
druid安装部署
Druid安装部署
一、环境需求
Java 8 (8u92 +)
Linux, Mac OS X, or other Unix-like OS(不支持Windows系统)
Zookeeper (3.4 +)
Druid下载:
官网:https://druid.apache.org,进入官网后点击“Download”,进入下载界面,当前最新版本0.16,这里我们选择编译版本下载;
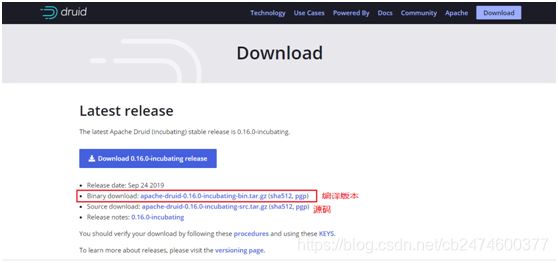
如果想下载历史版本,可以下拉,点击“Apache release archives “进入历史版本下载界面
二、单机版安装部署
1.将安装包上传到服务器,并解压安装包
tar -xzf apache-druid-0.16.0-incubating-bin.tar.gz -C /data
2.下载zookeeper安装包上传到服务器,并解压安装包到druid的根目录,并重名为zk
tar -xzf zookeeper-3.4.6.tar.gz -C /data/apache-druid-0.16.0-incubating
mv /data/apache-druid-0.16.0-incubating/zookeeper-3.4.6 /data /apache-druid-0.16.0-incubating/zk
3.进入druid的安装目录,执行单机启动脚本
cd /data/apache-druid-0.16.0-incubating
./bin/start-micro-quickstart
4.访问http://localhost:8888 查看druid管理界面

三、集群版安装部署
部署规划
|
角色 |
机器 |
集群角色(进程) |
|
主节点 |
hadoop1(192.168.252.111) |
Coordinator,Overlord |
|
数据节点 |
hadoop2(192.168.252.112) |
Historical, MiddleManager |
|
查询节点 |
hadoop3(192.168.252.113) |
Broker ,router |
外部依赖
|
组件 |
机器 |
描述 |
|
zookeeper |
hadoop1、hadoop2、hadoop3 |
提供分布式协调服务 |
|
hadoop |
hadoop1、hadoop2、hadoop3 |
提供数据文件存储库 |
|
mysql |
hadoop1 |
提供元数据存储库 |
注:外部依赖组件安装请查阅相关资料,这里默认外部依赖已安装成功并运行
1.将安装包上传到hadoop1服务器,并解压安装包,并进入该目录
tar -xzf apache-druid-0.16.0-incubating-bin.tar.gz -C /data
cd /data/apache-druid-0.16.0-incubating
2.修改核心配置文件,配置文件如下
vim conf/druid/cluster/_common/common.runtime.properties
-
#
-
# Licensed to the Apache Software Foundation (ASF) under one
-
# or more contributor license agreements. See the NOTICE file
-
# distributed with this work for additional information
-
# regarding copyright ownership. The ASF licenses this file
-
# to you under the Apache License, Version 2.0 (the
-
# "License"); you may not use this file except in compliance
-
# with the License. You may obtain a copy of the License at
-
#
-
# http://www.apache.org/licenses/LICENSE-2.0
-
#
-
# Unless required by applicable law or agreed to in writing,
-
# software distributed under the License is distributed on an
-
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-
# KIND, either express or implied. See the License for the
-
# specific language governing permissions and limitations
-
# under the License.
-
#
-
-
# Extensions specified in the load list will be loaded by Druid
-
# We are using local fs for deep storage - not recommended for production - use S3, HDFS, or NFS instead
-
# We are using local derby for the metadata store - not recommended for production - use MySQL or Postgres instead
-
-
# If you specify `druid.extensions.loadList=[]`, Druid won't load any extension from file system.
-
# If you don't specify `druid.extensions.loadList`, Druid will load all the extensions under root extension directory.
-
# More info: https://druid.apache.org/docs/latest/operations/including-extensions.html
-
druid.extensions.loadList=["mysql-metadata-storage","druid-hdfs-storage","druid-kafka-indexing-service"]
-
-
# If you have a different version of Hadoop, place your Hadoop client jar files in your hadoop-dependencies directory
-
# and uncomment the line below to point to your directory.
-
#druid.extensions.hadoopDependenciesDir=/my/dir/hadoop-dependencies
-
-
-
#
-
# Hostname
-
#
-
druid.host=localhost
-
-
#
-
# Logging
-
#
-
-
# Log all runtime properties on startup. Disable to avoid logging properties on startup:
-
druid.startup.logging.logProperties=true
-
-
#
-
# Zookeeper
-
#
-
-
druid.zk.service.host=hadoop1:2181,hadoop2:2181,hadoop3:2181
-
druid.zk.paths.base=/druid
-
-
#
-
# Metadata storage
-
#
-
-
# For Derby server on your Druid Coordinator (only viable in a cluster with a single Coordinator, no fail-over):
-
#druid.metadata.storage.type=derby
-
#druid.metadata.storage.connector.connectURI=jdbc:derby://localhost:1527/var/druid/metadata.db;create=true
-
#druid.metadata.storage.connector.host=localhost
-
#druid.metadata.storage.connector.port=1527
-
-
# For MySQL (make sure to include the MySQL JDBC driver on the classpath):
-
druid.metadata.storage.type=mysql
-
druid.metadata.storage.connector.connectURI=jdbc:mysql://hadoop1:3306/druid
-
druid.metadata.storage.connector.user=root
-
druid.metadata.storage.connector.password=123456
-
-
# For PostgreSQL:
-
#druid.metadata.storage.type=postgresql
-
#druid.metadata.storage.connector.connectURI=jdbc:postgresql://db.example.com:5432/druid
-
#druid.metadata.storage.connector.user=...
