
Flume基础知识
概述
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。
主要作用:实时读取服务器本地磁盘数据,将数据写入HDFS;
优点:
- 可以和任意存储进程集成。
- 输入的的数据速率大于写入目的存储的速率(读写速率不同步),flume会进行缓冲,减小hdfs的压力。
- flume中的事务基于channel,使用了两个事务模型(sender + receiver),确保消息被可靠发送。
Flume使用两个独立的事务分别负责从soucrce到channel,以及从channel到sink的事件传递。一旦事务中所有的数据全部成功提交到channel,那么source才认为该数据读取完成。同理,只有成功被sink写出去的数据,才会从channel中移除;失败后就重新提交;
组成:Agent 由 source+channel+sink构成;
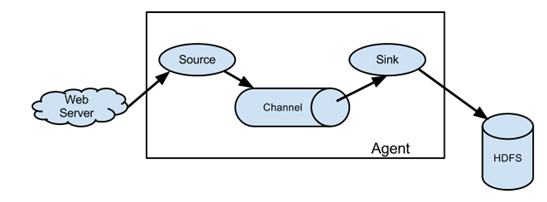
source是数据来源的抽象,sink是数据去向的抽象;
Source
Source是负责接收数据到Flume Agent的组件。Source组件可以处理各种类型、各种格式的日志数据
数据输入端输入类型:spooling directory(spooldir)文件夹里边的数据不停的滚动、exec 命令的执行结果被采集
syslog系统日志、avro上一层的flume、netcat网络端传输的数据
Channel
Channel是位于Source和Sink之间的缓冲区。因此,Channel允许Source和Sink运作在不同的速率上。Channel是线程安全的,可以同时处理几个Source的写入操作和几个Sink的读取操作。
Flume自带两种Channel:Memory Channel和File Channel。
Memory Channel是内存中的队列。Memory Channel在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么Memory Channel就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
Channel选择器是决定Source接收的一个特定事件写入哪些Channel的组件,它们告知Channel处理器,然后由其将事件写入到每个Channel。
Channel Selector有两种类型:Replicating Channel Selector(default,会把所有的数据发给所有的Channel)和Multiplexing Chanell Selector(选择把哪个数据发到哪个channel)和自定义选择器;
Source 发送的 Event 通过 Channel 选择器来选择以哪种方式写入到 Channel 中,Flume 提供三种类型 Channel 选择器,分别是复制、复用和自定义选择器。
-
复制选择器: 一个 Source 以复制的方式将一个 Event 同时写入到多个 Channel 中,不同的 Sink 可以从不同的 Channel 中获取相同的 Event,比如一份日志数据同时写 Kafka 和 HDFS,一个 Event 同时写入两个 Channel,然后不同类型的 Sink 发送到不同的外部存储。该选择器复制每个事件到通过Source的channels参数所指定的所有的Channels中。复制Channel选择器还有一个可选参数optional,该参数是空格分隔的channel名字列表。此参数指定的所有channel都认为是可选的,所以如果事件写入这些channel时,若有失败发生,会忽略。而写入其他channel失败时会抛出异常。
2.(多路)复用选择器: 需要和拦截器配合使用,根据 Event 的头信息中不同键值数据来判断 Event 应该写入哪个 Channel 中。
还有一种是kafka channel,它是没有sink;
3. 自定义选择器
Sink
