
Python学习多线程、多进程、多协程记录
一、多线程
应用于 请求和IO
#1. Python中关于使用多线程多进程的库/模块

#2. 选择并发编程方式 (多线程Thread、多进程Process、多协程Coroutine)
前置知识:
一、三种有各自的应用场景
1. 一个进程中可以启动多个线程
2. 一个线程中可以启动多个协程
二、各自优缺点
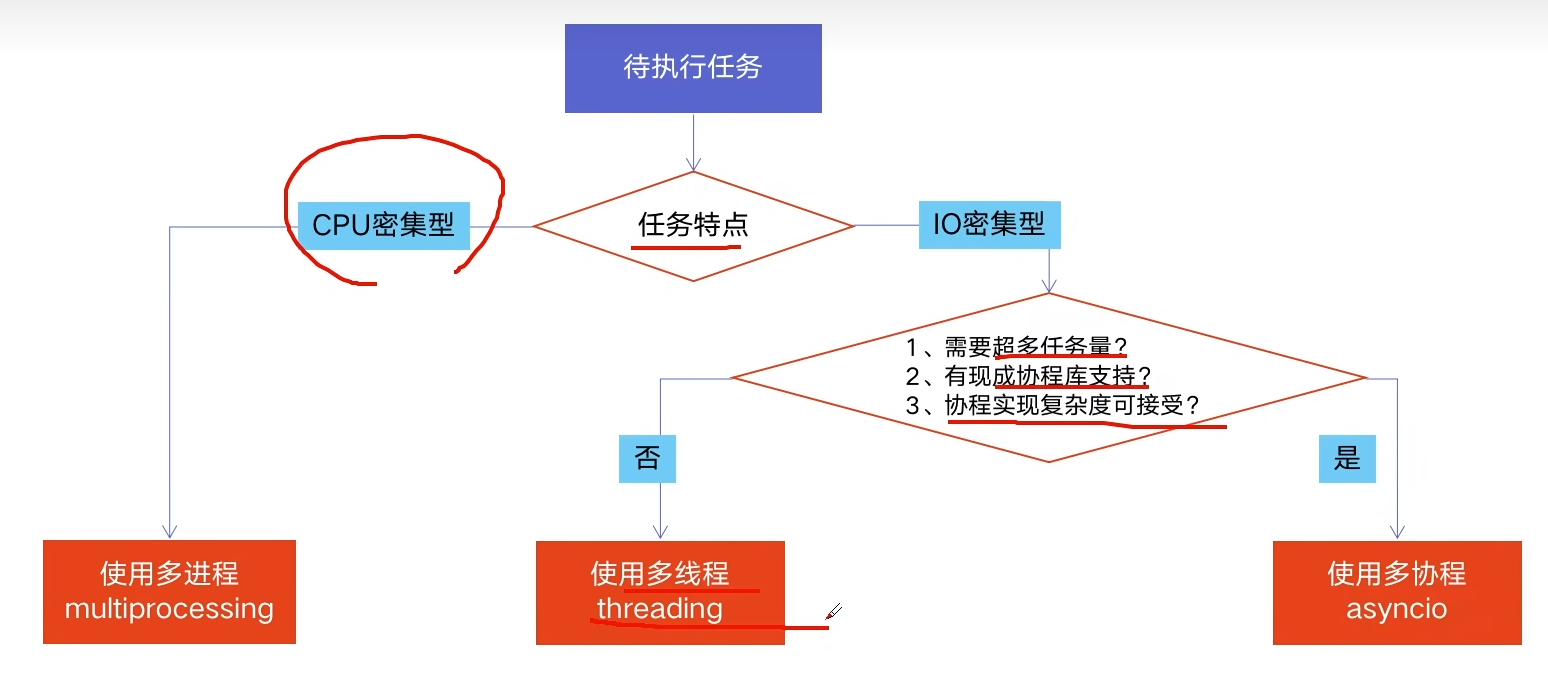
1). 多线程Thread: (multiprocessing) [CPU密集型计算]
优点:可以利用多核CPU併行运算
缺点:占用资源最多、可启动数目比线程少
2). 多进程Process: (threading) [IO密集型计算、同时运行的任务数目要求不多]
优点: 相比进程、更轻量级、占用资源少
缺点:
相比进程:多线程只能并发执行,不能利用多CPU(GIL/全局解释器锁)
相比协程:启动数目有限制,占用内存资源,有线程切换开销
3). 多协程Coroutine: (asyncio) [IO密集型计算、需要超多任务运行、但有现成库支持的场景]
优点:内存开销最少、启动协程数量最多
缺点:支持的库有限制(aiohttp(支持) vs requests(不支持))、代码实现复杂
三、如何选择
#3. 线程安全Lock
用法1: try-finally模式
import threading
lock = threading.Lock() #要写在最外层
lock.acquire() #与try..finally同层
try:
#do something
finally:
lock.release()
用法2: with模式
import threading
lock = threading.Lock() #要写在最外层
whith lock:
# do something
#4. 线程池ThreadPoolExecutor
原理:
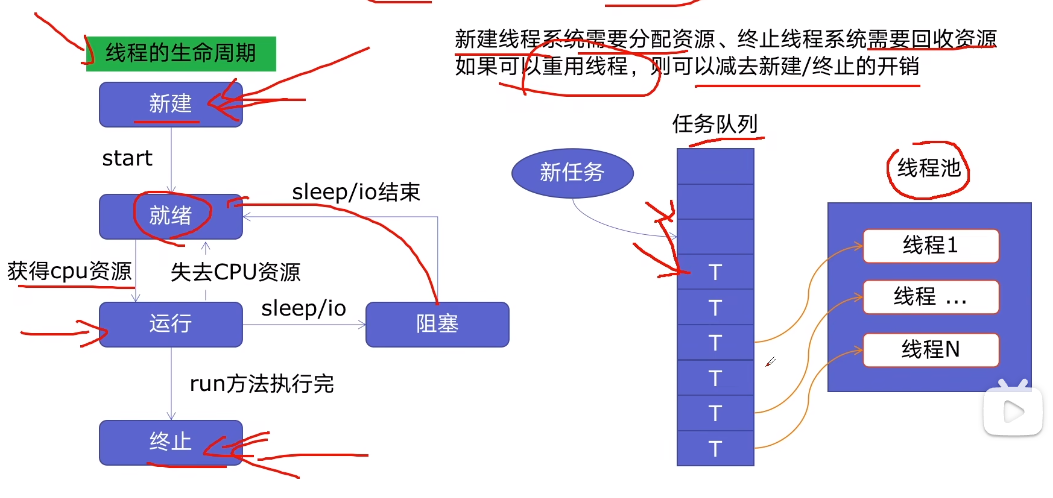
好处:
1、提升性能:因为减去了大量新建、终止线程的开销,
重用了线程资源;
2、适用场景:适合处理突发性大量请求或需要大量线程完成任务、但实际任务处理时间较短
3、防御功能:能有效避免系统因为创建线程过多,而导致系统负荷过大相应变慢等问题
4、代码优势:使用线程池的语法比自己新建线程执行线程更加简洁
使用语法:
from concurrent.futures import ThreadPoolExecutor, as_completed
import itertools
def add(a, b):
return a+b
a_list = [1, 3, 5, 7, 9]
b_list = [2, 4, 6, 8, 10]
用法一: 运用map函数
#map()实现方法
with ThreadPoolExecutor(max_workers=5) as pool:
results = pool.map(add, a_list, b_list)
print(list(results))
用法二: future模式, 更强大
#futures实现方法
with ThreadPoolExecutor(max_workers=5) as pool:
futures = [pool.submit(add, a_list[i], b_list[i]) for i in range(5)]
for future in futures:
print(future.result())
for future in as_completed(futures):
print(future.result()) #乱序输出
#5. Python使用线程池在Web服务中实现加速
优化之前:
import flask
import json
import time
app = flask.Flask(__name__)
def read_file():
time.sleep(0.1)
return 'file result'
def read_db():
time.sleep(0.2)
return 'db result'
def read_api():
time.sleep(0.3)
return 'api result'
@app.route("/")
def index():
result_file = read_file()
result_db = read_db()
result_api = read_api()
return json.dumps({
"result_file": result_file,
"result_db": result_db,
"result_api": result_api,
})
if __name__ == '__main__':
app.run()
优化之后:
import flask
import json
import time
from concurrent.futures import ThreadPoolExecutor
app = flask.Flask(__name__)
pool = ThreadPoolExecutor()
def read_file():
time.sleep(0.1)
return 'file result'
def read_db():
time.sleep(0.2)
return 'db result'
def read_api():
time.sleep(0.3)
return 'api result'
@app.route("/")
def index():
result_file = pool.submit(read_file)
result_db = pool.submit(read_db)
result_api = pool.submit(read_api)
return json.dumps({
"result_file": result_file.result(),
"result_db": result_db.result(),
"result_api": result_api.result(),
})
if __name__ == '__main__':
app.run()
二、多进程
#6. 多进程multiprocessing

