网页中Office和pdf相关文件导出
最近被派去维护和开发一些做了一半、年久失修的项目。有一部分内容是关于word文件导出,顺带着把excel、pdf文件的导出也调研下吧,我想未来开发我应该会遇到的,遂做了下笔记分享给需要的人。
由于项目年久失修,所以你可能已经猜到了。是的,本文章基于JQuery以及JQuery相关的插件进行开发实践,如果后面空下来有时间我会进一步出Vue、Angular、React相关的例子。阅读本篇文章你将获得:
- JQuery插件的封装
- 基于JQuery插件WordExport及其衍生插件的使用
- 基于JQuery插件tableExport及其衍生插件的使用
- 一种直奔源码解决问题的处事思想
- 导出相关文件中文乱码的解决方法
- 导出相关图片不全的解决方法
- 媒体查询打印也不失为一种好的选择
emmm,本文关于表格的导出,绝大部分是基于table这个元素得到的。
word相关导出
依赖
- Jquery.js
- FileSaver.js
- jquery.wordexport.js
核心代码
$(document).ready(function ($) {
$('.word-export').click(function (event) {
$('#page-content').wordExport('警情研判');
});
});
这里就是给.word-export这个类绑定一个点击事件,然后其执行的内容是调用wordExport方法导出word。
需求是实现一张形如楼下的网页导出

起初看到这样一个页面,我内心是拒绝用table布局的,其一是之前学前端看到一些前端说table元素布局的一些弊端,比如占更多字节、下载就会延迟、阻塞浏览器渲染、影响内部元素布局、不利于搜索引擎爬取等等, 其二是我对table不是特别熟悉。所以一开始看到楼上的效果,我是喜欢用grid网格布局或者flex弹性布局来实现的。所以,就先用弹性布局出一版吧。
先说下思路吧,左侧那个表格类别和辖区我一开始是觉得用canvas绘图比较合适,表格整体用flex布局实现,其他同类项用flex:1进行均分,flex:1是flex-grow、flex-shrink和flex-basis的简写,具体的可以看下阮老师写的flex布局http://www.ruanyifeng.com/blog/2015/07/flex-grammar.html。然后你会遇到表格间距不一样的问题,我是这么解决的,每次我只画表格最小单元的左边框和上边框,那么到最后它是不是就剩下最大的那个表格的右边框和下边框,这样子就解决了。大致的思路是这样子了,实现的效果如下:
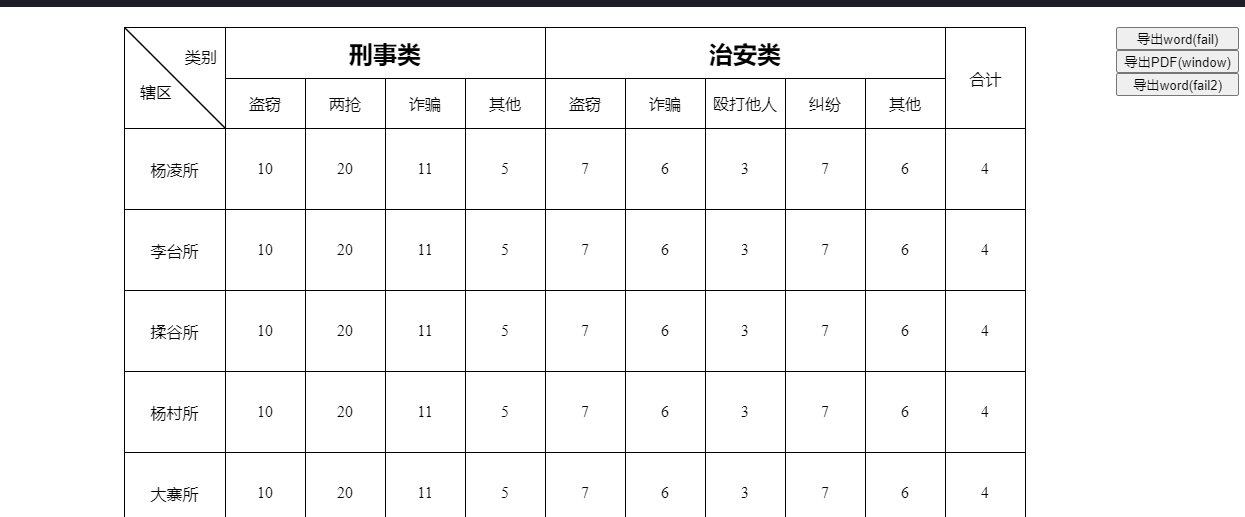
但是这个实现导出的结果有些不尽如人意,其一因为导出的是word,格式问题在所难免。其二是回到我们最初的依赖,这里是依赖于jquery.wordexport.js这个导出word的插件,所以发现预期与理想不符,我们就需要区阅读源码来找到答案。
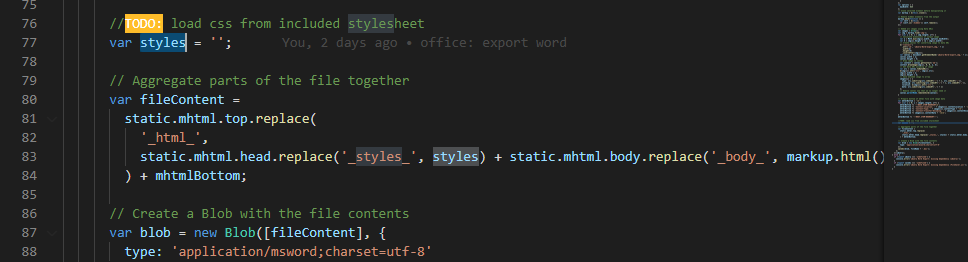
