
大数据系列之并行计算引擎Spark部署及应用
相关博文:
之前介绍过关于Spark的程序运行模式有三种:
1.Local模式;
2.standalone(独立模式)
3.Yarn/mesos模式
本文将介绍Spark安装及运行模式的第1、3两种模式。
安装包:
spark-2.1.0-bin-hadoop2.7.tgz size:195MB
下载链接: https://pan.baidu.com/s/1bphB3Q3 密码: 9v5h
安装步骤:
1.本地模式:
1.直接将tgz包放置在任一目录:LZ放在了 /home/mfz/resources 下
2.解压:
tar -xzvf spark-2.1.0-bin-hadoop2.7.tgz
3.进入spark-2.1.0-bin-hadoop2.7目录下,启动spark:
bin/spark-shell --master local

4.下面就可以在spark命令行上编程scala啦;
在启动spark时,spark提供了一个RDD,属性名叫sc。下面我们来操作一下计算wordcount:
新建文本/home/mfz/scalaWordCount.txt
![]()
scala命令如下:
val wordtxt = sc.textFile("file:///home/mfz/scalaWordCount.txt") //加载文本scalaWordCount.txt
//将文本按照空格切分成Map(word,1),再进行reduceByKey将map的value进行累加,将计算结果落入磁盘(file表示本地磁盘)wordResult.txt目录中 wordtxt.flatMap(_.split(" ")).map(x => (x,1)).reduceByKey(_+_).saveAsTextFile("file:///home/mfz/wordResult.txt");

