
caffe不同lr_policy参数设置方法
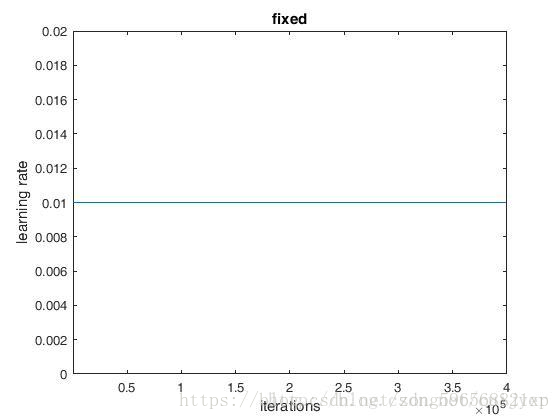
fixed
参数:
-
base_lr: 0.01
-
lr_policy: "fixed"
-
max_iter: 400000
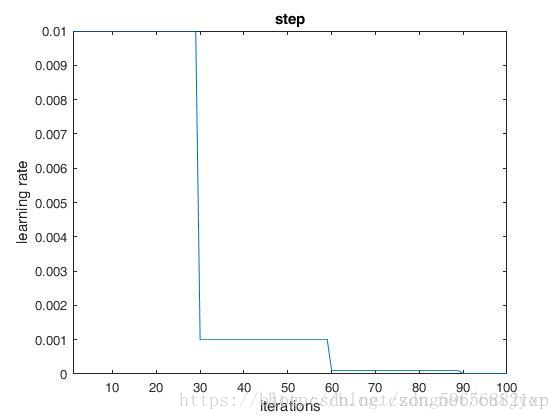
step
参数:
-
base_lr: 0.01
-
lr_policy: "step"
-
gamma: 0.1
-
stepsize: 30
-
max_iter: 100
exp
参数:
-
base_lr: 0.01
-
lr_policy: "exp"
-
gamma: 0.1
-
max_iter: 100
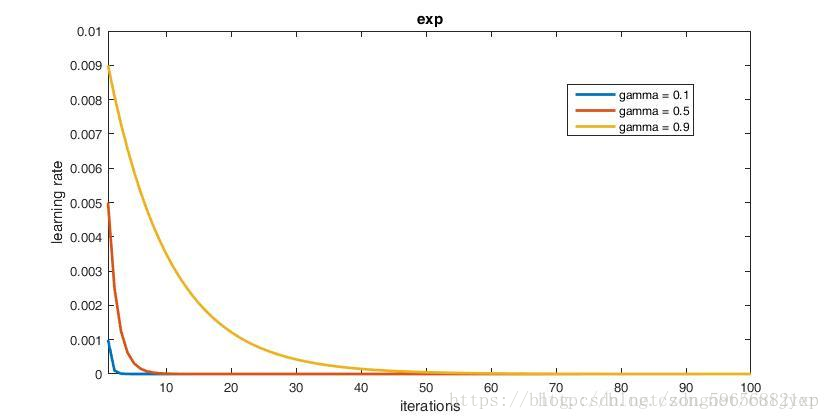
参数 gamma 的值要小于1。当等于1的时候,学习策略变为了 fixed。由exp的学习率计算方式可以看出,在 gamma = 0.1 的情况下,学习率每迭代一次变为上一次迭代的0.1倍。
inv
参数:
-
base_lr: 0.01
-
lr_policy: "inv"
-
gamma: 0.1
-
power: 0.75
-
max_iter: 10000
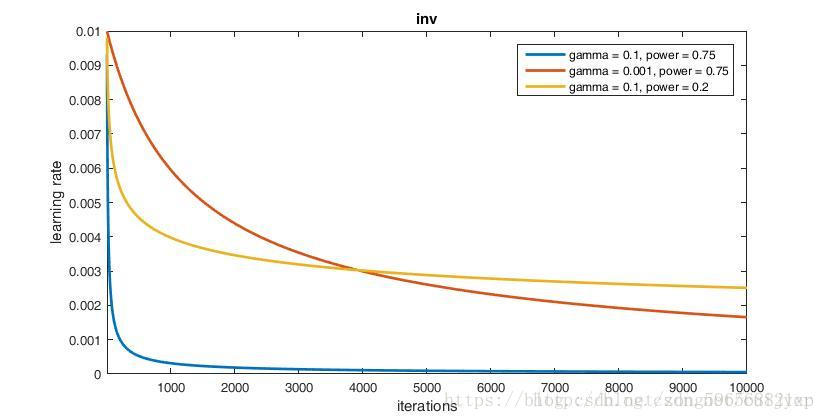
由上图可以看出,参数 gamma 控制曲线下降的速率,而参数 power 控制曲线在饱和状态下学习率达到的最低值。
multistep
参数:
-
base_lr: 0.01
-
lr_policy: "multistep"
