
SQL Server 内存数据库解析整合
SQL Server 2016:内存列存储索引
SQL Server 2016的一项新特性是可以在“内存优化表(Memory Optimized Table)”上添加“列存储索引(Columnstore Index)”。要理解这是什么意思,我们应该首先解释术语列存储索引和内存优化表。
列存储索引是一种按照列而不是行组织数据的索引。每个数据块只存储一个列的数据,最多包含100万行。因此,如果数据为5列1000万行,那么就需要存储在50个数据块中。当只查询部分列时,这种数据组织策略特别有效,因为数据库不会从磁盘读取用户不关心的列。
列存储索引比表扫描要快得多,但没有传统的B树索引那么快。这特别适合于那种无法预测需要什么索引的即时报表。
内存优化表正如它的名字, 它是一个经过优化并一直驻留在内存中的表。这有许多好处,比如锁无关写,但它也有很大的局限性。比如,只允许有8个索引,这对于用于即时查询的表而言限制太大。
SQL Server 2016部分地弥补了这种限制,它允许那8个索引中的其中一个为列存储索引。但要遵循如下规则:
•像内存优化表上的其它索引一样,列存储索引必须在表创建时定义。
•列存储索引必须包含基表中的所有列。(在普通表上的列存储索引不存在这种限制。)
•列存储索引必须包含基表中的所有行。换言之,它不能是“筛选索引(filtered index)”。
一个与内存优化表相关的特性是创建本地编译查询。数据库使用C编译器将这些查询编译成了机器码,而不使用SQL Server解释器。使用列存储索引的查询可以使用这个选项,而不用总是通过解释器运行。
--------------------------------------------------
SQL Server 2016 列存储索引功能增强
列存储索引(columnstore index)在SQL Server 2012中已经引入,其带来性能提升的同时也有很多限制,比如对带有列存储索引的表进行INSERT, UPDATE和DELETE时,会遇到如下错误提示:
由于这种限制,索引列存储索引并不太适合在SQL Server 2012 OLTP DB中应用。不过,SQL Server 2016对列存储索引做了很多改进,其中我觉得最大的变化是可更新的列存储索引,即可以直接对带有列存储索引的表进行INSERT, UPDATE和DELETE,因此,我们可以在SQL Server 2016环境中尝试应用这以功能,已提升查询性能。若想具体了解列存储索引的概念、特征、创建及使用,可参考我之前整理的Blog。
在SQL 2016环境测试的过程中,我发现列存储索引对于有聚集函数的T-SQL,有很好的性能提升,比如下面这个示例,性能提升约15倍:
JOIT表有1500833笔记录,复制一份到JOIT_CSI表,2张表的唯一区别是JOIT_CSI有非聚集列存储索引, 在统计列SERNUM个数的查询中,可以发现JOIT需要7210ms,而JOIT_CSI只有463ms,性能提升约15倍。感兴趣的,可以去发掘其他性能提升的最佳实践。
--------------------------------------------------
SQL Server 2016新特性: In-Memory OLTP
下面的示例(取自MSDN),展示了如何通过T-SQL创建memory-optimized filegroup、Memory-Optimized Tables,最终可以看到基于磁盘表和内存优化表之间的性能差异,及Native SP带来的进一步性能提升。
-
创建数据库,及其内存优化文件组(memory-optimized filegroup)
CREATE DATABASE imoltp;
go
ALTER DATABASE imoltp ADD FILEGROUP [imoltp_mod]
CONTAINS MEMORY_OPTIMIZED_DATA;
ALTER DATABASE imoltp ADD FILE
(name = [imoltp_dir], filename= 'c:\data\imoltp_dir')
TO FILEGROUP imoltp_mod;
go
USE imoltp;
go
2、创建Memory-OptimizedTables, and NCSProc
go
DROP PROCEDURE IF EXISTS ncsp;
DROP TABLE IF EXISTS sql;
DROP TABLE IF EXISTS hash_i;
DROP TABLE IF EXISTS hash_c;
go
CREATE TABLE [dbo].[sql] (
c1 INT NOT NULL PRIMARY KEY,
c2 NCHAR(48) NOT NULL
);
go
CREATE TABLE [dbo].[hash_i] (
c1 INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000),
c2 NCHAR(48) NOT NULL
) WITH (MEMORY_OPTIMIZED=ON, DURABILITY = SCHEMA_AND_DATA);
go
CREATE TABLE [dbo].[hash_c] (
c1 INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000),
c2 NCHAR(48) NOT NULL
) WITH (MEMORY_OPTIMIZED=ON, DURABILITY = SCHEMA_AND_DATA);
go
CREATE PROCEDURE ncsp
@rowcount INT,
@c NCHAR(48)
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC
WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
DECLARE @i INT = 1;
WHILE @i <= @rowcount
BEGIN;
INSERT INTO [dbo].[hash_c] VALUES (@i, @c);
SET @i += 1;
END;
END;
Go
3、执行下面的T-SQL,可看到内存优化表的性能状况
go
SET STATISTICS TIME OFF;
SET NOCOUNT ON;
-- Inserts, one at a time.