查看结果

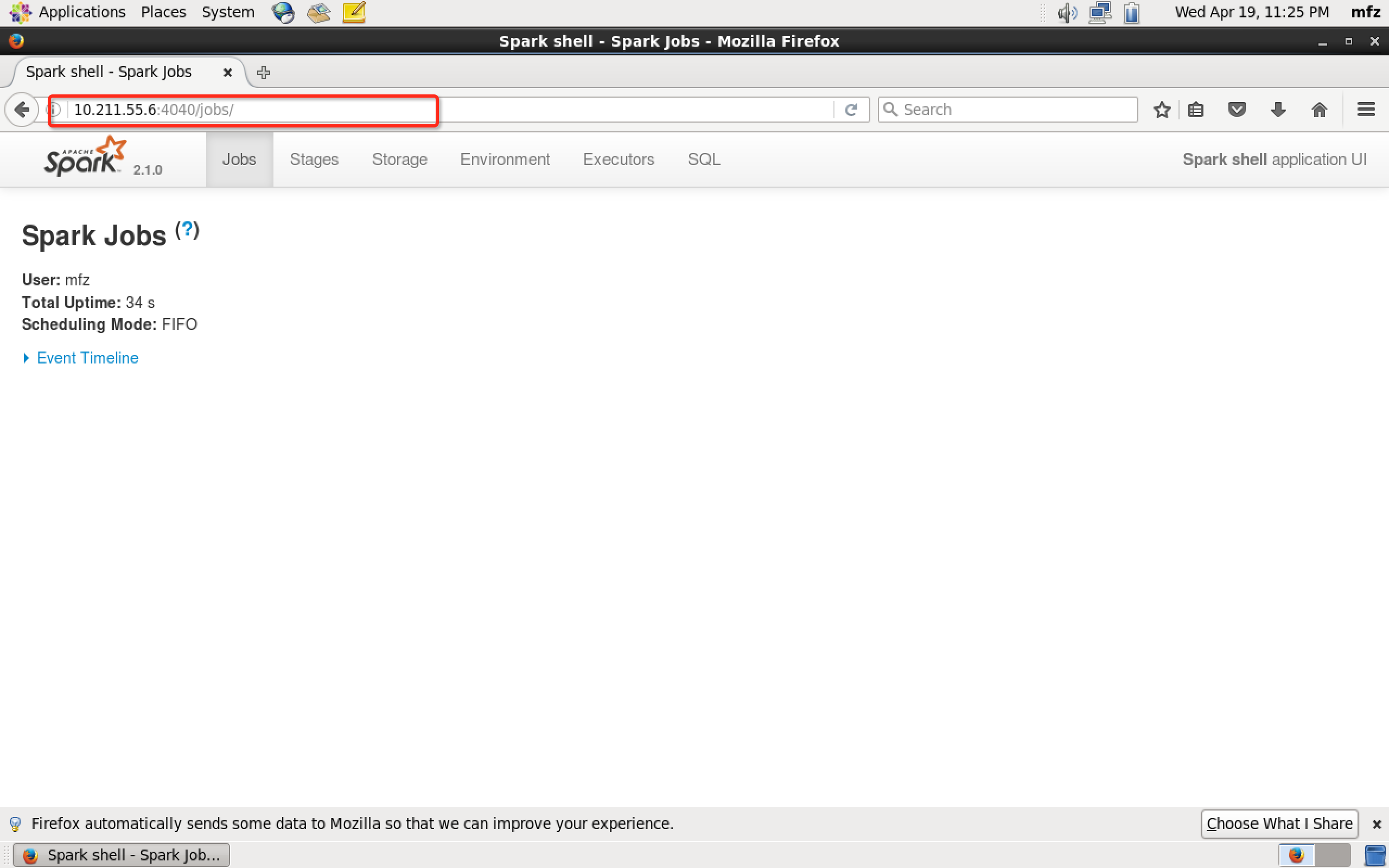
再看WebUI

scala语法详见:https://yq.aliyun.com/topic/69
2.Yarn上运行
在Yarn上运行我们就需要启动HDFS与Yarn服务了。关于Hadoop安装步骤详见博文:大数据系列之Hadoop分布式集群部署
1.修改spark配置文件:
vim /home/mfz/spark-2.1.0-bin-hadoop2.7/conf/spark-env.sh
#添加Hadoop配置文件环境变量 export HADOOP_CONF_DIR=/home/mfz/hadoop-2.7.3/etc/hadoop
2.
cp spark-defaults.conf.template spark-defaults.conf vim spark-defaults.conf 添加如下 spark.master=local # 配置historyServer spark.yarn.historyServer.address=master:18080 //master是hadoop服务器hostname spark.history.ui.port=18080 spark.eventLog.enabled=true spark.eventLog.dir=hdfs:///tmp/spark/events spark.history.fs.logDirectory=hdfs:///tmp/spark/events
3.修改$Hadoop_HOME/etc/hadoop下yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://master:19888/jobhistory/logs</value>
</property>
</configuration>
4.启动HDFS,Yarn服务
$HADOOP_HOME/sbin/start-dfs.sh $HADOOP_HOME/sbin/start-yarn.sh $HADOOP_HOME/sbin/mr-jobhistory-daemon.sh start historyserver
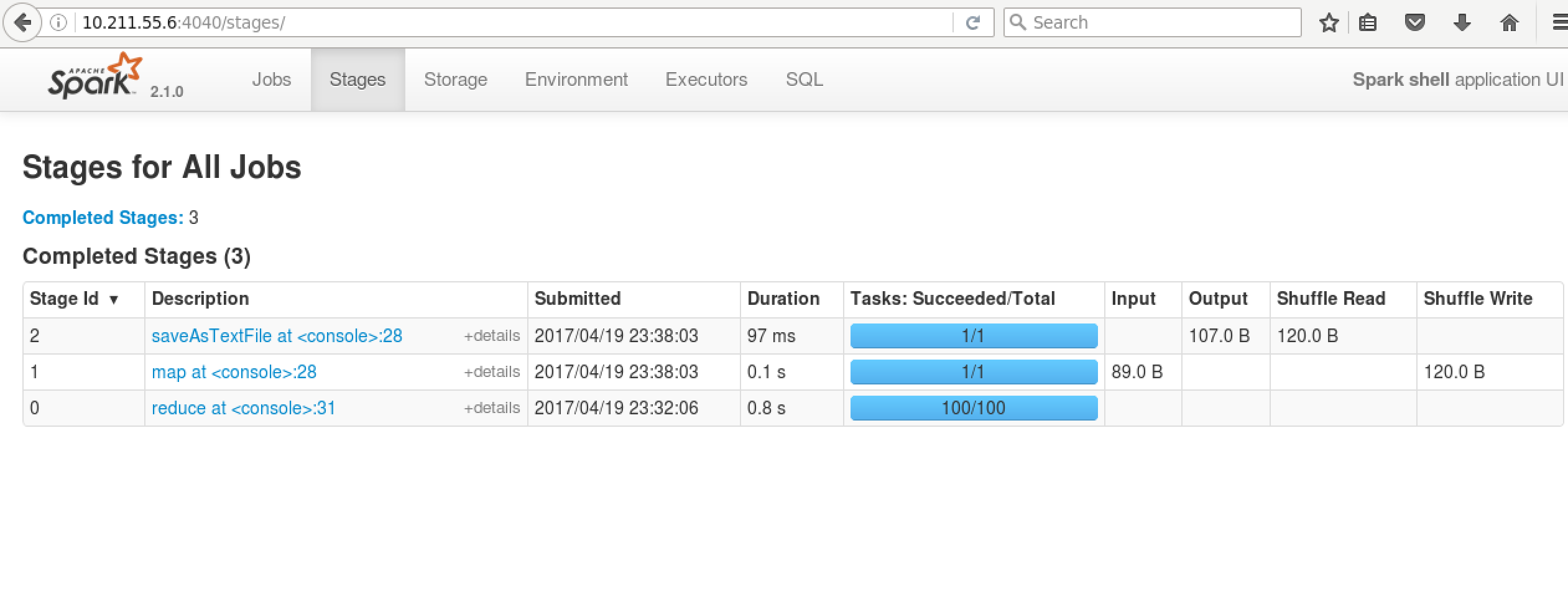
5.验证启动是否成功:


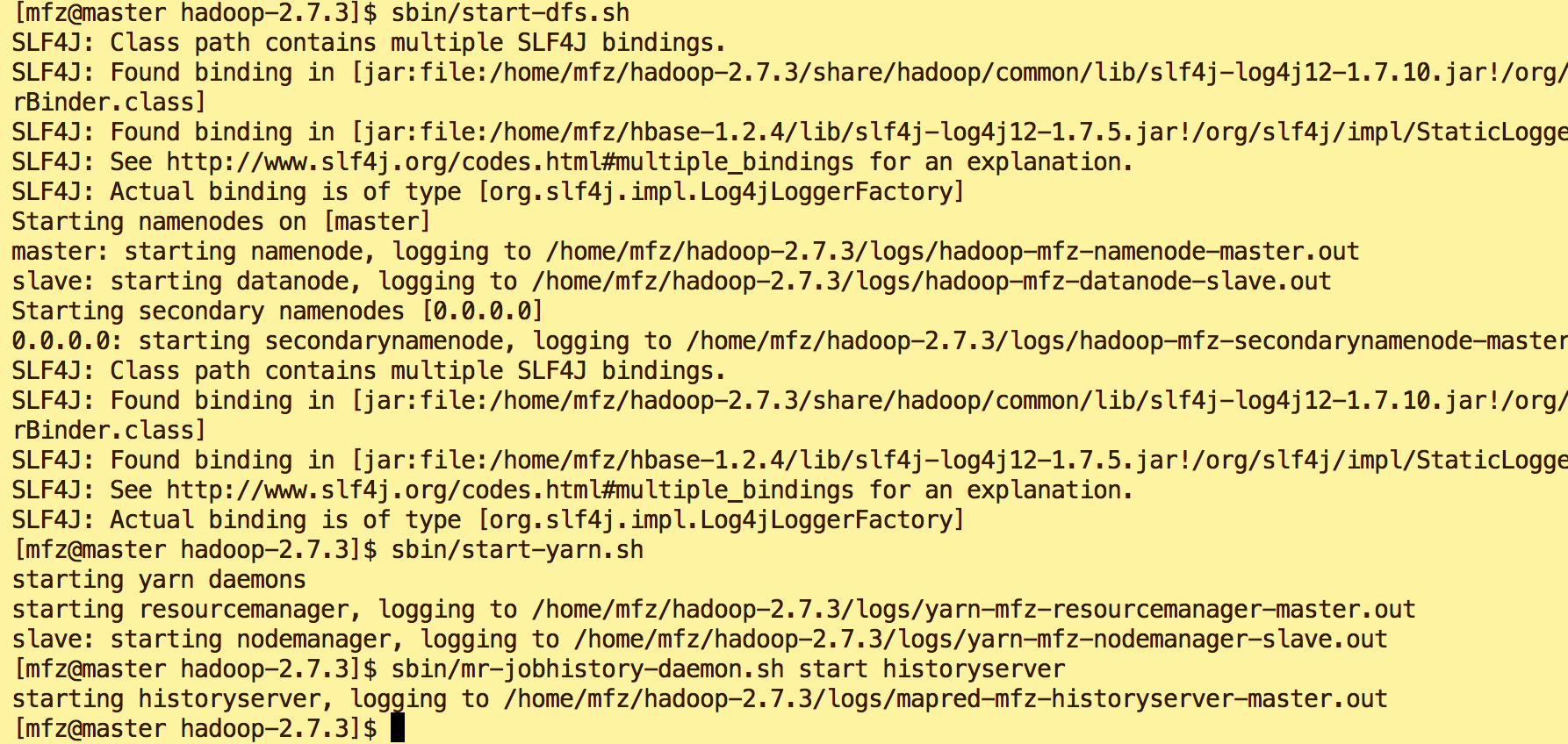
6.新建dfs目录
hdfs dfs -mkdir -p /tmp/spark/events hdfs dfs -mkdir -p /tmp/spark/history
#查看目录
hdfs dfs -ls /tmp/spark
7. 启动Spark on Yarn
cd spark-2.1.0-bin-hadoop2.7 bin/spark-shell --master yarn-client

