

目标检测 RCNN、SPP、Fast RCNN、Faster RCNN、R-FCN
 目标检测 RCNN、SPP、Fast RCNN、Faster RCNN、R-FCN
目标检测 RCNN、SPP、Fast RCNN、Faster RCNN、R-FCN
概述
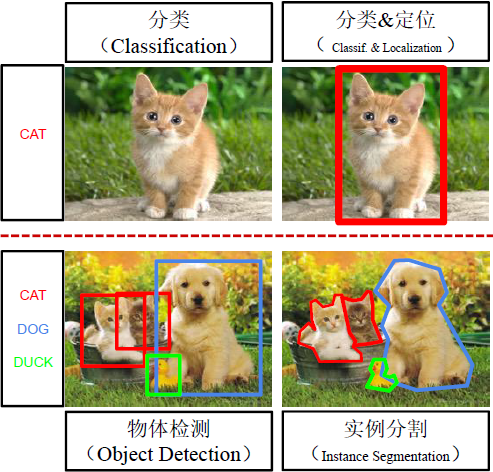
目标检测检测图片中所有物体的类别标签和位置(最小外接矩形Bounding box)。一般分类问题的输入的图像里,一般待分类物体占主要位置和大部分位置,要解决的问题是对很多个图像里的该物体加分类标签。目标检测问题的输入的图像里,会有多个待检测物体,相互之间有遮挡,需要使用最小外接矩形定位,并最终打上标签。分类和定位一般是单例任务,物体检测和实例分割是多例任务。
ILSVRC竞赛 Imagenet Large Scale Visual Recognition Challenge 2013-2017 物体类别200,每个图片多组标签比如类别和Bounding box(x,y,w,h); 竞赛还包含图像分类、场景分类、物体定位、场景解析。
目标检测传统方法的思路,先提取物体的区域,再对区域进行分类识别。
1 Region-CNN (R-CNN)
论文 https://arxiv.org/abs/1311.2524
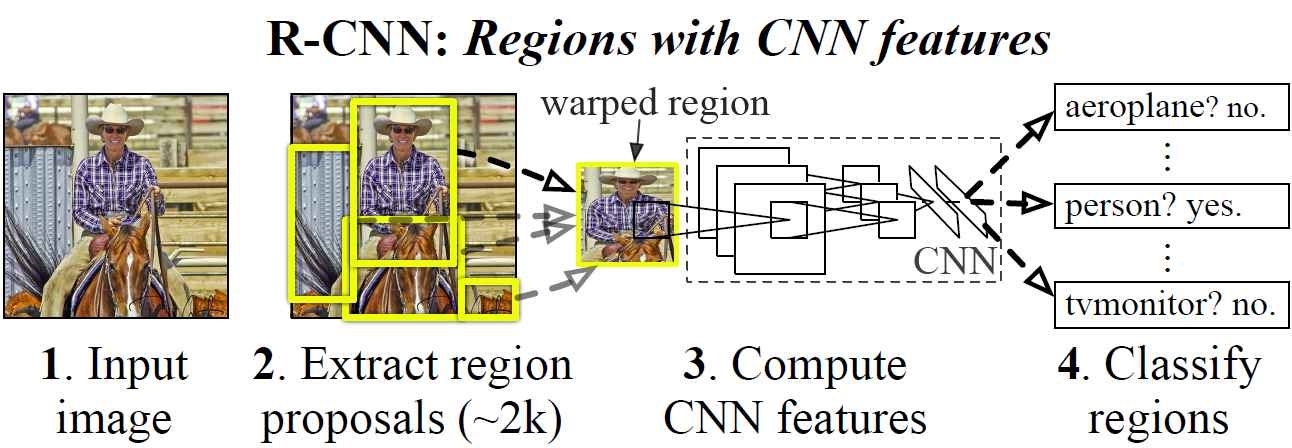
在输入的图片上,生成2000个矩形框包含所有可能成为物体的侯选区域,对所有矩形区域进行处理统一尺度,然后交给CNN进行特征提取,让特征作为SVM的输入和某个卷积层的特征作为边框的回归(Bounding box regression)的输入。
selective search
为后续的处理提供候选框
算法步骤:
- 按一定的规则生成区域集合\(R\)
- 计算区域集合 \(R\) 里每个相邻区域的相似度 \(S=\{s_1,s_2,\cdots\}\)
- 找出相似度最高的两个区域,将其合并为新集,添加进\(R\)
- 颜色(颜色直方图)相近的
- 纹理(梯度直方图)相近的
- 合并后总面积小的
- 合并后,总面积在斯bounding box中所占比例大的
- 从\(S\) 中移除所有与 2 中有关的子集
- 计算新集与所有子集的相似度
- 跳至 2,直到 \(S\) 为空
Warp
对目标区域进行填充、拉伸、缩放等方法统一处理作为CNN的输入(如:AlexNet \(227\times 227\))。
模块架构

使用AlexNet网络结构。第7层输出的特征(4096维)输入进SVM,第5层输出的特征进行Bounding box回归。

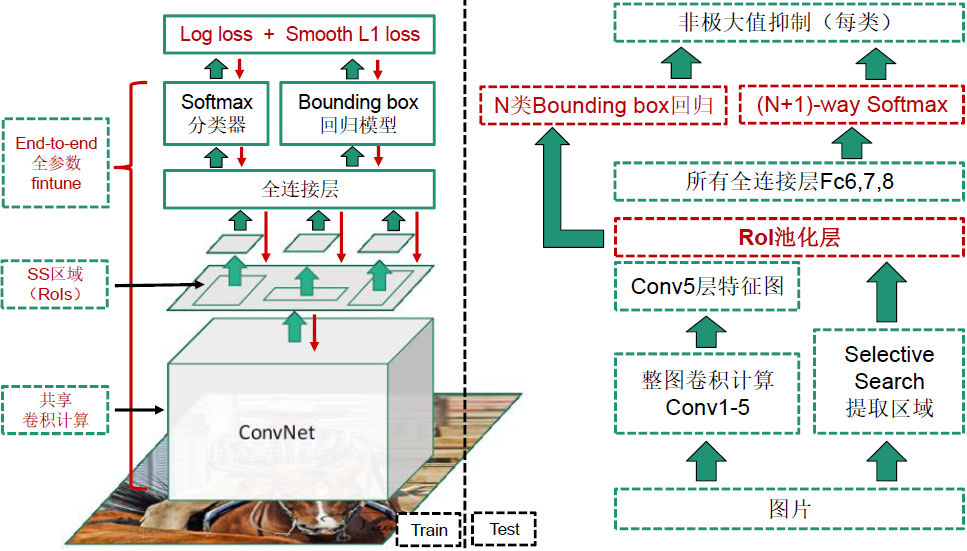
使用ImageNet对CNN模型进行预训练 pre-train. 然后将 Softmax 层改成 (N+1)-way(1000-way换成21-way或者201-way等根据数据集不同有所差异),在Selective search 方法生成的所有区域上对预训练好的CNN模型进行微调 fine-tune。(N+1)-way 中 N类 为 跟Ground-truth(专家人工标注的区域)重合\(IoU\geq0.5\)的打标签为正样本, (\(IoU=\frac{A\cap B}{A\cup B}\)), 1类负样本为 \(IoU<0.5\)只包含很小的局部、只包含背景或者其它类的物体等情况打标签为负样本。正样本里类别的数量 N 根据目标检测的时候问题包含的类数,比如Pascal VOC数据集是20类,ImageNet是200类。
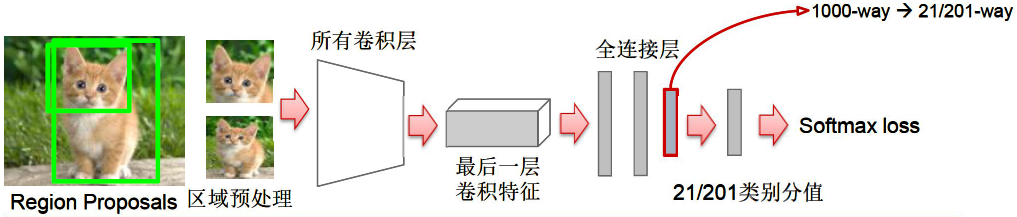
SVM分类问题
对第7层Fc7输出的特征放入SVM进行训练。每个类别(N类)对应一个SVM分类器(比如判断类别为猫,则有分类为猫的SVM)。正样本为所有Ground-truth区域,负样本为跟Ground-truth重合 \(IoU<0.3\)的selective search区域。

技巧: 一般情况下,SVM训练完成后,如果完全分类正确,所有正样本的输出概率都大于0.5,而所有负样本的的输出概率都小于0.5。对于有一部分的负样本的输出概率也大于0.5的假阳性的情况,对假阳性收集起来对SVM进行二次训练,会提高分类准确度。
Bounding box回归
对于微调fine-tuning 后的模型的第5层输出的特征上做Bounding box回归模型。每个类别(N类)训练一个回归模型,目标使selective search做出的矩形框\(P\)(经过CNN后的特征) 与同一类的Ground-truth的框\(G\)进行回归, \(P\rightarrow G\)。
对于Bounding box\(\{(P^i, G^i)\}_{i=1,\cdots ,N}\),矩形中心的位置 \((x,y)\), 宽高 \((w,h)\),selective search 做出的区域 \(P^i=(P_x^i, P_y^i, P_w^i, P_h^i)\),Ground-truth 区域 \(G=(G_x, G_y, G_w, G_h)\),selective search 在第5层Conv5卷积的输出特征 \(\phi_5(P)\)。要求只对selective search中接近Ground-truth的情况做回归即 \(P\) 的\(IoU>0.6\)。
