.NET 原生驾驭 AI 新基建实战系列(二):Semantic Kernel 整合对向量数据库的统一支持
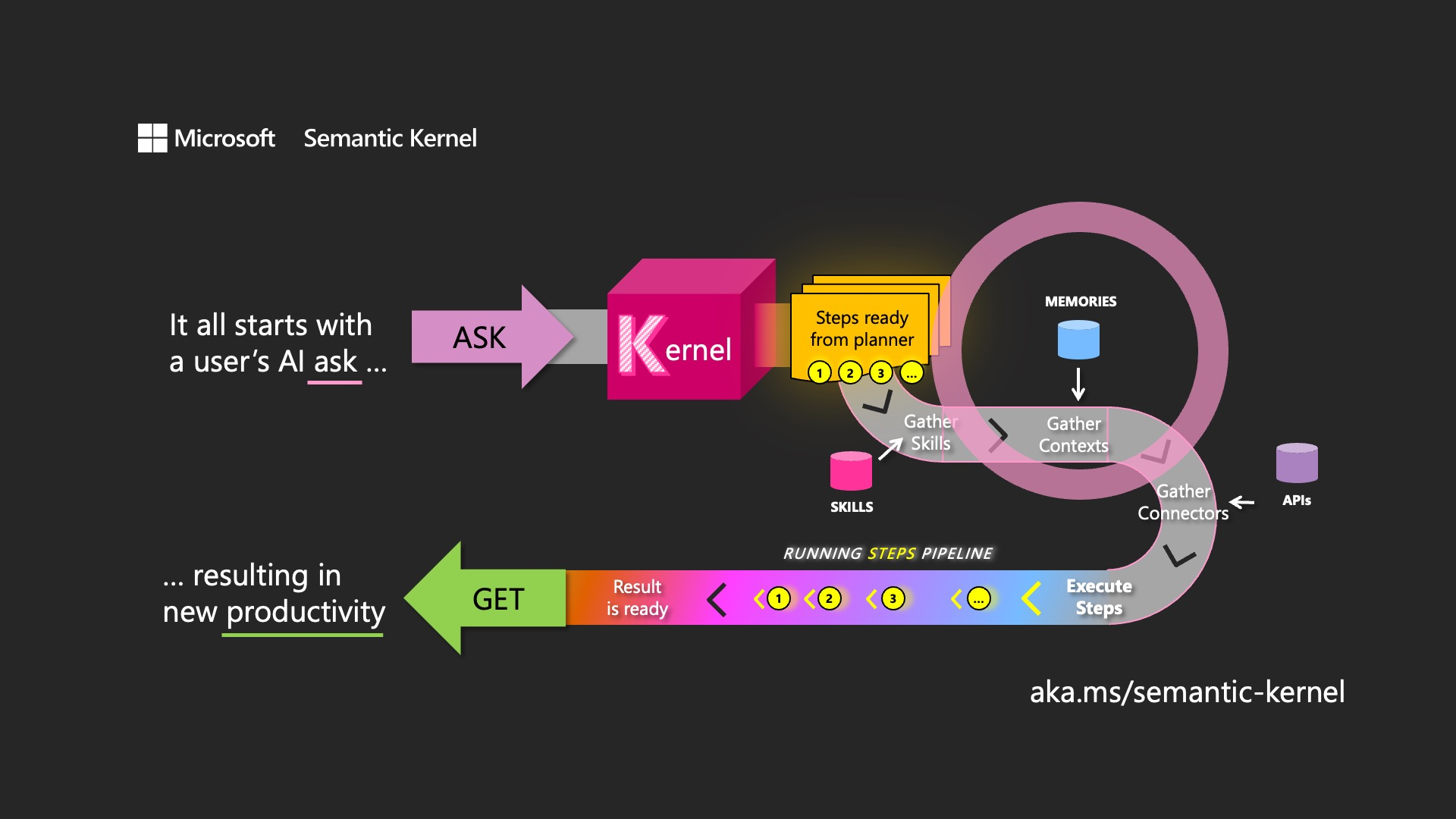
1. 引言
在人工智能(AI)应用开发迅猛发展的今天,向量数据库作为存储和检索高维数据的重要工具,已经成为许多场景(如自然语言处理、推荐系统和语义搜索)的核心组件。
对于.NET生态系统的开发者而言,如何高效地整合和管理不同的向量数据库,并以统一的方式使用它们,是一个亟待解决的问题。
Semantic Kernel是一个企业就绪型SDK,允许开发人员插入不同的LLM模型和不同的语言,并为这些插件提供自动编排功能。.NET通过Semantic Kernel这一开源工具包,结合其丰富的扩展和支持,提供了强有力的解决方案。
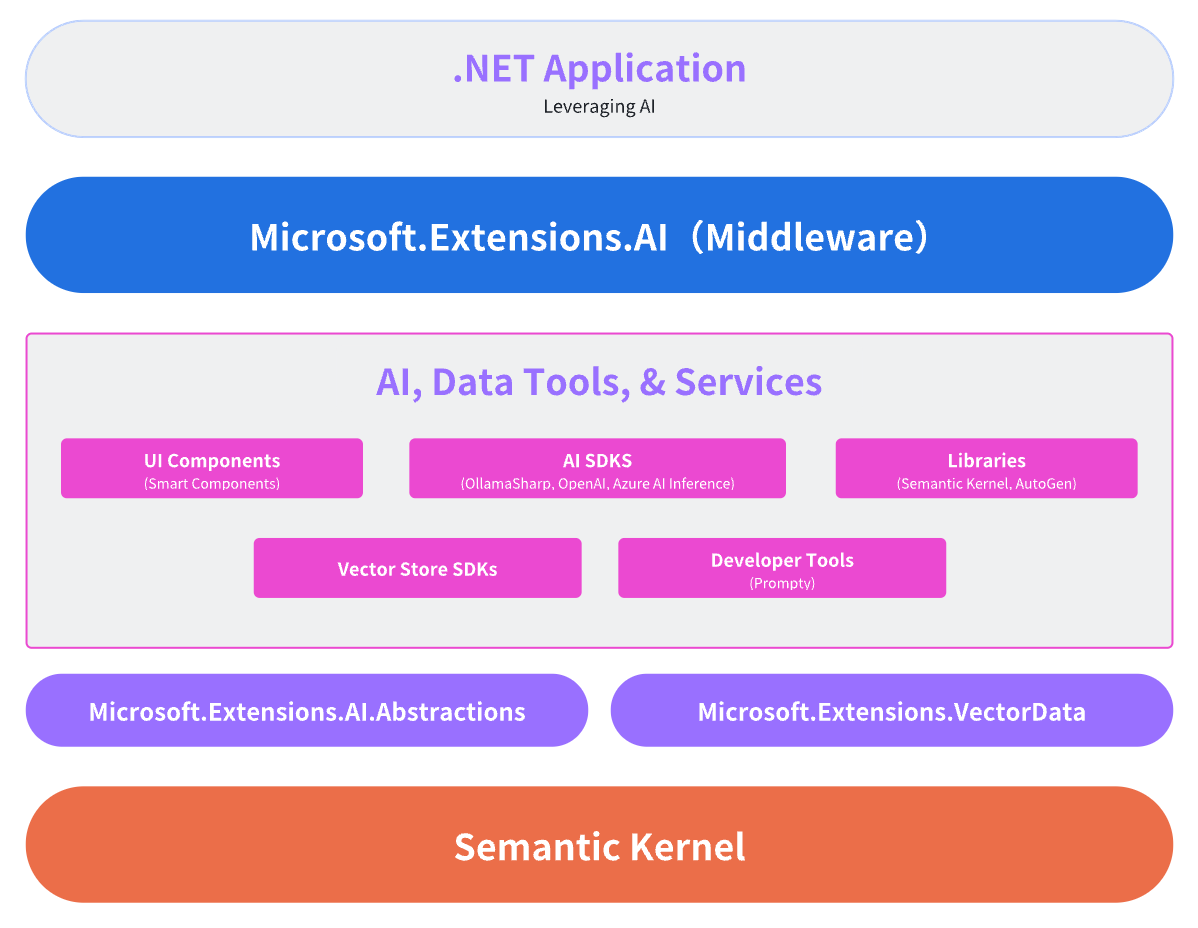
为了更好的使Semantic Kernel和.NET之间有更好的协作,微软发布了几个辅助库:
-
第一个是 Microsoft.Extensions.AI库,用于抽象常见的AI服务,例如聊天客户端。 -
第二个包是 Microsoft.Extensions.VectorData.Abstractions库,它为大规模语言模型(LLM)的向量嵌入处理提供了标准化接口。该抽象层主要解决向量化存储的核心需求:
❝在LLM技术栈中,向量嵌入(Embedding)是指将文本、图像等离散数据转化为高维向量空间中的数学表示。通过将数据特征映射为连续型向量,原本无法被神经网络直接处理的离散信息(如自然语言)得以转化为可计算、可比较的数值形式。这种转换使语义相似的数据在向量空间中具有几何临近性(例如"猫"与"犬科动物"的向量距离小于"猫"与"计算机"),从而支撑起基于向量相似度的语义搜索技术——相比传统的关键词匹配,它能更精准地捕捉查询意图与内容间的深层关联。
因此,Semantic Kernel 不仅提供了一个灵活的框架,还通过其模块化设计和丰富的组件(如Vector Store Connectors、Embedding Generation和Vector Search),为.NET 开发者提供了一个统一的接口来操作向量数据库。本文将从 Semantic Kernel 的基本概念入手,逐步深入探讨微软如何通过这一工具实现向量数据库的整合,并分析其在实际开发中的优势与前景。
2. Semantic Kernel 概述
2.1 什么是 Semantic Kernel?
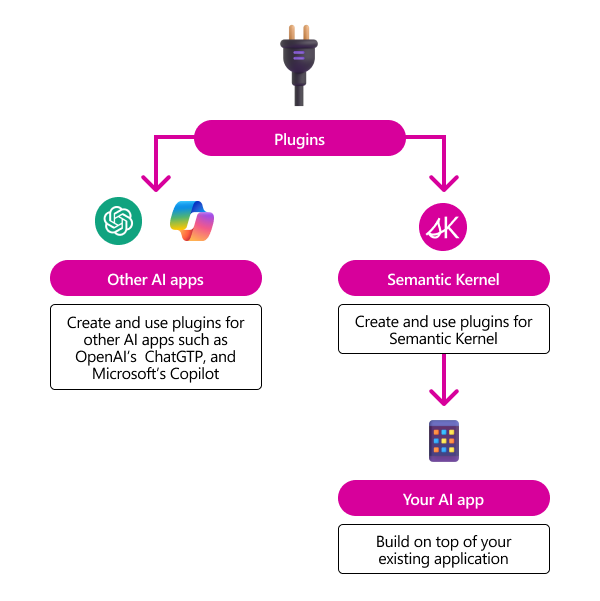
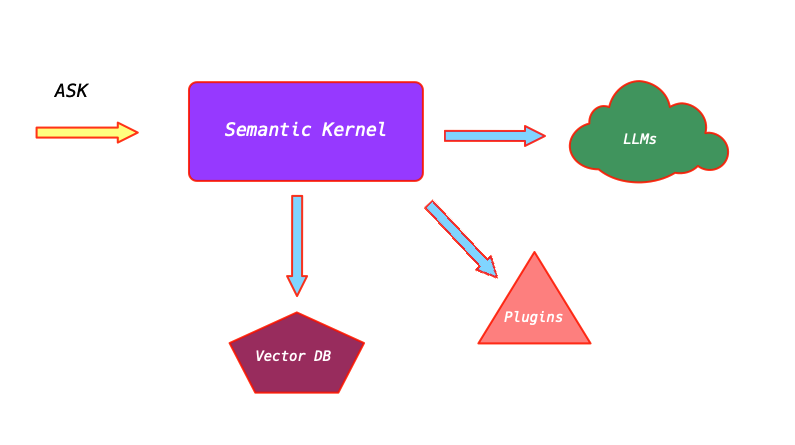