-
#druid.metadata.storage.connector.password=...
-
-
#
-
# Deep storage
-
#
-
-
# For local disk (only viable in a cluster if this is a network mount):
-
#druid.storage.type=local
-
#druid.storage.storageDirectory=var/druid/segments
-
-
# For HDFS:
-
druid.storage.type=hdfs
-
druid.storage.storageDirectory=hdfs://testcluster/druid/segments
-
-
# For S3:
-
#druid.storage.type=s3
-
#druid.storage.bucket=your-bucket
-
#druid.storage.baseKey=druid/segments
-
#druid.s3.accessKey=...
-
#druid.s3.secretKey=...
-
-
#
-
# Indexing service logs
-
#
-
-
# For local disk (only viable in a cluster if this is a network mount):
-
#druid.indexer.logs.type=file
-
#druid.indexer.logs.directory=var/druid/indexing-logs
-
-
# For HDFS:
-
druid.indexer.logs.type=hdfs
-
druid.indexer.logs.directory=hdfs://testcluster/druid/indexing-logs
-
-
# For S3:
-
#druid.indexer.logs.type=s3
-
#druid.indexer.logs.s3Bucket=your-bucket
-
#druid.indexer.logs.s3Prefix=druid/indexing-logs
-
-
#
-
# Service discovery
-
#
-
-
druid.selectors.indexing.serviceName=druid/overlord
-
druid.selectors.coordinator.serviceName=druid/coordinator
-
-
#
-
# Monitoring
-
#
-
-
druid.monitoring.monitors=["org.apache.druid.java.util.metrics.JvmMonitor"]
-
druid.emitter=noop
-
druid.emitter.logging.logLevel=info
-
-
# Storage type of double columns
-
# ommiting this will lead to index double as float at the storage layer
-
-
druid.indexing.doubleStorage=double
-
-
#
-
# Security
-
#
-
druid.server.hiddenProperties=["druid.s3.accessKey","druid.s3.secretKey","druid.metadata.storage.connector.password"]
-
-
-
#
-
# SQL
-
#
-
druid.sql.enable=true
-
-
#
-
# Lookups
-
#
-
druid.lookup.enableLookupSyncOnStartup=false
重点关注红色部分,其中druid.extensions.loadList为需要加载的外部组件配置,示例中依赖外部组件zookeeper、hadoop、mysql。(kafka依赖配置可选)
zookeeper默认配置支持zookeeper3.4.14,如何外部依赖zookeeper版本不兼容,则需要将相关的zookeeper jar拷贝到druid的lib目录下替换原zookeeper相关jar
hadoop 默认配置支持hadoop 2.8.3客户端,该处需要将外部依赖中hadoop的核心配置文件core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml拷贝到druid中的conf/druid/cluster/_common/目录下,如果该hadoop客户端不兼容组件中的hadoop集群,还需要将集群兼容的hadoop客户端相关jar拷贝到druid中的extensions/druid-hdfs-storage目录下替换原来相关jar
mysql 没有默认支持,需要将相关版本的mysql的驱动jar拷贝到extensions/mysql-metadata-storage目录下
3.将druid整个目录发送到hadoop2和hadoop3机器中
4.根据需要(机器配置、性能要求等)修改hadoop1中关于master节点相关配置,在Druid中的conf\druid\cluster\master\coordinator-overlord目录下,其中runtime.properties为druid想的属性配置,jvm.config为该节点进程的jvm参数配置,默认的集群版本的jvm配置均比较高,如果用于学习测试机器配置不够用情况下,可以将单机版的配置拷贝过来,单机版配置目录conf\druid\single-server\micro-quickstart\coordinator-overlord
5.根据需要(机器配置、性能要求等)修改hadoop2中关于data节点相关配置,在Druid中的conf\druid\cluster\ data目录下,该节点有两个进程historical和middleManager,根据需要修改相关配置,类似步骤4如果测试可以选择单机版的相关配置
6. 根据需要(机器配置、性能要求等)修改hadoop3中关于query节点相关配置,在Druid中的conf\druid\cluster\ query目录下,该节点有两个进程broker和router,根据需要修改相关配置,类似步骤4如果测试可以选择单机版的相关配置
注:这里druid集群版本中默认配置较测试学习虚拟机要求过高,笔者测试均采用单机版配置
7.启动
hadoop1:sh bin/start-cluster-master-no-zk-server >master.log &
hadoop2:sh bin/start-cluster-data-server > data.log &
hadoop3:sh bin/start-cluster-query-server > query.log &
8.关闭:只需要在相关的节点执行 bin/service --down 关闭当前节点的druid相关的全部进程
9.Druid相关管理界面访问地址:
http://192.168.252.113:8888/
http://192.168.252.111:8081/
常见问题
1.关闭命令,不能使用sh bin/service --down ,因为service 脚本获取参数缺陷
2. bin/verify-default-ports 脚本为启动检查端口占用脚本,如果你修改过相关组件的端口后,还是提示端口占用,需要关注该脚本,同步修改(该情况一般出现在单机版中)
3.如果启动日志中出现:Unrecogized VM option 'ExitOnOutOfMemoryError' 说明内存不足,需要修改相应进程的jvm.config配置,或者加机器内存
https://blog.csdn.net/cb2474600377/article/details/103577796

 浙公网安备 33010602011771号
浙公网安备 33010602011771号