【源码剖析】Mybatis 详解

在之前的博文中,本人分别讲解了 Spring、Spring MVC 的核心源码
那么,在本篇博文中,本人就来讲解下 Mybatis 的核心源码:
本人先来给出一个 API使用案例:
API调用:
首先是 实体类(O):
实体类(O):
package edu.youzg.pojo;
import java.io.Serializable;
public class Account implements Serializable {
private Integer id;
private String name;
private Integer money;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getMoney() {
return money;
}
public void setMoney(Integer money) {
this.money = money;
}
@Override
public String toString() {
return "Account{" +
"id=" + id +
", name='" + name + '\'' +
", money=" + money +
'}';
}
}
接着是 mapper(R):
mapper(R):
AccountMapper 类:
package edu.youzg.mapper;
import edu.youzg.pojo.Account;
public interface AccountMapper {
Account selectById(Integer id);
}
AccountMapper.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="edu.youzg.mapper.AccountMapper">
<!--开启 二级缓存-->
<cache/>
<resultMap id="result" type="edu.youzg.pojo.Account">
<id column="id" jdbcType="INTEGER" property="id"/>
<result column="name" jdbcType="VARCHAR" property="name"/>
<result column="money" jdbcType="INTEGER" property="money"/>
</resultMap>
<select id="selectById" resultMap="result">
select id,name,money from account
<where>
<if test="_parameter > 0">
and id=#{_parameter}
</if>
</where>
</select>
</mapper>
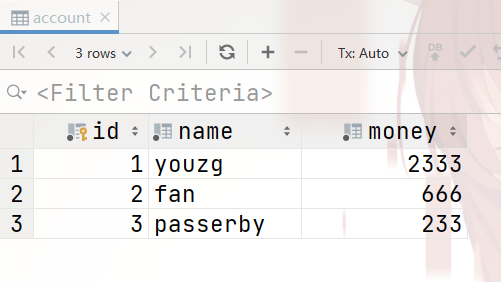
接着是 数据库信息(M):
数据库信息(M):
然后是 配置类:
配置类:
db.properties:
mysql.driverClass=com.mysql.cj.jdbc.Driver
mysql.jdbcUrl=jdbc:mysql://localhost:3306/explore_source?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8
mysql.user= root
mysql.password= 123456
mybatis-config.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<properties resource="db.properties"></properties>
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${mysql.driverClass}"/>
<property name="url" value="${mysql.jdbcUrl}"/>
<property name="username" value="${mysql.user}"/>
<property name="password" value="${mysql.password}"/>
</dataSource>
</environment>
</environments>
<mappers>
<package name="edu/youzg/mapper"/>
</mappers>
</configuration>
最后,是 测试类:
测试类:
package edu.youzg.demo;
import edu.youzg.mapper.AccountMapper;
import edu.youzg.pojo.Account;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import java.io.IOException;
import java.io.Reader;
/**
* @Author: Youzg
* @CreateTime: 2021-03-28 14:29
* @Description: 带你深究Java的本质!
*/
public class YouzgDemo {
public static void main(String[] args) {
String resource = "mybatis-config.xml";
Reader reader;
try {
//将XML配置文件构建为Configuration配置类
reader = Resources.getResourceAsReader(resource);
// 通过加载配置文件流构建一个SqlSessionFactory DefaultSqlSessionFactory
SqlSessionFactory sqlMapper = new SqlSessionFactoryBuilder().build(reader);
// 数据源 执行器 DefaultSqlSession
SqlSession session = sqlMapper.openSession();
try {
// 获取mapper代理
AccountMapper mapper = session.getMapper(AccountMapper.class);
// 执行查询 底层执行jdbc
Account account = mapper.selectById(2);
session.commit();
System.out.println(account);
} catch (Exception e) {
e.printStackTrace();
} finally {
session.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
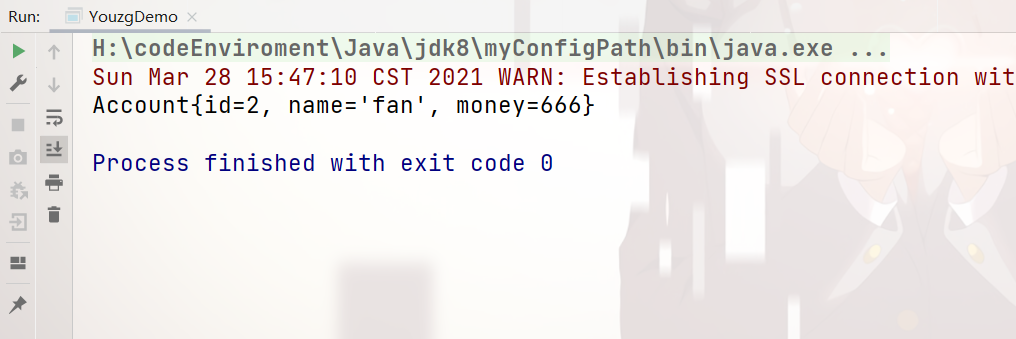
那么,本人来展示下 运行结果:
接下来,本人就来讲解下 Mybatis 的核心源码:
首先,本人来通过 一张图,来展示下 Mybatis 的 功能架构:
功能架构:
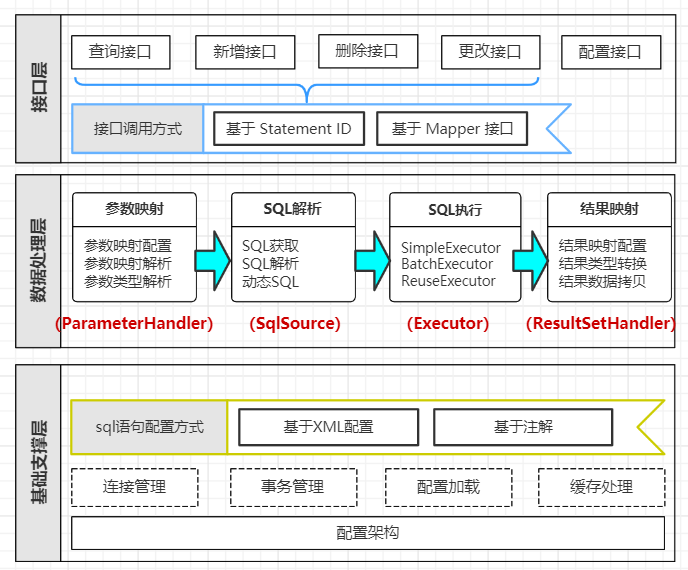
从上图中,我们也能看出:
我们所有的 SQL执行,都是 基于Statement 的
因此,Mybatis的核心源码,可分为 解析配置信息、执行SQL 两大类
那么,本人先来讲讲 解析配置信息 这部分代码:
解析配置信息:
我们从上面的 测试类 中可以看得出:
读取 配置类,并进行 解析 是在
//将XML配置文件构建为Configuration配置类
reader = Resources.getResourceAsReader(resource);
// 通过加载配置文件流构建一个SqlSessionFactory DefaultSqlSessionFactory
SqlSessionFactory sqlMapper = new SqlSessionFactoryBuilder().build(reader);
的 代码块 中进行的
其实,主要的 解析操作,还是靠
SqlSessionFactory sqlMapper = new SqlSessionFactoryBuilder().build(reader);
这行代码执行的
那么,我们来看看 build()方法 做了什么:
解析 配置内容 —— build()方法:

我们可以看到:
这是一个 包装方法,并没有什么 执行逻辑
我们跟进去,来看看具体是怎么实现的:
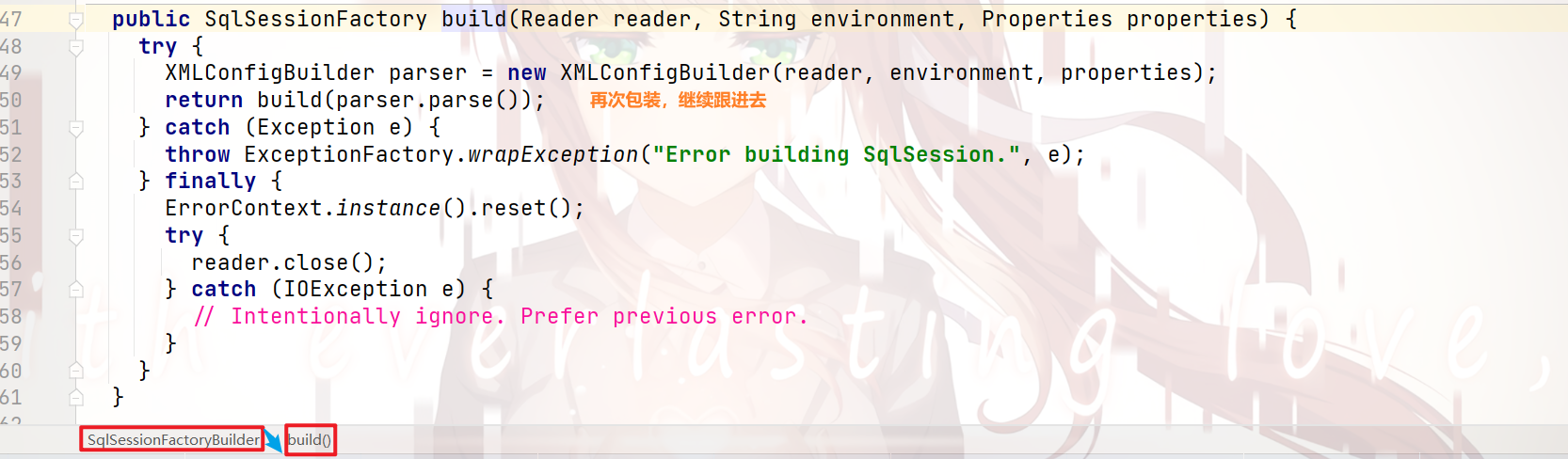
我们继续跟进去:

我们可以看到:
build()方法 本质上 创建了一个 DefaultSqlSessionFactory类 对象,并且将配置类中的所有内容,注册到了 DefaultSqlSessionFactory类 对象 中
那么,build()方法 的参数 Configuration类 的构成是什么呢?