Semantic Kernel 是微软开发的一个开源项目,旨在简化 AI 应用的开发过程。它最初设计为一个轻量级的 SDK(软件开发工具包),支持开发者在 C#、Python 和 Java 等语言中构建 AI 代理并集成最新的 AI 模型。在 .NET 生态系统中,Semantic Kernel 尤为重要,因为它为开发者提供了一个高度模块化的架构,使得 AI 功能的集成和扩展变得更加简单。
Semantic Kernel 的核心理念是将 AI 应用开发分解为多个可重用的组件,通过一个中央管理单元——内核(Kernel)——进行协调。这种设计不仅提高了代码的可维护性,还为开发者提供了灵活性,使其能够根据具体需求选择和组合不同的功能模块。
2.2 Semantic Kernel 的核心组件
Semantic Kernel 的功能依赖于以下几个核心组件:
-
内核(Kernel)
内核是 Semantic Kernel 的心脏,充当依赖注入容器,负责管理所有运行 AI 应用所需的服务和插件。它协调各种组件之间的交互,确保应用的顺畅运行。开发者可以通过内核注册 AI 服务、插件和向量数据库连接器,从而构建一个完整的 AI 应用。 -
插件(Plugins)
插件是 Semantic Kernel 中的可重用代码块,可以是原生函数(Native Functions)或语义函数(Semantic Functions)。它们封装了特定的功能,例如文本处理、数据检索或数学计算,开发者可以根据需要加载和调用这些插件。 -
AI 服务(AI Services)
AI 服务提供了与外部 AI 模型的集成能力,例如聊天完成(Chat Completion)、嵌入生成(Embedding Generation)等。Semantic Kernel 支持多种 AI 服务提供商,如 Azure OpenAI、Hugging Face 等,开发者可以根据需求选择合适的服务。 -
Vector Store Connectors
Vector Store Connectors 是 Semantic Kernel 中专门用于连接和操作向量数据库的组件。它们提供了一组标准化的接口,使得开发者能够以一致的方式与不同的向量数据库交互。
通过这些组件,Semantic Kernel 为开发者提供了一个强大的平台,使得 AI 应用开发更加模块化和高效。
3. 向量数据库与 Semantic Kernel
3.1 向量数据库的基本概念
向量数据库是一种专门设计用于存储和检索高维向量的数据库系统。与传统的关系型数据库不同,向量数据库优化了相似性搜索(Similarity Search)和高维数据处理,能够快速找到与给定查询向量最相似的向量。这种特性使得向量数据库在 AI 应用中具有广泛的用途,例如语义搜索、推荐系统和图像识别。
