selenium-webdriver
2、selenium 驱动ie 和 chrome 、Firefox的三种种方式:
selenium驱动ie,chrome 的时候需要下载驱动 IEDriverServer、Chromedriver、geckodriver
①把 ie驱动、chrome驱动放在相应文件夹,在程序中添加路径即可:
Chrome:
System.setProperty(“webdriver.chrome.driver”,”D:\Chromedriver.exe”);
WebDriver driver = new ChromeDriver();
IE:
System.setProperty(“webdriver.ie.bin”,“D:\IEDriverServer.exe”);
WebDriver driver = new InternetExplorerDriver();
②直接把 ie驱动、chrome驱动放在Python根目录或其他目录下(只要该目录添加到了系统环境变最path下面即可),然后直接驱动
③将驱动放在各自浏览器的安装目录下,并设置用户环境变量
将chromedriver.exe 放在chrome浏览器安装目录下(同时设置用户环境变量path:C:\Users\xxxxxx\AppData\Local\Google\Chrome\Application;)
将IEDriverServer.exe 放在ie浏览器安装目录下(同时设置用户环境变量path:C:\Program Files\Internet Explorer )
调用ie浏览器时,要注意安全设置问题(internet选项–》安全 去掉“启用保护模式”的勾选)
二、selenium 调用浏览器
①web自动化练习网站:
http://sahitest.com/demo/index.htm
②调用chrome浏览器
from selenium import webdriver driver=webdriver.Chrome() #调用chrome浏览器 driver.get('https://www.baidu.com') print (driver.title) driver.quit()
③调用IE浏览器
from selenium import webdriver driver=webdriver.Ie() #调用IE浏览器 driver.get('https://www.baidu.com') print (driver.title) driver.quit()
③调用firefox浏览器
from selenium import webdriver import time driver=webdriver.Firefox() #调用chrome浏览器 driver.get('https://www.baidu.com') driver.find_element_by_id("kw").send_keys("Selenium2") driver.find_element_by_id("su").click() time.sleep(3) # 强制等待3秒再执行下一步, 强制等待,不管你浏览器是否加载完了 driver.quit()
三、Selenium的基本使用
selenium下包含2个包,common和webdriver。
common下仅有一个exceptions。selenium.common.exceptions所有selenium中可能发生的异常。
其他操作及功能都在webdriver下。webdriver里除了common 和support ,其余的都是对应浏览器的方法/属性等。
1、浏览器对象
Selenium支持很多浏览器包括chrome、Firefox、Edge、Safari等,各浏览器初始化对象方法:
from selenium import webdriver #browser=webdriver.Firefox() browser=webdriver.Chrome() #browser=webdriver.Edge() #browser=webdriver.Safari() print(type(browser)) #返回的是一个WebDriver对象 <class 'selenium.webdriver.chrome.webdriver.WebDriver'>
WebDriver对象的方法和属性:(browser=webdriver.Chrome()即browser的方法和属性)
-
back(): 在浏览器历史记录中后退一步
-
forward(): 在浏览器历史上前进一步
-
close(): 关闭当前窗口
-
quit():退出驱动程序并关闭每个关联的窗口
-
refresh():刷新当前页面
-
name:返回此实例的基础浏览器的名称
-
title:返回当前页面的标题
-
current_url:获取当前页面的URL
-
add_cookie(cookie_dict):为当前会话添加一个cookie,为字典类型
-
delete_all_cookies():删除会话范围内的所有cookie delete_cookie(name): 删除具有给定名称的单个cookie
-
get_cookie(name):按名称获取单个cookie get_cookies():返回一组字典的cookies
-
execute(driver_command,params=None): 发送command执行的命令
-
execute_async_script(script,*args):异步执行当前窗口或框架中的JavaScript,它不会阻塞主线程执行
-
execute_script(script,*args):同步执行当前窗口或框架中的JavaScript,用它执行js代码会阻塞主线程执行,直到js代码执行完毕
-
get(url):在当前浏览器会话中加载网页,一定要输入全部链接,包括“http://”,否则可能找不到
-
get_log(log_type):获取给定日志类型的日志
-
get_screenshot_as_base64():获取当前窗口的屏幕截图,作为base64编码的字符串
-
get_screenshot_as_file(filename):将当前窗口中的截屏保存为png图形
-
