MatLab学习笔记
前言:
MatLab 与 Python 对比:
MatLab:数值计算、微分方程求解、仿真等
Python:爬虫、数据挖掘、机器学习、深度学习等
入门:
基础知识点:
| 知识点 | 说明 |
|---|---|
| Ctrl键 + N | 创建(普通)脚本文件(后缀:.m) |
| % Ctrl键 + R Ctrl键 + T |
注释 添加注释 取消注释 |
| 实时脚本文件(后缀:.mlx) Ctrl键 + E Ctrl键 + Alt +Enter Ctrl键 + Enter |
文件特点:代码与文本分离;可插入图片与公式;运行结果实时显现;交互式文档 切换文本与代码 分节符 运行当前节代码 |
| Ctrl键 + I | 代码快速智能缩进 |
| ; | 对应代码运行结果在命令行窗口不显示(也可以起到分隔语句的作用) |
| 数据文件 | 后缀:.mat |
常用命令行:
| 命令 | 作用 |
|---|---|
| clc | 清空命令行窗口 |
| clear clear 变量名 |
清空工作区 删除指定变量 |
| 上/下键 | 查找历史命令 |
| Ctrl键 + C | 强制结束程序 |
特殊变量:
| 变量名称 | 描述 |
|---|---|
| ans | 默认用于保存运算结果 |
| pi | 圆周率 |
| inf / -inf | 无穷大[^1] / 负无穷大 |
| NaN | 缺失值或未定值 |
| i / j | 复数单位 |
| eps | 浮点相对精度(大小约为 2.22e-16,近似为零) |
数学运算函数:
| 函数名 | 作用 |
|---|---|
| abs | 绝对值或复数求模 |
| floor | 向下取整 |
| ceil | 向上取整 |
| fix | 保留整数 |
| round round(x,n) |
四舍五入取整 保留 n 位小数(若 n 为负数,则反向取零[^2]) |
| mod(x,y) | 取余 |
| sqrt(a) | 开平方根(若 a 为负数,结果为复数) |
| exp(x) | ex |
| log(x) | lg x |
| log2 / log10 | 计算以2 / 10为底的对数[^3] |
| sin / cos / tan sind / cosd / tand asin / acos / atan |
三角函数(以弧度为单位) 三角函数(以角度为单位) 反三角函数(以弧度为单位) |
| isprime | 判断质数 |
功能函数:
| 函数名 | 功能 |
|---|---|
| format long g | 长固定小数点格式 |
| doc 命令名称 | 查看官方文档 |
| disp | 标准输出流 |
| load | 导入工作区变量 |
断点调试:
| 指令 | 效果 |
|---|---|
| 设置断点 | 无 |
| 继续 | 执行代码至下一断点 |
| 步进 | 逐行运行代码 |
向量:
创建:
1.直接创建法
将数据用 "[ ]" 括入,数据之间以空格、逗号(行向量)或者分号、回车(列向量)分隔
2.冒号法
A : step : B
A为起始值,step为步长,B为终止边界[^4]
3.函数创建法(linspace / logspace)
linspace(a,b):创建元素总数为100,以a为起点,b为终点的等差数列行向量(若 a>b,步长为负数)
linspace(a,b,n):创建元素总数为n,以a为起点,b为终点的等差数列行向量
logspace(a,b):创建元素总数为50,以10^a^ 为起点,10^b^ 为终点的等比数列行向量
logspace(a,b,n):创建元素总数为n,以10^a^ 为起点,10^b^ 为终点的等比数列行向量
索引:
length(a) / numel(a):返回向量维度
MatLab中,元素的索引从"1" 开始,最大索引即为向量维度
a = [2 3 5 6 8 1 0]
单元素提取:
a(index)
多元素提取(将index设置为向量,存放需访问索引):
index = [1 2 3 4]
a(index)
或者a([1 2 3 4])
或者a(1:1:4)
MatLab支持元素重复提取:
a([1 2 2 2])
end索引:指向向量末元素的索引
a(3:end)
注意:使用end之后,不可以将其赋值给变量(如下代码)
index = 3:end
修改与删除:
a(1) = 2
a([1 2]) = [8 9] (注意左右两侧向量长度需相等)
a(1:3) = [7 8 9]
a[1:3] = 100 (若右侧为常数,则表示将左侧指定元素全赋值为该常数)
a(1) = [] (删除指定元素)
a(end-3:end) (删除指定区域元素)
矩阵:
创建:
1.直接输入法
将数据用 "[ ]" 括入,同行数据之间以空格、逗号分隔,行与行之间以分号、回车分隔
2.函数创建法
zeros(n) 创建 n 阶零矩阵
zeros(m,n) 创建 mxn 阶零矩阵
ones 的用法与 zeros 类似;用于创建元素均为"1"的矩阵
eye(n) 创建 n 阶单位矩阵
% 根据线性代数的知识可知,单位矩阵必须为方阵
% 但在MatLab中,可以使用 eye 函数来创建类似于单位矩阵的 "mxn 阶单位矩阵"
% eye(2,3)
% [1 0 0
% 0 1 0]
rand(n) n 阶矩阵
rand(m,n) mxn 阶矩阵
数据来源:[0,1]随机、均匀分布取样
randi([min,max],n) n 阶矩阵
randi([min,max],m,n) mxn 阶矩阵
randi(max,m,n) min == 1
数据来源:[min,max]随机、均匀分布取样(整数)
randn(n) n 阶矩阵
randn(m,n) mxn 阶矩阵
数据来源:(0,1)随机、标准正态分布取样
% 标准正态分布:以0为均值、1为标准差的正态分布
创建对角矩阵(首参数为向量):
diag([1 2 3])
[1 0 0
0 2 0
0 0 3]
diag([1 2 3],-1)
[0 0 0 0
1 0 0 0
0 2 0 0
0 0 3 0]
diag([1 2 3],2)
[0 0 1 0 0
0 0 0 2 0
0 0 0 0 3
0 0 0 0 0
0 0 0 0 0]
获取对角线元素(首参数为方阵):
A =
[6 0 1 0 9
3 0 0 2 0
0 0 8 0 3
0 0 5 0 0
0 0 1 9 0]
diag(A) == [6 0 8 0 0]
diag(A,-1) == [3 0 5 9]
diag(A,2) == [1 2 3]
-------------------------------------------------------------------------------------------------------------------
创建分块对角矩阵:
A1 = [1 2 3
3 4 5]
A2 = [4 5 6 7
0 1 2 4
2 3 4 0]
A3 = [0 1
0 9
8 1]
blkdiag(A1,A2,A3) ==
[1 2 3 0 0 0 0 0 0
3 4 5 0 0 0 0 0 0
0 0 0 4 5 6 7 0 0
0 0 0 0 1 2 4 0 0
0 0 0 2 3 4 0 0 0
0 0 0 0 0 0 0 0 1
0 0 0 0 0 0 0 0 9
0 0 0 0 0 0 0 8 1]
3.文件导入法
MatLab 支持读取本地文件:
.txt 、.dat 、.csv (适用于带分隔符的文本文件)
.xls 、.xlsb 、.xlsm 、.xlsx 、.xltm 、.xltx 、.ods (适用于电子表格文件)
行列索引:
A =
[6 0 1 0 9
3 0 0 2 0
0 0 8 0 3
0 0 5 0 0
0 0 1 9 0]
单元素索引:
A(row_index,col_index)
多元素索引:
A([1 3],[1 2 6]) 提取1,3行、1,2,6列元素
A(1:2:end,1:2:end) 提取奇数行、奇数列元素
% 简写:起始"1"与终止"end"可以省略
A(:,n) 提取矩阵中第n列元素
A(m,:) 提取矩阵中第m行元素
A([2 3],:) 提取矩阵中第2,3行元素
A(2:2:end,:) 提取矩阵中偶数行元素
A(1:2:end,3:3:end) 提取矩阵中奇数行、3的倍数列元素
size(A) 即返回[A_row,A_col]
size(A,1) 即返回A_row
size(A,2) 即返回A_col
返回值可以直接使用向量来接收,也可以使用两个常数接收
vector = size(A)
[A_r,A_c] = size(A)
length(A) 即返回max(A_row,A_col)
numel(A) 即返回元素总数
线性索引:
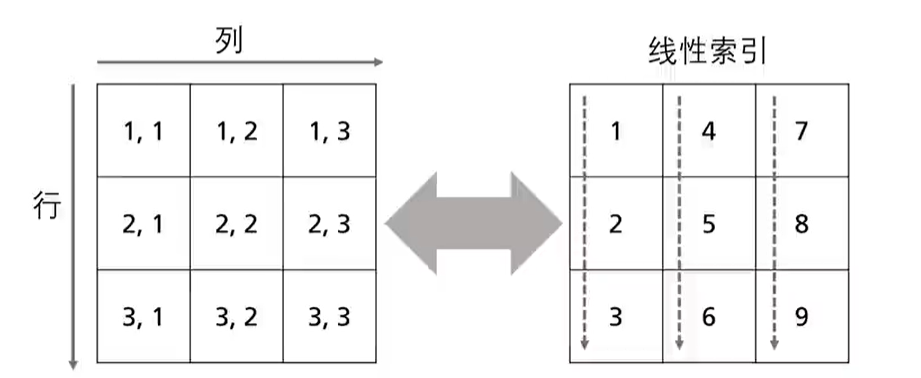
MatLab 中数据的存储方式为 "列线性"
A =
[6 0 1 0 9
3 0 0 2 0
0 0 8 0 3
0 0 5 0 0
0 0 1 9 0]
A(7) == A(2,2)
A(6:9) == A([1 2 3 4],2)
A(:) 表示将A中所有元素按照线性索引顺序重构成列向量
A(1:end) 表示将A中所有元素按照线性索引顺序重构成行向量
% 线性索引与行列索引转换
index = sub2ind([A_row,A_col],row,col) 输入矩阵大小,求解行列、数,返回相应线性索引
[row,col] = ind2sub([A_row,A_col],index) 输入矩阵大小,求解线性索引,返回相应行列、数
修改与删除:
% 行列索引
A(2,3) = 10
A(1,:) = 100
A([2 3],[3 4]) = [8 8;8 8] 2x2矩阵大小需匹配
% 线性索引
A(3) = 5
A(1:end) = 0
A(2:4) = [8 8 8]
% 若修改索引越界矩阵,此时并不会报错, MatLab会将空缺位置以"0"补充
A =
[2 3 1
1 7 8]
A(3,4) = 7
A ==
[2 3 1 0
1 7 8 0
0 0 0 7]
% 利用行列索引进行矩阵删除操作只能整行或整列
A =
[2 3 1 0
1 7 8 0
0 0 0 7]
A(:,1) = []
A(:,[2,end]) = []
% 利用线性索引进行矩阵删除操作无需对整行或整列操作,不过其返回结果为剩余元素按照线性索引排列的行向量
A =
[2 3 1 0
1 7 8 0
0 0 0 7]
A(1:4) = []
A == [7 0 1 8 0 0 0 7]
拼接与重复:
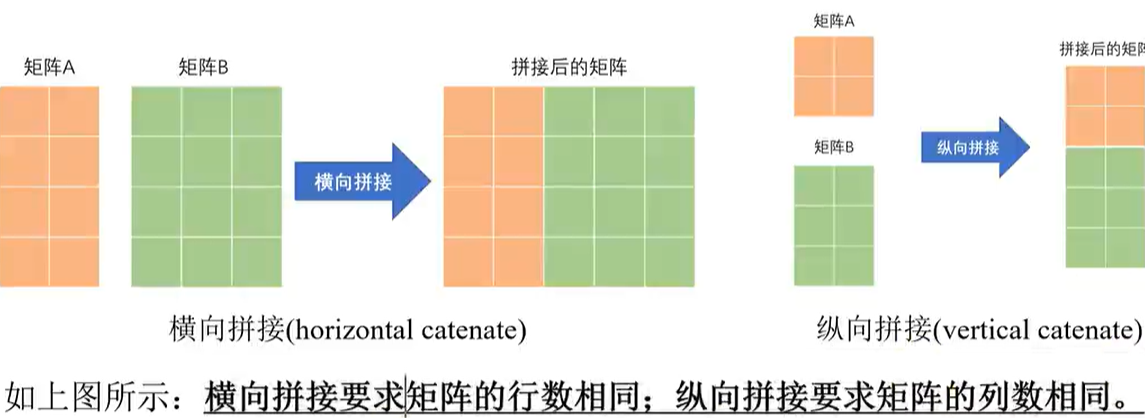
% 横向拼接
C = [A B]
C = horzcat(A,B)
C = cat(dim,A,B) //dim == 2
% 纵向拼接
C = [A
B]
C = vertcat(A,B)
C = cat(dim,A,B) //dim == 1
🌟以上拼接方式也适用于多个矩阵之间的拼接

% 将矩阵在行方向重复m次,列方向重复n次
B = repmat(A,m,n)
% 将向量元素重复
v = [1 2 3]
-------------------------------------------------------------------------------------------------------------------
repelem(v,n) 表示将v中所有元素重复n次
repelem(v,2)
v == [1 1 2 2 3 3]
-------------------------------------------------------------------------------------------------------------------
repelem(v,[2 3 1]) 表示将v中第一个元素重复2次,第二个元素重复3次,第三个元素重复1次
v == [1 1 2 2 2 3]
% 将矩阵元素重复
A =
[2 3 1
1 7 8]
-------------------------------------------------------------------------------------------------------------------
repelem(A,3,2) 表示将A所有行元素重复3次,所有列元素重复2次
A ==
[2 2 3 3 1 1
2 2 3 3 1 1
2 2 3 3 1 1
1 1 7 7 8 8
1 1 7 7 8 8
1 1 7 7 8 8]
-------------------------------------------------------------------------------------------------------------------
repelem(A,3,[1,2,3]) 表示将A所有行元素重复3次,第一列元素重复1次,第二列元素重复2次,第三列元素重复3次
A ==
[2 3 3 1 1 1
2 3 3 1 1 1
2 3 3 1 1 1
1 7 7 8 8 8
1 7 7 8 8 8