目标是以下式子尽可能小:
\(t_x=(G_x-P_x)/P_w\)
\(t_y=(G_y-P_y)/P_h\)
\(t_w=\log G_w - \log P_w=\log (G_w/P_w)\)
\(t_h=\log G_h - \log P_h = \log (G_h/P_h)\)
所以:
\(G_x=P_w t_x + P_x\)
\(G_y=P_h t_y + P_y\)
\(G_w = P_w \exp (t_w)\)
\(G_h = P_h \exp (t_h)\)
使用\(\exp\)能保证 \(G_w\), \(G_h\) 为正。
selective search 的矩形框经过一定的平移变换和缩放就可以达到 Ground-truth。
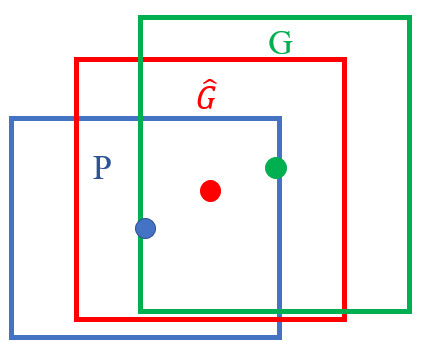
绿色的框是Ground-truth, \(P\) 是 selective search 给出的候选区域。

绿色的框是Ground-truth区域,红色的是 selective search 给出的候选区域。对二者的\(IoU>0.6\)的区域进行候选区域对Ground-truth区域的回归微调。
假定实验中经过 \(d_x(P)\), \(d_y(P)\) 的平移变换和\(d_w(P)\), \(d_h(P)\) 的缩放才能接近 Ground-truth,即
\(\hat{G}_x=P_w d_x(P) + P_x\)
\(\hat{G}_y=P_h d_y(P) + P_y\)
\(\hat{G}_w = P_w \exp (d_w(P))\)
\(\hat{G}_h = P_h \exp (d_h(P))\)
于是回归的目标函数可以表示为 \(d_\star (P)=\omega_\star^T\phi_5(P)\), (\(Y=\mathbf{\omega} X\)), 要使得 \(t_\star\) 与 \(d_\star (P)\) 的差异最小,所以损失函数:
\(Loss=\sum\limits_i^N (t_\star^i-\hat{\omega}_\star^T\phi_5(P^i))^2\)
同时要使回归中权重尽量小:
\(\mathbf{w}_\star=\mathrm{argmin}_{\hat{\omega}_\star}\sum\limits_i^N (t_\star^i-\hat{\omega}_\star^T\phi_5(P^i))^2+\lambda\parallel\hat{\omega}_\star\parallel^2\)
相当于单层的感知机。
测试阶段:参数 \(\mathbf{w}\) 已经训练好。
步骤:
- selective search (fast mode) 提取2000区域
- 将所有区域膨胀和缩放到 \(227\times 227\)
- 使用 fine-tune 过的AlexNet计算2套特征
- 为每个类别(比如猫)分别执行
- 第7层 全连接 full connected 7 特征 -> SVM分类器 -> 类别打分
- 对区域按分值排序,保留分值最大的,其它的与这个最大值的相近(与最大值的 \(IoU\geq0.5\))的都去掉,即非极大值抑制方法
- 第5层 卷积层 Conv5 特征 -> Bounding box 回归模型 -> 得到偏差
- 使用Bounding box 偏差修正区域子集
- 第7层 全连接 full connected 7 特征 -> SVM分类器 -> 类别打分
- 为每个类别(比如猫)分别执行
性能评价:
True Positive: 与Ground-truth 的 \(IoU\geq 0.5\)
False Positive: 与Ground-truth 的 \(IoU\lt 0.5\)
False Negative: 遗漏的 Gound truth 区域
使用准确率precision: \(TP/(TP+FP)\)和召回率recall: \(TP/(TP+FN)\)
平均精度(Average Precision):PR曲线下的面积,是Precision 对于 Recall 的积分。mAP 是所有类别的平均精度求和除以所有类别数,即对数据集中所有类的平均精度的平均值。
缺点
训练时间长,特征提取占很长时间,占用磁盘空间比较大,IO占时间也比较长。
每张图片都会产生2000区域分别计算CNN特征,计算量太大。
2 SPP-NET (Spatial Pyramid Pooling)
论文 https://arxiv.org/abs/1406.4729
对于R-CNN的改进,输入整图,进行卷积,在Conv5层的输出上提取所有区域的特征。相当于所有区域共享了卷积计算之后再用selective search 提取区域特征。
引入空间金字塔池化 Spatial Pyramid Pooling,为不同尺寸的区域,在Conv5的输出上提取特征,映射到尺寸固定的全连接层上。
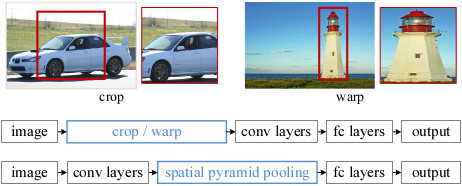