save_screenshot(filename):将当前窗口的屏幕截图保存为PNG图形文件
-
get_screenshot_as_png():获取当前窗口的屏幕截图作为二进制数据
-
get_window_position(windowhandle=‘current’):获取当前窗口的x,y位置
-
get_window_rect():获取窗口的x,y坐标以及当前窗口的高度和宽度
-
get_window_size():获取当前窗口的高度和宽度
-
maximize_window():最大化webdriver正在使用的当前窗口
-
minimize_window():最小化当前webdricer使用窗口
-
fullscreen_window():调用窗口管理器特定的全屏操作
-
set_window_rect(x=None,y=None,width=None,height=None):设置窗口的x,y坐标以及当前窗口的高度和宽度
-
set_window_size(width,height,windowHandle=‘current’):设置当前窗口的高度和宽度
-
set_window_position(x,y,windowHandle=‘current’):设置当前窗口的x,y位置
-
current_window_handle:返回当前窗口的句柄
-
window_handles:返回当前会话中所有窗口的句柄
-
create_web_element(element_id): 使用指定的id创建Web元素
-
set_page_load_timeout(time_to_wait):设置等待页面加载完成的时间
-
set_script_timeout(time_to_wait):设置脚本在执行期间等待的时间
-
desired_capabilities:返回驱动程序当前使用的所需功能
-
log_types:获取可用日志类型的列表
-
page_source:获取当前页面的源码
-
switch_to 将焦点切换到所有选项的对象上
-
switch_to.alert 返回浏览器的Alert对象,可对浏览器alert、confirm、prompt框操作
-
switch_to.default_content() 切到主文档
-
switch_to.frame(frame_reference) 切到某个frame
-
switch_to.parent_frame() 切到父frame,有多层frame的时候很有用
-
switch_to.window(window_name) 切到某个浏览器窗口
-
switch_to.active_element 返回当前焦点的WebElement对象,网页上当前操作的对象(也就是你网页上光标的位置),比如你鼠标点击到了一个input框,你可以在这个input框里输入信息,这时这个input框即焦点。
实现JavaScript:
from selenium import webdriver driver=webdriver.Chrome() driver.get('https://www.baidu.com') driver.execute_script("alert('are you sure');") #它基本可以实现JavaScript的所有功能
from selenium import webdriver browser=webdriver.Chrome() browser.get('http://selenium-python.readthedocs.io') browser.execute_script('window.open("https://www.baidu.com");') #在标签页打开URL browser.execute_script('window.open("https://www.taobao.com");') browser.back() #后退到前一个页面 browser.set_page_load_timeout(5) browser.forward() #前进到下一个页面 print(browser.name) print(browser.title) print(browser.current_url) print(browser.current_window_handle) print(browser.get_cookies()) print(type(browser))
获取页面截图:
from selenium import webdriver driver=webdriver.Chrome() driver.get('http://www.python.org') driver.save_screenshot('screenshot.png') #保持页面截图到当前路径 driver.quit()
将页面滚动到底部:
from selenium import webdriver driver=webdriver.Chrome() driver.get('http://www.python.org') #通过js中的window对象的scrollTo方法,将窗口位置滚动到指定位置,document.body.scrollHeight返回整个body的高度,所以页面将滚动到页面底部 driver.execute_script("window.scrollTo(0,document.body.scrollHeight);")
cookies操作:
#!/usr/bin/ python3 # -*- coding: utf-8 -*- from selenium import webdriver driver=webdriver.Chrome() driver.get('https://www.baidu.com') print(driver.get_cookies()) #获取所有cookies driver.add_cookie({'name':'name','domain':'www.baidu.com','value':'germey'}) #添加cookie print(driver.get_cookies()) driver.delete_all_cookies() print(driver.get_cookies())
2、定位元素
