Java内存区域划分
1. JVM内存区域划分
jvm在运行java应用程序过程中,会把它所管理的内存划分为若干不同的数据区域。

☝️ 灰色部分(Java栈,本地方法栈和程序计数器)是线程私有,不存在线程安全问题,橙色部分(方法区和堆)为线程共享区。
2. 类加载器
类加载器(Class Loader)负责加载class文件,class文件在文件开头有特定的文件标识,将class文件字节码内容加载到内存中,并将这些内容转换成方法区中的运行时数据结构。ClassLoader只负责class文件的加载,至于它是否可以运行,则由执行引擎Execution Engine决定。类加载示意图:
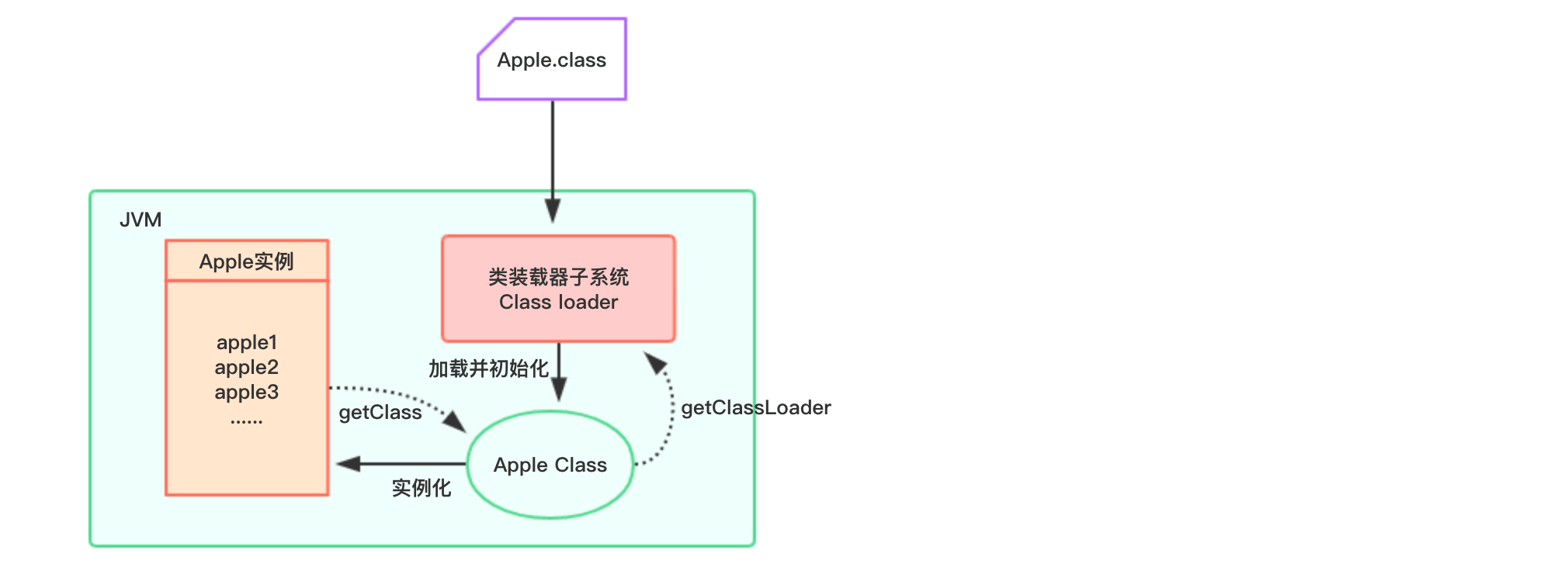
也就是说,类加载器识别的class文件除了是.class格式外,文件的开头还得有特殊的标识,使用文本编辑器打开一个class格式的文件:
cafe babe 0000 0034 0010 0a00 0300 0d07
000e 0700 0f01 0006 3c69 6e69 743e 0100
0328 2956 0100 0443 6f64 6501 000f 4c69
6e65 4e75 6d62 6572 5461 626c 6501 0012
4c6f 6361 6c56 6172 6961 626c 6554 6162
6c65 0100 0474 6869 7301 0014 4c63 632f
6d72 6269 7264 2f63 6173 2f54 6573 743b
0100 0a53 6f75 7263 6546 696c 6501 0009
5465 7374 2e6a 6176 610c 0004 0005 0100
1263 632f 6d72 6269 7264 2f63 6173 2f54
6573 7401 0010 6a61 7661 2f6c 616e 672f
4f62 6a65 6374 0021 0002 0003 0000 0000
0001 0001 0004 0005 0001 0006 0000 002f
0001 0001 0000 0005 2ab7 0001 b100 0000
0200 0700 0000 0600 0100 0000 0300 0800
0000 0c00 0100 0000 0500 0900 0a00 0000
0100 0b00 0000 0200 0c
这个特定的标识就是十六进制字符cafe babe。
3. 程序计数器
🌳 程序计数器是一块非常小的内存空间,它可以看做是当前线程所执行的字节码的行号指示器。字节码解释器工作时通过改变程序计数器的值来选取下一条需要执行的字节码指令。读取一个指令后,将该指令“翻译”成固定的操作,并根据这些操作进行分支、循环、跳转、异常处理等流程。