1 7 7 8 8 8]
-------------------------------------------------------------------------------------------------------------------
repelem(A,[3,4],[1,2,3])
重构与重排:
reshape:按照线性索引将矩阵重构
A =
[2 3 1 0 9 8
1 7 8 1 2 4]
B = reshape(A,3,4)
B ==
[2 7 0 2
1 1 1 8
3 8 9 4]
% 实际上,由于转化前后元素数量不变,只需要给出转化后的行数或列数即可
reshape(A,3,[])
reshape(A,[],4)
sort:
% 对向量排序
sort(v) 默认升序
sort(v,'descend') 降序排序
% 对矩阵各列(自上而下)排序
sort(A,dim) //dim == 1
sort(A,dim,'descend')
% 对矩阵各行(自左而右)排序
sort(A,dim) //dim == 2
sort(A,dim,'descend')
% sort函数的返回值可以为双参数
v = [5 6 1 3 9 0]
[sorted_v,index] = sort(v)
sorted_v == [0 1 3 5 6 9]
index == [6 3 4 1 2 5] 存储sorted_v中对应数据在原向量中的索引
恒等式:v(index) == sorted_v
% 矩阵同样适用 %
sortrows:
% 利用sort函数对矩阵排序,矩阵各行/列中元素的联系被打乱
% 利用sortrows函数可以将矩阵各行元素绑定
A =
[2 7 0 2
1 1 1 2
3 8 9 4]
-------------------------------------------------------------------------------------------------------------------
sorted_A = sortrows(A,col) 表示按照第col列元素进行排序
sorted_A = sortrows(A,2)
sorted_A ==
[1 1 1 2
2 7 0 2
3 8 9 4]
% 若省略参数col,则表示默认为 1:end
-------------------------------------------------------------------------------------------------------------------
sorted_A = sortrows(A,[col_1,col_2]) 表示按照第col_1列元素进行排序,若col_1列元素相等则按照第col_2列元素进行排序
sorted_A = sortrows(A,[4,3])
sorted_A ==
[2 7 0 2
1 1 1 2
3 8 9 4]
-------------------------------------------------------------------------------------------------------------------
sorted_A = sortrows(A,[col_1,col_2],{'descend','ascend'})
% 表示按照第col_1列元素降序排序,若col_1列元素相等则按照第col_2列元素升序排序
% sortrows函数的返回值可以为双参数
A =
[2 7 0 2
1 1 1 2
3 8 9 4]
[sorted_A,index] = sortrows(A,2)
sorted_A ==
[1 1 1 2
2 7 0 2
3 8 9 4]
index == [2 1 3]
恒等式:A(index,:) == sorted_A
flip、fliplr、flipud:
flip(A)
% 若A为向量,将向量中各元素顺序翻转
恒等式:A(end:-1:1) == flip(A)
% 若A为矩阵,将矩阵中各行元素上下翻转
-------------------------------------------------------------------------------------------------------------------
flip(A,dim)
dim == 1:矩阵上下翻转
恒等式:flip(A,1) == flipud(A)
dim == 2:矩阵左右翻转
恒等式:flip(A,2) == fliplr(A)
rot90:
% 将矩阵逆时针旋转(k*90)度,若k为负数代表顺时针旋转
rot90(A,k)
运算:
函数运算:
| 函数 | 作用 |
|---|---|
| exp(A) | 将矩阵各元素取为以e为底的指数 |
| round(A,n) | 对矩阵各元素进行四舍五入操作 |
| mod(A,x) | 对矩阵各元素取余 |
| 函数 | 作用 |
|---|---|
| sum | 求和 |
| prod | 求积 |
| cumsum | 求累计和 |
| diff | 求差分 |
| mean | 求平均值 |
| median | 求中位数 |
| mode | 求众数 |
| var | 求方差 |
| std | 求标准差 |
| min | 求最小值 |
| max | 求最大值 |
% 对向量求和/积
sum(v)
prod(v)
% 对矩阵各行、各列元素求和/积
sum(A,dim) / prod(A,dim)
dim == 1:返回各列元素和(行向量)
dim == 2:返回各行元素和(列向量)
% 对矩阵所有元素求和/积
sum(A(:)) / prod(A(:)) 其中A(:)为线性列向量
sum(A,'all') / prod(A,'all')
sum(A,[1,2]) / prod(A,[1,2])
% 数据中存在缺失值
若数据中存在缺失值,利用sum函数求和时,结果仍为NaN
sum(A,dim,'omitnan') / prod(A,dim,'omitnan')代表忽略NaN后的求和结果
% 对向量求累积和(即前缀和)
v = [1 2 3 0 -1]
cumsum(v) == [1 3 6 6 5]
% 对矩阵各行、各列元素求累积和
cumsum(A,dim)
dim == 1:返回各列元素累积和
dim == 2:返回各行元素累积和
% 'omitnan'忽略NaN后计算累计和
cumsum(A,dim,'omitnan')
% 求解向量差分
diff(v,n) n表示计算n阶差分
% 求解矩阵各行、各列元素n阶差分
diff(A,n,dim)
dim == 1:求解各列元素n阶差分
dim == 2:求解各列元素n阶差分
% 不支持'omitnan'参数
% 求解向量平均值/中位数
mean / median(v)
% 求解矩阵各行、各列元素平均值/中位数
mean / median(A,dim)
dim == 1:求解各列元素平均值/中位数
dim == 2:求解各列元素平均值/中位数
% 求解矩阵所有元素平均值/中位数
mean / median(A(:))
% 数据中存在缺失值
mean / median(A,dim,'omitnan')
% 求解向量众数
mode(v)
% 求解矩阵各行、各列元素众数
mode(A,dim)
dim == 1:求解各列元素众数
dim == 2:求解各列元素众数
% 求解矩阵所有元素众数
mode(A(:))
% mode函数执行时会自动忽略NaN,故不支持'omitnan'参数
% mode函数多参数返回值
[M,F] = mode(v) 其中M为最小众数,F为M出现次数
[M,F,C] = mode(v) C为元胞数组,其中存储包含v中所有众数的列向量
C{1}
% 矩阵用法类似 %

% 求解向量方差/标准差
diff / std(v,w)
w == 0:样本方差
w == 1:总体方差
% 求解矩阵各行、各列元素方差/标准差
diff / std(A,w,dim)
dim == 1:求解各列元素方差/标准差
dim == 2:求解各列元素方差/标准差
% 数据中存在缺失值
diff / std(A,w,dim,'omitnan')
% 求解两矩阵对应位置元素的较小值
min(A,B) 返回值为"较小值矩阵"
% 若A,B不为同型矩阵,则必须保证其具有兼容性(矩阵兼容性见"算数运算"一节)
A =
[1 3 5
2 3 8
1 2 3
2 1 4]
-------------------------------------------------------------------------------------------------------------------
B = 4
min(A,B) ==
[1 3 4
2 3 4
1 2 3
2 1 4]
-------------------------------------------------------------------------------------------------------------------
B = [1 2 3]
min(A,B) ==
[1 2 3
1 2 3
1 2 3
1 1 3]
-------------------------------------------------------------------------------------------------------------------
B = [1
2
3
4]
min(A,B) ==
[1 1 1
2 2 2
1 2 3
2 1 4]
% 求解向量最小值
min(v)
% 求解矩阵各行、各列元素最小值
min(A,[],dim) 添加空向量参数是为与情形2区分
dim == 1:求解各列元素最小值
dim == 2:求解各列元素最小值
% min函数多参数返回值
[min_A,index] = min(A) 其中min_A为最小值向量,index为最小值所在维度上的索引(若最小值出现多次,则为首次出现位置)
% min函数执行时会自动忽略NaN,故不支持'omitnan'参数
% max函数与min函数使用方法完全一致 %
算术运算:
矩阵兼容:
% 同型矩阵
矩阵的行、列均相同,运算规则与线性代数中完全一致
% 矩阵 + 标量
运算法则:该常数与矩阵各元素分别运算
% 矩阵 + 具有相同行数的列向量
运算法则:将该列向量在水平方向上堆叠,直至形成同型矩阵,转至情形1
% 矩阵 + 具有相同列数的行向量
运算法则:将该行向量在竖直方向上堆叠,直至形成同型矩阵,转至情形1
% 列向量 + 行向量
运算法则:将行向量在竖直方向上堆叠,列向量在水平方向上堆叠,直至形成"公共同型矩阵",转至情形1
基本运算符:
| 运算符 | 功能 |
|---|---|
| + | 加 |
| - | 减 |
| * | 乘 |
| .* | 点乘 |
| / | 右除 |
| ./ | 点除 |
| \ | 左除 |
| ^ | 乘方 |
| .^ | 点乘方 |
| ' | 转置 |
| .' | 点转置 |
% 加法(+)、减法(-)
运算法则与线性代数一致,只需满足矩阵兼容即可
% 点乘(.*)
对应元素分别相乘,只需满足矩阵兼容即可
% 乘(*)
矩阵相乘运算法则与线性代数一致,需满足行、列关系
若常数与矩阵相乘,点乘与乘的结果一致
% 右除(/)、左除(\)
x*A = B 求解x
x = B/A
A*x = B 求解x
x = A\B
本质为矩阵的逆,需满足对应行、列关系
% 点除(./)
A./B 表示A的各元素除以B的对应元素,只需满足矩阵兼容即可
若A为常数,则A./B == A/B
% 乘方(^)
运算法则与线性代数一致,需满足矩阵为方阵
A^(-1) 表示逆矩阵
inv(A) 表示逆矩阵
% 点乘方(.^)
对应元素分别乘方,矩阵无形式要求
A.^(0.5) 表示对A的各元素开根号
A.^(-1) == 1./A
% 转置(')、点转置(.')
行、列交换
':若矩阵中存在复数,在转置的同时将复数变为共轭复数
.':若矩阵中存在复数,在转置的同时保持复数不变
关系运算:
| 关系运算符 | 作用 |
|---|---|
| == | 等于 |
| ~= | 不等于 |
| > / < | 大于/小于 |
| >= / <= | 大于等于/小于等于 |
% 关系运算符仍满足矩阵的兼容模式
A = [2 3 5]
B =
[3
2]
A == B
ans ==
[0 1 0
1 0 0]
% NaN(不定值)之间互不相等,inf(无穷大)之间判断相等
% 连续使用关系运算符通常会带来意想不到的结果(不建议使用)
-1 < 0 < 1
% 结合关系运算与函数运算,可以用来判断矩阵中满足某些条件的元素个数
A =
[1 3 5
4 3 8
1 2 3
5 1 4]
B = A>3
B ==
[0 0 1
1 0 1
0 0 0
1 0 1]
sum(B(:)) 表示A中大于3的元素个数
% 浮点数判断相等
由于计算机存储数据的误差存在,直接使用"=="判断两个浮点数是否相等不可实现
通常将作差结果与"极小数"比较,判断是否相等,该"极小数"通常称为容差(tol)
|A-B|<tol