常见的向量数据库包括 Azure Cognitive Search、Pinecone、Weaviate、Chroma 等,每种数据库都有其独特的优势和适用场景。然而,这种多样性也为开发者带来了挑战:如何在不同的数据库之间保持一致的操作方式?为此,Semantic Kernel 扩展了一系列的组件来解决这一问题。
3.2 Semantic Kernel 对向量数据库的支持
在 Semantic Kernel 中,向量数据库的支持是通过 Vector Store Connectors 实现的。这些连接器抽象了底层数据库的实现细节,提供了一个统一的 API,使得开发者无需深入了解每种数据库的具体操作即可进行数据存储、检索和搜索。这种设计不仅降低了学习曲线,还提高了代码的可移植性和可维护性。
通过 Semantic Kernel,开发者可以在 .NET 应用中轻松集成多个向量数据库,并以一致的方式使用它们。这种统一支持的核心在于微软提供的标准化接口和扩展工具,下面将详细介绍相关机制。
3.2.1 核心技术细节
-
插件化设计:
Semantic Kernel 的插件系统允许开发者通过 TextMemoryPlugin 添加自定义功能。例如,该插件可以将文本内容存储为记忆,并在需要时检索。
-
多存储支持:
MultipleMemoryStore 通过配置多个 IMemoryStore 实例,实现了对不同存储系统的统一管理。这为开发者提供了灵活性,可以根据需求选择内存存储或外部向量数据库。
-
与向量数据库的潜在整合:
虽然示例中未直接使用向量数据库,但 IMemoryStore 接口的设计允许开发者通过自定义实现将其连接到向量数据库。例如,可以创建一个基于 Redis 或 Pinecone 的存储实现。通过扩展 IMemoryStore,开发者可以无缝地将向量数据库集成到 AI 代理中,实现嵌入存储和相似性搜索。这种灵活性是 Semantic Kernel 在 .NET 中支持向量数据库的关键实现。
4. Vector Store Connectors
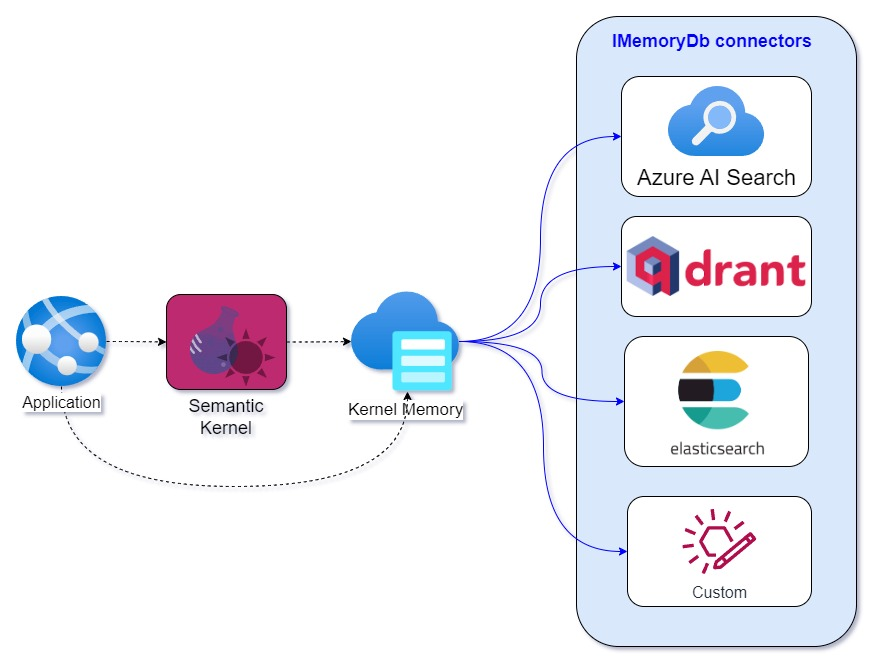
4.1 Vector Store Connectors 的作用
Vector Store Connectors是Semantic Kernel中连接向量数据库的关键组件。它们提供了一组通用的接口和方法,用于执行以下操作:
-
数据存储:将生成的向量存储到数据库中。 -
数据检索:根据条件从数据库中获取向量或其他数据。 -
相似性搜索:在数据库中搜索与查询向量相似的向量。
通过Vector Store Connectors,Semantic Kernel支持多种流行的向量数据库,包括但不限于:
-
Azure Cognitive Search:微软自家的向量搜索服务,适用于需要与 Azure 生态集成的场景。 -
Chroma:一个开源的向量数据库,专为 AI 应用设计,支持高效的向量存储和相似性搜索。 -
Qdrant:一个高性能的向量数据库,支持实时搜索和过滤功能。 -
Milvus:一个开源的分布式向量数据库,专为大规模数据设计,支持多种索引类型。 -
Pinecone:一个高性能的云原生向量数据库,适合大规模分布式应用。 -
Weaviate:一个开源向量数据库,支持语义搜索和知识图谱。 -
……
4.2 配置和使用 Vector Store Connectors
在Semantic Kernel中配置和使用Vector Store Connectors通常包括以下步骤:
-
选择合适的连接器
根据项目需求,开发者可以从 Semantic Kernel 支持的连接器列表中选择合适的 Vector Store Connector。例如,若项目使用 Azure Cognitive Search,则选择对应的连接器。 -
提供连接信息
配置连接器需要提供必要的参数,例如 API 密钥、数据库端点地址等。这些信息通常在向量数据库的管理控制台中可以找到。 -
注册到内核
将配置好的 Vector Store Connector 注册到 Semantic Kernel 的内核中,使其成为应用的一部分。注册后,开发者可以通过内核调用连接器的功能。
例如,一个简单的配置过程可能如下:
var vectorStore = new PineconeVectorStore(new PineconeClient(pineconeApiKey));通过这种方式,开发者可以在 .NET 应用中轻松集成向量数据库,并利用其强大的功能。
5. Embedding Generation
5.1 Embedding Generation 的作用
Embedding Generation是将文本、图像或其他数据转换为高维向量的过程。这些向量(也称为嵌入)捕捉了数据的语义信息,可以用于相似性搜索、聚类等任务。在向量数据库的上下文中,Embedding Generation 是数据存储和检索的基础步骤。
例如,在语义搜索场景中,文档和查询首先被转换为向量,然后存储到向量数据库中。搜索时,通过比较查询向量与数据库中存储的向量,可以找到语义上最相关的文档。
5.2 Semantic Kernel 中的 Embedding Generation
Semantic Kernel通过AI 服务支持Embedding Generation。开发者可以选择不同的嵌入生成服务,例如Azure OpenAI或Hugging Face,并在内核中进行配置。配置和使用Embedding Generation的基本步骤包括:
-
注册 AI 服务
在内核中注册一个嵌入生成服务,例如Azure OpenAI的文本嵌入模型。 -
生成嵌入
使用注册的服务将输入数据(如文本)转换为向量。例如,输入一段文本后,服务返回一个高维向量。 -
存储到向量数据库
将生成的向量通过Vector Store Connector存储到目标向量数据库中。
这种集成方式使得开发者能够灵活地选择嵌入生成模型,并将其与向量数据库无缝结合。例如,一个典型的嵌入生成和存储流程可能是:
var embeddingService = new AzureOpenAIEmbeddingService(apiKey, endpoint);
kernel.RegisterAIService(embeddingService);
var vector = embeddingService.GenerateEmbedding("这是一个测试句子");
connector.StoreVector(vector);通过这种方式,Semantic Kernel提供了一个统一的嵌入生成框架,简化了向量数据库的使用。
6. Vector Search
6.1 Vector Search 的概念
Vector Search是指在向量数据库中搜索与给定查询向量相似的向量。这是向量数据库的核心功能之一,广泛应用于推荐系统、语义搜索等领域。Vector Search的核心在于高效的相似性计算,通常使用余弦相似度或欧几里得距离等指标。
例如,在一个推荐系统中,用户的兴趣向量可以与商品向量进行比较,以找到最相似的商品推荐给用户。
6.2 Semantic Kernel 中的 Vector Search
在Semantic Kernel中,Vector Search是通过Vector Store Connectors实现的。开发者可以使用统一的API执行搜索操作,而无需关心底层数据库的具体实现。Vector Search的基本流程包括:
-
生成查询向量
使用Embedding Generation服务将查询转换为向量。例如,将用户输入的搜索词转换为高维向量。 -
执行搜索
使用Vector Store Connector在向量数据库中搜索与查询向量相似的向量。 -
处理结果
根据搜索结果进行后续处理,例如返回最相关的文档或推荐内容。
例如,一个简单的Vector Search操作可能是:
// 伪代码
var queryVector = embeddingService.GenerateEmbedding("查找相关文档");