SPP空间金字塔池化层在Conv5层的后面代替AlexNet原来的池化层。对于selective search的区域特征,在Conv5的卷积层输出的特征图feature map上选取与原图对应的区域位置,因为卷积的过程的每个feature map 只对原图的每个部分进行响应,相当于提取原图的一部分特征,但是并不改变这部分特征在原图中的相对位置。
网络结构
网络结构示意图如下:

空间金字塔池化 Spatial Pyramid Pooling
在空间金字塔池化层上,对 feature map 进行统计bin分块 \(1\times1\),\(2\times2\),\(4\times4\),Bin内使用 Max pooling,然后将3个level的bin 合并 \(16+4+1=21\) 个bin 的 \(21\times256-\mathrm{d}\) 传给full connected 第6层。sliding window pooling 的方法,\(4\times4\)的bin 即 池化结果为 \(4\times4\),所以pooling窗口为\(sizeX=\lceil{13\over 4}\rceil=4\),\(stride=\lfloor{13\over 4}\rfloor=3\)

SPP-Net训练过程:
- 在ImageNet 上对CNN模型进行pre-train
- 在Conv5后面计算所有selective search 区域的SPP特征
- 使用SPP特征fine tune新的fc6->fc7->fc8层(只fine tune 全连接层)
- 使用fc7的特征训练线性SVM分类器
- 使用SPP特征训练Bounding box 回归模型
优点:
由于先卷积再处理区域特征相较于R-CNN大大节省了特征提取的时间
缺点:
仍然需要存储大量的特征,复杂的多阶段训练,训练时间仍然长。
SPP-Net的新问题,SPP层之前的所有卷积层参数不能fine tune。
3 Fast R-CNN
论文 https://arxiv.org/abs/1504.08083
改进:相较于R-CNN、SPP-Net训练和测试更快,mAP更高。能够实现端对端单阶段的训练*,不需要离线存储特征文件。使用多任务损失函数。所有层的参数都可以fine tune。
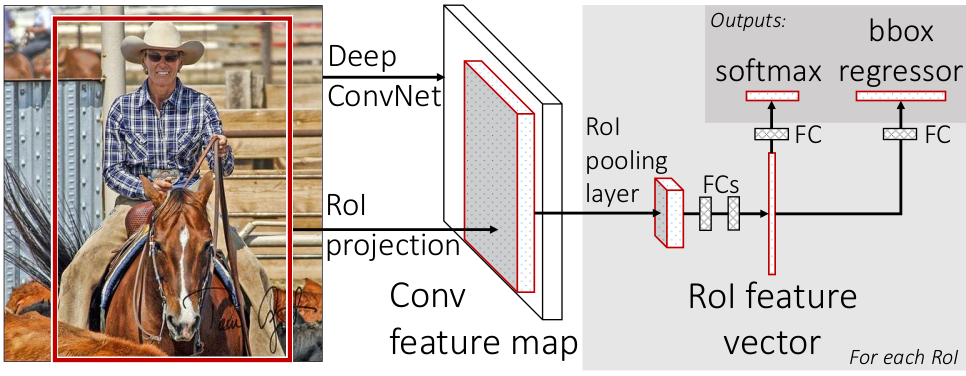
使用感兴趣区域池化层(Region of Interest)代替空间金字塔池化层。
网络结构
网络结构示意图:
Conv5输出的特征图进入感兴趣区域池化层,感兴趣区域池化的区域特征来自原图的 selective search 区域特征。
N类Bounding Box 回归和 (N+1)-way Softmax分类的损失函数合并在一起,Log loss + Sooth L1 loss,最后做非极大值抑制。
感兴趣区域池化 Region of Interest
与SPP里的使用多种粒度的bins不同,RoI 只使用一层较细粒度的bins,相当于SPP的特例,只有一层SPP。将特征图分成 \(H\times W\)网络如 在VGG上使用\(7\times7\)网络。每个bin内进行Max pooling。

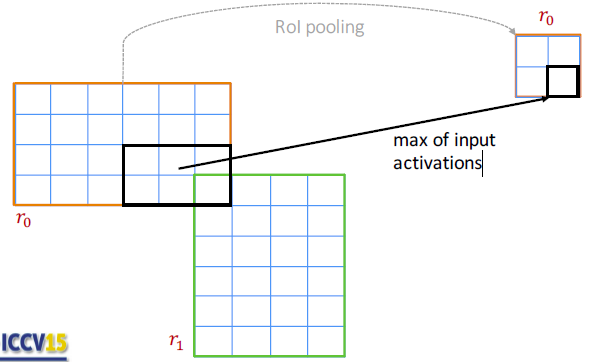
感兴趣区域可能是重合的,对于非重叠的区域,类似Max pooling 的方法。对于重叠区域前向传播是max pooling,反向传播是计算梯度的和。
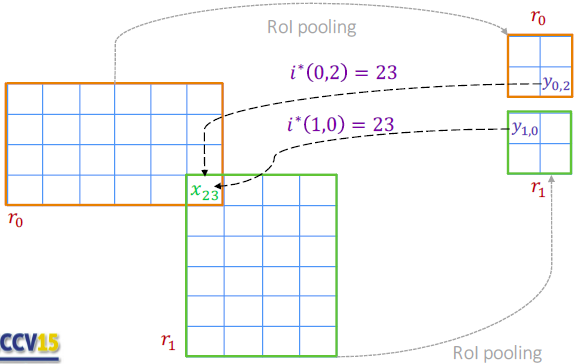
前向传播中,\(y_{0,2}\) 中的 \(0\), \(2\) 表示来自\(r_0\)区域的第\(2\)个输出的 pooling 结果,其值为\(r_0\)区域的第\(2\)子区域的最大值,即第\(23\)号位置的值。\(r_1\) 区域的在池化后的结果中\(y_{1,0}\)的值是其子区域的最大值 \(x_23\)>
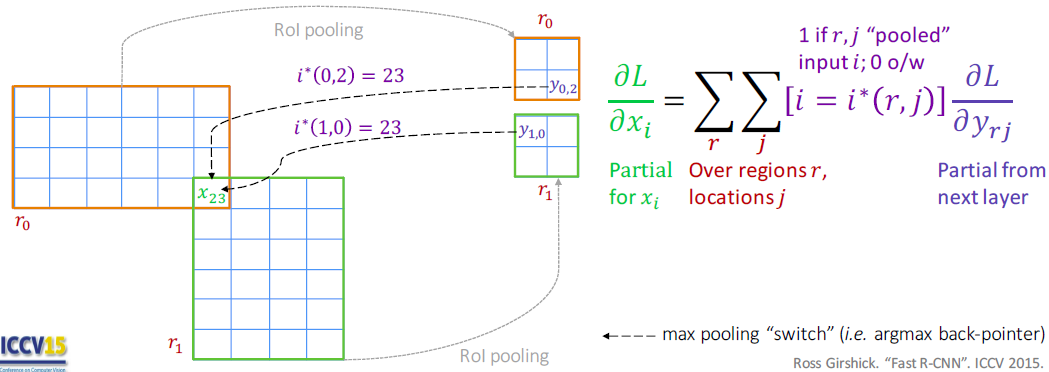
如图示区域 \(r_0\) 和 \(r_1\) 重叠,反向传播在\(r_0\) 的 其它非重叠部分使用 max pooling,重叠部分要计算\(x_i\)对pooling结果有贡献的梯度的和。\(\frac{\partial L}{\partial x_{23}}=\frac{\partial L}{\partial y_{0,2}}+\frac{\partial L}{\partial y_{1,0}}\)
多任务损失函数
将分类打标签的损失函数和Bounding box 回归的损失函数加在一起。
\(L(p,u,d^u,t)=L_{\text{classifier}}(p,u)+\lambda[u\geq 1]L_{\text{location}}(t,d^u)\)
\(\lambda\)调整二者的重要关系。
分类器损失函数\(L_{\text{classifier}}(p,u)\)
