SKLearn数据集API(一)
注:本文是人工智能研究网的学习笔记
数据集一览
| 类型 | 获取方式 |
|---|---|
| 自带的小数据集 | sklearn.datasets.load_ |
| 在线下载的数据集 | sklearn.datasets.fetch_ |
| 计算机生成的数据集 | sklearn.datasets.make_ |
| svmlight/libsvm格式的数据集 | sklearn.datasets.load_svmlight_file(...) |
| mldata.org在线下载数据集 | sklearn.datasets.fetch_mldata(...) |
自带的小数据集
返回的是bunch对象,是字典类型
| 名称 | 数据包 |
|---|---|
| 鸢尾花数据集 | load_iris() |
| 乳腺癌数据集 | load_breast_cancer() |
| 手写数字数据集 | load_digits() |
| 糖尿病数据集 | load_diabetes() |
| 波士顿房价数据集 | load_boston() |
| 体能训练数据集 | load_linnerud() |
| 图像数据集 | load_sample_image(name) |
鸢尾花数据集
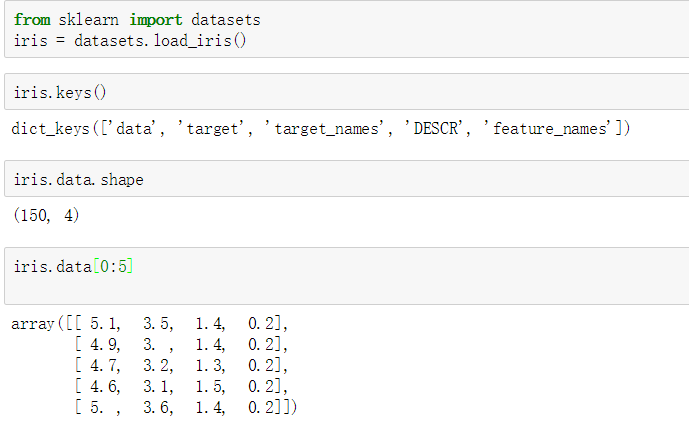
下面使用花萼长度单个特征来划分查看,这是探索性分析,当我们不知道该使用那些特征的时候,就这样查看一下。
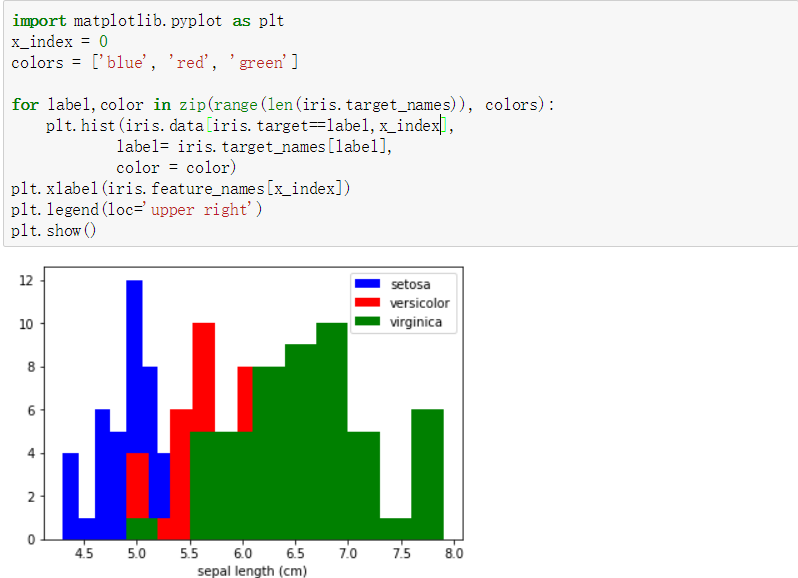
下面使用两个特征来划分查看
手写数字数据集

图像数据集

在线下载的数据集
使用datasets.get_data_home()函数获取下载目录
| 类型 | 获取方式 |
|---|---|
| 20类新闻文本数据集 | fetch_20newsgroups() / fetch_20newsgroups_vectorized() |
| 野外带标记人脸数据集 | fetch_lfw_people() / fetch_lfw_pairs() |
| Olivetti人脸数据集 | fetch_olivetti_faces() |
| rcvl多标签数据集 | fetch_rcvl() |
| 加利福尼亚房价数据集 | fetch_canlifornia_housing() |
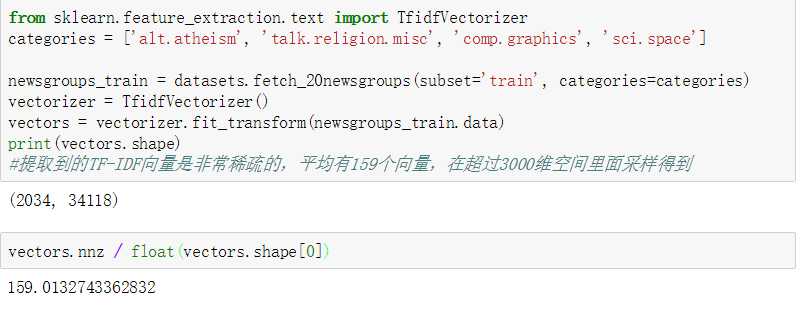
20类新闻文本数据集
包含了关于20个话题(topic)的18000条新闻报道,被分为两个子集: 训练集和测试集
| 函数 | 内容 |
|---|---|
| fetch_20newsgroups() | 原始的文本列表,该文本可以被输入到文本特征提取器sklearn.feature_extraction.text.CountVectorizer进一步处理得到特征向量 |
| fetch_20newsgroups_vectorized() | 返回一个直接可以使用的特征,无须在进行特征提取。 |
Olivetti人脸数据集
Olivetti人脸数据集是AT&T在1992-1994年手机的人脸数据集,包含了40个不同的目标,每个目标10张图片,某些目标的图像在不同的时间段采集,带有光照,面部表情(眼镜开闭,笑容),面部袭细节的各种变化,所有的人脸图像被正立的放在一个灰色的背景上。
每一张图像上有256个灰度级,用无符号8为来存。加载函数会将所有的图像转换成[0,1]区间上的浮点数,目标值target存放着0到39的数字代表人脸的类别标签。然而每个标签对应的人脸图像都只有10张,每张图像的分辨率是64*64。这个小数据集会更加适合来做无监督学习或者半监督学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号