Tesseract-OCR的简单使用与训练
Tesseract,一款由HP实验室开发由Google维护的开源OCR(Optical Character Recognition , 光学字符识别)引擎,与Microsoft Office Document Imaging(MODI)相比,我们可以不断的训练的库,使图像转换文本的能力不断增强;如果团队深度需要,还可以以它为模板,开发出符合自身需求的OCR引擎。
源码地址为:https://github.com/tesseract-ocr/tesseract;
EXE可执行文件地址:http://download.csdn.net/download/whatday/7740469;
接下来,我们将在Windows环境下安装Tesseract并实现简单的转换和训练:
1、Tesseract实现
大体流程:Tesseract安装 -> 打开命令行 -> 生成目标文件
Tesseract安装
下载tesseract-ocr-setup-3.02.02.exe安装包,安装成功后会在相应磁盘下有Tesseract-OCR文件夹,如图

打开命令行
打开命令行,输入tesseract,回车;以下便是tesseract的大体面貌:
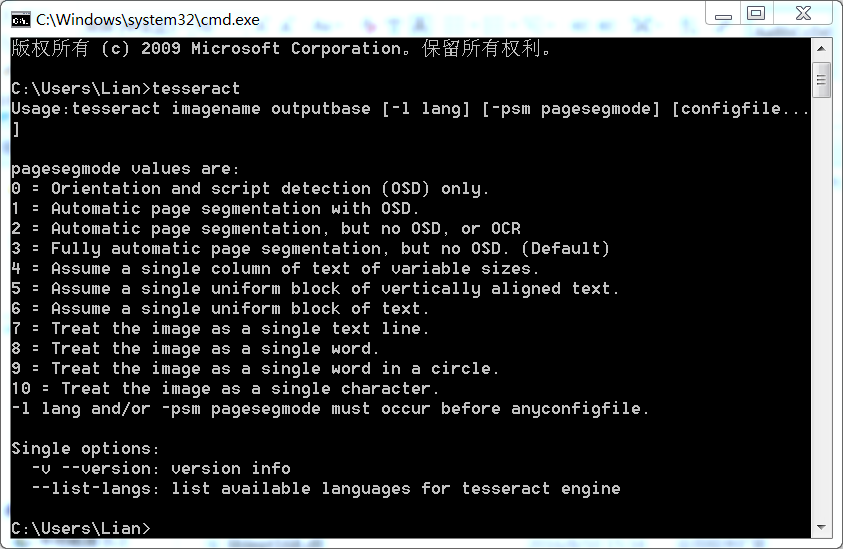
生成目标文件
先准备一张图片文件,如test.png
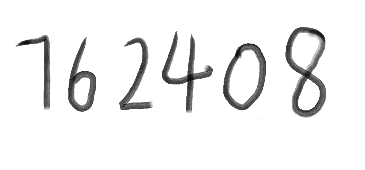
将命令行切换至目标图像文件目录,比如我们转换文件为test.png(图片文件允许多种格式),位于C:\Users\Lian\Desktop\test;然后在命令行中输入
tesseract test.png output_1 –l eng
【语法】: tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile…]
imagename为目标图片文件名,需加格式后缀;outputbase是转换结果文件名;lang是语言名称(在Tesseract-OCR中tessdata文件夹可看到以eng开头的语言文件eng.traineddata),如不标-l eng则默认为eng。