假定原始图像中包含\(C+1\)个类,每个RoI中\(C+1\)个分类(\(C\)个物体类别,\(1\)个背景类别)的概率分布可以表示为 \(p=(p_0,\cdots,p_C)\)。某个RoI的Ground-truth类别为\(u\),\(u\in\{0,\cdots,C\}\),目标损失函数为尽可能将该RoI标记为\(u\),\(L_{\text{classifier}}(p,u)=-\log p_u\),标记为正确的分类的话 \(p_u=1\),损失函数为 \(0\),如果分到 \(\{0,\cdots,u,\cdots,C\}\)中其它不是\(u\)的类,\(p_u<1\),是个比较小的数,取 \(\log\) 后是个绝对值比较大的负数,前面再取负号,损失函数值就会是比较大的正数。如此损失函数要尽可能小,则需要分到Ground-truth分类\(u\)的概率要尽可能的大。对于类别\(u\)的取值,\(0\)表示背景,如果\(u=0\),则指示函数\([u\geq1]=0\),没有Bounding box回归的必要,\(\lambda[u\geq 1]L_{\text{location}}(t,d^u)=0\),如果\(u\geq1\)表示RoI区域特征是物体,则指示函数\([u\geq1]=1\),后面的Bounding box回归项存在。
Bounding box 回归损失函数 \(L_{\text{location}}(t,d^u)\)
对于Bounding box\(\{(P^i, G^i)\}_{i=1,\cdots ,N}\),矩形中心的位置 \((x,y)\), 宽高 \((w,h)\),selective search 做出的区域 \(P^i=(P_x^i, P_y^i, P_w^i, P_h^i)\),Ground-truth 区域 \(G=(G_x, G_y, G_w, G_h)\)。与Ground-truth的真实偏差 表示为\(t=(t_x,t_y,t_w,t_h)\),标记为\(u\)类的RoI的预测偏差表示为\(d^u=(d_x^u,d_y^u,d_w^u,d_h^u)\)
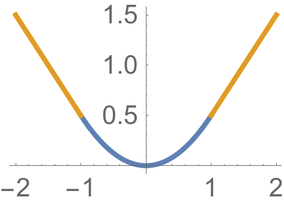
要使得 \(t_\star\) 与 \(d_\star\) 的差异最小,所以对于每个标记为\(u\)类的RoI区域特征图距离 \((t_\star-d_\star^u)^2\) 最小。考虑有outlier的特殊情况,二者差距非常大,导致平方后更大,特别是差距为大于 \(1\) 的数,导致一批数据的回归受到影响,很难把outlier离群点回归掉。为了消除这种影响使用了 smooth L1 做为损失函数。
\(\text{smooth}_{L1}(x)=\begin{cases}
0.5x^2 & \mid x\mid<1\\
\mid x\mid-0.5 & \text{otherwise.}
\end{cases}\)
在 \(\mid x\mid<1\) 的时候使用 \(x^2\),在\(\mid x\mid\geq1\) 的时候使用自身的绝对值,变成线性的了。\(\mid x\mid-0.5\)可以与\(0.5x^2\)衔接拼起来。
标记分类为\(u\)的RoI的损失函数可以写为:\(L_\text{location}(t,d^u)=\sum\limits_{\star\in\{x,y,w,h\}}\text{smooth}_{L1}(t_\star-d_\star^u)\)
训练中的技巧:
- 使用 Mini-batch sampling 抽样
分级抽样法 Hierarchical sampling
每个Batch的尺寸为\(128=2\times64\)个RoI。包含\(2\)个图片,每个图片选取\(64\)个RoI。并对RoI分类的比例为物体占\(25\%\),背景占\(75\%\),因为随机选的话,选到背景(负向样本)会多一点,需要保证抽样的正向样本(物体)能够达到一定的比例有利于训练。具体做法是,类别为\(u\geq1\)且与Ground-truth的\(IoU\geq0.5\)的占\(25\%\),类别为\(u=0\)且与Ground-truth的 \(IoU\in[0.1, 0.5)\) 的占 \(75\%\)

- 降低全连接层的计算量
一般情况下,全连接的计算量比较大。目标检测任务中,要处理的RoI数量比较多,几乎一半的前向计算时间被用于全连接层。对于Fast R-CNN,RoI池化层后的全连接层需要进行约2000次。在Fast R-CNN 中采用奇异值分解 Singular Value Decomposition加速全连接层计算。假定全连接层输入数据为\(X\),输出数据为\(Y\),全连接层权值为\(u\times v\)的矩阵$W,该层全连接计算为 \(Y=W\times X\),将 \(W\) 进行奇异值分解 \(W\approx U\Sigma_t V^T\) 相当于在中间加了一层,减少了权值,降低了计算量。

4 Faster R-CNN
论文 https://arxiv.org/abs/1506.01497
网络结构
使用Region Proposal Network (RPN) 网络替代Selective Search为网络提供候选区域。相当于使用 Attention 机制引导 Fast R-CNN 关注区域。RPN提供的 Region proposal 量少质优,有较高的precision,较高的 recall。
Faster R-CNN=Fast R-CNN + RPN
Region Proposal Network (RPN)