-
gamma: 0.5
-
stepvalue: 1000
-
stepvalue: 3000
-
stepvalue: 4000
-
stepvalue: 4500
-
stepvalue: 5000
-
max_iter: 6000
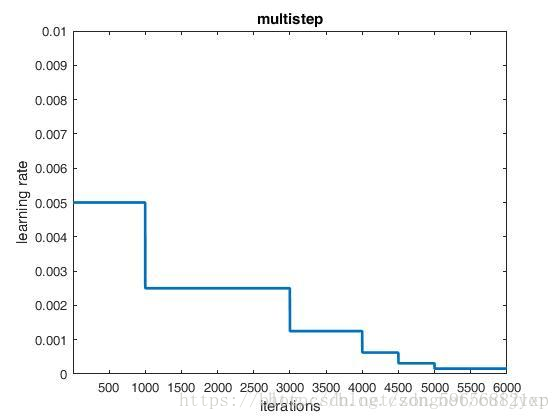
每一次学习率下降到之前的 gamma 倍。
poly
参数:
-
base_lr: 0.01
-
lr_policy: "poly"
-
power: 0.5
-
max_iter: 10000
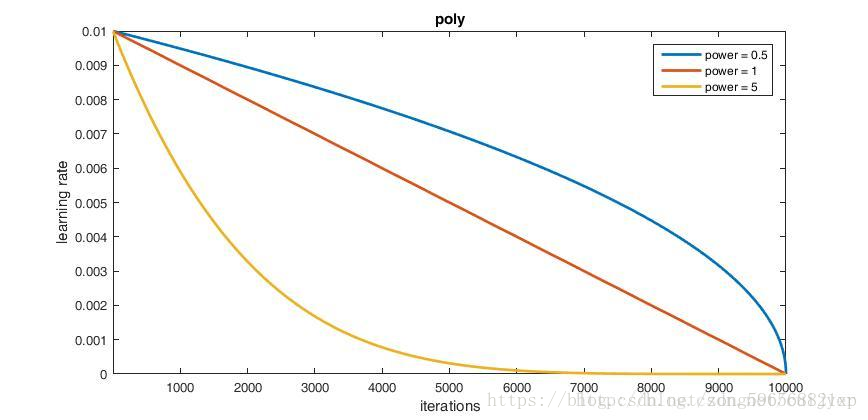
学习率曲线的形状主要由参数 power 的值来控制。当 power = 1 的时候,学习率曲线为一条直线。当 power < 1 的时候,学习率曲线是凸的,且下降速率由慢到快。当 power > 1 的时候,学习率曲线是凹的,且下降速率由快到慢。
sigmoid
参数:
-
base_lr: 0.01
-
lr_policy: "sigmoid"
-
gamma: -0.001
-
stepsize: 5000
-
max_iter: 10000
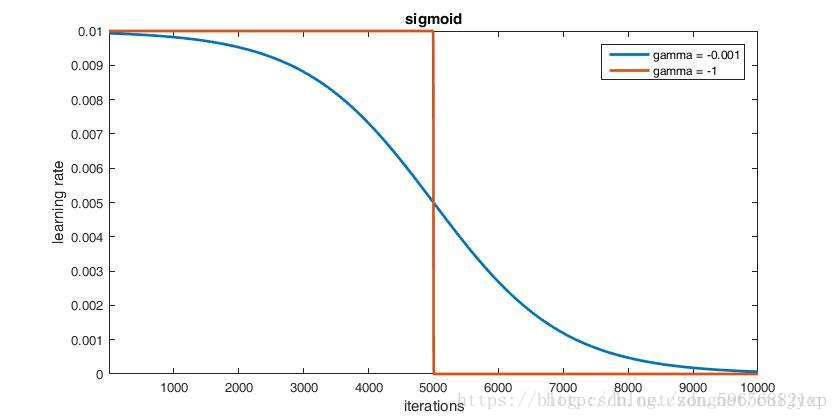
参数 gamma 控制曲线的变化速率。当 gamma < 0 时,才能控制学习率曲线呈下降趋势,而且 gamma 的值越小,学习率在两头变化越慢,在中间区域变化越快

 浙公网安备 33010602011771号
浙公网安备 33010602011771号