mini-lsm通关笔记Week2Overview
Week 2 Overview: Compaction and Persistence
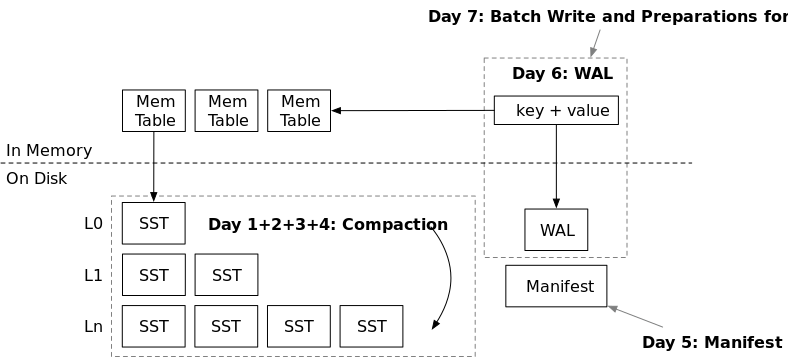
在上周,您已经实现了LSM存储引擎的所有必要结构,并且您的存储引擎已经支持读写接口。在本周中,我们将深入探讨SST文件的磁盘组织,并研究在系统中实现性能和成本效益的最佳方法。我们将花4天时间学习不同的compaction策略,从最简单的到最复杂的,然后为存储引擎持久化实现剩下的部分。在本周结束时,您将拥有一个功能齐全且高效的LSM存储引擎。
合并和读放大
我们先来说说合并。在前面的部分中,我们简单地将memtable转储到一个L0 SST中。想象一下,你已经写入了千兆字节的数据,现在你有100个SST。每个读请求(不过滤)需要从这些SST读取100个块。这个放大就是读放大——一个get操作需要发送到磁盘的I/O请求数。
为了减少读取放大,我们可以将所有L0 SST合并到一个更大的结构中,这样就可以只读取一个SST和一个块来检索请求的数据。假设我们还有这100个SST,现在,我们对这100个SST进行合并排序,以生成另外100个SST,每个SST都包含不重叠的键值范围。这个过程就是合并,这100个不重叠的SST就是一个排序的run。
为了使这一过程更加清晰,让我们来看一个具体的示例:
SST 1: key range 00000 - key 10000, 1000 keys
SST 2: key range 00005 - key 10005, 1000 keys
SST 3: key range 00010 - key 10010, 1000 keys
在LSM结构中,我们有3个SST。如果我们需要访问键02333,我们需要探测这3个SST。如果我们可以进行合并,我们可能会得到以下3个新的SST:
SST 4: key range 00000 - key 03000, 1000 keys
SST 5: key range 03001 - key 06000, 1000 keys
SST 6: key range 06000 - key 10010, 1000 keys
通过合并SST 1、2和3创建3个新SST。我们可以得到一个排序后的3000个key,然后将它们拆分成3个文件,这样就可以避免一个超大的SST文件。现在我们的LSM状态有3个不重叠的SST,我们只需要访问SST 4,找到键02333。
合并和写放大的两个极端
因此,从上面的例子中,我们有2种幼稚的方法来处理LSM结构—根本不进行合并,和总是在转储新的SST时进行完全合并。
合并是一个耗时的操作。它需要从某些文件中读取所有数据,并将相同数量的文件写入磁盘。这个操作会占用大量的CPU资源和I/O资源。完全不做合并会导致高读放大,但它不需要写入新文件。总是执行完全合并可以减少读取放大,但它需要不断地重写磁盘上的文件。
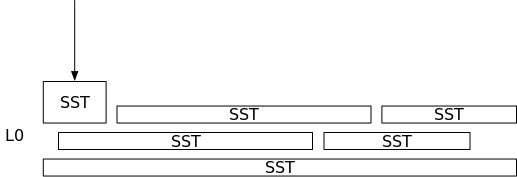
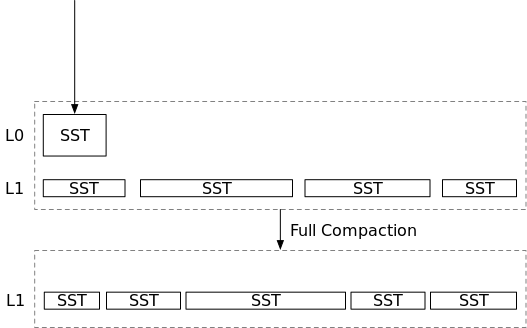
转储到磁盘的memtables与写入磁盘的总数据的比值就是写放大。也就是说,没有合并的写放大率是1倍,因为一旦SST被转储到磁盘,它们就会一直停留在那里。总是做合并有非常高的写放大。如果我们在每次获取SST时都执行一次完全合并,那么写入磁盘的数据将是转储SST数量的二次方。例如,如果我们将100个SST转储到磁盘,我们将执行2个文件、3个文件、...100个文件的合并,其中我们实际写入磁盘的数据总量约为5000个SST。在这种情况下,写入100个SST后的写放大将是50倍。
一个好的合并策略可以在读放大、写放大和空间放大(我们后面会讲到)之间取得平衡。在通用的LSM存储引擎中,通常不可能找到一种策略,可以在所有这3个因素中实现最低的放大,除非引擎可以使用某些特定的数据模式。LSM的好处是,我们可以从理论上分析合并策略的放大,所有这些事情都发生在后台。我们可以选择合并策略,并动态地改变其中的一些参数,从而将我们的存储引擎调整到最佳状态。合并策略都是关于权衡的,基于LSM的存储引擎让我们可以在运行时选择要交换的内容。
