Python3.6学习笔记(三)
面向对象编程
面向对象编程 Object Oriented Programming 简称 OOP,是一种程序设计思想。OOP把对象作为程序的基本单元,一个对象包含了数据和操作数据的函数。
面向过程的程序设计把计算机程序视为一系列的命令集合,即一组函数的顺序执行。为了简化程序设计,面向过程把函数继续切分为子函数,即把大块函数通过切割成小块函数来降低系统的复杂度。
而面向对象的程序设计把计算机程序视为一组对象的集合,而每个对象都可以接收其他对象发过来的消息,并处理这些消息,计算机程序的执行就是一系列消息在各个对象之间传递。
在Python中,所有数据类型都可以视为对象,当然也可以自定义对象。自定义的对象数据类型就是面向对象中的类(Class)的概念。面向对象的抽象程度又比函数要高,因为一个Class既包含数据,又包含操作数据的方法。
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
def print_score(self):
print('%s: %s' % (self.name, self.score))
类和实例
class后面紧接着是类名,即Student,类名通常是大写开头的单词,紧接着是(object),表示该类是从哪个类继承下来的,继承的概念我们后面再讲,通常,如果没有合适的继承类,就使用object类,这是所有类最终都会继承的类。
定义好了Student类,就可以根据Student类创建出Student的实例,创建实例是通过类名+()实现的。__init__函数与其它函数有所不同,它的第一个参数永远是实例变量self,并且,调用时,不用传递该参数。
数据封装
类本身拥有数据和方法,相当于将“数据”封装起来了。对于外部来说,并不需要知道内部的逻辑。
访问限制
Class可以有属性和方法,我们可以对属性和方法进行控制,以达到允许或者不允许外部访问的目的。如果要让内部属性不被外部访问,可以把属性的名称前加上两个下划线__,在Python中,实例的变量名如果以__开头,就变成了一个私有变量(private),只有内部可以访问,外部不能访问。
class Student(object):
def __init__(self, name, score):
self.__name = name
self.__score = score
def print_score(self):
print('%s: %s' % (self.__name, self.__score))
def get_name(self):
return self.__name
def get_score(self):
return self.__score
def set_score(self, score):
if 0 <= score <= 100:
self.__score = score
else:
raise ValueError('bad score’)
在Python中,变量名类似
__xxx__的,也就是以双下划线开头,并且以双下划线结尾的,是特殊变量,特殊变量是可以直接访问的,不是private变量,所以,不能用__name__、__score__这样的变量名。
继承和多态
在OOP程序设计中,当我们定义一个class的时候,可以从某个现有的class继承,新的class称为子类(Subclass),而被继承的class称为基类、父类或超类(Base class、Super class)。
class Animal(object):
def run(self):
print('Animal is running…')
class Dog(Animal):
def run(self):
print('Dog is running...')
class Cat(Animal):
def run(self):
print('Cat is running…')
当子类和父类都存在相同的run()方法时,我们说,子类的run()覆盖了父类的run(),在代码运行的时候,总是会调用子类的run()。这样,我们就获得了继承的另一个好处:多态。在继承关系中,如果一个实例的数据类型是某个子类,那它的数据类型也可以被看做是父类。但是,反过来就不行。
对于一个变量,我们只需要知道它是Animal类型,无需确切地知道它的子类型,就可以放心地调用run()方法,而具体调用的run()方法是作用在Animal、Dog、Cat还是Tortoise对象上,由运行时该对象的确切类型决定,这就是多态真正的威力:调用方只管调用,不管细节,而当我们新增一种Animal的子类时,只要确保run()方法编写正确,不用管原来的代码是如何调用的。这就是著名的“开闭”原则:
对扩展开放:允许新增Animal子类;
对修改封闭:不需要修改依赖Animal类型的外部函数。
鸭子类型
对于静态语言(例如Java)来说,如果需要传入Animal类型,则传入的对象必须是Animal类型或者它的子类,否则,将无法调用run()方法。对于Python这样的动态语言来说,则不一定需要传入Animal类型。我们只需要保证传入的对象有一个run()方法就可以了。这就是动态语言的“鸭子类型”,它并不要求严格的继承体系,一个对象只要“看起来像鸭子,走起路来像鸭子”,那它就可以被看做是鸭子。
获取对象信息
判断Python中对象的类型,可以用以下方法。
type()
基本类型都可以用type()判断,基本数据类型可以直接写int、str,判断是否函数需要使用types中定义的常量。
>>> import types
>>> def fn():
... pass
...