嗯,看到76行Todo那里开始往下看,我们找到了原因。
导出的结果这里就补贴了,不堪入目,有兴趣可以看下这个项目的demo地址如下:https://codepen.io/ataola/pen/xxONVQv
既然,用flex布局达不到预期,那么grid布局也没有必要去试了。那要不卑微码农屈服下吧,去学下table元素的表格布局。
这次我们同样实现了楼上的效果,略微有点不同的是,我这里没再用canvas实现左上角的效果,而是用position绝对定位和transform的rotate属性去实现。这次稍微有点word的样子,没有糊哒哒的一坨了。

但是这个效果显然是不理想的,咦,边框404了。
这个版本的项目地址是:https://codepen.io/ataola/pen/eYzaxZy
我们先思考下,看了之前的源码,再看了我这个的源码,我突然有个不成熟的想法。之前我是用加载相关css,然后用类或者id选择器去控制其样式,要不简单粗暴一点,直接style一把梭,好,那我们就试试吧。
最后,我得到了我想要的效果,虽然也还是有点瑕疵,毕竟word嘛,追求格式的完美,不容易变形、请使用pdf,哈哈。
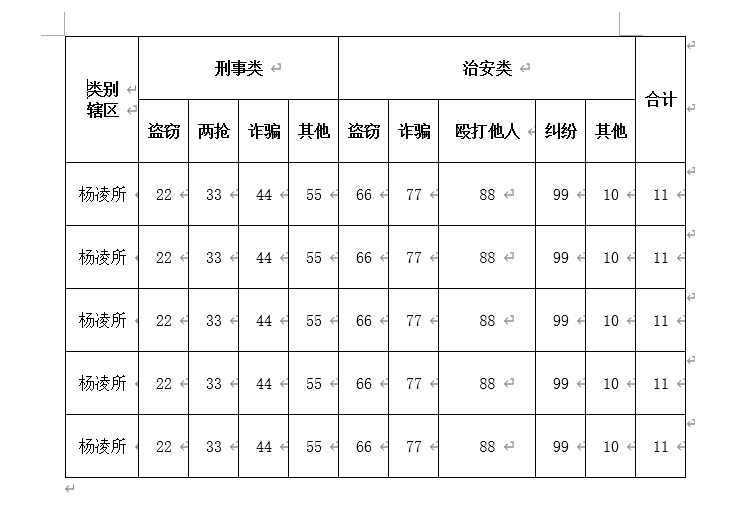
这个的demo地址:https://codepen.io/ataola/pen/vYKwPZx
以上是我抽离出表格模块,单独阉割出来的版本。比较综合的一个版本,请访问这个地址:http://zhengjiangtao.cn/show/office/export-word.html
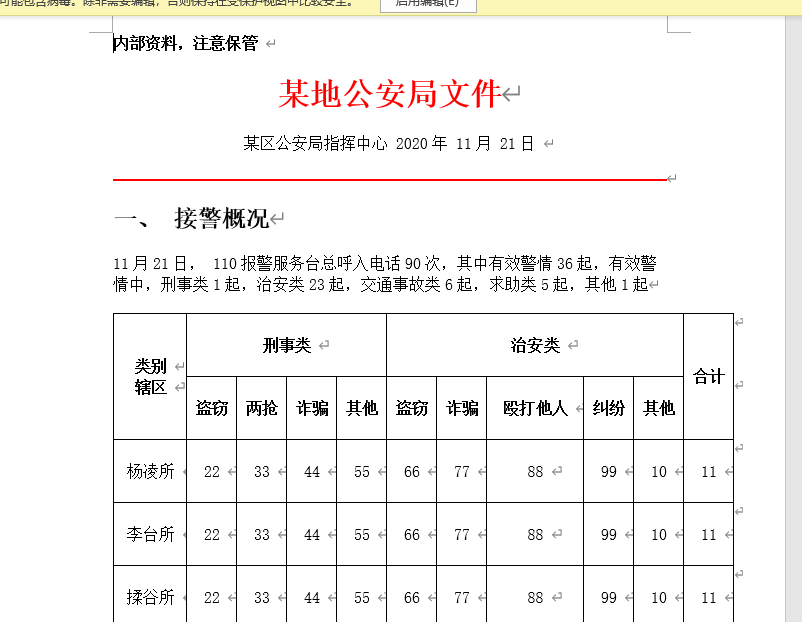
excel相关导出
做完楼上这个模块,总感觉意犹未尽,比如表格我很容易联想到excel、格式不易变形我很容易联想到pdf,要不再往下走走。
我们要实现这样一个效果,可以导出xls、xlsx、csv、xml、txt、json、sql文件格式的功能,这里我分别准备了三个测试用例,复杂表格、中文表格、英文表格,如下:
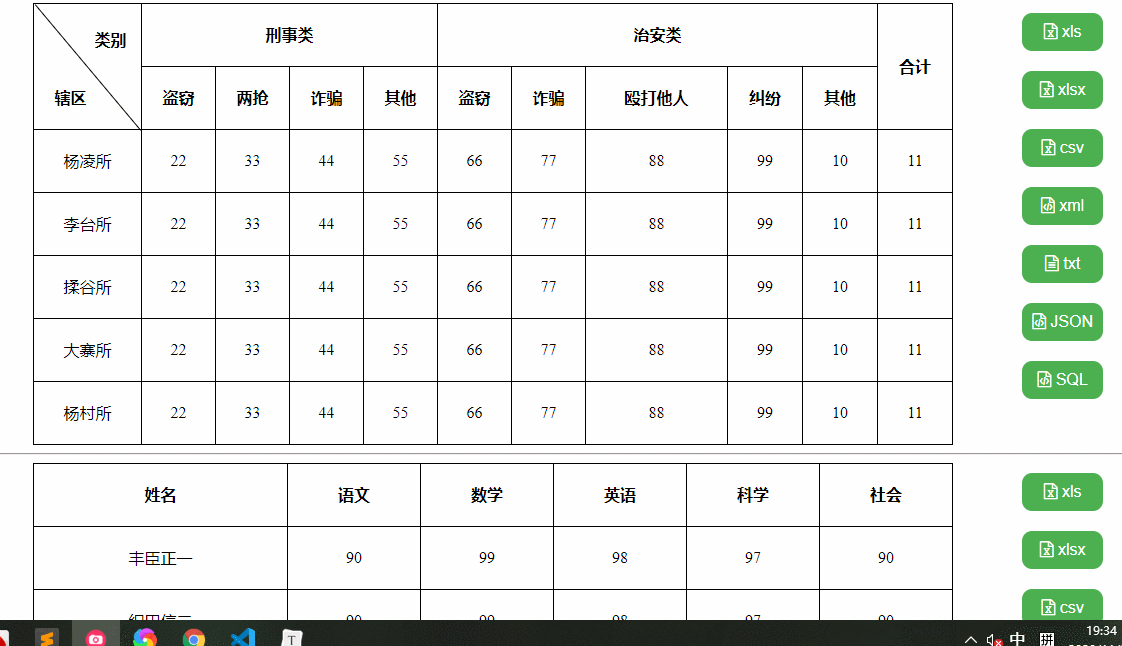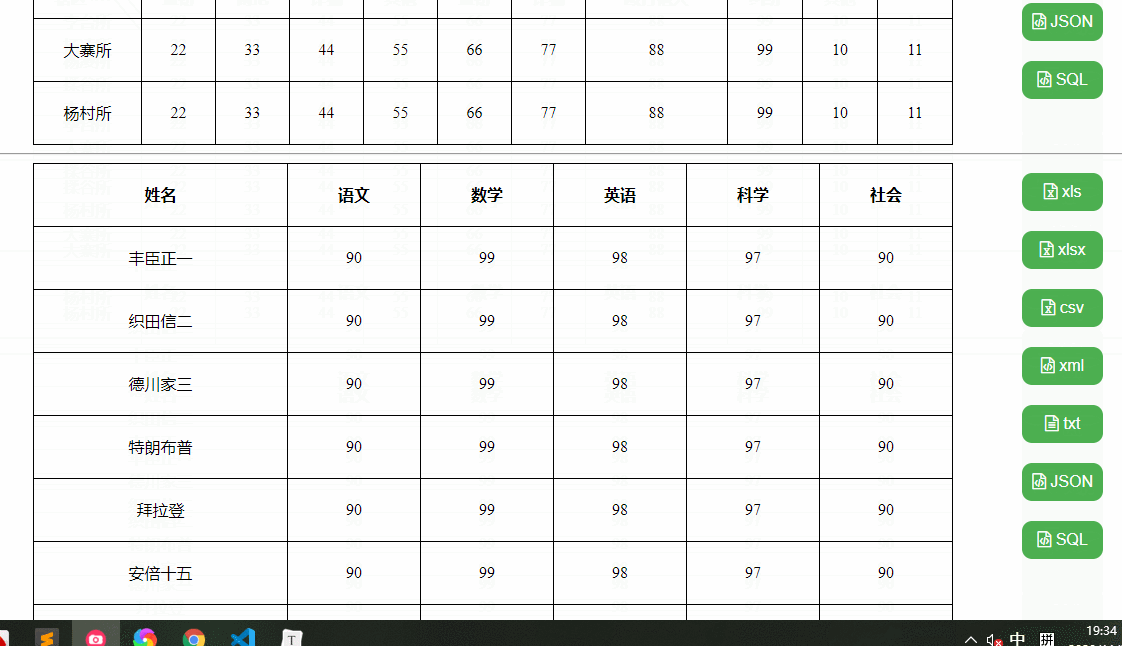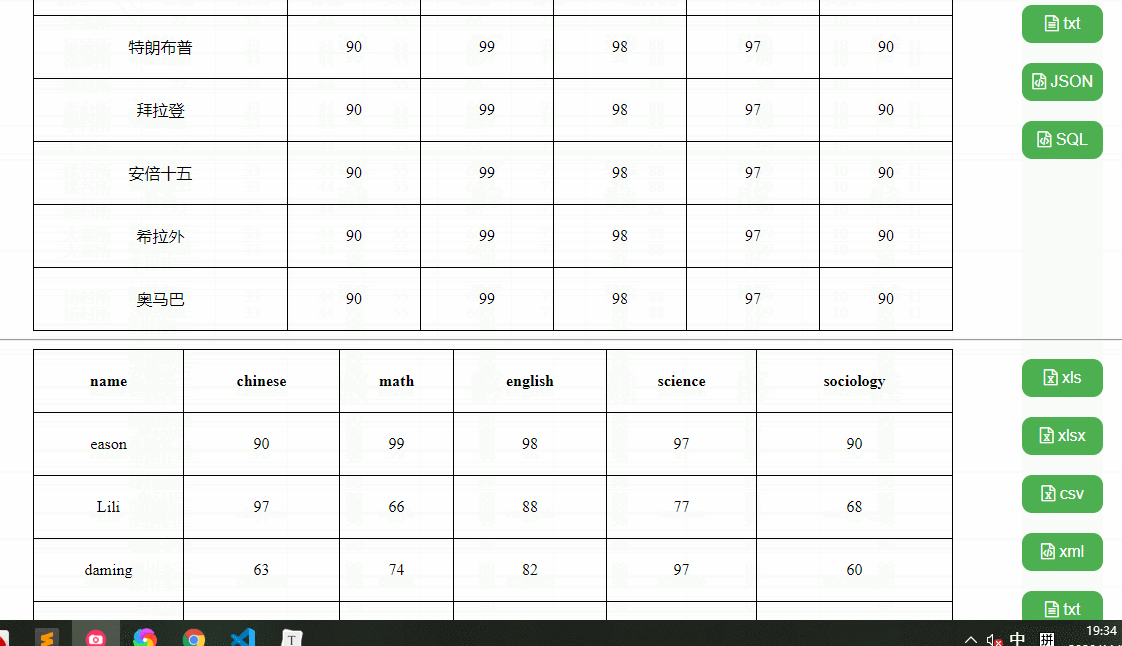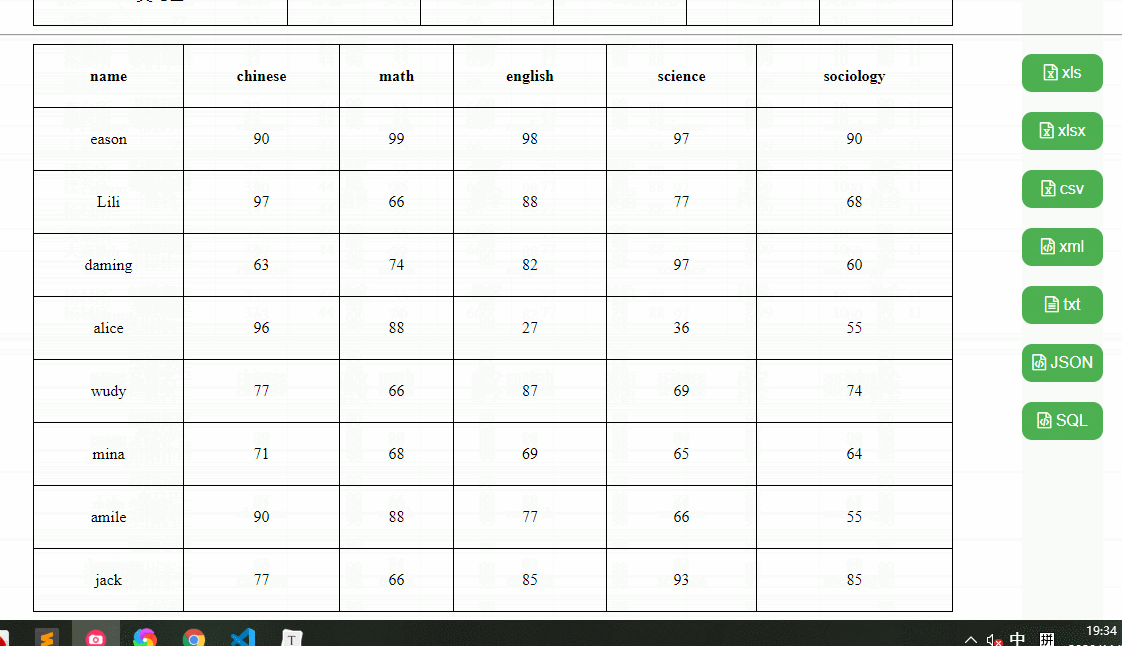
依赖
- jquery.js
- FileSaver.js
- xlsx.js(非必须,导出xlsx格式需要)
- tableExport.js(依赖Jquery)
核心代码
$(document).ready(function () {
$('#exportExcelOneXls').click(function () {
$('#table').tableExport({ type: 'excel', fileName: '警情研判', tableName: 'myTableName' });
});
