【源码剖析】Spring IOC 详解

在本人之前的博文中,分别讲述了 Spring框架 的 Ioc功能 的 API调用 和 自主实现流程
作为一款当今各大企业都在使用的 框架,本人的实现相对于真正的 Spring Ioc 来讲,相差甚远
那么,在本篇博文中,本人就来讲解下:在 Spring框架 中,Ioc功能 具体是如何实现的
那么,为了照顾到 初学的同学
在讲解 Spring IOC 的 源码 之前,本人先来回答几个问题:
问题:
为什么要将类实例的创建,交给容器来完成?
答曰:
交由容器来完成,方便我们对这些bean进行管理
为什么容器实现实例的创建,方便我们控制呢?
答曰:
举一个简单的例子:
有一个类的实例对象,在100个类中进行了创建
那么,如果这个对象的 构造函数 不得不做些 改变,我们就需要去改变这100个类的代码
但是,我们交由Spring容器来创建的话,就可以只改动一个类(Bean Configration)的代码
现在,本人就来讲解下 Spring IOC 的相关 源码:
在讲解IOC源码之前,本人先来展示下 IOC 的 总体流程图:
流程图:
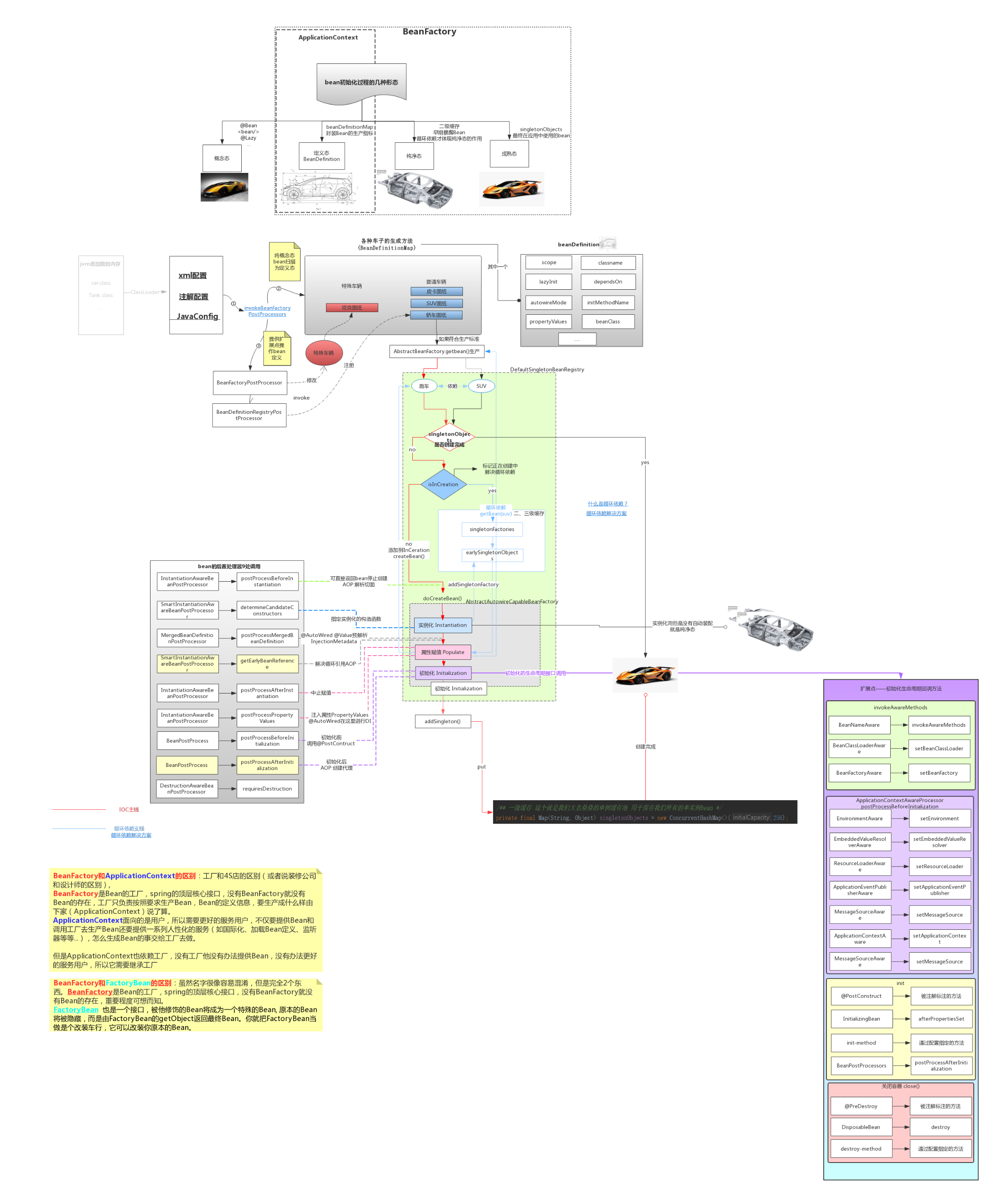
在Spring中,有一个非常重要的组件 —— BeanFactory
在后续的源码讲解中,我们会发现:
BeanFactory 将会十分频繁地出现,并且在 SpringIOC源码 中 起到 至关重要 的作用:
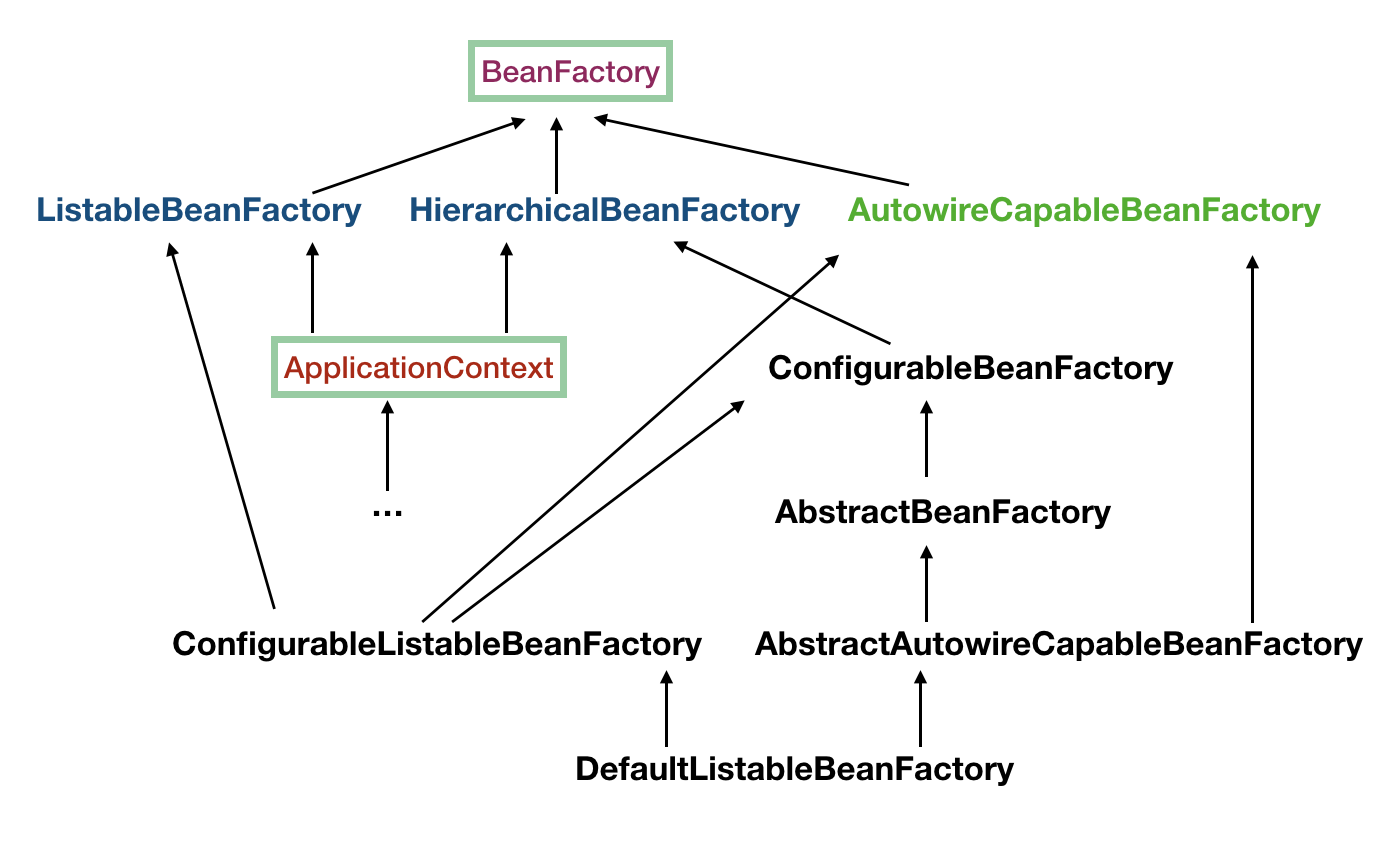
BeanFactory:
为了之后的讲解,本人先来展示下在 Spring IOC 中,BeanFactory 的 派生类:
继承关系:
首先,本人来给出一个 简单的API使用案例:
API调用:
package edu.youzg.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import java.util.Date;
/**
* @Author: Youzg
* @CreateTime: 2021-03-16 15:17
* @Description: 带你深究Java的本质!
*/
@Configuration
@ComponentScan("edu.youzg.bean") // 该包下有两个类:ClassA、ClassB,两个类构成属性的“循环依赖”
public class YouzgConfig {
@Bean("springIocDate")
public Date createDate() {
return new Date();
}
}
那么,我们根据上面的代码,来看看每一步都干了什么:
上下文 · 可变参构造:
首先,我们来看看 16行代码:
public AnnotationConfigApplicationContext(Class<?>... componentClasses) {
this();
this.register(componentClasses);
this.refresh();
}
那么,我们分别来看看,这三个方法都干了什么?
上下文 · 无参构造:
/**
* 父类构造
*/
public GenericApplicationContext() {
this.customClassLoader = false;
this.refreshed = new AtomicBoolean();
this.beanFactory = new DefaultListableBeanFactory();
}
/**
* 本类 无参构造
*/
public AnnotationConfigApplicationContext() {
// 注解扫描器
this.reader = new AnnotatedBeanDefinitionReader(this);
// 指定 配置类bean扫描器
this.scanner = new ClassPathBeanDefinitionScanner(this);
}
可以看到:
无参构造,其实做的只有:
给一些属性赋值,注册了 注解扫描器 和 文件扫描器
这两个 组件,在后面的 getBean()方法 中,将起到重要作用
而我们一层一层点进去查看源码的实现流程,我们就会发现:
通过注册 reader 和 scanner,
context 间接地在 bean定义Map 中注册了很多 用于 之后解析配置类、实现IOC功能 的 处理器(Processor) 的 bean名称:
(但是,这里仅是 注册bean定义,后续的 getBean操作 才会真正地创造这些处理器的实例)
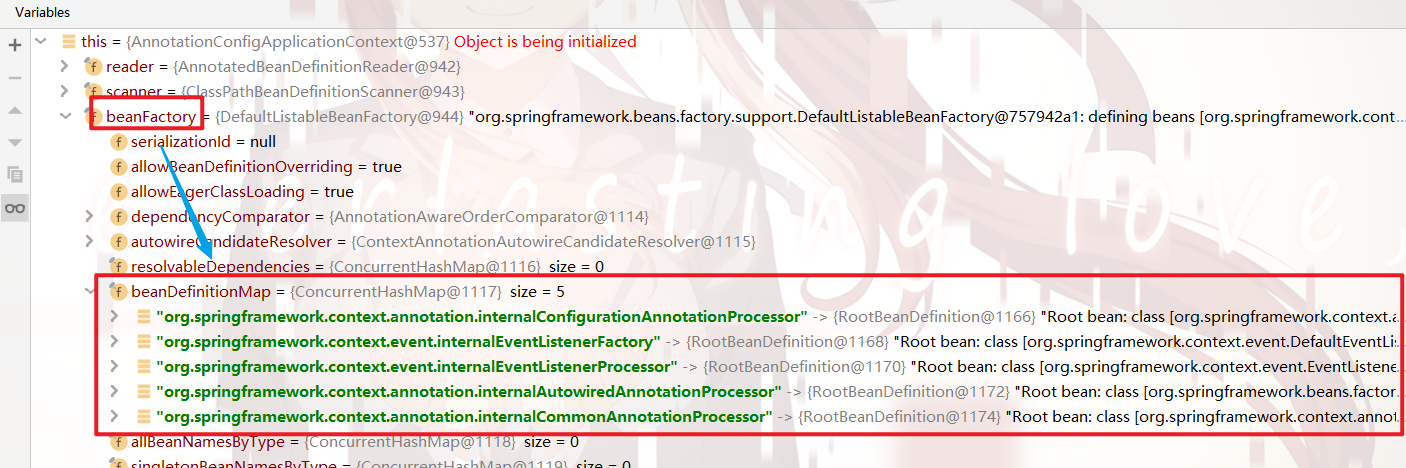
那么,我们继续看 register()方法 干了什么:
register()方法:
public void register(Class<?>... componentClasses) {
// 注册所有参数所传bean
for (Class<?> componentClass : componentClasses) {
registerBean(componentClass);
}
}
上面的代码,其实做的事也很简单,
我们一层一层点进去,就会看到如下代码:
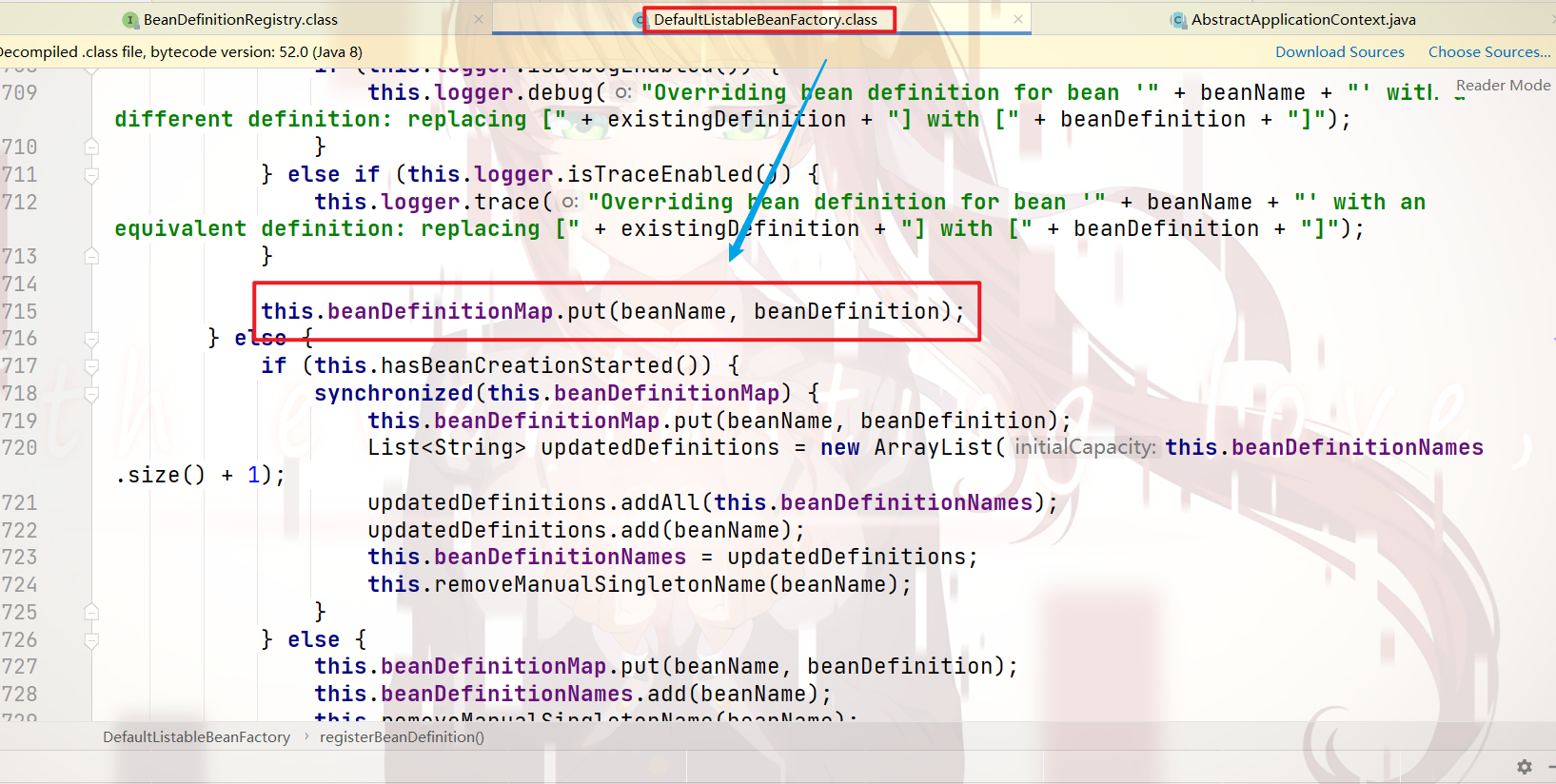
可以看到:
只是将 API调用时所传配置类的bean 注册到了 beanDefinitionMap 中
那么,我们继续看下面的方法 —— refresh()方法:
refresh方法:
这个方法可了不得,基本上所有的 逻辑,都要在这里实现:
@Override
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
// 准备环境
prepareRefresh();
// 获取 bean工厂
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// 为bean工厂设置各种处理器和参数
prepareBeanFactory(beanFactory);
try {
// Allows post-processing of the bean factory in context subclasses.