逻辑运算:
| 逻辑运算 | 函数名 | 运算符 | 运算规则 |
|---|---|---|---|
| 逻辑与 | and | & | 同真为真 |
| 逻辑或 | or | | | 同假为假 |
| 逻辑非 | not | ~ | 取反 |
| 逻辑异或 | xor | 无 | 逻辑值相同为假,不同为真 |
| 逻辑与(短路) | 无 | && | 短路逻辑与 |
| 逻辑或(短路) | 无 | || | 短路逻辑或 |
% 与、或、非的基本运算规则与C++一致,且只需要满足矩阵的兼容性即可
% logical() 将数值转化为逻辑值
A =
[1 0 5
4 0 8
0 2 3
0 0 0]
logical(A) ==
[1 0 1
1 0 1
0 1 1
0 0 0]
% true/false(m,n) 生成m行n列的全真/假矩阵
% 复数与NaN值无法进行逻辑运算
% && 、 ||
&& 和 || 只能对标量进行逻辑运算,不可以对矩阵运算
% 短路现象
A && B 若A为假,B便不会再操作与判断
A || B 若A为真,B便不会再操作与判断
(10 > 3) | (logical(NaN)) 报错
(10 > 3) || (logical(NaN)) 不报错
% 利用逻辑值提取矩阵元素
A =
[1 3 5
4 3 8
1 2 3
5 1 4]
L =(A <= 3)
L ==
[1 1 0
0 1 0
1 1 1
0 1 0]
A(L) ==
[1
1
3
3
2
1
3]
% L必须为逻辑矩阵,不可以为0/1的数值矩阵
-------------------------------------------------------------------------------------------------------------------
p = 0.2 每位同学被抽中的概率
A = 1:20 每位同学编号
r = rand(1,20) 随机生成20个0~1均匀分布的随机数(此时,落在0~p之间的数的概率即为p)
L = (r<p)
A(L) 得到抽中的同学编号
% 利用逻辑值修改或删除矩阵元素
v(v>6) = 100 将所有大于6的元素修改为100
v(v<=5) = [] 将所有小于等于的元素删除
% 若用以上方法删除矩阵元素,返回结果为删除元素后按照线性索引拼接而成的行向量
A(mod(A,3)==0) = 10 将所有被3整除的元素修改为10
% isnan(A) 返回值为判断元素是否为NaN的逻辑数组
A(isnan(A)) = mean(A(~isnan(A))) 将所有的NaN替换成所有非缺失值的平均值
常见逻辑函数:
| 函数 | 功能 |
|---|---|
| all | 判断是否都为非零值 |
| any | 判断是否存在非零值 |
| find | 查找非零元素索引 |
% all函数
all(A,dim)
dim == 1:判断各列是否均为非零元素,若均非零则返回ture,最终结果为行向量
dim == 2:判断各行是否均为非零元素,若均非零则返回ture,最终结果为列向量
all(A(:)) 判断矩阵所有元素是否为非零值,若成立,返回true
-------------------------------------------------------------------------------------------------------------------
score = randi([50,100],100,3)
all(score>=85,2) 三科成绩均大于85为优秀学生
any(score<60,2) 存在学科挂科需补考
all(score>=65) 判断是否有科目没有同学挂科
% any函数其余用法与all函数用法完全一致
% find函数
find(A) 返回A中非零元素的线性索引组成的向量
find(A,n) 返回A中前n个非零元素的线性索引组成的向量
find(A,n,'last') 返回A中倒数n个非零元素的线性索引组成的向量
[row,col] = find(A) 以行、列的形式返回非零元素索引
[row,col,val] = find(A) val为非零元素的值
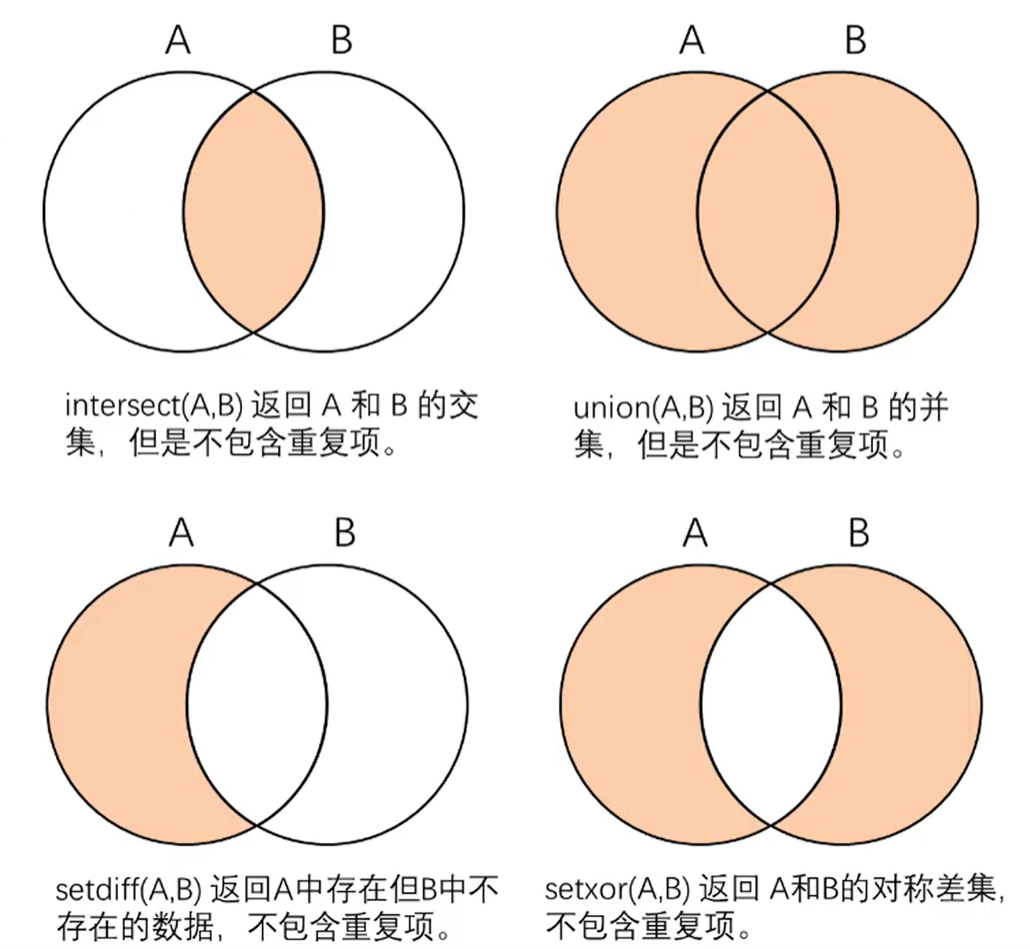
集合运算:
目前,在MatLab中并没有推出集合数据结构。为此,通常使用普通数组模拟集合功能。
集合运算函数:
| 函数名 | 功能 |
|---|---|
| unique | 返回数组中唯一值 |
| ismember | 判断元素是否存在数组中 |
| intersect | 返回交集 |
| union | 返回并集 |
| setdiff | 返回差集 |
| setxor | 返回对称差集 |
% unique函数——向量
v = [3 5 8 1 8 1 2 0]
c = unique(v)
c == [0 1 2 3 5 8] unique可以对向量元素去重,并将结果按照升序排列
% unique函数多参数返回值
[c,iv,ic] = unique(v)
iv == [8 4 7 1 2 3] iv为向量c中元素在向量v中的索引值
ic == [4 5 6 2 6 2 3 1] ic为向量v中元素在向量c中的索引值
恒等式:c(ic) == v ; v(iv) == c
% unique函数stable参数
c = unique(v,'stable') 表示固定原有顺序,而非升序排序
-------------------------------------------------------------------------------------------------------------------
% unique函数——矩阵
A =
[3 5
6 8
3 5
4 1
2 8
2 5
4 1]
C = unique(A)
C ==
[1
2
3
4
5
6
8]
即unique(A) == unique(A(:))
% unique函数rows参数
C = unique(A,'rows') 将各行视为整体进行去重与排序操作,排序时按照首元素升序排序,若首元素相同则按照次元素升序排序
C ==
[2 5
2 8
3 5
4 1
6 8]
C = unique(A,'rows','stable') 排序时按照各行出现顺序排序
% ismember函数
A = [4 1 3 4 8]
B = [3 7 4 5 4 9 6]
h = ismember(A,B)
h == [1 0 1 1 0] 返回值为A矩阵中元素在B矩阵中是否存在的逻辑值
-------------------------------------------------------------------------------------------------------------------
A =
[3 1
8 5
4 0]
B = [3 7 4 5 4 9 6]
h = ismember(A,B)
h ==
[1 0
0 1
1 0]
% ismember函数双参数
A =
[3 1
8 5
4 0]
B = [3 7 4 5 4 9 6]
[h,ib] = ismember(A,B) ib表示A中元素在B中的最小索引(线性索引)
h ==
[1 0
0 1
1 0]
ib ==
[1 0
0 4
3 0]
% ismember函数rows参数
若矩阵A、B列数相同,加上 'rows' 参数,可以将A的各行视为整体
A =
[3 1
8 5
4 0]
B =
[5 1
3 1
7 9]
[h,ib] = ismember(A,B,'rows')
h ==
[1
0
0]
ib ==
[2
0
0]
-------------------------------------------------------------------------------------------------------------------
案例解析:
A = randi([1,10],100,3) 随机生成100张彩票
B = [6 1 8] 中奖号码
二等奖:其中两数字中奖,剩余元素未中奖
edj_1 = ismember(A(:,[1 2]),B([1 2]),'rows') & (A(:,3) ~= B(3))
edj_2 = ismember(A(:,[2 3]),B([2 3]),'rows') & (A(:,1) ~= B(1))
edj_3 = ismember(A(:,[1 3]),B([1 3]),'rows') & (A(:,2) ~= B(2))
index = find(edj_1 | edj_2 | edj_3)
x = A(index,:) 二等奖号码
若不要求中奖号码的顺序,可以对彩票与中奖号码按照行排序,再进行判断
A = [5 3 1 4 2 7 2]
B = [2 8 6 1 0 3 9 5]
C = intersect(A,B) 返回A、B交集(不包含重复项),默认升序排序
C == [1 2 3 5]
C = intersect(A,B,'stable')
C == [5 3 1 2]
-------------------------------------------------------------------------------------------------------------------
A =
[3 1
8 5
4 0]
B =
[3 7 4
4 9 6]
若A、B为矩阵,则先将其转化为线性索引列向量,再取交集
C = intersect(A,B)
C ==
[3
4]
-------------------------------------------------------------------------------------------------------------------
若A、B列数相同,输入参数 'rows' ,将矩阵行视为整体取交集,结果按升序排序
A =
[3 7 0
3 7 4
8 5 2
4 0 7]
B =
[3 7 4
4 9 6
8 5 2]
C = intersect(A,B)
C ==
[3 7 4
8 5 2]
% 剩余函数与intersect函数类似
线性代数:
函数:
| 函数名 | 功能 |
|---|---|
| det | 求解方阵行列式 |
| rank | 求解矩阵的秩 |
| trace | 求解方阵的迹(主对角线元素之和) |
| rref | 将矩阵转化为行最简型 |
| inv | 返回方阵的逆 |
| transpose | 返回转置矩阵 |
| triu | 返回矩阵上三角 |
| tril | 返回矩阵下三角 |
| eig | 求解方阵特征值与特征向量 |
| norm | 求解向量或矩阵的范数 |
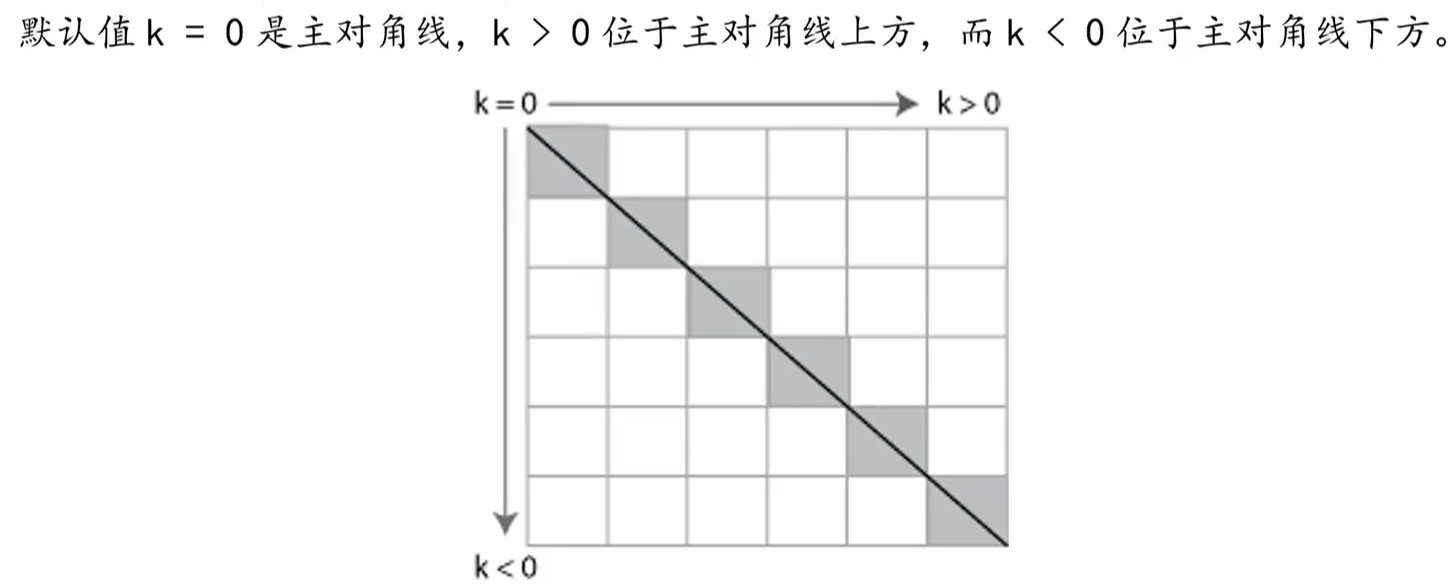
% triu、tril函数
triu(A,k) 返回第k条对角线及其以上的元素,其余元素以0填充
tril(A,k) 返回第k条对角线及其以下的元素,其余元素以0填充
% 案例解析:随机生成n阶对称矩阵
n = 4
nums =n*(n-1)/2 上(下)三角矩阵共需生成nums个随机数
A = zeros(n) 初始化为零阵
L = triu(true(n),1) 上三角逻辑填充矩阵
A(L) = randi([0,9],num,1) 将随机数填充到上三角中
A = A + A' 补充下三角矩阵
A = A + diag(randi([0,9],n,1)) 补充主对角线元素
% eig函数
e = eig(A) 返回值为列向量,包含A所有特征值
[V,D] = eig(A) V表示由特征向量(列向量)组成的矩阵,D表示由特征值组成的对角阵
% 由于特征值对应的特征向量并不唯一,所以MatLab会将特征向量单位化
-------------------------------------------------------------------------------------------------------------------
将特征值按照降序排列,并要求对应特征向量对齐
[V,D] = eig(A)
e = diag(D) 提取特征值
[sorted_e,ind] = sort(e,'descend')
D_new = diag(sorted_e)
V_new = V(:ind)

% norm函数(向量)
norm(v,p) 计算向量v的p范数,默认p取2
补充:
d曼哈顿距离 = || x-y ||1
d欧氏距离 = || x-y ||2
d闵氏距离 = || x-y ||p
程序控制流程:
条件语句:
% if语句
if 表达式1
语句1
elseif 表达式2
语句2
elseif 表达式3
语句3
else
语句4
end
% 若表达式为向量或矩阵,则当且仅当其所有元素均非零时,表达式成立
% if语句嵌套时,每个if都要有配套的end
if 表达式1
if 表达式2
语句1
else
语句2
end
else
if 表达式3
语句3
else
语句4
end
end
% switch语句
switch 开关表达式
case 表达式1
语句1
case 表达式2
语句2
...
