Xpath爬虫使用记录
#1.Xpath获取指定元素相邻的不被标签括起来的文本
div/preceding-sibling::a[1] 与div上面相邻的第一个a标签元素
div/following-sibling::a[1] 与div下面相邻的第一个a标签元素
div/preceding-sibling::text()[1] 与div上面相邻的第一个非标签文本元素
div/following-sibling::text()[1] 与div下面相邻的第一个非标签文本元素
实战:
如图:
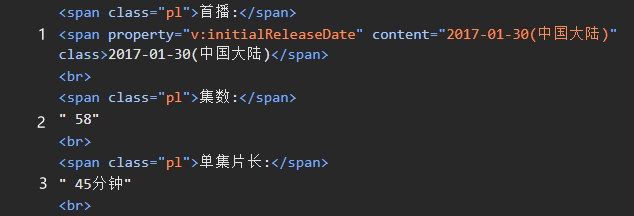
已知图片中标注1、2、3对应的内容
在业务中我需要获取标志2对应的"58"这个值,但是这个值不包括在某个标签中,在span“集数”和br标签之间,为了减小获取"58"这个值不被之前的标签数量的影响
-
先获取标签1所对应的元素,因为标签1有property="v:initialReleaseDate"这个属性和属性值,所以很容易用xpath获取,且具有唯一性:
//span[@property="v:initialReleaseDate"] -
获取标签1元素对象之后,我们可以根据标签1为基准,算一下"58"这个值是相邻的第几个元素,如图可知除去span标签不看,是相邻2个元素(包括br在内)
*[@id="info"]/span[@property="v:initialReleaseDate"]/following-sibling::text()[2]之后就可以拿到标注2的值
![image]()
-
成功拿到标注2的值“58”后,如果我 们好想再拿到标注3的"45分钟"这个值, 那我们就算算要相邻几个元素, 经过不断修改following-sibling::text()[index]中index的值最后发现是相邻的第4个值。
*[@id="info"]/span[@property="v:initialReleaseDate"]/following-sibling::text()[4]
![image]()


#2. 获取a标签中onclick()内的sid值
<div class="pic">
<a class="nbg" href="https://www.douban.com/link2/?url=https%3A%2F%2Fmovie.douban.com%2Fsubject%2F26683290%2F&query=%E4%BD%A0%E7%9A%84%E5%90%8D%E5%AD%97&cat_id=1002&type=search&pos=0" target="_blank" onclick="moreurl(this,{i: '0', query: '%E4%BD%A0%E7%9A%84%E5%90%8D%E5%AD%97', from: 'dou_search_movie', sid: 26683290, qcat: ''})" title="君の名は。" ><img src="https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2395733377.webp"></a>
</div>
onclick="moreurl(this,{i: '0', query: '%E4%BD%A0%E7%9A%84%E5%90%8D%E5%AD%97', from: 'dou_search_movie', sid: 26683290, qcat: ''})"
data = xpahContext(context).xpath('//*[@id="content"]/div/div[1]/div[3]/div[1]/div[1]/div[2]/div/h3/a/@onclick')
sid = data[0][data[0].index("sid:") + 5 : data[0].index(", qcat")]
#3. xpath判断div的多个class中是否包含一个叫做paginator的class
//div[contains(@class, 'paginator')]
#4.获取 div 元素中的最后一个 a 标签
//div//a[last()]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号