详解 线程池 的基本实现

在跟着本人学习了这么久的web以及框架的一些知识后
相信有不少同学都忘记了有关线程的很多知识点
那么,在本文开头,本人先来带同学们回顾下线程的重要知识点:
有关“线程”
多(进程)线程系统:
多个线程“并发”执行,实际上是通过“共享”CPU时间片段实现的
OS将CPU时间分成“CPU时间片段”,每一个片段CPU执行某一个线程;
当时间片段消耗完成,由OS中的“线程调度进程(程序)”负责调度另一个线程执行;
即所谓的“在就绪态的线程中,选择一个线程执行”
线程调度过程:
线程A时间片段到后,线程调度进程需要先“保护现场”,
即,需要将当前正在执行的线程暂时中断,
并将这个线程当前执行的状态保存起来,
当然是为了未来这个线程恢复执行时,能够接着被中断的程序继续执行
上文中的 “现场信息”包括:
- 线程中断前执行的代码的地址;
- 所有寄存器
(包括:通用寄存器、段寄存器、堆栈寄存器、标志位寄存器、IP寄存器);- 线程栈帧
(当前线程的系统堆栈的首地址)
一个线程从运行态变为就绪态或阻塞态,存在如下几种可能性:
- 时间片段到;
- 因I/O资源不能满足而阻塞;
- 软件阻塞(自我阻塞);
- 因出现优先级更高的线程,强行“抢断”当前线程执行。
那么,为什么本人要在这里讲解线程池呢?
一是为了带同学们深入了解下Java线程池的基本实现过程
再者是为了优化本人之前的博文中的一些问题:
前情回顾
在本人之前的《C/SFramwork》专栏中,我们能发现有这样的问题:
服务器在侦听客户端连接时,
每侦听到一个客户端连接请求,都将产生一个线程,
这个线程负责维护与客户端的持续通信
若存在大量客户端连接服务器的情况,那么,就会存在大量线程的产生
这种情况,由于每一个线程通常存在比较长的时间,
因此,情况不是非常严重
但是,在本人之前的博文 —— 《详解 RMI技术 的基本实现》中:
在RMI服务器端,也存在每侦听到一个客户端,
就需要产生一个线程,完成客户端对特定方法的调用
这个过程本质上只是执行了一个方法,
所以,这个线程将很快结束
那么,在大量客户端都存在向服务器端进行RMI请求的情况下,
服务器端会存在海量的线程的“创建”、“销毁”动作
然而,线程的“创建”是耗时、耗资源的!
如果非常频繁地创建、销毁线程,将使得服务器效率降低!
因此,先辈们考虑到上述的问题,就提供了线程池这样的api
那么,本人来介绍下 线程池:
线程池
基本功能:
先创建一些线程,当线程运行结束后,并不直接销毁,
而是将它们存放到一个“线程池”中;
若有新的线程需求,直接从线程池中获取它们,
从而避免频繁、耗资源的线程创建和销毁工作
那么,在本篇博文中,本人就来讲解下 线程池 是怎样实现的:
基本实现
实现思路:
- 每创建一个线程,这个线程都一直保持“运行”状态,
直到整个线程池被用户终结,才会结束并销毁- 应该限定“核心线程”数量;
所谓“核心线程”是一直处在待执行状态的线程;- 当核心线程数量达到极值,后面产生的线程不再进入空闲线程池;
- 还要控制最大并行线程数量;
若最大并行线程数量达到极值,
则,对于用户产生的新的线程需求,不再立刻满足,
而是等待若干时间,再从空线程池中获取可用线程- 对于线程池的结束,
应该考虑到正在执行中的线程的“强制结束” 或者 “等待结束”这两种处理方式
那么,接下来,本人就依据上述的思想,来实现下线程池的核心操作:
首先,本人来给出一个用于规范每一个线程所要完成的 基本任务的Tasker接口:
Tasker接口:
package edu.youzg.about_threadpool.core;
/**
* 用于定义 每一个线程 所要完成的 任务(包括 预先准备、核心任务、善后工作 三步骤)
*/
public interface Tasker {
void beforeTask();
void task();
void afterTask();
}
接下来,本人来给出一个用于处理每一个线程的任务的线程类 —— Worker类:
Worker类:
package edu.youzg.about_threadpool.core;
/**
* 用于执行“任务”的线程
*/
public class Worker implements Runnable {
private volatile Tasker tasker;
private volatile boolean goon;
private ThreadPool threadPool;
Worker(ThreadPool threadPool) { //设置所属的“线程池”
this.threadPool = threadPool;
}
void setTasker(Tasker tasker) {
this.tasker = tasker;
}
/**
* 用于 启动线程
*/
void start() {
goon = true;
new Thread(this).start();
}
/**
* 用于 停止线程
*/
void stop() {
goon = false;
}
/**
* 执行任务,执行一次就结束执行,返回空闲队列中
*/
@Override
public void run() {
while (goon) {
if (tasker != null) {
tasker.beforeTask(); //执行 前置任务
try {
tasker.task(); //执行 核心任务
} catch (Throwable t) {
t.printStackTrace();
}
tasker.afterTask(); //执行 善后工作
tasker = null; //释放指针
threadPool.workerFree(this); //将该worker放入“空闲队列”中
}
}
}
}
那么,有了上述的铺垫,
现在本人就来给出 模拟的线程池 的核心类 —— ThreadPool类:
ThreadPool类:
package edu.youzg.about_threadpool.core;
import java.util.LinkedList;
import java.util.List;
import java.util.Queue;
import java.util.concurrent.ConcurrentLinkedQueue;
/**
* 模拟实现的 线程池
*/
public class ThreadPool {
private final Queue<Worker> freeThreadList; //空闲的 线程队列
private final List<Worker> busyThreadList; //正在工作的 线程列表
public ThreadPool() {
freeThreadList = new ConcurrentLinkedQueue<Worker>();
busyThreadList = new LinkedList<>();