var results = connector.SearchVectors(queryVector, topK: 5);
foreach (var result in results)
{
Console.WriteLine($"找到相似向量:{result.Id}");
}通过这种方式,Semantic Kernel为开发者提供了一个一致的接口,使得Vector Search 在不同的向量数据库中都能高效运行。
7. Microsoft.Extensions.VectorData 的统一
7.1 向量数据库的整合
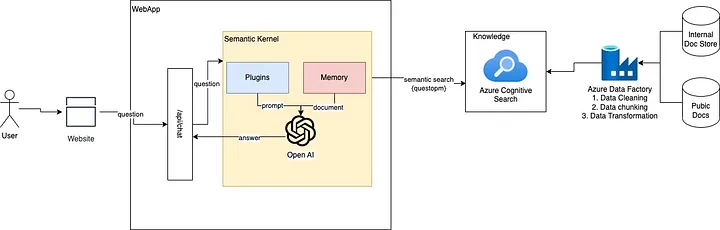
为了进一步支持向量数据库的整合,微软推出了 Microsoft.Extensions.VectorData,这是一个专为 .NET 开发者设计的扩展库。它提供了一组通用的接口和实现,用于处理向量数据的存储、检索和搜索。Microsoft.Extensions.VectorData与Semantic Kernel紧密集成,使得开发者可以在 .NET 应用中无缝使用向量数据库。
❝可以认为
Microsoft.Extensions.VectorData是Microsoft.SemanticKernel.Plugins.Memory的演变。
这个扩展库的主要功能包括:
-
标准化接口:为向量数据的操作提供一致的 API。 -
高性能实现:优化了向量数据的处理效率。 -
与现有工具集成:支持与 Semantic Kernel和其他.NET组件的协同工作。
7.2 丰富的文档和社区支持
微软为Semantic Kernel和相关工具提供了详尽的文档和示例。例如,开发者可以在Microsoft Learn上找到关于Vector Store Connectors、Embedding Generation和Vector Search的详细指南。此外,微软还通过GitHub和社区论坛提供技术支持,帮助开发者解决实际问题。
通过这些扩展和支持,微软为.NET开发者提供了一个强大且易用的平台,使得向量数据库的整合变得更加简单和高效。
7.3 AI 服务与向量数据库的协同
Semantic Kernel的AI服务是其支持向量数据库的另一关键环节。这些服务包括:
7.3.1 聊天完成(Chat Completion)
聊天完成服务(Chat Completion)允许 AI 代理与用户进行自然语言对话。通过集成Azure OpenAI或其他模型,开发者可以实现连贯的对话生成和函数调用。在这一过程中,向量数据库可以存储对话历史或用户偏好,以提供上下文相关的响应。例如,代理可以将对话内容转换为嵌入向量并存储在向量数据库中,以便后续检索。
7.3.2 嵌入生成(Embedding Generation)
