
Linux 笔记 - 第十八章 Linux 集群之(三)Keepalived+LVS 高可用负载均衡集群
一、前言
前两节分别介绍了 Linux 的高可用集群和负载均衡集群,也可以将这两者相结合,即 Keepalived+LVS 组成的高可用负载均衡集群,Keepalived 加入到 LVS 中的原因有以下几点:
1)LVS 拥有一个很关键的角色 Dir(分发器),如果分发器宕机,所有的服务和访问都将会中断。因为入口全部都在 Dir 上,所以需要对分发器做高可用,使用 Keepalived 来实现高可用,Keepalived 其实也具有负载均衡的作用。
2)在使用 LVS 时,如果没有其他额外的操作,把其中一个 Real Server 关机,再去访问是会出现问题的,因为 LVS 依然会把请求转发给已经宕机的服务器,Keepalived 的出现 就可以解决这个问题,即使有一台 Real Server 宕机了,它也能正常提供服务,当请求分发过来时它能够自动检测到后端的 Real Server 宕机,就不会再把请求继续转发到有问题的 Real Server 上。
一个完整的 Keepalived+LVS 架构至少需要有两台调度器(角色为 Dir),分别安装 Keepalived 来实现高可用。Keepalived 内置了 ipvsadm 功能,所以不需要再安装 ipvsadm 包,也不用编写和执行 lvs_dir.sh 脚本。