打开文件output_1.txt,发现tesseract成功的将图像转换成152408。
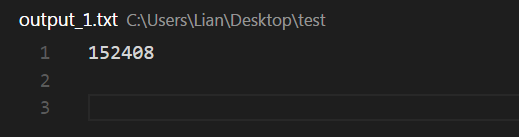
可喜可贺,说明老牌名将tesseract还是很强的!但是还是有点不够准确,那么我们有没有什么办法能提高tesseract识别字符准确率呢?接下来,我们将使用配套训练工具jTessBoxEditor来训练样本,来提高我们的准确率!
2、Tesseract训练:
大体流程为:安装jTessBoxEditor -> 获取样本文件 -> Merge样本文件 –> 生成BOX文件 -> 定义字符配置文件 -> 字符矫正 -> 执行批处理文件 -> 将生成的traineddata放入tessdata中
安装jTessBoxEditor
下载jTessBoxEditor,地址https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/;解压后得到jTessBoxEditor,由于这是由Java开发的,所以我们应该确保在运行jTessBoxEditor前先安装JRE(Java Runtime Environment,Java运行环境)。
获取样本文件
我们可以用画图工具绘制样本文件,数量越多越好,我自己画了5张图,如图:
【注意】:样本图像文件格式必须为tif\tiff格式,否则在Merge样本文件的过程中会出现 Couldn’t Seek 的错误。
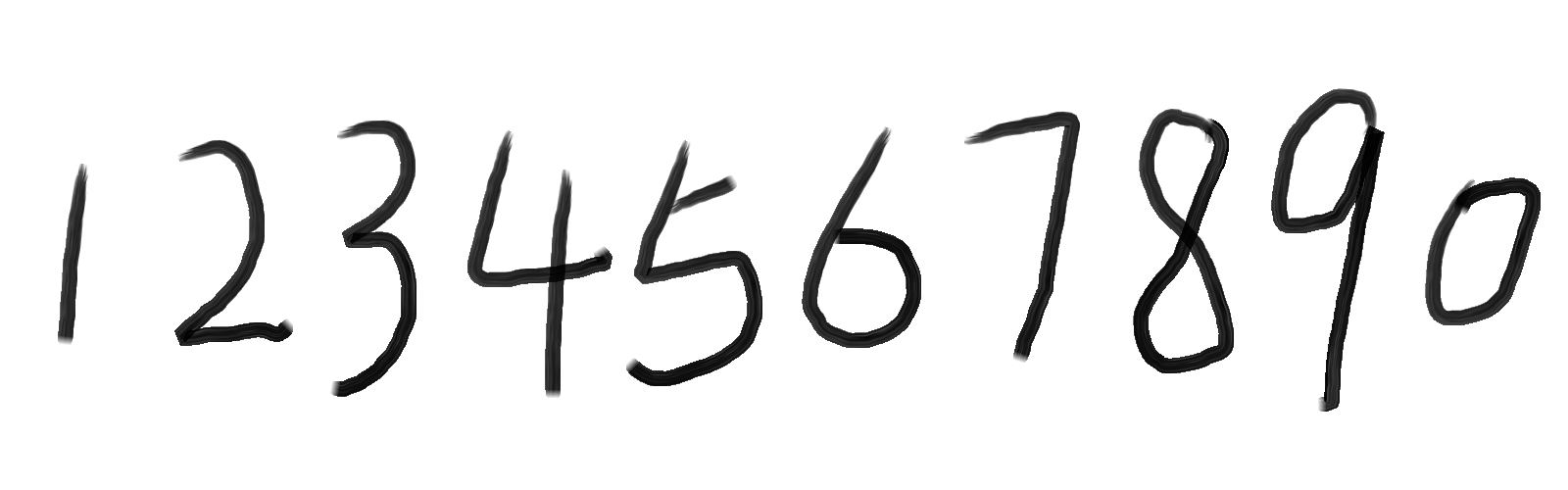



Merge样本文件
打开jTessBoxEditor,Tools->Merge TIFF,将样本文件全部选上,并将合并文件保存为num.font.exp0.tif
生成BOX文件
打开命令行并切换至num.font.exp0.tif所在目录,输入,生成文件名为num.font.exp0.box
tesseract num.font.exp0.tif num.font.exp0 batch.nochop makebox
【语法】:tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox
lang为语言名称,fontname为字体名称,num为序号;在tesseract中,一定要注意格式。
定义字符配置文件
在目标文件夹内生成一个名为font_properties的文本文件,内容为
font 0 0 0 0 0
【语法】:<fontname> <italic> <bold> <fixed> <serif> <fraktur>
fontname为字体名称,italic为斜体,bold为黑体字,fixed为默认字体,serif为衬线字体,fraktur德文黑字体,1和0代表有和无,精细区分时可使用。
字符矫正
打开jTessBoxEditor,BOX Editor -> Open,打开num.font.exp0.tif;矫正<Char>上的字符,记得<Page>有好多页噢!

修改后记得保存。
执行批处理文件
在目标目录下生成一个批处理文件
rem 执行改批处理前先要目录下创建font_properties文件
echo Run Tesseract for Training.. tesseract.exe num.font.exp0.tif num.font.exp0 nobatch box.train echo Compute the Character Set.. unicharset_extractor.exe num.font.exp0.box mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp0.tr echo Clustering.. cntraining.exe num.font.exp0.tr echo Rename Files.. rename normproto num.normproto rename inttemp num.inttemp rename pffmtable num.pffmtable rename shapetable num.shapetable echo Create Tessdata.. combine_tessdata.exe num.
echo. & pause
保存后执行即可,执行结果如图:

最终文件夹内会有以下文件,如图:

将生成的traineddata放入tessdata中
最后将num.trainddata复制到Tesseract-OCR中tessdata文件夹即可。
3、最后的测试
按照之前步骤,使用命令行输入
tesseract test.png output_2 -l num
我们可以看到新生成的文件output_2的内容为762408,内容完全正确。细心的人会发现,最后一句指令,我们使用了指令[-l num]而不是[-l eng]。这说明,最后一次转换我们使用的是新生成的num语言的匹配库而不是默认的eng语言匹配库。

我们可以看到,经过简单的训练,我们对于数字数据的转换准确率提高了很多。Tesseract的优点除了可以不断学习以外,还因为是使用C++写的开源程序,可以使用C#或者C++调用以及修改,很关键!
关于Tesseract,关于OCR,关于计算机,还有太多值得自己去学习,希望以后可以在这里记录下来。
如有错误或者建议,请尽情指教!
大二暑期实习
2016/8/12
作者: 小LiAn
出处: http://www.cnblogs.com/cnlian/>
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出, 原文链接 如有问题, 可邮件(671266128@qq.com)咨询.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号