python----基础之可变、不可变数据类型、collections模块
可变与不可变类型
截止到目前,已经写了很多数据类型了:数字类型,字符串类型,列表类型,元祖类型,字典类型,集合类型。
在python中,我们对数据类型还有另外一种分类方式,我们把数据类型分为可变数据类型和不可变数据类型。
可变、不可变类型指的是id不变,type不变的前提下,value是否可变。
我们先来看看分类情况:
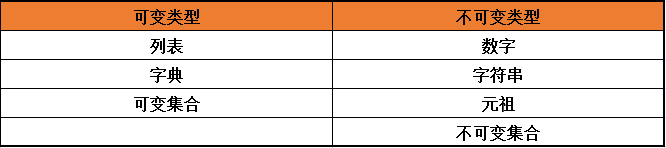
列表:
>>> w = [1,2,3,4,5] >>> id(w) 31768864 >>> w[1]=22.2 >>> w [1, 22.2, 3, 4, 5] >>> id(w) 31768864
字典:
>>> a = {"name":"ike","age":18}
>>> a
{'name': 'ike', 'age': 18}
>>> id(a)
31318400
>>> a['age']=28
>>> a
{'name': 'ike', 'age': 28}
>>> id(a)
31318400
数字:
>>> a = 21 >>> id(a) 1382081616 >>> a += 1 >>> id(a) 1382081632
字符串:
>>> q = 'hello' >>> id(q) 36322528 >>> q += ' world' >>> q 'hello world' >>> id(q) 36356848
>>> q = 'hello'
>>> w = q.replace('h','H')
>>> q
'hello'
>>> w
'Hello'
当我们调用q.replace('h', 'H')时,实际上调用方法replace是作用在字符串对象'hello'上的,而这个方法虽然名字叫replace,但却没有改变字符串'hello'的内容。相反,replace方法创建了一个新字符串'Hello'并返回,如果我们用变量w指向该新字符串,就容易理解了,变量q仍指向原有的字符串'hello',但变量w却指向新字符串'Hello'了.
元祖不可以修改--前边已经说过
>>> t = (1,2) >>> t(0) = 5 File "<stdin>", line 1 SyntaxError: can't assign to function call
enumerate(补充)
enumerate函数用于遍历序列中的元素以及它们的下标,多用于在for循环中得到计数,enumerate参数为可遍历的变量,如 字符串,列表等..
语法:
enumerate(sequence, [start=0])
参数:
- sequence -- 一个序列、迭代器或其他支持迭代对象。
- start -- 下标起始位置。
返回值:返回 enumerate(枚举) 对象。
>>> seasons = ['Spring', 'Summer', 'Fall', 'Winter'] >>> list(enumerate(seasons)) [(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')] >>> list(enumerate(seasons, start=1)) [(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
# 普通for循环 >>> i = 0 >>> seq = ['one', 'two', 'three'] >>> for element in seq: ... print(i, seq[i]) ... i +=1 ... 0 one 1 two 2 three
# enumerate循环 >>> seq ['one', 'two', 'three'] >>> for index, element in enumerate(seq): ... print(index, element) ... 0 one 1 two 2 three
collections模块
collections模块在内置数据类型(dict、list、set、tuple)的基础上,还提供了几个额外的数据类型:ChainMap、Counter、deque、defaultdict、namedtuple和OrderedDict等。
1.namedtuple: 生成可以使用名字来访问元素内容的tuple子类
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
3.Counter: 计数器,主要用来计数
4.OrderedDict: 有序字典
5.defaultdict: 带有默认值的字典
我们知道tuple可以表示不变集合,例如,一个点的二维坐标就可以表示成:
>>> p = (1, 2)
但是,看到(1, 2),很难看出这个tuple是用来表示一个坐标的。
定义一个class又小题大做了,这时,namedtuple就派上了用场:
>>> from collections import namedtuple >>> point=namedtuple('point',['x','y']) >>> p = point(1,2) >>> p.x 1 >>> p.y 2
namedtuple是一个函数,它用来创建一个自定义的tuple对象,并且规定了tuple元素的个数,并可以用属性而不是索引来引用tuple的某个元素。
这样一来,我们用namedtuple可以很方便地定义一种数据类型,它具备tuple的不变性,又可以根据属性来引用,使用十分方便。
可以验证创建的Point对象是tuple的一种子类:
>>> isinstance(p, point) True >>> isinstance(p, tuple) True
类似的,如果要用坐标和半径表示一个圆,也可以用namedtuple定义:
# namedtuple('名称', [属性list]): Circle = namedtuple('Circle', ['x', 'y', 'r'])
deque
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈:
>>> from collections import deque >>> q = deque(['a','b','c']) >>> q.append('w') >>> q.appendleft('y') >>> q deque(['y', 'a', 'b', 'c', 'w'])
deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
defaultdict
使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict:
>>> from collections import defaultdict >>> dd = defaultdict(lambda: 'N/A') >>> dd['key1']='abc' >>> dd['key1'] 'abc' >>> dd['key2'] 'N/A'
注意默认值是调用函数返回的,而函数在创建defaultdict对象时传入。
除了在Key不存在时返回默认值,defaultdict的其他行为跟dict是完全一样的。
OrderedDict
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。
如果要保持Key的顺序,可以用OrderedDict:
>>> from collections import OrderedDict >>> d = dict([('a', 1), ('b', 2), ('c', 3)]) >>> d # dict的Key是无序的 {'a': 1, 'c': 3, 'b': 2} >>> od = OrderedDict([('a', 1), ('b', 2), ('c', 3)]) >>> od # OrderedDict的Key是有序的 OrderedDict([('a', 1), ('b', 2), ('c', 3)])
注意,OrderedDict的Key会按照插入的顺序排列,不是Key本身排序:
>>> od = OrderedDict() >>> od['z'] = 1 >>> od['y'] = 2 >>> od['x'] = 3 >>> od.keys() # 按照插入的Key的顺序返回 ['z', 'y', 'x']
OrderedDict可以实现一个FIFO(先进先出)的dict,当容量超出限制时,先删除最早添加的Key:
from collections import OrderedDict class LastUpdatedOrderedDict(OrderedDict): def __init__(self, capacity): super(LastUpdatedOrderedDict, self).__init__() self._capacity = capacity def __setitem__(self, key, value): containsKey = 1 if key in self else 0 if len(self) - containsKey >= self._capacity: last = self.popitem(last=False) print 'remove:', last if containsKey: del self[key] print 'set:', (key, value) else: print 'add:', (key, value) OrderedDict.__setitem__(self, key, value)
Counter
Counter是一个简单的计数器,例如,统计字符出现的个数:
>>> from collections import Counter >>> c = Counter() >>> for ch in 'running': ... c[ch] = c[ch] + 1 ... >>> c Counter({'n': 3, 'r': 1, 'u': 1, 'i': 1, 'g': 1})


 浙公网安备 33010602011771号
浙公网安备 33010602011771号