webdriver 提供了八种元素定位方法:
- id
- name
- class name
- tag name
- link text
- partial link text
- xpath
- css selector
- find_element_by_id(id属性,可以唯一定位)
- find_element_by_name (name属性,可以唯一定位)
- find_element_by_xpath (最灵活,万能)
- find_element_by_link_text (定位文字连接好用)
- find_element_by_partial_link_text (定位文字连接好用)
- find_element_by_tag_name (每个元素都会有tag标签,最不靠谱)
- find_element_by_class_name (class属性定位元素)
- find_element_by_css_selector (css选择器定位)
有时候需要操作的元素是一个文字链接,那么我们可以通过link text 或partial link text 进行元素定位。也就是a标签
比如,定位百度首页右上角的“新闻”,“hao123”,。。。。等等这些文字连接。就可以使用link text和partail link text定位方式
通过linx text定位:
find_element_by_link_text("新闻") find_element_by_link_text("贴吧")
通过partail link text定位:
find_element_by_link_text("新") find_element_by_link_text("贴")
要查找多个元素(这些方法将返回一个列表):
- find_elements_by_name
- find_elements_by_xpath
- find_elements_by_link_text
- find_elements_by_partial_link_text
- find_elements_by_tag_name
- find_elements_by_class_name
- find_elements_by_css_selector
from selenium import webdriver from selenium.webdriver.common.by import By driver=webdriver.Chrome() driver.get('http://selenium-python.readthedocs.io/locating-elements.html#locating-elements') data=driver.find_elements(By.CLASS_NAME,'simple') #获取多个 data=driver.find_element(By.CLASS_NAME,'simple') #获取一个 driver.find_element(By.ID,'IDname') #获取ID标签定位元素 driver.find_element(By.CSS_SELECTOR,'cssname')#CSS选择器定位元素 driver.find_element(By.LINK_TEXT,'linktext') #链接文本定位元素 driver.find_element(By.PARTIAL_LINK_TEXT,'linktext') #部分链接文件定位元素 driver.find_element(By.NAME,'name') #属性名定位元素 driver.find_element(By.TAG_NAME,'tagname') #标签名定位元素 print(data.text) #打印元素文本内容
通过Id定位:
当您知道元素的id属性时使用此选项。使用此策略,将返回id属性值与该位置匹配的第一个元素,如使用find_elements_by_id将返回多个匹配的元素。如果没有元素具有匹配的id 属性,NoSuchElementException则会触发
driver.find_element_by_id('kw1') driver.find_elements_by_id('kw1')
按名称定位:
当您知道元素的name属性时,请使用此选项。使用此策略,将返回名称属性值与位置匹配的第一个元素,如使用find_elements_by_name将返回多个匹配的元素。如果没有元素具有匹配的name 属性,NoSuchElementException则将触发
driver.find_element_by_name('wd') driver.find_elements_by_name('wd')
按标签名称定位元素:
如果要按标签名称查找元素,请使用此选项。使用此策略,将返回具有给定标记名称的第一个元素。如果没有元素具有匹配的标记名称则将引发NoSuchElementException异常。tag name 获取的是标签的名字,在一个页面上往往会有很多标签名相同的元素,这并不是说 tag name 方法就毫无用武之处,在定位一组元素的时候我们往往需要 tag name 方法来帮忙。
driver.find_element_by_tag_name('input')
按类名定位元素:
如果要按类属性名称定位元素,请使用此选项。使用此策略,将返回具有匹配类属性名称的第一个元素。如果没有元素具有匹配的类属性名称,NoSuchElementException则将引发
driver.find_element_by_class_name('s_ipt')
通过链接文本查找超链接:
当操作的元素是一个文字链接, 那么我们可以通过link text 或 partial link text 进行元素定位。将返回链接文本值与位置匹配的第一个元素。如果没有元素具有匹配的链接文本属性,NoSuchElementException则将引发。当一个文字连接很长时,我们可以只取其中的一部分,只要取的部分可以唯一标识元素。一般一个页面上不会出现相同的文件链接,通过文字链接来定位元素也是一种简单有效的定位方式。
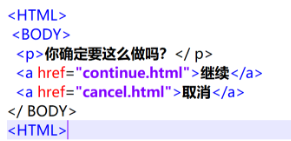
