
第三次博客作业_JML之图的构建
第三单元博客作业
一、JML基础知识梳理及工具链应用
1、注释结构
1 //@annotation 2 /*@ 3 annotation 4 @*/
2、方法规格
- 前置条件(pre-condition) 前置条件是对方法输入参数的限制,如果不满足前置条件,方法
执行结果不可预测requires bulabula; - 后置条件(post-condition) 后置条件是对方法执行结果的限制,如果执行结果满足后
置条件,则表示方法执行正确,否则执行错误 ensures bulaubla; - 副作用范围限定(side-effects) 副作用指方法在执行过程中对输入对象或this 对象进行了修改(对
其成员变量进行了赋值,或者调用其修改方法)- assignable \nothing;
- modifiable \everything;
- signals子句 满足b_expr时抛出异常 signals (Exception E) a_expr
3、常用表达式
- \forall表达式:全称量词修饰的表达式,表示对于给定范围内的元素,每个元素都满足相应的条件约束
- \exists表达式:存在量词修饰的表达式,表示对于给定范围内的元素,存在某个元素满足相应的条件约束
- \sum表达式:返回给定范围内的满足条件约束的变量表达式的和
- \product表达式:返回给定范围内的满足条件约束的变量表达式的连乘结果
- \max表达式:返回给定范围内的满足条件约束的变量表达式的最大值。
- \min表达式:返回给定范围内的满足条件约束的变量表达式的最小值。
- \num_of表达式:返回指定变量中满足相应条件约束的取值个数。
4、类型规格
- 不变式约束 invariant
- 状态变化约束 constraint
5、工具链应用
- openJML
- JMLUnitNG
二、JMLUnitNG测试类
- 结合讨论区大佬的帖子完成了较为简单的测试类建立:
1 MyGraph graph = new MyGraph(); 2 MyPath path1; 3 MyPath path2; 4 MyPath path3; 5 6 public void setUp() throws Exception { 7 int[] p1 = {1, 3, 5, 6, 8}; 8 int[] p2 = {1, 2, 3, 4, 5, 6, 7}; 9 int[] p3 = {-1, 4, 6, 7, 8, 10}; 10 path1 = new MyPath(p1); 11 path2 = new MyPath(p2); 12 path3 = new MyPath(p3); 13 graph.addPath(path1); 14 graph.addPath(path2); 15 graph.addPath(path3); 16 } 17 18 public void tearDown() throws Exception { 19 } 20 21 public void testContainsNode() throws