Scrapy学习篇(六)之Selector选择器
当我们取得了网页的response之后,最关键的就是如何从繁杂的网页中把我们需要的数据提取出来,python从网页中提取数据的包很多,常用的有下面的几个:
- BeautifulSoup
它基于HTML代码的结构来构造一个Python对象, 对不良标记的处理也非常合理,但是速度上有所欠缺。 - lxml
是一个基于 ElementTree (不是Python标准库的一部分)的python化的XML解析库(也可以解析HTML)。
你可以在scrapy中使用任意你熟悉的网页数据提取工具,但是,scrapy本身也为我们提供了一套提取数据的机制,我们称之为选择器(seletors),他们通过特定的 XPath 或者 CSS 表达式来“选择” HTML文件中的某个部分。XPath 是一门用来在XML文件中选择节点的语言,也可以用在HTML上。 CSS 是一门将HTML文档样式化的语言。选择器由它定义,并与特定的HTML元素的样式相关连。
Scrapy选择器构建于 lxml 库之上,这意味着它们在速度和解析准确性上非常相似。下面我们来了解scrapy选择器。
使用选择器
scrapy中调用选择器的方法非常的简单,下面我们从实例中进行学习。
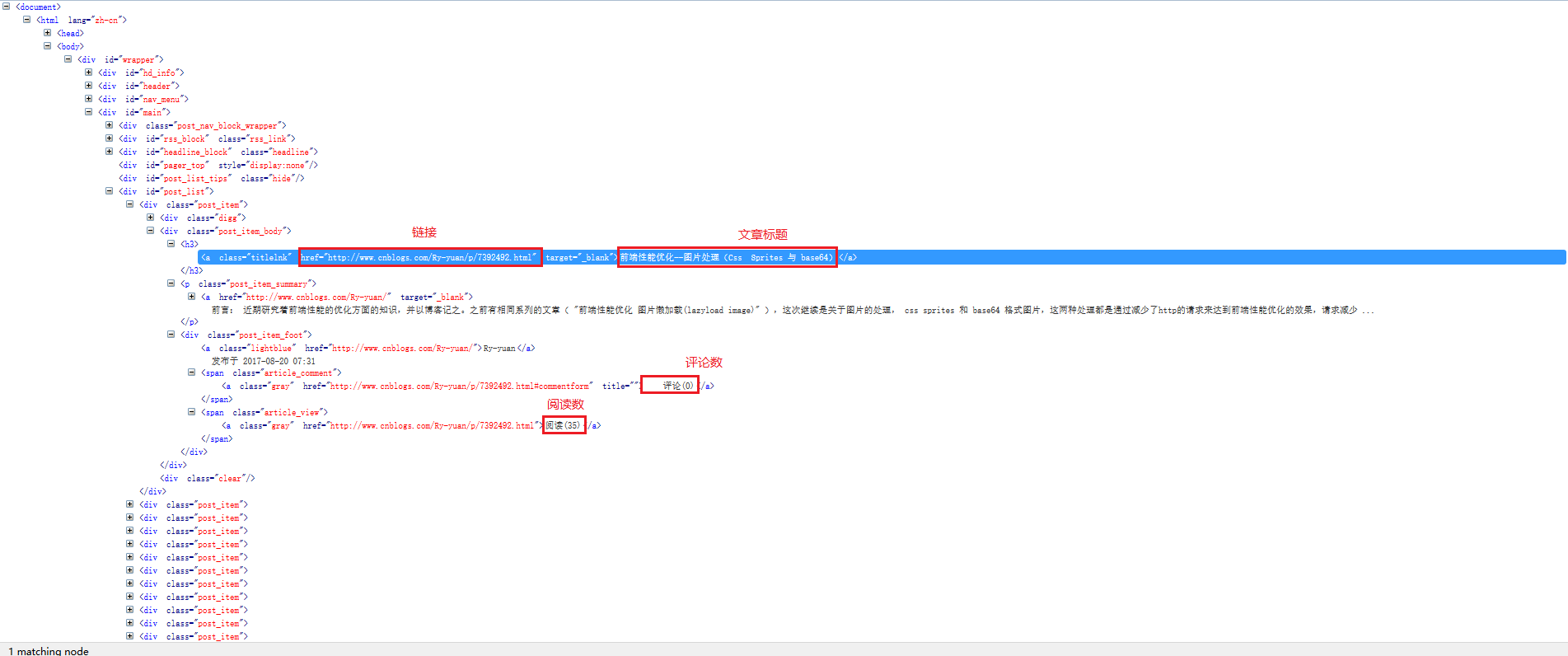
我们还是以博客园首页的信息作为例子,演示使用选择器抓取数据,下图是首页的html信息,我们下面就是抓取标题,链接,阅读数,评论数。
import scrapy
from scrapy.selector import Selector
class Cnblog_Spider(scrapy.Spider):
name = "cnblog"
allowed_domains = ["cnblogs.com"]
start_urls = [
'https://www.cnblogs.com/',
]
def parse(self, response):
selector = Selector(response=response)
title = selector.xpath('//a[@class="titlelnk"]/text()').extract()
link = selector.xpath('//a[@class="titlelnk"]/@href').extract()
read = selector.xpath('//span[@class="article_comment"]/a/text()').extract()
comment = selector.xpath('//span[@class="article_view"]/a/text()').extract()
print('这是title:',title)
print('这是链接:', link)
print('这是阅读数', read)
print('这是评论数', comment)
选择器的使用可以分为下面的三步:
- 导入选择器
from scrapy.selector import Selector - 创建选择器实例
selector = Selector(response=response) - 使用选择器
selector.xpath()或者selector.css()
当然你可以使用xpath或者css中的任意一种或者组合使用,怎么方便怎么来,至于xpath和css语法,你可以去额外学习,仔细观察,你会发现每个选择器最后都有一个extract(),你可以尝试去掉这个看一下,区别在于,当你没有使用extract()的时候,提取出来的内容依然具有选择器属性,简而言之,你可以继续使用里面的内容进行提取下级内容,而当你使用了extract()之后,提取出来的内容就会变成字符串格式了。我们进行多级提取的时候,这会很有用。值得注意的是,选择器提取出来的内容是放在列表里面的,即使没有内容,那也是一个空列表,下面我们运行这个爬虫,你会发现内容已经被提取出来了。

事实上,我们可以完全不用那么麻烦,因为scrapy为我们提供了选择器的简易用法,当我们需要选择器的时候,只要一步就可以了,如下:
import scrapy
class Cnblog_Spider(scrapy.Spider):
name = "cnblog"
allowed_domains = ["cnblogs.com"]