>>> type(fn)==types.FunctionType
True
>>> type(abs)==types.BuiltinFunctionType
True
>>> type(lambda x: x)==types.LambdaType
True
>>> type((x for x in range(10)))==types.GeneratorType
True
isinstance()
对于类和实例,使用type()就不是很方便,可以使用isinstance()。基本数据类型也可以使用isinstance()判断。还可以判断一个变量是否是某些类型中的一种。
>>> isinstance([1, 2, 3], (list, tuple))
True
>>> isinstance((1, 2, 3), (list, tuple))
True
dir()
如果要获得一个对象的所有属性和方法,可以使用dir()函数,它返回一个包含字符串的list,比如,获得一个str对象的所有属性和方法。
实例属性和类属性
Python类创建的实例可以任意绑定属性,如果需要对类本身绑定属性,则需要在类中定义,这就区分了类属性和实例属性。
在编写程序的时候,千万不要把实例属性和类属性使用相同的名字,因为相同名称的实例属性将屏蔽掉类属性,但是当你删除实例属性后,再使用相同的名称,访问到的将是类属性。
面向对象高级编程
数据封装、继承和多态是面相对象程序设计中的三个基本概念,另外还有很多特性,包括多重继承、定制类等。
使用 slots()
在Python中,可以对类动态的增加属性和方法,这在静态语言中很难实现。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
class Student(object):
def __init__(self):
print("Instance Created")
Tracy = Student()
Tracy.age = 30
Bob = Student()
Bob.age = 41
Ceaser = Student()
print(Tracy.age)
print(Bob.age)
def set_age(self, age):
self.age = age
from types import MethodType
s = Student()
s.set_age = MethodType(set_age, s)
s.set_age(25)
print(s.age)
Student.set_age = set_age
Ceaser.set_age(33)
print(Ceaser.age)
但这也带来一个问题,属性和方法可以随意更改,如果我们要限制怎么办?可以使用__slots。Python允许在定义class的时候,定义一个特殊的__slots__变量,来限制该class实例能添加的属性。使用__slots__要注意,__slots__定义的属性仅对当前类实例起作用,对继承的子类是不起作用的。
class Student(object):
__slots__ = ('name', 'age') # 用tuple定义允许绑定的属性名称
使用@Property
Python中实例的属性暴露在外面可以随便修改,这样就无法保证属性的有效性符合校验规则。虽然可以通过设置Setter和Getter来进行检查,但如果属性特别多,操作起来又比较麻烦。
还记得装饰器(decorator)可以给函数动态加上功能吗?对于类的方法,装饰器一样起作用。Python内置的@property装饰器就是负责把一个方法变成属性调用的。
class Student(object):
@property
def score(self):
return self._score
@score.setter
def score(self, value):
if not isinstance(value, int):
raise ValueError('score must be an integer!')
if value < 0 or value > 100:
raise ValueError('score must between 0 ~ 100!')
self._score = value
@property的实现比较复杂,我们先考察如何使用。把一个getter方法变成属性,只需要加上@property就可以了,此时,@property本身又创建了另一个装饰器@score.setter,负责把一个setter方法变成属性赋值,于是,我们就拥有一个可控的属性操作。
>>> s = Student()
>>> s.score = 60 # OK,实际转化为s.set_score(60)
>>> s.score # OK,实际转化为s.get_score()
60
>>> s.score = 9999
Traceback (most recent call last):
...