Exception { 22 //TODO: Test goes here... 23 Assert.assertEquals(1, graph.addPath(path1), 1); 24 Assert.assertEquals(1, graph.addPath(path2), 1); 25 Assert.assertTrue(path3.containsNode(-1)); 26 Assert.assertTrue(graph.containsNode(10)); 27 Assert.assertEquals(1, graph.addPath(path2), 1); 28 Assert.assertTrue(graph.containsNode(5)); 29 } 30 31 public void testAddPath() throws Exception { 32 Assert.assertEquals(1,graph.addPath(path1),1); 33 Assert.assertEquals(1,graph.addPath(path2),1); 34 } 35 36 public void testRemovePath() throws Exception { 37 Assert.assertEquals(1, graph.addPath(path1), 1); 38 Assert.assertEquals(1, graph.addPath(path2), 1); 39 Assert.assertEquals(1, graph.addPath(path1), 1); 40 Assert.assertEquals(1, graph.addPath(path2), 1); 41 }
- 测试结果:
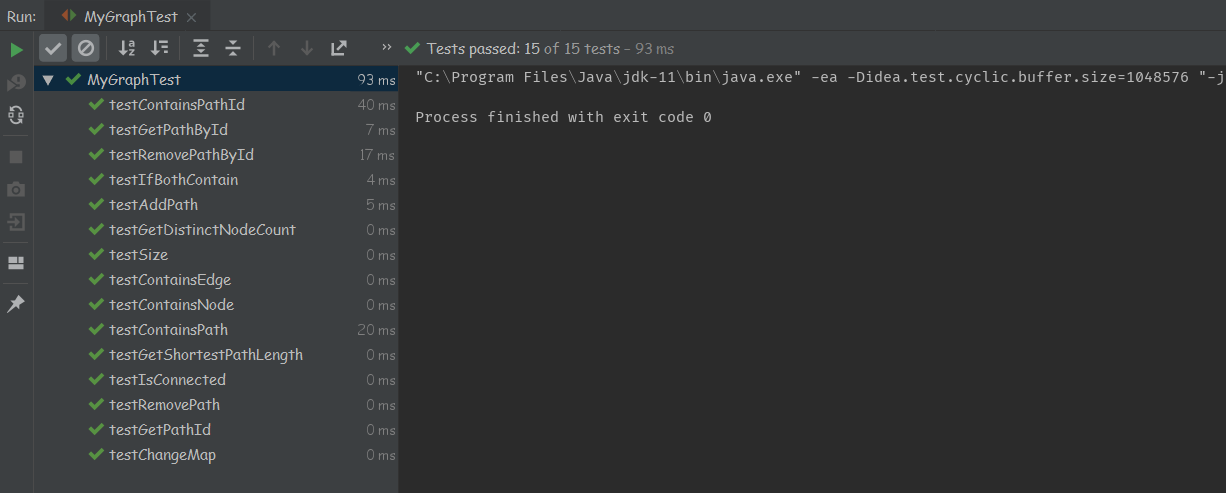
生成样例均为较为极限的数据:
三、架构设计
1、第一次作业
- 第一次作业比较简单,对照开源库中需要重载的接口方法对应的JML编写代码即可,需保证代码完全符合JML的逻辑约束。‘’
新建两个类MyPath、MyPathContainer实现官方开源库中的Path和PathContainer接口中的所有方法,方法主要涉及路径节点的查找、路径的增删与路径与路径Id、路径的节点数组的对应、路径中不同节点的个数。
- 需要注意的点是不要囿于JML中所描述的数据处理的结构(本次为数组)JML注重的是逻辑的描述而不是具体方法如何实现,所以在保证逻辑的合理性的前提下,数据结构可任意选择(当然为了提高性能,推荐使用HashSet储存节点数组,因为在MyPath中需要实现方法DistinctNodeCount(),如果用list的话list的contain方法是循环遍历实现的,而HashSet则是利用key与value的映射关系查找的复杂度要更低些,从而提高程序性能)
- 即本次作业利用两种不同类型的数据结构处理节点序列,list用与下角标索引查找元素,而HashSet去重与快速查询是否存在元素集于一体,可以轻松管理数据并有一个较好的性能体现