配置内容 的 封装 —— Configuration类:
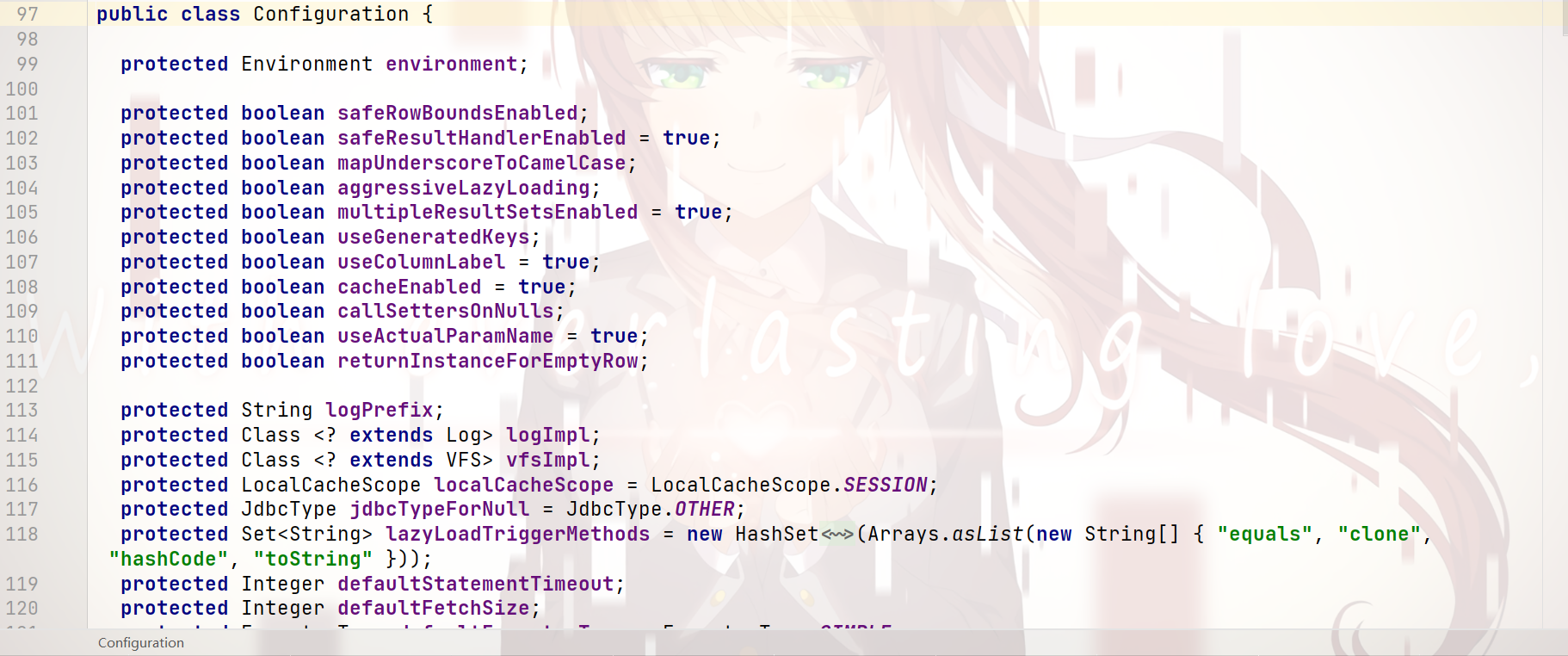
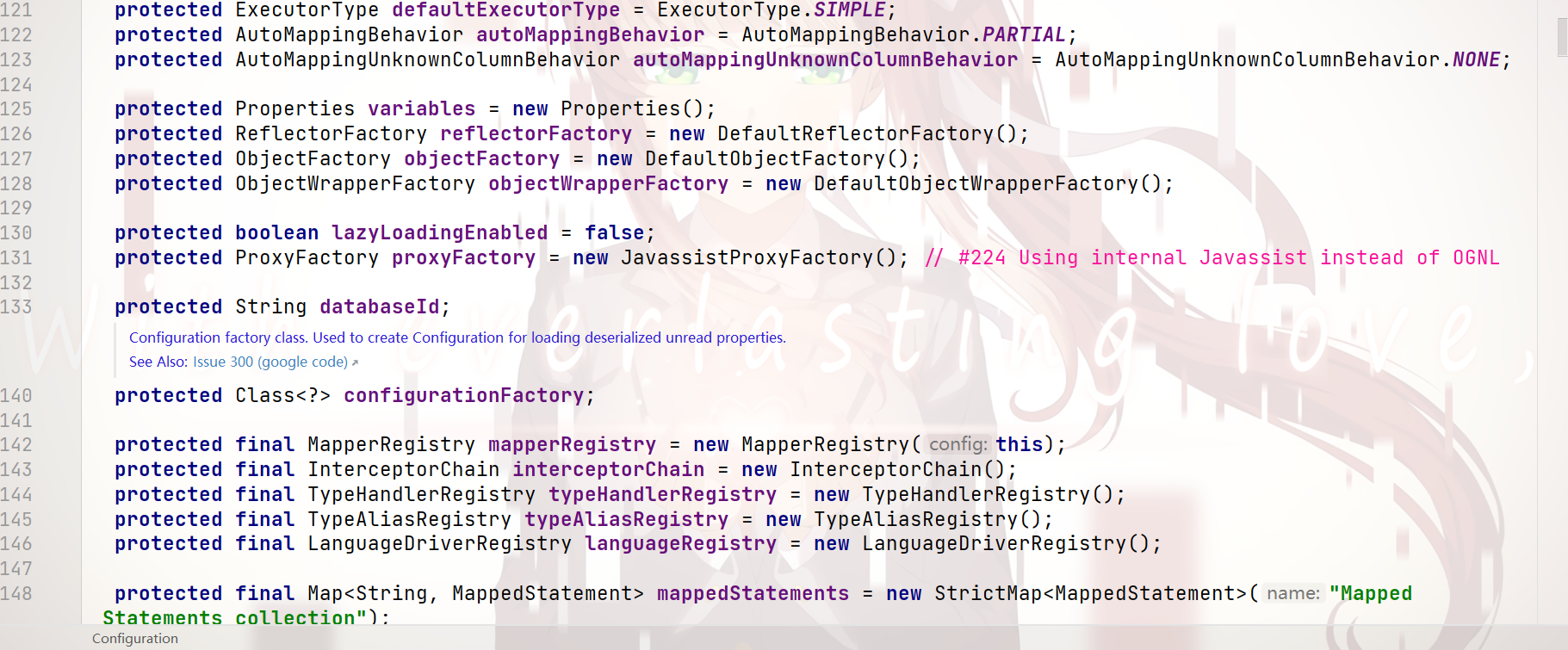
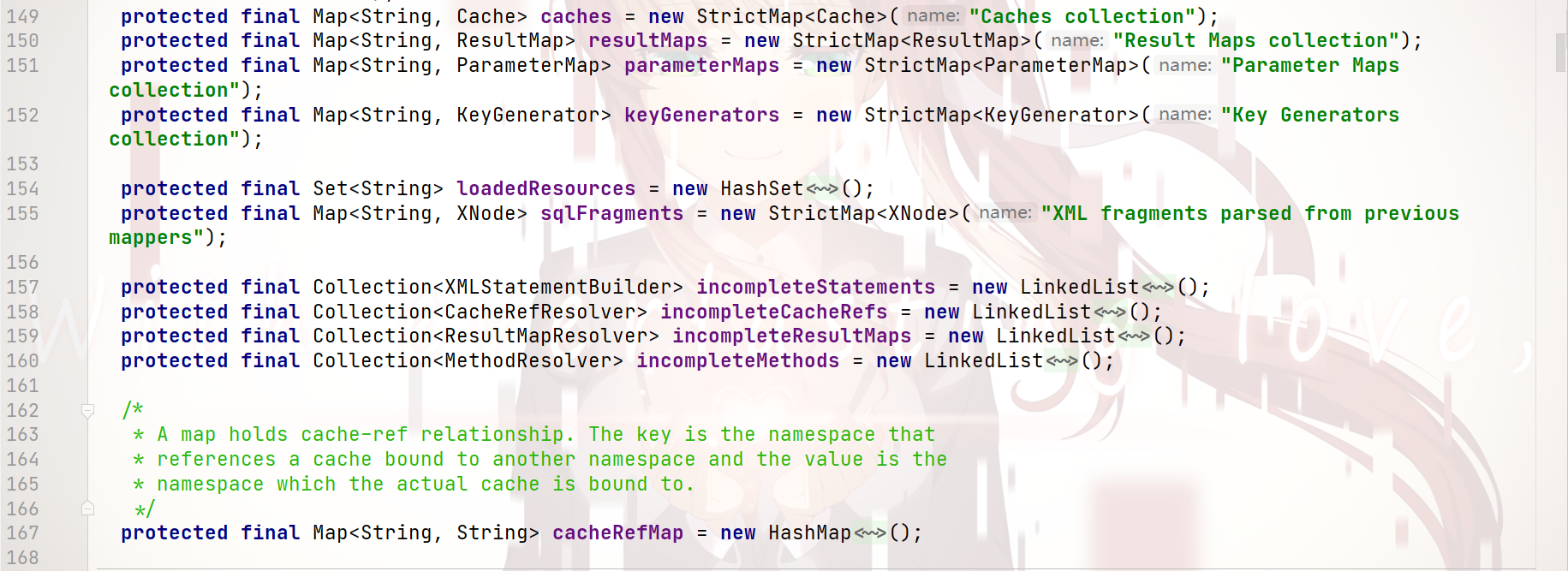
可以看到:
基本上 所有配置文件的信息 都可以封装在 Configuration类 中
而 这个 Configuration类 对象,是 通过调用 XMLConfigBuilder类 的 parse()方法 解析得出
那么,本人来展示下 parse()方法 的内容:
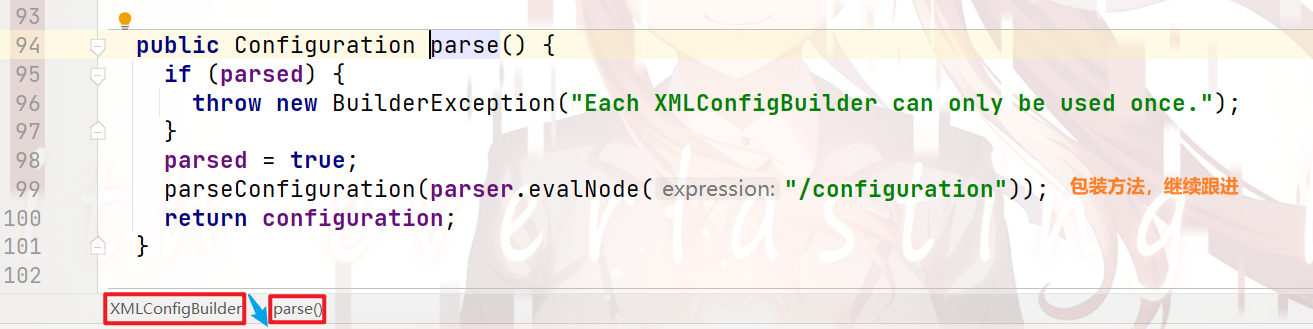
封装 配置信息 —— parseConfiguration()方法:
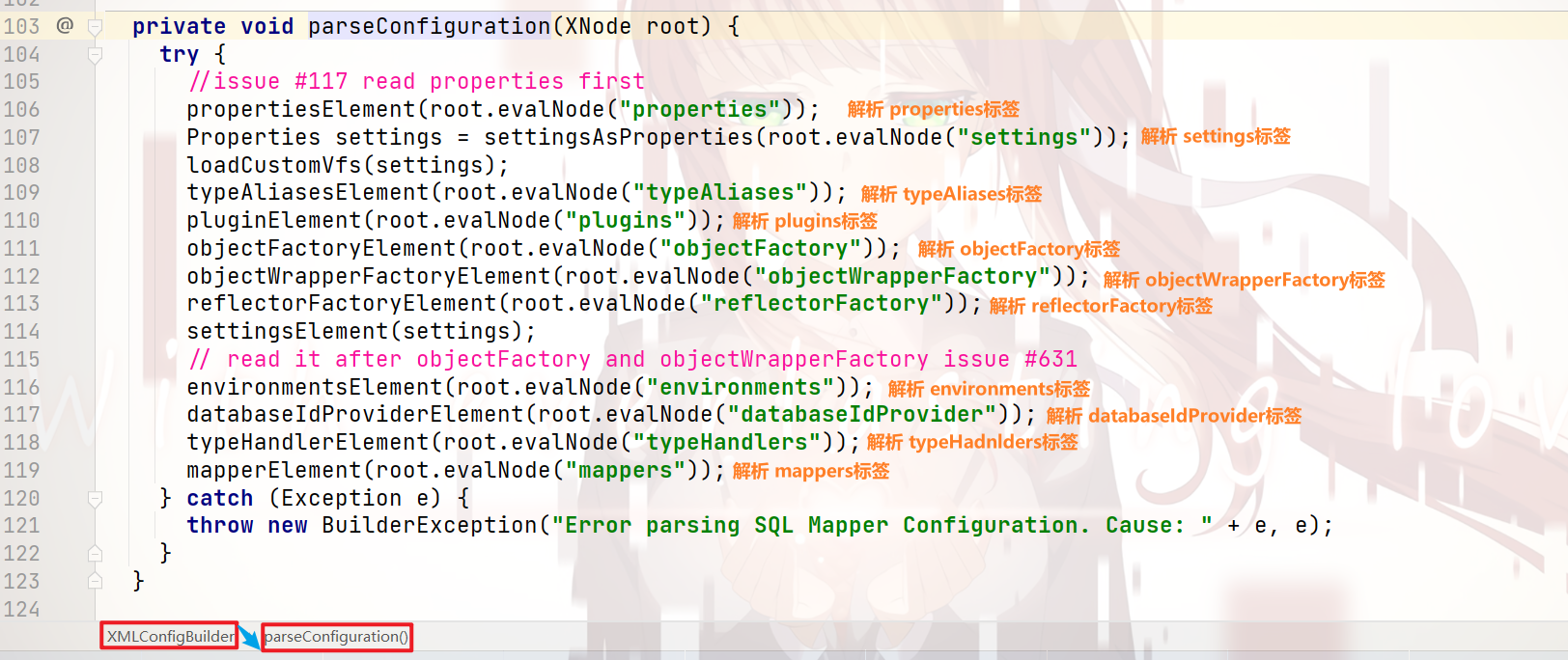
那么,具体是怎么解析的呢?
