
传统视觉处理方法笔记
1. 图像分割
传统的方法根据灰度、颜色、纹理、形状等特征划分。深度学习是基于语义划分。基于灰度值的两个基本特性,不连续性和相似性(区域内)。
使用场景有前景背景分割等。
1.1 阈值、边缘
阈值法
每个像素与阈值比较,分成大于阈值和小于阈值的两部分。阈值用大津(日本人)法寻找。在灰度统计直方图上找一个位置,这个位置满足,分成的两部分的方差最大。\(\omega_0(u_0-u_T)^2+\omega_1(u_1-u_T)^2\),\(u^T\)为总的期望, \(u_0\) 为第一部分的期望(加权平均),\(\omega_0\) 为第一部分像素的概率和。详细推导1
边缘在边缘上图像局部特征不连续。先确定图像中的边缘像素,这些像素构成边界。
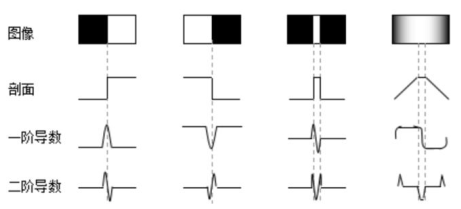
1.1.1 区域生长法
将像素或者子区域不断扩大并计算像素灰度均值
新的像素与平均值差的绝对值达到一定的阈值作为终止条件
分水岭 灰度图像求梯度图,然后进行分水岭,像水淹一样,保留梯度比较大的地方,即为边缘(分水岭),即完成算法。
1.1.2 图论(分割(目标检测))
Graph Cuts
(1) 每两个邻域顶点连接{p, q}, 第一类边
(2) 选定两个特定点(种子顶点),S、T. 每个点与这两个点相连{p, S}, {p, S}, {q, S}, {q, S}, 第二类边
(3) 寻找集合,集合中的所有边断开会导致 S、T分开
(4) 这个集合所有边的权值(参数)之和,就是最小的分割,即图像分割的结果
工具:能量算法 \(E(A)=\lambda\cdot R(A)+B(A)\), 目标为图的能量\(E(A)\)最小
\(R(A)=\sum\limits_{p\in\mathcal{P}}R_p(A_p)\) 刻画像素点属于目标或者背景的概率。
\(B(A)\) 第一类边,如果灰度值之差(\(I_p-I_q\))较小(相似),距离比较远(分成两个类), B很大,B的惩罚使 E(A) 大;如果灰度值之差较大(属于两个类),距离比较远(分成两个类),B趋向0, E(A) 小.
Grab Cut
在目标外画一个框,把目标框住. (框怎么选?),如果用户能手动选择或者画框,效果更好,(人为标注)。相当于框外是背景,框内是前景。两组点通过两个不同参数的高斯分布随机生成,而不是用一个高斯分布去描述能够分成两类的点。其实就是聚类。于是直接用聚类的方法 k-means 去求解。k-means,初始中心可以是任意点(跟初始状态还是有点关系的)。k的数值是经验值,多尝试几个值。K的位置初始位置也是可以选几次,也可以找一些技巧比如找彼此距离最远的点。k-means聚类对图像分割不会一直选质心,已经被证明了是可以最终收敛。框外框内分别选好质心,进行聚类,框内的背景点也会被聚到框外的质心。是看每一个像素点聚类归到哪个中心,所以中间带孔的,孔内也是会归到背景的。做完 k-means 后再做 graphcut.
2 人脸检测
应用场景人脸识别(dlib库)包含人脸检测(haar级联)的过程。
Haar小波(波形上是小波,转换成图像就是特征模板) 特征模板内有白色和黑色两种矩形,模板的特征值定义为白色矩形内的像素灰度值的和减去黑色矩形内的像素的和。模板可以有很多种角度(15种),可以与图像的不同位置对应,尺度缩放也可以不同。
2.1 Haar-like 特征+级联分类器
Adaboost级联分类器是集成学习里boosting(提升)里的一种。级联分类器是传统机器学习方法,是传统机器学习的方法效果能跟深度学习方法相匹敌的方法。级联分类器是多个强分类器连接在一起进行操作。强分类器是由若干个弱分类机器加权组成。
比如人脸,弱分类器只要求成功率稍高于50%区分人脸和非人脸.
