【源码剖析】序列化 底层实现原理

在之前的博文中,本人介绍了 Java对象经 序列化 后,转换成的 内容
相信很多同学在上一篇博文中,仍对 生成的内容的 格式 抱有很多疑惑
那么,在本篇博文中,本人就来在源码角度,来带同学们了解下 对象序列化 的本质:
我们平时使用 序列化 机制,基本上都会是如下步骤:
调用代码:
首先,我们需要一个之后会被序列化的对象:
pojo对象:
package edu.youzg.about_serialize.pojo;
import java.io.Serializable;
/**
* @Author: Youzg
* @CreateTime: 2021-2-16 16:48
* @Description: 带你深究Java的本质!
*/
public class Fan implements Serializable {
private static final long serialVersionUID = 3439052454193760044L;
private String name;
private Integer age;
private int likeNum;
public Fan() {
}
public Fan(String name, Integer age, int likeNum) {
this.name = name;
this.age = age;
this.likeNum = likeNum;
}
public static long getSerialVersionUID() {
return serialVersionUID;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public int getLikeNum() {
return likeNum;
}
public void setLikeNum(int likeNum) {
this.likeNum = likeNum;
}
@Override
public String toString() {
return "Fan{" +
"name='" + name + '\'' +
", age=" + age +
", likeNum=" + likeNum +
'}';
}
}
那么,要被序列化的pojo准备好了,
现在,本人来给出一个 序列化对象 的 小Demo:
序列化对象:
package edu.youzg.about_serialize.demo;
import edu.youzg.about_serialize.pojo.Fan;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
public class YouzgDemo {
public static void main(String[] args) throws IOException {
try {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("./prettyGril.txt"));
Fan aFan = new Fan("prettyGril", 16, 666);
oos.writeObject(aFan);
} catch (Exception e) {
// TODO: handle exception
}
}
}
那么,至于运行结果,由于在前一篇博文中展示过,本人就不再展示了
相信看完前一篇博文的同学,对于最后的输出结果的内容,仍然抱有很多疑惑
那么,接下来,本人就来讲解下输出格式 以及 序列化对象的原理:
序列化 的 本质:
在上面的代码中,我们可以看出:
序列化对象,只需调用两个方法:
new ObjectOutputStream();
和
oos.writeObject();
那么,本人现在来讲解下 这两个方法的源码:
首先是 ObjectOutputStream类的构造函数:
ObjectOutputStream类✨构造函数 源码:
public ObjectOutputStream(OutputStream out) throws IOException {
verifySubclass();
// bout 可以理解为一个 “容器”,用于存储对象序列化后的部分信息
bout = new BlockDataOutputStream(out);
handles = new HandleTable(10, (float) 3.00);
subs = new ReplaceTable(10, (float) 3.00);
enableOverride = false;
writeStreamHeader();
// 将 bout 的 blkmode属性 置为 true
bout.setBlockDataMode(true);
if (extendedDebugInfo) {
debugInfoStack = new DebugTraceInfoStack();
} else {
debugInfoStack = null;
}
}
那么,本人再来展示下 上面方法中 BlockDataOutputStream类 的构造函数:
BlockDataOutputStream类 ✨ 构造函数 源码:
private static final int MAX_BLOCK_SIZE = 1024;
private static final int MAX_HEADER_SIZE = 5;
private static final int CHAR_BUF_SIZE = 256;
private final byte[] buf = new byte[MAX_BLOCK_SIZE];
private final byte[] hbuf = new byte[MAX_HEADER_SIZE];
private final char[] cbuf = new char[CHAR_BUF_SIZE];
private boolean blkmode = false;
private int pos = 0;
private final OutputStream out;
private final DataOutputStream dout;
BlockDataOutputStream(OutputStream out) {
this.out = out;
dout = new DataOutputStream(this);
}
可以看到:
BlockDataOutputStream类 其实就是 封装后的 DataOutputStream类
并 提供了一些 缓冲区 和 参数
我们也可以看到,当执行 ObjectOutputStream类的构造函数时,构造了一个 BlockDataOutputStream类的对象,
并在之后的代码中,
那么,为什么在这几行代码中,本人单独挑选
bout = new BlockDataOutputStream(out);
这行代码进行代码展示呢?