我们来看下几个比较常用的配置的解析:
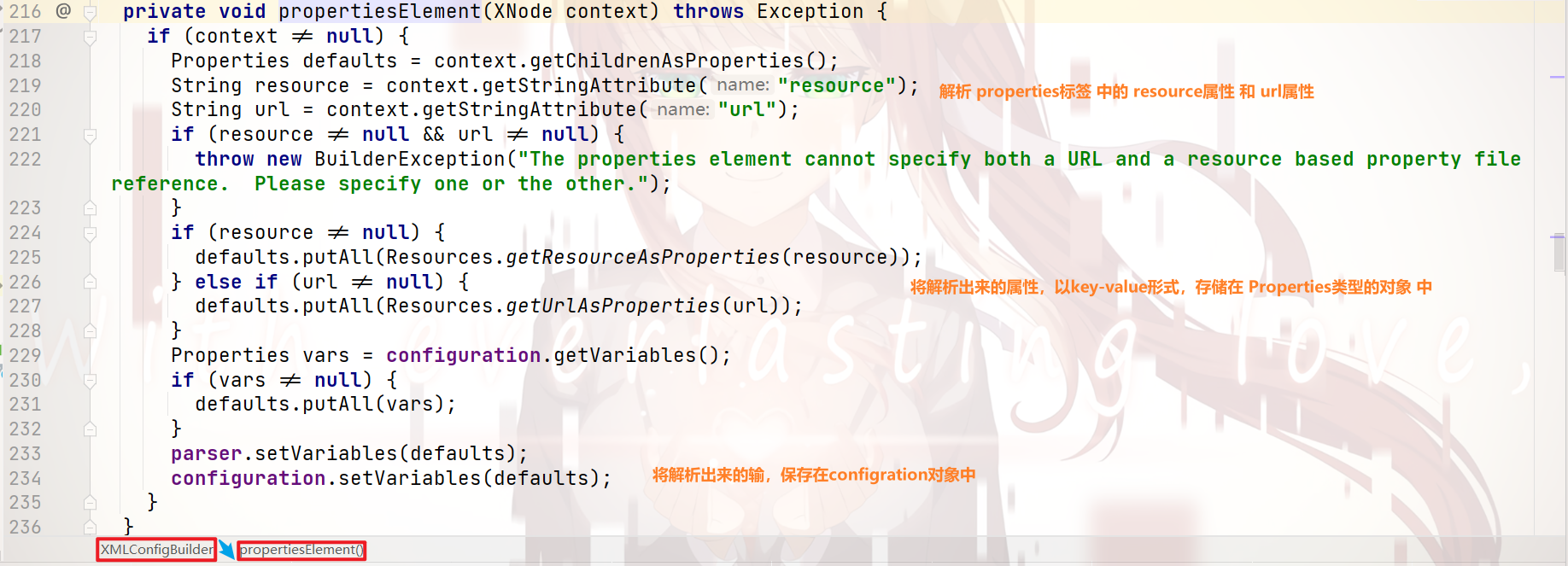
propertiesElement标签 的 解析:
typeAliase标签 的 解析:
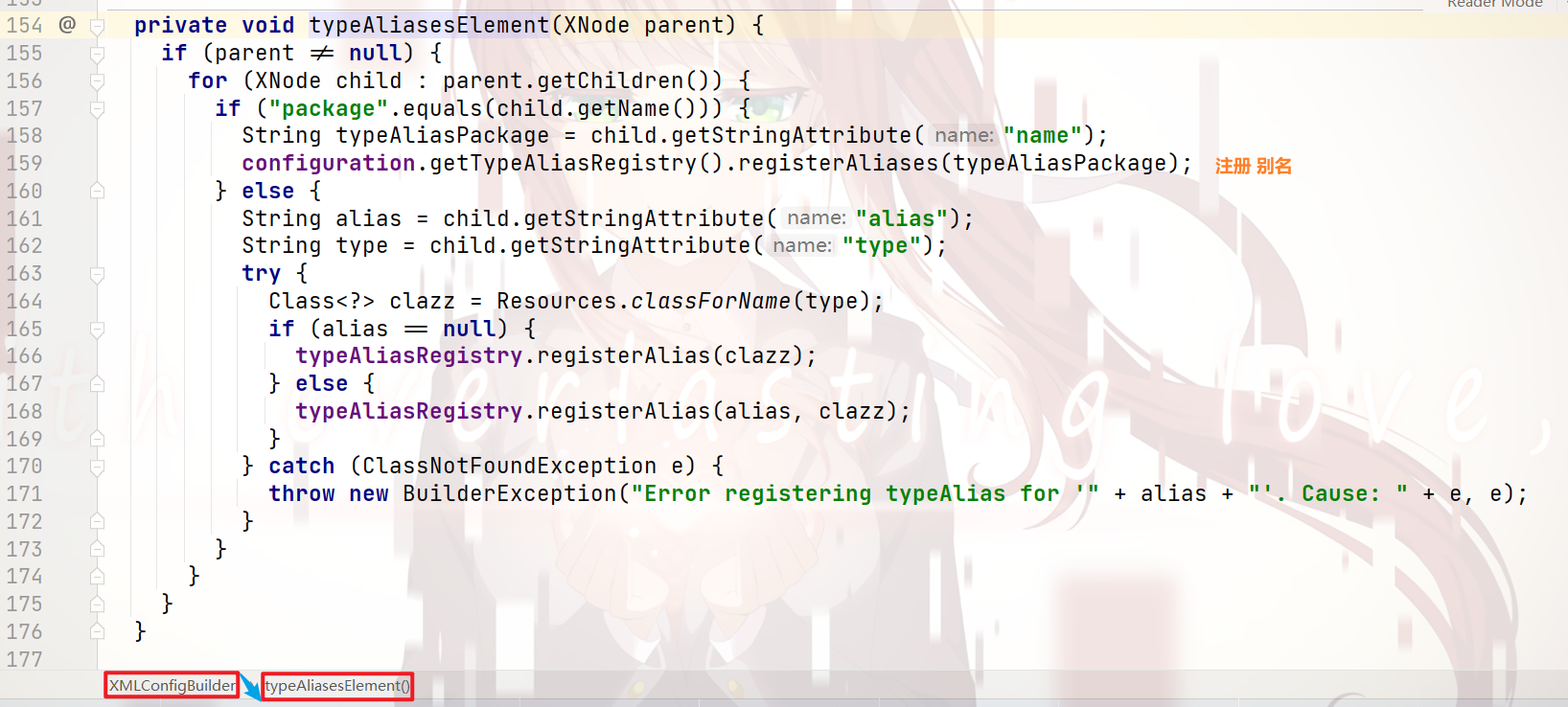
我们一直跟下去,就会看到如下代码:
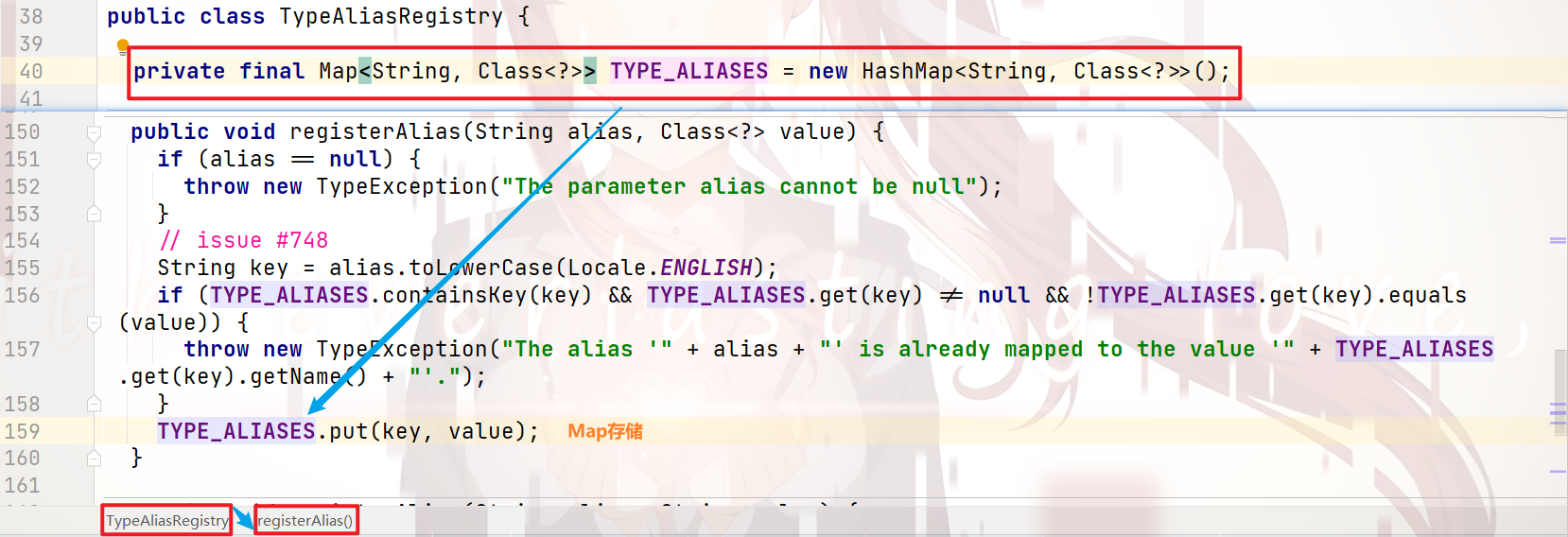
environments标签 的 解析:
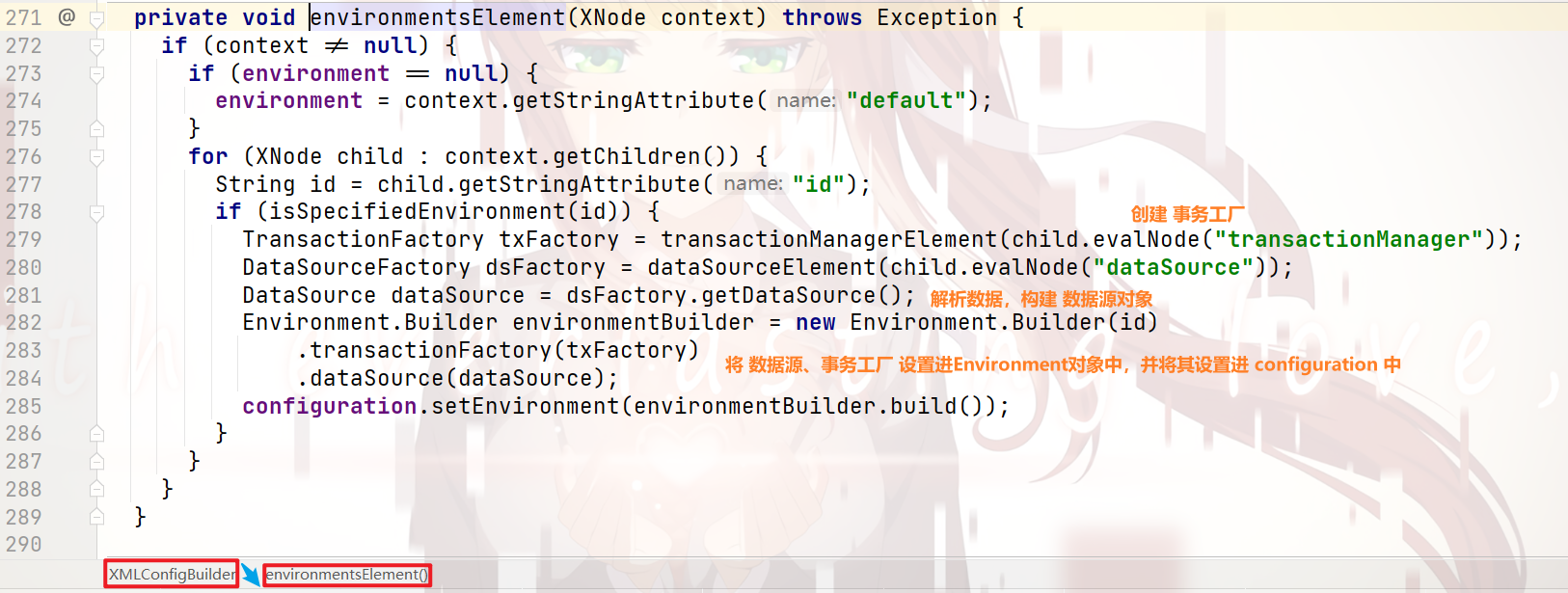
mappers标签 的 解析:

那么,我们再来看看
mapperParser.parse();
这行代码,底层是如何实现的:
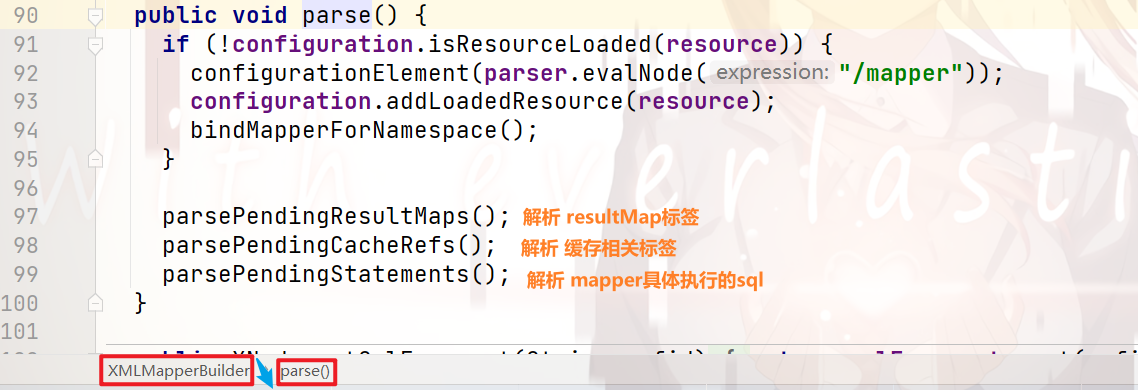
那么,至此,配置信息就解析完毕了!
本人再来总结下 解析配置信息 的流程:
解析配置 流程图:
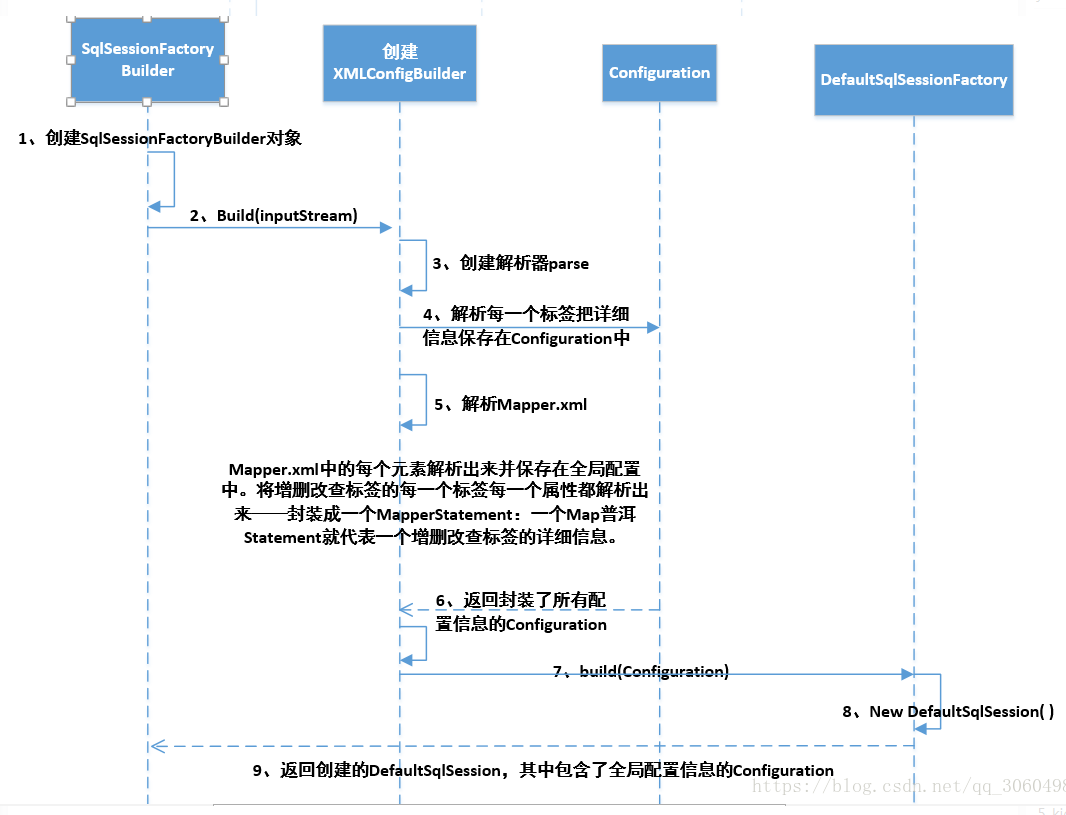
在我们 解析完配置 后,就到了 获取SqlSession 的环节了:
获取 SqlSession:

我们可以看到:这是一个 包装方法,我们继续跟进去:
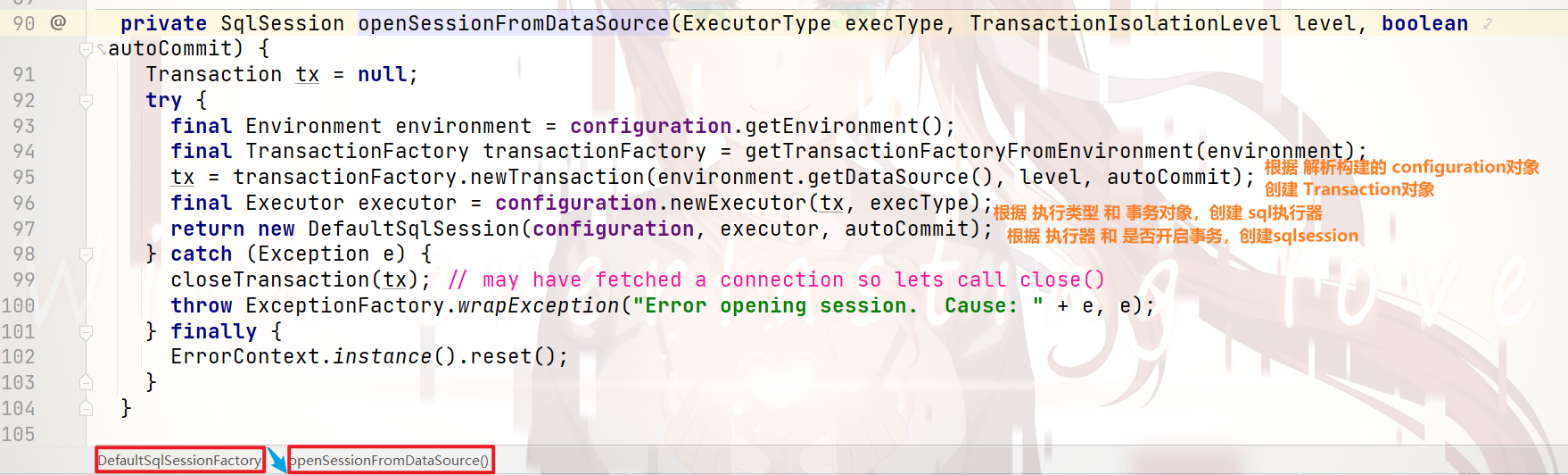
我们来看看 上图中 96行 代码,发生了什么:
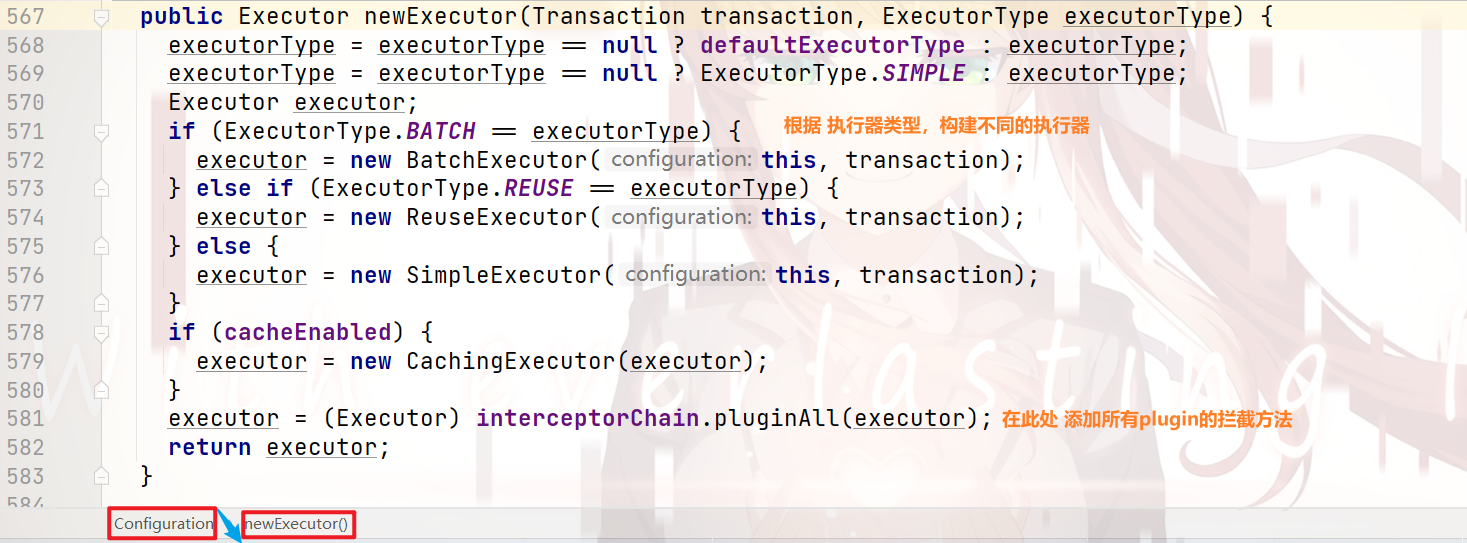
可以看到:
执行器 根据 设置的类型 构建
在这里,本人要提醒的一点是:
本方法中,使用了
装饰器的 设计模式
那么,这 四种执行器,有什么 区别 呢?
本人将在 文末 进行讲解!