ValueError: score must between 0 ~ 100!
还可以定义只读属性,只定义getter方法,不定义setter方法就是一个只读属性。
class Student(object):
@property
def birth(self):
return self._birth
@birth.setter
def birth(self, value):
self._birth = value
@property
def age(self):
return 2015 - self._birth
多重继承
继承是面向对象编程的一个重要的方式,因为通过继承,子类就可以扩展父类的功能。举例来说对于动物的对象设计,可以按照“哺乳动物”、“鸟类”来设计分类对象,按照不同的维度,也可以按照“能跑的”、“能飞的”或者“宠物”、“非宠物”设计分类,如果按照单一继承的方式,类的设计就像下图,会变的非常复杂。
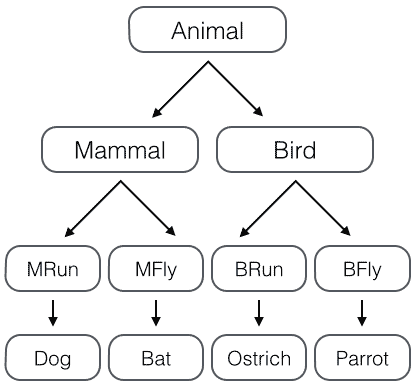
正确的办法是采用多重继承。一个子类就可以同时获得多个父类的所有功能。在设计类的继承关系时,通常,主线都是单一继承下来的,例如,Ostrich继承自Bird。但是,如果需要“混入”额外的功能,通过多重继承就可以实现,比如,让Ostrich除了继承自Bird外,再同时继承Runnable。这种设计通常称之为MixIn。
class Animal(object):
pass
# 大类:
class Mammal(Animal):
pass
class Bird(Animal):
pass
# 各种动物:
class Dog(Mammal):
pass
class Bat(Mammal):
pass
class Parrot(Bird):
pass
class Ostrich(Bird):
pass
class Runnable(object):
def run(self):
print('Running...')
class Flyable(object):
def fly(self):
print('Flying…’)
class Dog(Mammal, Runnable):
pass
class Bat(Mammal, Flyable):
pass
Python自带的很多库也使用了MixIn。举个例子,Python自带了TCPServer和UDPServer这两类网络服务,而要同时服务多个用户就必须使用多进程或多线程模型,这两种模型由ForkingMixIn和ThreadingMixIn提供。通过组合,我们就可以创造出合适的服务来。
定制类
类似于__slots__,Python的class中还有许多这样有特殊用途的函数,可以帮助我们定制类。
str
定义print 函数调用时的返回结果。
>>> class Student(object):
... def __init__(self, name):
... self.name = name
... def __str__(self):
... return 'Student object (name: %s)' % self.name
...