8.下面我们再来执行一次WordCount命令,区别于Local我们将落盘地址改为HDFS上。
val wordtxt = sc.textFile("file:///home/mfz/scalaWordCount.txt") //加载文本scalaWordCount.txt wordtxt.flatMap(_.split(" ")).map(x => (x,1)).reduceByKey(_+_).saveAsTextFile("/tmp/wordResult");
![]()
9.结果如下:
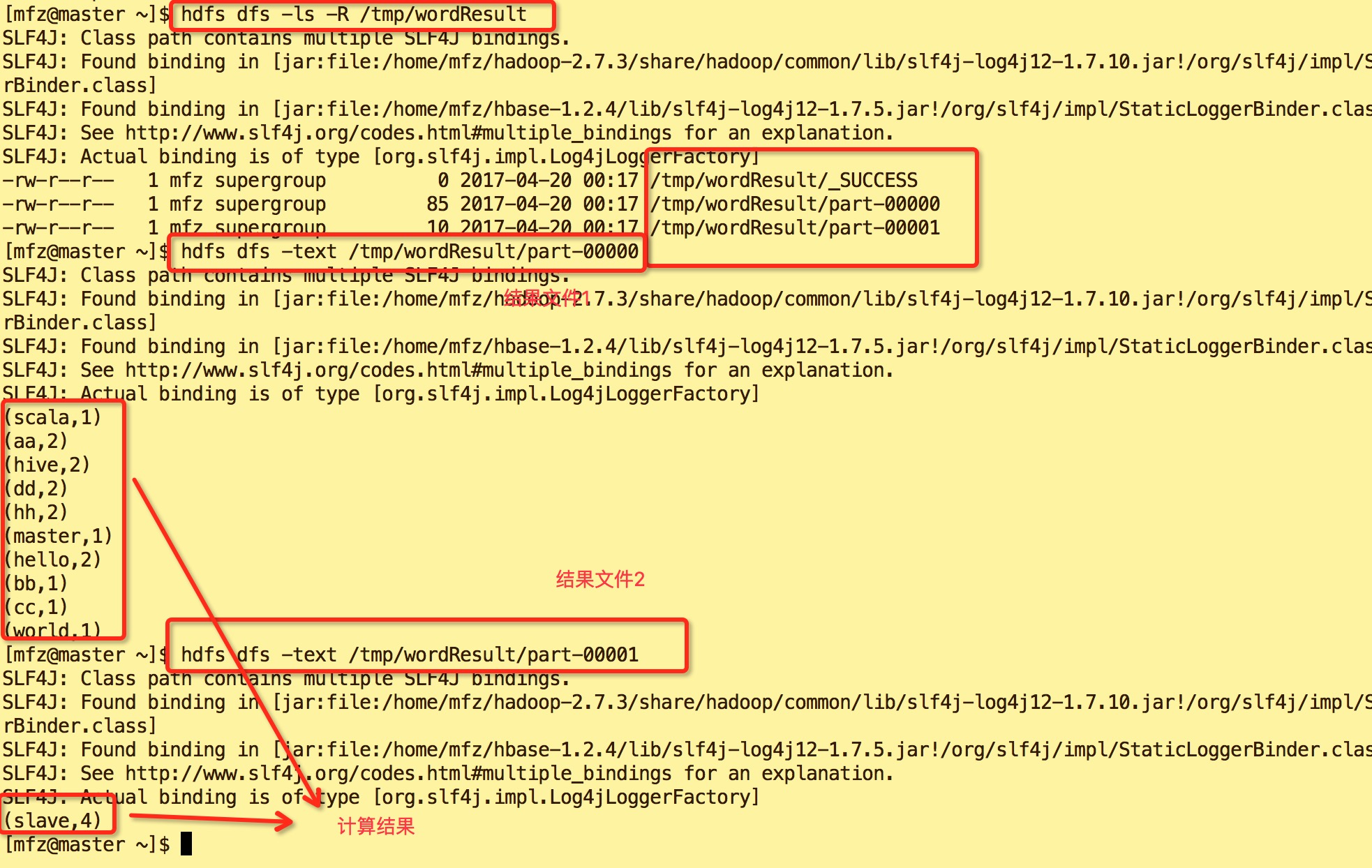
10.查看Yarn WebUi :master:18088。可以看到在红色框中的ID是 application_1492617622120_0001,正是我们上图spart on Yarn启动的app id 号,点击yarn web ui的spark id
可进入spark web ui查看我们刚才执行所有操作.

完~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号