🌳 JVM的多线程实现方式是通过CPU时间片轮转(即线程轮流切换并分配处理器执行时间)算法来实现的。也就是说,某个线程在执行过程中可能会因为时间片耗尽而被挂起,而另一个线程获取到时间片开始执行。当被挂起的线程重新获取到时间片的时候,它要想从被挂起的地方继续执行,就必须知道它上次执行到哪个位置,在JVM中,通过程序计数器来记录某个线程的字节码执行位置。因此,每个线程工作时都有属于自己的独立计数器。各个线程之间的计数器互不影响,独立存取,这类内存区域成为 线程私有 内存
🌳如果执行的是一个Native方法,那这个计数器的值为undefied。
通过一段代码,我们来看一下程序计数器所记录的字节码的行号
-
新建Test.java文件
public class Test { public static void main(String[] args) { int a = 1; int b = 1; int sum = a + b; System.out.println(sum); } } -
编译Test.java为字节码文件
javac Test.java -
使用javap工具打开字节码文件
javap -verbose Test.class # 右侧行号,左侧为指令 stack=2, locals=4, args_size=1 0: iconst_1 1: istore_1 2: iconst_1 3: istore_2 4: iload_1 5: iload_2 6: iadd 7: istore_3 8: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream; 11: iload_3 12: invokevirtual #3 // Method java/io/PrintStream.println:(I)V 15: return假如当前线程的程序计数器存储的指令地址为6,这时候CPU切换到别的线程中处理工作;一段时间后,当前线程重新获取了CPU时间片继续执行时,根据程序计数器存的6就知道,当前需要执行iadd(即a+b操作)指令。执行引擎会将这条指令翻译为机器指令,然后CPU执行该运算操作。
4. 虚拟机栈(Java栈)
🌳 虚拟机栈也称为Java栈,每个方法被执行的时候,Java虚拟机都会同步创建一个栈帧(Stack Frame)。
- Java虚拟机栈是线程私有的,它的生命周期与线程相同(随线程而生,随线程而灭)。
- 栈帧包括局部变量表、操作数栈、动态链接、方法返回地址和一些附加信息。
- 每一个方法被调用直至执行完毕的过程,就对应这一个栈帧在虚拟机栈中从入栈到出栈的过程。
虚拟机栈示意图如下所示:

栈帧结构:

本地方法栈
🌳 本地方法栈(Native Method Stacks)与虚拟机栈发挥的作用的非常相似的。虚拟机栈是为虚拟机执行java方法服务,而本地方法栈是为虚拟机执行本地方法服务的。
什么是本地方法接口?
