Scrapy学习篇(四)之数据存储
上一篇中,我们简单的实现了一个博客首页信息的爬取,并在控制台输出,但是,爬下来的信息自然是需要保存下来的。这一篇主要是实现信息的存储,我们以将信息保存到文件和mongo数据库为例,学习数据的存储,依然是以博客首页信息为例。
编写爬虫
修改items.py文件来定义我们的item
Item 是保存爬取到的数据的容器;其使用方法和python字典类似。虽然你也可以在Scrapy中直接使用dict,但是Item提供了额外保护机制来避免拼写错误导致的未定义字段错误。简单的来说,你所要保存的任何的内容,都需要使用item来定义,比如我们现在抓取的页面,我们希望保存 title,link, 那么你就要在items.py文件中定义他们,以后你会发现,items.py文件里面你所要填写的信息是最简单的了。
import scrapy
class CnblogItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
这样就已经定义好了。
编写spider文件
在项目中的spiders文件夹下面创建一个文件,命名为cnblog_spider.py我们将在这个文件里面编写我们的爬虫。先上代码再解释。
import scrapy
from cnblog.items import CnblogItem #新添加
class Cnblog_Spider(scrapy.Spider):
name = "cnblog"
allowed_domains = ["cnblogs.com"]
start_urls = [
'https://www.cnblogs.com/',
]
def parse(self, response):
item = CnblogItem() #新添加
item['title'] = response.xpath('//a[@class="titlelnk"]/text()').extract() #修改
item['link'] = response.xpath('//a[@class="titlelnk"]/@href').extract() #修改
yield item #新添加
下面主要对新添加或者修改的地方讲解
- 导入CnblogItem自定义类,注意:新建项目中带有scrapy.cfg文件的那个目录默认作为项目的根目录,因此from cnblog.items import CnblogItem就是从cnblog项目里面的items.py文件里面导入我们自定义的那个类,名称是CnblogItem,就是上面我们定义的那个CnblogItem ,只有导入了这个类,我们才可以保存我们的字段。
- item = CnblogItem() 实例化,不多说。
- item['title']和item['link'],前面已经说过,item其实就是可以简单的理解为字典,这个地方就是相当于给字典里面的键赋值。
- 最后yield item生成器,scrapy会将item传递给pipeline进行后续的处理,当然,前提是你打开了settings设置里面的设置项,相关的设置马上就会说到。
修改pipelines.py文件,实现保存。
import pymongo #别忘了导入这个模块
class FilePipeline(object):
'''
实现保存到txt文件的类,类名这个地方为了区分,做了修改,
当然这个类名是什么并不重要,你只要能区分就可以,
请注意,这个类名待会是要写到settings.py文件里面的。
'''
def process_item(self, item, spider):
with open('cnblog.txt', 'w', encoding='utf-8') as f:
titles = item['title']
links = item['link']
for i,j in zip(titles, links):
f.wrire(i + ':' + j + '\n')
return item
class MongoPipeline(object):
'''
实现保存到mongo数据库的类,
'''
collection = 'cnblog' #mongo数据库的collection名字,随便
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
'''
scrapy为我们访问settings提供了这样的一个方法,这里,
我们需要从settings.py文件中,取得数据库的URI和数据库名称
'''
return cls(
mongo_uri = crawler.settings.get('MONGO_URI'),
mongo_db = crawler.settings.get('MONGO_DB')
)
def open_spider(self, spider): #爬虫一旦开启,就会实现这个方法,连接到数据库
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider): #爬虫一旦关闭,就会实现这个方法,关闭数据库连接
self.client.close()
def process_item(self, item, spider):
'''
每个实现保存的类里面必须都要有这个方法,且名字固定,用来具体实现怎么保存
'''
titles = item['title']
links = item['link']
table = self.db[self.collection]
for i, j in zip(titles, links):
data = {}
data['文章:链接'] = i + ':' + j
table.insert_one(data)
return item
修改settings.py文件
之前,我们修改了两个内容,ROBOTSTXT_OBEY和DEFAULT_REQUEST_HEADERS,这里我们在之前的基础上,在添加如下内容。
ROBOTSTXT_OBEY = False
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
#新修改
ITEM_PIPELINES = {
'cnblog.pipelines.FilePipeline': 300, #实现保存到txt文件
'cnblog.pipelines.MongoPipeline': 400, #实现保存到mongo数据库
}
#新添加数据库的URI和DB
MONGO_URI = 'mongodb://localhost:27017' D
MONGO_DB = "cnblog"
对于新修改的内容简单的解释,如果你仅仅想保存到txt文件,就将后者注释掉,同样的道理,如果你仅仅想保存到数据库,就将前者注释掉,当然,你可以两者都实现保存,就不用注释任何一个。对于上面的含义,cnblog.pipelines.FilePipeline其实就是应用cnblog/pipelines模块里面的FilePipeline类,就是我们之前写的那个,300和400的含义是执行顺序,因为我们这里既要保存到文件,也要保存到数据库,那就定义一个顺序,这里的设置就是先执行保存到文件,在执行保存到数据库,数字是0-1000,你可以自定义。
运行爬虫
进入到项目文件,执行
scrapy crawl cnblog
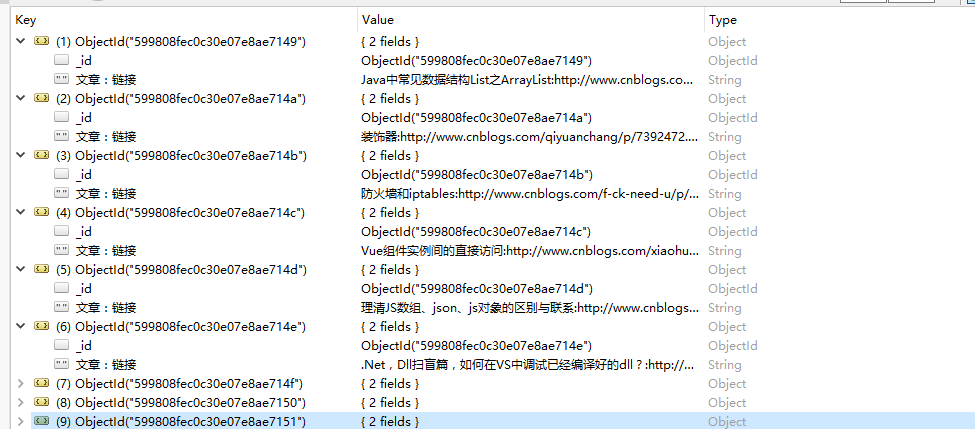
可以看到根目录下生成了cnblog.txt的文件,mongo数据库也新增了相应的内容。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号