postProcessBeanFactory(beanFactory);
// 执行bean工厂中 注册的所有后置处理器
// 将配置类中的所有注解bean进行解析,并存入bean定义map中
invokeBeanFactoryPostProcessors(beanFactory);
// 注册 BeanPostProcessor 的实现类
registerBeanPostProcessors(beanFactory);
// 国际化
initMessageSource();
// 初始化 事件多播器(spring监听器功能 使用)
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
onRefresh();
// 事件监听器
registerListeners();
// 初始化 所有bean定义Map中的 单例非懒加载bean
finishBeanFactoryInitialization(beanFactory);
// 广播 ”上下文容器 初始化完成“事件
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
// Destroy already created singletons to avoid dangling resources.
destroyBeans();
// Reset 'active' flag.
cancelRefresh(ex);
// Propagate exception to caller.
throw ex;
}
finally {
// Reset common introspection caches in Spring's core, since we
// might not ever need metadata for singleton beans anymore...
resetCommonCaches();
}
}
}
那么,在实现 IOC功能 的过程中,我们主要看的方法只有如下:
- invokeBeanFactoryPostProcessors() 方法
- registerBeanPostProcessors(beanFactory) 方法
invokeBeanFactoryPostProcessors() 方法:
protected void invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory beanFactory) {
PostProcessorRegistrationDelegate.invokeBeanFactoryPostProcessors(beanFactory, getBeanFactoryPostProcessors());
// 检测LoadTimeWeaver并准备编织(如果在此期间发现)
//(例如,通过ConfigurationClassPostProcessor注册的@Bean方法)
if (beanFactory.getTempClassLoader() == null && beanFactory.containsBean(LOAD_TIME_WEAVER_BEAN_NAME)) {