DECLARE @starttime DATETIME2 = sysdatetime();
DECLARE @timems INT;
DECLARE @i INT = 1;
DECLARE @rowcount INT = 1000000;
DECLARE @c NCHAR(48) = N'12345678901234567890123456789012345678';
-- Harddrive-based table and interpreted Transact-SQL.
BEGIN TRAN;
WHILE @i <= @rowcount
BEGIN;
INSERT INTO [dbo].[sql] VALUES (@i, @c);
SET @i += 1;
END;
COMMIT;
SET @timems = datediff(ms, @starttime, sysdatetime());
SELECT 'A: Disk-based table and interpreted Transact-SQL: '
+ cast(@timems AS VARCHAR(10)) + ' ms';
-- Interop Hash.
SET @i = 1;
SET @starttime = sysdatetime();
BEGIN TRAN;
WHILE @i <= @rowcount
BEGIN;
INSERT INTO [dbo].[hash_i] VALUES (@i, @c);
SET @i += 1;
END;
COMMIT;
SET @timems = datediff(ms, @starttime, sysdatetime());
SELECT 'B: memory-optimized table with hash index and interpreted Transact-SQL: '
+ cast(@timems as VARCHAR(10)) + ' ms';
-- Compiled Hash.
SET @starttime = sysdatetime();
EXECUTE ncsp @rowcount, @c;
SET @timems = datediff(ms, @starttime, sysdatetime());
SELECT 'C: memory-optimized table with hash index and native SP:'
+ cast(@timems as varchar(10)) + ' ms';
go
DELETE sql;
DELETE hash_i;
DELETE hash_c;
go
执行结果:
--------------------------------------------------
SQL server 2014 内存表特性概述
内存优化表是SQL server2014版本中推出的新特性之一。也是基于create table创建的,只不过是驻留在内存中表。从内存读取表中的行和将这些行写入内存。 整个表都驻留在内存中。表数据的另一个副本维护在磁盘上,但仅用于持续性目的。内存中 OLTP 与 SQL Server 集成,以便在所有方面(如开发、部署、可管理性和可支持性)提供无缝体验。 内存优化表中的行是版本化的。 这意味着表中的每行都可能有多个版本。 所有行版本均维护在同一个表数据结构中。 本文主要描述SQL server 2014内存表的相关特性。