那么,本人在这里,通过一张图总结下 获取sqlsession 的流程图:
获取sqlsession 流程图:
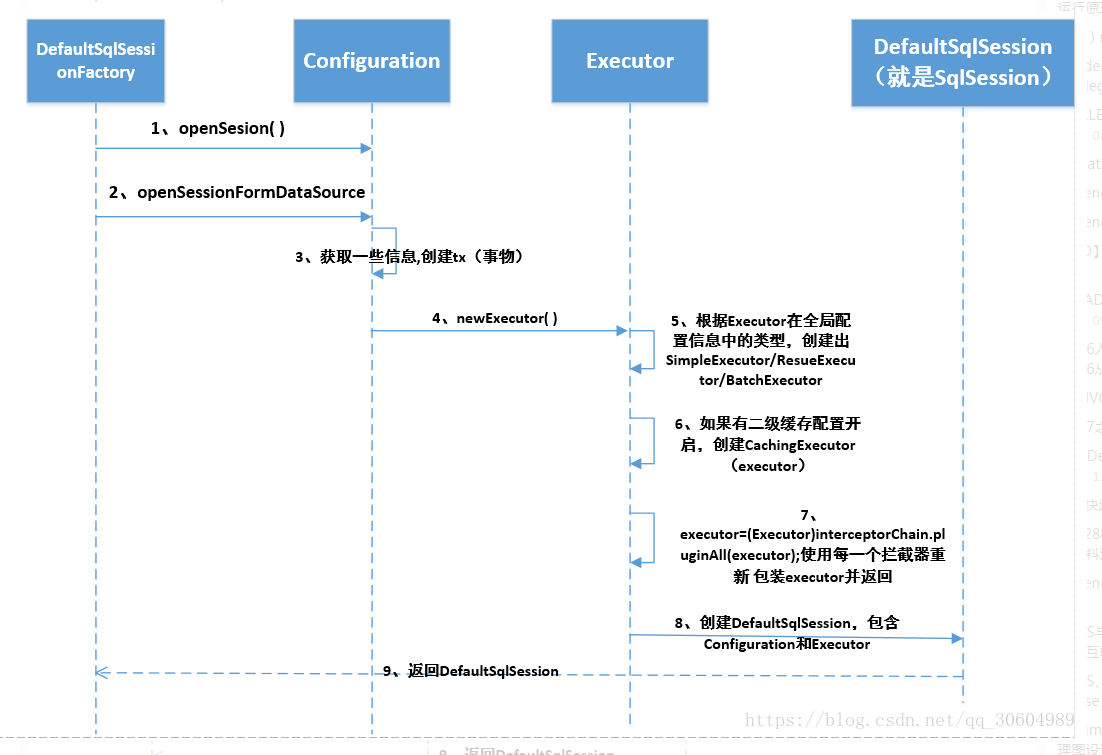
在上面的代码中,解析了配置,创建了sqlsession
接下来,本人就讲解下 获取mapper 的过程:
获取 mapper代理:
我们来跟进示例代码的 32行:

我们来跟进看看是不是 在Map中查询的:

我们继续跟进:
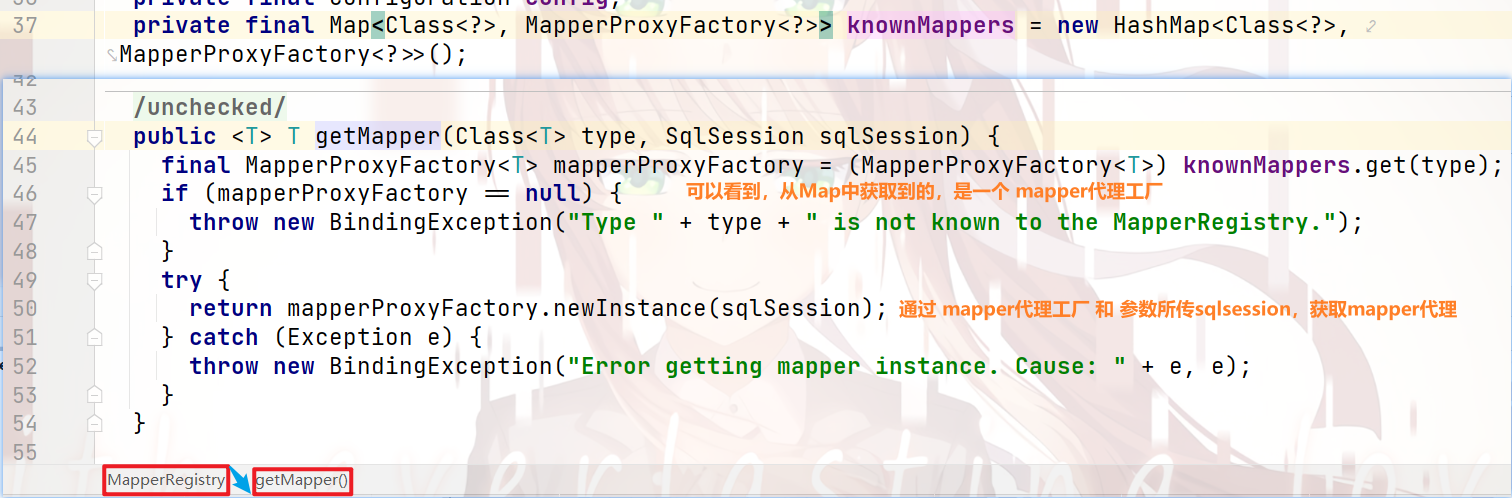
我们可以看到:
在底层,是通过 接口类型,获取 对应的mapper代理工厂
之后,通过 对应的mapper代理工厂 和 参数所传sqlsession 创建了 mapper代理
那么,本人在这里,通过一张图总结下 获取mapper 的流程图:
获取mapper代理 流程图:
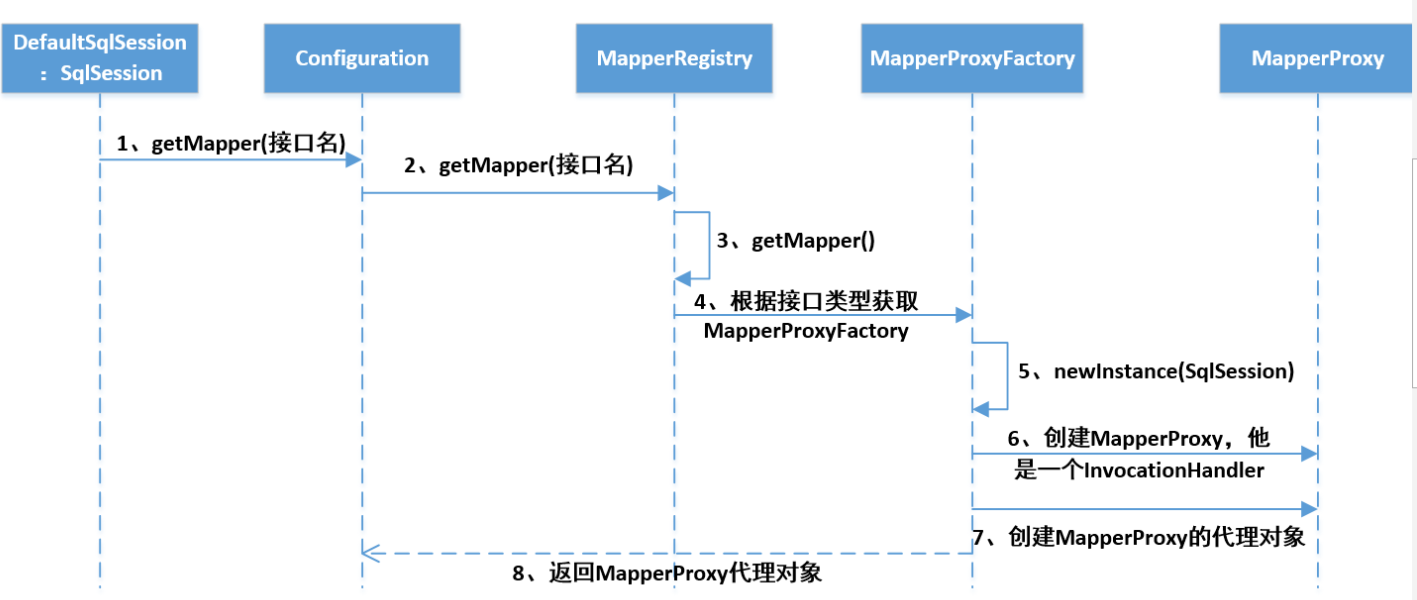
最后,本人就讲解下 调用执行sql 的过程:
调用执行sql:
本人在 示例代码 的 35行 打上断点,来看看具体是怎么执行的:
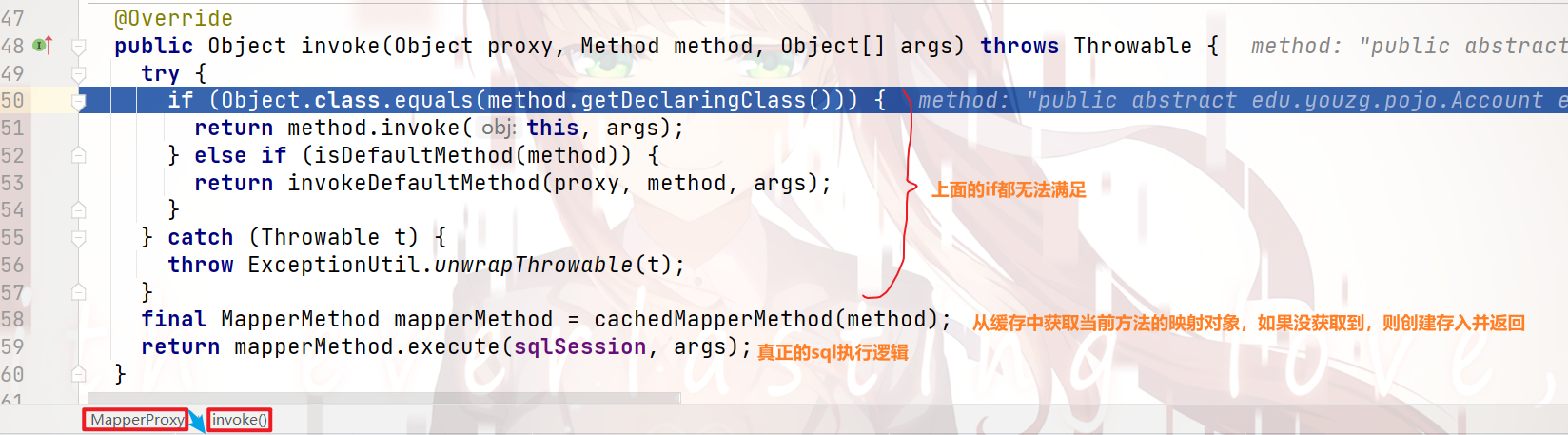
跟着断点执行,就会发现:
上面方法真正执行的是 最下面两行代码
获取缓存映射对象 —— cachedMapperMethod()方法:

那么,从缓存中获取之后,我们再来看看之后会如何执行:
sql执行原生API 的调用 —— execute()方法:
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
switch (command.getType()) { // 根据sql类型,分别进行不同的执行流程