start_urls = [
'https://www.cnblogs.com/',
]
def parse(self, response):
title = response.xpath('//a[@class="titlelnk"]/text()').extract()
link = response.xpath('//a[@class="titlelnk"]/@href').extract()
read = response.xpath('//span[@class="article_comment"]/a/text()').extract()
comment = response.xpath('//span[@class="article_view"]/a/text()').extract()
print('这是title:', title)
print('这是链接:', link)
print('这是阅读数', read)
print('这是评论数', comment)
可以看到,我们直接使用response.xpath()就可以了,并没有导入什么,实例化什么,可以说非常方便了,当然直接response.css()一样可以。
拓展
scrapy为我们提供的选择器还有一些其他的特点,这里我们简单的列举
- extract()
前面已经提到了,.xpath() 及 .css() 方法返回一个类 SelectorList 的实例, 它是一个新选择器的列表,就是说,你依然可以使用里面的元素进行向下提取,因为它还是一个选择器,为了提取真实的原文数据,我们需要调用 .extract()>>> response.xpath('//title/text()') [<Selector (text) xpath=//title/text()>] >>> response.css('title::text') [<Selector (text) xpath=//title/text()>] - extract_first()
如果想要提取到第一个匹配到的元素, 可以调用response.xpath('//span[@class="article_view"]/a/text()').extract_first()这样我们就拿到了第一个匹配的数据,当然,我们之前提到了选择器返回的数据是一个列表,那么你当然可以使用response.xpath('//span[@class="article_view"]/a/text()').extract()[0]拿到第一个匹配的数据,这和response.xpath('//span[@class="article_view"]/a/text()')[0].extract()效果是一样的,值得注意的是,如果是空列表,这两种方法的区别就出现了,extract_first()会返回None,而后面的那种方法,就会因列表为空而报错。
除此之外,我们还可以为extract_first()设置默认值,当空列表时,就会返回一个我们设置的值,比如:extract_first(default='not-found')。
结合正则表达式
你会发现,之前我们匹配的阅读数,评论数都会有汉字在里面,如果我们只想提取里面的数字呢,这个时候就可以使用正则表达式和选择器配合来实现,比如下面:
import scrapy
class Cnblog_Spider(scrapy.Spider):
name = "cnblog"
allowed_domains = ["cnblogs.com"]
start_urls = [
'https://www.cnblogs.com/',
]
def parse(self, response):
read = response.xpath(
'//span[@class="article_comment"]/a/text()').re('\d+')
comment = response.xpath(
'//span[@class="article_view"]/a/text()').re('\d+')
print('这是阅读数', read)
print('这是评论数', comment)
运行一下,可以看到,效果就出来了。
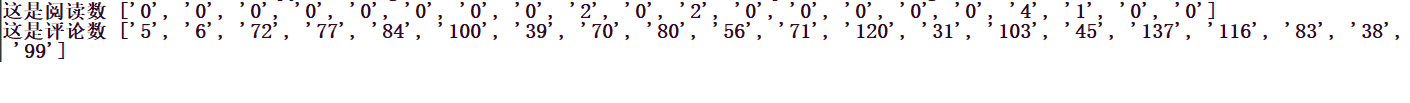

 浙公网安备 33010602011771号
浙公网安备 33010602011771号