$('#exportExcelOneXlsx').click(function () {
$('#table').tableExport({ type: 'xlsx', fileName: '警情研判', tableName: 'myTableName' });
});
$('#exportExcelOneCsv').click(function () {
$('#table').tableExport({ type: 'csv', fileName: '警情研判' });
});
$('#exportExcelOneXml').click(function () {
$('#table').tableExport({
type: 'xml',
fileName: '警情研判',
mso: { fileFormat: 'xmlss', worksheetName: ['杨凌区每日警情统计'] }
});
});
$('#exportExcelOneTxt').click(function () {
$('#table').tableExport({ type: 'txt', fileName: '警情研判' });
});
$('#exportExcelOneJson').click(function () {
$('#table').tableExport({ type: 'json', fileName: '警情研判' });
});
$('#exportExcelOneSql').click(function () {
$('#table').tableExport({ type: 'sql', fileName: '警情研判' });
});
});
大致就是给相应的按钮绑定相应的点击事件,然后调用tableExport去下载相应文件格式的文件。
项目地址如下:http://zhengjiangtao.cn/show/office/export-excel.html
踩坑
这里大致遇到这么些问题,我这里进行总结下,解决问题的思路,大致都指向一点,那就是看源码、改源码。
- 导出csv乱码
源码252行: if (defaults.type === 'csv' || defaults.type === 'tsv' || defaults.type === 'txt')
先找到触发下载csv文件指向的相关逻辑
源码325行-332行
saveToFile(
csvData,
defaults.fileName + '.' + defaults.type,
'text/' + (defaults.type === 'csv' ? 'csv' : 'plain'),
'utf-8',
'',
defaults.type === 'csv' && defaults.csvUseBOM
);
嗯,程序调用了saveToFile这个函数,如果你和我一样用VSCode开发的话,按住CTRL+鼠标左键进入函数相关实现,
2443行,找到了,给它来个特写
function saveToFile(data, fileName, type, charset, encoding, bom) {