driver.find_element_by_link_text('继续) #通过链接文本定位到元素 driver.find_element_by_partial_link_text('继续) #通过链接文本定位到元素
通过XPath定位:
XPath是用于在XML文档中定位节点的语言。由于HTML可以是XML的实现,因此可以利用XPath来定位其Web应用程序中的元素。XPath扩展了通过id或name属性定位的方法,并打开了各种新的可能性,例如在页面上查找第三个复选框。使用XPath的主要原因之一是当您没有适合您要查找的元素的id或name属性时。您可以使用XPath以绝对术语或相对于具有id或name属性的元素来定位元素。XPath定位器也可以用来通过id和name之外的属性指定元素。

绝对路径定位(定位最后一个元素): find_element_by_xpath("/html/body/div[2]/form/span/input") 相对路径定位(定位最后一个元素): #通过自身的 id 属性定位 find_element_by_xpath("//input[@id=’input’]") #通过上一级目录的 id 属性定位 find_element_by_xpath("//span[@id=’input-container’]/input") #通过上三级目录的 id 属性定位 find_element_by_xpath("//div[@id=’hd’]/form/span/input") #通过上三级目录的 name属性定位 find_element_by_xpath("//div[@name=’q’]/form/span/input")
当我们所要定位的元素很难找到合适的方式时,可以通这种绝对路径的方式位,缺点是当元素在很多级目录下时,我们不得不要写很长的路径,而且这种方式难以阅读和维护。 XPath 的定位方式非常灵活和强大的,而且 XPath 可以做布尔逻辑运算,例如://div[@id=’hd’ or @name=’q’]。
driver.find_element_by_xpath("//from[1]") #查看第一个表单元素 driver.find_element_by_xpath("//from[@id='loginform']") #查找id为loinform的表单元素
xpath定位的缺点:
1、性能差,定位元素的性能要比其它大多数方式差;
2、不够健壮,XPath 会随着页面元素布局的改变而改变;
3、兼容性不好,在不同的浏览器下对 XPath 的实现是不一样的。
通过CSS选择器定位元素:
CSS被用来描述 HTML 和 XML 文档的表现。CSS 使用选择器来为页面元素绑定属性。这些选择器可以被 selenium 用作定位。将返回具有匹配的CSS选择器的第一个元素。CSS 可以比较灵活选择控件的任意属性,一般情况下定位速度要比 XPath 快,但对于初学者来说比较难以学习使用。如果没有元素具有匹配的CSS选择器,NoSuchElementException则会引发
driver.find_element_by_css_selector('p.content')
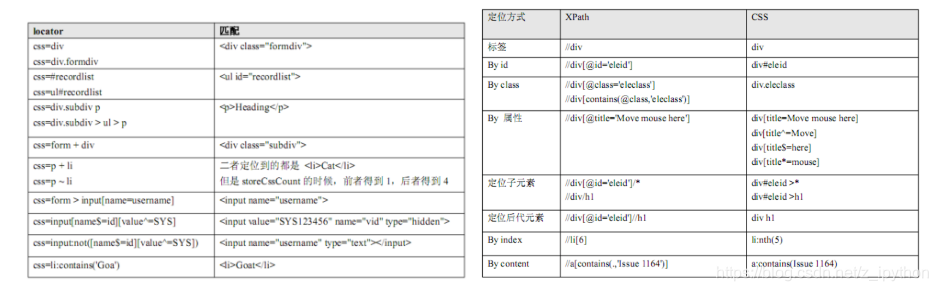
XPath、CSS定位速查表:
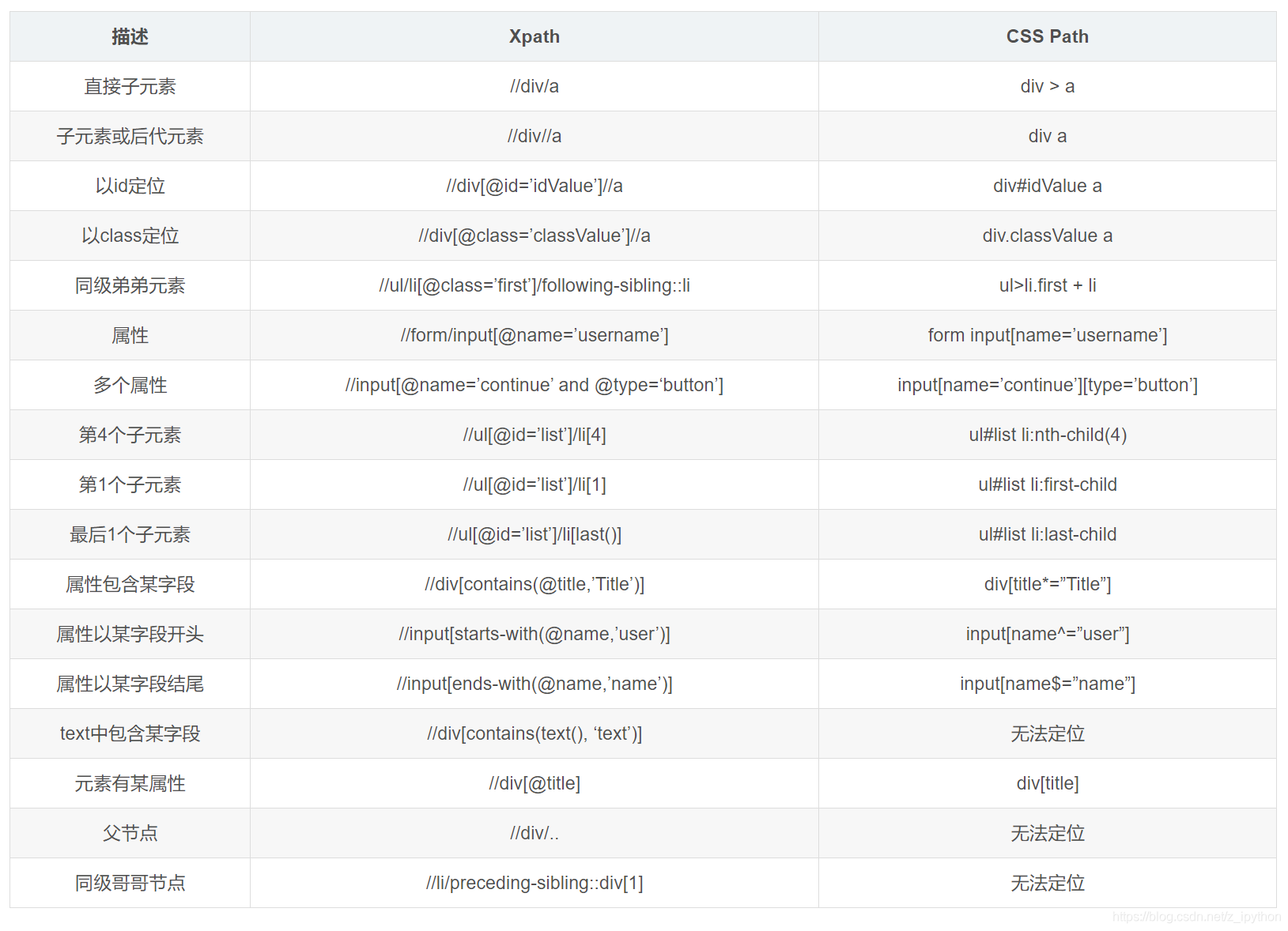
CSS定位语法比 XPath 更为简洁,定位方式更多灵活多样;不过对 CSS 理解起来要比 XPath较难;但不管是从性能还是定位更复杂的元素上,CSS 优于XPath,所以更推荐使用 CSS定位页面元素。
3、元素对象(element)
当我们通过上面 的方法定位到元素后返回的对象称为web元素对象,我们可以对元素对象再进行交互或继续查找等操作
from selenium import webdriver from selenium.webdriver.chrome.options import Options # 实例化浏览器选项 opt=Options() # 添加参数,浏览器不弹出 opt.add_argument('headless') # 选项应用到浏览器驱动对象上 driver=webdriver.Chrome(chrome_options=opt) driver.get('http://selenium-python.readthedocs.io/api.html') element=driver.find_element_by_id('remote-webdriver-webelement') print(element) print(type(element))
element的方法和属性包括:
- clear() :清除文本元素
- click() :单击元素按钮
- get_attribute(name) :获取元素的给定属性的属性值
- get_property(name) :获取元素的给定属性
- is_displayed() :判断元素是否存在
- is_enable() :判断元素是否被启用
- is_selected() :返回元素是否被选中
- screenshot(filename) :将当前元素的屏幕截图保存到文件
- send_keys() #发送元素值,例如获取的搜素框后向其中输入搜素内容
- submit() :提交表单
- value_of_css_property() :CSS属性的值
- id :selenium使用的内部ID
- location :元素在可渲染画布中的位置
- location_once_scrolled_into_view :发现元素在屏幕视图中的位置
- rect :返回包含元素大小和位置的字典
- screenshot_as_base64 :获取当前元素的截屏,作为base64编码的字符串
- size :获取元素的大小
- tag_name :获取元素的tagName属性
- text :获取元素的文本
与页面交互,实现输出文本搜索功能,并打印搜索结果源码:
from selenium import webdriver driver=webdriver.Chrome() driver.get('http://www.baidu.com') element=driver.find_element_by_id('xx') #获取输入框元素 element.send_keys('python') #发送元素 button=driver.find_element_by_id('btnZzk') #获取搜索按钮 button.click() #发送搜索动作 data=driver.page_source print(driver.current_url) #打印URL print(data) print(type(element)) driver.close()
4、动作链
selenium.webdriver.common.action_chains.ActionChains(driver)
在上面的实例中我们针对的是某个节点元素的操作,如果要对没有特定元素的对象操作如鼠标拖拽、键盘按键等,这些动作就称为动作链,selenium使用ActionChains()类来实现鼠标移动,鼠标按钮操作,按键操作、上下文菜单交互,悬停和拖放等
- click(on_element=None) ——单击鼠标左键
- click_and_hold(on_element=None) ——点击鼠标左键,不松开
- context_click(on_element=None) ——点击鼠标右键
- double_click(on_element=None) ——双击鼠标左键
- drag_and_drop(source, target) ——拖拽到某个元素然后松开
- drag_and_drop_by_offset(source, xoffset, yoffset) ——拖拽到某个坐标然后松开
- key_down(value, element=None) ——按下某个键盘上的键
- key_up(value, element=None) ——松开某个键
- move_by_offset(xoffset, yoffset) ——鼠标从当前位置移动到某个坐标
- move_to_element(to_element) ——鼠标移动到某个元素
- move_to_element_with_offset(to_element, xoffset, yoffset) ——移动到距某个元素(左上角坐标)多少距离的位置
- perform() ——执行链中的所有动作
- release(on_element=None) ——在某个元素位置松开鼠标左键
- send_keys(*keys_to_send) ——发送某个键到当前焦点的元素
- send_keys_to_element(element, *keys_to_send) ——发送某个键到指定元素
将元素拖拽到目标位置:
from selenium.webdriver import ActionChains element = driver.find_element_by_name("source") target = driver.find_element_by_name("target") action = ActionChains(driver) action.drag_and_drop(element, target).perform()
执行鼠标操作的流程:
from selenium.webdriver import ActionChains menu = driver.find_element_by_css_selector(".nav") #获取element对象 submenu = driver.find_element_by_css_selector(".nav #submenu1") #获取点击对象 actions = ActionChains(driver) #创建鼠标对象 actions.move_to_element(menu) #移动鼠标到对象 actions.click(submenu) #点击对象 actions.perform() #执行操作
(5)弹出对话框
selenium.webdriver.common.alert.Alert(driver)
首先区别下alert、window和伪装对话框:
alert,浏览器弹出框,一般是用来确认某些操作、输入简单的text或用户名、密码等,根据浏览器的不同,弹出框的样式也不一样,不过都是很简单的一个小框。在firebug中是无法获取到该框的元素的,也就是说alert是不属于网页DOM树的。如下图所示:
window,浏览器窗口,点击一个链接之后可能会打开一个新的浏览器窗口,跟之前的窗口是平行关系(alert跟窗口是父子关系,或者叫从属关系,alert必须依托于某一个窗口),有自己的地址栏、最大化、最小化按钮等。这个很容易分辨。
div伪装对话框,是通过网页元素伪装成对话框,这种对话框一般比较花哨,内容比较多,而且跟浏览器一看就不是一套,在网页中用firebug能够获取到其的元素,如下图:
Alert内置支持处理弹窗对话框的方法:
- accept() :确认弹窗,用法:Alert(driver).appept()
- authenticate(username,password) :将用户名和密码发送到authenticated对话框,隐含点击确定,用法driver.switch_to.alert.authenticate(‘username’,‘password’)
- dismiss() :取消确认
- send_keys(keysToSend) :将密钥发送到警报,keysToSend为要发送的文本
- text :获取Alert的文本
import time from selenium import webdriver from selenium.webdriver.common.alert import Alert driver=webdriver.Chrome() driver.get('https://www.baidu.com') driver.execute_script("alert('确定');") #弹出窗口 time.sleep(2) print(driver.switch_to.alert.text) #输出alert文本 alert=Alert(driver).accept() #自动点击确定窗口
window操作
window类似于alert,不过与原window是平行的,所以只需要切换到新的window上便可以操作该window的元素。driver.switch_to.window(window_handle)