二、创建 Keepalived+LVS 高可用负载均衡集群
以下使用 Keepalived+LVS 来实现高可用负载均衡集群。
2.1 准备集群节点
准备4台服务器,其中两台作为主备分发器(也叫作调度器,简称 Dir),均安装 Keepalived 服务,另外两台是 Real Server,均安装 nginx 服务,用作处理用户请求的服务器。
主机名 masternode:主调度器,网卡 IP 是 192.168.93.140 是内网(VMWare 网络地址转换 NAT)。
主机名 backupnode:备用调度器,网卡 IP 是 192.168.93.139 是内网(VMWare 网络地址转换 NAT)。
主机名 datanode1:Real Server 1,IP 为 192.168.93.141。
主机名 datanode2:Real Server 2,IP 为 192.168.93.142。
VIP:192.168.93.200
为4台服务器分别设置好 IP 地址和主机名,并关闭防火墙。
2.2 设置 master 主服务器的 Keepalived
编辑配置文件 /etc/keepalived/keepalived.conf,设置为如下内容:
[root@masternode keepalived]# vim /etc/keepalived/keepalived.conf ! Configuration File for master node keepalived global_defs { notification_email { admin@moonxy.com } notification_email_from root@moonxy.com smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id LVS_DEVEL } vrrp_instance VI_1 { state MASTER #绑定VIP的网卡为ens33 interface ens33 virtual_router_id 51 #设置主服务器优先级为100 priority 100 advert_int 1 authentication { auth_type PASS auth_pass moonxy } virtual_ipaddress { 192.168.93.200 } } virtual_server 192.168.93.200 80 { #每隔10秒钟检查一次Real Server状态 delay_loop 6 #LVS 负载均衡算法 lb_algo rr #LVS DR 模式 lb_kind DR #同一个IP的连接多少秒内被分配到同一台Real Server上,此处设置为0 persistence_timeout 0 #用TCP协议检查Real Server状态 protocol TCP real_server 192.168.93.141 80 { #权重 weight 100 TCP_CHECK { #10秒无响应超时 connect_timeout 10 nb_get_retry 3 delay_before_retry 3 connect_port 80 } } real_server 192.168.93.142 80 { #权重 weight 100 TCP_CHECK { #10秒无响应超时 connect_timeout 10 nb_get_retry 3 delay_before_retry 3 connect_port 80 } } }
主服务器好的配置文件和备份服务器的配置文件的设置基本相同,将 state 设置为 BACKUP,将 priority 设置为 90
2.3 设置 backup 备份服务器的 Keepalived
编辑配置文件 /etc/keepalived/keepalived.conf,设置为如下内容:
[root@backupnode keepalived]# vim /etc/keepalived/keepalived.conf ! Configuration File for master node keepalived global_defs { notification_email { admin@moonxy.com } notification_email_from root@moonxy.com smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id LVS_DEVEL } vrrp_instance VI_1 { state BACKUP #绑定VIP的网卡为ens33 interface ens33 virtual_router_id 51 #设置备用服务器优先级为90 priority 90 advert_int 1 authentication { auth_type PASS auth_pass moonxy } virtual_ipaddress { 192.168.93.200 } } virtual_server 192.168.93.200 80 { #每隔10秒钟检查一次Real Server状态 delay_loop 6 #LVS 负载均衡算法 lb_algo rr #LVS DR 模式 lb_kind DR #同一个IP的连接多少秒内被分配到同一台Real Server上,此处设置为0 persistence_timeout 0 #用TCP协议检查Real Server状态 protocol TCP real_server 192.168.93.141 80 { #权重 weight 100 TCP_CHECK { #10秒无响应超时 connect_timeout 10 nb_get_retry 3 delay_before_retry 3 connect_port 80 } } real_server 192.168.93.142 80 { #权重 weight 100 TCP_CHECK { #10秒无响应超时 connect_timeout 10 nb_get_retry 3 delay_before_retry 3 connect_port 80 } } }
如果在之前执行过 LVS 的脚本,需要提前执行一些操作:
# ipvsadm -C
# systemctl restart network
或者可重启调度服务器。
2.4 启动相关服务
在 masternode 和 backupnode 上面分别启动 keepalived 服务,如下:
masternode:
[root@masternode log]# systemctl start keepalived [root@masternode log]# ps aux |grep keepalived root 7204 0.0 0.1 122876 1368 ? Ss 00:46 0:00 /usr/sbin/keepalived -D root 7205 0.0 0.3 133840 3360 ? S 00:46 0:00 /usr/sbin/keepalived -D root 7206 0.0 0.2 133776 2636 ? S 00:46 0:00 /usr/sbin/keepalived -D root 7215 0.0 0.0 112708 980 pts/0 R+ 00:58 0:00 grep --color=auto keepalived [root@masternode log]# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:3b:90:07 brd ff:ff:ff:ff:ff:ff inet 192.168.93.140/24 brd 192.168.93.255 scope global noprefixroute ens33 valid_lft