原文中实验采用的是ZFNet 和 VGG16。ZFNet类似AlexNet,Conv5的特征图为 \(13\times 13\times 256\)。将特征图进行 padding 2,使用stride 1的\(3\times3\)的滑动窗口与\(3\times3\),\(256-d\)进行卷积。每个\(3\times3\)的滑动窗口与\(3\times3\)的卷积核进行卷积结果为 \(1\times 1\),对于\(256-d\)个feature map 共有 \(1\times 1\times256-d\),每个feature map的每个像素都要用滑动窗口处理,共有\(13\times 13\)个滑动窗口,总的输出为 \(13\times13\times256-d\)。下图为其中一个滑动窗口的例子 \(1\times1\times256-d\)即\(256-d\)向量。
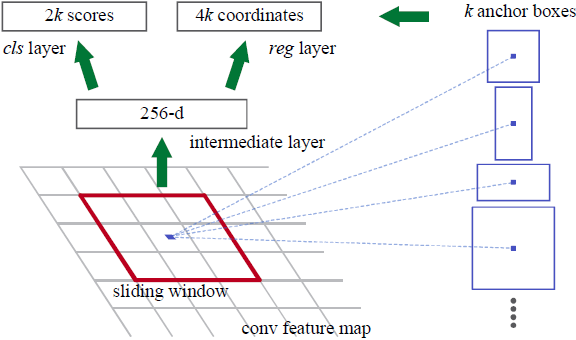
相当于逆向思维,不是先选候选框,(比如SPP,要参照原图的selective search 给出的候选框的位置,在Conv5上给出候选框的位置再做进一步处理),而是对每个像素去猜在它上面原图可能的候选框是什么样的。给了 \(k=9\) 种可能的候选框形状当作 Anchor box,包含相对于原图的3种尺度 scale: 128,256,512,还包含3种矩形形状,宽高比 ratio为 1:1,1:2,2:1。假定特征图上每个点上在原图上都有几种候选框,相当于在特征图上的每个点有 \(k\) 个 anchor box。特征图上的 Anchor 的总数量为 \(W\times H\times k=13\times13\times9\)。Anchor box 的中心与特征图上的滑动窗口的中心是对应的,特征图上的滑动窗口的中心即当前要猜的区域的中心点,Anchor box即可能的候选框。


对于一个滑动窗口得到 \(1\times1\times256\) 后,分别进行分类和Bounding box回归。
对于分类使用 256个 \(1\times1\times 2k-d\)进行卷积输出 \(k\) 组包含物体和非物体分值的结果,\(2\) 表示两个分类:物体、非物体,也即 \(2\)类,\(k\) 组,\(256\) 个 \(1\times1\)的卷积。所以每个滑动窗口的\(1\times1\times256-d\)的输出与\(1\times1\times256-d\)进行卷积的再输出为\(1\times1\times256-d\),考虑\(2\)类和\(k\)组,共输出\(1\times1\times18\times256-d\)。
考察每个Anchor,假定原始图像中包含\(C+1\)个类,每个Anchor中\(C+1\)个分类的概率分布可以表示为 \(p_i^u=(p_i^0,\cdots,p_i^C)\)。某个Anchor \(i\) 的Ground-truth类别为\(u_i\),\(u_i\in\{0,\cdots,C\}\),对于类别\(u_i\)的取值,\(0\)表示背景,如果\(u_i=0\),则指示函数\([u_i\geq1]=0\),没有Bounding box回归的必要,\(\lambda[u_i\geq 1]L_{\text{location}}(t^{u_i},d^{u_i})=0\),如果\(u_i\geq1\)表示Anchor区域特征是物体,则指示函数\([u_i\geq1]=1\),后面的Bounding box回归项存在。
损失函数为 \(L_{\text{classifier}}(p_i,u_i)\propto-\log(p_i^{u_i})\)
对于Bounding Box回归使用 \(1\times1\times4 k-d\) 进行卷积,输出 \(k\) 组候选框的偏移位置 \((x,y,w,h)\),共输出 \(1\times1\times36\times256-d\),其中\(4\)表示偏移的\(4\)个位置参数 \((x,y,w,h)\)
对于Anchor box\(\{(A^i, G^i)\}_{i=1,\cdots ,N}\),矩形中心的位置 \((x,y)\), 宽高 \((w,h)\),对于某个Anchor box \(i\)被标记为\(u_i\),其区域位置 \(A^{u_i}=(A_x^{u_i}, A_y^{u_i}, A_w^{u_i}, A_h^{u_i})\),相应的 Ground-truth 区域 \(G^i=(G_x^i, G_y^{u_i}, G_w^{u_i}, G_h^{u_i})\)。要求只对Anchor box中接近Ground-truth的情况做回归即 \(A^{u_i}\) 的\(IoU>0.7\)。
目标是以下式子尽可能小:
\(t_x^{u_i}=(G_x^{u_i}-A_x^{u_i})/A_w^{u_i}\)
\(t_y^{u_i}=(G_y^{u_i}-A_y^{u_i})/A_h^{u_i}\)
\(t_w^{u_i}=\log G_w^{u_i} - \log A_w^{u_i}=\log (G_w^{u_i}/A_w^{u_i})\)
\(t_h^{u_i}=\log G_h^{u_i} - \log A_h^{u_i} = \log (G_h^{u_i}/A_h^{u_i})\)