beanFactory.addBeanPostProcessor(new LoadTimeWeaverAwareProcessor(beanFactory));
beanFactory.setTempClassLoader(new ContextTypeMatchClassLoader(beanFactory.getBeanClassLoader()));
}
}
这里的操作,所实现的功能也很简单:
执行 bean工厂 中 注册的所有后置处理器
也是在这一步中,对 配置类的内容 进行了 解析,解析了@ComponentScan注解、@Bean注解、@Component注解
但是,总结起来十分轻巧,我们来看看其具体的 部分实现逻辑:
配置类解析 · 具体实现逻辑:
PostProcessorRegistrationDelegate类 · invokeBeanFactoryPostProcessors()方法:
private static void invokeBeanDefinitionRegistryPostProcessors(
Collection<? extends BeanDefinitionRegistryPostProcessor> postProcessors, BeanDefinitionRegistry registry) {
for (BeanDefinitionRegistryPostProcessor postProcessor : postProcessors) {
// 解析配置类,并将用户自定义的bean记录在bean定义Map中
postProcessor.postProcessBeanDefinitionRegistry(registry);
}
}
那么,我们来看看具体是怎么解析配置类的:
ConfigurationClassPostProcessor类 · postProcessBeanDefinitionRegistry()方法:
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) {
int registryId = System.identityHashCode(registry);
if (this.registriesPostProcessed.contains(registryId)) {
throw new IllegalStateException(
"postProcessBeanDefinitionRegistry already called on this post-processor against " + registry);
}
if (this.factoriesPostProcessed.contains(registryId)) {
throw new IllegalStateException(
"postProcessBeanFactory already called on this post-processor against " + registry);