var saveIt = true;
if (typeof defaults.onBeforeSaveToFile === 'function') {
saveIt = defaults.onBeforeSaveToFile(data, fileName, type, charset, encoding);
if (typeof saveIt !== 'boolean') saveIt = true;
}
if (saveIt) {
try {
blob = new Blob([data], { type: type + ';charset=' + charset });
saveAs(blob, fileName, bom === false);
if (typeof defaults.onAfterSaveToFile === 'function') defaults.onAfterSaveToFile(data, fileName);
} catch (e) {
downloadFile(
fileName,
'data:' +
type +
(charset.length ? ';charset=' + charset : '') +
(encoding.length ? ';' + encoding : '') +
',',
bom ? '\ufeff' + data : data
);
}
}
}
blob = new Blob([data], { type: type + ';charset=' + charset });这行,应该是其转换成二进制时编码出了问题, 修改下
if (defaults.type === 'csv') {
blob = new Blob([(defaults.type == 'csv' && defaults.csvUseBOM ? '\ufeff' : '') + csvData], {
type: 'text/' + (defaults.type == 'csv' ? 'csv' : 'plain') + ';charset=utf-8'
});
} else {
blob = new Blob([data], { type: type + ';charset=' + charset });
}
这里是因为笔者试过,用txt打开csv,然后将其编码改成带BOM的UTF8可以显示中文,所以这么改。
注意这里的逻辑,我并没有把作者原来的那句话干掉,而是判断了csv格式的情况,这样是比较严谨的,因为作者这样写自然有其道理,我们改源码的目的是为了实现我们需求的功能而不是干掉原来的,因为有可能引发其他问题的,年轻人要讲码德,耗子尾汁,哈哈哈。
备注:由于我用了prettier进行相关的格式化,所以这里的代码行数仅作参考
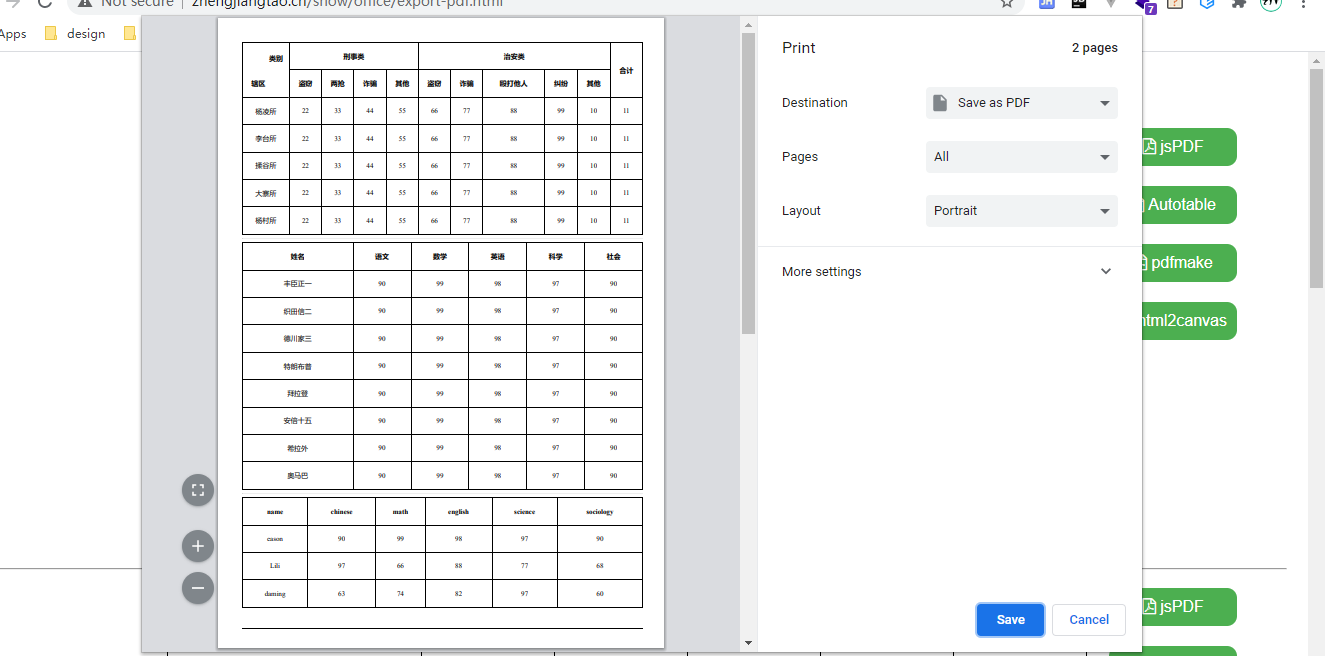
pdf相关导出
因为tableExport这个插件,如果有JsPDF、jsPDF-Autoable、pdfmake的加持的话,它可以实现pdf文件的导出,这里我们实践下吧。