本地方法接口(Native Interface)的作用是融合不同的编程语言为Java所用,它的初衷是融合C/C++程序。Java诞生的时候是 C/C++横行的时候,要想立足,必须有调用 C/C++程序,于是就在内存中专门开辟了一块区域处理标记为native的代码。例如查看java.lang.Thread类中存在许多native方法:
public static native void yield();
public static native void sleep(long millis) throws InterruptedException;
native方法没有方法体(因为不是Java实现),所以看上去像是“接口”一样,故得名本地方法接口。
Java堆
Java 堆是虚拟机所管理的内存中最大的一块,是被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一作用就是存放对象实例,几乎所有的对象实例都是在这里分配的(不绝对,在虚拟机的优化策略下,也会存在栈上分配、标量替换的情况)。当类加载器读取了类文件后,需要把类、方法、常量、变量放到堆内存中,保存所有引用类型的真实信息,以方便执行器执行。
Java 堆是 GC 回收的主要区域,因此很多时候也被称为 GC 堆。从内存回收的角度看,Java 堆还可以被细分为新生代和老年代;再细一点新生代还可以被划分为 Eden Space、From Survivor Space、To Survivor Space。从内存回收的角度看,线程共享的 Java 堆可能划分出多个线程私有的分配缓冲区(Thread Local Allocation Buffer,TLAB)。「属于线程共享的内存区域」