所以:
\(G_x^{u_i}=A_w^{u_i} t_x^{u_i} + A_x^{u_i}\)
\(G_y^{u_i}=A_h^{u_i} t_y^{u_i} + A_y^{u_i}\)
\(G_w^{u_i} = A_w^{u_i} \exp (t_w^{u_i})\)
\(G_h^{u_i} = A_h^{u_i} \exp (t_h^{u_i})\)
使用\(\exp\)能保证 \(G_w^{u_i}\), \(G_h^{u_i}\) 为正。
假定实验中经过 \(d_x^{u_i}(A)\), \(d_y^{u_i}(A)\) 的平移变换和\(d_w^{u_i}(A)\), \(d_h^{u_i}(A)\) 的缩放才能接近 Ground-truth,即
\(\hat{G_x^{u_i}}=A_w^{u_i} d_x^{u_i}(A) + A_x^{u_i}\)
\(\hat{G_y^{u_i}}=A_h^{u_i} d_y^{u_i}(A) + A_y^{u_i}\)
\(\hat{G_w^{u_i}} = A_w^{u_i} \exp (d_w^{u_i}(A))\)
\(\hat{G_h^{u_i}} = A_h^{u_i} \exp (d_h^{u_i}(A))\)
要使得 \(t_\star^{u_i}\) 与 \(d_\star^{u_i} (A)\) 的差异最小,所以损失函数:\(L_\text{location}(t^{u_i},d^{u_i})=\sum\limits_{\star\in\{x,y,w,h\}}\text{smooth}_{L1}(t_\star^{u_i}-d_\star^{u_i})\)
与 Fast R-CNN 相同将两部分的损失函数定义在一起:
\(L(\{p_i\},\{t_i^{u_i}\})=\frac{1}{N_{\text{classifier}}}\sum\limits_i^{N_\text{classifier}}L_{\text{classifier}}(p_i,u_i)+\lambda\frac{1}{N_{\text{location}}}\sum\limits_i^{N_\text{location}}[u_i\geq 1]L_{\text{location}}(t^{u_i},d^{u_i})\)
\(\lambda\)调整二者的重要关系。
使用 Mini-batch sampling 抽样
每个Batch的尺寸为\(256\)。单个图片,\(128\)个负向样本(非物体) \(IoU<0.3\)的anchor box,\(128\)个正向样本(物体) \(IoU>0.7\)的anchor box,如果都不大于\(0.7\)就选最大的。损失函数中的 \(i\) 即为 mini-batch 中的某个 anchor box \(i\)。
Faster R-CNN 的训练过程:
- 1 单独训练RPN网络,使用 ImageNet 上pretrained模型参数对卷积层初始化。训练完产生 Region proposals
- 2 训练Fast R-CNN网络,使用 ImageNet 上pretrained模型参数对卷积层初始化,该过程中的卷积层与第1步卷积层不共享
- Region proposals 由第1步的RPN生成
- 3 调优RPN,使用第2步Fast R-CNN的卷积层参数初始化训练RPN网络的卷积层,然后固定卷积层,finetune RPN网络的剩余层,生成新的更精确的Region proposals
- 4 调优Fast R-CNN,与第3步共享卷积层(即都是使用第2步训练好的),固定卷积层,finetune 剩余的RoI以上的层
- 这一步用到的 Region proposals 由第3步生成
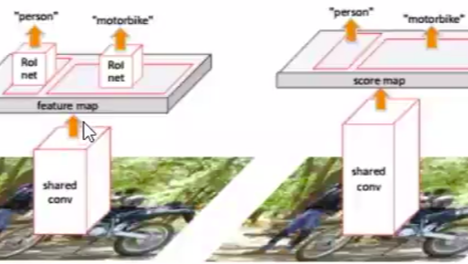
5 R-FCN
论文 https://arxiv.org/abs/1605.06409
基础主干网络是ResNet101。
CNN的发展演化有全卷积化的趋势,卷积层越来越取代全连接层, 比如 ResNet、GoogLeNet 只有1个全连接层。全连接计算量大,能够实现通道融合,但是在这些目标检测的方法中对region proposals全连接后相对位置信息会有变化。目标检测网络对变换敏感性 (Translation variance)较大,全连接层对其影响较大。分类网络的变换不变性 (Translation invariance)较强,全连接层对分类网络影响不大,卷积层越深,感受野增大,不变性越强,全连接层的影响越不敏感。由于卷积网络不会导致相对位置信息的变化。对于区域相关的网络 region proposals net 的输入如果改成卷积更好。
网络结构
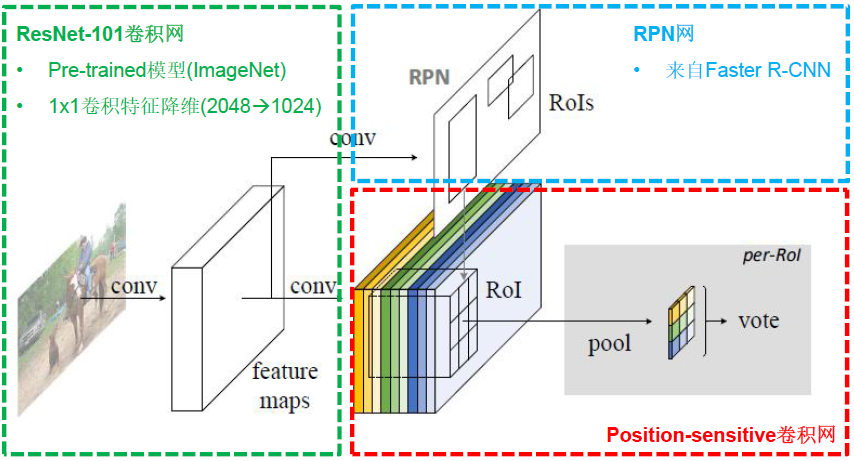
对于以前已经有的 RPN 和 RoI
RPN的输入共享卷积feature map,它替代的是 selective search 的功能,它的结果不是最终框,输出的是需要调整的候选框,但是这些候选框由于经过了网络训练,更加准确。