数据去向常见的目的地有:HDFS、Kafka、logger(记录INFO级别的日志)、avro(下一层的Flume)、File、Hbase、solr、ipc、thrift自定义等
Sink不断地轮询Channel中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个Flume Agent。
Sink是完全事务性的。在从Channel批量删除数据之前,每个Sink用Channel启动一个事务。批量事件一旦成功写出到存储系统或下一个Flume Agent,Sink就利用Channel提交事务。事务一旦被提交,该Channel从自己的内部缓冲区删除事件。
Sink groups允许组织多个sink到一个实体上。 Sink processors(处理器)能够提供在组内所有Sink之间实现负载均衡的能力,而且在失败的情况下能够进行故障转移从一个Sink到另一个Sink。简单的说就是一个source 对应一个Sinkgroups,即多个sink,这里实际上复用/复制情况差不多,只是这里考虑的是可靠性与性能,即故障转移与负载均衡的设置。
DefaultSink Processor 接收单一的Sink,不强制用户为Sink创建Processor
FailoverSink Processor故障转移处理器会通过配置维护了一个优先级列表。保证每一个有效的事件都会被处理。
工作原理是将连续失败sink分配到一个池中,在那里被分配一个冷冻期,在这个冷冻期里,这个sink不会做任何事。一旦sink成功发送一个event,sink将被还原到live 池中。
Load balancing Processor负载均衡处理器提供在多个Sink之间负载平衡的能力。实现支持通过① round_robin(轮询)或者② random(随机)参数来实现负载分发,默认情况下使用round_robin
事务
Put事务流程:
doPut将批数据先写入临时缓冲区putList; doCommit:检查channel内存队列是否足够合并; doRollback:channel内存队列空间不足,回滚数据;
尝试put先把数据put到putList里边,然后commit提交,查看channel中事务是否提交成功,如果都提交成功了就把这个事件从putList中拿出来;如果失败就重写提交,rollTback到putList;
Take事务:
doTake先将数据取到临时缓冲区takeList; doCommit如果数据全部发送成功,则清除临时缓冲区takeList; doRollback数据发送过程中如果出现异常,rollback将临时缓存takeList中的数据归还给channel内存队列;
拉取事件到takeList中,尝试提交,如果提交成功就把takeList中数据清除掉;如果提交失败就重写提交,返回到channel后重写提交;
这种事务:flume有可能有重复的数据;
Event
传输单元,Flume数据传输的基本单元,以事件的形式将数据从源头送至目的地。 Event由可选的header和载有数据的一个byte array 构成。Header是容纳了key-value字符串对的HashMap。

拦截器(interceptor)
拦截器是简单插件式组件,设置在Source和Source写入数据的Channel之间。每个拦截器实例只处理同一个Source接收到的事件。
因为拦截器必须在事件写入channel之前完成转换操作,只有当拦截器已成功转换事件后,channel(和任何其他可能产生超时的source)才会响应发送事件的客户端或sink。
Flume官方提供了一些常用的拦截器,也可以自定义拦截器对日志进行处理。自定义拦截器只需以下几步:
- 使用的Flume版本为:apache-flume-1.6.0
实现org.apache.flume.interceptor.Interceptor接口
Flume拓扑结构
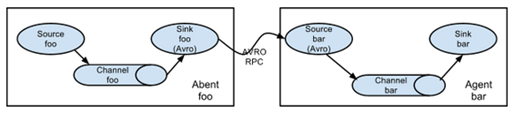
① 串联:channel多,但flume层数不宜过多;这种模式是将多个flume给顺序连接起来了,从最初的source开始到最终sink传送的目的存储系统。此模式不建议桥接过多的flume数量, flume数量过多不仅会影响传输速率,而且一旦传输过程中某个节点flume宕机,会影响整个传输系统。