一、基本特性
是一张持续驻留在内存中的表。
使用基于行版本化特性(等同于Oracle MVCC),需要维护每一个行的多个不同版本。
行版本控制用于实现对同一行的并发读取和写入,注意此处是并发。
如表tb1有三行:r1、r2 和 r3。 r1 有三个版本,r2 有两个版本,r3 有四个版本。
同一行的不同版本不必占用连续的内存位置。 不同的行版本可分散到整个表数据结构中。二、持久化特性
支持事务(ACID)原则的完全持久化表,因为磁盘上会有相应的副本。
使用延迟事务提交写入磁盘。缺点是丢失已提交但未保存到磁盘的事务。
非持久的内存优化表,不记录这些表的日志且不在磁盘上保存它们的数据。掉电丢失,等同mysql memory引擎。 三、性能与可伸缩
使用本机编译的存储过程获得最佳性能,解释性TSQL一般。
对于基于复杂存储过程实现逻辑,且应用较少调用的的场景,表现优异。
内存表哈希索引高于非聚集索引,内存表非聚集索引性能高于磁盘表非聚集索引。
解决了IO瓶颈,缺点是需要增大内存开销。
避免了闩锁与旋转锁争用。
基于乐观并发控制形式来实现所有事务隔离级别,解决了读阻塞写的问题。Oracle是用MVCC及undo来搞定。四、内存表图示描述
下图为内存表调用方式描述图
下图为本文草画的流程图
--------------------------------------------------
今天的世界已经是一个大数据的世界,伴随数据量爆发式增长的还有硬件的计算能力、不断增强的CPU计算能力和单位GB内存价格的不断下降,更好地利用这些强大的资源是大势所趋。微软SQL Server 2014提供了众多激动人心的新功能,但其中最让人期待的特性之一就是代号为” Hekaton”的内存数据库了,内存数据库特性并不是SQL Server的替代,而是适应时代的补充,现在SQL Server具备了将数据表完整存入内存的功能。相比较于Oracle的TimesTen和IBM的SolidDB,Hekaton是完全集成于数据库引擎并且不需要额外付费的功能。
一、内存数据库出现的背景
在传统的数据库表中,由于磁盘的物理结构限制,OLTP类操作引起的随机查找会给IO系统带来高昂的开销,因此传统的表和索引的结构设计为使用B-Tree而尽量减少随机查找,但由于机械磁盘和数据库锁的存在,B-Tree结构在处理大并发的OLTP环境时就显得非常乏力,虽然有很多办法来解决这类问题,比如说乐观并发控制、应用程序缓存、分布式架构等,但采用上述方案会导致修改引用程序,这不仅成本高且风险极大。而随着这些年硬件的发展,现在服务器拥有几百G内存并不罕见,此外由于硬件NUMA架构的成熟,也消除了多CPU访问内存的瓶颈问题,因此具备了使用新方式来处理更大并发和数据量的条件,这种新的方式就是使用内存计算技术。