RoI从空间金字塔的较细粒度的bins改过来,作用是将不同尺度的图像的特征统一维度的特征向量给后面的全连接层。RoI 里的框信息是 selective search 或者 RPN给出的,RoI 也算是 Region proposal。RoI 需要进一步分类和Bounding box 回归。这种思路的解决问题的方式,在R-FCN原文里被称作RoI-wise。
这里的 RPN 和 RoI
这里的RPN和之前Faster RCNN的一样。
这里的RoI 依然负责 Region proposal, 其区域仍然由 RPN 提供。但是这里设计了新的卷积层来生成 RoI,不像前面的直接在共享卷积层上进行操作,而是进行 \(1\times1\times k^2(C+1)\) 的卷积操作来生成的 feature map 来作为 RoI,在此基础上加上 RPN的候选框以及进行位置敏感分值图,继而进行池化等操作,共享计算就是指的共享这部分卷积计算和卷积计算生成的RoI。对于边框回归也采用 \(1\times1\times 4k^2(C+1)\) 统一的卷积操作形式。
变换敏感性 Translation variance
位置敏感分值图 Position-sensitive score maps
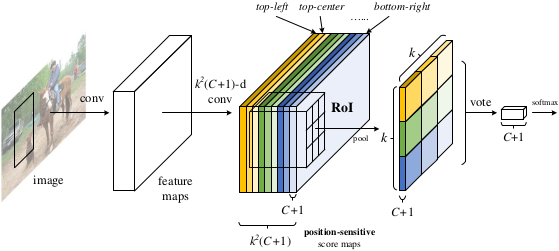
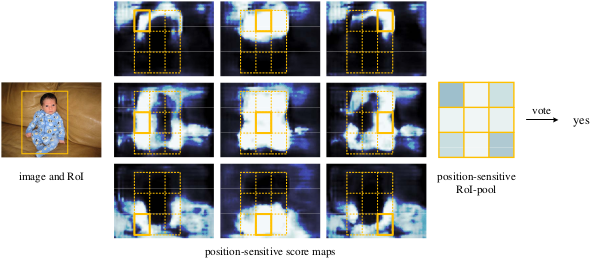
假定共有\(C+1\)类,其中 \(C\)类物体,\(1\) 类非物体 (背景或者框住一点点物体的情况,用\(0\)表示)。给定 \(k^2\times(C+1)\) 的reature map RoI中,给定了RPN的候选框,再给定划分了\(k\)个bins的score map,比如\(k=3\),则对于对\(C+1\)中某一类可以形像地表述为\(k^2=9\)层RoI上RPN框住的候选框做bins所响应的特征,并与 \(k\times k=3\times3\) score map 的bins区域对应,彼此bin区域的左上、中上、右上、左中、中中、右中、左下、左中、右下进行对应。假定类别为人,则第一层响应的为人的左上部分,第二层响应的为人的左中等等。若人是倒立的,那么中上为脚,卷积网络也是通过训练来获取特征,并不涉及物体本身是否倒立,只要训练集能够获取足够多特征就能够准确响应相应的特征。后面的进行位置敏感池化整合特征。
具体操作去掉 ResNet101 的全连接层和最后一层卷积层后面的池化层,换成 \(k^2\times (C+1)\) 通道的 \(1\times1\times\) 进行卷积。
位置敏感池化 Position-sensitive RoI pooling
对于 \(k\times k\)的score map 的 bins,每一块bin不止一个像素,它是对RoIs也做了bins,取了每个RoI rectangle(RPN框好的感兴趣区域,所以RPN 生成 RoI)对应位置的bin块,拼接成 \(k\times k\), 所以可以使用均值池化或者最大值池化。然后再对所有bin块计算的值求和。对于第一个框住的物体来说需要 \(C+1\) 通道的 score map,得到 \(C+1\) 维向量。
对于 size 为 \(w\times h\) 取bin,\({w\over k} \times {h\over k}\),对 第\((i,j)\) 个 bin \((0\leq i,j\leq k-1)\)的范围是 \(\lfloor i{w\over k}\rfloor\leq x \lt \lceil(i+1){w\over k}\rceil\), \(\lfloor j{h\over k}\rfloor\leq y \lt \lceil(i+1){h\over k}\rceil\)。对某类物体\(c\)的bins的\((i,j)\) 个 bin中的像素\((x,y)\)的概率值(训练出的) \(z_{i,j,u}\) 相加再取平均\(z_{i,j,u}/n\)作均值池化,即\(r_u(i,j\mid\Theta)=\sum\limits_{(x,y)\in\text{bin}(i,j)\\(0\leq i,j\leq k-1)} z_{i,j,u}(x+x_0,y+y_0\mid\Theta)/h\),其中 \(\Theta\) 是网络中的参数。
对其求和 \(r_u(\Theta)=\sum\limits_{i,j}r_u(i,j\mid\Theta)\)
Softmax归一化得到概率值 \(p_u(\Theta)=e^{r_u (\Theta)}/\sum\limits_{u=0}^C e^{r_{u^\prime} (\Theta)}\)
可视化如图,框的正确的话相应块响应高的比较多,最后得分比较高:

损失函数
分类损失函数,与之前一样 \(L_{\text{classifier}}(p,u)=−\log p_u\)
