ClickHouse入门:表引擎-HDFS
前言
插件及服务器版本
服务器:ubuntu 16.04
Hadoop:2.6
ClickHouse:20.9.3.45
文章目录
-
- 简介
- 引擎配置
- HDFS表引擎的两种使用形式
- 引用
简介
ClickHouse的HDFS引擎可以对接hdfs,这里假设HDFS环境已经配置完成,本文测试使用的HDFS版本为2.6
HDFS引擎定义方法如下:
ENGINE = HDFS(hdfs_uri,format)
参数定义:
- hdfs_uri表示HDFS的文件存储路径
- format表示文件格式(指ClickHouse支持的文件格式,常见有CSV、TSV和JSON等)
HDFS表引擎两种使用方式:
- 即负责读文件也负责写文件
- 只负责读文件,文件写入工作则由外部系统完成
引擎配置
-
由于hdfs配置了HA,如果不做配置,创建一张只负责读文件的表,并查询数据,会报如下错误:
Code: 210. DB::Exception: Received from localhost:9000. DB::Exception: Unable to connect to HDFS: InvalidParameter: Cannot parse URI: hdfs://mycluster, missing port or invalid HA configuration Caused by: HdfsConfigNotFound: Config key: dfs.ha.namenodes.mycluster not found.![在这里插入图片描述]()
-
需要做如下配置解决问题
1、拷贝hdfs-site.xml文件至/etc/clickhouse-server,并修改文件名为hdfs-client.xml![在这里插入图片描述]()
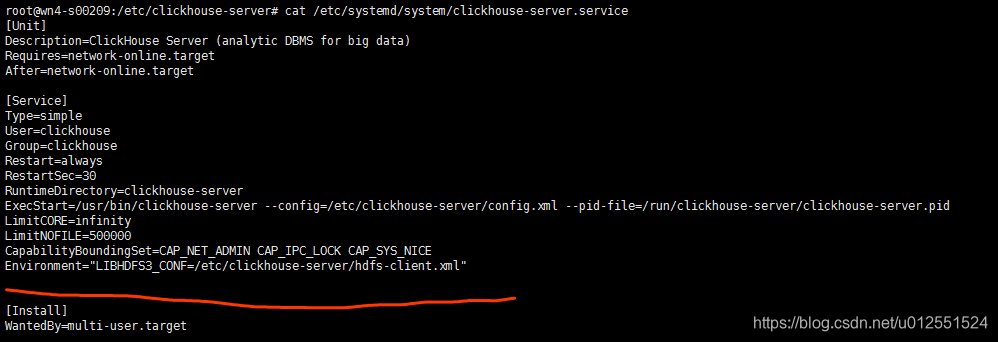
2、修改ClickHouse Server启动文件,添加环境变量Environment=“LIBHDFS3_CONF=/etc/clickhouse-server/hdfs-client.xml”
备注:
这里测试环境为ubuntu环境,启动服务用systemctl启动,所以修改启动文件的路径为:vi /etc/systemd/system/clickhouse-server.service![在这里插入图片描述]()
3、加载并重启clickhouse-serversystemctl daemon-reload systemctl restart clickhouse-server.service4、测试
新创建一张只读表,对应的hdfs上已经提前放了一个测试文件 1.txt![在这里插入图片描述]()
CREATE TABLE test_hdfs ( id Int32 ) ENGINE HDFS('hdfs://mycluster/1.txt','CSV');![在这里插入图片描述]()
查询表里的数据![在这里插入图片描述]()





HDFS表引擎的两种使用形式
-
即负责读文件,也负责写文件
-
创建一张新表
CREATE TABLE test_hdfs_read ( id Int32, name String ) ENGINE HDFS('hdfs://mycluster/test','CSV');![在这里插入图片描述]()
-
插入数据
insert into test_hdfs_read values (1,'tracy');![在这里插入图片描述]()
-
查询表数据并查看hdfs目录情况
![在这里插入图片描述]()
![在这里插入图片描述]()
这里可以看到hdfs目录下多了一个test文件
-
-
只负责读文件,文件写入工作则由外部系统完成
这种形式类似于hive的外挂表,由其它系统直接将文件直接写入HDFS,通过参数hdsfs_ui和format与HDFS的文件路径、文件格式建立映射,其中hdfs_uri支持以下几种常见的配置方法:
1. 绝对路径:会指定路径上的单个文件,例如hdfs://mycluster/1.txt
2. *通配符:匹配所有字符,例如hdfs://mycluster/ * ,会读取hdfs://mycluster/路径下的所有文件
3. ?通配符:匹配单个字符,例如hdfs://mycluster/test_?.txt会匹配所有test_?.txt的文件,?代表任意字符
4. {M…N}数字区间:匹配指定数字的文件,例如路径hdfs://mycluster/test_{1…3}.txt,则会读取hdfs://mycluster/路径下的文件test_1.txt,test_2.txt,test_3.txt-
在hdfs新建一个目录,并放3个文件
![在这里插入图片描述]()
-
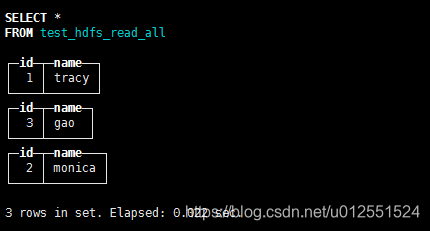
测试*通配符
CREATE TABLE test_hdfs_read_all ( `id` Int32, `name` String ) ENGINE = HDFS('hdfs://mycluster/test_hdfs_read/*', 'CSV')![在这里插入图片描述]()
-
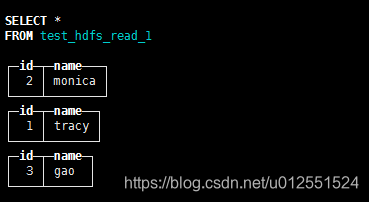
测试?通配符
CREATE TABLE test_hdfs_read_1 ( `id` Int32, `name` String ) ENGINE = HDFS('hdfs://mycluster/test_hdfs_read/test_?.csv', 'CSV')![在这里插入图片描述]()
-
测试数字区间通配符通配符
CREATE TABLE test_hdfs_read_2 ( `id` Int32, `name` String ) ENGINE = HDFS('hdfs://mycluster/test_hdfs_read/test_{2..3}.csv', 'CSV')![在这里插入图片描述]()
这里只匹配了test_2和test_3,所以只有两条记录
-






引用
https://github.com/ClickHouse/ClickHouse/issues/8159

 浙公网安备 33010602011771号
浙公网安备 33010602011771号