}
this.registriesPostProcessed.add(registryId);
processConfigBeanDefinitions(registry);
}
在这里,我们还是看不到具体流程,
那么,为了节省篇幅,本人来直接跟进到 解析注解 的地方:
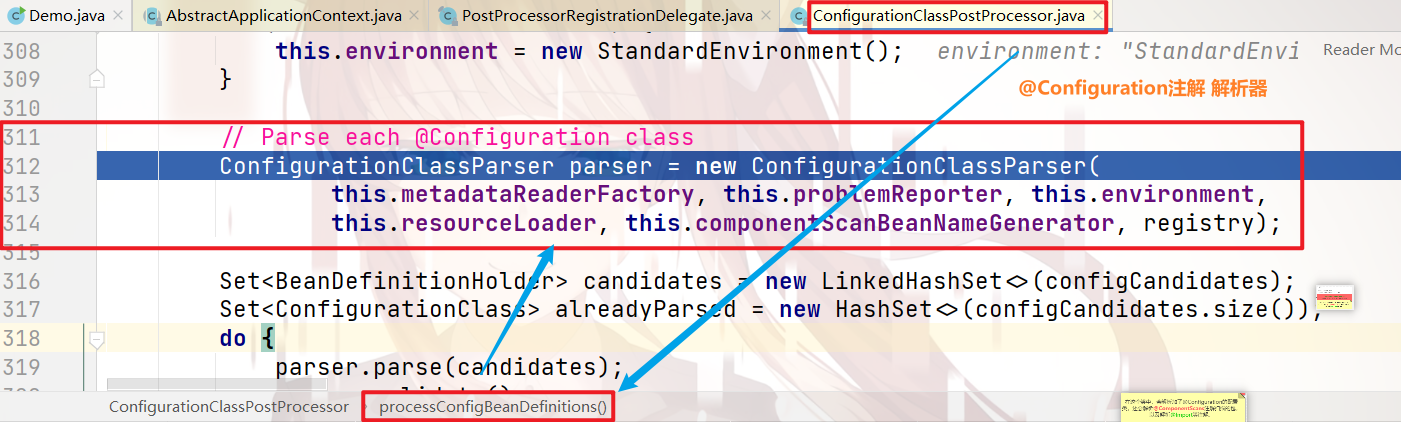
那么,我们直接来看上图中,319行的代码的具体实现流程:
配置类的解析 —— ConfigurationClassPaser类 :
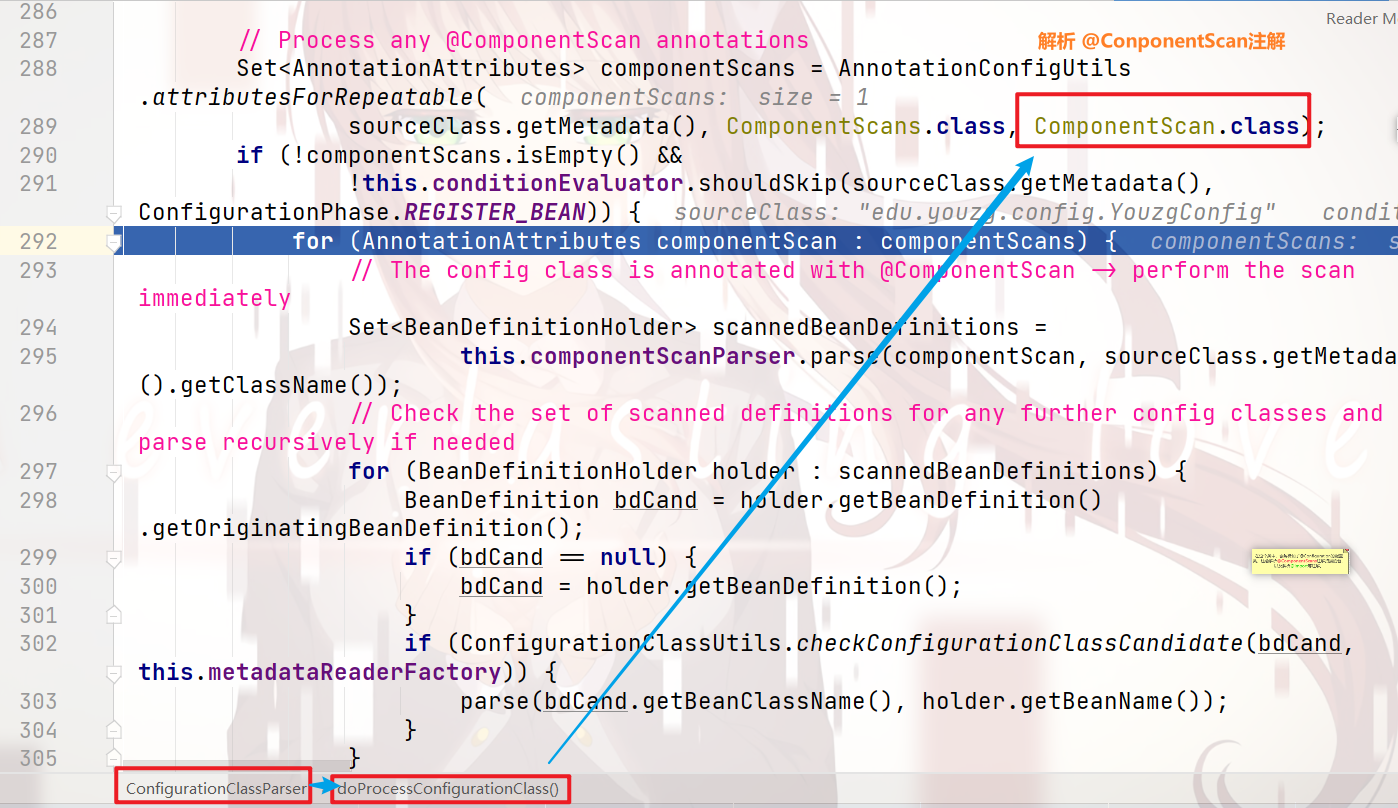
我们跟进 上图中的295行:
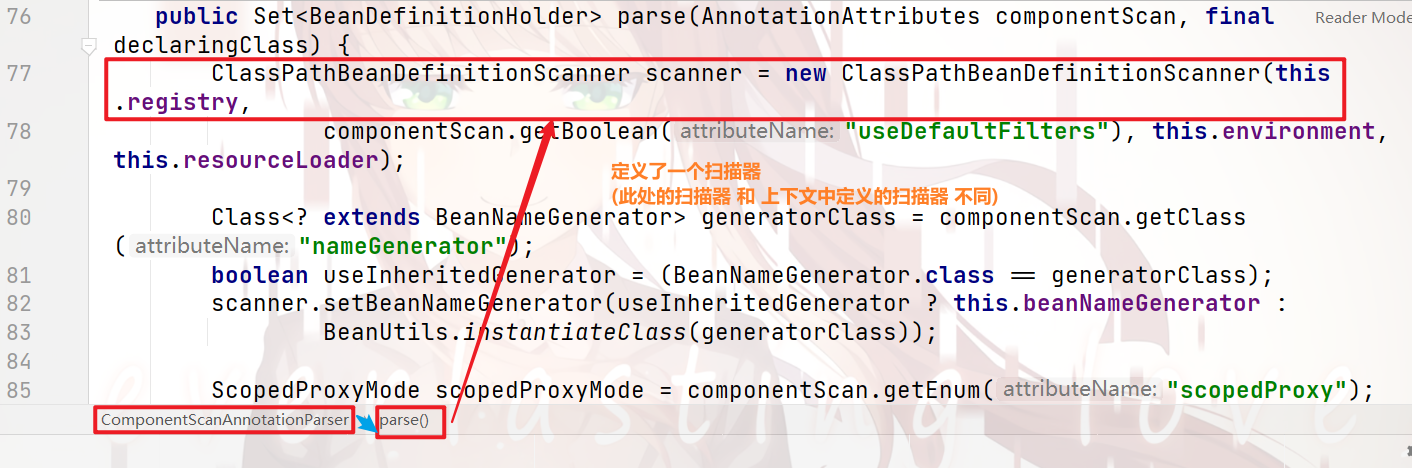
在后面的代码中,对这个扫描器进行了 属性赋值:
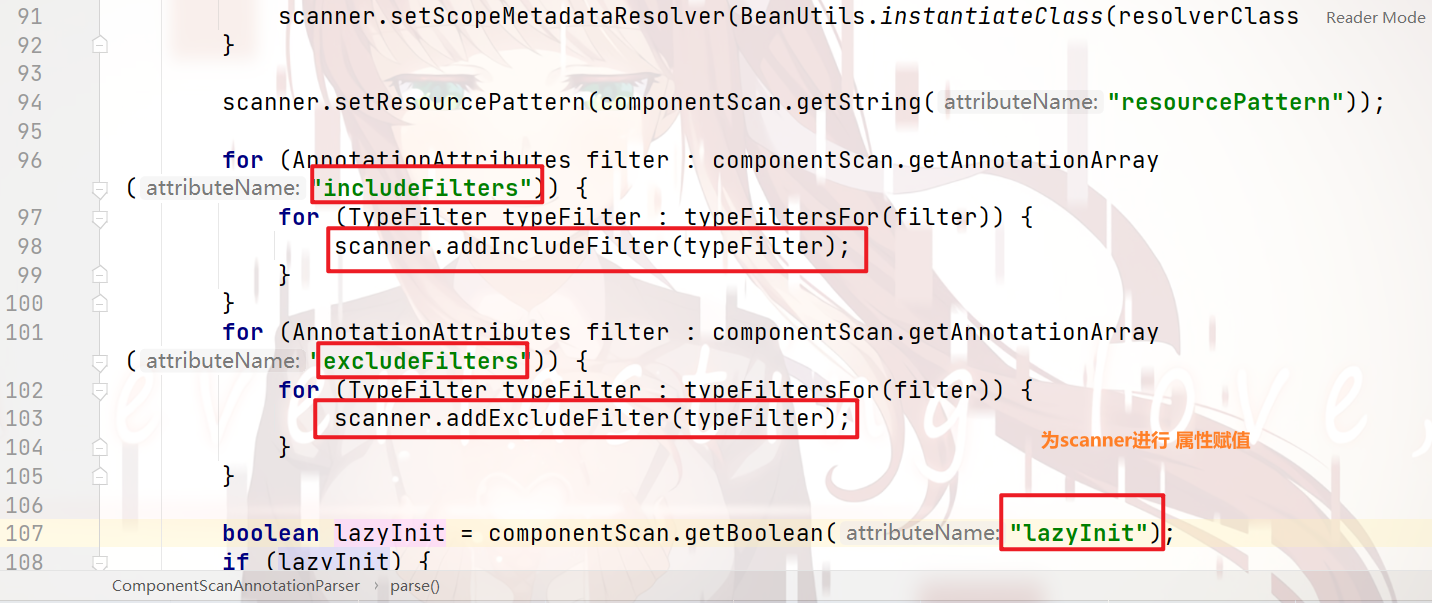
之后,进行了 真正的 扫描操作
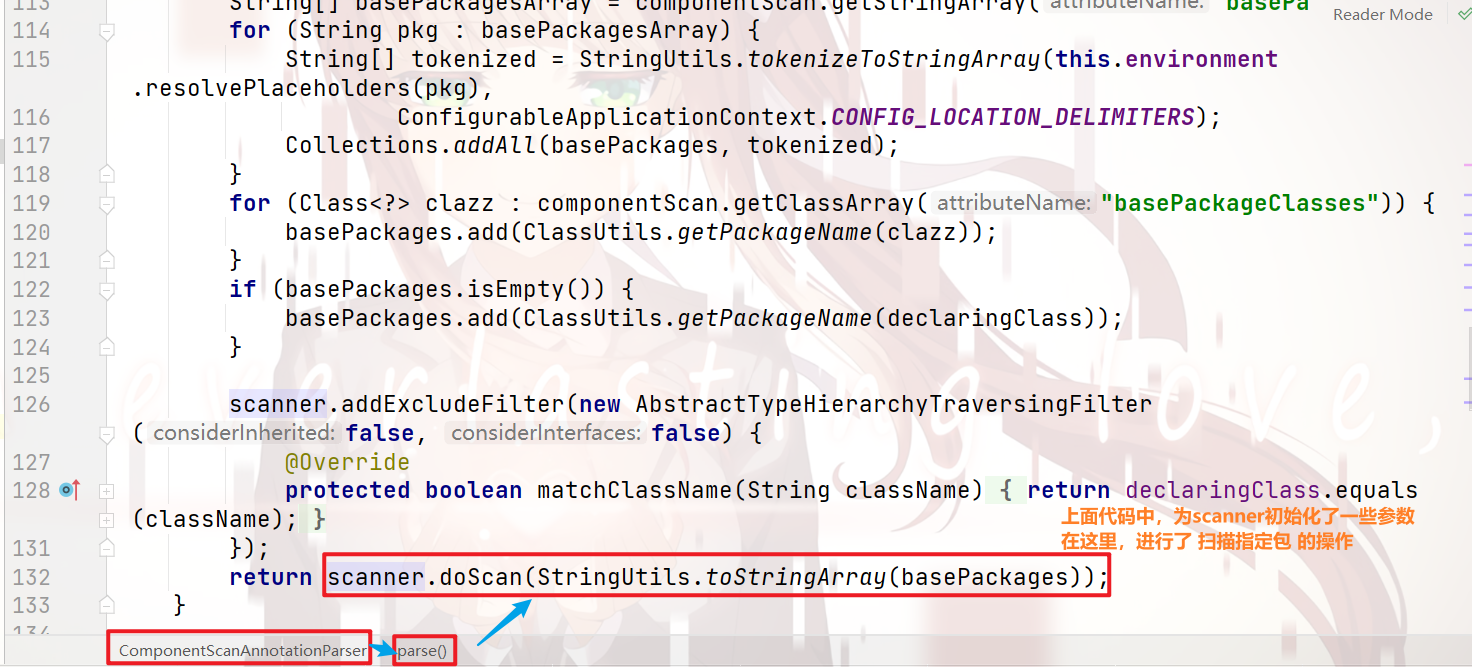
那么,一直跟进去,就会看到下图:
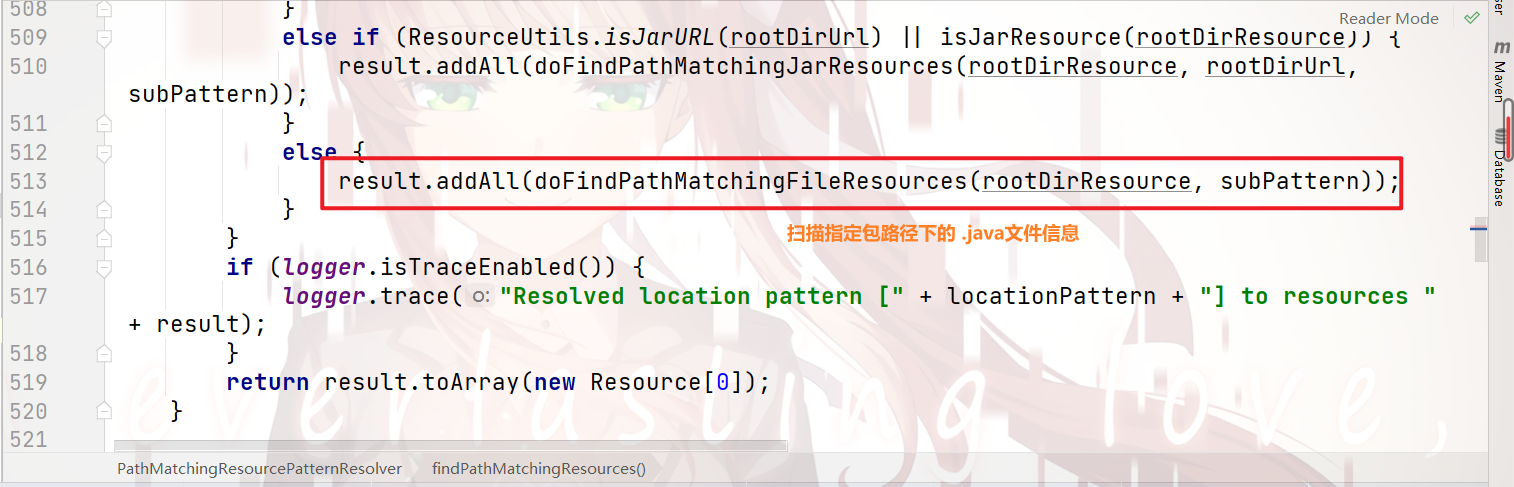
但是,在这里,解析出来的result,是指定包路径下的所有 .java文件的信息,
(其实是编译后目录 target/out/bin目录 下的 .class文件信息,但我们一般日常开发,是不会接触到这么深的层次,
因此,我们就简单理解为 .java文件 信息即可)
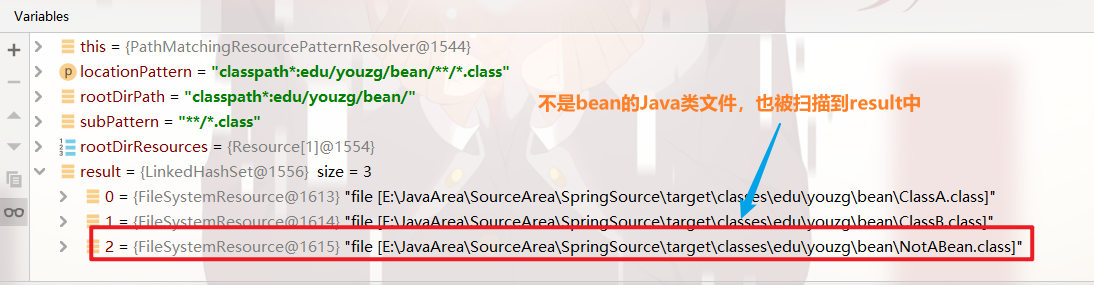
之后,在 扫描到的所有.java文件 中,筛选出 bean的信息:
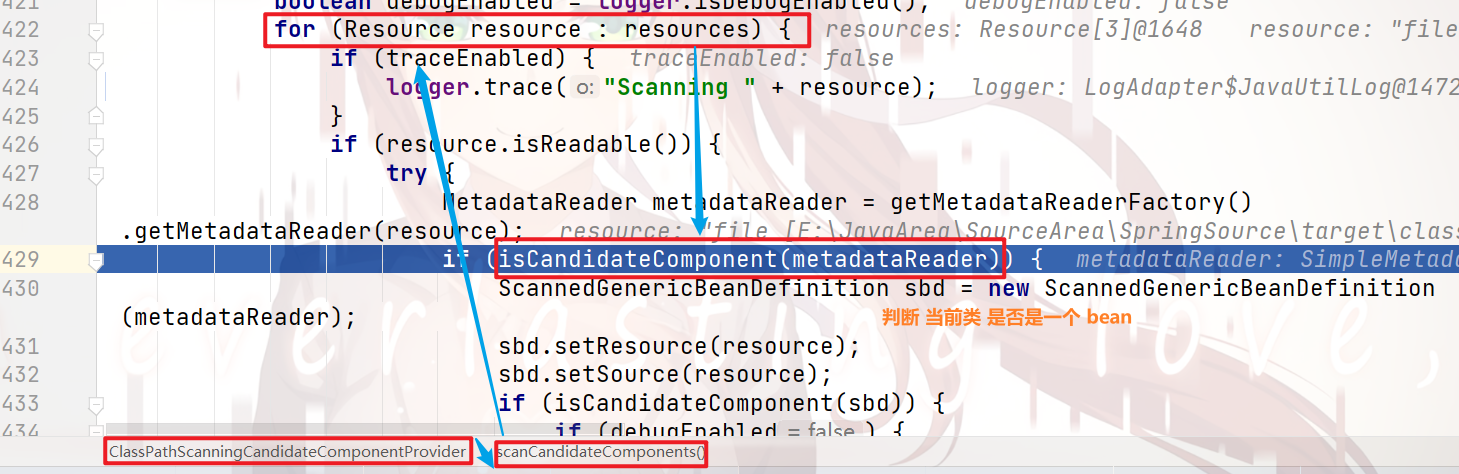
我们跟进去:
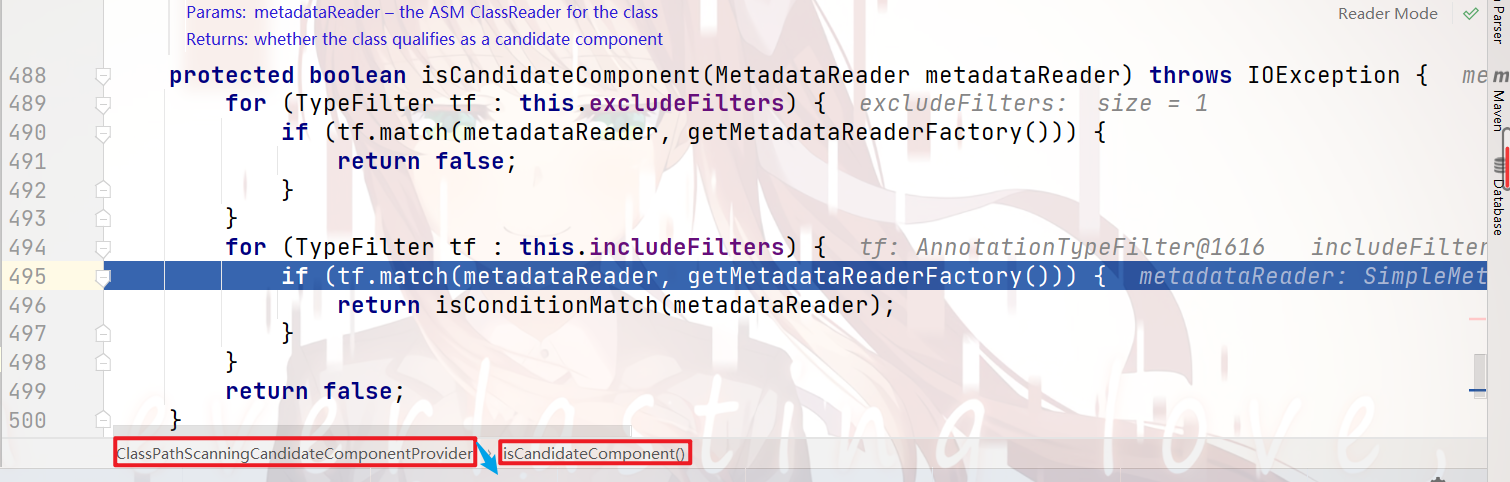
一直跟进去,就会看到在 检验注解:
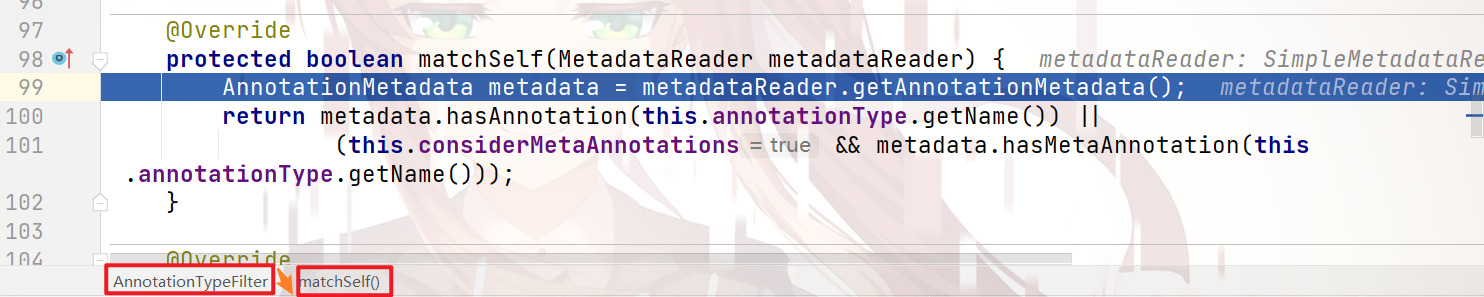
在之后,只会将 解析出来的bean信息,存储在 bean定义Map 中:
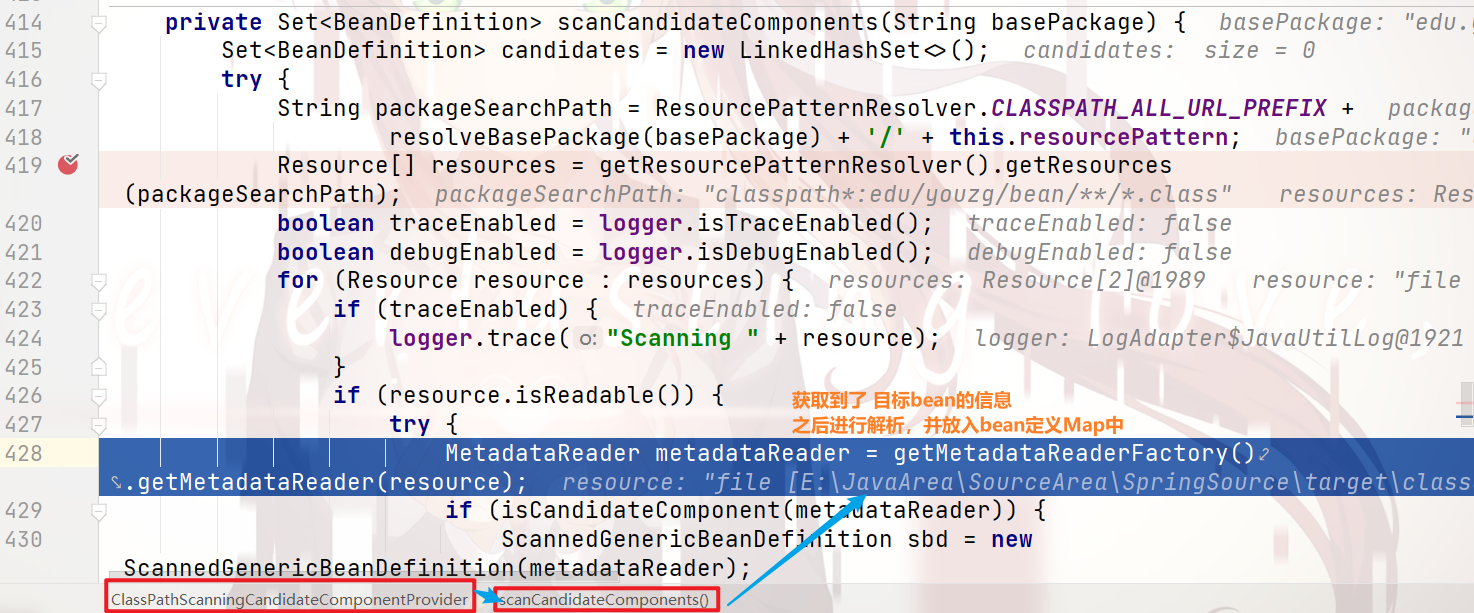
接着向下执行,层层返回,我们可以看到,只解析到了 合法的bean:
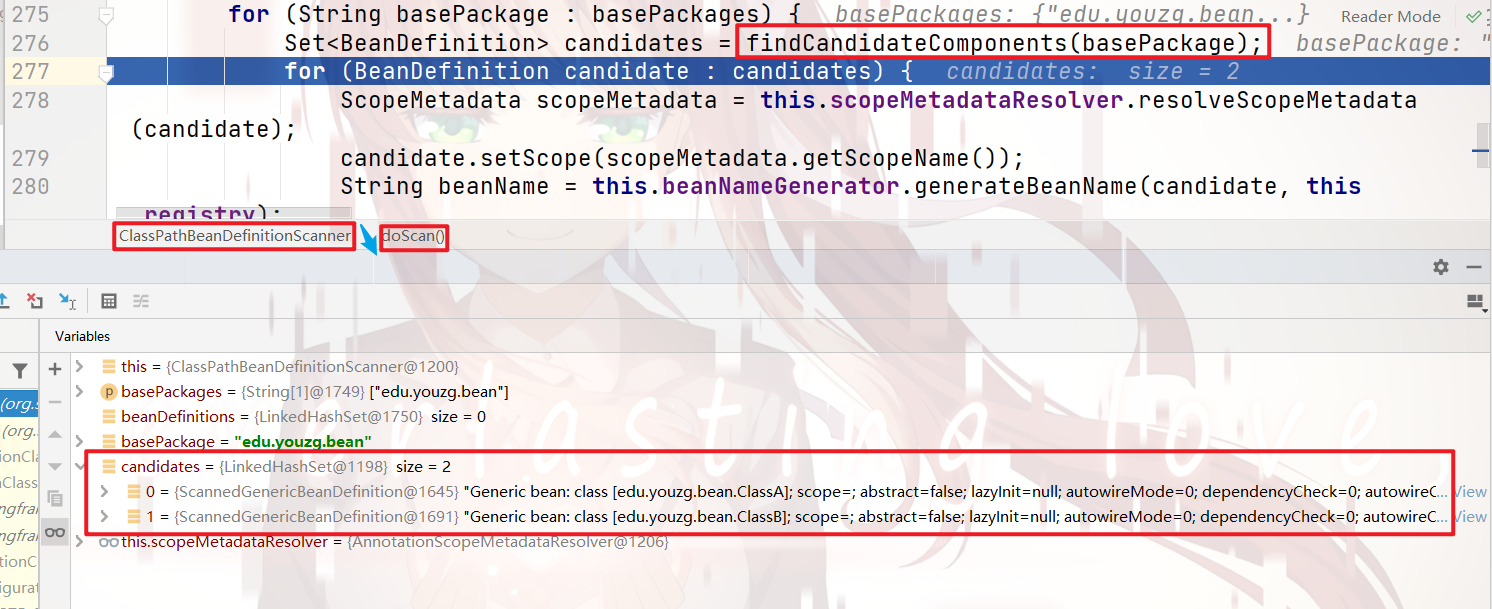
向下执行,就会对解析出来的bean,根据 注解的属性配置,进行 bean的属性配置:
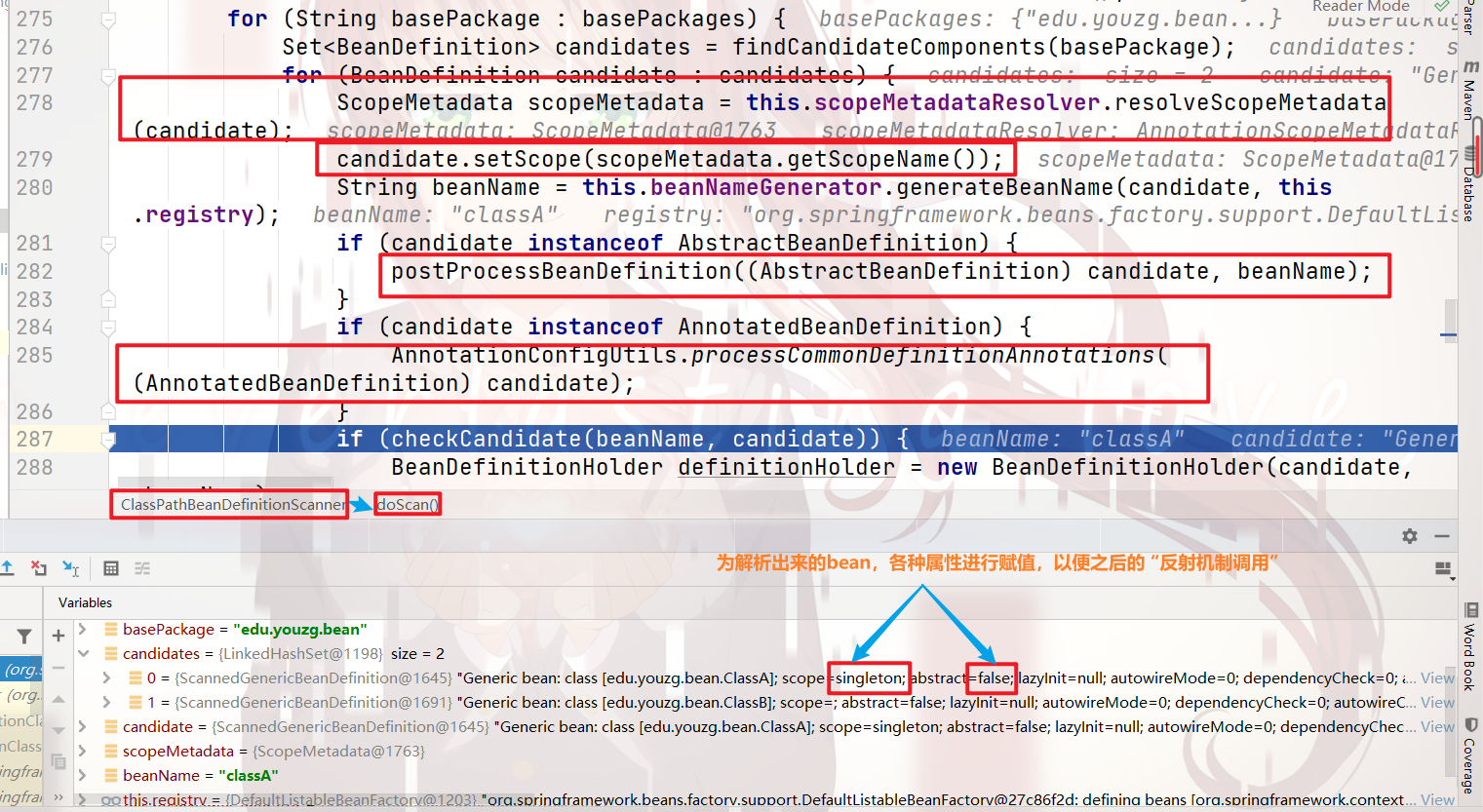
之后,对解析到的 真正的bean的信息,进行一些列操作,最终将信息放入了 bean定义Map 中:
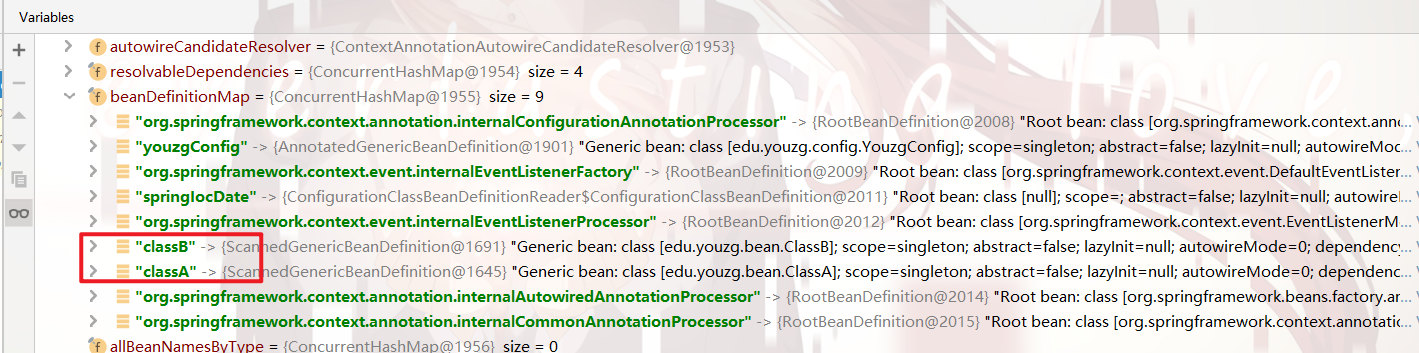
至此,自定义的bean信息 就全部 解析并存储 到了 bean定义Map 中!
那么,自定义bean的实例,在什么时候会被创建呢?
答曰:
还是在 refresh()方法 中
在finishBeanFactoryInitialization(beanFactory);这一句会被 初始化成功!