需求是实现一张形如楼下的网页导出:
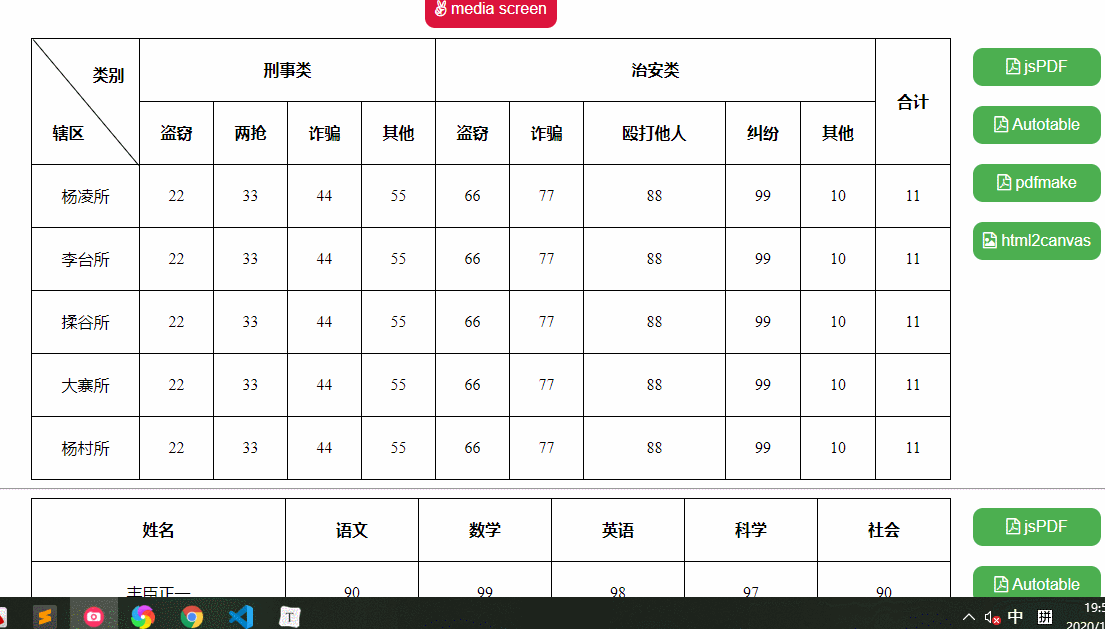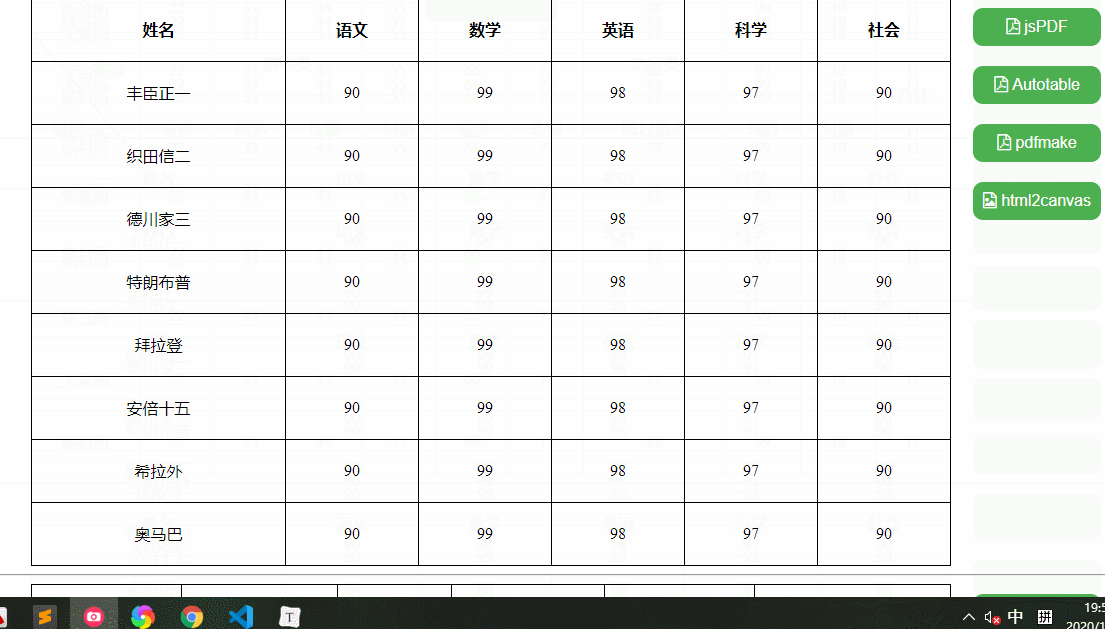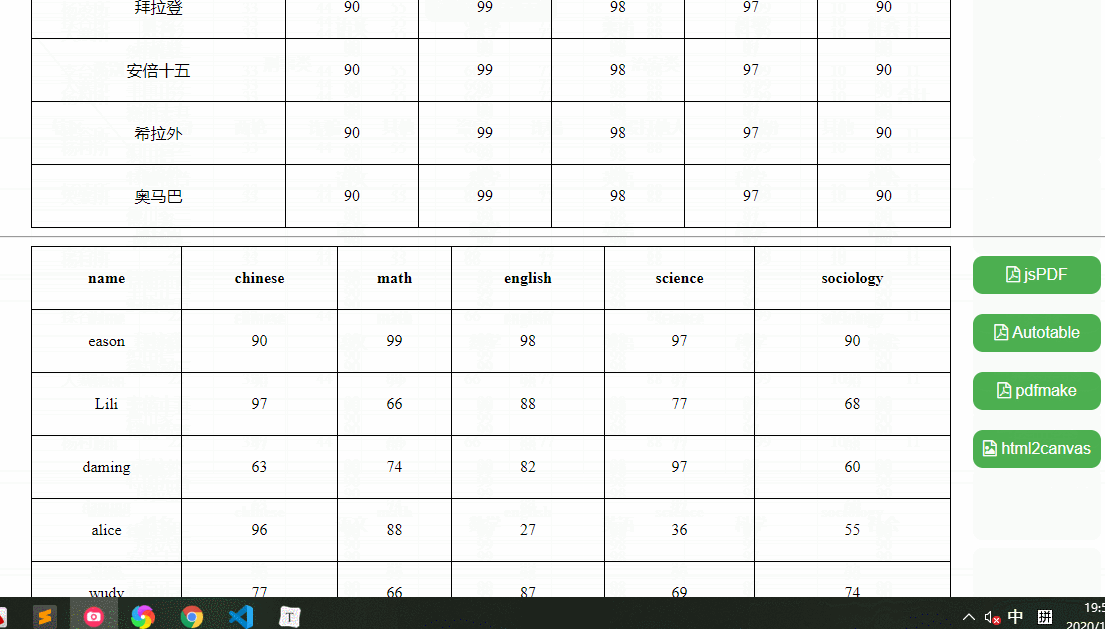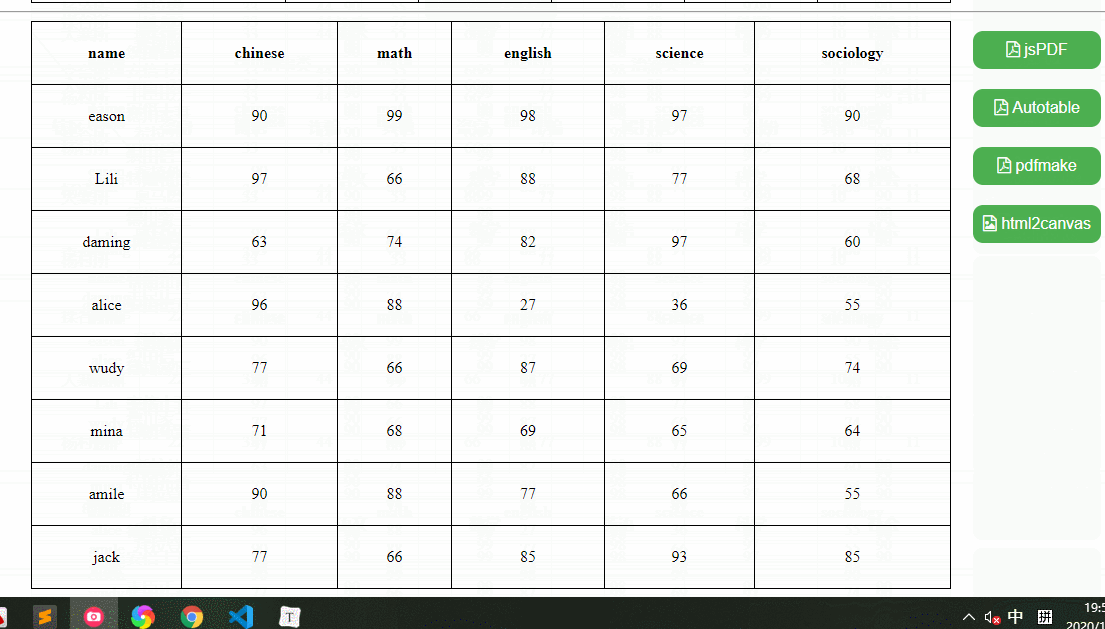
依赖
- jquery.js
- FileSaver.js
- jsPdf.js
- jsPDF.Autoable.js
- pdfmake.js
- tableExport.js
核心代码
$(document).ready(function () {
$('#exportPdfOneJs').click(function () {
$('#table').tableExport({
type: 'pdf',
fileName: '警情研判',
jspdf: {
orientation: 'p',
margins: { right: 20, left: 20, top: 30, bottom: 30 },
autotable: { styles: { fillColor: 'inherit', textColor: 'inherit', fontStyle: 'inherit' }, tableWidth: 'wrap' }
}
});
});
$('#exportPdfOneAutotable').click(function () {
$('#table').tableExport({
type: 'pdf',
fileName: '警情研判',
jspdf: {
orientation: 'l',
format: 'a3',
margins: { left: 10, right: 10, top: 20, bottom: 20 },
autotable: { styles: { fillColor: 'inherit', textColor: 'inherit' }, tableWidth: 'auto' }
}
});
});
$('#exportPdfOnePdfMake').click(function () {
$('#table').tableExport({
type: 'pdf',
fileName: '警情研判',
pdfmake: { enabled: true, docDefinition: { pageOrientation: 'landscape' } }
});
});
});
逻辑同楼上,分别用了三种插件实现了三种导出,其中前两种对中文支持不友好,第三章pdfmake加上相关字体文件的加持,可以导出可以看的中文版。
项目地址如下:http://zhengjiangtao.cn/show/office/export-pdf.html
踩坑
- pdfmake导出中文乱码显示 “口”
源码112行-121行
pdfmake: {