这是因为 在之后的 writeObject方法 的代码中,会主要使用到 bout对象 的方法
在创建完的对象之后,的构造函数 调用了 writeStreamHeader方法
那么,本人就来讲解下 writeStreamHeader方法 的源码:
ObjectOutputStream类✨writeStreamHeader方法 源码:
/**
* Magic number that is written to the stream header.
*/
final static short STREAM_MAGIC = (short)0xaced;
/**
* Version number that is written to the stream header.
*/
final static short STREAM_VERSION = 5;
protected void writeStreamHeader() throws IOException {
bout.writeShort(STREAM_MAGIC);
bout.writeShort(STREAM_VERSION);
}
根据 源码注释,我们能够知道:
STREAM_MAGIC 代表 序列化的标识
STREAM_MAGIC 代表 版本
可以看到:
其实这个方法的 具体实现流程 我们不用跟下去
我们只需要知道这个方法的作用是:发送一个头信息 即可
其实,在 ObjectOutputStream类 的 构造函数 中,还有一个 值得注意的点:
enableOverride = false;
那么,构造函数 的基本流程 我们理解了
现在,本人来讲解下 writeObject方法 的源码:
ObjectOutputStream类✨writeObject方法 源码:
public final void writeObject(Object obj) throws IOException {
if (enableOverride) {
writeObjectOverride(obj);
return;
}
try {
writeObject0(obj, false);
} catch (IOException ex) {
if (depth == 0) {
writeFatalException(ex);
}
throw ex;
}
}
根据上文对代码的分析,我们能够知道:
执行 writeObject方法,其实只会执行 writeObject0方法
那么,接下来,我们来看看 writeObject0方法 的具体实现步骤:
ObjectOutputStream类✨writeObject0方法 源码:
private void writeObject0(Object obj, boolean unshared)
throws IOException
{
boolean oldMode = bout.setBlockDataMode(false);
depth++;
try {
// 1⃣️
// handle previously written and non-replaceable objects
int h;
if ((obj = subs.lookup(obj)) == null) {
writeNull();
return;
} else if (!unshared && (h = handles.lookup(obj)) != -1) {
writeHandle(h);
return;
} else if (obj instanceof Class) {
writeClass((Class) obj, unshared);
return;
} else if (obj instanceof ObjectStreamClass) {
writeClassDesc((ObjectStreamClass) obj, unshared);
return;
}
// 2⃣️
// check for replacement object
Object orig = obj;
Class<?> cl = obj.getClass();
ObjectStreamClass desc;
for (;;) {
// REMIND: skip this check for strings/arrays?
Class<?> repCl;
desc = ObjectStreamClass.lookup(cl, true);
if (!desc.hasWriteReplaceMethod() ||
(obj = desc.invokeWriteReplace(obj)) == null ||
(repCl = obj.getClass()) == cl)
{
break;
}
cl = repCl;
}
if (enableReplace) {
Object rep = replaceObject(obj);
if (rep != obj && rep != null) {
cl = rep.getClass();
desc = ObjectStreamClass.lookup(cl, true);
}
obj = rep;
}
// 3⃣️
// if object replaced, run through original checks a second time
if (obj != orig) {
subs.assign(orig, obj);
if (obj == null) {
writeNull();
return;
} else if (!unshared && (h = handles.lookup(obj)) != -1) {
writeHandle(h);
return;
} else if (obj instanceof Class) {
writeClass((Class) obj, unshared);
return;
} else if (obj instanceof ObjectStreamClass) {
writeClassDesc((ObjectStreamClass) obj, unshared);
return;
}
}
// 4⃣️
// remaining cases
if (obj instanceof String) {
writeString((String) obj, unshared);
} else if (cl.isArray()) {
writeArray(obj, desc, unshared);
} else if (obj instanceof Enum) {
writeEnum((Enum<?>) obj, desc, unshared);
} else if (obj instanceof Serializable) {
writeOrdinaryObject(obj, desc, unshared);
} else {