现在我们来看下,finishBeanFactoryInitialization()方法 的源码:
自定义bean的 实例化 —— finishBeanFactoryInitialization()方法:
// 初始化 自定义单例非懒记载bean
protected void finishBeanFactoryInitialization(ConfigurableListableBeanFactory beanFactory) {
if (beanFactory.containsBean(CONVERSION_SERVICE_BEAN_NAME) &&
beanFactory.isTypeMatch(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class)) {
beanFactory.setConversionService(
beanFactory.getBean(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class));
}
// Register a default embedded value resolver if no bean post-processor
// (such as a PropertyPlaceholderConfigurer bean) registered any before:
// at this point, primarily for resolution in annotation attribute values.
if (!beanFactory.hasEmbeddedValueResolver()) {
beanFactory.addEmbeddedValueResolver(new StringValueResolver() {
@Override
public String resolveStringValue(String strVal) {
return getEnvironment().resolvePlaceholders(strVal);
}
});
}
String[] weaverAwareNames = beanFactory.getBeanNamesForType(LoadTimeWeaverAware.class, false, false);
for (String weaverAwareName : weaverAwareNames) {
getBean(weaverAwareName);
}
// Stop using the temporary ClassLoader for type matching.
beanFactory.setTempClassLoader(null);
// 冻结配置,防止 bean 定义解析、加载、注册
beanFactory.freezeConfiguration();
// 初始化 自定义非懒加载单例bean 的实例
beanFactory.preInstantiateSingletons();
}
那么,根据上面代码的注释,我们也能知道:
真正的 实例化bean逻辑 在
preInstantiateSingletons()方法中
preInstantiateSingletons()方法:
@Override
public void preInstantiateSingletons() throws BeansException {
if (this.logger.isDebugEnabled()) {
this.logger.debug("Pre-instantiating singletons in " + this);
}
List<String> beanNames = new ArrayList<String>(this.beanDefinitionNames);
// 触发所有的非懒加载的 singleton beans 的初始化操作
for (String beanName : beanNames) {
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
// 判断当前bean的合法性
if (!bd.isAbstract() && bd.isSingleton() && !bd.isLazyInit()) {
// 判断当前自定义bean,是否是 工厂bean
if (isFactoryBean(beanName)) {
/*
FactoryBean 的话,在 beanName 前面加上 ‘&’ 符号
因为工厂bean的真实bean定义,在bean定义Map中,是以”&工厂bean“作为beanName的
*/
final FactoryBean<?> factory = (FactoryBean<?>) getBean(FACTORY_BEAN_PREFIX + beanName);
// 判断当前 FactoryBean 是否是 SmartFactoryBean 的实现,此处忽略,直接跳过
boolean isEagerInit;
if (System.getSecurityManager() != null && factory instanceof SmartFactoryBean) {
isEagerInit = AccessController.doPrivileged(new PrivilegedAction<Boolean>() {
@Override
public Boolean run() {
return ((SmartFactoryBean<?>) factory).isEagerInit();
}
}, getAccessControlContext());
}
else {
isEagerInit = (factory instanceof SmartFactoryBean &&
((SmartFactoryBean<?>) factory).isEagerInit());
}
if (isEagerInit) {
getBean(beanName);
}
}
else {
// 实例化 普通自定义bean
getBean(beanName);
}
}
}
// 到这里
// 所有的非懒加载的单例bean 已经完成了实例化
// 之后的操作,都是用于实现 ”回掉函数“,我们一般用不到,这里可以当作结束了
for (String beanName : beanNames) {
Object singletonInstance = getSingleton(beanName);
if (singletonInstance instanceof SmartInitializingSingleton) {
final SmartInitializingSingleton smartSingleton = (SmartInitializingSingleton) singletonInstance;
if (System.getSecurityManager() != null) {
AccessController.doPrivileged(new PrivilegedAction<Object>() {
@Override
public Object run() {
smartSingleton.afterSingletonsInstantiated();
return null;
}
}, getAccessControlContext());
}
else {
smartSingleton.afterSingletonsInstantiated();
}
}
}
}
上面的代码,也十分秃然!
但是,其实我们仔细去看,这个方法无论是哪个分支,只要是以 实例化bean 为目的的,都会执行 getBean() 这个方法
那么,本人现在来讲解下 getBean()方法:
bean实例 的获取 —— getBean()方法:
还是Spring之前的作风,包装了一层
真正的操作方法,都是以 doXxx 格式存在的!

那么,我们来跟进去:
实际操作 —— doGetBean()方法:
/**
* doGetBean() 不止用于 创建容器中的bean
* 在我们通过beanName进行获取bean实例时,也会调用此方法
* (已经初始化过了就从容器中直接返回,否则就先初始化再返回)
*/
@SuppressWarnings("unchecked")
protected <T> T doGetBean(
final String name, final Class<T> requiredType, final Object[] args, boolean typeCheckOnly)
throws BeansException {
// beanName转换,以便 别名、工厂bean 的 实例创建
final String beanName = transformedBeanName(name);
// 定义返回值
Object bean;
// 检查当前bean 是否已被创建
Object sharedInstance = getSingleton(beanName);
// args不为null,则 创建 bean实例
if (sharedInstance != null && args == null) {
if (logger.isDebugEnabled()) {
if (isSingletonCurrentlyInCreation(beanName)) {
logger.debug("...");
}
else {
logger.debug("Returning cached instance of singleton bean '" + beanName + "'");
}
}
/*
如果是普通 bean 的话,直接返回 sharedInstance,
如果是 FactoryBean 的话,返回 创建的实例对象
*/
bean = getObjectForBeanInstance(sharedInstance, name, beanName, null);
}
else {
if (isPrototypeCurrentlyInCreation(beanName)) {
// 判断当前bean的实例,是否正在被创建
throw new BeanCurrentlyInCreationException(beanName);
}
// 检查一下这个 BeanDefinition 在容器中是否存在
BeanFactory parentBeanFactory = getParentBeanFactory();
if (parentBeanFactory != null && !containsBeanDefinition(beanName)) {
// 如果当前容器不存在这个 BeanDefinition,在父容器中查找
String nameToLookup = originalBeanName(name);
if (args != null) {
// 返回父容器的查询结果
return (T) parentBeanFactory.getBean(nameToLookup, args);
}
else {
// No args -> delegate to standard getBean method.
return parentBeanFactory.getBean(nameToLookup, requiredType);
}
}
if (!typeCheckOnly) {
// typeCheckOnly 为 false,将当前 beanName 放入一个 alreadyCreated 的 Set 集合中。
markBeanAsCreated(beanName);
}
// 创建bean实例
try {
final RootBeanDefinition mbd = getMergedLocalBeanDefinition(beanName);
checkMergedBeanDefinition(mbd, beanName, args);
// 先初始化依赖的所有 Bean,这个很好理解。
// 注意,这里的依赖指的是 depends-on 中定义的依赖
/*
初始化 所有depends-on 中定义的依赖的 bean定义
*/
String[] dependsOn = mbd.getDependsOn();
if (dependsOn != null) {
for (String dep : dependsOn) {
// 检查是否有循环依赖,此处的循环依赖是不能发生的(此处是直接初始化,并没有设置 “三级缓存”)
if (isDependent(beanName, dep)) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Circular depends-on relationship between '" + beanName + "' and '" + dep + "'");
}
// 注册 依赖关系
registerDependentBean(dep, beanName);
// 实例化 被依赖bean
getBean(dep);
}
}
/*
实例化 目标bean
*/
if (mbd.isSingleton()) {
sharedInstance = getSingleton(beanName, new ObjectFactory<Object>() {
@Override
public Object getObject() throws BeansException {
try {
// 执行创建 Bean,详情后面再说
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
destroySingleton(beanName);
throw ex;
}
}
});
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
// 创建 prototype 的实例
else if (mbd.isPrototype()) {
// It's a prototype -> create a new instance.
Object prototypeInstance = null;
try {
beforePrototypeCreation(beanName);
// 执行创建 Bean
prototypeInstance = createBean(beanName, mbd, args);
}
finally {
afterPrototypeCreation(beanName);
}
bean = getObjectForBeanInstance(prototypeInstance, name, beanName, mbd);
}
// 如果不是 singleton 和 prototype 的话,需要委托给相应的实现类来处理
else {
String scopeName = mbd.getScope();
final Scope scope = this.scopes.get(scopeName);
if (scope == null) {
throw new IllegalStateException("No Scope registered for scope name '" + scopeName + "'");
}
try {
Object scopedInstance = scope.get(beanName, new ObjectFactory<Object>() {
@Override
public Object getObject() throws BeansException {
beforePrototypeCreation(beanName);
try {
// 执行创建 Bean
return createBean(beanName, mbd, args);
}
finally {
afterPrototypeCreation(beanName);
}
}
});
bean = getObjectForBeanInstance(scopedInstance, name, beanName, mbd);
}
catch (IllegalStateException ex) {
throw new BeanCreationException(beanName,
"Scope '" + scopeName + "' is not active for the current thread; consider " +
"defining a scoped proxy for this bean if you intend to refer to it from a singleton",
ex);
}
}
}
catch (BeansException ex) {
cleanupAfterBeanCreationFailure(beanName);
throw ex;
}
}
// 最后,检查类型是否满足要求
if (requiredType != null && bean != null && !requiredType.isInstance(bean)) {
try {
return getTypeConverter().convertIfNecessary(bean, requiredType);
}
catch (TypeMismatchException ex) {
if (logger.isDebugEnabled()) {
logger.debug("Failed to convert bean '" + name + "' to required type '" +
ClassUtils.getQualifiedName(requiredType) + "'", ex);
}
throw new BeanNotOfRequiredTypeException(name, requiredType, bean.getClass());
}
}
return (T) bean;
}
上面的代码看的人头痛!

但是,Spring IOC 所有的 实例化bean的操作,都是在本方法中进行实现的
在这里,有一个非常重要的知识点 —— 循环依赖 的解决
那么,为了同学们能够顺利过一遍逻辑,本人就在下文来详细地讲下 Spring IOC 的 循环依赖 解决
API获取bean:
那么,我们就来讲解下 getBean()方法:

一直跟进去:

那么,兜兜转转,又回来了!
相信在这里,同学们应该能明白 IOC的基本流程了!
接下来,本人就来讲解下 Spring IOC 的 循环依赖 的 解决方式:
循环依赖 的解决:
在讲解源码之前,本人先来讲解下 一个很重要的名词 —— 三级缓存
三级缓存:
相信同学们一旦搜索 Spring循环依赖,就会发现 三级缓存 这个名词十分瞩目
但是,很少有人能解释的通什么是 三级缓存
这就经常会给我们造成心理上的“畏惧”
那么,本人来展示下 相关的源码:
/**
(一级缓存)单例对象的缓存:
beanName 到 bean实例 的映射
用于保存 实例化、注入、初始化完成 的bean实例
*/
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/**
(二级缓存)早期单例对象的缓存:
beanName 到 bean实例(未注入、初始化) 的映射
用于保存 实例化完成(未注入、初始化) 的bean实例
*/
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
/**
(三级缓存)单例工厂的缓存:
beanName 到 ObjectFactory 的映射
用于保存bean创建工厂,以便于后面扩展有机会创建代理对象
*/
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
可以看到:
所谓的
三级缓存,不过就是三个Map
那么,为什么要称之为 三级缓存 呢?
其实我们字字对译,也很通俗易懂
三级,就是在不同阶段
缓存,就是 内存中 存取数据的 数据结构
那么,既然要涉及存取,就要用到 双列集合
综合所有方面的考虑,Map无疑非常合适,因此取名为三级缓存
那么,为什么要按照本人上文中所讲解的顺序进行排名呢?
答曰:
在之后的源码中,我们能发现:
我们获取一个bean的实例对象时,其实是 按照 一级缓存 -> 二级缓存 -> 三级缓存 的顺序 进行获取的
那么,Spring又是怎么通过 三级缓存 来解决 循环依赖 问题的呢?