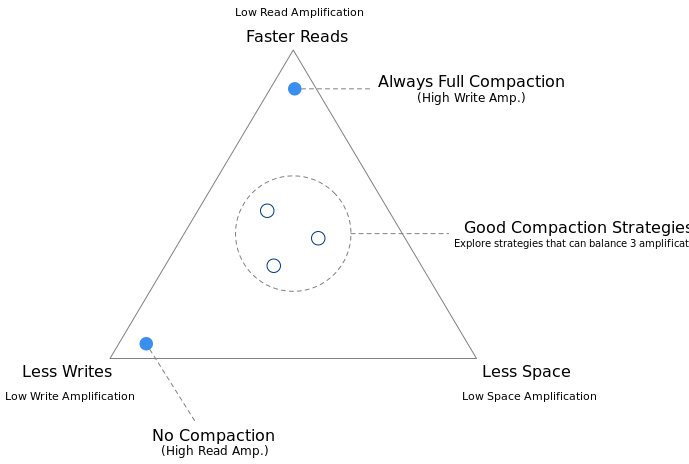
业内一个典型的业务场景是这样的:用户在启动一个产品时,首先将数据批量注入到存储引擎中,通常是每秒千兆字节。然后,系统上线,用户开始在系统上做小交易。在第一阶段,引擎应该能够快速存储数据,因此我们可以使用最小化写入放大的合并策略来加速这一过程。然后,我们调整合并算法的参数,使其针对读放大进行优化,并做一次完全的合并,对已有的数据进行重新排序,这样系统上线后就可以稳定运行了。
如果业务场景类似于时间序列数据库,则用户可能总是按时间填充和截断数据。因此,即使没有合并,这些append-only的数据仍然可以在磁盘上具有低放大。因此,在现实生活中,你应该注意用户的模式或特定需求,并利用这些信息来优化你的系统。
合并策略概述
合并策略通常的目的是控制排序的run层数,从而使读放大保持在一个合理的数量。通常有两类合并策略:分级(leveled)和分层(tiered)。
在分级合并中,用户可以指定最大级别数,即系统中排序的run的层数(L0除外)。例如,RocksDB通常在分级合并模式下保持6级(排序的run)。在合并过程中,来自两个相邻层的SST将被合并,然后产生的SST将被放到两个层的较低层。因此,在分级合并中,您通常会看到一个小的排序的run与一个大的排序的run合并。排序的run(级别)在大小上呈指数增长-较低的级别在大小上将是较高的级别的<some number>倍。
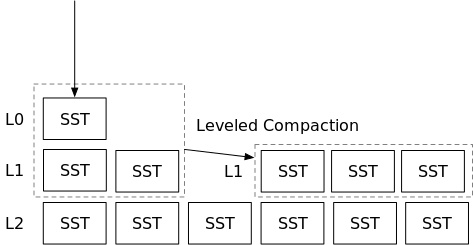
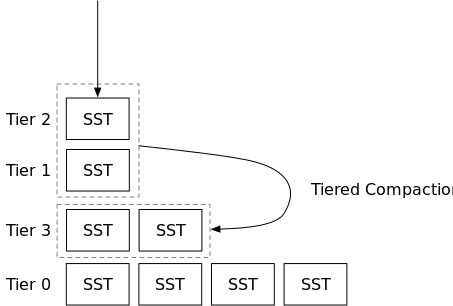
在分层合并中,引擎将通过合并它们或让转储新的SST作为新的排序的run(层)来动态调整排序的run的数量,以最小化写入放大。在此策略中,您通常会看到引擎合并两个大小相等的排序的run。如果合并策略不选择合并层,则层数可能会很高,因此读取放大率会很高。在本教程中,我们将实现RocksDB的通用合并,这是一种分层合并策略。
空间放大
计算空间放大的最直观方法是将LSM引擎使用的实际空间除以用户空间使用量(即数据库大小或数据库中的行数等)。引擎将需要存储删除的墓碑,有时,如果合并发生得不够频繁,则会有同一个键的多个版本,因此会导致空间放大。
在引擎端,通常很难知道用户存储的确切数据量,除非我们扫描整个数据库,看看引擎中到底有多少个不再使用的版本。因此,估计空间放大的一种方法是将完整存储文件大小除以最后一级大小。这种估算方法背后的假设是,用户填充初始数据后,工作负载的插入率和删除率应该是相同的。我们假设用户端的数据大小不会改变,因此最后一层包含用户数据在某个时刻的快照,而上层包含新的更改。当合并将所有内容合并到最后一层时,使用这种估计方法,我们可以得到1x的空间放大系数。
请注意,合并也会占用空间——在合并完成之前,您不能删除正在合并的文件。如果您对数据库执行完全合并,您将需要与当前引擎文件大小相同的可用存储空间。
在这一部分中,我们将有一个合并模拟器来帮助你可视化合并过程和你的合并算法的决策。我们提供了最小的测试用例来检查您的合并算法的属性,您应该密切关注统计信息和合并模拟器的输出,以了解您的合并算法的工作情况。
持久化
在实现了合并算法之后,我们将在系统中实现两个关键组件:manifest,这是一个存储LSM状态的文件,WAL,它将memtable数据持久化到磁盘,然后作为SST刷新。完成这两个组件后,存储引擎将拥有完整的持久化支持,可以在您的产品中使用。
如果不想太深入探讨合并,也可以先看完2.1和2.2章,实现一个非常简单的Leveled合并算法,直接进入持久化部分。在第2周构建一个可工作的存储引擎时,不需要实现完全的leveled合并和universal合并。
零食时间
在实现了合并和持久化之后,我们将有一个关于实现批量写入接口和校验和的简短章节。