三、多协程(单线程)
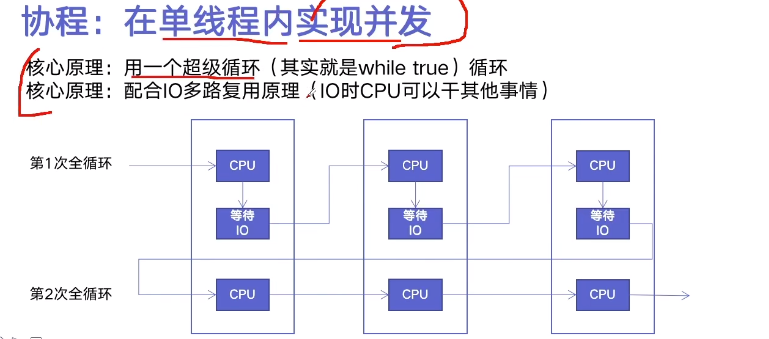
IO部分默认后台执行: 用await关键字
CPU部分优先执行: 用async定义
#7. Python异步lO实现并发爬虫 asyncio
requests不支持asyncio, 需要用aiohttp、httpx
import asyncio
#获取事件循环
loop asyncio.get_event_loop()
#定义协程
async def myfunc(url):
await get_url(url) #对应IO
#创建task列表
tasks = [loop.create_task(myfunc(url)) for url in urls]
#执行爬虫事件列表
loop.run_until_complete(asyncio.wait(tasks))
import asyncio
import aiohttp
import spider_common as sc
import time
async def async_craw(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
result = await resp.text()
print(f"craw url: {url}, {len(result)}")
loop = asyncio.get_event_loop()
tasks = [
loop.create_task(async_craw(url))
for url in sc.urls
]
start = time.time()
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print("use time seconds: ", end - start)
#8. 在异步IO中使用信号量控制爬虫并发度


 浙公网安备 33010602011771号
浙公网安备 33010602011771号