我们来 回顾下 doGetBean()方法 的 部分源码:
再见 doGetBean():
由于 doGetBean()方法 的源码,本人在上文中已经很清楚地展示了
那么,在这里,本人就通过源码截图的形式,来讲解下 Spring IOC 中,循环依赖 的解决:
首先,我们直接跳转到 初次获取目标bean实例 的那行代码:
初次获取 目标bean实例:
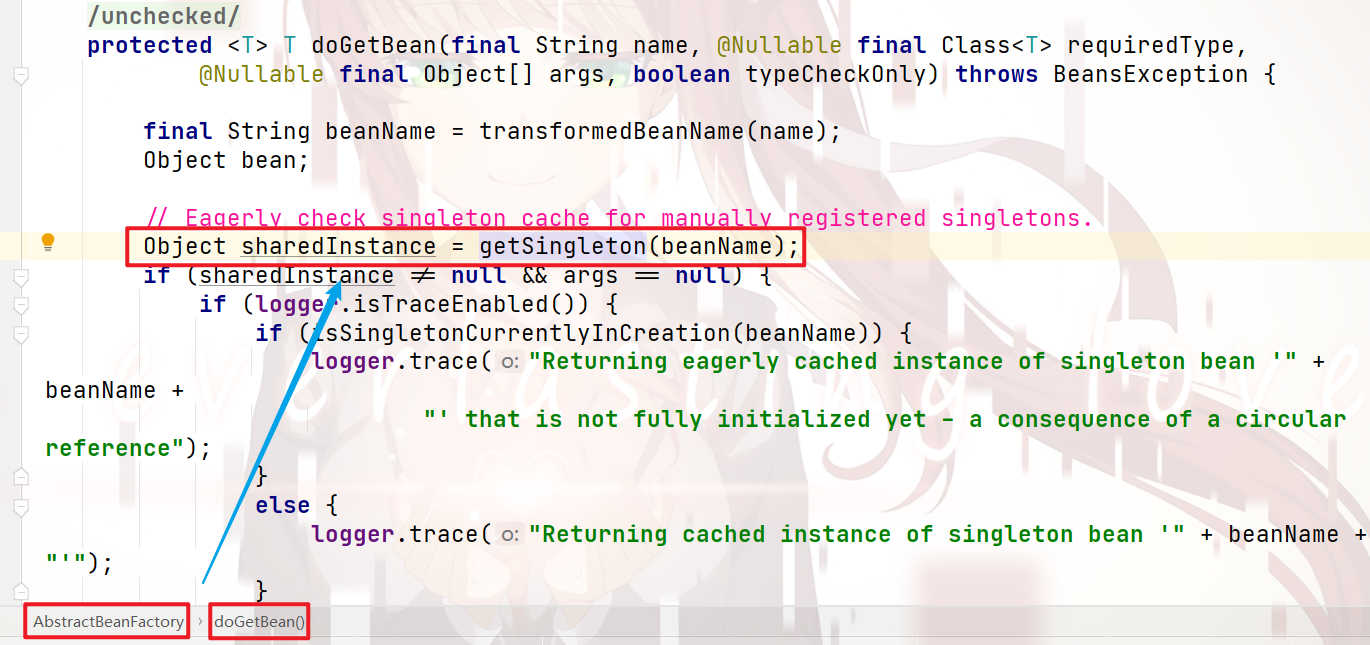
跟进去:
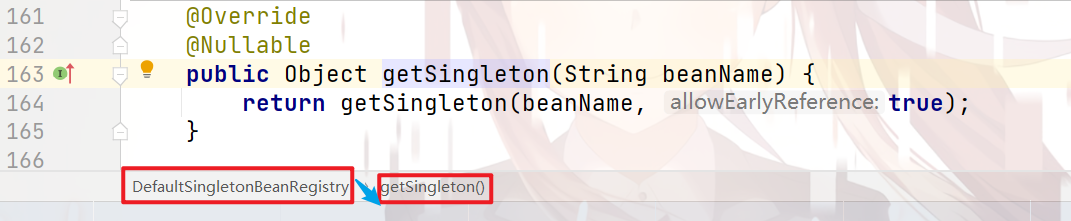
继续跟进去:
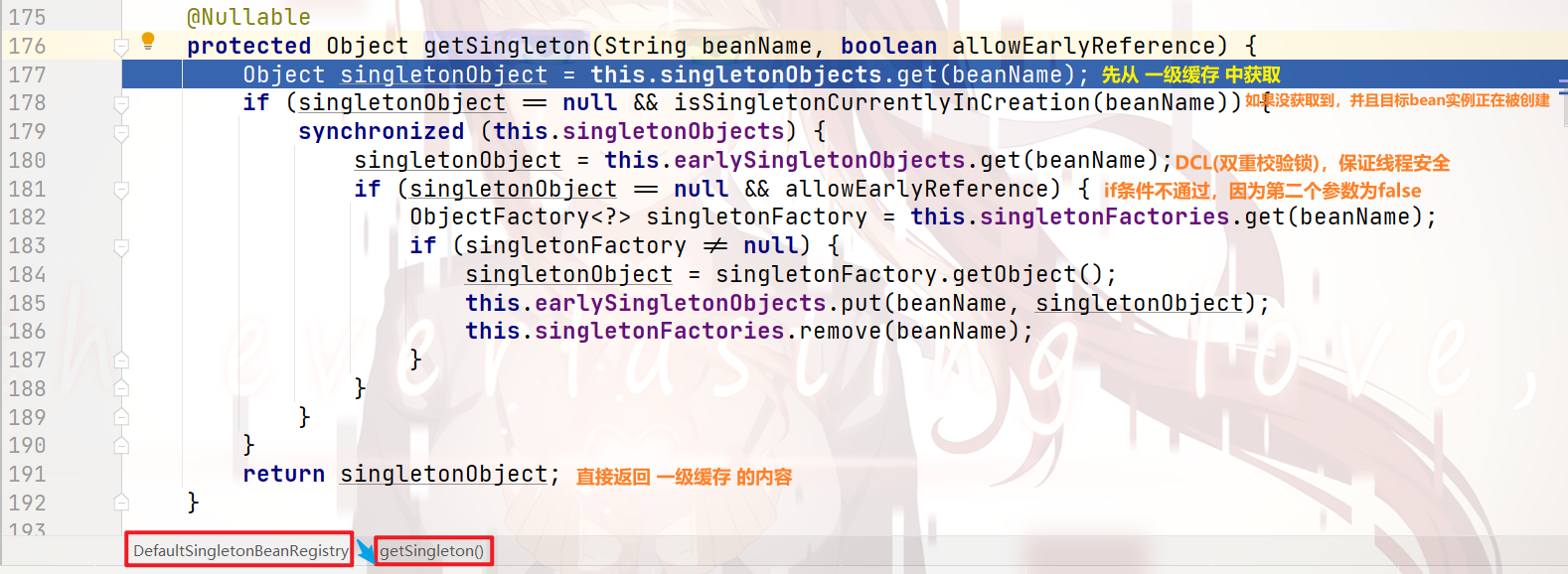
我们可以看到:
当我们想要获取一个bean的实例时,会先去
一级缓存中尝试获取
当 一级缓存 中没有取到目标bean实例,就会去 二级缓存 中去获取 未实例化完成的目标bean实例
当 二级缓存 中不存在 未实例化完成的目标bean实例,再去 三级缓存 中获取 目标bean的实例化工厂后置处理器
不管我们是 创建bean实例,还是 通过beanName获取bean实例,我们都会优先调用这个方法
三级缓存 的排名,就是由此而来!
我们继续debug:

这里的代码,只是为了保证在 一个线程创建bean实例 的过程中,其 元数据 不会被其它线程所更改
继续向下debug,就会到 创建目标bean实例 的代码块:
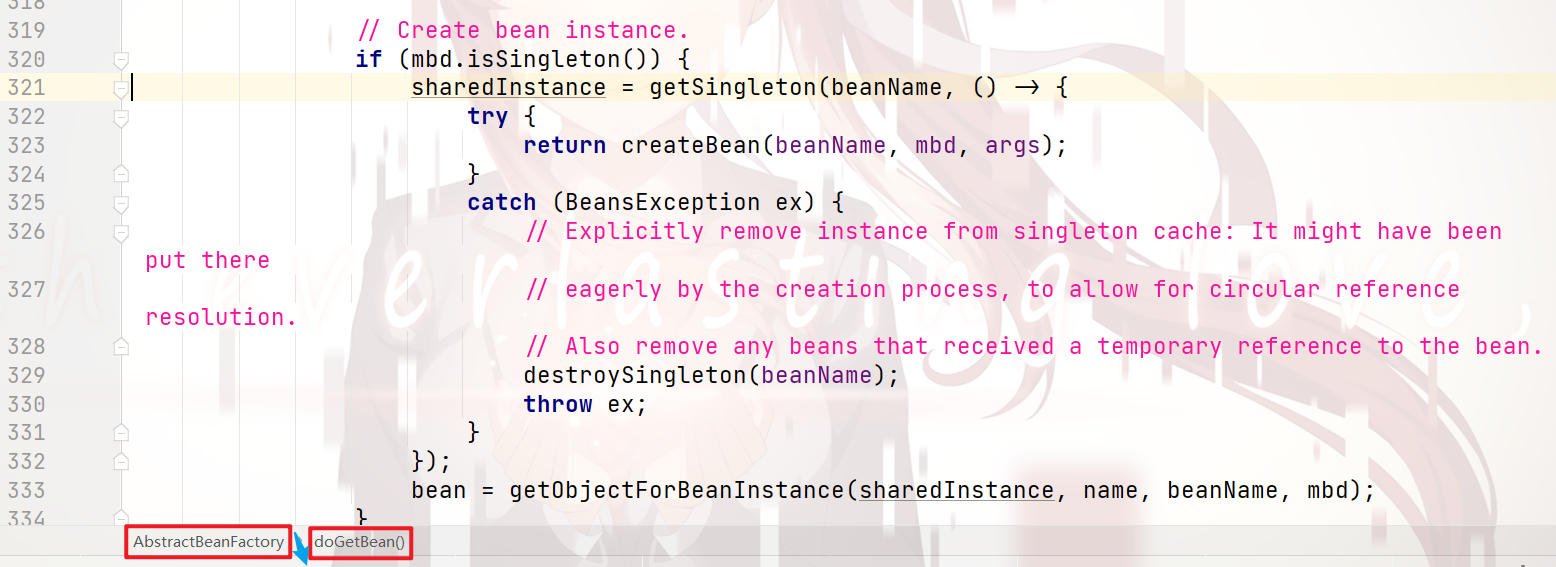
我们来看下上图中的 321行代码 的 执行流程:
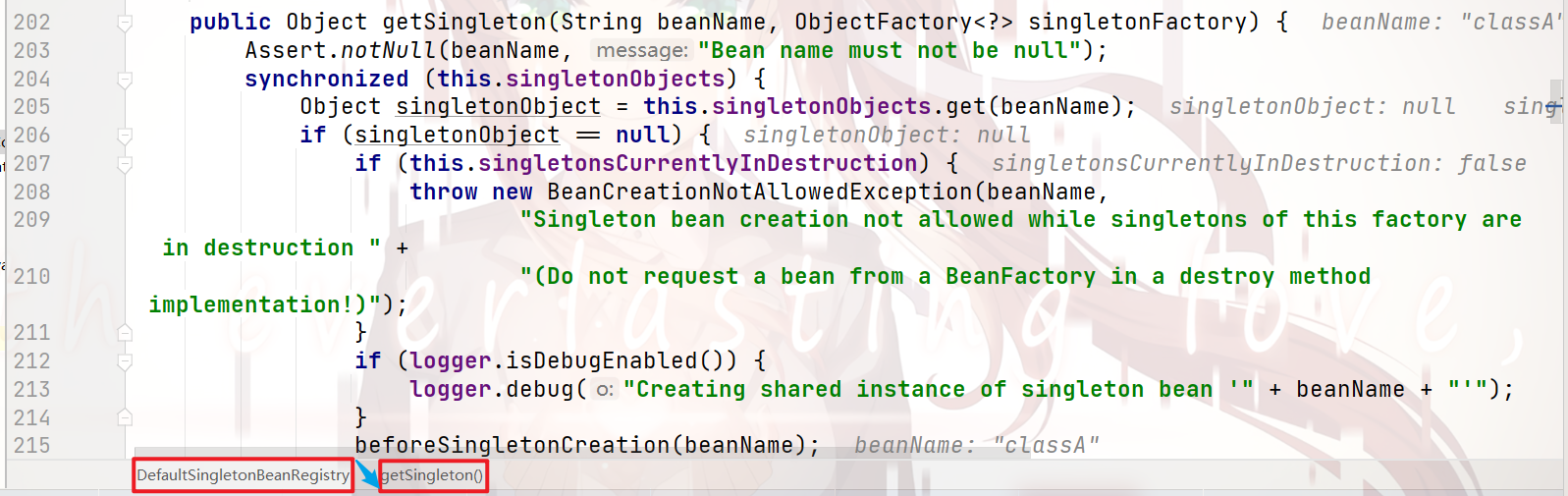
向下debug:

可以看到:
在 实例化目标bean 之前,Spring会将 目标bean 存储到 正在创建列表 中
以便我们为一个bean进行属性注入时,能够 将重复bean识别,避免重复创建bean实例
这里也是 循环依赖 的出口,只有标记了 当前bean的实例正在被创建,我们才能 发现并处理 循环依赖
继续看 之后的代码,会执行参数所穿的 “钩子函数”:
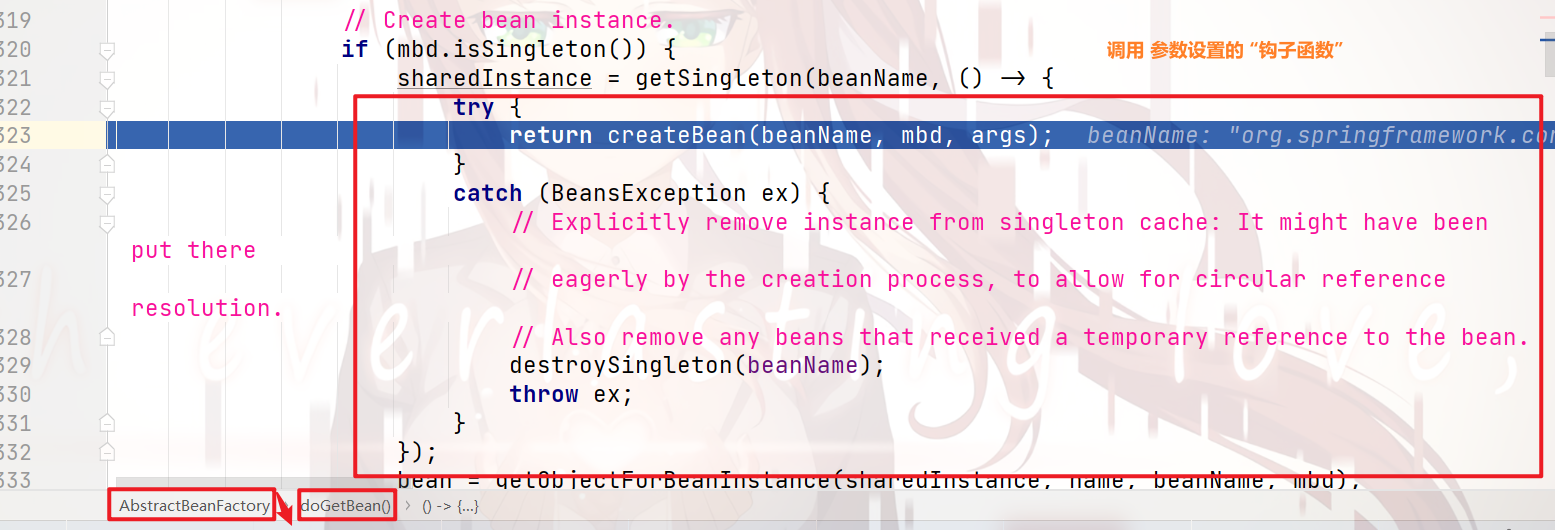
继续向下执行,会执行到 createBean()方法:
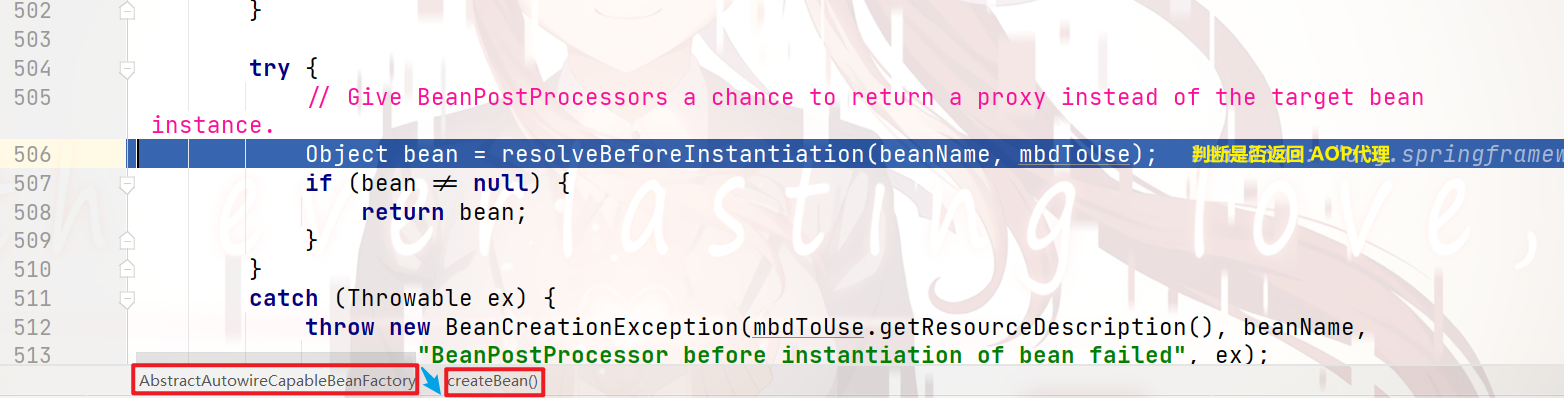
继续向下debug:
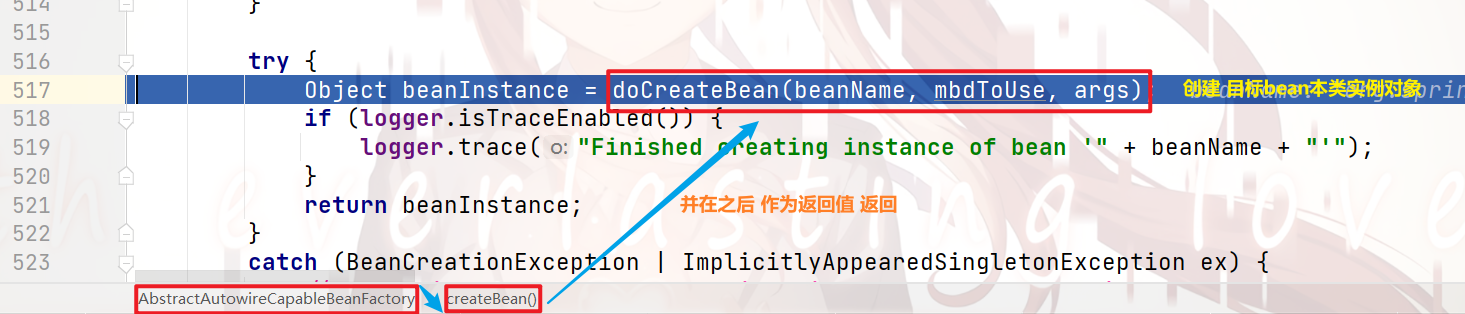
我们跟进去,来看看具体的 创建目标bean本类实例 的流程:
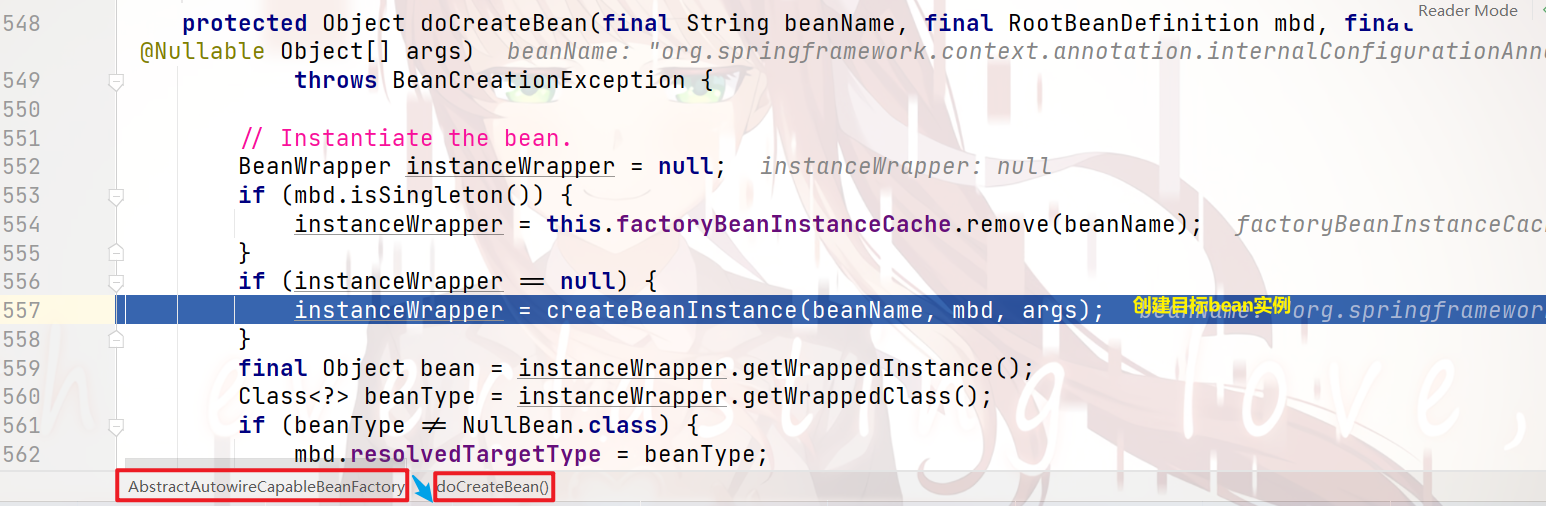
继续跟进去 557行代码:
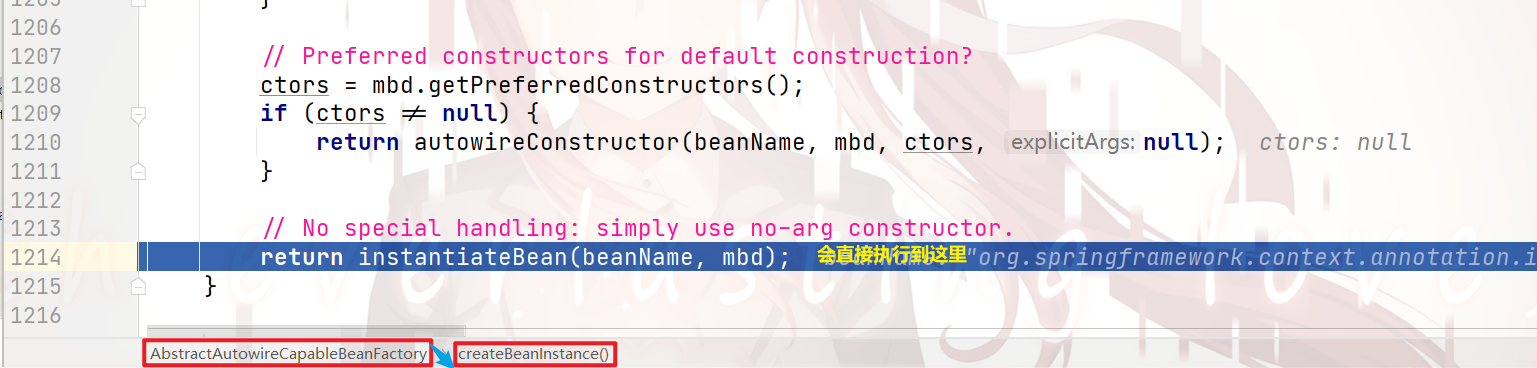
继续跟进去:
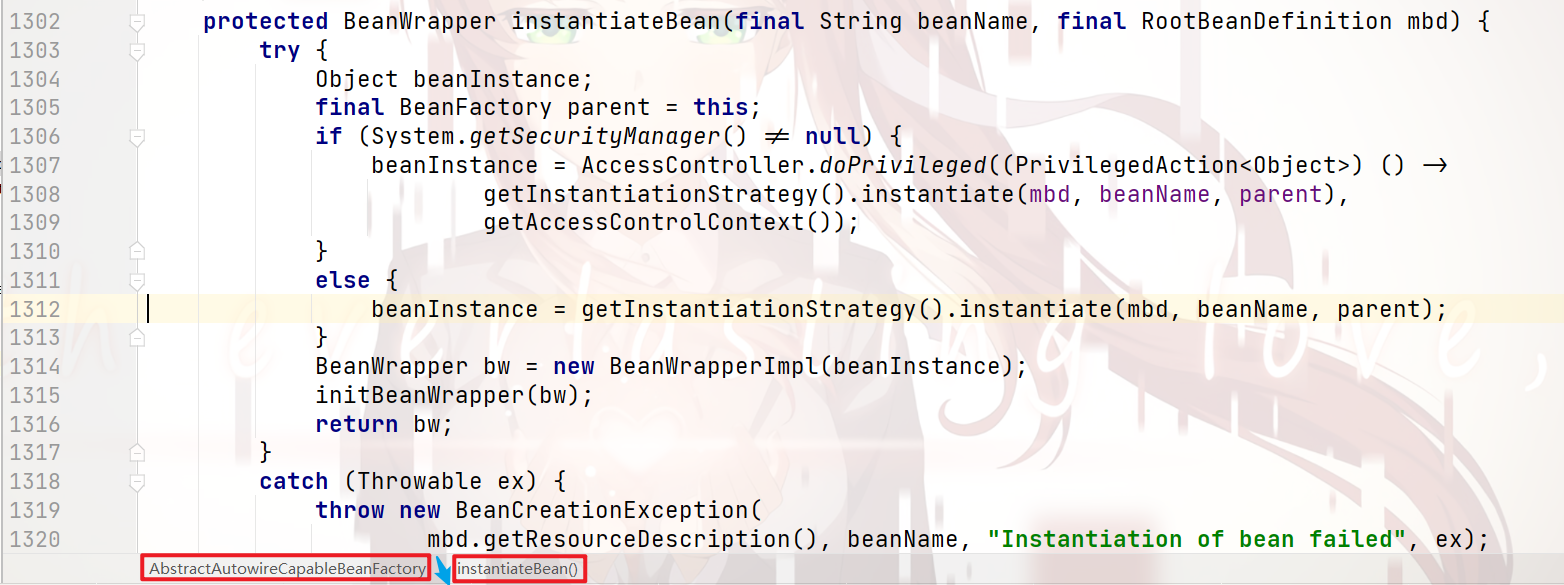
点进 1312行代码:
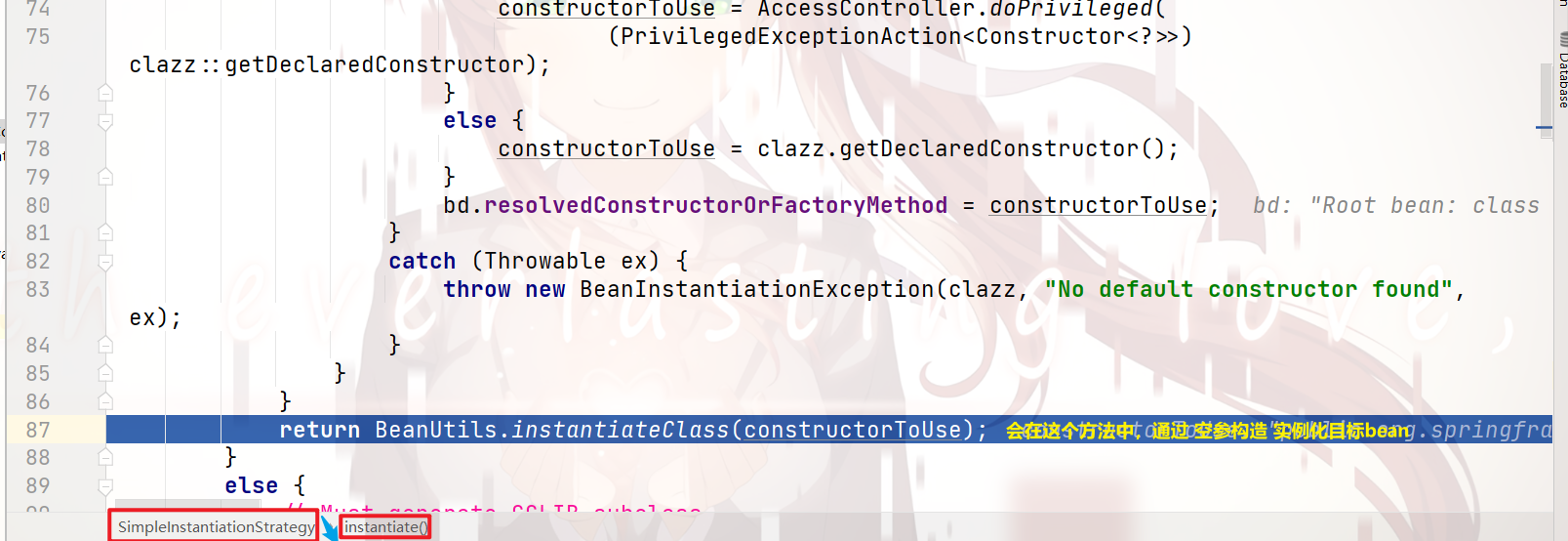
继续跟进去,就没有必要了,
因为,在这里已经通过使用 发射机制 调用 目标bean 的 空参构造 进行了 bean实例化
(注意,这里的 目标bean实例,是 没属性注入的,用专业术语来讲,就是 纯净的)
那么,我们将这个结果返回,来执行之后的代码:
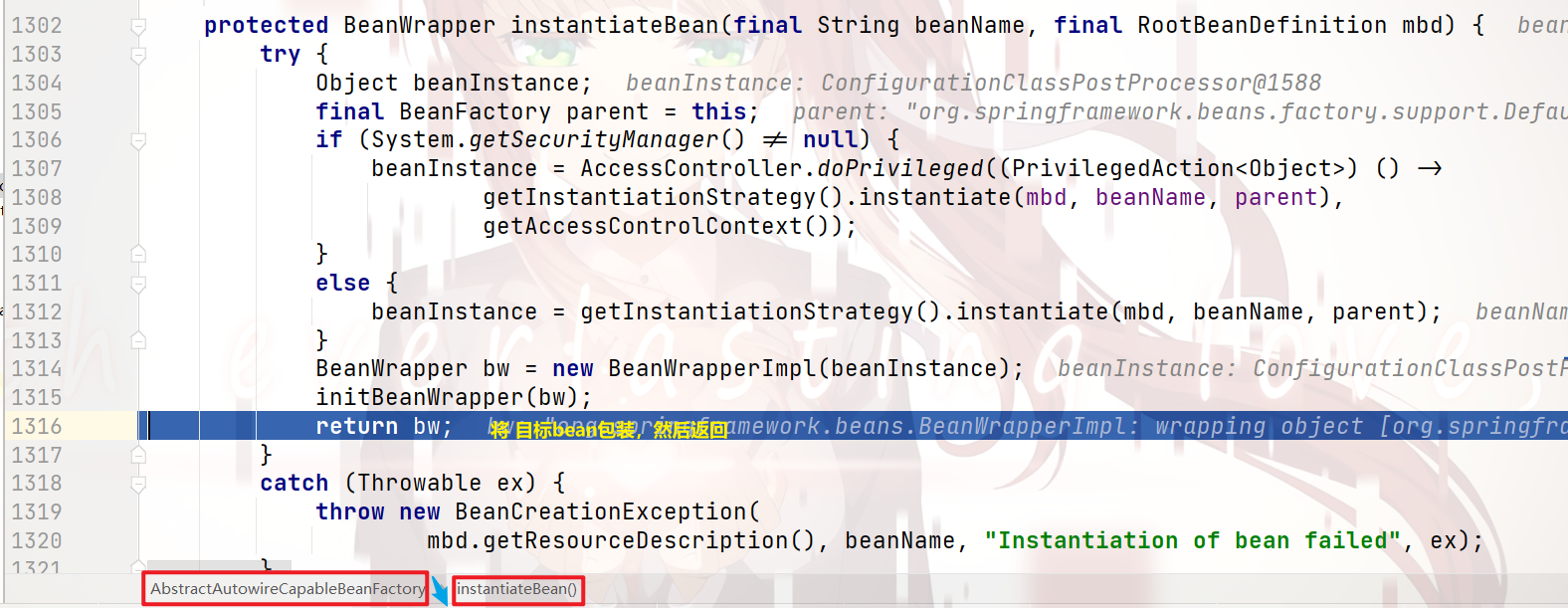
继续返回,向下执行:
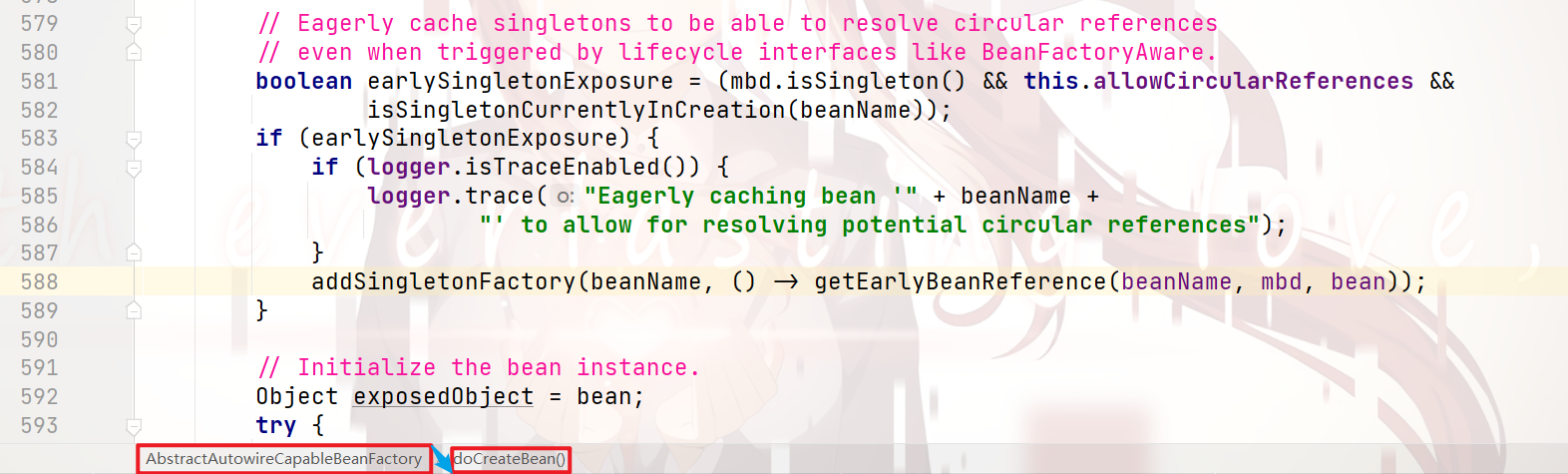
跟进 588行:
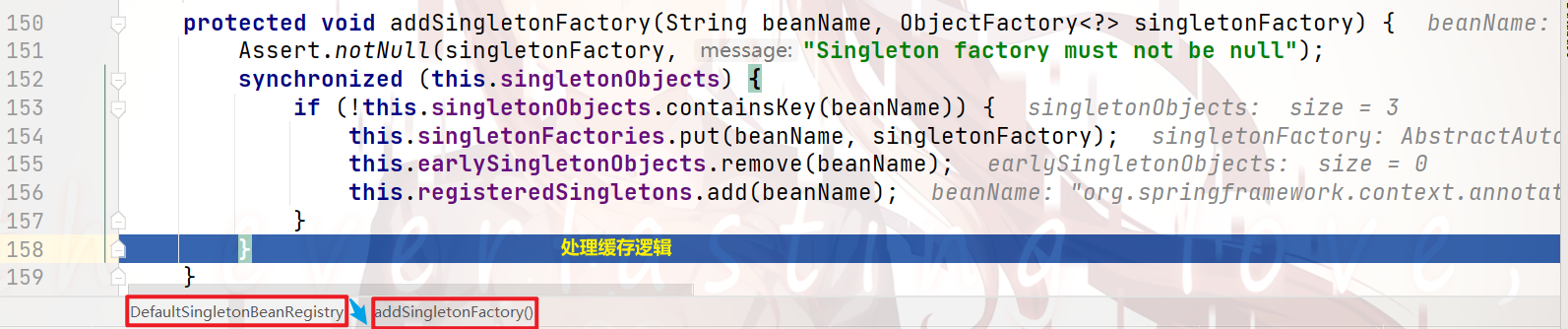
可以看到:
当我们获取到 目标bean 的 实例化纯净对象 后,
就会对缓存做如下处理:
存入 三级缓存
在 二级缓存 中删除
这样做是为了 处理 循环依赖
继续向下执行:
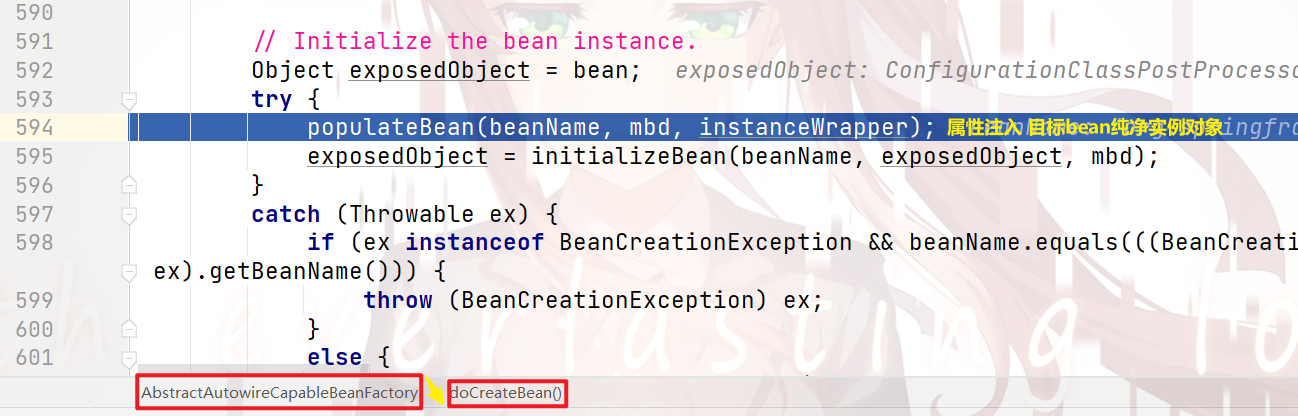
可以看到:
之后的代码,就要执行 属性注入 的相关操作了
那么,最后,本人来通过一张 流程图,来形象地概括下 循环依赖 的 解决流程:
解决流程:
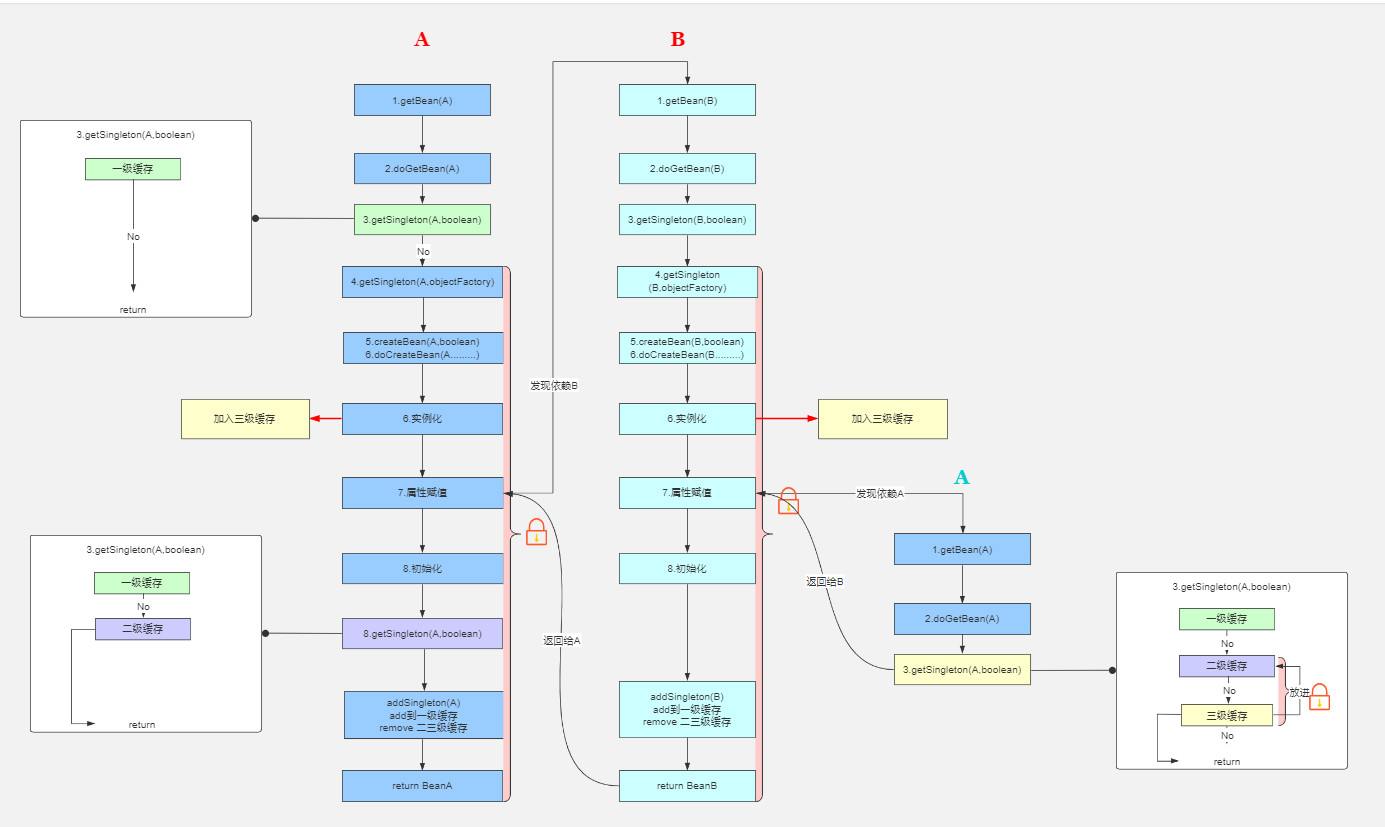
看完上图之后,相信有同学还会有这样的问题:
一级缓存 和 三级缓存 已经够用了,为什么还要 二级缓存 呢?
二级缓存 的作用:
假设我们只用 一级缓存 和 三级缓存 进行IOC实现
那么,当 A依赖B、C,B、C分别都依赖 A 这种情况出现时,
B和C所注入的A,都是通过 三级缓存 获取的 A工厂,所注入的就不是 同一个A对象 了
所以,二级缓存 的主要作用,就是为了保证:
循环依赖 的过程中,注入的对象都是同一个
那么,讲到这里,Spring IOC 的 基本实现流程 就讲解完毕了!