而window是通过window句柄handle来定位的。而selenium提供了两个属性方法来查询window句柄:driver.current_window_handle 和driver.window_handles
用以上两个属性获取到当前窗口以及所有窗口的句柄,就可以切换到其他的window了。
from selenium import webdriver from time import sleep from selenium.webdriver.common.alert import Alert driver = webdriver.Firefox() driver.maximize_window() driver.get('http://sahitest.com/demo/index.htm') current_window = driver.current_window_handle # 获取当前窗口handle name driver.find_element_by_link_text('Window Open Test With Title').click() all_windows = driver.window_handles # 获取所有窗口handle name # 切换window,如果window不是当前window,则切换到该window for window in all_windows: if window != current_window: driver.switch_to.window(window) print driver.title # 打印该页面title driver.close() driver.switch_to.window(current_window) # 关闭新窗口后切回原窗口,在这里不切回原窗口,是无法操作原窗口元素的,即使你关闭了新窗口 print driver.title # 打印原页面title driver.quit()
div类对话框
div类对话框是普通的网页元素,通过正常的find_element就可以定位并进行操作。不在这里进行详述。注意设置一定的等待时间,以免还未加载出来便进行下一步操作,造成NoSuchElementException报错。
6、键盘操作
selenium.webdriver.common.keys.Keys
selenium提供一个keys包来模拟所有的按键操作,下面是一些常用的按键操作:
- 回车键:Keys.ENTER
- 删除键:Keys.BACK_SPACE
- 空格键:Keys.SPACE
- 制表键:Keys.TAB
- 回退键:Keys.ESCAPE
- 刷新键:Keys.F5
- 全选(ctrl+A):send_keys(Keys.CONTROL,‘a’) #组合键需要用send_keys方法操作
- 复制(ctrl+C):send_keys(Keys.CONTROL,‘c’)
- 剪切(ctrl+X):send_keys(Keys.CONTROL,‘x’)
- 粘贴(ctrl+V):send_keys(Keys.CONTROL,‘v’)
import requests from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.common.action_chains import ActionChains driver=webdriver.Chrome() driver.get('https://pypi.org/') element=driver.find_element_by_id('search') #获取输入框 element.send_keys('selenium') #搜索selenium包 element.send_keys(Keys.ENTER) #按回车键 #element_a=driver.find_element_by_link_text('selenium') #定位selenium包链接 element_a = driver.find_element_by_xpath('//*[@id="content"]/section/div/div[2]/form/section[2]/ul/li[1]/a/h3/span[1]')#定位selenium包链接 ActionChains(driver).move_to_element(element_a).click(element_a).perform() #按左键点击链接执行 element_down=driver.find_element_by_link_text('Download files') #定位下载链接 ActionChains(driver).move_to_element(element_down).click(element_down).perform() #按左键点击链接 element_selenium=driver.find_element_by_link_text('selenium-3.13.0.tar.gz') #定位元素selenium下载包链接 data=element_selenium.get_attribute('href') #获取链接地址 with open('selenium-3.13.0.tar.gz','wb') as f: source=requests.get(data).content #请求下载链接地址获取二进制包数据 f.write(source) #写入数据 f.close() driver.quit()
7、延时等待
目前大多数Web应用程序都在使用AJAX技术。当浏览器加载页面时,该页面中的元素可能以不同的时间间隔加载。这使定位元素变得困难:如果DOM中尚未存在元素,则locate函数将引发ElementNotVisibleException异常。使用等待,我们可以解决这个问题。Selenium Webdriver提供两种类型的等待: 隐式和显式。
显式等待使WebDriver等待某个条件发生,然后再继续执行。隐式等待在尝试查找元素时,会使WebDriver轮询DOM一段时间。
显示等待:
显性等待WebDriverWait,配合该类的until()和until_not()方法,就能够根据判断条件而进行灵活地等待了。它主要的意思就是:程序每隔xx秒看一眼,如果条件成立了,则执行下一步,否则继续等待,直到超过设置的最长时间,然后抛出TimeoutException。
until
method: 在等待期间,每隔一段时间(__init__中的poll_frequency)调用这个传入的方法,直到返回值不是False
message: 如果超时,抛出TimeoutException,将message传入异常
until_not
与until相反,until是当某元素出现或什么条件成立则继续执行,
until_not是当某元素消失或什么条件不成立则继续执行,参数也相同,不再赘述。
常用等待条件:
- title_is :标题是某内容
- title_contains :标题包含某内容
- presence_of_element_located :节点加载出来,传入定位元组,如(By.ID, ‘p’)
- presence_of_all_elements_located :所有节点加载出来
- visibility_of_element_located :节点可见,传入定位元组
- visibility_of :可见,传入节点对象
- text_to_be_present_in_element :某个节点文本包含某文字
- text_to_be_present_in_element_value :某个节点值包含某文字
- invisibility_of_element_located :节点不可见
- frame_to_be_available_and_switch_to_it :加载并切换
- element_to_be_clickable :节点可点击
- staleness_of :判断一个节点是否仍在DOM,可判断页面是否已经刷新
- element_to_be_selected :节点可选择,传节点对象
- element_located_to_be_selected :节点可选择,传入定位元组
-element_selection_state_to_be :传入节点对象以及状态,相等返回True,否则返回False - element_located_selection_state_to_be :传入定位元组以及状态,相等返回True,否则返回False
- alert_is_present :是否出现警告
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC driver=webdriver.Chrome() driver.get('https://www.taobao.com/') wait=WebDriverWait(driver,3) #设置监听driver等待时间3秒 input=wait.until(EC.presence_of_element_located((By.ID,'q'))) #设置等待条件为id为q的元素加载完成 button=wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'.btn-search'))) #设置等待条件为class名为btn-search的元素加载完成 print(input,button)
隐式等待:
Selenium在DOM中没有找到节点,如果使用了隐式等待,Selenium将会进行等待,当超出设定时间后,则抛出找不到节点的异常。即当要查找的节点没有立即出现的时候,隐式等待将等待一段时间再查找DOM,默认的时间是0。调用driver的implicitly_wait()方法实现隐式等待:
from selenium import webdriver driver = webdriver.Chrome() driver.implicitly_wait(10) #隐式等待设置等待时间为10s driver.get("http://somedomain/url_that_delays_loading") myDynamicElement = driver.find_element_by_id("myDynamicElement")
8、异常处理
所有webdriver代码中发生的异常:
- selenium.common.exceptions.WebDriverException :webdriver基本异常
- selenium.common.exceptions.UnknownMethodException :请求的命名与URL匹配但该URL方法不匹配
- selenium.common.exceptions.UnexpectedTagNameException :当支持类没有获得预期的Web元素时抛出
- selenium.common.exceptions.UnexpectedAlertPresentException :出现意外警报时抛出,通常在预期模式阻止webdriver表单执行任何更多命令时引发
- selenium.common.exceptions.UnableToSetCookieException :当驱动程序无法设置cookie时抛出
- selenium.common.exceptions.TimeoutException :当命令没有在足够的时间内完成时抛出
- selenium.common.exceptions.StaleElementReferenceException :当对元素的引用现在“陈旧”时抛出,陈旧意味着该元素不再出现在页面的DOM上
- selenium.common.exceptions.SessionNotCreatedException :无法创建新会话
- selenium.common.exceptions.ScreenshotException :屏幕截图错误异常
- selenium.common.exceptions.NoSuchWindowException :当不存在要切换的窗口目标时抛出
- selenium.common.exceptions.NoSuchElementException :无法找到元素时抛出
- selenium.common.exceptions.NoSuchCookieException :在当前浏览上下文的活动文档的关联cookie中找不到与给定路径名匹配的cookie