if (extendedDebugInfo) {
throw new NotSerializableException(
cl.getName() + "\n" + debugInfoStack.toString());
} else {
throw new NotSerializableException(cl.getName());
}
}
} finally {
depth--;
bout.setBlockDataMode(oldMode);
}
}
这里的源码太长了
在本人看来,长的代码的可读性很差
因此,本人在源码中通过 序号注释,将这个方法拆分成了几部分
那么,本人现在就来分别讲解下这几部分的原理:
第一部分:
// 1⃣️
// handle previously written and non-replaceable objects
int h;
if ((obj = subs.lookup(obj)) == null) {
writeNull();
return;
} else if (!unshared && (h = handles.lookup(obj)) != -1) {
writeHandle(h);
return;
} else if (obj instanceof Class) {
writeClass((Class) obj, unshared);
return;
} else if (obj instanceof ObjectStreamClass) {
writeClassDesc((ObjectStreamClass) obj, unshared);
return;
}
从源码的注释中,我们能够知道:
这部分代码的 主要功能 是:
处理 以前编写的对象 和 不可替换对象
绝大多数情况下,我们的代码,是不会进入这个代码块的
所以,这个代码块我们只要知道它的作用就可以了

第二部分:
// 2⃣️
// check for replacement object
Object orig = obj;
Class<?> cl = obj.getClass();
ObjectStreamClass desc;
for (;;) {
// REMIND: skip this check for strings/arrays?
Class<?> repCl;
desc = ObjectStreamClass.lookup(cl, true);
if (!desc.hasWriteReplaceMethod() ||
(obj = desc.invokeWriteReplace(obj)) == null ||
(repCl = obj.getClass()) == cl)
{
break;
}
cl = repCl;
}
if (enableReplace) {
Object rep = replaceObject(obj);
if (rep != obj && rep != null) {
cl = rep.getClass();
desc = ObjectStreamClass.lookup(cl, true);
}
obj = rep;
}
根据注释,我们能够知道:
这部分代码 的功能是 检查可替换对象
其实,我们来读一读源码中的if判断条件,也会发现:
这部分的代码块 也是 不会执行的
第三部分:
// 3⃣️
// if object replaced, run through original checks a second time
if (obj != orig) {
subs.assign(orig, obj);
if (obj == null) {
writeNull();
return;
} else if (!unshared && (h = handles.lookup(obj)) != -1) {
writeHandle(h);
return;
} else if (obj instanceof Class) {
writeClass((Class) obj, unshared);
return;
} else if (obj instanceof ObjectStreamClass) {
writeClassDesc((ObjectStreamClass) obj, unshared);
return;
}
}
根据 源码注释 和 之前代码的讲解,我们能够知道:
这里的代码块的作用是 如果对象被替换,则第二次执行原始检查
但是,我们并没有在上面代码块中替换对象
因此,这部分代码块 是不会执行的
第四部分:
// 4⃣️
// remaining cases
if (obj instanceof String) {
writeString((String) obj, unshared);
} else if (cl.isArray()) {
writeArray(obj, desc, unshared);
} else if (obj instanceof Enum) {
writeEnum((Enum<?>) obj, desc, unshared);
} else if (obj instanceof Serializable) {
writeOrdinaryObject(obj, desc, unshared);
} else {
if (extendedDebugInfo) {
throw new NotSerializableException(
cl.getName() + "\n" + debugInfoStack.toString());
} else {
throw new NotSerializableException(cl.getName());
}
}
从注释中,我们可以得知:
这部分的代码块的作用是:处理剩余类型的对象
其实这里我们也能看出:
就是在处理
字符串、数组、枚举、可序列化对象
由于我们一般序列化进行网络传输的基本上都是 可序列化对象,
那么,本人就来着重讲解下 可序列化对象 的处理方法进行详细讲解:
可序列化对象 的处理:
writeOrdinaryObject 方法✨源码解析:
private void writeOrdinaryObject(Object obj,
ObjectStreamClass desc,
boolean unshared)
throws IOException
{
if (extendedDebugInfo) {
debugInfoStack.push(
(depth == 1 ? "root " : "") + "object (class \"" +
obj.getClass().getName() + "\", " + obj.toString() + ")");
}
try {
// 检查 可序列化性
desc.checkSerialize();
// 先写入一个 “对象标志符”,表示当前传输的数据为 一个对象
bout.writeByte(TC_OBJECT);