case 表达式n
语句n
otherwise
语句n+1
end
开关表达式的计算结果必须为数值标量、字符向量、字符串,不可以为向量或矩阵
-------------------------------------------------------------------------------------------------------------------
案例解析:
switch n
case n>=60
disp("pass")
otherwise
disp("fail")
end
对于以上代码,当n>=60时,case语句判断成立,返回值为逻辑值1,与n不相等,所以最终输出fail
修改代码如下:
switch true
case n>=60
disp("pass")
otherwise
disp("fail")
end
-------------------------------------------------------------------------------------------------------------------
% switch语句元胞数组
month = randi([1,12])
switch month
case {1,2,3}
season="春天"
case {4,5,6}
season="夏天"
case {7,8,9}
season="秋天"
case {10,11,12}
season="冬天"
end
循环语句:
% for循环
for 循环变量 = 向量/矩阵
循环体
end
循环变量每次迭代从向量/矩阵中依次取出各列进行赋值,直至遍历完所有列向量,循环结束
-------------------------------------------------------------------------------------------------------------------
前n项倒数阶乘和
for n = 1:100
y = 0
for k = 1:n
y = y + 1/(k^2)
end
S(n) = y
end
-------------------------------------------------------------------------------------------------------------------
水仙花数
S = []
for num = 100:999
digital_1 = floor(num/100)
digital_2 = floor(mod(num,100)/10)
digital_3 = mod(num,10)
if num == digital_1^3 + digital_2^3 + digital_3^3
S = [S,num] 矩阵拼接
end
end
% 使用字符向量存储数字
for num = 100:999
temp = str2num((num2str(num))')
if num == temp(1)^3 + temp(2)^3 + temp(3)^3
S = [S,num] 矩阵拼接
end
end
-------------------------------------------------------------------------------------------------------------------
循环变量的取值在刚进入for循环时便以确定,后续再对向量或矩阵修改也不会改变循环变量的取值
x = 1:4
for i = x
x = [0 0 0 0]
disp(x)
end
-------------------------------------------------------------------------------------------------------------------
可以在循环体中修改循环变量的值,但是下轮循环会自动恢复
x = 1:4
for i = x
if x == 1
x = 0
disp(x)
end
-------------------------------------------------------------------------------------------------------------------
% while循环
while 表达式
循环体
end
-------------------------------------------------------------------------------------------------------------------
斐波那契数列
F(1) = 1
F(2) = 1
n = 2
while F(n) <= 999999
n = n + 1
F(n) = F(n-1) + F(n-2)
end
disp(F(end))
% break 立即结束循环
% continue 结束当前迭代
-------------------------------------------------------------------------------------------------------------------
蒙特卡洛模拟
二分搜索法求解函数零点
异常处理:
% try-catch语句
try
疑似异常代码块
catch ME
异常处理代码块
end
若"疑似异常代码块"中出现代码报错,则跳过"疑似异常代码块"直接执行"异常处理代码块"中的代码,反之只执行"疑似异常代码块"中代码
ME——Exception中为报错信息,通常不添加
程序控制流程函数:
| 函数名 | 功能 |
|---|---|
| tic/toc | 以秒为单位输出tic-toc中间的程序运行时间 |
| pause | 暂停程序运行 |
| input | 标准输入流 |
| warning | 程序运行时显示警告信息 |
| error | 显示自定义报错信息并终止程序运行 |
n = 1000;
A = rand(n,n);
B = rand(n,n);
tic
C_1 = zores(n,n);
for i = 1:n
for j = 1:n
if A(i,j) > B(i,j)
C_1 = A(i,j) + B(i,j);
else
C_1 = A(i,j) * B(i,j);
end
end
end
toc
time == 0.025
-------------------------------------------------------------------------------------------------------------------
tic
C_2 = (A>B).*(A+B) + (A<=B).*(A.*B);
toc
time == 0.0025
pause:暂停程序运行,按任意键继续
pause(n):暂停程序运行n秒
x = input(提示文本)
txt = input(提示文本,'s') 将用户输入视为文本格式,返回值txt为字符向量格式,常用于获取纯文本输入
warning off 关闭警告信息
warning on 开启警告信息
warning('自定义警告')
-------------------------------------------------------------------------------------------------------------------
warning on
a = input('请输入常数a:')
b = input('请输入常数b:')
if b == 0
warning('分母不为 0') 自定义警告不会终止程序运行
end
c = a/b
a = input('请输入常数a:')
b = input('请输入常数b:')
if b == 0
error('分母不为 0') 自定义报错,并终止程序运行
end
文本处理:
ASCII与Unicode:
ASCII编码表:
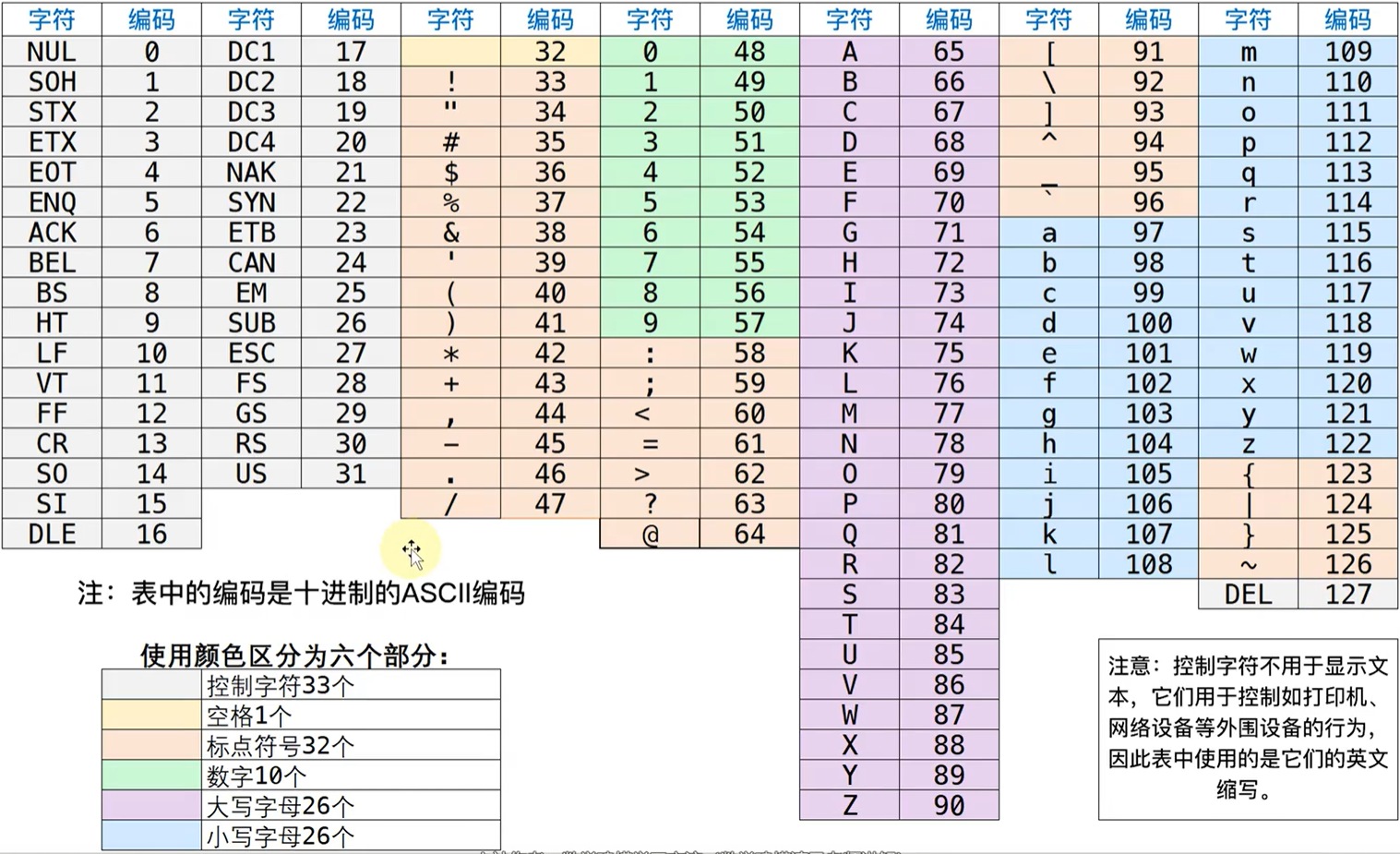
特殊ASCII编码字符:
| 十进制ASCII编码值 | 字符 |
|---|---|
| 48-57 | 数字 0-9 |
| 65-90 | 'A' - 'Z' |
| 97-122 | 'a' - 'z' |
| 10 | 换行符 |
| 32 | 空格 |
在MatLab中,字符以Unicode编码的形式存储,Unicode编码的前128位于ASCII编码一致,因此,Unicode编码可以兼容ASCII编码
字符数组:
常用函数:
| 函数名 | 功能 |
|---|---|
| double() | 获取字符对应的Unicode编码(十进制) |
| char() | 获取Unicode编码(十进制)对应的字符 |
| strcmp(c_1,c_2) strcmpi(c_1,c_2) strncmp(c_1,c_2,n) strncmpi(c_1,c_2,n) |
用于比较两个字符向量整体是否相等(区分大小写) 用于比较两个字符向量整体是否相等(不区分大小写) 用于比较两个字符向量前n项是否相等(区分大小写) 用于比较两个字符向量前n项是否相等(不区分大小写) |
| upper() | 小写字母转化为大写字母 |
| lower() | 大写字母转化为小写字母 |
| num2str(pi,n) | 指定有效数字位数进行字符转换(可以应用于向量与矩阵) |
| dec2base(D,n) | 将十进制整数D转化为n进制 |
| dec2bin(D) | 将十进制整数D转化为二进制 |
| blanks(n) | 生成n个空格 |
| deblank() | 去除字符向量末尾空白字符 |
| strtrim() | 去除字符向量开头与末尾空白字符 |
| strip() | 去除指定位置的指定字符 |
| strjust() | 设置字符向量对齐方式 |
| deal() | 将输入变量分发给输出变量 |
字符向量:
% 单字符——单引号
'a' '0' '俺'
与C++一致,对字符进行算术运算、关系运算、逻辑运算时,结果会自动转换为Unicode编码值
% 字符向量——单引号
'abc' '001' '黑凤梨'
行字符向量
'abc' == ['a','b','c']
列字符向量
['x';'y';'z']
(['x';'y';'z'])' == 'xyz'
若对字符向量使用double、char函数,返回值为数值向量以及字符向量
double('abcd') = [97 98 99 100]
char('A':'Z') = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
% 字符向量的算数运算与关系运算,运算结果为对应字符Unicode编码值运算
c_1 = 'abc'
c_2 = 'ABC'
c_1 - c_2 == [32 32 32]
char(c_2 + 32) == 'abc'
% 算数运算与关系运算满足兼容模式
c_3 = ['a';'b']
c_1 - c_3 ==
[0 1 2
-1 0 1]
c_1 > c_3 ==
[0 1 1
0 0 1]
-------------------------------------------------------------------------------------------------------------------
% 字符向量的本质还是字符数组,所以字符向量的引用、修改和删除方法与数值数组的方式一致
-------------------------------------------------------------------------------------------------------------------
% 字符向量的拼接(以横向拼接为例)
·[c_1,c_2]
·cat(2,c_1,c_2)
·horzcat(c_1,c_2)
% 字符向量的重复
·repmat(c_3,1,3)
·repelem(c_4,3)
% 字符向量的排序(按照Unicode编码值排序)
sort(c_5)
% 字符向量的翻转
c_6(end:-1:1)
flip(c_6)
fliplr(c_6)
-------------------------------------------------------------------------------------------------------------------
% 字符向量比较(满足兼容模式即可)
c_1 = 'pool'
c_2 = 'moon'
c_1 == c_2 返回逻辑数组[0 1 1 0]
c_3 = '你说过爱你一万年'
ind = (c_3 == '你') ind被赋值为逻辑数组[1 0 0 0 1 0 0 0]
c_4 = 'abc'
c_5 = ['a';'b';'c']
c_4 == c_5 返回逻辑数组
[1 0 0
0 1 0
0 0 1]
% 注意事项
1、使用连续单引号代替单引号
'I'm Li Hua.' ---> 'I''m Li Hua.'
2、换行符
c_new = [c_1,char(10),c_2]
c_new = [c_1,newline,c_2]
3、字符向量的长度
c = 'abcdefg'
numel(c) = 7
length(c) = 7
size(c) = [1 7] size函数会同时返回行数与列数
1、字母大小写转换
c = '我爱MatLab'
d = double(c) 获取字符向量的Unicode编码
ind = d >= 97 & d <= 122 返回逻辑数组,其中记录为小写字母的字符的下标
d(ind) = d(ind) - 32
new_c = char(d)
new_c == '我爱MATLAB'
-------------------------------------------------------------------------------------------------------------------
c = '我爱MatLab'
ind = c >= 97 & c <= 122
c(ind) = char(c(ind)-32)
2、实现strcmp函数
flag = all(size(c_1) == size(c_2)) && ... 判断向量大小是否相等(...表示行的连续)
all(c_1 == c_2) 比较各字符是否相等
3、统计元音字母出现频率
ind = ismember(c,'aeiouAEIOU')
num = sum(ind)
pl = num/numel(c)
-------------------------------------------------------------------------------------------------------------------
Y = 'aeiouAEIOU'
n = numel(c)
num = 0
for i = 1:n
if any(c(i) == Y)
num = num + 1;
end
end
-------------------------------------------------------------------------------------------------------------------
for i = c
if any(i == Y)
num = num + 1;
end
end
-------------------------------------------------------------------------------------------------------------------
Y' == ['a';'e';'i';'o';'u';'A';'E';'I';'O';'U']
c == Y' 返回 8*n 的逻辑数组
any(c == Y') 返回值与 ismember(c,'aeiouAEIOU') 一致
4、凯撒密码加密
c = 'Retreat to the countryside tomorrow morning.';
% 定义映射关系
x = ['A':'Z','a':'z'];
y = ['D':'Z','A':'C','d':'z','a':'c'];
new_c = c;
n = numel(c);
for i = 1:n
% 检查当前字符是否为字母,并进行加密替换
ind = find(new_c(i) == x, 1); % 查找当前字符在x中的位置
if ~isempty(ind) % 如果当前字符是字母
new_c(i) = y(ind); % 则用映射后的字母进行替换
end
end
-------------------------------------------------------------------------------------------------------------------
[ind,d] = ismember(c,x) ind检查是否为字母,d存储字母在x中的索引
new_c(ind) = y(d(ind)) 将原字符向量中的字母替换为加密后字符
-------------------------------------------------------------------------------------------------------------------
offset = 3; % 定义偏移量
for i = 1:numel(c)
if c(i) >= 'A' && c(i) <= 'Z' % 判断当前字符是否为大写字母
new_c(i) = char(mod(c(i) - 'A' + offset, 26) + 'A');
elseif c(i) >= 'a' && c(i) <= 'z' % 判断当前字符是否为小写字母
new_c(i) = char(mod(c(i) - 'a' + offset, 26) + 'a');
end % 对于非字母字符,保持不变
end
5、二进制转换(模数取余法)
n = 60658;
c = ''; % 初始化二进制数为空的字符向量
quotient = n; % 初始化商等于n
while quotient > 0
remainder = mod(quotient, 2); % 除以2的余数
quotient = fix(quotient / 2); % 更新商
c = [num2str(remainder), c]; % 更新c(拼接结果)
end
字符矩阵:
c_1 = ['g','o','o','d';
'f','i','n','e']
-------------------------------------------------------------------------------------------------------------------
c_2 = ['good'; 字符矩阵可以使用字符向量(行向量)来简化书写,本质为矩阵的拼接
'fine']
strcmp(c_1,c_2) == 1
c_2 == vercat('good','fine') == cat(1,'good','fine')
% 矩阵的纵向拼接要求列数相同
% 若不满足纵向拼接的条件,需要手动添加空格
Wrong:c = ['good';
'great']
Right:c = ['good ';
'great']
% 若字符向量过多,手动添加空格过于麻烦,可以使用char函数
char('good','','great','perfect') ==
['good ';
' ';
'great ';
'perfect']
-------------------------------------------------------------------------------------------------------------------
A_1 = [65 66;
67 68]
A_2 = 'abcd'
c = char(A_1,A_2)
c ==
['AB ';
'CD ';
'abcd']
1、二进制回文数
res = '' 初始化空字符向量
for n = 1:100
c = dec2bin(n);
re_c = c(end;-1;1);
if strcmp(c,re_c)
tmp = [num2str(n),': ',c];
res = strvcat(res,tmp); 拼接时自动忽略空行
end
end
disp(res)
-------------------------------------------------------------------------------------------------------------------
res = '' 初始化空字符向量
for n = 1:100
c = dec2bin(n);
re_c = c(end;-1;1);
if strcmp(c,re_c)
tmp = [num2str(n),': ',c];
res = char (res,tmp);
end
end
res(1,:) = [] 手动删除首行
disp(res)
2、九九乘法表
c = ''
for i = 1:9
tmp = ''
for j = 1:i
tmp = [tmp,num2str(j),'x',num2str(i),'=',num2str(i*j),' '];
end
c = char(c,tmp)
end
c(1,:) = []
res = strjust(c,'center') 居中对齐
disp(res)
3、数独
sd = [1 9 4 3 8 5 7 2 6;
8 3 2 7 6 9 4 5 1;
6 5 7 4 2 1 9 3 8;
2 6 9 8 3 7 5 1 4;