createWorker(5);
}
/**
* 终止所有正在工作的worker
* @return busyThreadList是否为空
*/
public boolean stop() {
Worker worker;
if (busyThreadList.isEmpty()) {
while ((worker = freeThreadList.poll()) != null) {
worker.stop();
}
return true;
}
return false;
}
/**
* 根据所传“数量”,创造指定数量的 Worker,并将其加入到 “空闲列表”(freeThreadList中),以便我们之后需要时的调用
* @param count
*/
private void createWorker(int count) {
for (int i = 0; i < count; i++) {
Worker worker = new Worker(this);
worker.start();
freeThreadList.add(worker);
}
}
/**
* 获取空闲的线程,并为其设置“工作”,将其放入 “工作队列”(busyThreadList中)
* @param tasker
*/
public void setTask(Tasker tasker) {
Worker worker = freeThreadList.poll();
if (worker == null) { //如果空闲列表为空,我们则“扩容”
createWorker(3);
worker = freeThreadList.poll(); //取得新增长的“空闲列表”中的第一个值
}
worker.setTasker(tasker); //为该线程设置“任务”
busyThreadList.add(worker); //将这个worker放入“工作队列”中
}
/**
* 将所传的Worker “空闲化”
* @param worker 需要“空闲化”的worker
*/
void workerFree(Worker worker) {
busyThreadList.remove(worker); //将这个worker从busyThreadList中“移除”
if (freeThreadList.size() < 20) {
freeThreadList.offer(worker); //将该worker设置进“空闲列表”中
} else {
worker.stop(); //将该worker之前的任务“解除”
}
}
}
可能会有同学对于上述的两个成员有如下疑问:
问题:
为什么 “空闲队列” 和 “工作列表” 是两种不同的数据存储类型 呢?
答曰:
- 由于“空闲队列”是供我们提取直接运用的,
可能会存在着一些顺序上的逻辑
所以我们将“空闲队列”用 有序 的 队列类型存储- 而 “工作列表”是用于存储正在执行某项“工作”的线程,
由于CPU的时间片段分配问题,
我们并不知道这些会在何时执行完各自的工作,也就不知道执行完成顺序
所以,这里采用 无序 的 列表类型来存储
那么,现在我们来通过一个测试类来看看所制作的线程池的基本功能是否实现:
自定义测试线程类:
package edu.youzg.about_threadpool.test;
import edu.youzg.about_threadpool.core.Tasker;
/**
* 被 Tasker接口 所规范
*/
public class MyThread implements Tasker {
private volatile boolean goon;
public MyThread() {
goon = true;
}
public void finished() {
goon = false;
}
@Override
public void beforeTask() {
System.out.println("beforeTask");
}
/**
* 每隔1s 输出“工作一下”
*/
@Override
public void task() {
while (goon) {
try {
Thread.sleep(1000);
System.out.println("工作一下!");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
@Override
public void afterTask() {
System.out.println("afterTask");
}
}
测试类:
package edu.youzg.about_threadpool.core;
import edu.youzg.about_threadpool.test.MyThread;
/**
* @Author: Youzg
* @CreateTime: 2020-05-11 11:58
* @Description: 带你深究Java的本质!
*/
public class MyTest {
public static void main(String[] args) {
ThreadPool pool = new ThreadPool();
Worker worker = new Worker(pool);
System.out.println("线程池开始");
worker.start();
try {
Thread.sleep(666);
} catch (InterruptedException e) {
e.printStackTrace();
}
MyThread myThread = new MyThread();
System.out.println("开始工作!");
worker.setTasker(myThread);
try {
Thread.sleep(6666);
} catch (InterruptedException e) {
e.printStackTrace();
}
myThread.finished();
System.out.println("工作结束!");
try {
Thread.sleep(1234);
} catch (InterruptedException e) {
e.printStackTrace();
}
worker.stop();
System.out.println("线程池结束");
}
}
那么,现在本人来展示下运行结果:
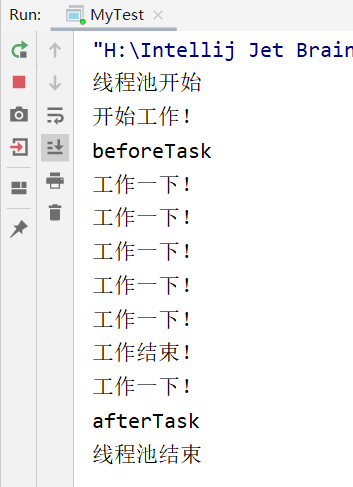
那么,我们能从运行结果看得出:
线程池的基本功能已经实现了!
jdk提供的线程池:
最后,如果想要了解jdk提供的线程池的同学,请点击下方链接:
《详解 线程池》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号