forever preferred_lft forever inet 192.168.93.200/32 scope global ens33 valid_lft forever preferred_lft forever inet6 fe80::1bb9:5b87:893c:e112/64 scope link noprefixroute valid_lft forever preferred_lft forever 3: ens37: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:3b:90:11 brd ff:ff:ff:ff:ff:ff inet 192.168.150.140/24 brd 192.168.150.255 scope global noprefixroute ens37 valid_lft forever preferred_lft forever inet6 fe80::20c:29ff:fe3b:9011/64 scope link valid_lft forever preferred_lft forever [root@masternode log]# ipvsadm -Ln IP Virtual Server version 1.2.1 (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 192.168.93.200:80 rr -> 192.168.93.141:80 Route 100 0 0 -> 192.168.93.142:80 Route 100 0 0
backupnode:
[root@backupnode keepalived]# systemctl start keepalived [root@backupnode keepalived]# ps aux |grep keepalived root 7185 0.0 0.1 122876 1376 ? Ss 00:47 0:00 /usr/sbin/keepalived -D root 7186 0.0 0.3 133840 3364 ? S 00:47 0:00 /usr/sbin/keepalived -D root 7187 0.0 0.2 133776 2640 ? S 00:47 0:00 /usr/sbin/keepalived -D root 7189 0.0 0.0 112708 980 pts/0 S+ 00:47 0:00 grep --color=auto keepalived [root@backupnode keepalived]# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:88:29:9b brd ff:ff:ff:ff:ff:ff inet 192.168.93.139/24 brd 192.168.93.255 scope global noprefixroute ens33 valid_lft forever preferred_lft forever inet6 fe80::8055:62bc:4a07:d345/64 scope link tentative noprefixroute dadfailed valid_lft forever preferred_lft forever inet6 fe80::1bb9:5b87:893c:e112/64 scope link tentative noprefixroute dadfailed valid_lft forever preferred_lft forever inet6 fe80::8cac:8f3b:14b2:47ae/64 scope link noprefixroute valid_lft forever preferred_lft forever 3: ens37: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:88:29:a5 brd ff:ff:ff:ff:ff:ff inet 192.168.150.139/24 brd 192.168.150.255 scope global noprefixroute ens37 valid_lft forever preferred_lft forever inet6 fe80::20c:29ff:fe88:29a5/64 scope link valid_lft forever preferred_lft forever [root@backupnode keepalived]# ipvsadm -Ln IP Virtual Server version 1.2.1 (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 192.168.93.200:80 rr -> 192.168.93.141:80 Route 100 0 0 -> 192.168.93.142:80 Route 100 0 0
可以看到此时 VIP:192.168.93.200 绑定在了 masternode 的网卡 ens33 上。
由于在 Keepalived 的配置文件中定义的 LVS 模式为 DR,所以还需要在两台 RS 上分别执行 lvs_rs.sh 脚本,这与上一节的脚本相同,如下:
[root@datanode1 sbin]# service nginx start Redirecting to /bin/systemctl start nginx.service [root@datanode1 sbin]# sh /usr/local/sbin/lvs_rs.sh ...... [root@datanode2 sbin]# service nginx start Redirecting to /bin/systemctl start nginx.service [root@datanode2 sbin]# sh /usr/local/sbin/lvs_rs.sh
相关服务启动完毕之后,可执行测试。
2.5 测试高可用负载均衡集群
在宿主机上请求 VIP 地址:192.168.93.200,如下:
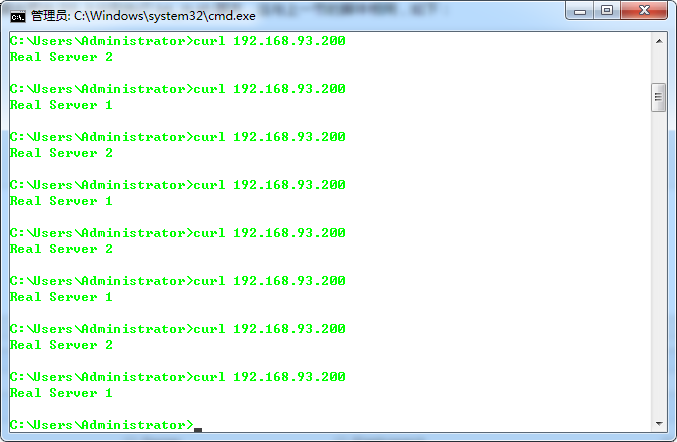
可以看到实现了负载均衡的效果。
1)测试关闭两台调度器中的 maternode 主调度器
再来看看分发器的高可用,关闭 masternode 主分发器,如下:
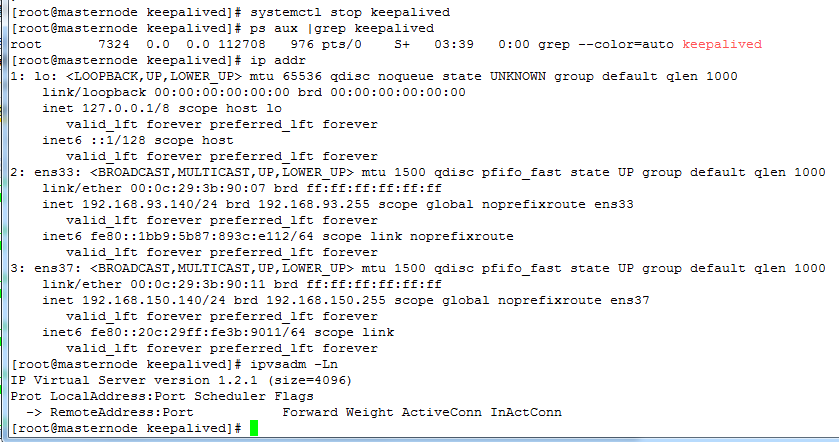
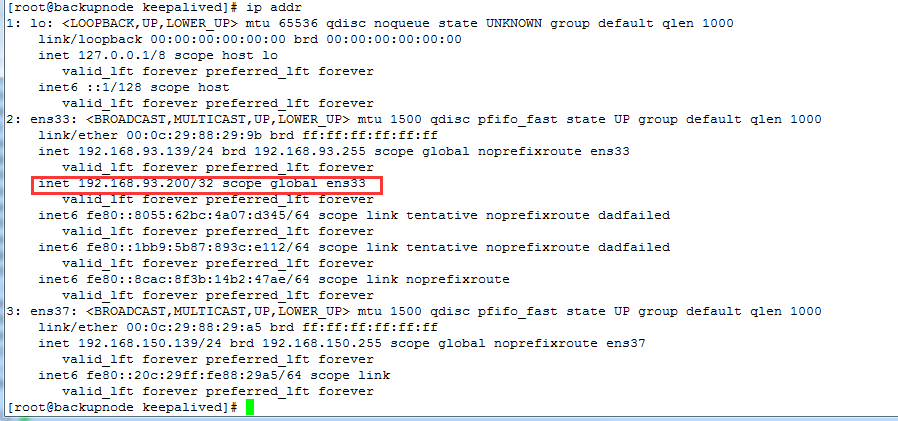
可以看到 masternode 已经解除了 VIP 地址的绑定,backupnode 自动绑定了这个 VIP,如下:
再次请求 VIP 地址,如下正常显示:

2)测试关闭 Real Server 中的 datanode2 的 nginx 服务
现在我们再关闭 RS 中的 datanode2 的 nginx,如下:

访问 VIP 地址,看到了 Keepalived 已经自动将所有请求都转发到了 datanode1 上面了,如下:

ipvsadm 转发规则会自动将 "删除" datanode2,如下:

3)测试再次启动 Real Server 中的 datanode2 的 nginx
如果再次启动 datanode2 上面的 nginx 服务,此时 ipvsadm 又会自动添加其转发规则,如下:

访问 VIP,如下:
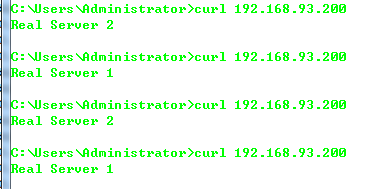
可以发现 Keepalived 功能确实很强大。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号