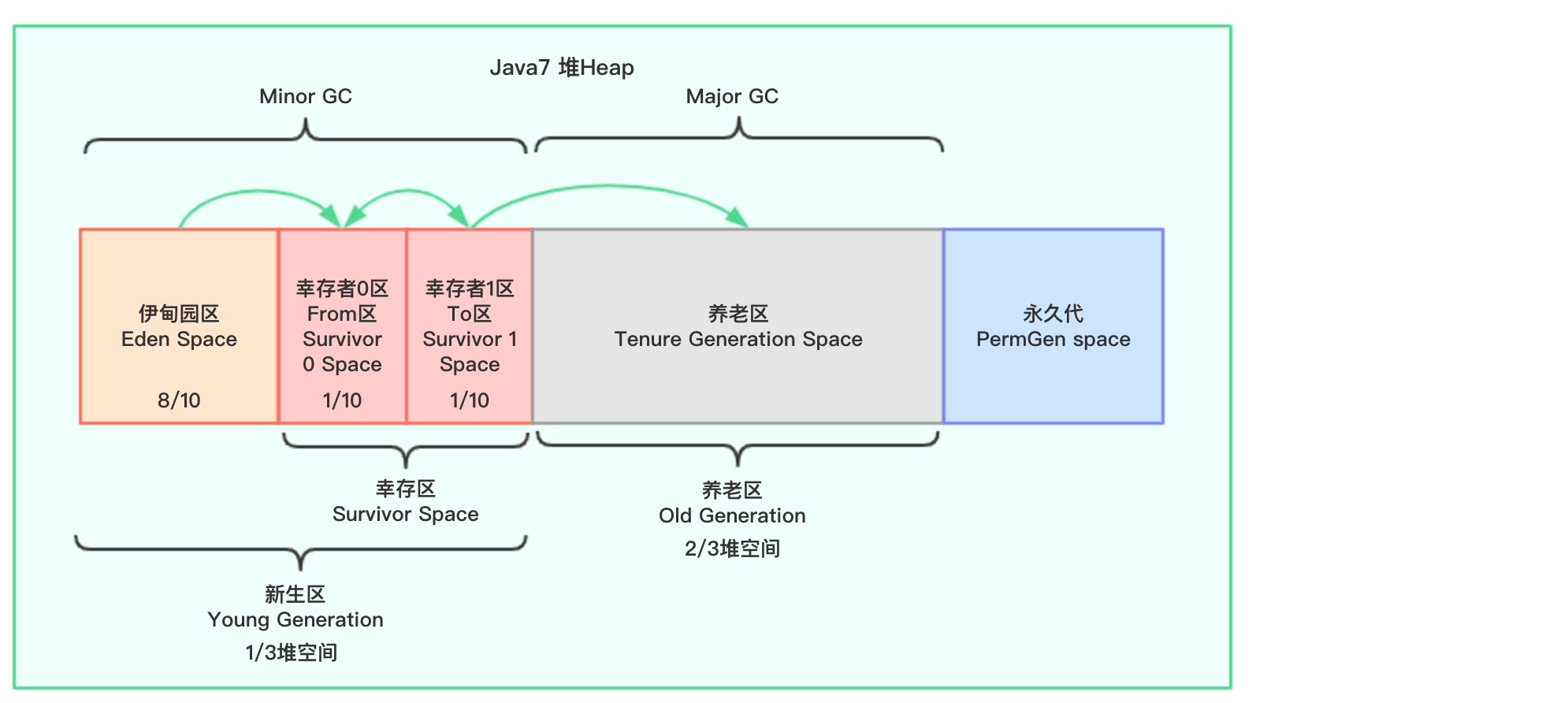
堆在逻辑上分为三个区域:
Java7:
Java8:
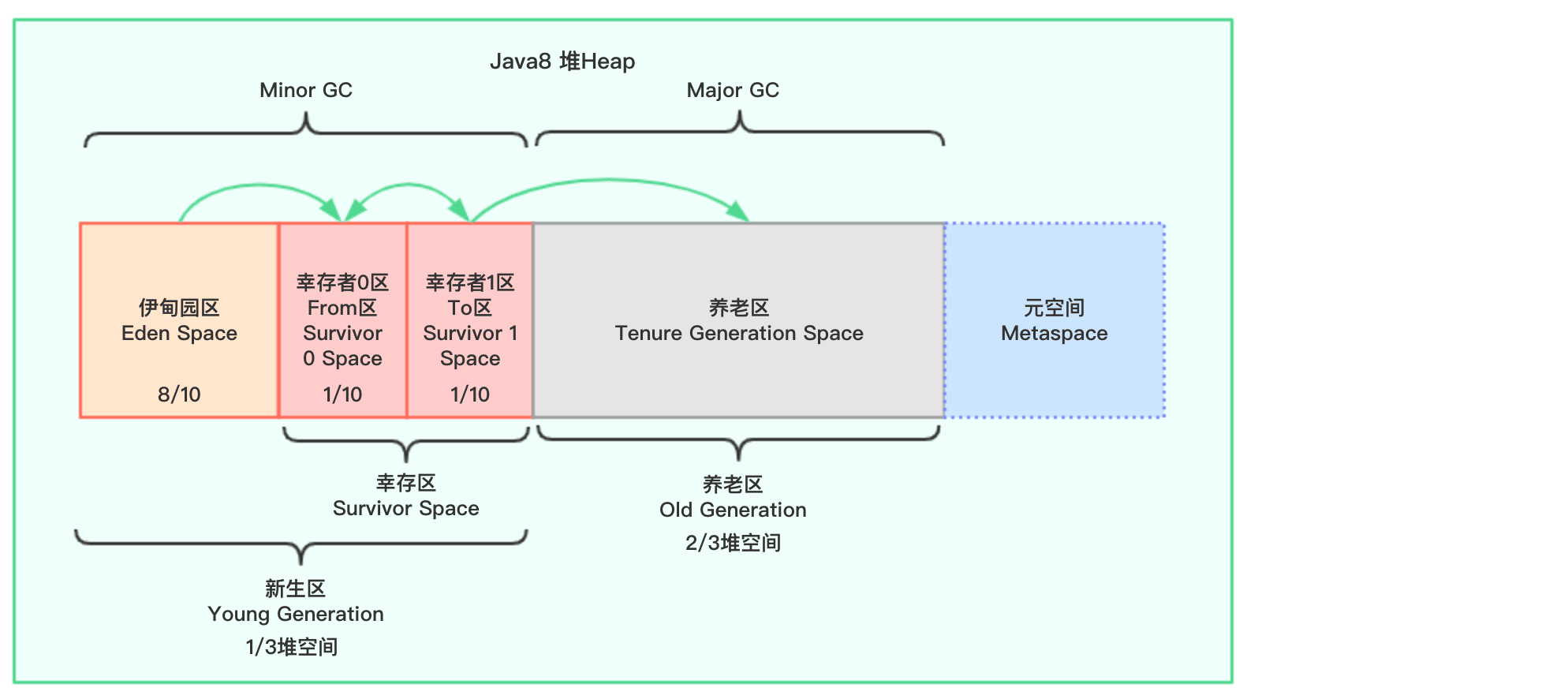
可以看到,在Java7时代,堆分为新生区(新生区包含伊甸园区和幸存区,幸存区又包含幸存者0区和幸存者1区。此外,幸存者0区又称为From区,幸存者1区又称为To区,From区和To区并不是固定的,复制之后交互,谁空谁是To),养老区和永久代;在Java8中,永久代已经被移除,被一个称为元空间的区域所取代。元空间的本质和永久代类似。
元空间与永久代之间最大的区别在于:永久代使用的JVM的堆内存(但是逻辑上是非堆的),但是java8以后的元空间并不在虚拟机中而是使用本机物理内存(所以在上图中,我用虚线表示)。
永久代:是一个常驻内存的区域,用于存放JDK自身所携带的Class,Interface的元数据,即存储的是运行环境必须的类信息,被转载进此区域的数据是不会被垃圾回收的,只有关闭JVM才会释放此区域所占用的内存空间。
元空间:取代永久代,不在Java虚拟机的堆中实现,而是使用本机物理内存实现。默认情况下元空间大小仅受本地内存限制。类的元数据放入native memory,字符串常量在Java堆中(运行时常量和基本类型常量在元空间——方法区)
PS:jdk1.8,jvm把字符串常量池移到了堆内存里。此时方法区=元空间
堆之所以要分区是因为:Java程序中不同对象的生命周期不同,70%~99%对象都是临时对象,这类对象在新生区“朝生夕死”。如果没有分区,GC时搜集垃圾需要对整个堆内存进行扫描;分区后,回收这些“朝生夕死”的对象,只需要在小范围的区域中(新生区)搜集垃圾。所以,分区的唯一理由就是为了优化GC性能。