// 写入 类元数据
writeClassDesc(desc, false);
handles.assign(unshared ? null : obj);
if (desc.isExternalizable() && !desc.isProxy()) {
writeExternalData((Externalizable) obj);
} else {
// 将 序列化后的对象数据 写入
writeSerialData(obj, desc);
}
} finally {
if (extendedDebugInfo) {
debugInfoStack.pop();
}
}
}
writeClassDesc 方法✨源码解析:
private void writeClassDesc(ObjectStreamClass desc, boolean unshared)
throws IOException
{
int handle;
if (desc == null) {
writeNull();
} else if (!unshared && (handle = handles.lookup(desc)) != -1) {
writeHandle(handle);
} else if (desc.isProxy()) {
writeProxyDesc(desc, unshared);
} else {
// 最终我们的逻辑,只会执行这个方法
writeNonProxyDesc(desc, unshared);
}
}
writeNonProxyDesc 方法✨源码解析:
/**
* Writes class descriptor representing a standard (i.e., not a dynamic
* proxy) class to stream.
*/
private void writeNonProxyDesc(ObjectStreamClass desc, boolean unshared)
throws IOException
{
// 先写入 一个“类元标志符”
bout.writeByte(TC_CLASSDESC);
handles.assign(unshared ? null : desc);
if (protocol == PROTOCOL_VERSION_1) {
// do not invoke class descriptor write hook with old protocol
desc.writeNonProxy(this);
} else {
// 这个if循环,一般会执行else代码块中的代码
writeClassDescriptor(desc);
}
Class<?> cl = desc.forClass();
bout.setBlockDataMode(true);
if (cl != null && isCustomSubclass()) {
ReflectUtil.checkPackageAccess(cl);
}
annotateClass(cl);
bout.setBlockDataMode(false);
// 写入 一个“object描述块结束标志符”
bout.writeByte(TC_ENDBLOCKDATA);
writeClassDesc(desc.getSuperDesc(), false);
}
那么,本人再来展示下上面方法,最后调用的writeClassDescriptor方法的源码:
writeClassDescriptor 方法✨源码解析:
protected void writeClassDescriptor(ObjectStreamClass desc)
throws IOException
{
desc.writeNonProxy(this);
}
可以看到:
这个方法 其实就是包装调用的 writeNonProxy方法
writeNonProxy 方法✨源码解析:
/**
* Writes non-proxy class descriptor information to given output stream.
*/
void writeNonProxy(ObjectOutputStream out) throws IOException {
// 先写入 类名
out.writeUTF(name);
// 先写入 类的序列号
out.writeLong(getSerialVersionUID());
// 计算 类的特性(flags)
byte flags = 0;
if (externalizable) {
flags |= ObjectStreamConstants.SC_EXTERNALIZABLE;
int protocol = out.getProtocolVersion();
if (protocol != ObjectStreamConstants.PROTOCOL_VERSION_1) {
flags |= ObjectStreamConstants.SC_BLOCK_DATA;
}
} else if (serializable) {
// 一般都会执行这里的代码
// 因为我们序列化的对象,一般都是具有serializable属性的
flags |= ObjectStreamConstants.SC_SERIALIZABLE;
}
if (hasWriteObjectData) {
flags |= ObjectStreamConstants.SC_WRITE_METHOD;
}
if (isEnum) {
flags |= ObjectStreamConstants.SC_ENUM;
}
// 将 类的特性 写入,以便“反解析”的进行
out.writeByte(flags);
// 写入 对象的字段前,先写入 字段的数量,以便之后的“反解析”过程的进行
out.writeShort(fields.length);
for (int i = 0; i < fields.length; i++) {
ObjectStreamField f = fields[i];
// 写入 字段的类型码
out.writeByte(f.getTypeCode());
// 写入 字段的名字
out.writeUTF(f.getName());
// 如果是 对象/接口
// 写入 表示对象的字符串
if (!f.isPrimitive()) {
out.writeTypeString(f.getTypeString());
}
}
}
根据本人在源码中的注释,我们也能看出;
这个方法的 作用 是:
写入目标对象的 类型信息
具体写入顺序为:
- 类名
- 类的序列号
- 类的特性
- 字段信息(字段的类型码 + 字段的名字)
- 表示对象的字符串(如果是 对象接口)
那么,上面代码中,本人提及的 字段状态码 是什么呢?