enabled: false, // true: Use pdfmake as pdf producer instead of jspdf and jspdf-autotable
docDefinition: {
pageOrientation: 'portrait', // 'portrait' or 'landscape'
defaultStyle: {
font: 'ZCOOLXiaoWei' // Default font is 'Roboto' (needs vfs_fonts.js to be included)
} // For an arabic font include mirza_fonts.js instead of vfs_fonts.js
}, // For a chinese font include either gbsn00lp_fonts.js or ZCOOLXiaoWei_fonts.js instead of vfs_fonts.js
fonts: {}
},
之前defaultStyle是Roboto是不支持中文的,好在作者写了注释,我们把它替换成站酷的字体ZCOOLXiaoWei,好了,这下子导出正常了。
emmm,讲道理就实践来看,浏览器打印出来的pdf是最稳的,所以这里我有个不成熟的想法,就是利用媒体查询加上window自带的打印去实现这个功能。
核心代码如下:
@media print {
.media-screen, .export-pdf-operate {
display: none;
}
#tableBox {
width: 920px;
margin: 0 auto;
}
}
打印时利用媒体查询隐藏掉不相关的元素,然后利用window.print()函数去打印相关的内容。
图片相关导出
依赖
- jquery.js
- html2canavs.js
- tableexport.js
核心代码
$('#exportPdfTwoHtmlTwoCanvas').click(function () {
$('#tableTwo').tableExport({
type: 'png',
fileName: '初三二班成绩排名'
});
});
逻辑同楼上。
踩坑
- html2canvas截图不全
通过查阅相关文献,我知道了,原因大概就是可能没有加载完全就开始截图了,然后位置不对。既然是这样,那大概是两种思路,第一种,加延迟(治标不治本,万一文件很大凉凉), 第二种,重置截图位置(友好一点,截图完给它复原下)
我们双管齐下,翻到源码913行
setTimeout(() => {
const pageYOffset = window.pageYOffset;
window.pageYOffset = 0;
const htmlScrollTop = document.documentElement.scrollTop;
document.documentElement.scrollTop = 0;
const bodyScrollTop = document.body.scrollTop;