若某区域Ground-truth类别为\(u\),\(u\in\{0,\cdots,C\}\),目标损失函数为尽可能将该其标记为\(u\),\(L_{\text{classifier}}(p,u)=-\log p_u\),标记为正确的分类的话 \(p_u=1\),损失函数为 \(0\),如果分到 \(\{0,\cdots,u,\cdots,C\}\)中其它不是\(u\)的类,\(p_u<1\),是个比较小的数,取 \(\log\) 后是个绝对值比较大的负数,前面再取负号,损失函数值就会是比较大的正数。如此损失函数要尽可能小,则需要分到Ground-truth分类\(u\)的概率要尽可能的大。对于类别\(u\)的取值,\(0\)表示背景或者框到一点物体的情况,如果\(u=0\),则指示函数\([u\geq1]=0\),没有Bounding box回归的必要,\(\lambda[u\geq 1]L_{\text{location}}(t,d^u)=0\),如果\(u\geq1\)表示RoI区域特征是物体,则指示函数\([u\geq1]=1\),后面的Bounding box回归项存在。
回归使用同样的卷积方式 \(1\times1\times 4k^2(C+1)\)
同样的池化方式得到 \(4\times k\times k\) 输出
在\(k\times k\)上做均值投票后得到预测值 \(d_\star=(d_x,d_y,d_w,d_h)\)
与 Ground-truth 值\(t_\star=(t_x,t_y,t_w,t_h)\)比较
\(L_\text{location}(t,d^u)=\sum\limits_{\star\in\{x,y,w,h\}}\text{smooth}_{L1}(t_\star-d_\star^u)\)
与 Faster R-CNN 相同将两部分的损失函数定义在一起:
\(L(p,t_{x,y,w,h})=L_{\text{classifier}}(p,u)+\lambda[u\geq 1]L_{\text{location}}(t,d^u)\)
\(\lambda\)调整二者的重要关系。
训练
OHEM (Online Hard Example Mining)技巧
- 首先对RPN获得的候选RoI进行排序(正负样本分别进行排序)
- 然后在含有正样本(目标)的RoI中选择前 N 个 RoI,将正负样本的比例维持在 1:3 的范围内,保证每次抽取的样本中都含有一定的正样本,这样训练可以提高网络的分类能力
与 Faster R-CNN训练过程类似4步:
RPN与R-FCN交替训练
Faster R-CNN 的训练过程:
- 1 单独训练RPN网络,使用 ImageNet 上pretrained模型参数对卷积层初始化。训练完产生 Region proposals
- 2 训练R-FCN网络,使用 ImageNet 上pretrained模型参数对卷积层初始化,该过程中的卷积层与第1步卷积层不共享
- Region proposals 由第1步的RPN生成
- 3 调优RPN,使用第2步R-FCN的卷积层参数初始化训练RPN网络的卷积层,然后固定卷积层,finetune RPN网络的剩余层,生成新的更精确的Region proposals
- 4 调优R-FCN,与第3步共享卷积层(即都是使用第2步训练好的),固定卷积层,finetune 剩余的RoI以上的层
- 这一步用到的 Region proposals 由第3步生成
[1] https://blog.csdn.net/zijin0802034/article/details/77685438
[2] https://www.researchgate.net/figure/Bounding-box-regression-15_fig4_339245946
[3] https://www.bilibili.com/video/av65889220
[4] https://blog.csdn.net/u011534057/article/details/51219959
[5] https://blog.csdn.net/qqliuzihan/article/details/81217766
[6] https://blog.csdn.net/u014365862/article/details/77887230
[7] https://blog.csdn.net/liulina603/article/details/79496553
[8] https://www.cnblogs.com/wangyong/p/8513563.html
[9] https://towardsdatascience.com/deep-learning-for-object-detection-a-comprehensive-review-73930816d8d9
[10] 理解全连接层与GAP csdn
[11] CNN 入门讲解:什么是全连接层(Fully Connected Layer)? zhihu
[12] R-FCN算法及Caffe代码详解 csdn
[13] 详解R-FCN zhihu
[14] object detection[rfcn] cnblogs
[15] R-FCN论文阅读(R-FCN: Object Detection via Region-based Fully Convolutional Networks) cnblogs
[16] RFCN中说roi pooling会破坏空间信息? zhihu
[17] R-FCN目标检测模型原理 csdn
[18]【Deep Learning】R-FCN csdn

 浙公网安备 33010602011771号
浙公网安备 33010602011771号