字段类型码:
我们可以从这个方法中,看到 类型 和 类型码 的 对应关系:
/**
* Creates an ObjectStreamField representing a field with the given name,
* signature and unshared setting.
*/
ObjectStreamField(String name, String signature, boolean unshared) {
if (name == null) {
throw new NullPointerException();
}
this.name = name;
this.signature = signature.intern();
this.unshared = unshared;
field = null;
switch (signature.charAt(0)) {
case 'Z': type = Boolean.TYPE; break;
case 'B': type = Byte.TYPE; break;
case 'C': type = Character.TYPE; break;
case 'S': type = Short.TYPE; break;
case 'I': type = Integer.TYPE; break;
case 'J': type = Long.TYPE; break;
case 'F': type = Float.TYPE; break;
case 'D': type = Double.TYPE; break;
case 'L':
case '[': type = Object.class; break;
default: throw new IllegalArgumentException("illegal signature");
}
}
那么,本人来总结下:
| 类型 | 类型码 |
|---|---|
| Boolean | Z |
| Byte | B |
| Character | C |
| Short | S |
| Integer | I |
| Long | J |
| Float | F |
| Double | D |
| 数组 | [ |
| Object(对象/接口) | L |
| 其它 | 非法参数异常 |
writeSerialData 方法✨源码解析:
/**
* Writes instance data for each serializable class of given object, from
* superclass to subclass.
*/
private void writeSerialData(Object obj, ObjectStreamClass desc)
throws IOException
{
// 按照“由父到子”顺序,获取 序列化对象的数据布局
ObjectStreamClass.ClassDataSlot[] slots = desc.getClassDataLayout();
for (int i = 0; i < slots.length; i++) {
ObjectStreamClass slotDesc = slots[i].desc;
if (slotDesc.hasWriteObjectMethod()) { // 如果 目标对象的类 实现了 writeObject方法
PutFieldImpl oldPut = curPut;
curPut = null;
SerialCallbackContext oldContext = curContext;
if (extendedDebugInfo) {
debugInfoStack.push(
"custom writeObject data (class \"" +
slotDesc.getName() + "\")");
}
try {
curContext = new SerialCallbackContext(obj, slotDesc);
bout.setBlockDataMode(true);
slotDesc.invokeWriteObject(obj, this);