5 8 3 1 9 4 6 7 2;
4 7 1 2 5 6 3 8 9;
9 1 5 6 7 2 8 4 3;
3 2 6 5 4 8 1 9 7;
7 4 8 9 1 3 2 6 5];
Condition_1 = all(all(sort(sd,1) == (1:9)')) % 每列是否为1到9的不重复数
Condition_2 = all(all(sort(sd,2) == 1:9)) % 每行是否为1到9的不重复数
c = mat2cell(sd,[3,3,3],[3,3,3]) % 每个九宫格是否为1到9的不重复数
Condition_3 = true;
for i = 1:9
tmp = c{i}; % 第i个宫格对应的3×3的方阵
% tmp(:) 线性索引排序
if ~all(sort(tmp(:)) == (1:9)')
Condition_3 = false;
break
end
end
Condition_3
c ==
['good ';
' ';
'great ';
'perfect']
% 若不想保留末尾空格,可使用以下函数删除
for i = 1:size(c,1)
c_i = c(i,:)
tmp = deblank(c_i)
disp(tmp)
end
-------------------------------------------------------------------------------------------------------------------
strip(c,'left')
strip(c,'right')
strip(c,'both') 默认
strip(c,'both','a') 同时删除两侧的 'a'
% 注意指定字符必须为单字符,不可以为字符向量
-------------------------------------------------------------------------------------------------------------------
strjust(c,'left') 左对齐
strjust(c,'right') 右对齐(默认)
strjust(c,'center') 居中对齐
元胞数组:
用于保存不同大小、不同类型数据
创建:
c =
{1:3, 'abcd';
char('ab','cd','e') 50;
[5 6 7;8 9 0] [60:70]}
% 实际上MatLab将元胞数组中的每个元素视为一个独立的元胞,以便灵活修改而不影响整体结构
-------------------------------------------------------------------------------------------------------------------
cell(row,col)
创建row行col列且数据类型均为空矩阵的元胞数组
-------------------------------------------------------------------------------------------------------------------
嵌套元胞数组
c = {{1:3,'abcd'};
[3 4;5 6]}
索引:
% () 使用小括号索引元胞数组时,返回值为对应位置的元胞数组
c =
{1:3, 'abcd';
char('ab','cd','e') 50;
[5 6 7;8 9 0] [60:70]}
-------------------------------------------------------------------------------------------------------------------
c(1,1) == {1:3}
c(3) == {[5 6 7;8 9 0]} 线性索引
c(2:2:end,:) ==
{char('ab','cd','e') 50} 偶数行元素
c(:) ==
{1:3;
char('ab','cd','e');
[5 6 7;8 9 0];
'abcd';
50;
[60:70]} 按照线性索引的顺序将元胞数组元素重排
% {} 使用大括号索引元胞数组时,返回值为对应元胞中的数据
c{1,1} == [1 2 3]
-------------------------------------------------------------------------------------------------------------------
若使用大括号索引返回值不唯一,MatLab会根据线性索引依次返回
[c_1,c_2] = c{1,:}
c_1 == [1 2 3]
c_2 == 'abcd'
若返回变量数量小于索引的元胞数量,则按线性索引顺序依次返回前序元胞
[c_1,c_2,c_3] = c{1:2,:}
c_1 == [1 2 3]
c_2 == char('ab','cd','e')
c_3 == 'abcd'
-------------------------------------------------------------------------------------------------------------------
使用大括号取出的元胞中的数据可以使用 '[]' 快速进行水平拼接
x = [c{3,:}] 等价于cat(2,c{3,:})或者horzcat(c{3,:})
x ==
[5 6 7 60
8 9 0 70]
% 链式索引
c =
{1:3, 'abcd';
char('ab','cd','e') 50;
[5 6 7;8 9 0] [60:70]}
c{1,1}(1,2) == 2 单个表达式中执行多次索引操作(()-索引必须放到索引表达式的最后)
% 嵌套元胞数组的引用
c = {{1:3,'abcd'};
[3 4;5 6]}
c(1,1) == 返回1x1的元胞数组
{{1:3,'abcd'}}
c{1,1} == 返回1x2的元胞数组
{1:3,'abcd'}
c{1}(2) == {'abcd'}
c{1}{2} == 'abcd'
c{1}{2}([1,end]) == 'ad'
% Tips
C = {A,B} 等价于 {A} {B}
而C(1) == {A} , C{2} == B
student = {'李华',[65 78 90];
'清风',[95 99 93];
'张无忌', [79 88 64];
'苏大强', [54 96 33]}
name = char(student{:,1}) char函数快速拼接元胞数组中的元素
name ==
['李华 '
'清风 '
'张无忌'
'苏大强']
% 显示元胞数组的数据
直接使用disp函数只会返回元胞数组的元素数据类型,想要完全展示数组数据可以使用celldisp函数
cc = {'xyz',{1:3, 'abcd'};
[3,4;5 6],3+2i};
disp(cc)
{'xyz' } {1×2 cell}
{2×2 double} {[3 + 2i]}
celldisp(cc)
cc{1,1} = 'xyz'
cc{2,1} =
[3 4
5 6]
cc{1,2}{1} = [1 2 3]
cc{1,2}{2} = 'abcd'
cc{2,2} = 3 + 2i
拼接:
C1 = {1, 2};
C2 = {'A', 'B'};
C3 = {10, 20};
% [] 中括号拼接
[C1 C2 C3] == {[1]} {[2]} {'A'} {'B'} {[10]} {[20]}
等价于 horzcat(C1,C2,C3) 或者 cat(2,C1,C2,C3)
[C1;C2;C3] %纵向拼接
等价于 vertcat(C1,C2,C3) 或者 cat(1,C1,C2,C3)
% {} 大括号拼接
{C1 C2 C3} == {1×2 cell} {1×2 cell} {1×2 cell} 即 {{1, 2} {'A', 'B'} {10, 20}} 嵌套元胞数组
修改:
% () 小括号修改,使用新的元胞数组代替原元胞
C = {'apple', 'banana';
'pear', 'cherry'};
C(2,1) = {'watermelon'}
-------------------------------------------------------------------------------------------------------------------
% 修改位置超出元胞数组索引,将剩余位置用空元胞填充
C = {'apple', 'banana'};
C(2,1) = {'watermelon'}
% Tips
修改矩阵元素可以超出索引,其余位置用对应空数据填充,但引用矩阵元素必须在索引范围之内
-------------------------------------------------------------------------------------------------------------------
% 元胞数组的修改与其他矩阵一样,只需要满足兼容模式即可
C = {'apple', 'banana';
'pear', 'cherry'};
C(:,1) = {[1,2,3]}
{[1 2 3]} {'banana'}
{[1 2 3]} {'cherry'}
-------------------------------------------------------------------------------------------------------------------
% {} 大括号修改
C = {'apple', 'banana';
'pear', 'cherry'};
C{2,1} = 'watermelon'
C{2,1} = {'watermelon'} 将原位置数据替换为元胞
-------------------------------------------------------------------------------------------------------------------
% 链式索引修改
c = {[5 3 1];
{10,20,[30 40]}}
c{1}([1,3]) = [8,6]
c ==
{[8 3 6 ]}
{1×3 cell}
c{2}{3}(2) = 400;
c{2} == {[10]} {[20]} {[30 400]}
-------------------------------------------------------------------------------------------------------------------
% 使用{}修改数据时,MatLab不支持使用简单赋值语句为多个元素赋值,可以考虑以逗号分隔的列表赋值
C = {'apple', 'banana';
'pear', 'cherry'};
% C{:,1} = 'xyz' 错误
C(:,1) = {'xyz'}
-------------------------------------------------------------------------------------------------------------------
% 逗号分隔的列表赋值
C = {'apple', 'banana';
'pear', 'cherry'};
[C{:,1}] = deal('xyz')
[C{:,1}] 可以视作 [C{1,1},C{2,1}]
删除:
% ()删除(整行、列删除)
C = {'apple', 'banana';
'pear', 'cherry'};
C(2,:) = []
% {}删除(单删除)
C = {'apple', 'banana';
'pear', 'cherry'};
C{2,1} = []
% 若使用{}删除多个数据也要使用逗号分隔的列表
C = {'apple', 'banana';
'pear', 'cherry'};
[C{2,:}] = deal([])
运算:
C = {65,'A',true;
[1 2 3],'xyz','a'}
[r_num,c_num] = size(C) % 分别返回行数与列数
numel(C) % 返回元素总数
length(C) % 返回行数、列数中的较大值
-------------------------------------------------------------------------------------------------------------------
% 以下函数只有元胞数组为字符向量元胞数组(元胞数组中的数据全为字符向量)时才可使用
C1 = {'bc','aca','bc','ab'};
unique(C1)
unique(C1,'stable')
C2 = 'bc';
ismember(C1,C2)
C3 = {'aca','BC','Ab'};
ismember(C3,C1)
% intersect(交集)、union(并集)、setdiff(差集)、setxor(对称差集)
数据类型转换:
% num2cell函数
% 单独转换
a =
1 4 7 10
2 5 8 11
3 6 9 12
num2cell(a)
ans =
3×4 cell 数组
{[1]} {[4]} {[7]} {[10]}
{[2]} {[5]} {[8]} {[11]}
{[3]} {[6]} {[9]} {[12]}
b =
3×4 char 数组
'ADGJ'
'BEHK'
'CFIL'
num2cell(b)
ans =
3×4 cell 数组
{'A'} {'D'} {'G'} {'J'}
{'B'} {'E'} {'H'} {'K'}
{'C'} {'F'} {'I'} {'L'}
-------------------------------------------------------------------------------------------------------------------
% 整行转换
c1 = num2cell(a,1)
celldisp(c1)
c1{1} =
1
2
3
c1{2} =
4
5
6
c1{3} =
7
8
9
c1{4} =
10
11
12
c2 = num2cell(a,2)
c2 =
3×1 cell 数组
{[1 4 7 10]}
{[2 5 8 11]}
{[3 6 9 12]}
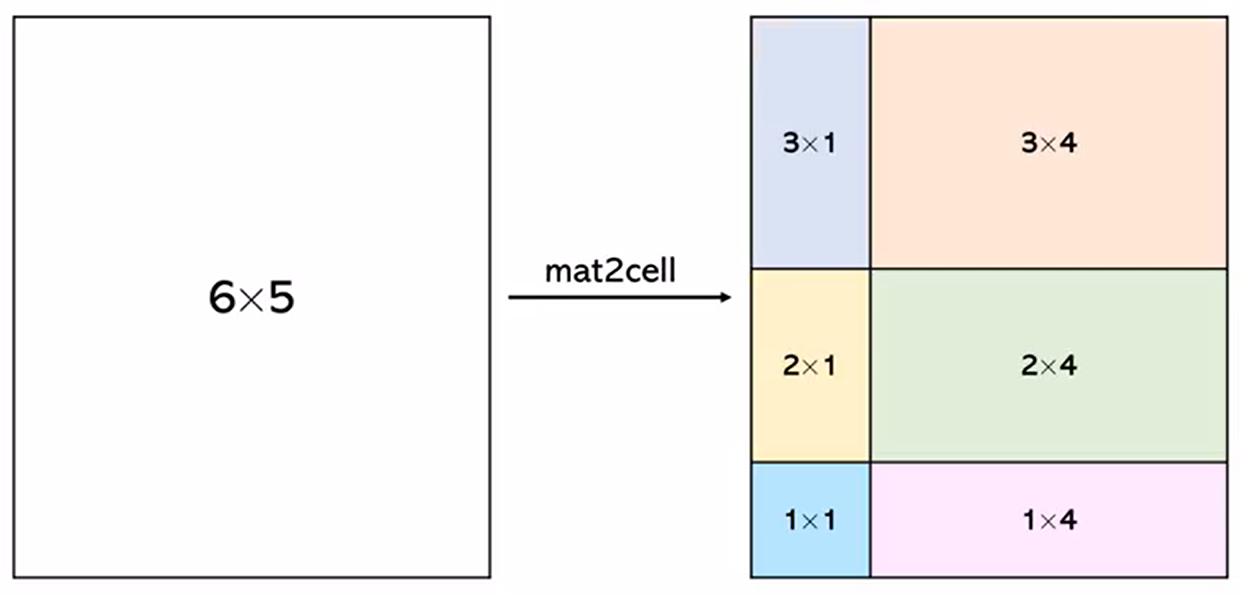
% mat2cell函数
mat2cell 函数可以将矩阵分割为多个大小不同的子块,并将这些子块存储在元胞数组中
A = randi(10,6,5)
r = [3 2 1] 行方向分割为 3 2 1
c = [1 4] 列方向分割为 1 4
cell_A = mat2cell(A,r,c)
-------------------------------------------------------------------------------------------------------------------
mat2cell函数可以代替num2cell函数
c1 = num2cell(a,1)
c1 = mat2cell(a,3,[1 1 1 1])
% cell2mat函数为mat2cell函数的逆函数,作用为将元胞数组转化为数值矩阵
% cellfun函数
C = {[10.48,10.41,10.36];
[11.01,10.86,10.76,10.50];
[10.76,10.58];
[10.49,10.53,10.56]};
n = length(C); % 有几名运动员
best = zeros(n,1); % 初始化最好成绩均为0
for i = 1:n
best(i) = min(C{i});
end
best 计算每名运动员最好成绩
-------------------------------------------------------------------------------------------------------------------
clear;clc
C = {[10.48,10.41,10.36];
[11.01,10.86,10.76,10.50];
[10.76,10.58];
[10.49,10.53,10.56]};
best = cellfun(@min,C)
mean_score = cellfun(@mean,C)
cellfun函数会遍历元胞数组中的每个元胞,将元胞中的数据作为参数传递给func,并将func的返回值串联构成新的数组
% 默认情况下cellfun函数返回值为标量,并将标量串联为新数组
% 如果返回值为向量,则需要使用参数'UniformOutput',此时返回值为元胞数组
sort_score = cellfun(@sort,C,'UniformOutput',false)
% isqual函数
元胞数组不可以使用 '==' 判断是否相等,可以考虑isqual函数
c = {65,65};
d = {'A',65};
isequal(c,d)
当元胞数组大小相等,对应位置元素等效时返回逻辑值1
字符向量元胞数组:
| 函数 | 功能 |
|---|---|
| cellstr | 其他类型文本转换为字符向量元胞数组 |
| isletter | 判断字符是否为字母(或汉字) |
| isspace | 判断字符是否为空白字符(若空格、制表符、换行符) |
| isstrpop | 处理多种类型的文本数据,识别更为广泛的文本形式 |
| strfind | 查找索引 |
| strrep | 将旧文本替换为新文本 |
| strjoin | 将文本进行连接 |
| strsplit | 在指定分隔符处拆分文本 |
| tabulate | 统计数据中各元素出现频率及百分比 |
| strlength | 统计字符串字符数 |
% cellstr函数
cellstr函数在转换的过程中会自动删除字符向量(字符串不会删除)每行末尾的空白字符
a1 = ['abc ',newline,char(9)];
cellstr(a1)
ans =
1×1 cell 数组
{'abc'}
-------------------------------------------------------------------------------------------------------------------
a2 = char('a','123','good')
cellstr(a2)
ans =
3×1 cell 数组
{'a' }
{'123' }
{'good'}
% isletter、isspace函数
isletter函数用于判断字符是否为字母(或汉字),参数通常为字符数组或者字符串标量,若为其他数据类型则直接返回逻辑值0
c1 = char('One is 1;','Ten is 10.');
isletter(c1)
ans =
2×10 logical 数组
1 1 1 0 1 1 0 0 0 0
1 1 1 0 1 1 0 0 0 0
-------------------------------------------------------------------------------------------------------------------
c3 = {'One is 1','Two is 2'};
isletter(c3)
ans =
1×2 logical 数组
0 0
% 此时若想要对元胞数组使用isletter函数可以考虑函数句柄
ind = cellfun(@isletter,c3, ...
'UniformOutput',false)
ind =
1×2 cell 数组
{[1 1 1 0 1 1 0 0]} {[1 1 1 0 1 1 0 0]}
-------------------------------------------------------------------------------------------------------------------
isspace函数用于判断字符是否为空白字符(若空格、制表符、换行符)
c1 = ['春去 ',newline,'秋来 ',...
newline,'你还在。']
size(c1) 1行 12列
isspace(c1)
ans =
1×12 logical 数组
0 0 1 1 0 0 1 1 0 0 0 0
% isstrpop函数
isstrpop函数可以处理多种类型的文本数据(字符数组、字符串标量、数值数组、字符向量元胞数组、字符串数组),并且可以识别更为广泛的文本形式,例如数字、标点、控制字符等
TF = isstrprop(str,category) str参数表示文本数据,category表示需要检测的字符类型
% 若输入str为字符数组、字符串标量、数值数组,输出TF为逻辑数组
% 若输入str为字符向量元胞数组、字符串数组,输出TF为元胞数组
% 末尾增加参数'ForceCellOutput',true 可以强制将返回值转化为元胞数组
c1 = '10月1日是国庆节,今年放7天假。';
isstrprop(c1,'digit')
ans =
1×17 logical 数组
1 1 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0
-------------------------------------------------------------------------------------------------------------------
isstrprop(c1,'digit', ...