关键代码如下:
1 private int[] nodes; 2 private HashSet<Integer> hs = new HashSet<>(); 3 4 public MyPath(int... nodeList) { 5 nodes = nodeList; 6 int i; 7 for (i = 0;i < this.size();i++) { 8 hs.add(nodes[i]); 9 } 10 } 11 12 //由于hs存储的元素都是非重复的,所以这个方法返回其大小就完事儿了 13 public int getDistinctNodeCount() { 14 return hs.size(); 15 }
类图如下:
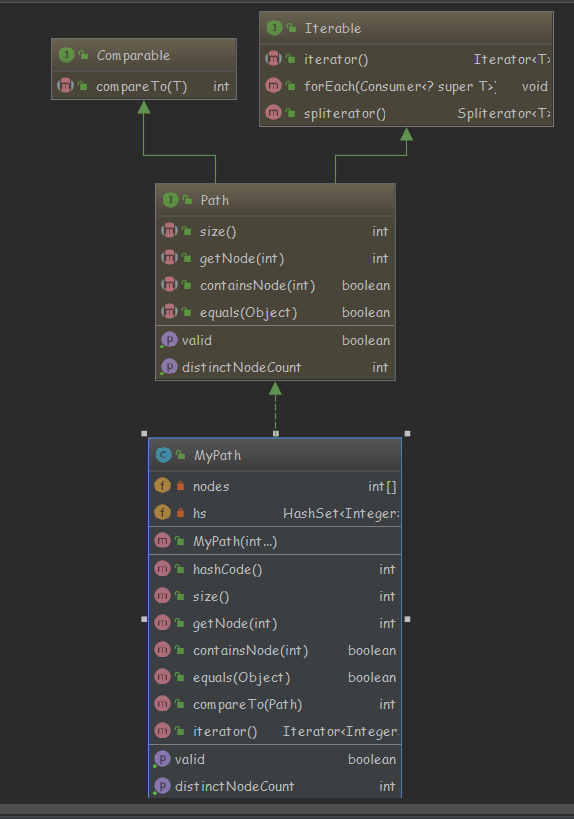
由类图可知,各个类之间的结构层次比较简单,清晰可见。
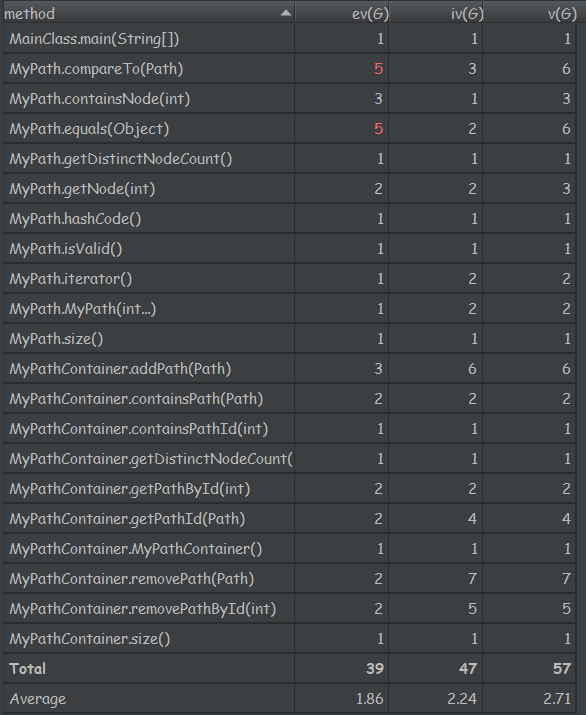
复杂度分析如下:
 C
C
由复杂度分析可知,方法内部均较为简单,设计相对合理。
2、第二次作业
- 相对于第一次作业,在路径容器PathContainer基础上扩展了四个方法ContainNode、ContainEdge、isConnected以及getShortestPathLength,主要考察无向图中边和节点的关系以及最短路径的查找
- 关于寻找最短路径和判断两节点是否连通,我采用的是伪BFS,主要原理和BFS相同,都是优先广度搜索,但未使用二维数组去储存边和边的权重,而是采用的两个一维数组。
- 循环遍历节点,判断是否ContainEdge,然后继续延伸,直到判断的边的另一端点为toNodeId便停止,并返回true
- 若不是toNodeId,则将点记录下来,以便后续以其为中心点进行循环遍历查找,同时每变换一次中心节点,与之相对应的长度数组数值++,最后得到的数值便是最短路径的长度
代码如下:
1 public boolean isConnected(int fromNodeId, 2 int toNodeId) throws NodeIdNotFoundException { 3 if (ifBothContain(fromNodeId,toNodeId)) { //判断两个节点是否都在图中 4 if (fromNodeId == toNodeId) { 5 return true; 6 } 7 else { 8 if (!shortLen.containsKey(fromNodeId + "-" + toNodeId)) { 9 int[] weight = new int[nodeMap.size()]; //用于记录途中节点到起始点路径的长度 10 for (int i = 0; i < weight.length; i++) { 11 weight[i] = -1; //长度均初始化为-1 12 } 13 14 HashSet<Integer> hs = new HashSet<>(); //同第一次作业中说的双数组记录数据,hs判断contain,list查找索引元素以减少运行时间,提高性能 