这不算爬虫吧?!
------------------------------------------------------------------------------------------------------------------
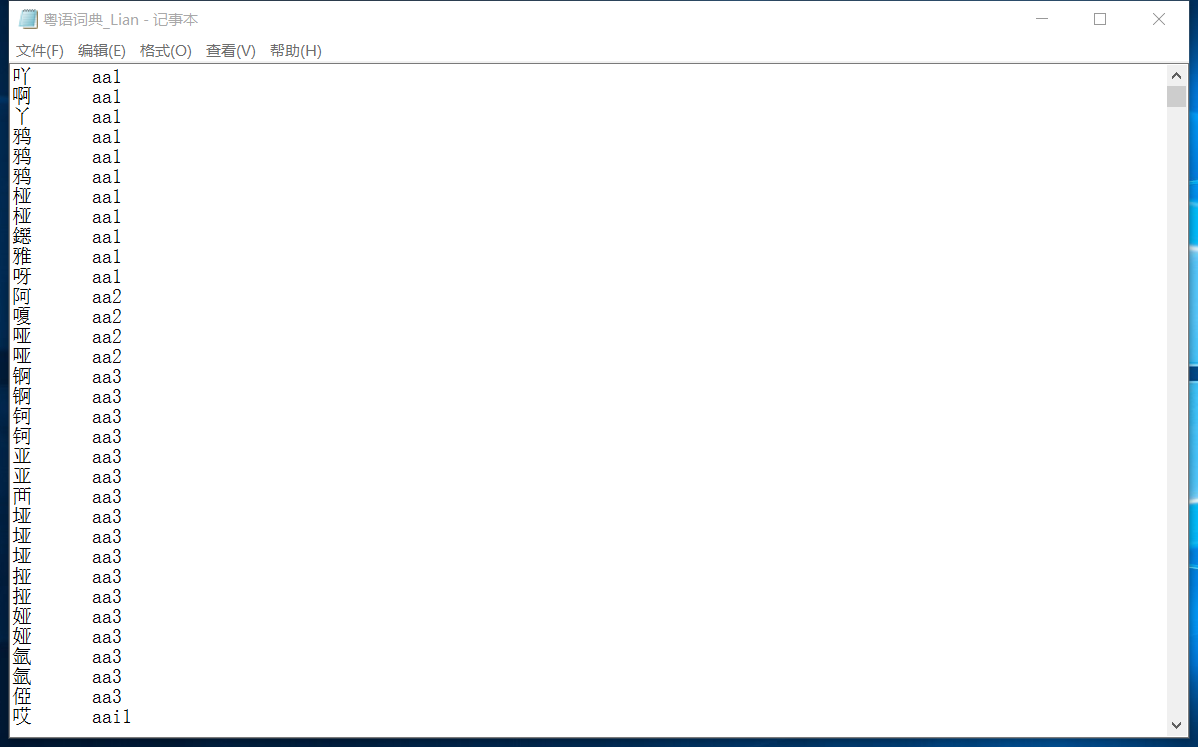
因程序需要,需要拿到一个粤语词典(需要找到任一个汉字的粤语拼音),但是在网上找来找去都没有找到现有的词典。
走投无路下,只能对现有粤语词典网站进行知识“掠夺”:),拿到一个对应表。
于是,码了以下代码:
1 using System; 2 using System.Text; 3 using System.Net; 4 using System.IO; 5 using System.Threading; 6 7 namespace Yueyu_Dic_Crawler 8 { 9 class Program 10 { 11 static void Main(string[] args) 12 { 13 string[] array = { "0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "A", "B", "C", "D", "E", "F" }; 14 { 15 //建立文件,准备输入 16 FileStream fs = new FileStream(@"C:\Users\Lian\Desktop\Dic\Dictionary.txt", FileMode.Create); 17 StreamWriter sw = new StreamWriter(fs); 18 19 //由于此网站URL的特殊性,不用实现真正意义上的爬虫就可以获取信息 20 //只需要更改URL中间的4位就可以遍历60000+汉字的信息 21 for (int apple=0;apple<16;apple++) 22 for (int pear = 0; pear < 16; pear++) 23 for (int orange = 0; orange < 16; orange++) 24 for (int peach = 0; peach < 16; peach++) 25 { 26 //没有这个sleep,就要被网站服务器的防护机制给弄炸了:( 27 Thread.Sleep(100); 28 29 //从0000到FFFF:) 30 string url = "http://www.yueyv.cn/?keyword=%" + array[apple] + array[pear] + "%" + array[orange] + array[peach] + "&submit=%B2%E9+%D1%AF"; 31 32 //Request AND Response 33 HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create(url); 34 request.Method = "GET"; 35 HttpWebResponse response = (HttpWebResponse)request.GetResponse(); 36 37 //使用StreamReader读取html源代码 38 StreamReader reader = new StreamReader(response.GetResponseStream(), Encoding.GetEncoding("gb2312")); 39 40 //经观察,第370行存储汉字,第394行存储粤语拼音 41 string hanzi_line; 42 for (int z = 0; z < 369; z++, reader.ReadLine()) ; 43 hanzi_line = reader.ReadLine(); 44 string yuepin_line; 45 for (int z = 0; z < 23; z++, reader.ReadLine()) ; 46 yuepin_line = reader.ReadLine(); 47 48 //写入文件 49 sw.Write(hanzi_line + "\t" + yuepin_line + "\r\n"); 50 Console.WriteLine(hanzi_line + "\t" + yuepin_line); 51 52 /*@@@@@@!!!!!!@@@@@@!!!!!!@@@@@@!!!!!!@@@@@@*/ 53 54 //如果不关闭HttpWebResponse,在请求两次后,就收不到回音了= = 55 //应该算是C#的特点吧,很关键,花费了很长很长时间。 56 response.Close(); 57 } 58 //清空缓冲区 59 sw.Flush(); 60 //关闭流 61 sw.Close(); 62 fs.Close(); 63 } 64 } 65 } 66 }
其实,中间还有一些小细节,比如:
1、实际上只有一部分组合存储着信息,如8000-8FFF的组合中,其实只有8140-8FFE有信息(感谢partner);
2、大约将0000-FFFF分成了10块,分了10次才爬下来,因为即使sleep,服务器的防护机制有时间也能把你拦住;
3、没有使用正则表达式,就是用excel简单处理了一下结果:)以后肯定要使用正则表达式:)
4、多音字,只收录了它的第一次读音:)
从昨天中午有这个想法,到今天晚上实现,感触最深的有两点:
一是,这个时代学习东西太方便了,知识的交互太便捷了!
二是,互联网上存储着多少知识和财富啊!!!!!!!!
过几天把这个粤语词典放网上:)应该不犯法吧。。。
小Lian
2017/4/15凌晨
作者: 小LiAn
出处: http://www.cnblogs.com/cnlian/>
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出, 原文链接 如有问题, 可邮件(671266128@qq.com)咨询.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号