'ForceCellOutput',true)
ans =
1×1 cell 数组
{[1 1 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0]}
-------------------------------------------------------------------------------------------------------------------
isstrprop(c1,'alphanum') % 字母与数字
isstrprop(c1,'punct') % 标点
-------------------------------------------------------------------------------------------------------------------
c2 = {'北京小王13288888888';
'15877777777 小李上海';
'小刘13199999999呼和浩特'};
TF = isstrprop(c2,'digit')
num = length(TF); % 客户数量
phone = cell(num,1);
for ii = 1:num
tmp = c2{ii};
phone{ii} = tmp(TF{ii});
end
phone
% strfind函数
k = strfind(str,pat) 在str中搜索出现的pat
str:输入文本,指定为字符串数组、字符向量或字符向量元胞数组
pat:搜索模式,指定为字符串标量、字符向量和pattern标量
k指示str中每次出现的pat的起始索引,若未找到,pat则返回空数组
% 若str为字符向量、字符串标量,输出k为double类型的向量
% 若str为字符向量元胞数组、字符串数组,输出k为double类型的向量元胞数组
c1 = '人要是行,干一行行一行';
strfind(c1,'行')
ans =
4 8 9 11
strfind(c1,'行','ForceCellOutput',true)
ans =
1×1 cell 数组
{[4 8 9 11]}
-------------------------------------------------------------------------------------------------------------------
c2 = 'Are you a youngster?';
strfind(c2,'your')
ans =
[]
c3 = {'How are you?';
'Are you a youngster?';
'You are so beautiful!'};
strfind(c3,'you')
ans =
3×1 cell 数组
{[ 9]}
{[ 5 11]}
{0×0 double}
% strrep、replace函数
newStr = strrep(str,old,new)
str:输入文本,字符串数组、字符向量或字符向量元胞数组
old、new:待替换与替换文本,字符串数组、字符向量或字符向量元胞数组
c1 = '你喜欢我,我也喜欢你!';
strrep(c1,'喜欢','不喜欢')
c3 = {'abcdccd','efcacd','dcace'};
strrep(c3,'c','p')
-------------------------------------------------------------------------------------------------------------------
c4 = '我和你,他和她。';
strrep(c4,{'他';'她'},'Ta') % 分别将'他'和'她'替换为'Ta'
ans =
2×1 cell 数组
{'我和你,Ta和她。'}
{'我和你,他和Ta。'}
strrep(c4,'和',{'与';'爱';'喜欢'}) % 将'和'分别替换为了'与'、'爱'和'喜欢'
ans =
3×1 cell 数组
{'我与你,他与她。' }
{'我爱你,他爱她。' }
{'我喜欢你,他喜欢她。'}
strrep(c4,{'他';'她'},{'ta';'TA'}) % 将'他'和'她'分别替换为了'ta'和'TA'
ans =
2×1 cell 数组
{'我和你,ta和她。'}
{'我和你,他和TA。'}
-------------------------------------------------------------------------------------------------------------------
cc = 'abababab';
strrep(cc,'aba','*') % 替换允许重叠式文本
ans =
'***b'
replace(cc,'aba','*') % 替换不允许重叠式文本
ans =
'*b*b'
-------------------------------------------------------------------------------------------------------------------
c4 = '我和你,他和她。';
replace(c4,{'他';'她'},'Ta')
ans =
'我和你,Ta和Ta。'
% replace(c4,'和',{'与';'爱';'喜欢'}) 错误,替换文本必须为标量或与匹配文本大小一致
replace(c4,{'他';'她'},{'ta';'TA'})
ans =
'我和你,ta和TA。'
% strjion函数
c1 = {'apple','banana','pear'};
strjoin(c1) % 默认使用空格连接 ans = 'apple banana pear'
strjoin(c1,', ') % 指定分隔符为', '
strjoin(c1,newline) % 指定分隔符为换行符
-------------------------------------------------------------------------------------------------------------------
% 若分隔符不止一个,则交错循环使用分隔符
c2 = {'one','three','four'};
strjoin(c2,{' + ',' = '})
ans =
'one + three = four'
c3 = {'今天','明天','每一天'};
strjoin(c3,'\\') % 转义字符
ans =
'今天\明天\每一天'
-------------------------------------------------------------------------------------------------------------------
c = '0\n0';
strjoin({'1','2'},c)
ans =
'10
02'
strjoin({'1','2'},'0\\n0')
ans =
'10\n02'
% strsplit函数
C = sresplit(str,delimiter)
str:字符向量或字符串标量
delimiter:指定分隔符,默认情况为空白字符
% 若分隔符连续出现,MatLab会将其视为一个分隔符
c1 = ['You are great! ', newline, ...
'I salute you.'];
strsplit(c1)
ans =
1×6 cell 数组
{'You'} {'are'} {'great!'} {'I'} {'salute'} {'you.'}
-------------------------------------------------------------------------------------------------------------------
c2 = ' You are great! ';
strsplit(c2)
ans =
1×5 cell 数组
{0×0 char} {'You'} {'are'} {'great!'} {0×0 char}
-------------------------------------------------------------------------------------------------------------------
c4 = 'if,no,,or,,,and';
strsplit(c4,',')
ans =
1×4 cell 数组
{'if'} {'no'} {'or'} {'and'}
-------------------------------------------------------------------------------------------------------------------
c5 = 'bacon, lettuce, and tomato';
strsplit(c5,{', ',', and '})
ans =
1×3 cell 数组
{'bacon'} {'lettuce'} {'and tomato'}
% 多分隔符在delimiter中的顺序无关紧要,除非出现分割点重复的情况
ans =
1×3 cell 数组
{'bacon'} {'lettuce'} {'tomato'}
-------------------------------------------------------------------------------------------------------------------
% c6 = {'abc,def','ghi,jkl'}; 错误,输入为字符向量或字符串标量
% strsplit(c6,',')
-------------------------------------------------------------------------------------------------------------------
cc = 'if,no,,or,,,and';
strsplit(cc,',','CollapseDelimiters',false) % 将连续分隔符当做单个分隔符处理
ans =
1×7 cell 数组
{'if'} {'no'} {0×0 char} {'or'} {0×0 char} {0×0 char} {'and'}
% tabulate函数
tabulate(x) 显示向量x中数据的频数表,对于x中每个唯一值,tabulate函数显示该值在x中的实例数与百分比
当x为数值时,tbl = tabulate(x) 以数值矩阵的形式返回频数表tbl,否则以元胞数组的形式返回
-------------------------------------------------------------------------------------------------------------------
x1 = randi([-5,3],1,6)
x1 =
2 3 -4 3 0 -5
t1 = tabulate(x1)
t1 =
-5 1 16.67
-4 1 16.67
0 1 16.67
2 1 16.67
3 2 33.33
-------------------------------------------------------------------------------------------------------------------
x2 = {'yes','no','yes','yes','and'};
t2 = tabulate(x2)
t2 =
3×3 cell 数组
{'yes'} {[3]} {[60]}
{'no' } {[1]} {[20]}
{'and'} {[1]} {[20]}
-------------------------------------------------------------------------------------------------------------------
% 若向量x中只包含正整数,则tabulate将为 1-max(x) 之间未出现数据返回计数 0
x3 = [5 2 4 4 5 5];
t3 = tabulate(x3)
t3 =
1 0 0
2 1 16.67
3 0 0
4 2 33.33
5 3 50
% 解决方案
tabulate(string(x3))
tabulate(categorical(x3))
-------------------------------------------------------------------------------------------------------------------
% 自实现tabulate函数
x = {'yes','no','yes','yes','and','no','or'};
% 使用unique函数找出x中的唯一值,同时获得每个元素在唯一值数组中的索引ind
[Value, ~, ind] = unique(x,'stable') % 加'stable'保持原文本出现的先后顺序
Count = sum(ind == 1:length(Value)) % 统计每个唯一值在x中出现的次数
Percent = Count/sum(Count)*100 % 计算每个唯一值出现的百分比
t = cell(length(Value),3) % 初始化元胞数组用于保存最终结果
% 将Value、Count和Percent的值分别填充到元胞数组t的相应位置
t(:,1) = Value % 第一列保存唯一值(这里无需对Value转置,大小匹配即可)
t(:,2) = num2cell(Count) % 第二列保存各值计数
t(:,3) = num2cell(Percent) % 第三列保存各值百分比
disp(t) % 输出结果t
字符串数组:
创建:
% 字符串创建 ———— " "
单个字符串又称字符串标量,字符串标量需要视作为整体,大小为 1x1
s1 = "你真棒!"
size(s1)
ans =
1 1
c1 = 'good'; % 字符向量
size(c1)
ans =
1 4
-------------------------------------------------------------------------------------------------------------------
s2 = "" % 空字符串
size(s2)
ans =
1 1
c2 = '' % 空字符向量
size(c2)
ans =
0 0
-------------------------------------------------------------------------------------------------------------------
% 字符串数组创建
由于单个字符串为标量,为此,字符串数组的使用方式与数值数组一致
s3 = ["good","great","perfect"]
s3 =
1×3 string 数组
"good" "great" "perfect"
s33 = ['good','great','perfect']
s33 =
'goodgreatperfect'
-------------------------------------------------------------------------------------------------------------------
% strings函数——创建空字符串数组
ss1 = strings(2,3)
ss1 =
2×3 string 数组
"" "" ""
"" "" ""
-------------------------------------------------------------------------------------------------------------------
% string函数——将其他数据类型转换为字符串数组
c1 = '你好呀'; % 字符向量
string(c1)
ans =
"你好呀"
c2 = char('good','great'); % 字符矩阵
s2 = string(c2)
s2 =
2×1 string 数组
"good "
"great"
% strip、strtrim或deblank函数都可以应用于字符串数组
c3 = {'good','great'}; % 字符向量元胞数组
s3 = string(c3)
s3 =
1×2 string 数组
"good" "great"
x1 = ([3 6 7 5] > 5)
s1 = string(x1)
s1 =
1×4 string 数组
"false" "true" "true" "false"
x2 = 1:15; % 数值数组转换为字符串数组
s2 = string(x2)
% 文本转化为数值矩阵
% str2num函数
c1 = '1.5 4.3 6.5';
str2num(c1)
ans =
1.5 4.3 6.5
c2 = num2str(rand(2,3))
str2num(c2)
ans =
0.81472 0.12699 0.63236
0.90579 0.91338 0.09754
% 无法解析输入参数时返回空向量
c3 = '1、2、3';
str2num(c3)
ans =
[]
% 函数可用于字符串标量的转换,不支持字符串数组
s1 = "1,2,3"; % MATLAB高版本才能运行,低版本会报错
str2num(s1)
s2 = ["1", "5 6"];
% str2num(s2) Wrong
% str2num函数参数中可以包含表达式
cc = char('3 3*5 6/4', ...