② 单source,多channel、sink; 一个channel对应多个sink; 多个channel对应多个sink;
---->sink1 ---->channel1 --->sink1
单source ---> channel----->sink2 source
----->sink3 ------>channel2---->sink2
Flume支持将事件流向一个或者多个目的地。这种模式将数据源复制到多个channel中,每个channel都有相同的数据,sink可以选择传送的不同的目的地。
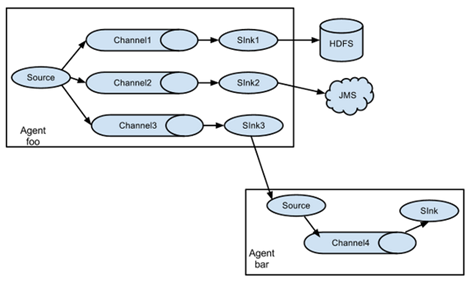
③ 负载均衡 Flume支持使用将多个sink逻辑上分到一个sink组,flume将数据发送到不同的sink,主要解决负载均衡和故障转移问题。
负载均衡 :并排的三个channel都是轮询,好处是增大流量并且保证数据的安全;(一个挂了,三个不会都挂;缓冲区比较长,如果hdfs出现问题,两层的channel,多个flune的并联可以保证数据的安全且增大缓冲区)
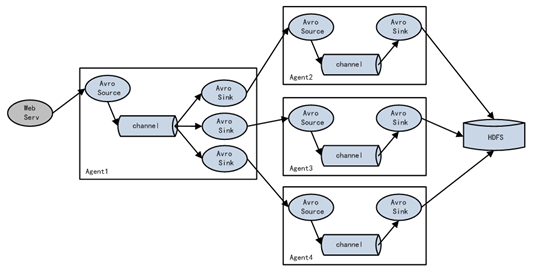
④ Flume agent聚合 日常web应用通常分布在上百个服务器,大者甚至上千个、上万个服务器。产生的日志,处理起来也非常麻烦。用flume的这种组合方式能很好的解决这一问题,每台服务器部署一个flume采集日志,传送到一个集中收集日志的flume,再由此flume上传到hdfs、hive、hbase、jms等,进行日志分析。
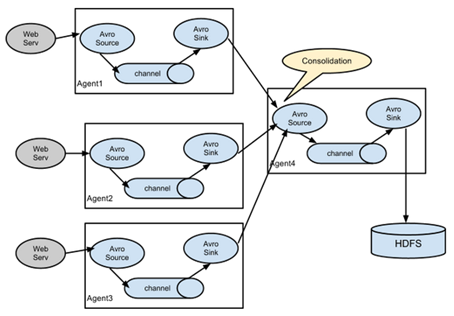
场景模拟
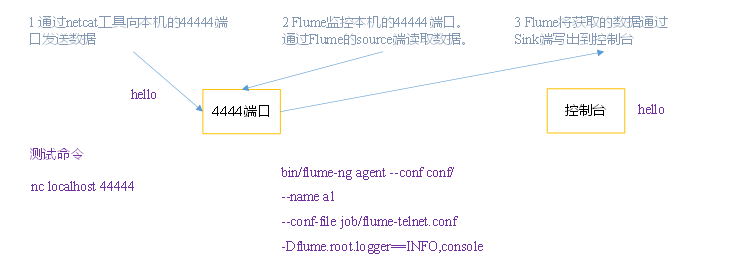
1. 监控端口数据--netcat
监控端口数据:
端口(netcat)--->flume--->Sink(logger)到控制台
2. 实时读取本地文件到HDFS

实时读取本地文件到HDFS:
hive.log(exec)--->flume--->Sink(HDFS)
取Linux系统中的文件,就得按照Linux命令的规则执行命令。由于Hive日志在Linux系统中所以读取文件的类型选择:exec即execute执行的意思。表示执行Linux命令来读取文件。
3. 实时读取目录文件到HDFS
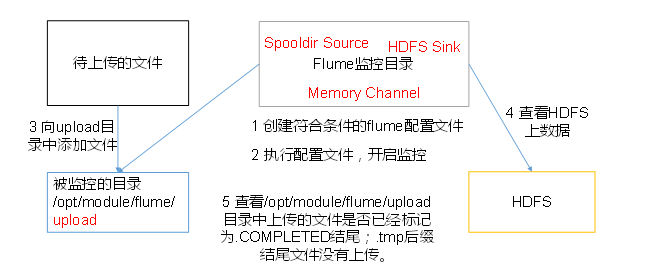
实时读取目录文件到HDFS:
目录dir(spooldir)--->flume--->Sink(HDFS)
4. 单数据源多出口(选择器)
单Source多Channel、Sink
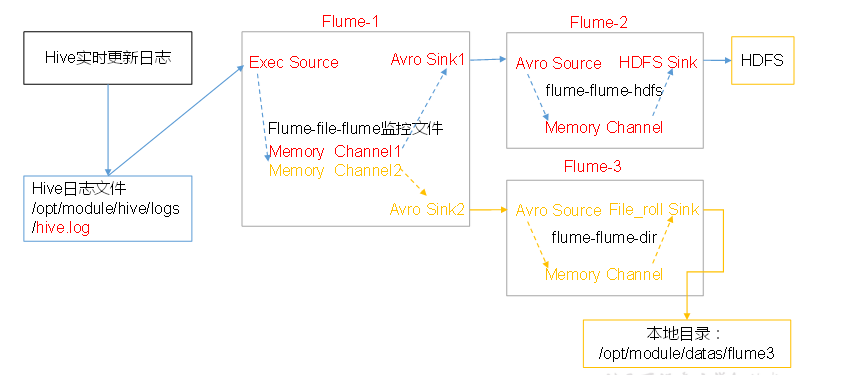
单数据源多出口(选择器):单Source多Channel、Sink
hive.log(exec)---->flume1--Sink1(avro)-->flume2--->Sink(HDFS)
---Sink2(avro)-->flume3--->Sink(file roll本地目录文件data)
5. 单数据源多出口案例(Sink组)
单Source、Channel多Sink(负载均衡)
Flume 的负载均衡和故障转移
目的是为了提高整个系统的容错能力和稳定性。简单配置就可以轻松实现,首先需要设置 Sink 组,同一个 Sink 组内有多个子 Sink,不同 Sink 之间可以配置成负载均衡或者故障转移。

单数据源多出口(Sink组): flum1-load_balance
端口(netcat)--->flume1---Sink1(avro)-->flume2---Sink(Logger控制台)
---Sink2(avro)-->flume3---Sink(Logger控制台)
6. 多数据源汇总
多Source汇总数据到单Flume


 浙公网安备 33010602011771号
浙公网安备 33010602011771号