case INSERT: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
case UPDATE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.update(command.getName(), param));
break;
}
case DELETE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.delete(command.getName(), param));
break;
}
case SELECT:
if (method.returnsVoid() && method.hasResultHandler()) {
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) {
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) {
result = executeForMap(sqlSession, args);
} else if (method.returnsCursor()) {
result = executeForCursor(sqlSession, args);
} else {
Object param = method.convertArgsToSqlCommandParam(args); // 转换参数
result = sqlSession.selectOne(command.getName(), param); // 调用sqlsession的api
}
break;
case FLUSH:
result = sqlSession.flushStatements();
break;
default:
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
}
可以看到:
执行流程,先 转换了参数,然后 调用sqlsession的sql执行API
我们继续往下跟:
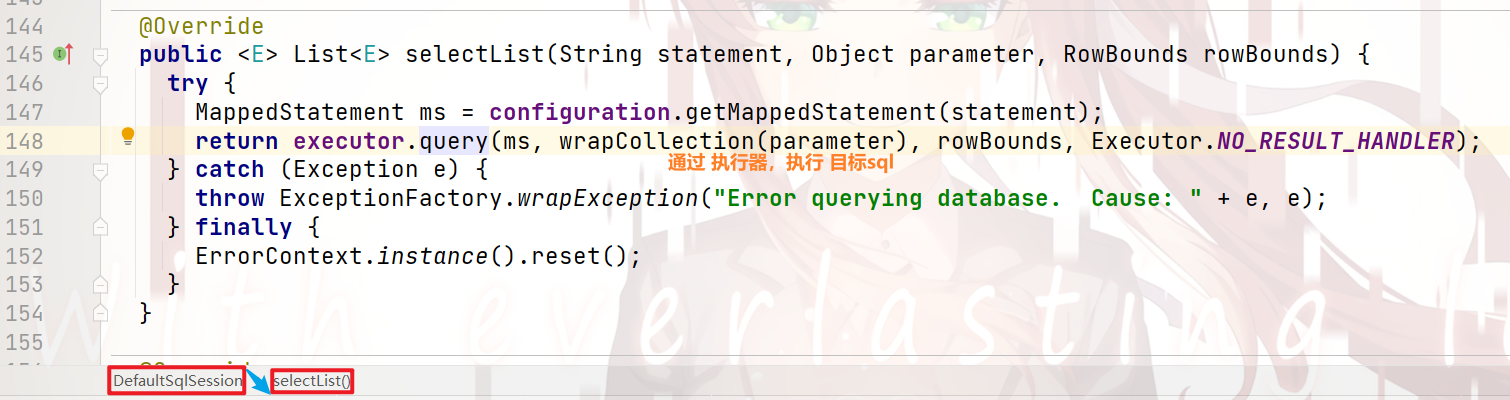
在上一步中,调用了 executor 的 query()方法
但是,此处的 executor 并不是 JDBC提供的,而是 封装继承JDBC所提供的executor
那么,缓存的功能,在底层是如何实现的呢?
缓存的实现(仅 配置开启缓存) —— executor的使用:
我们来跟着断点,来看看 是如何实现缓存的:
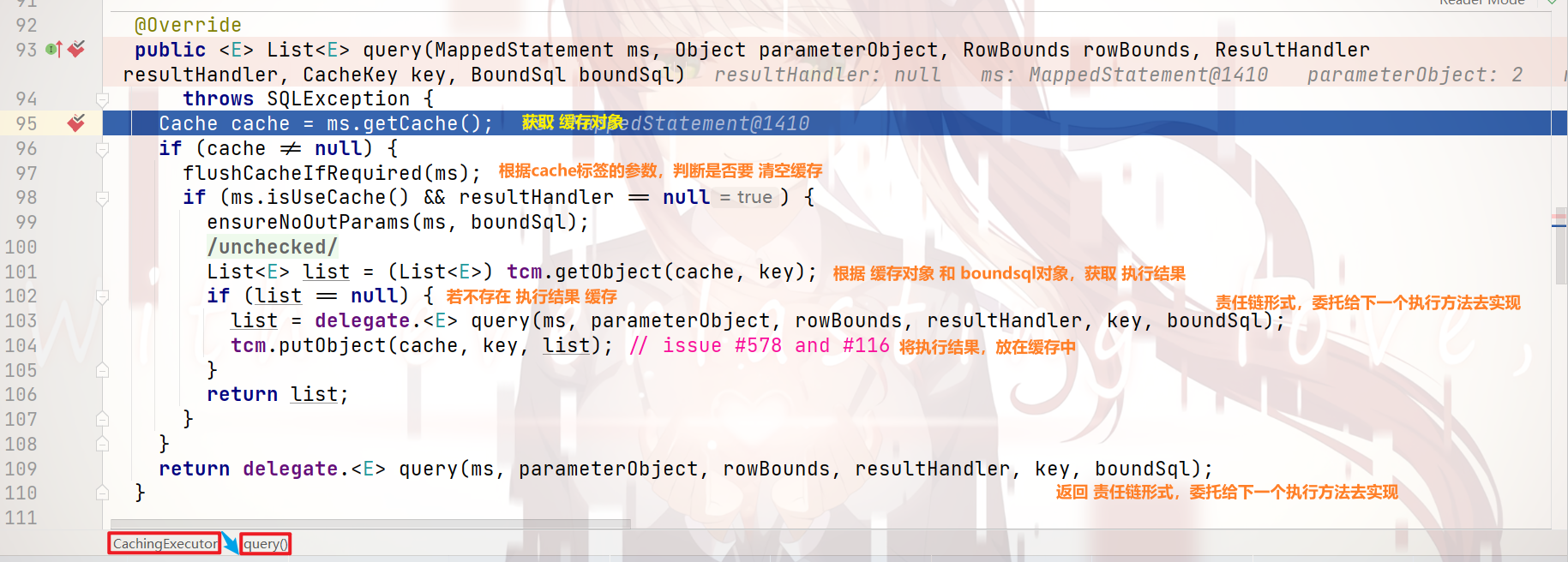
在上图中,我们可以看出:
若我们 开启了缓存,
当 查询 时,就会先从缓存中获取
若 没有取到,则会交由 真正的执行sql执行器 去执行,并将 执行结果 存入 二级缓存 中
我们来跟进上图中 101行 代码:

我们可以看到:这是一个 包装方法
继续跟进:
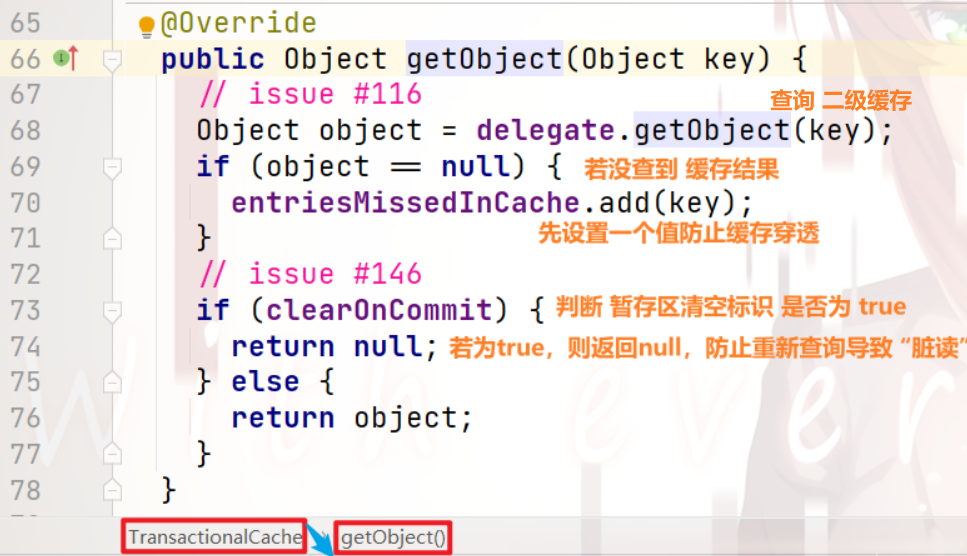
我们可以看到:
首先,查询了 二级缓存
然后,若没查到,就设置一个值 防止 缓存穿透
再 根据 标识,决定是否返回 缓存中查询到的信息
顺带一提:
当我们执行 增删改 操作时,底层会调用如下方法:

我们能看到:
当执行 增、删、改 操作 时,就会 清空缓存
到此,相信就能完全验证本人之前博文《【Mybatis框架 学习】缓存 详解》的内容!