- selenium.common.exceptions.NoSuchAttributeException :无法找到元素的属性时抛出
- selenium.common.exceptions.JavascriptException :执行用户提供的JavaScript时发生错误
from selenium import webdriver from selenium.common.exceptions import NoSuchElementException driver=webdriver.Chrome() driver.get('https://www.baidu.com') try: element=driver.find_element_by_id('test') print(element) except NoSuchElementException as e: print('元素不存在:',e)
9、实例:抓取淘宝页面商品信息
import re import pymongo from selenium import webdriver from selenium.common.exceptions import TimeoutException from selenium.webdriver.common.by import By from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from urllib.parse import quote from selenium.common.exceptions import WebDriverException from pyquery import PyQuery as pq #链接mongodb数据库 client=pymongo.MongoClient(host='localhost',port=27017) db=client['taobao'] #定义无头chrome opt=webdriver.ChromeOptions() opt.add_argument('--headless') driver=webdriver.Chrome(chrome_options=opt) #定义页面等待时间 wait=WebDriverWait(driver,10) #定义搜索商品名 uname='iPad' #搜索商品 def search(): try: url = 'https://s.taobao.com/search?q=' + quote(uname) driver.get(url) total=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.total'))) except TimeoutException: return search() return total.text #实现翻页商品 def next_page(page): print('正在抓取第{}'.format(page)) try: if page >= 1: input=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.form > input'))) submit=wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit'))) input.clear() input.send_keys(page) submit.click() wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > ul > li.item.active > span'),str(page))) wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-itemlist .items .item'))) get_products() except TimeoutException: next_page(page) except WebDriverException as e: print('index_page:',e) #解析商品信息 def get_products(): #print('开始解析页面...') html = driver.page_source doc = pq(html, parser='html') items = doc('#mainsrp-itemlist .items .item').items() for i in items: product = { 'image': 'https:' + i.find('.pic .img').attr('data-src'), 'price': i.find('.price').text(), 'deal': i.find('.deal-cnt').text(), 'title': i.find('.title').text(), 'shop': i.find('.shop').text(), 'location': i.find('.location').text() } #print(product) save_to_mongo(product) #保存到mongodb def save_to_mongo(result): try: if db['collection_taobao'].insert(result): print('保存到mongodb成功!',result) except Exception: print('保存到mongodb失败',result) #主函数调用 def main(): try: total=search() total=int(re.compile('(\d+)').search(total).group(1)) for i in range(1,total+1): next_page(i) finally: driver.quit() #执行函数入口 if __name__ == '__main__': main()
参考

 浙公网安备 33010602011771号
浙公网安备 33010602011771号