基于 haar 模板的级联分类器计算比较快。Haar 模板有简单计算方法。
3 行人检测
梯度 \(\nabla f(x,y)\left[G_x\,G_y\right]^T=\left[{\partial f \over \partial x}\, {\partial f \over \partial y}\right]^T\)
\(G_x\) 是沿 \(x\) 方向上的梯度。梯度幅值(像素变化迅速程度) \(\mid \nabla f(x,y)\mid =mag(\nabla f(x,y))=\sqrt{G_x^2+G_y^2}\), 方向角(左黑右白,或者沿某一角度\(\phi\)的黑白分割) \(\phi(x,y)=\arctan\left({G_y\over G_x}\right)\)
离散微分模板梯度计算 \(G_x(x,y)=H(x+1,y)-H(x-1,y)\)(当前位置为中间点,左边与右边像素灰度相减), \(G_y(x,y)=H(x,y+1)-H(x,y-1)\)
3.1 HOG(方向梯度直方图)+SVM(支持向量机)
分别计算水平、垂直梯度。梯度幅值 \(\mid \nabla f(x,y)\mid\), 方向\(\phi\)。无平滑。对于彩色图,选取梯度幅值最大的通道。
(1) 与SIFT、SURF类似先分块 Block。先分块(\(16\times 16\)), 块内分4个Cell,每个Cell \(8\times 8\),这样可以减少光照差异性的影响(与CLAHE类似), 步长为一个Cell的宽度8,两个Block有一部分重叠,造成每个像素点为多个Block的直方图运算提供数据(与CLAHE类似)。
(2) 计算Cell的梯度方向直方图。具体方法:位置高斯加权平滑(损失一定的精确度和边缘的细节换取降低光线的影响的效果)。方向0-180度分成9(经验值,运算量与效果有协调最好)个统计bin。85度的解决方法(SIFT放在90度的直方图),这里使用插值方法(|85-70|)/20=3/4 放在70度直方图,(|85-90|)/20=1/4放在90度直方图。直方图累积的是梯度幅值。为了保证Block的颜色连续,使用另外一种插值方法参考CLAHE的像素插值方法;每个Cell的中心点是直方图的结果,基它点,考虑与Block中的四个中心点的相对位置,保证Block里颜色的过度更好来赋值。
(3) 得到描述图像特征的向量
64X128的图像,得到 7x15=105块,105x(2x2)x9 = 3780维向量。向量元素是什么?
(4) 减少光照影响。在块范围内,做对比度归一化问题。
(5) 前面是特征提取。高维分类使用 SVM。深度学习不需要那么多特征提取,直接就是算法,深度学习是逐层提取特征。
SVM 是将两类点分开。两个条件:找一条超平面(\(w\cdot x +b =0\))分开;边界超平面上的点之间的距离(\({2\over \parallel w\parallel}\))最大, 即\(\min\limits_{w,b} {1\over 2} {\parallel w\parallel}^2\)。边界超平面上的点为支持向量。约束条件为:\(y_i(w\cdot x_i+b)\geq 1\)。 \(y_i\)是属于哪一类的标签。
SVM对于 outlier 的问题,有的样本点落在对方的区域。加上Outlier 样本点到己方边界的距离 \(C\Sigma_i \xi_i\),允许有少量的Outlier 的样本存在。
SVM 映射到高维空间,解决低维线性不可分的问题。高维线性可分。
3.2 DPM(Deformable Part Model可变形的组件模型)
深度学习逐层提取特征。DPM也是逐层提取特征。
(1) 根滤波器,用来看整体形状。\(R_{x_0, l_0}(x_0,y_0)\), 比如人的整体轮廓
(2) 组件滤波(高分辨率(提高分辨率:上采样后,高斯平滑)),比如人脸的各部分是不是在合理的位置上。最小化一个目标函数,设置不合理的位置出现的Cost 比较大。\(\Sigma_{i=1}^n \{D_{i,l_0-\lambda}(2(x_0,y_0)+v_i)+b\}\)
\(score(x_0,y_0,l_0)=R_{x_0, l_0}(x_0,y_0)+\Sigma_{i=1}^n \{D_{i,l_0-\lambda}(2(x_0,y_0)+v_i)+b\}\)

使用 Latent SVM进行分类
其它
人脸可以用 dlib 效果比较好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号