大数据系列之分布式大数据查询引擎Presto
关于presto部署及详细介绍请参考官方链接 http://prestodb-china.com
PRESTO是什么?
Presto是一个开源的分布式SQL查询引擎,适用于交互式分析查询,数据量支持GB到PB字节。
Presto的设计和编写完全是为了解决像Facebook这样规模的商业数据仓库的交互式分析和处理速度的问题。
它可以做什么?
Presto支持在线数据查询,包括Hive, Cassandra, 关系数据库以及专有数据存储。 一条Presto查询可以将多个数据源的数据进行合并,可以跨越整个组织进行分析。
Presto以分析师的需求作为目标,他们期望响应时间小于1秒到几分钟。 Presto终结了数据分析的两难选择,要么使用速度快的昂贵的商业方案,要么使用消耗大量硬件的慢速的“免费”方案。
谁在使用它?
Facebook使用Presto进行交互式查询,用于多个内部数据存储,包括300PB的数据仓库。 每天有1000多名Facebook员工使用Presto,执行查询次数超过30000次,扫描数据总量超过1PB。
领先的互联网公司包括Airbnb和Dropbox都在使用Presto。
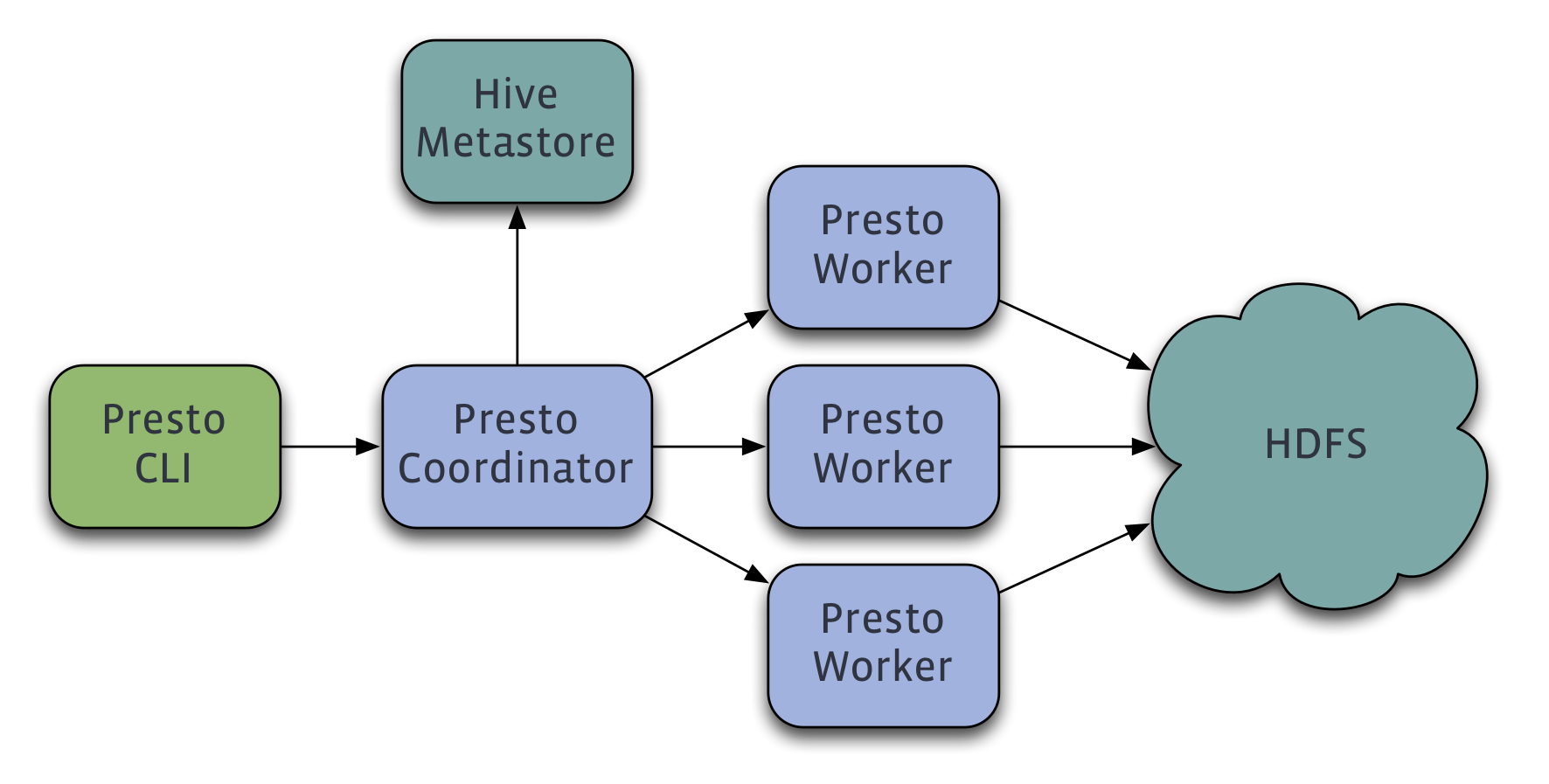