15 List<Integer> list = new ArrayList<>(); 16 hs.add(fromNodeId); 17 list.add(fromNodeId); 18 weight[0] = 0; 19 20 int begin = 0; 21 int j = 0; 22 while (begin < hs.size()) { 23 for (HashMap.Entry<Integer, Integer> entry 24 : nodeMap.entrySet()) { 25 if (hs.contains(entry.getKey()) || 26 entry.getKey() == list.get(begin)) { 27 continue; 28 } 29 if (containsEdge(list.get(begin), entry.getKey())) { 30 j++; 31 weight[j] = weight[begin] + 1; //begin下角标对应元素即为当前中心节点 32 if (entry.getKey() == toNodeId) { 33 shortLen.put(fromNodeId + "-" + toNodeId, 34 weight[j]); 35 shortLen.put(toNodeId + "-" + fromNodeId, 36 weight[j]); 37 //shortestLen = weight[j]; //shortLen即为最短路径长度 38 return true; 39 } 40 list.add(entry.getKey()); 41 hs.add(entry.getKey()); 42 } 43 } 44 begin++; 45 } 46 return false; 47 } 48 else { 49 return true; 50 } 51 } 52 } 53 else { 54 throw new NodeIdNotFoundException(fromNodeId); 55 } 56 }
野路子BFS(一直野一直爽,把第三次作业直接野出互测)导致的后果就是代码可拓展性很差,存图方式的不恰当导致第三次作业直接彻底重构,所以 祖宗流传下来的BFS等等算法中用邻接矩阵(二维数组)存储图的边是有道理的(祖宗大法好,灾难面前命能保,鼻青脸肿.jpg)
类图:
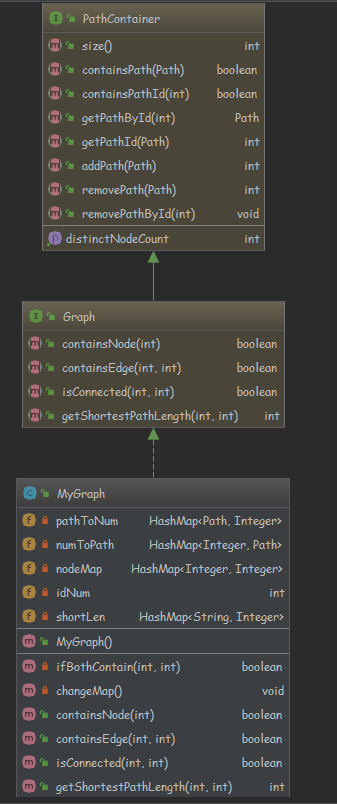
类间层次很清晰,接口方法的继承和扩展如上
复杂度分析:
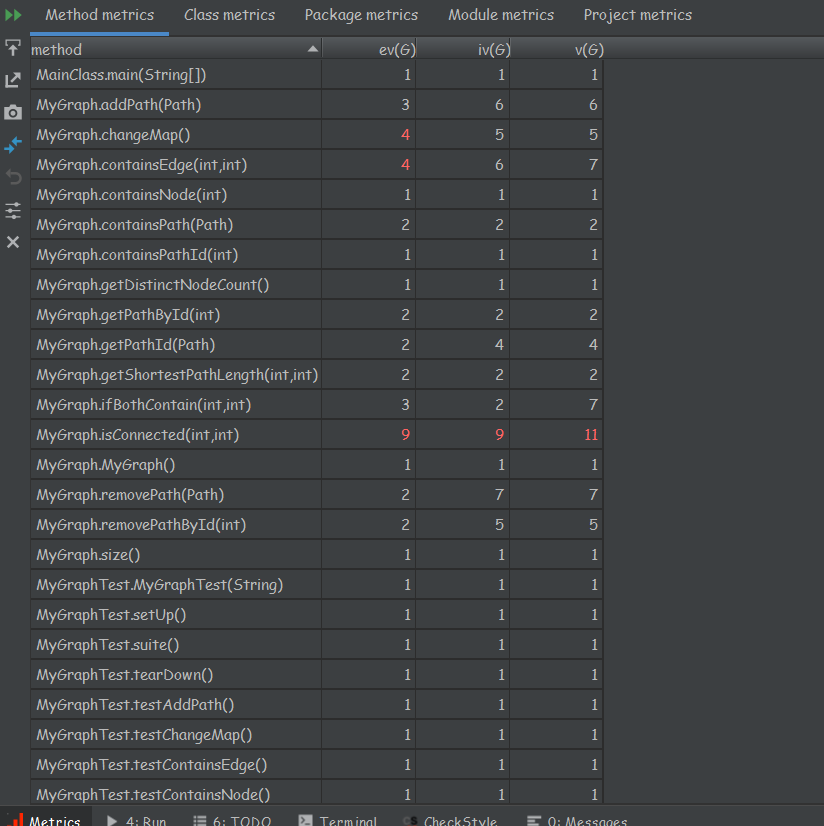
复杂度上,由于接口的设定,方法的分离很到位,所以多数方法内部复杂度很低,简洁明了;但自己写的containEdge与isConnected方法复杂度较高,循环遍历较多,较为暴力故复杂度较高。
同时这也导致了强测的爆炸,需要设置缓存层,存储节点间路径长度等信息,这样查询时就不必再每次都跑一遍大循环,导致程序运行时间过长,cpu时间超时。