方法区
🌳方法区(Method Area)并不是所谓的存储方法的区域,而是供各线程共享的运行时内存区域。它存储了已被虚拟机加载的类信息、方法信息、字段信息、常量(被final修饰)、静态变量、即时编译器编译后的代码缓存等。
方法区也是一种规范,在不同虚拟机里头实现是不一样的,最典型的实现就是HotSpot虚拟机Java8之前的永久代(PermGen space)和Java8的元空间(Metaspace)。
可参考:https://www.cnblogs.com/code-duck/p/13577103.html
执行引擎
类加载器加载的字节码并不能够直接运行在操作系统之上,因为字节码指令不是本地机器指令,执行引擎(Execute Engine)的任务就是讲字节码指令解释为对应平台上的本地机器指令。通俗地讲,执行引擎就是将高级语言翻译为本地机器语言的翻译官。
解释器和JIT编译器
- 解释器(Interpreter):JVM在程序运行时通过解释器逐行将字节码转为本地机器指令执行;
- JIT编译器(Just In Time Compiler,即时编译器):解释器的优点是程序一启动就可以马上发挥作用,逐行翻译字节码执行程序。而对于一些高频的代码(如循环体内代码和高频调用方法等),如果每次执行都用解释器逐行将字节码翻译为机器指令的话,势必会造成浪费,所以我们可以通过即时编译器将这部分高频代码直接编译为机器指令然后缓存在方法区中(上面介绍方法区内部组成时提到过JIT代码缓存),以此提高执行效率。和解释器相比,即时编译器的缺点就是编译需要耗费一定时间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号