document.body.scrollTop = 0;
html2canvas($(el)[0]).then(function (canvas) {
var image = canvas.toDataURL();
var byteString = atob(image.substring(22)); // remove data stuff
var buffer = new ArrayBuffer(byteString.length);
var intArray = new Uint8Array(buffer);
for (var i = 0; i < byteString.length; i++) intArray[i] = byteString.charCodeAt(i);
if (defaults.outputMode === 'string') return byteString;
if (defaults.outputMode === 'base64') return base64encode(image);
if (defaults.outputMode === 'window') {
window.open(image);
return;
}
saveToFile(buffer, defaults.fileName + '.png', 'image/png', '', '', false);
window.pageYOffset = pageYOffset;
document.documentElement.scrollTop = htmlScrollTop;
document.body.scrollTop = bodyScrollTop;
});
}, 5000);
大致是这样子的,加了5秒延迟,然后截图是置scrollTop、pageYOffset为0,然后截图完给它复现会去。
地址如下:http://zhengjiangtao.cn/show/office/export-pdf.html
JQuery插件的封装
看完楼上这些,我大致也知道怎么封装一个JQuery插件了,这里分享下思路
大致是搞了一个自执行函数,然后$.fn后面跟一个插件函数的实现,用$.extend去实现参数的继承。这里我们实现的一个函数效果是打印出该元素除了函数以外的style属性。
代码如下:
/*
* @Author: ataola
* @Date: 2020-11-22 17:08:19
* @Last Modified by: ataola
* @Last Modified time: 2020-11-22 18:21:45
*/
'use strict';
(function ($) {
$.fn.printStyle = function (options) {
console.log('function printStyle start ========>');
const el = this;
const defaults = {
color: 'red'
};
$.extend(true, defaults, options);