bout.setBlockDataMode(false);
bout.writeByte(TC_ENDBLOCKDATA);
} finally {
curContext.setUsed();
curContext = oldContext;
if (extendedDebugInfo) {
debugInfoStack.pop();
}
}
curPut = oldPut;
} else {
// 默认方式,写入实例数据
defaultWriteFields(obj, slotDesc);
}
}
}
那么,本人再来展示下 默认写入实例数据 的源码:
defaultWriteFields 方法✨源码解析:
private void defaultWriteFields(Object obj, ObjectStreamClass desc)
throws IOException
{
Class<?> cl = desc.forClass();
if (cl != null && obj != null && !cl.isInstance(obj)) {
throw new ClassCastException();
}
desc.checkDefaultSerialize();
int primDataSize = desc.getPrimDataSize();
if (primVals == null || primVals.length < primDataSize) {
primVals = new byte[primDataSize];
}
// 获取 对象中的 基本类型的实例数据
// 并将 这些数据 放入 primVals数组 中
desc.getPrimFieldValues(obj, primVals);
// 写入 实例数据数组
bout.write(primVals, 0, primDataSize, false);
// 将 目标对象的成员属性字段 保存在 objVals数组 中
ObjectStreamField[] fields = desc.getFields(false);
Object[] objVals = new Object[desc.getNumObjFields()];
int numPrimFields = fields.length - objVals.length;
desc.getObjFieldValues(obj, objVals);
for (int i = 0; i < objVals.length; i++) {
if (extendedDebugInfo) {
debugInfoStack.push(
"field (class \"" + desc.getName() + "\", name: \"" +
fields[numPrimFields + i].getName() + "\", type: \"" +
fields[numPrimFields + i].getType() + "\")");
}
try {
// 以 “递归式” 将 目标对象 的数据,转换并写入
writeObject0(objVals[i],
fields[numPrimFields + i].isUnshared());
} finally {
if (extendedDebugInfo) {
debugInfoStack.pop();
}
}
}
}
从上面代码和本人的注释,我们能够得出:
这个方法的作用是:
将 实例对象的成员属性,以“递归式”,进行 序列化 并 写入
那么,本人最后,以一张图,来总结下 一个对象进行序列化 的全过程:
总结:
一个对象的 序列化顺序,是按照如下步骤:
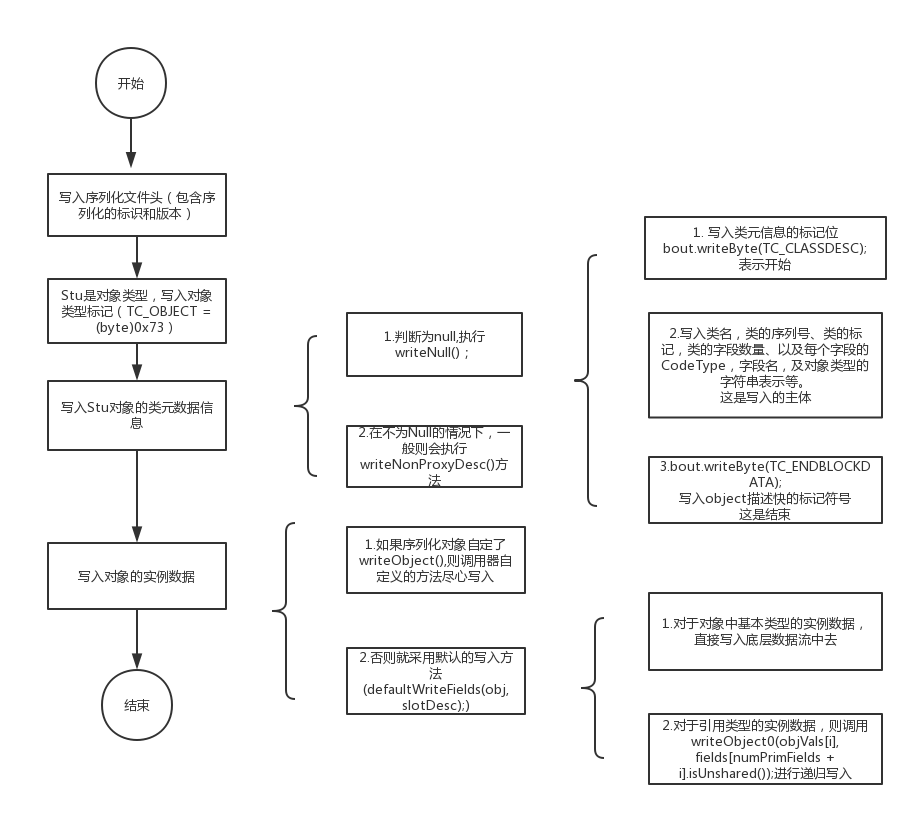
其实这还不算序列化的 全部实现原理,
因为在我们学习序列化流的过程中,transient关键字 和 静态成员属性 是无法被序列化的
因此,整个Java体系的 序列化流程,还是非常庞大的,本篇博文仅 介绍其 核心功能 的 实现原理
那么,到这里,对象序列化 的 底层实现原理就讲解完毕了!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号