那么,本人在这里,通过一张图总结下 调用执行sql 的流程图:
调用执行sql 流程图:
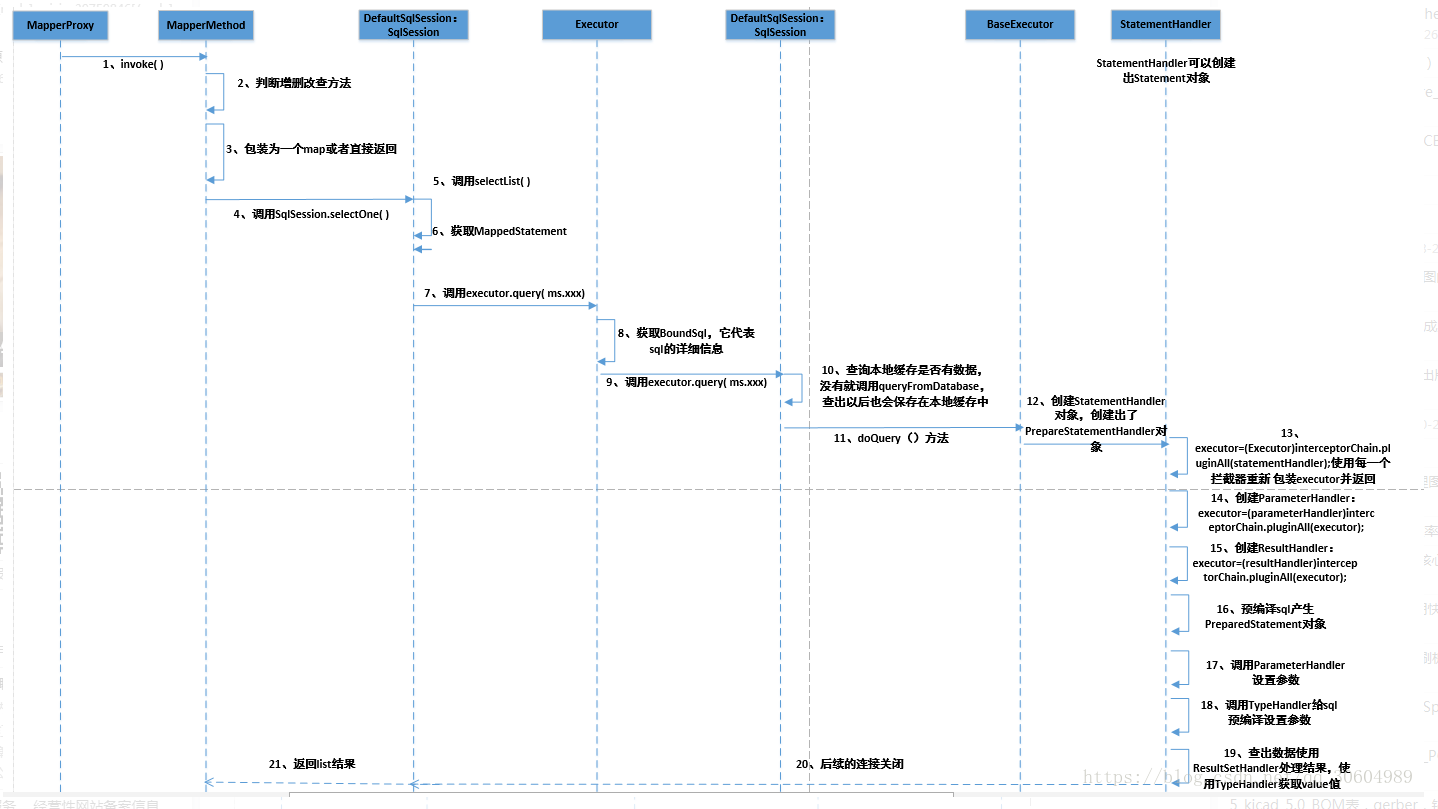
在上文中,本人也有一些问题留在文末进行讲解
那么,本人来总结讲解下 这些问题:
问题讲解:
四种执行器 有什么区别?
答曰:
SimpleExecutor:
每执行一次 update 或 select,就 开启一个Statement对象,用完立刻关闭 Statement对象ReuseExecutor:
执行 update 或 select,以 sql作为key 查找Statement对象,存在就使用,不存在就创建,
用完后,不关闭Statement对象,而是放置于Map<String, Statement>内,供下一次使用
简言之,就是 重复使用Statement对象BatchExecutor:
执行 update(没有select,JDBC批处理不支持select),将 所有sql 都添加到 批处理 中(addBatch()),等待 统一执行(executeBatch()),
它 缓存 了 多个Statement对象,每个Statement对象 都是 addBatch()完毕 后,等待 逐一执行executeBatch()批处理
与 JDBC批处理 相同CacheExecutor:
其实是封装了普通的Executor,
和 普通的 区别 是:在查询前先会查询缓存中是否存在结果,
- 如果 存在,就 使用 缓存 中的结果,
- 如果 不存在,还是 使用 普通的Executor 进行查询,再将查询出来的 结果 存入 缓存
在我们学习 Mybatis 时,了解过 防止缓存溢出 的 几大移除策略
那么,本人在这里讲解下 这些策略 的 底层实现:
缓存移除 策略:
SynchronizedCache:
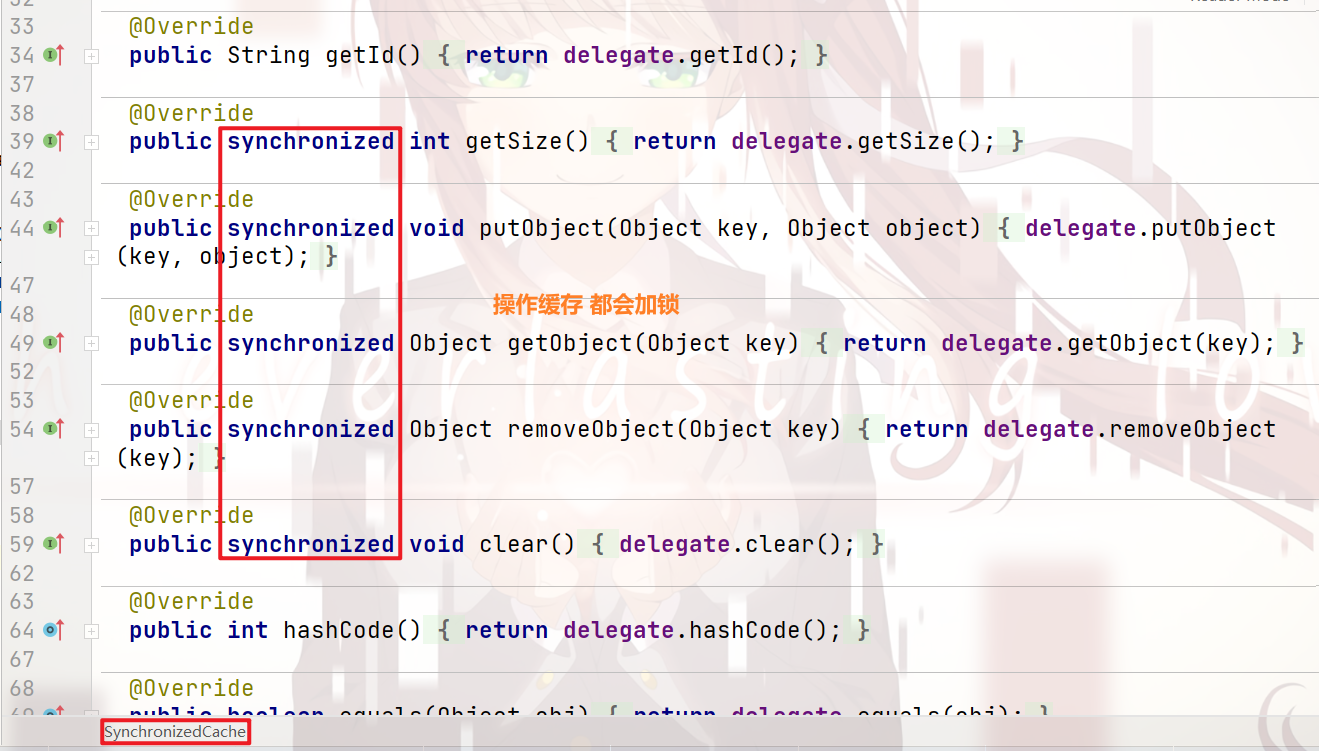
我们可以看到:
凡是 操作缓存 的方法,都加上了 synchronized关键字,保证了 线程安全
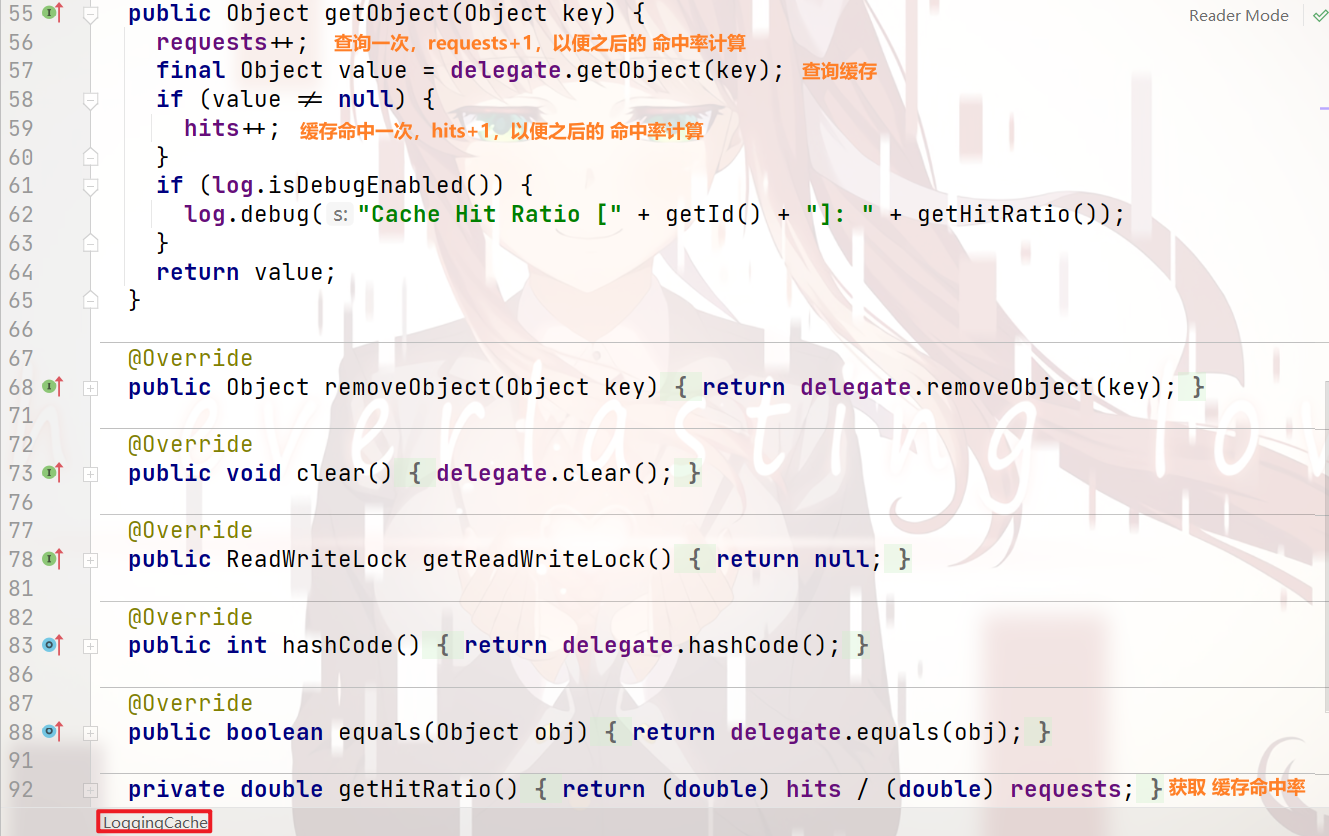
统计命中率以及打印日志 —— LoggingCache:
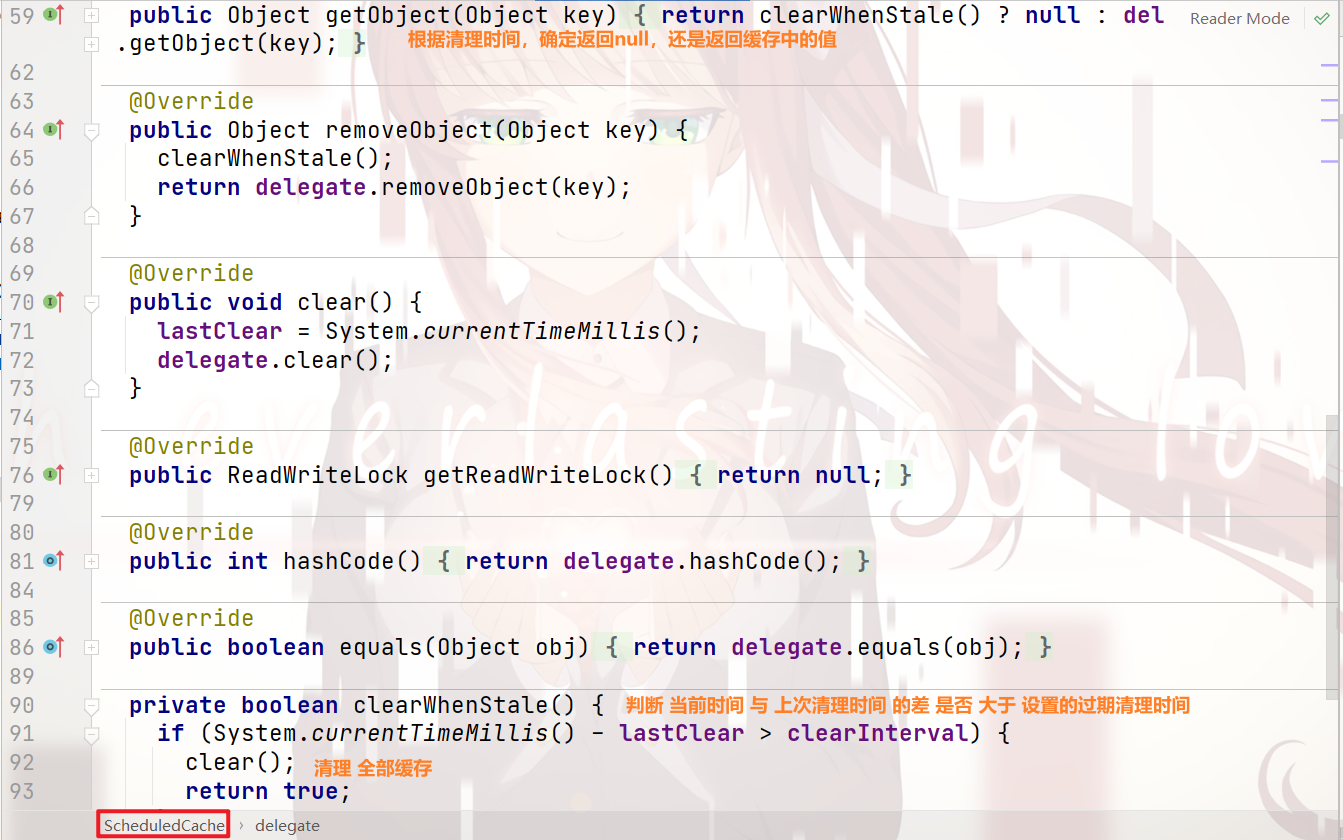
过期清理缓存区 —— ScheduledCache:
最近最少使用 —— LruCache:
public class LruCache implements Cache {
private final Cache delegate;
private Map<Object, Object> keyMap;
private Object eldestKey;
public LruCache(Cache delegate) {
this.delegate = delegate;
setSize(1024);
}
@Override
public String getId() {
return delegate.getId();
}
@Override
public int getSize() {
return delegate.getSize();
}
public void setSize(final int size) {
keyMap = new LinkedHashMap<Object, Object>(size, .75F, true) {
private static final long serialVersionUID = 4267176411845948333L;
@Override
protected boolean removeEldestEntry(Map.Entry<Object, Object> eldest) {
boolean tooBig = size() > size;
if (tooBig) {
eldestKey = eldest.getKey();
}
return tooBig;
}
};
}
@Override
public void putObject(Object key, Object value) {
delegate.putObject(key, value); // 向 缓存 中 添加 新键值对
cycleKeyList(key); // 判断是否 要删除最久键值对
}
// 每次访问,都会遍历一次key进行重新排序,将访问元素放到链表尾部。
@Override
public Object getObject(Object key) {
keyMap.get(key); // 更新最后访问时间
return delegate.getObject(key); // 从缓存中,获取key代表的键值对的值