' pi exp(3) sin(pi/2)')
str2num(cc)
ans =
3 15 1.5
3.14 20.08 1
% str2num双返回值
[x1,tf1] = str2num('1,2,3') 转换成功,tf为逻辑值1
[x2,tf2] = str2num('1、2、3') 转换失败,tf为逻辑值0
------------------------------------------------------------------------------------------------------------------
% double函数
c = char('abc','defg');
double(c)
ans =
97 98 99 32
100 101 102 103
% 将字符串数组转换为对应数值数组,单个字符串标量中仅能包含单个数字
s1 = "1 2 3";
double(s1)
ans =
NaN
s2 = string(rand(2,3))
double(s2)
ans =
0.2785 0.9575 0.15761
0.5468 0.9648 0.97059
s3 = ["1.3e4","-688","a","1,3"];
double(s3)
ans =
13000 -688 NaN NaN
% 不支持参数存在表达式
s4 = ["pi", "3.14", "1+1";
"a", "6", "666"];
double(s4)
ans =
NaN 3.14 NaN
NaN 6 666
------------------------------------------------------------------------------------------------------------------
% str2double函数
c1 = '31,050'; str2double函数可以处理千位分隔符
str2double(c1)
ans =
31050
c2 = '1\2\3';
str2double(c2)
ans =
NaN
c2 = '1+1';
str2double(c2)
ans =
NaN
% 当转换的字符数组包含多个数值时,函数会尝试将结果按照线性索引的方式拼接为数值标量,而不是返回数值矩阵
c3 = '1,2,3'; % 逗号隔开
str2double(c3)
ans =
123
c4 = ['1';'2';'3']; % 列字符向量
str2double(c4)
ans =
123
c5 = ['1234';
'5678'];
str2double(c5) % 按照线性索引的顺序转换
ans =
15263748
% 将字符向量元胞数组转换为数值矩阵
c = {'1.2','3.5';'xyz','8.8'};
str2double(c)
ans =
1.2 3.5
NaN 8.8
% 将字符串数组转换为数值数组
s = ["pi", "3.14", "1+1";
"a", "6", "666"];
str2double(s)
ans =
NaN 3.14 NaN
NaN 6 666
% 混合创建字符串数组,创建时至少含有一个字符串类型
s1 = ["abc",'ab',100]
s1 =
1×3 string 数组
"abc" "ab" "100"
s2 = [1,2,3;"yes",true,"no"]
s2 =
2×3 string 数组
"1" "2" "3"
"yes" "true" "no"
s3 = [{'你好','我好'},"大家好"]
s3 =
1×3 string 数组
"你好" "我好" "大家好"
s4 = [char('a','bc');"defg"]
s4 =
3×1 string 数组
"a "
"bc"
"defg"
% s5 = [{'你好','我好'}; "大家好"] 大小不兼容,创建失败
% 统计字符串长度(即包含字符数量)
s1 = "Hello,你好!";
strlength(s1)
ans =
9
s2 = ["yes", "no", "sorry";
"or", "if", "good"];
strlength(s2)
ans =
3 2 5
2 2 4
c1 = 'a':'z'
strlength(c1)
ans =
26
c2 = {'abc','','3*4=5';
newline,'1234',char(0)};
strlength(c2)
ans =
3 0 5
1 4 1
引用:
% ()索引返回字符串、字符串数组
s1 = ["1一","5五","9九";
"2二","6六","10十";
"3三","7七","11十一";
"4四","8八","12十二"]
------------------------------------------------------------------------------------------------------------------
s1(3,2) 行列索引
s1(7) 线性索引
s1(2:2:end,:) % 偶数行
ans =
2×3 string 数组
"2二" "6六" "10十"
"4四" "8八" "12十二"
------------------------------------------------------------------------------------------------------------------
% {}索引返回字符向量
s1{3,2}
[a,b,c] = s1{1,:}
% 将返回的字符向量进行水平拼接
[s1{1,:}]
ans =
'1一5五9九'
% 将返回的字符向量保存到字符矩阵
char(s1{1,:})
ans =
3×2 char 数组
'1一'
'5五'
'9九'
------------------------------------------------------------------------------------------------------------------
% 链式索引
c = s1{end}(1:2)
c =
'12'
% 反转字符向量中的字符顺序
c1 = 'abcdefg';
c1(end:-1:1)
% 亦可以使用fliplr(c1)、flip(c1)
------------------------------------------------------------------------------------------------------------------
% 反转字符串中的字符顺序
s1 = "abcdefg";
string(s1{1}(end:-1:1)) 先转换为字符向量,反转后再换回字符串
------------------------------------------------------------------------------------------------------------------
% 反转字符串数组中的字符顺序
s2 = ["你好","我好";
"大家好","12345"];
% 初始化和s2相同大小的字符串数组ss保存结果
ss = strings(size(s2))
for ii = 1:numel(s3)
ss(ii) = string(s3{ii}(end:-1:1));
end
ss
------------------------------------------------------------------------------------------------------------------
% reverse函数
reverse({'abcde','12345'})
ans =
1×2 cell 数组
{'edcba'} {'54321'}
修改与删除:
% ()修改,等号右边的值可以为字符串、字符向量或字符向量元胞数组,只需保证大小兼容即可
s1 = ["abc", "ABC";
"清风","老师"];
s1(2,2) = "弟弟"
s1(2,:) = {'666';'888'}
s1 =
2×2 string 数组
"abc" "ABC"
"666" "888"
s1(1,:) = '可爱'
s1 =
2×2 string 数组
"可爱" "可爱"
"666" "888"
------------------------------------------------------------------------------------------------------------------
% {}修改,等号右边只能为字符向量
s1 = ["abc", "ABC";
"清风","老师"];
% s1{2,2} = "弟弟"
s1{2,2} = '弟弟'
------------------------------------------------------------------------------------------------------------------
% ()删除,改变元素数量
s2 = ["ab","cd","ef";
"gh","ij","kl";
"mn","op","qr";
"st","uv","wx"];
s2([1,4],:) = []
s2 =
2×3 string 数组
"gh" "ij" "kl"
"mn" "op" "qr"
% 若不是整行、整列删除,返回值为按照线性索引排列的行向量
s2 =
1×5 string 数组
"gh" "mn" "ij" "kl" "qr"
------------------------------------------------------------------------------------------------------------------
% {}大括号删除,删除位置使用缺失值代替
s2{2} = []
s2 =
1×5 string 数组
"gh" <missing> "ij" "kl" "qr"
% 使用加号(+)连接字符串数组
s1 = ["李","王","张"]; % 姓
s2 = ["一诺","泽","若汐"]; % 名
s1 + s2
ans =
1×3 string 数组
"李一诺" "王泽" "张若汐"
------------------------------------------------------------------------------------------------------------------
% 支持算术运算的五种兼容模式
s1 + s2'
ans =
3×3 string 数组
"李一诺" "王一诺" "张一诺"
"李泽" "王泽" "张泽"
"李若汐" "王若汐" "张若汐"
------------------------------------------------------------------------------------------------------------------
% 与字符向量进行运算
s1 + '清风'
ans =
1×3 string 数组
"李清风" "王清风" "张清风"
------------------------------------------------------------------------------------------------------------------
% 与字符向量元胞数组进行运算
s1 + {'lj','jk','zq'}
ans =
1×3 string 数组
"李lj" "王jk" "张zq"
------------------------------------------------------------------------------------------------------------------
% 与数值数组进行运算
s1 + [1,2,3]
ans =
1×3 string 数组
"李1" "王2" "张3"
% 注意运算优先级问题
% s1 + 1:3
s1 + (1:3)
------------------------------------------------------------------------------------------------------------------
% 随机生成新生儿姓名
s1与s2分别表示姓氏与名字,请从姓、名中分别提取两两组合,生成所有可能情况
s1 = "1王 2李 3张 4刘 5陈 6杨 7黄 8周 9胡 10赵";
s2 = "辰、瑞、泽、伊、一、若汐、一诺、艺涵、奕辰、宇泽、浩然、奕泽";
s1{:}
ans =
'1王 2李 3张 4刘 5陈 6杨 7黄 8周 9胡 10赵'
s1 = s1{:}(isletter(s1)) 提取s1中的所有姓氏
s1 = string(s1')
s2 = strsplit(s2,'、')
s2 =
1×12 string 数组
"辰" "瑞" "泽" "伊" "一" "若汐" "一诺" "艺涵" "奕辰" "宇泽" "浩然" "奕泽"
name = s1 + s2
ind = randperm(numel(name),10) 随机获取10个索引
name_10 = name(ind) 通过线性索引随机获取10个姓名
拼接:
s1 = ["ab", "cd"];
s2 = ["ef", "gh"];
[s1,s2]
% [s1 s2]
% 等价于horzcat(s1,s2)或cat(2,s1,s2)
% 对于非字符串类型的数据MatLab会自动转化为字符串类型
[s1;[66 88]]
ans =
2×2 string 数组
"ab" "cd"
"66" "88"
重构:
s = string(1:12)
reshape(s,3,4)
% reshape(s,[],4)
% reshape(s,3,[])
% reshape(s,[3,4])
重复:
s = ["a", "b"];
repmat(s,3,2)
ans =
3×4 string 数组
"a" "b" "a" "b"
"a" "b" "a" "b"
"a" "b" "a" "b"
repelem(s,[2,3])
ans =
1×5 string 数组
"a" "a" "b" "b" "b"
排序:
% 使用sort函数排序时,默认按照Unicode编码升序排序,unicode编码一致时按照长短排序
s = ["aa","A","ab"," z","ac","123","Bc","ba","bad","abc"];
[sort_s, ind] = sort(s)
sort_s =
1×10 string 数组
" z" "123" "A" "Bc" "aa" "ab" "abc" "ac" "ba" "bad"
ind =
4 6 2 7 1 3 10 5 8 9
------------------------------------------------------------------------------------------------------------------
重构随机字符矩阵
% 定义字符集
c = 'abcd';
% 生成1到4随机索引,总共需要4*3*2个随机数
ind = randi([1, 4], 1, 4 * 3 * 2);
% 根据索引从字符集中选取字符,生成字符数组,并将其重塑为两列的矩阵
cc = reshape(c(ind), [], 2);
% 将字符矩阵转换为字符串数组,并重塑为4行3列的矩阵形式
s = reshape(string(cc), 4, 3)
s =
4×3 string 数组
"dd" "cb" "dc"
"db" "ad" "da"
"ad" "bd" "ad"
"da" "cd" "dd"
sortrows(s,[1,2],{'ascend','descend'}) 基于首列升序,首列相同基于次列降序排序
关系运算:
s = ["ab","cd","b";
"Ab","ce","cc";
"c","cd","def"];
s == "ab"
ans =
3×3 logical 数组
1 0 0
0 0 0
0 0 0
strcmpi(s,"ab") % 不区分大小写
strncmp(s,"c",1) % 仅比较前n个字符
------------------------------------------------------------------------------------------------------------------
% 关系运算符满足兼容模式,strcmp函数并不满足
s == ["c","cd","ccc"]
ans =
3×3 logical 数组
0 1 0
0 0 0
1 1 0
------------------------------------------------------------------------------------------------------------------
students = ["张三", "李四", "王五", "赵六"];
grades = ["A", "B", "C", "A"];
% 找出获得A等级的学生
A_students = students(grades == "A")
% 找出获得A或B等级的学生
AB_students = students(grades == "A" | grades == "B" )
集合运算:
% unique函数——返回唯一值
s1 = ["Ac", "ab", "aa","ab","Ab","a"];
unique(s1)
ans =
1×5 string 数组
"Ab" "Ac" "a" "aa" "ab"
unique(s1,'stable')
------------------------------------------------------------------------------------------------------------------
% ismember函数
s2 = ["Aa", "Ab", "aa"];
ismember(s1, s2) 判断s1中元素是否存在于s2中
ans =
1×6 logical 数组
0 0 1 0 1 0
------------------------------------------------------------------------------------------------------------------
% intersect() 交集
% union() 并集
% setdiff() 差集
% setxor() 对称差集
常用函数:
| 函数 | 功能 |
|---|---|
| pad | 添加前导或尾随字符 |
| join | 按照指定维度拼接字符串数组 |
| split | 指定位置拆分文本 |
| replaceBetween | 在指定区间替换文本 |
| insertAfter/Before | 指定位置插入文本 |
| extractBetween/After/Before | 提取指定位置字符 |
| erase | 删除指定文本 |
| contains | 查找字符串特定模式 |
% pad函数
s = ["abcdefg";
"hij ";
"kl "];
strjust(s) % 默认右对齐,即将所有空格移向左边
pad(s) % 默认情况在末尾添加空格使得所有字符串长度相同
ans =
3×1 string 数组
"abcdefg"
"hij "
"kl "
------------------------------------------------------------------------------------------------------------------
% 指定字符串总长度
newStr = pad(str,numberOFCharacters)
s = ["33";
"666";
"8888"];
pad(s,10)
ans =
3×1 string 数组
"33 "
"666 "
"8888 "
------------------------------------------------------------------------------------------------------------------
% 指定字符添加方式
newStr = pad(str,side)
side 取值为 'left' 'right' 'both'
s = ["1";
"111";
"11111";
"1111111"];
pad(s,'both')
ans =
4×1 string 数组
" 1 "
" 111 "
" 11111 "
"1111111"
pad(s,15,'both')
ans =
4×1 string 数组
" 1 "
" 111 "
" 11111 "
" 1111111 "
------------------------------------------------------------------------------------------------------------------
% 指定添加字符(此参数只能位于末尾)
pad(s,'*')
pad(s,'both','*')
ans =
4×1 string 数组
"***1***"
"**111**"
"*11111*"
"1111111"
% join函数
s = ["ab","cd";
"Ab","ce";
"c","cd"];
strjoin(s)
ans = "ab Ab c cd ce cd"
join(s) 默认情况沿着列方向从左往右添加空格进行拼接
ans =
3×1 string 数组
"ab cd"
"Ab ce"
"c cd"
join(s,1) 指定沿着行方向从上向下拼接
ans =
1×2 string 数组
"ab Ab c" "cd ce cd"
------------------------------------------------------------------------------------------------------------------
% 指定拼接字符
join(s,', ',2)
ans =
3×1 string 数组
"ab, cd"
"Ab, ce"
"c, cd"
join(s,', ',1)
ans =
1×2 string 数组
"ab, Ab, c" "cd, ce, cd"
------------------------------------------------------------------------------------------------------------------
% 对于 1xN 或者 Nx1 的字符串向量,strjion函数与join函数的效果相同
% 但对于 1xN 或者 Nx1 的字符向量元胞数组,两函数返回值数据类型有所差异
s = ["ab","cd","Ab","ce"];
cs = cellstr(s)
strjoin(cs)
ans =
'ab cd Ab ce'
join(cs)
ans =
1×1 cell 数组
{'ab cd Ab ce'}
% split函数
split函数参数为字符向量返回值为字符向量元胞数组,参数为字符串标量返回值为字符串数组
c1 = ['a b c',newline,' d'];
strsplit(c1)
ans =
1×4 cell 数组
{'a'} {'b'} {'c'} {'d'}
split(c1) 默认分隔符也为空白字符,返回列向量
ans =
4×1 cell 数组
{'a'}
{'b'}
{'c'}
{'d'}
------------------------------------------------------------------------------------------------------------------
s1 = string(c1);
strsplit(s1)
ans =
1×4 string 数组
"a" "b" "c" "d"
ans =
4×1 string 数组
"a"
"b"
"c"
"d"
------------------------------------------------------------------------------------------------------------------
% 处理连续分隔符
s2 = "abbc";
strsplit(s2,'b') % 指定分隔符为'b'
ans =
1×2 string 数组
"a" "c"
strsplit(s2,'b','CollapseDelimiters',false)
ans =
1×3 string 数组
"a" "" "c"
split(s2,'b')
ans =
3×1 string 数组
"a"
""
"c"
------------------------------------------------------------------------------------------------------------------
% 指定多分隔符
s = "Oh, what a beautiful day!";
split(s,[" ",",","!"])
ans =
7×1 string 数组
"Oh"
""
"what"
"a"
"beautiful"
"day"
""
strsplit(s,[" ",",","!"])
ans =
1×6 string 数组
"Oh" "what" "a" "beautiful" "day" ""
------------------------------------------------------------------------------------------------------------------
% 拆分多维字符串数组与字符向量元胞数组
strsplit函数参数只能为字符向量或者字符串标量
s = ["Mary Butler";
"Santiago Marquez";
"Diana Lee"];
split(s)
ans =
3×2 string 数组
"Mary" "Butler"
"Santiago" "Marquez"
"Diana" "Lee"
% 对于拆分之后无法组合成完整数组的字符串数组使用split函数仍会报错,此时可以使用循环将各行拆分结果保留在元胞数组中
s = ["Mary Butler Abc";
"Santiago Marquez";
"Diana Lee"];
c = cell(size(s));
for ii = 1:numel(s)
tmp = s(ii);
c{ii} = split(tmp);
% c{ii} = strsplit(tmp);
end
c
------------------------------------------------------------------------------------------------------------------
% splitlines函数
固定分隔符为换行符,等价于split(s,newline)
% replaceBetween函数
str = "ABCDEFGHIJ";
replaceBetween(str,"C","G","*")
% 或者写成
replaceBetween(str,"BC","G","*")
replaceBetween(str,4,6,"*")
ans =
"ABC*GHIJ"
------------------------------------------------------------------------------------------------------------------
s = ["great","good","perfect"];
n = strlength(s);
replaceBetween(s,n-1,n,"**")
ans =
1×3 string 数组
"gre**" "go**" "perfe**"
------------------------------------------------------------------------------------------------------------------
% 边界处理
str = "ABCDEFGHIJABCDEFGHIJ";
replaceBetween(str,"C","G","*",'Boundaries','inclusive') 包含边界全部替换
str = "ABCDEFGHIJABCDEFGHIJ";
replaceBetween(str,4,6,"*",'Boundaries','exclusive') 不包含边界替换
------------------------------------------------------------------------------------------------------------------
% 多参数替换
str = ["Edgar Allen Poe";
"Louisa May Alcott"];
newText = ["A.";"M."];
replaceBetween(str,[7;8],[11;10],newText) 将文本的 7-11、 8-10 分别替换为"A."、"M."
% insertAfter/Before函数
s = ["香蕉(3)";
"苹果(6)";
"菠萝蜜(10)"];
s1 = insertAfter(s,"(","价格:")
s2 = insertBefore(s1,")","元/斤")
s2 =
3×1 string 数组
"香蕉(价格:3元/斤)"
"苹果(价格:6元/斤)"
"菠萝蜜(价格:10元/斤)"
------------------------------------------------------------------------------------------------------------------
% 或者利用索引插入
s = ["abcd","efgh"];
insertAfter(s,2,".")