const style = $(el).get(0).style;
const div = document.createElement('div');
for (const attr in style) {
const val = getStyle($(el).get(0), attr);
if (!(val instanceof Function)) {
const res = `${attr}: ${val}`;
div.innerHTML = div.innerHTML + res + '<br/>';
console.log(res);
}
}
div.style.color = defaults.color;
document.body.appendChild(div);
console.log('function printStyle end <========');
};
function getStyle(obj, attr) {
if (obj.currentStyle) {
return obj.currentStyle[attr];
} else {
return getComputedStyle(obj, false)[attr];
}
}
})(jQuery);
效果如下:
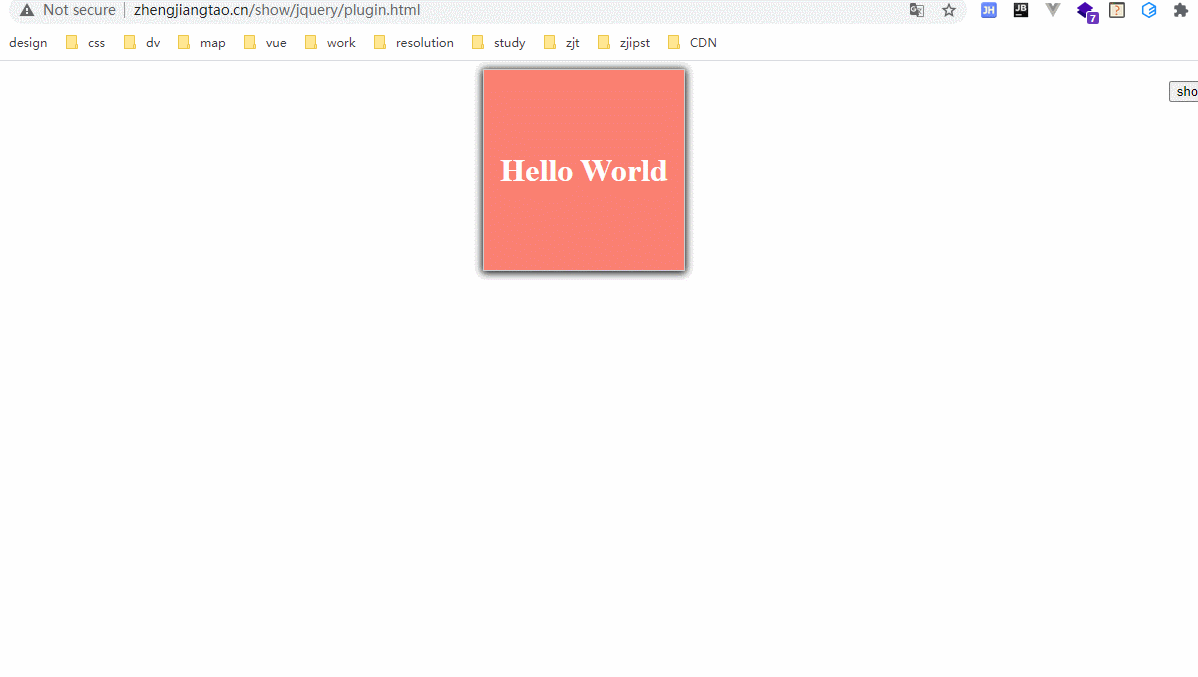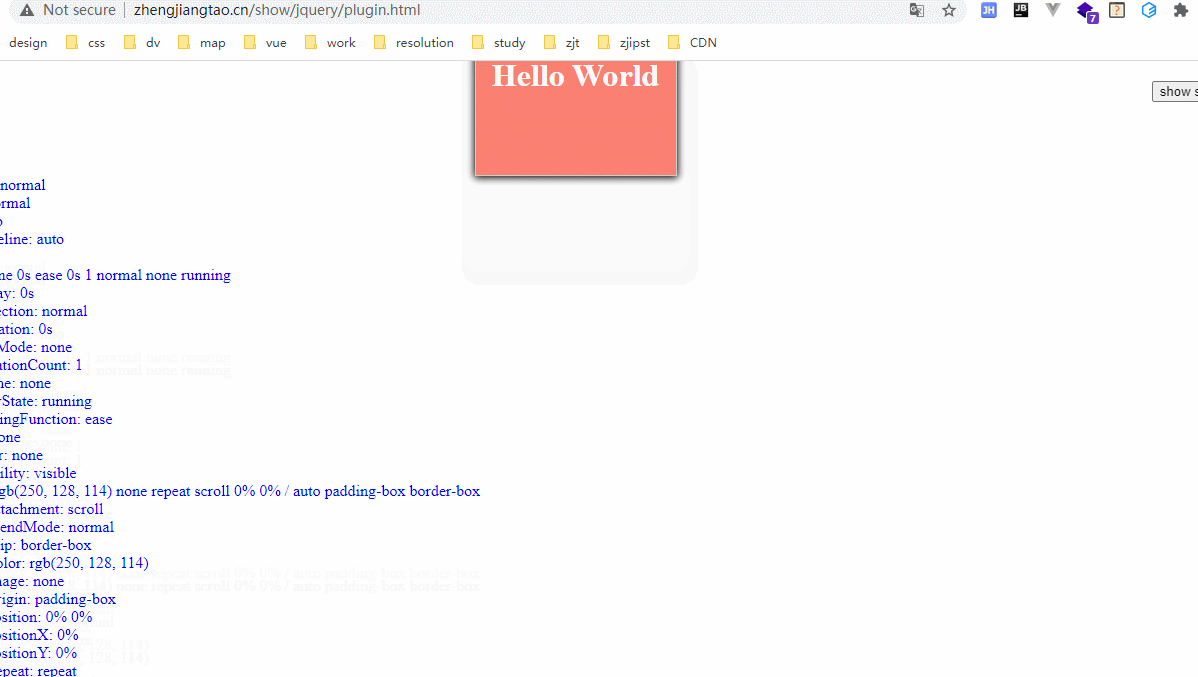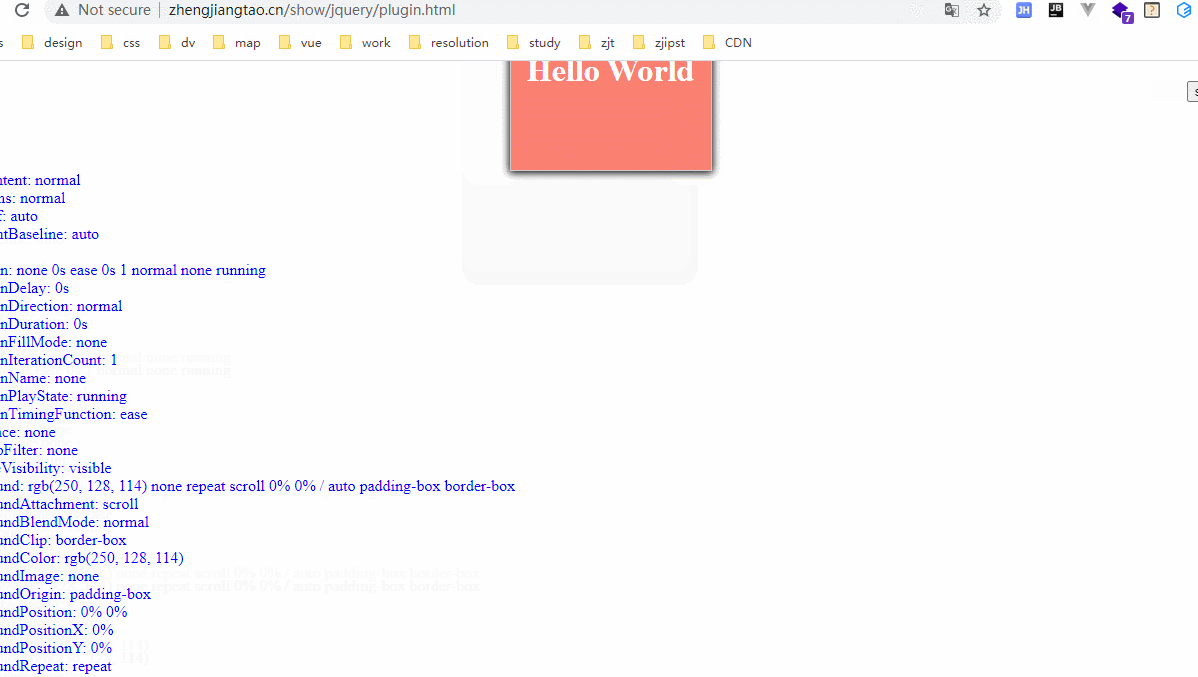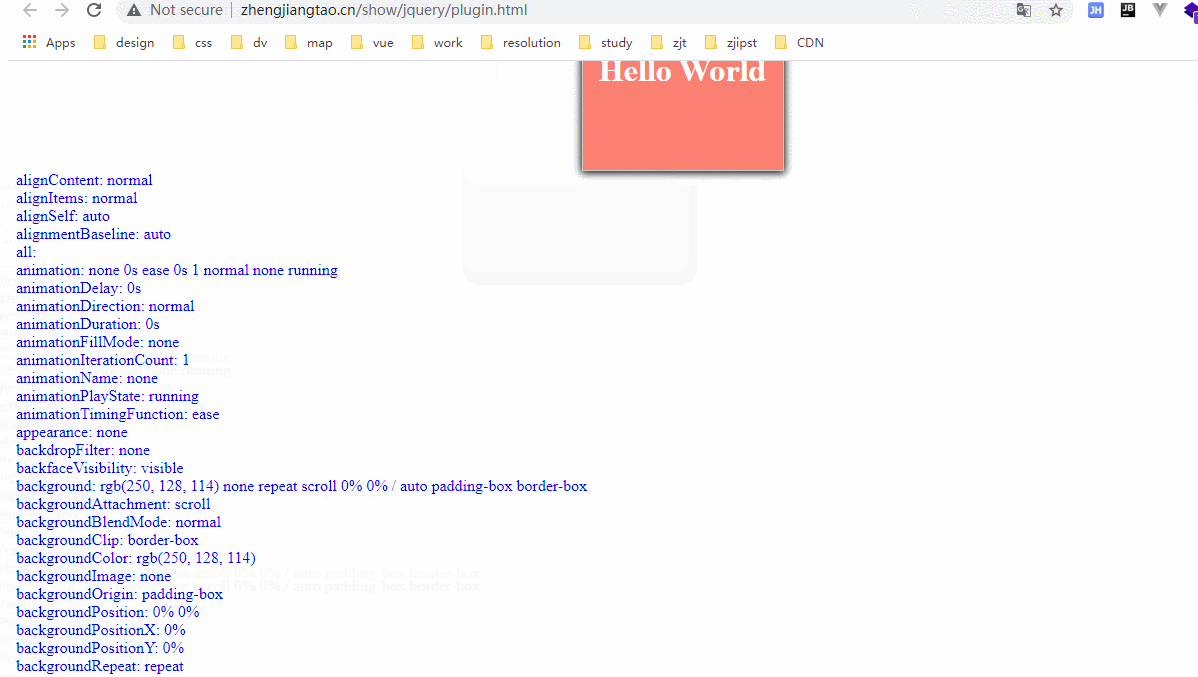
地址如下:http://zhengjiangtao.cn/show/jquery/plugin.html
看到这里,再回到之前word的那个例子,你大概就能明白实现word高度还原,其实是挺复杂的。。。。。。
因为好像没有API让我们去获取选择器上所定义的相关css属性,而你直接写在元素的style上是直接可以读到的,style的权重(1000)也很高。
以上就是今天的全部内容,感谢阅读!
参考文献
FileSaver.js: https://github.com/eligrey/FileSaver.js
JQuery-Word-Export: https://github.com/markswindoll/jQuery-Word-Export
tableExport.jquery.plugin: https://github.com/hhurz/tableExport.jquery.plugin
pdfmake: https://github.com/bpampuch/pdfmake
html2canvas: https://github.com/niklasvh/html2canvas
html2canvas截图不全: https://www.jianshu.com/p/88f07d5c5c70


 浙公网安备 33010602011771号
浙公网安备 33010602011771号