}
@Override
public Object removeObject(Object key) {
return delegate.removeObject(key); // 删除 指定key的键值对
}
@Override
public void clear() {
delegate.clear(); // 清空 责任链列表
keyMap.clear(); // 清空 keyMap
}
@Override
public ReadWriteLock getReadWriteLock() {
return null;
}
private void cycleKeyList(Object key) {
keyMap.put(key, key);
if (eldestKey != null) {
delegate.removeObject(eldestKey); // 删除 最久未访问的key 的键值对
eldestKey = null; // 将 eldestKey 置为 null
}
}
}
说到 LRU,那可是 面试常问点
在 Mybatis 中,实现也很简单 —— 利用 LinkedHashMap 的性质:
- 当 添加新元素 时,调用removeEldestEntry()方法,若返回true,则 删除最久未使用的元素
- 当 访问一个元素 时,会将 当前键值对 放于 链表末尾(更新最后访问时间)
希望同学们在看完本人的解析后,能有所感悟!
先进先出 —— FifoCache:
public class FifoCache implements Cache {
private final Cache delegate;
private final Deque<Object> keyList;
private int size;
public FifoCache(Cache delegate) {
this.delegate = delegate;
this.keyList = new LinkedList<Object>();
this.size = 1024;
}
@Override
public String getId() {
return delegate.getId();
}
@Override
public int getSize() {
return delegate.getSize();
}
public void setSize(int size) {
this.size = size;
}
@Override
public void putObject(Object key, Object value) {
cycleKeyList(key); // 先 判断是否超出范围
delegate.putObject(key, value); // 再 向缓存中添加键值对
}
@Override
public Object getObject(Object key) {
return delegate.getObject(key);
}
@Override
public Object removeObject(Object key) {
return delegate.removeObject(key);
}
@Override
public void clear() {
delegate.clear();
keyList.clear();
}
@Override
public ReadWriteLock getReadWriteLock() {
return null;
}
private void cycleKeyList(Object key) {
keyList.addLast(key); // 将 新元素的键,放入keyList的末尾
if (keyList.size() > size) {
Object oldestKey = keyList.removeFirst(); // 获取 最早入队的键
delegate.removeObject(oldestKey); // 删除 最早的键值对
}
}
}
FIFO策略 的 实现步骤,和 LRU策略 的实现步骤十分类似:
录入前,先判断是否 超出范围,若 超出范围,则 先删除最早的键值对,再添加新键值对
那么,至此,Mybatis 的核心源码,就解读完毕了!
写了这么多篇 SSM 框架 的源码解读博文,最后才发现 Mybatis的源码反而是最简单易懂的
那么,秋招前可能不会再更新博文了,也可能在学习一些很重要的知识点时想要深挖会写几篇
在得闲时,本人会继续写些更有价值的博文,觉得有帮助的提醒不要吝啬关注和赞哦!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号