mini-lsm通关笔记Week2Day5
Summary
在本章中,您将:
- 实现manifest文件的编解码。
- 系统重启时从manifest文件中恢复。
要将测试用例复制到启动器代码中并运行它们,
cargo x copy-test --week 2 --day 5
cargo x scheck
Task 1-Manifest Encoding
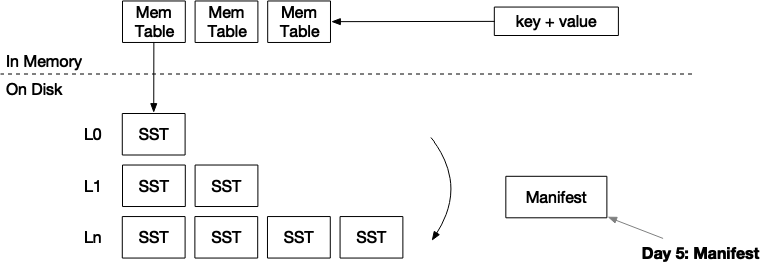
系统使用manifest文件来记录引擎中发生的所有操作。目前只有两种类型:合并和转储SST。当引擎重新启动时,它将读取manifest文件,重建状态,并将磁盘上SST文件加载到内存中。
存储LSM状态的方法有很多。最简单的方法之一是简单地将完整状态存储到JSON文件中。每当我们执行一次合并或转储SST时,我们可以将整个LSM状态序列化到一个文件中。这种方法的问题是,当数据库变得超大(即10k SST)时,将manifest写入磁盘将超级慢。因此,我们将manifest设计为一个追加写的文件。
在此任务中,您需要修改:
src/manifest.rs我们使用JSON对manifest进行编码。你可以使用
serde_json::to_vec将manifest编码为json,并将其写入manifest文件,然后执行fsync。当你从manifest文件读取时,你可以使用serde_json::Deserializer::from_slice,它将返回一个记录流。你不需要存储记录长度等,因为serde_json可以自动找到记录的拆分。manifest文件格式如下:
| JSON record | JSON record | JSON record | JSON record |再次注意,我们并没有记录每条记录有多少字节的信息。
在引擎运行几个小时后,manifest文件可能会变得非常大。此时,您可以定期压缩manifest文件以存储当前快照并截断日志。这是您可以作为奖励任务的一部分实现的优化。
serde_json该库可以实现JSON的自动拆分,就是说serde_json::Deserializer::from_slice可以解析如下格式的json文件:
{
...
}
{
...
}
{
...
}
与标准的json数组相比前后不需要[]包裹,中间不需要,分隔。
所有我们实现add_record_when_init函数只需要序列化对象,然后对文件进行追加写操作:
pub fn add_record_when_init(&self, record: ManifestRecord) -> Result<()> {
// 获取锁,避免两个线程竞争写入
let mut file = self.file.lock();
// 将对象序列化成二进制数据
let buf = serde_json::to_vec(&record)?;
// 写入文件
file.write_all(&buf)?;
// 避免操作系统缓存,强制写入磁盘
file.sync_all()?;
Ok(())
}
Task 2-Write Manifests
现在,您可以继续并修改您的LSM引擎以在必要时写入manifest文件。在此任务中,您需要修改:
src/lsm_storage.rs src/compact.rs目前,我们只使用两种类型的manifest记录:转储SST和合并。转储SST操作的manifest记录中存储转储到磁盘的SST id。合并操作的manifest记录中存储了合并任务和生成的SST id。每次向磁盘写入一些新文件时,首先同步文件和存储目录,然后写入manifest并同步manifest。manifest文件应写入
<path>/MANIFEST。要同步目录,可以实现sync_dir函数,其中可以使用
File::open(dir).sync_all()?来同步它。在Linux上,目录是一个文件,包含目录中的文件列表。通过在目录上执行fsync,您将确保在断电时,新写入的(或删除的)文件可以对用户可见。记住为后台合并触发器(leveled/simple/universal)和用户请求执行强制合并时写一个合并manifest记录。
- 创建
Manifests文件,先不考虑恢复场景,修改LsmStorageInner::open函数
let mut manifest = None;
if !manifest_path.exists() {
manifest = Some(Manifest::create(manifest_path)?);
}
...
let storage = Self {
...
manifest,
...
};
Ok(storage)
- 转储SST时写入
Manifests文件,修改force_flush_next_imm_memtable,在转储后记录一条记录,ManifestRecord::Flush的变体中只需要记录sst_id:
pub fn force_flush_next_imm_memtable(&self) -> Result<()> {
...