内存的学名叫做Random Access Memory(RAM),因此如其特性一样,是随机访问的,因此对于内存,随机查找不会引入额外开销,使用Hash-Index这样的数据结构更符合内存的特性,而对应并发的隔离方式也对应的变成了MVCC(多版本并发控制),从而消除了锁引入的性能瓶颈。因此内存数据库可以在同样的硬件资源下,处理更多的并发和请求,并且不会被锁阻塞,在SQL Server 2014中,集成了这个强大的内存数据引擎,如果结合SSD AS Buffer Pool特性,所产生的效果将会非常值得期待。
二、SQL Server内存数据库的组成和表现形式
在SQL Server 2014的内存数据库引擎由两部分组成:内存优化表和本地编译存储过程。虽然内存数据库集成进入关系数据库引擎,但访问内存数据库的方法对于客户端来说是透明的,这也意味着从客户端应用程序的角度来看,并不会知道内存数据库引擎的存在。如图1所示。
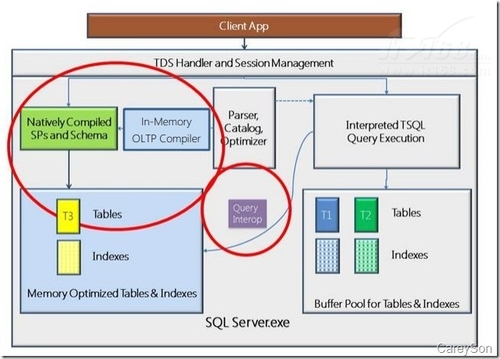
▲图1.客户端APP不会感知Hekaton引擎的存在
首先内存优化表完全不会再存在锁的概念(虽然之前的版本有快照隔离这个乐观并发控制的概念,但快照隔离仍然需要在修改数据的时候加锁),此外内存优化表Hash-Index结构使得随机读写的速度极大提高,内存优化表还可以设置为使用非持久化日志,既数据既不写日志,也不会CheckPoint到磁盘,从而极大的降低了IO压力(适合于ETL中间结果操作,或者其他允许丢失数据的场景),这样一来也可以消除写日志引入的性能瓶颈。
下面来创建一个内存优化表:
首先,内存优化表需要数据库中存在一个特殊的文件组,以供存储内存优化表的CheckPoint文件,与传统的mdf或ldf文件不同的是,该文件组是一个目录而不是一个文件,因为CheckPoint文件只会将新增的数据附加在到新的CheckPoint文件,而不会修改现有的CheckPoint文件,如图2所示。
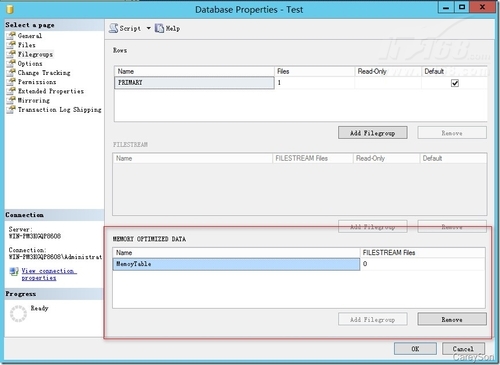
▲图2.内存优化表所需的特殊文件组
下面再来看一下内存优化文件组在磁盘系统的存储形式,如图3所示。

▲图3.内存优化文件组
创建完内存优化文件组之后,接下来再创建一个内存优化表,如图4所示。
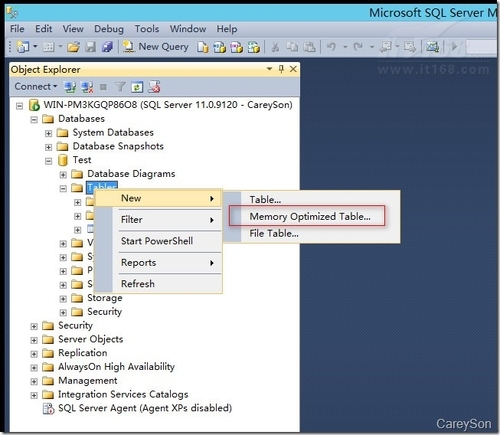
▲图4.创建内存优化表
目前SSMS还不支持UI界面创建内存优化表,因此只能通过T-SQL来创建内存优化表,如图5所示。

▲图5.使用代码创建内存优化表
这里创建一个简单的内存优化表,这里上述设置Hash Bucket为1024,目前SQL Server 2014还不支持动态的Hash Bucket,因此必须手动设置该值。表中设置了Memory_Optimized为ON意味着表是内存优化表,而Durability设置为Schema_And_Data则意味着内存优化表中数据也是持久化,这意味着除非启用了SQL Server 2014的延迟写特性,数据不会由于异常情况导致丢失。
当表创建好之后,就可以查询数据了,值得注意的是,查询内存优化表需要snapshot隔离等级或者hint,这个隔离等级与快照隔离是不同的,如图6所示。
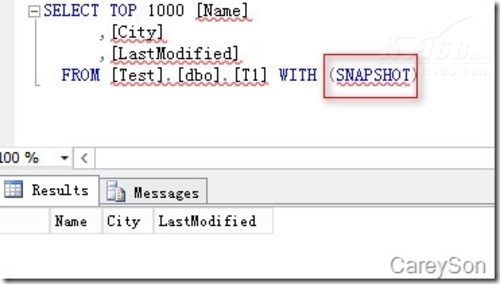
▲图6.查询内存优化表需要加提示
三、迁移现有环境到内存优化表
1.内存引擎与高可用特性兼容性