3、第三次作业
- 第三次作业需要实现MyPath、MyRailwaySystem类,铁路系统类继承了Graph接口,并新增加了四个主要方法:求最低票价、最少换乘次数、最低不满意度以及连通块个数
- 利用邻接矩阵记录边及边的权重,然后跑floyd算法求解最短路便可逐个击破
- 由于前两次作业对图的处理不到位,未使用邻接矩阵记录图的信息,导致第三次作业很难实现所要求的方法(GG)所以可拓展性需要在莽代码前充分的思考一下
思路如下:
采用邻接矩阵后就需要考虑节点序号不在正数范围的情况,故采用映射的方式将新加入的节点的序号重新排布,将其纳入一定范围内的正整数内,且逐次递增,利用HashMap可轻松完成数与数间的映射
代码如下:
1 private static HashMap<Integer, Integer> nodeMap = new HashMap<>(); 2 3 private static int nodeNum = 0; // nodeNum of map nodeId
每次新的节点的加入,nodeNum++,并利用nodeMap.put(oldNodeId,nodeNum)将其记录下来,同时放入邻接矩阵
利用边的权重的赋值改变求得票价、不满意度、换乘次数,连通块数量可采用并查集思想进行计算
边的权重赋值对应如下:
最低不满意度 F(u) = (int)(u % 5 + 5) % 5, H(u) = pow(4, F(u)) 边E(u,v)的不满意度 UE = max(H(u), H(v)) 每进行一次换乘会产生 UnP = 32 点不满意度 对于一条路径,UPath = sum(UE) + y * Unp, y为换乘次数 存储边权值,权值即为该边的不满意度 UE + 32,将该path构造为完全图 用Floyd算法求带权图最短路 最低票价 存储边权值,权值为该边的票价,即 1 + 2,将该path构造为完全图 用Floyd算法求带权图最短路 最少换乘 存储每个node所在路线号,并存储边权,权值初始化为INFINITY 对于每条path,边权值初始化为1,即不需要换乘,将该path构造为完全图 Floyd算法求最短路,(weight求和 - 1)为最少换乘次数
四、bug修复
第一次作业主要是强测有超时问题,list的contain方法的循环遍历导致了运行时间的过长,选择合适的数据结构管理数据尤为重要
第二次作业同样是存在强测超时的问题,一方面是缺少数据缓存层,另一方面是算法实现过于野。。。
第三次作业由于之前的架构有较为严重的问题(未用邻接矩阵),导致有中测点未过,严重超时,需重构
五、规格撰写相关心得
- 本单元的JML与代码间的相互约束,让我编程的逻辑更加严谨清晰
- 可靠的JML可以使得开发人员对方法的理解更深,不会因为自然语言的二义性导致问题,同时让你清楚地看到代码如何书写
- 同时本单元的作业对于程序的性能有了进一步的考验,算法优化真滴重要,不能因为代码量冗长抑或任务简单就忽略了算法的重要性

 浙公网安备 33010602011771号
浙公网安备 33010602011771号