% 等价于 insertBefore(s,3,".")
s = ["aaa","a12345"];
insertAfter(s,strlength(s),".txt") % 等价于直接计算 s + ".txt"
------------------------------------------------------------------------------------------------------------------
% 格式化输出(加号、等号前后添加空格)
s = ["1+1=2";
"2+2=4"];
% insertAfter(s,["+","="]," ")
% insertBefore(s,["+","="]," ")
tmp = ["+","="];
for ii = 1:numel(tmp)
s = insertAfter(s,tmp(ii)," ");
s = insertBefore(s,tmp(ii)," ");
end
s =
2×1 string 数组
"1 + 1 = 2"
"2 + 2 = 4"
% extractBetween函数
str = "ABCDEFGHIJAB12345IJ";
extractBetween(str,"AB","I")
ans =
2×1 string 数组
"CDEFGH"
"12345"
extractBetween(str,"AB","I", ...
'Boundaries','inclusive') 强制包含边界
ans =
2×1 string 数组
"ABCDEFGHI"
"AB12345I"
extractBetween(str,3,5)
ans =
"CDE"
str = ["Edgar Allen Poe";
"Louisa May Alcott"];
extractBetween(str,[7;8],[11;10])
ans =
2×1 string 数组
"Allen"
"May"
------------------------------------------------------------------------------------------------------------------
% extractAfter/Before函数
提取指定位置之后、之前所有元素
str = "ABCDEFGHIJAB12345IJ";
extractAfter(str,"A")
ans =
"BCDEFGHIJAB12345IJ"
extractBefore(str,3)
ans =
"AB"
str = ["abcde","fghijklmn"];
% 提取最后两个字符
extractAfter(str,strlength(str)-2)
ans =
1×2 string 数组
"de" "mn"
% 若分隔点出现多次,extractAfter/Before函数会以首个分隔符为准
s = ["2023/3/4 7℃";
"2024/4/16 19℃"
"2025/12/28 -5℃"]
day = extractBetween(s,"/"," ")
day =
3×1 string 数组
"3/4"
"4/16"
"12/28"
% erase函数
str = "good mood omg";
erase(str,"o")
ans =
"gd md mg"
erase(str,["o"," "])
ans =
"gdmdmg"
% 注意删除关键字的顺序
str = ["射雕英雄传.txt";
"鹿鼎记.docx";
"倚天屠龙记.doc";
"天龙八部.txt"];
erase(str,[".","txt","docx","doc"])
% eraseBetween函数
str = "abcdefg ab12345fghi";
eraseBetween(str,"b","f")
ans =
"abfg abfghi"
str = "<html><body><h1>Hello," + ...
" World!</h1></body></html>";
eraseBetween(str, "<", ">", ...
'Boundaries','inclusive')
ans =
"Hello, World!"
% contains函数
str = ["abcDe","aaccef","ad"];
contains(str,"d")
ans =
1×3 logical 数组
0 0 1
contains(str,["f","d"], ...
'IgnoreCase',true) 名称值参数——忽略大小写
ans =
1×3 logical 数组
1 1 1
files = ["image.png", "aaa.txt",...
"data.csv", "bbb.txt"];
ind = contains(files, ".txt")
ind =
1×4 logical 数组
0 1 0 1
% 返回所有以 ".txt" 结尾的文件名
txtFiles = files(ind)
s = ["永远18岁";
"今天天气很好!";
"你好,886!";
"Hi,520"];
ss = string(0:9);
contains(s,ss)
------------------------------------------------------------------------------------------------------------------
% count函数——统计出现频次
str = ["red green blue";
"green red blue green blue"];
count(str,"blue")
ans =
1
2
count(str,["red","blue"])
ans =
2
3
str = "abababab";
count(str,"aba") 不允许重叠制文本
ans =
2
s = ["永远18岁";
"今天天气很好!";
"你好,886!";
"Hi,520-1314"];
ss = string(0:9);
count(s,ss)
ans =
2
0
3
7
------------------------------------------------------------------------------------------------------------------
% starts/endsWith函数
str = ["刘诗诗","杨幂","刘亦菲"];
startsWith(str,"刘") 判断是否以"刘"开头
ans =
1×3 logical 数组
1 0 1
str = ["aa.png","bb.jpg","cc.txt"];
endsWith(str,[".jpg",".png"]) 判断是否以".jpg",".png"结尾
ans =
1×3 logical 数组
1 1 0
文本数据处理进阶篇:
文本格式化:
| 函数 | 作用 |
|---|---|
| sprintf | 解析转义字符与执行格式化文本操作 |
| compose | 符号计算与文本格式化 |
% sprintf函数
% 解析转义字符
c = '春眠不觉晓,\n处处闻啼鸟。'
c1 = sprintf(c)
c1 =
'春眠不觉晓,
处处闻啼鸟。'
s = "姓名\t年级\t电话"
s1 = sprintf(s)
s1 =
"姓名 年级 电话"
% 注意输入参数只能为字符向量或者字符串标量
% 执行格式化文本操作(数字精度、对齐方式、字段宽度)
% %d、%i:格式化整数
sprintf('%d',110)
sprintf('我有%d岁。\n你呢?',18)
year = 2011;
month = 3;
day = 21;
sprintf("张无忌的生日:\n%d年%d月%d日", year,month,day)
% 对于非整数,则会自动转换为科学计数法
sprintf('%d',123.45)
ans =
'1.234500e+02'
------------------------------------------------------------------------------------------------------------------
% %f:以定点记数法格式化数据
sprintf('小王100米纪录为%fs',12.68) % 默认保留6位小数
ans =
'小王100米纪录为12.680000s'
sprintf('圆周率=%f',pi) % 自动四舍五入
ans =
'圆周率=3.141593'
sprintf('%f',0.00000001)
ans =
'0.000000'
sprintf('圆周率pi=%.2f',pi) % 保留2位小数
sprintf('圆周率pi=%.3f',pi) % 保留3位小数
------------------------------------------------------------------------------------------------------------------
% %e:以科学记数法格式化数据
sprintf('%e',1234)
ans =
'1.234000e+03'
d = 0.0123;
sprintf('%f的科学计数法为%e',d,d)
ans =
'0.012300的科学计数法为1.230000e-02'
------------------------------------------------------------------------------------------------------------------
% %s:格式化文本数据
sprintf('%s','你好呀')
sprintf('%s%s',"你好呀",'小王')
student = '小王';
age = 3;
sprintf('%s今年%d岁啦',student,age)
% 若由正整数构成数组,则会转换成对应的字符
sprintf('%s',65:70)
ans =
'ABCDEF'
% 若指定不恰当的数值类型,会自动改为使用%e
sprintf('%s',123.45)
------------------------------------------------------------------------------------------------------------------
% 错误使用格式化操作符
d = 101
[s2,errmsg2] = sprintf('这是%p呀!', d)
s2 =
'这是'
errmsg2 =
'格式无效。'
------------------------------------------------------------------------------------------------------------------
% 非标量元素处理-按线性索引顺序格式化文本
s = ["Alice", "Bob", "Charlie"];
sprintf('学生: %s\n', s)
ans =
'学生: Alice
学生: Bob
学生: Charlie'
s = ["清风","小王呀"];
sprintf('学生%s、%s。',s)
ans =
'学生清风、小王呀。'
s1 = ["a","b","c"];
s2 = ["d","e"]; % 元素缺少
sprintf('字母%s和%s、',s1,s2)
ans =
'字母a和b、字母c和d、字母e和'
------------------------------------------------------------------------------------------------------------------
% 特殊字符处理
sprintf('她说''%s''','你好')
ans =
'她说'你好''
sprintf('1\\%d\\3',2)
ans =
'1\2\3'
sprintf('今年GDP增长了%f%%.',6.56)
ans =
'今年GDP增长了6.560000%.' % 双百分号代表真正百分号
------------------------------------------------------------------------------------------------------------------
% 精度
% %.nf、%.ne指定保留n位小数
sprintf('体重降低了%.2f%%',12.689)
ans =
'体重降低了12.69%'
sprintf('%.4e',0.01234567)
ans =
'1.2346e-02'
------------------------------------------------------------------------------------------------------------------
% 字段宽度(参数置于百分号与格式化操作符之间)
sprintf('绩点%5.2f',3.4)
ans =
'绩点 3.40'
sprintf('成绩%3d\n',[8 39 100])
ans =
'成绩 8
成绩 39
成绩100'
------------------------------------------------------------------------------------------------------------------
% 标志
% '-'左对齐标志
sprintf('绩点%-5.2f',3.4) % 宽度为5
ans =
'绩点3.40 '
sprintf('成绩%-3d\n',[8 39 100])
ans =
'成绩8
成绩39
成绩100'
% '+'始终显示符号标志
sprintf('%+d', 100)
ans =
'+100'
sprintf('%+5d', 100)
ans =
' +100'
sprintf('%-+6d', 100)
ans =
'+100 '
% '0'补零以填充字段宽度标志
sprintf('%04d',13)
ans =
'0013'
sprintf('%0+5d',13)
ans =
'+0013'
% compose函数
sprintf('%d月',1:3)
ans =
'1月2月3月'
compose('%d月',1:3) % 字符向量类型
ans =
1×3 cell 数组
{'1月'} {'2月'} {'3月'}
compose("%d月",1:3) % 字符串类型
ans =
1×3 string 数组
"1月" "2月" "3月"
------------------------------------------------------------------------------------------------------------------
% 非标量元素处理
x = [1;2;3];
y = [1;4;9];
sprintf("%d的平方是%d",x,y) % 注意参数类型为列向量
ans =
"1的平方是23的平方是14的平方是9"
compose("%d的平方是%d",x,y)
ans =
3×1 string 数组
"1的平方是1"
"2的平方是4"
"3的平方是9"
文本数据导入:
% fileread函数
filename1 = '测试的文本.txt';
% 尽量将文件名定义为字符向量类型
c = fileread(filename1)
c =
'这是大家读取的第一个文本文件中的内容喔!
本文件由数学建模清风老师于2024年1月18日创建!
现在的时间是什么时候呢?'
------------------------------------------------------------------------------------------------------------------
% 使用绝对路径导入
filename2 = 'F:\BaiduSyncdisk\matlab课程\分章word\第6章配套代码\测试的文本.txt';
c = fileread(filename2)
------------------------------------------------------------------------------------------------------------------
% 使用相对路径导入
cd('F:\BaiduSyncdisk\matlab课程\分章word\第6章配套代码')
f2 = '.\西游记数据\《西游记》章回内容梗概.txt';
% 当前平台的文件分隔符
filesep
c2 = fileread(f2)
------------------------------------------------------------------------------------------------------------------
% 编码
feature('DefaultCharacterSet') % 查看MatLab默认字符编码
% 导入utf-8编码的文件
c1 = fileread('测试utf-8.txt')
% 导入gb2312编码的文件
c2 = fileread('测试gb2312.txt')
% 修改编码方式
feature('DefaultCharacterSet','utf-8');
feature('DefaultCharacterSet','gbk');
------------------------------------------------------------------------------------------------------------------
% 指定编码形式
c1 = fileread('测试utf-8.txt','Encoding','UTF-8')
c2 = fileread('测试gb2312.txt','Encoding','GBK')
% fopen函数——打开文件进行读取或写入操作
fid = fopen(filename,permission)
filename:指定打开或创建文件名称
permission:指定文件使用方式
'r':只读模式(打开)-默认
'w':写入模式,删除原文件内容(打开、创建)
'a':写入模式,保留原文件内容(打开、创建)
fid:返回值——整数标量,文件打开失败时返回值为-1
filename = 'abc.txt'; % 指定文件名
fid = fopen(filename, 'r');
if fid == -1
warning('文件打开失败!')
% 或者直接使用error函数来中止程序的运行
end
% 注意文件在未使用时需要关闭,否则容易导致文件锁定或者内存泄漏问题
fname = '测试utf-8.txt'; % 打开文件的名称
fid = fopen(fname); % 打开文件并获取文件对应的标识符fid
if fid ~= -1
% 文件读写操作代码
fclose(fid); % 关闭文件标识符fid对应的文件
else
warning('文件打开失败。') % 或者使用error函数生成报错
end
% 批量关闭所有文件
fclose all;
% 指定字符编码方案(参数3为字节排列方式)
fid = fopen(fname,'r','n','UTF-8');
% fread函数
fclose all;
fname = '测试utf-8.txt';
fid = fopen(fname,'r','n','UTF-8');
if fid ~= -1
c = fread(fid,'*char'); % 返回列字符向量
c = c'; % 转置成的行字符向量
fclose(fid); % 关闭文件标识符fid对应的文件
disp(c)
else
warning('文件打开失败。') % 或者使用error函数生成报错
end
------------------------------------------------------------------------------------------------------------------
try
c = fileread('测试utf-8.txt','Encoding','UTF-8');
disp(c)
catch
warning('MATLAB版本不得低于2022b')
end
文本数据导出:
% fprintf函数——按照fopen函数指定的编码方案将数据写入文件
nbytes = fprintf(fid,formatSpec,A1,A2,A3,...,An)
nbytes:返回fprintf函数写入字节数
formatSpec:定义数据格式化方式
乘法口诀表(字符数组) cc
s = join(string(cc),newline) % 转换成字符串标量,用换行符隔开每行
fid = fopen('乘法口诀表.txt','w')
if fid ~= -1
fprintf(fid,'%s',s); % 将字符串文本写入文件
disp('保存成功!')
fclose(fid); % 关闭文件标识符fid对应的文件
else
warning('保存失败')
end
% fprintf函数——标准输出
fprintf('圆周率:%.4f\n',pi)
nbytes = fprintf('圆周率:%.4f\n',pi)
| 函数 | 作用 |
|---|---|
| readlines | 读取多行文本数据 |
| writelines | 写入多行文本数据 |

s1 = readlines('黄鹤楼.txt','Encoding','UTF-8') % MATLAB版本不低于2020b
s2 = readlines('黄鹤楼.txt','Encoding','UTF-8', ...
'EmptyLineRule','skip') % 跳过空行
s3 = readlines('黄鹤楼.txt','Encoding','UTF-8', ...
'EmptyLineRule','skip', ... % 跳过空行
'WhitespaceRule','trim') % 删除前导和尾部空白
% 请确保MATLAB版本不低于2022a
writelines(s3,'黄鹤楼崔颢.txt','Encoding','UTF-8', ...
'WriteMode','overwrite')
模型效果评判:







测试函数:
对于全局最优解来说,测试函数的选择是至关重要的,测试函数的好坏往往可以体现出搜索算法的优劣。有时性能一般的算法在某个特定的函数下发挥的很好,但是在别的函数下就很难搜索到全局最优解。因此我们需要设计各种测试函数,从搜索效率,搜索精度,适应程度多个方面综合比较各个算法,只有这样,在今后的使用中才能得心应手。
优化算法中常见测试函数[^5]:

🌟持续更新中...😙
[^1]:在 MatLab 中,常数除以零得到无穷大;零除零、零成无穷大为未定型,结果为 NaN
[^2]:round(12345.6,-2) == 12300
[^3]:若要计算以任意正数为底的对数值,可以使用换底公式
[^4]:步长可正可负,若起始值大于终止边界且步长大于零,则返回零向量(行向量);若步长为零,仍返回零向量(行向量)
[^5]:优化算法题解中通常要求利用测试函数,来证明所给出算法优于原先算法
Xi / i½(i=1,2,3...n) 可以用 x./sqrt(1:n) 表示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号