将现有数据库迁移到内存优化表需要充分考虑现有数据库系统的环境,从大的方向来说,内存优化表与一部分SQL Server高可用特性不兼容,比如说,数据库镜像和复制,但其他诸如AlwaysOn可用性组、日志传送、备份还原等高可用特性与内存优化表完全兼容。
2.内存引擎与传统引擎的无缝集成
内存引擎的最小粒度是表,所以仅可以将数据库中的部分表转为内存优化表。内存优化表与磁盘表可以无缝的进行交互,从而可以充分利用这两个引擎的优点。在图7中将内存优化表和磁盘表进行连接操作。
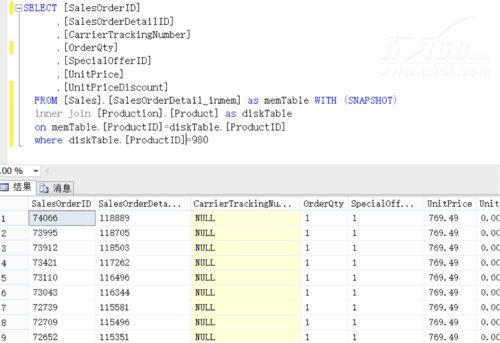
▲图7.内存优化表与磁盘表的连接
3.内存引擎与表级别特性的兼容性
内存优化表还与其他一些表级别特性不兼容,比如说迁移到内存优化表的表中不能存在计算列、触发器等。微软在SQL Server 2014中提供了一个叫做”内存优化顾问”的工具,该工具可以帮助数据库人员快速找出不兼容内存优化表的部分并帮助完成迁移。下面来看内存优化顾问。
4.内存优化顾问
不是所有的数据都可以无缝迁移到内存优化表中,如果表上存在一些诸如计算列、外键、Default或Check约束的对象时,则无法将现有表迁移到内存优化表中。因此使用微软提供的内存优化顾问可以使得迁移过程更加平滑。
通过SQL Server 2014的SSMS,在需要验证的表上右击,在弹出菜单中选择“内存优化顾问”来打开内存优化顾问,如图8所示。

▲图8.内存优化顾问
打开内存优化顾问后,可以利用内存优化顾问找到阻止迁移到内存优化表的问题,如图9所示。
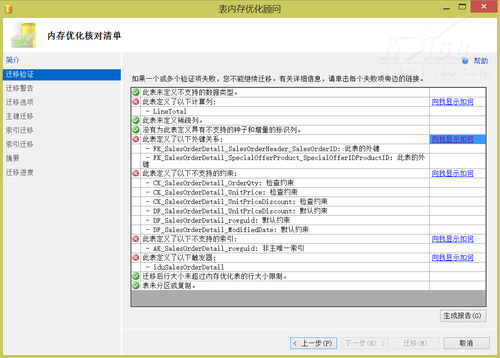
▲图9.查看影响迁移到内存优化表的问题
而如果不存在阻止迁移到内存优化表的问题,则可以利用内存优化顾问直接将表和表中的数据迁移到内存优化表中。如图10和图11所示。

▲图10.将数据也迁移到内存优化表
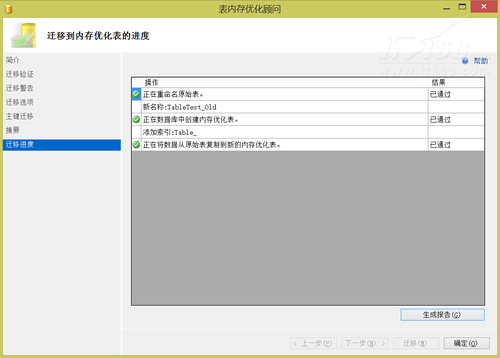
▲图11.将数据从磁盘表迁移到内存优化表完成
四、内存数据库性能测试
有了前文的理论铺垫后,下面来做一个简单的性能测试,来比对使用内存优化表结合本地编译存储过程与传统的B-Tree表,在B-Tree表上进行性能测试的结果如图12所示,在内存优化表加本地编译存储过程上进行性能测试的结果如图13所示。
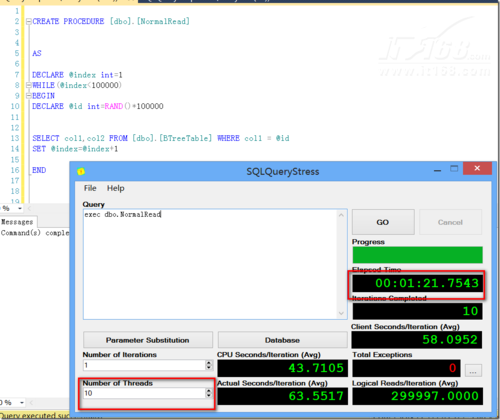
▲图12.传统的B-Tree表
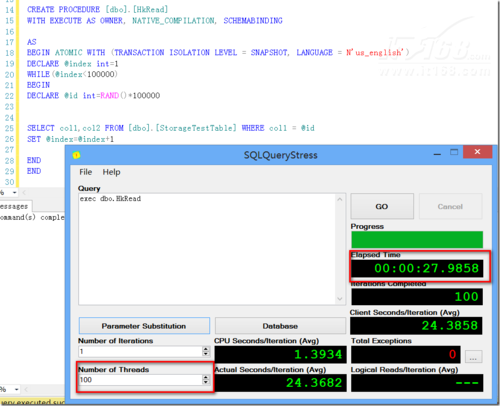
▲图13.内存优化表+本地编译存储过程
内存优化表在10倍于传统表并发的情况下,执行时间却只有传统表上执行时间的三分之一,因此不难看出,内存优化表+本地编译存储过程有接近几十倍的性能提升。
五、小结
SQL Server 2014中的内存数据库是一项可以极大的提升OLTP性能的功能,通过测试可以看出OLTP环境下使用内存数据引擎来说有几十倍的性能提升,微软同时还提供了内存优化顾问工具来使得迁移更加平滑。但是内存数据库的要求也比较严格,现有数据库如果希望能够享受内存优化表带来的性能提升,则需要做一些前期铺垫工作。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号