self.manifest
.as_ref()
.unwrap()
.add_record(&_state_lock, ManifestRecord::Flush(sst_id))?;
self.sync_dir()?;
}
- 合并sst写入
Manifests文件,修改trigger_compaction,在合并任务后记录一条记录,ManifestRecord::Compaction的变体中只需要记录合并的task任务和合并结果产生的新的sst:
self.manifest
.as_ref()
.unwrap()
.add_record(&_state_lock, ManifestRecord::Compaction(task, output))?;
self.sync_dir()?;
Task 3-Flush on Close
在此任务中,您需要修改:
src/lsm_storage.rs您需要实现close函数。如果
self.options.enable_wal = false(我们将在下一章介绍WAL),那么在停止存储引擎之前,应该将所有的memtable转储到磁盘,这样所有的用户更改都会被持久化。
此前的任务中修改过close函数,就是在close前关闭合并、转储线程。新增逻辑:
-
开启
enable_wal开关,待合并、转储线程线程停止后直接返回 -
未开启
enable_wal开关,应该将所有的memtable转储到磁盘
pub fn close(&self) -> Result<()> {
// 向合并线程发送停止信号
self.compaction_notifier.send(()).ok();
// 向转储线程发送停止信号
self.flush_notifier.send(()).ok();
let mut compaction_thread = self.compaction_thread.lock();
if let Some(compaction_thread) = compaction_thread.take() {
compaction_thread
.join()
.map_err(|e| anyhow::anyhow!("{:?}", e))?;
}
let mut flush_thread = self.flush_thread.lock();
if let Some(flush_thread) = flush_thread.take() {
flush_thread
.join()
.map_err(|e| anyhow::anyhow!("{:?}", e))?;
}
// 开启enable_wal开关直接返回
if self.inner.options.enable_wal {
return Ok(());
}
// 未enable_wal开关,转储所有`memtable`
if !self.inner.state.read().memtable.is_empty() {
self.inner
.force_freeze_memtable(&self.inner.state_lock.lock())?;
}
while {
let snapshot = self.inner.state.read();
!snapshot.imm_memtables.is_empty()
} {
self.inner.force_flush_next_imm_memtable()?;
}
self.inner.sync_dir()?;
Ok(())
}
Task 4-Recover from the State
在此任务中,您需要修改:
src/lsm_storage.rs现在,您可以修改
open函数以从manifest文件中恢复引擎状态。要恢复它,您需要首先生成需要加载的SST列表。您可以通过调用apply_compaction_result并恢复LSM状态下的SST id来完成此操作。之后,您可以迭代状态并加载所有SST(更新sstables哈希映射)。在此过程中,您需要计算最大SST id并更新next_sst_id字段。之后,您可以使用该id创建一个新的memtable,并将id递增1。如果您实施了分级合并,则可能在每次应用合并结果时对SST进行排序。但是,使用manifest recover,你的排序逻辑将被破坏,因为在恢复过程中,你无法知道每个SST的开始键和结束键。要解决这个问题,您需要读取
apply_compaction_result函数的in_recovery标志。在恢复过程中,不应尝试检索SST的第一个密钥。在LSM状态恢复并打开所有SST之后,您可以在恢复过程结束时进行排序。或者,您可以在manifest中包含每个SST的开始密钥和结束密钥。在RocksDB/BadgerDB中使用了这种策略,在
apply_compaction_result过程中不需要区分恢复模式和正常模式。您可以使用mini-lsm-cli来测试您的实现。
cargo run --bin mini-lsm-cli fill 1000 2000 close cargo run --bin mini-lsm-cli get 1500
要运行起mini-lsm-cli还需要执行path参数:cargo run --bin mini-lsm-cli -- --path /tmp/lsm。会将生成的sst保存在该目录下。
从Manifests文件读取记录
使用以下代码可以从文件中反序列化出记录:
pub fn recover(path: impl AsRef<Path>) -> Result<(Self, Vec<ManifestRecord>)> {
let mut file = OpenOptions::new()
.read(true)
.append(true)
.open(path)
.context("failed to recover manifest")?;
let mut buf = Vec::new();
file.read_to_end(&mut buf)?;
let mut stream = Deserializer::from_slice(&buf).into_iter::<ManifestRecord>();
let mut records = Vec::new();
while let Some(x) = stream.next() {
records.push(x?);
}
Ok((
Self {
file: Arc::new(Mutex::new(file)),
},
records,
))
}
修改LsmStorageInner::open函数,当Manifests文件文件存在时,走恢复流程
if !manifest_path.exists() {
manifest = Some(Manifest::create(manifest_path)?);
} else {
// 读取持久化的记录
let (m, records) = Manifest::recover(&manifest_path)?;
manifest = Some(m);
// 遍历记录,回放流程
for record in records {
match record {
ManifestRecord::Flush(sst_id) => {
if compaction_controller.flush_to_l0() {
state.l0_sstables.insert(0, sst_id);
} else {
state.levels.insert(0, (sst_id, vec![sst_id]));
}
next_sst_id = next_sst_id.max(sst_id);
}
ManifestRecord::NewMemtable(_) => {}
ManifestRecord::Compaction(task, output) => {
let (new_state, _) =
compaction_controller.apply_compaction_result(&state, &task, &output);
state = new_state;
next_sst_id =
next_sst_id.max(output.iter().max().copied().unwrap_or_default());
}
}
}
// 读取state中需要读取的SST
for table_id in state
.l0_sstables
.iter()
.chain(state.levels.iter().map(|(_, files)| files).flatten())
{
let table_id = *table_id;
let sst = SsTable::open(
table_id,
Some(block_cache.clone()),
FileObject::open(&Self::path_of_sst_static(path, table_id))
.context("failed to open SST")?,
)?;
state.sstables.insert(table_id, Arc::new(sst));
}
next_sst_id += 1;
state.memtable = Arc::new(MemTable::create(next_sst_id));
next_sst_id += 1;
}
可以在指导运行的目录,直接使用
cat命令查看Manifests文件,查看写入的内容