>>> print(Student('Michael'))
Student object (name: Michael)
repr
定义返回程序开发者看到的字符串,也就是在命令行状态下执行时的返回值。
class Student(object):
def __init__(self, name):
self.name = name
def __str__(self):
return 'Student object (name=%s)' % self.name
__repr__ = __str__
iter
如果一个类想被用于for … in循环,类似list或tuple那样,就必须实现一个__iter__()方法,该方法返回一个迭代对象,然后,Python的for循环就会不断调用该迭代对象的__next__()方法拿到循环的下一个值,直到遇到StopIteration错误时退出循环。
class Fib(object):
def __init__(self):
self.a, self.b = 0, 1 # 初始化两个计数器a,b
def __iter__(self):
return self # 实例本身就是迭代对象,故返回自己
def __next__(self):
self.a, self.b = self.b, self.a + self.b # 计算下一个值
if self.a > 100000: # 退出循环的条件
raise StopIteration()
return self.a # 返回下一个值
getitem
Fib实例虽然能作用于for循环,看起来和list有点像,但是,把它当成list来使用还是不行,比如,取第5个元素。
class Fib(object):
def __getitem__(self, n):
if isinstance(n, int): # n是索引
a, b = 1, 1
for x in range(n):
a, b = b, a + b
return a
if isinstance(n, slice): # n是切片
start = n.start
stop = n.stop
if start is None:
start = 0
a, b = 1, 1
L = []
for x in range(stop):
if x >= start:
L.append(a)
a, b = b, a + b
return L
通过上面的方法,我们自己定义的类表现得和Python自带的list、tuple、dict没什么区别,这完全归功于动态语言的“鸭子类型”,不需要强制继承某个接口。
getattr
正常情况下,当我们调用类的方法或属性时,如果不存在,就会报错。要避免这个错误,除了可以加上一个属性外,Python还有另一个机制,那就是写一个__getattr__()方法,动态返回一个属性。
class Student(object):
def __init__(self):
self.name = 'Michael'
def __getattr__(self, attr):
if attr=='score':
return 99
call
任何类,只需要定义一个__call__()方法,就可以直接对实例进行调用。__call__()还可以定义参数。对实例进行直接调用就好比对一个函数进行调用一样,所以你完全可以把对象看成函数,把函数看成对象,因为这两者之间本来就没啥根本的区别。
class Student(object):
def __init__(self, name):
self.name = name
def __call__(self):
print('My name is %s.' % self.name)
使用枚举类
之前说到过,Python中其实不存在常量,但是可以通过枚举类的方式来变通实现。
from enum import Enum
Month = Enum('Month', ('Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'))
for name, member in Month.__members__.items():
print(name, '=>', member, ',', member.value)
from enum import Enum, unique
@unique #@unique装饰器可以帮助我们检查保证没有重复值。
class Weekday(Enum):
Sun = 0 # Sun的value被设定为0
Mon = 1
Tue = 2
Wed = 3
Thu = 4
Fri = 5
Sat = 6
这样我们就获得了Month类型的枚举类,可以直接使用Month.Jan来引用一个常量,或者枚举它的所有成员。
使用元类
type()
type()函数可以查看一个类型或变量的类型,Hello是一个class,它的类型就是type,而h是一个实例,它的类型就是class Hello。我们说class的定义是运行时动态创建的,而创建class的方法就是使用type()函数。
type()函数既可以返回一个对象的类型,又可以创建出新的类型,比如,我们可以通过type()函数创建出Hello类,而无需通过class Hello(object)…的定义。
>>> def fn(self, name='world'): # 先定义函数
... print('Hello, %s.' % name)
...
>>> Hello = type('Hello', (object,), dict(hello=fn)) # 创建Hello class
>>> h = Hello()
>>> h.hello()
Hello, world.
>>> print(type(Hello))
<class 'type'>
>>> print(type(h))
<class '__main__.Hello’>
要创建一个class对象,type()函数依次传入3个参数:
1.class的名称;
2.继承的父类集合,注意Python支持多重继承,如果只有一个父类,别忘了tuple的单元素写法;
3.class的方法名称与函数绑定,这里我们把函数fn绑定到方法名hello上。
通过type()函数创建的类和直接写class是完全一样的,因为Python解释器遇到class定义时,仅仅是扫描一下class定义的语法,然后调用type()函数创建出class。
metaclass
metaclass,直译为元类,简单的解释就是:
当我们定义了类以后,就可以根据这个类创建出实例,所以:先定义类,然后创建实例。
但是如果我们想创建出类呢?那就必须根据metaclass创建出类,所以:先定义metaclass,然后创建类。
# metaclass是类的模板,所以必须从`type`类型派生:
class ListMetaclass(type):
def __new__(cls, name, bases, attrs):
attrs['add'] = lambda self, value: self.append(value)
return type.__new__(cls, name, bases, attires)

参考资料:
1、Python 3 官方文档

 浙公网安备 33010602011771号
浙公网安备 33010602011771号