嵌入生成服务(Embedding Generation)是将非结构化数据转换为向量表示的核心功能。Semantic Kernel支持通过Azure OpenAI等服务生成嵌入向量,并将其存储在向量数据库中。例如,开发者可以调用嵌入生成 API 将文本转换为向量,然后通过向量存储连接器保存到数据库中。这种流程为相似性搜索和推荐系统提供了基础。
8. 思考与未来展望
优势
-
统一性: Microsoft.Extensions.VectorData提供了一致的接口,简化了多向量数据库的整合。 -
模块化:开发者可以根据需求选择和组合不同的组件。 -
微软支持:丰富的文档和扩展工具降低了学习和使用成本。
挑战
-
数据库选择:不同的向量数据库适用于不同的场景,开发者需要根据需求选择合适的数据库。 -
性能优化:嵌入生成和向量搜索可能需要优化以满足高并发需求。
未来展望
-
更广泛的数据库支持:Microsoft.Extensions.VectorData 可能会扩展对更多向量数据库的支持。 -
更高效的嵌入生成:随着模型优化的进展,嵌入生成将更加快速和准确。 -
智能化的功能:结合更多的 AI 技术,向量数据库将提供更智能的搜索和分析能力。
相信微软作为 AI 领域的领导者,将继续投入资源,推动Microsoft.Extensions.VectorData和向量数据库技术的发展,为开发者提供更强大的工具和支持。
9. 总结
微软通过Microsoft.Extensions.VectorData 为.NET开发者提供了一个强大的工具,用于整合和管理各大向量数据库。借助Vector Store Connectors、Embedding Generation和Vector Search等组件,开发者可以以统一的方式操作不同的向量数据库,构建高效的 AI 应用。
同时,Microsoft.Extensions.VectorData等扩展工具和丰富的文档支持进一步降低了开发门槛,提高了开发效率。
在 AI 驱动的未来,Microsoft.Extensions.VectorData和向量数据库的结合将为开发者带来更多机遇。微软在这一领域的努力和成果,不仅体现了其技术实力,也为.NET生态系统注入了新的活力。
本文来自博客园,作者:AI·NET极客圈,转载请注明原文链接:https://www.cnblogs.com/code-daily/p/18814133

欢迎关注我们的公众号,作为.NET工程师,我们聚焦人工智能技术,探讨 AI 的前沿应用与发展趋势,为你立体呈现人工智能的无限可能,让我们共同携手共同进步。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号