Presto是一个运行在多台服务器上的分布式系统。 完整安装包括一个coordinator和多个worker。 由客户端提交查询,从Presto命令行CLI提交到coordinator。 coordinator进行解析,分析并执行查询计划,然后分发处理队列到worker。
本文介绍Hive与Presto的优缺点:
- 执行效率比较:
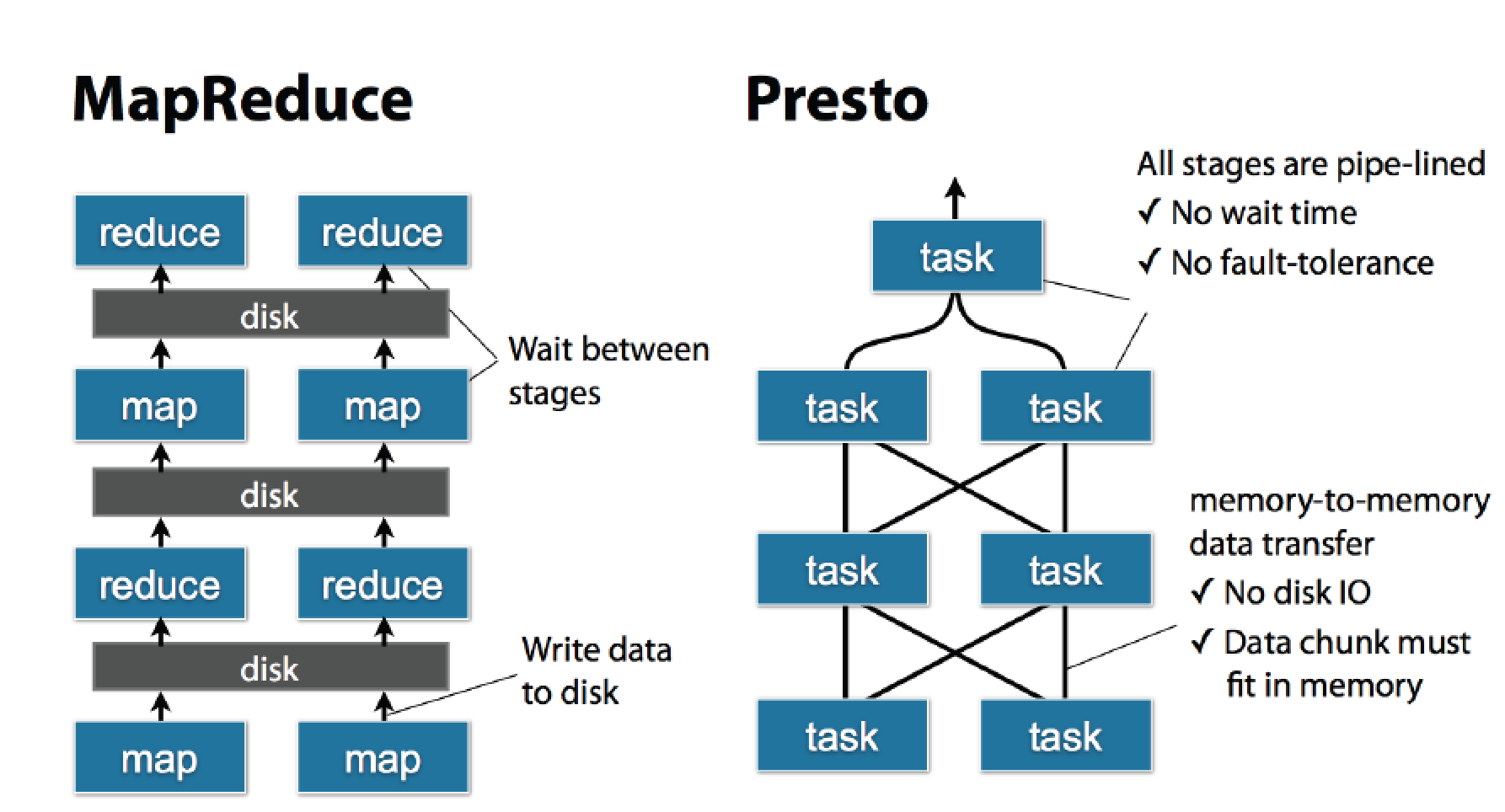
- Hive是Facebook在几年前专为Hadoop打造的一款数据仓库工具。因为它主要依赖MapReduce进行运行,所以随着年龄的上升,其在速度上已不能满足日益增长的数据要求。浏览一个完整的数据集可能要花费几分到几小时,这完全是不切实际的。
- Presto进行简单的查询只需要几百毫秒,即使是非常复杂的查询,也只需数分钟即可完成,它在内存中运行,并且不会向磁盘写入。
- 原理比较:
- Hive是依赖MapReduce进行运行,这个在之前关于Hive的博文中是有介绍的。MR在运行过程中会将结果落入HDFS上,这个比较耗时的。见下图:
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号