当然,本人讲解的仅是 很小一些规模 的 注解式实现
但是,其实其它注解和属性的解析流程,和上面分析都是类似的,都是通过 reader和scanner 注册时,所注册的各个 processor 去解析
并且一些很牛的功能 —— AOP、国际化、监听器 等功能的实现,都是在 Spring IOC 中实现的
有兴趣的小伙伴请自行阅读源码
那么,本人在这里来做几点小总结:
总结:
设计模式:
首先,我们读了这么长的源码,仔细去品的话,会发现有很多 看上去很 “繁琐” 的代码
(比如:本人说为了节省篇幅,直接定位到执行操作的代码处)
这就是运用到了很多的 设计模式,比如:
- 责任链模式
- 门面模式
- 代理模式
- 工厂模式
- 单例模式
- 策略模式
- 装饰器模式
- 发布订阅模式
- ...
这些 设计模式 的运用,以及很多 设计原则 的符合
使得我们这些 “编程菜鸟” 觉得Spring的代码很 “臃肿”
这种很 graceful 的代码设计,我们还是需要仔细去 品!
反射机制:
通过我们阅读 Spring IOC 的源码,我们也能发现:
创建bean实例,所运用到的就是
反射机制
这也是Java所提供给我们API调用者的一个非常强悍的 工具!
因此,我们学习源码,也会发现 业务开发中几乎用不到的 反射机制 在这里会 大放异彩!
循环依赖 与 三级缓存:
我们若是 在网上去阅读一些别人的博文,或是 看一些教程视频,就会发现很多人在说:
只要创建bean实例对象,就会使用到
三级缓存
当然,这样讲是正确的!
但是,却回答的很模糊
我们若是跟着代码debug一次,就会发现:
只有依赖别的bean,三级缓存 才会被全部使用到
我们创建的对象,若是并不依赖其它bean,那么只会使用到一级缓存
因此,对于别人讲解的知识点,我们能自己验证的,就最好验证一遍!
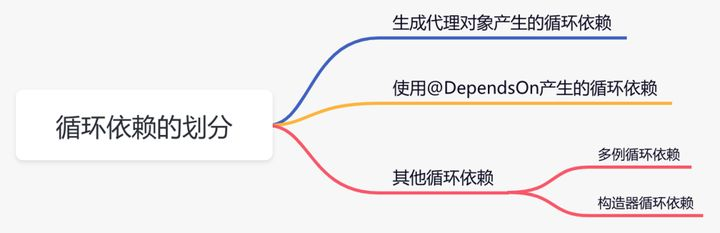
但是,并不是所有 循环依赖,Spring都能帮我们解决:
无法解决的 循环依赖:
还有很重要的一点,注解式 和 配置文件式 的加载流程还是有一些的区别的:
配置文件式 · 源码剖析:
参考文章:
《Spring 如何解决循环依赖的问题》
《Spring IOC 源码剖析 (配置文件式)》
《Spring 是如何解决循环依赖的?》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号