并发编程
操作系统的发展史
多道技术(基于单核背景下产生的)
并发与并行(!!!)
进程
1、什么是进程
2、进程与程序
3、进程调度(了解)
同步与异步(!!!)
阻塞与非阻塞(!!!)
进程的三种状态(!!!)
创建进程的两种方式
并发编程
操作系统的发展史
- 穿孔卡片
- 读取数据速度特别慢
- CPU的利用率极低
- 单用户(一份代码)使用
- 批处理
- 读取数据速度特别慢
- CPU的利用率极低
- 联机(多份代码)使用
- 效率还是很低
- 脱机批处理(现代操作系统的设计原理)
- 读取数据速度提高
- CPU的利用率提高
多道技术(基于单核背景下产生的)
单道:一条道走到黑
- 比如:a,b需要使用cpu,a先使用,b等待a使用完毕后,b才能使用cpu。
多道:(!!!)
- 比如a,b需要使用cpu,a先使用,b等待a,直到a进入“IO或执行时间过长”a会(切换 + 保存状态),然后b可以使用cpu,待b执行遇到 “IO或执行时间过长”再将cpu执行权限交给a,直到两个程序结束。(简而言之就是一个cpu轮流被多个程序使用)
- 空间上的复用(!!!)
- 多个程序使用一个CPU
- 时间上的复用(!!!)
- 切换 + 保存状态
- 优点:CPU的执行效率提高,当执行程序遇到IO时,操作系统会将CPU的执行权限剥夺。
- 缺点:程序的执行效率低,当执行程序执行时间过长时,操作系统会将CPU的执行权限剥夺。
并发与并行(!!!)
并发:
指的是看起来像同时在运行,多个程序不停 切换+保存状态
在单核(一个CPU)情况下,当执行两个a,b程序时,a先执行,当a遇到IO时,b开始争抢cpu的执行权限,再让b执行,他们看起像同时运行。
并行:
真正意义上的同时运行,在多核(多个CPU)的情况下,同时执行多个程序
在多核(多个cpu)的情况下,当执行两个a,b程序时,a与b同时执行。他们是真正意义上的同时运行。
进程
1、什么是进程
进程是一个资源单位
2、进程与程序
程序:一对代码文件
进程:执行代码的过程,称之为进程
3、进程调度(了解)
- 先来先服务调度算法(了解)
- 比如程序a,b,若a先来,则让a先服务,待a服务完毕后,b再服务。
- 缺点:执行效率低
- 短作业优先调度算法(了解)
- 执行时间越短,则先调度
- 缺点:导致执行时间长的程序,需要等待所有时间短的程序执行完毕后,才能执行
现代操作的系统进程调度算法:时间片轮转法 + 多级反馈队列 (知道)
- 时间片轮转法
- 比如同时有10个程序需要执行,操作系统会给你10秒,然后时间片轮转法会将10秒分成10等分。
- 多级反馈队列
- 1级队列: 优先级最高,先执行次队列中程序。
2级队列: 优先级以此类推
3级队列:
- 1级队列: 优先级最高,先执行次队列中程序。
同步与异步(!!!)
同步与异步,指的是“提交任务的方式”。
同步:
两个a,b程序都要提交并执行,假如a先提交执行,b必须等a执行完毕后,才能提交任务。
异步:
两个a,b程序都要提交并执行,假如a先提交并执行,b无需等a执行完毕,就可以直接提交任务。
阻塞与非阻塞(!!!)
阻塞(等待):
凡是遇到IO都会阻塞
IO:input()
output()
time.sleep(3)
文件的读写
数据的传输
非阻塞(不等待):
除了IO都是非阻塞(比如:程序长时间执行)
进程的三种状态(!!!)
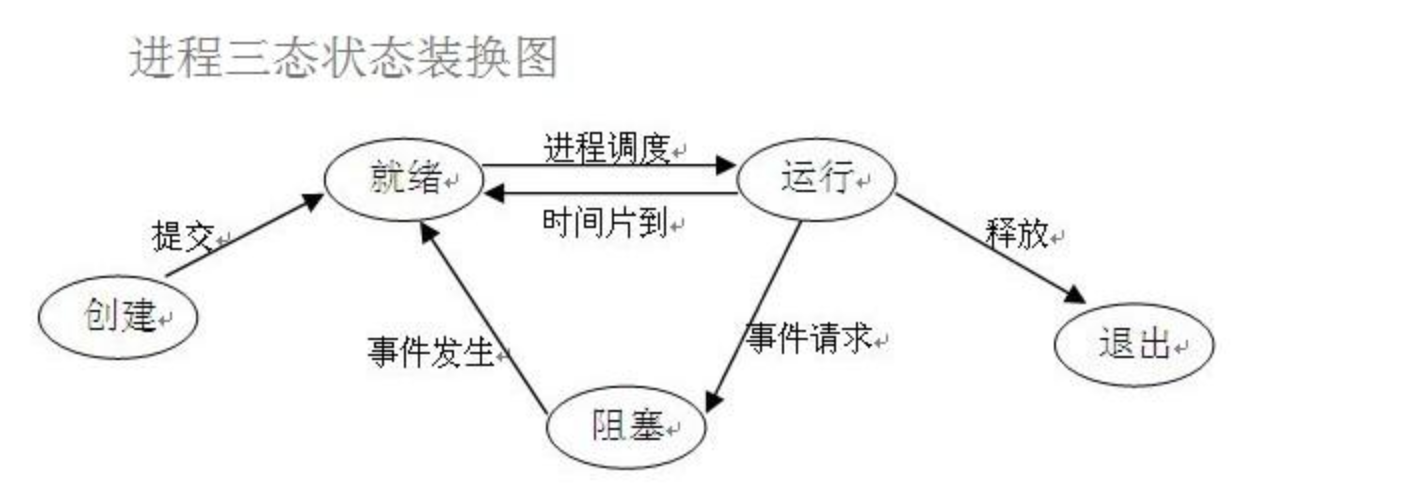
就绪态:
同步与异步
运行态:(程序的执行时间过长,会将程序返回给就绪态。)
指的是非阻塞的状态都是运行态
阻塞态:
指的是遇到IO时的状态
面试题:阻塞与同步是一样的吗?非阻塞与异步是一样的吗?
同步与异步 指的是提交任务时的方法
阻塞与非阻塞 指的是进程的状态
异步非阻塞:cpu的利用率最大化!
创建进程的两种方式
第一种:
from multiprocessing import Process
import time
# 方式一:直接调用Process
def task(name):
print(f'start...{name}的子进程')
time.sleep(3)
print(f'end....{name}的子进程')
# target=任务(函数地址) ---> 创建一个子进程
# 异步提交了三个任务
# p_obj1 = Process(target=task, args=('jason_sb',))
# p_obj1.start() # 告诉操作系统,去创建一个子进程
# p_obj1.start() # 告诉操作系统,去创建一个子进程
# p_obj1.start() # 告诉操作系统,去创建一个子进程
# p_obj1.start() # 告诉操作系统,去创建一个子进程
# p_obj1.start() # 告诉操作系统,去创建一个子进程
# p_obj1.start() # 告诉操作系统,去创建一个子进程
# p_obj1.start() # 告诉操作系统,去创建一个子进程
# p_obj1.start() # 告诉操作系统,去创建一个子进程
# p_obj1.start() # 告诉操作系统,去创建一个子进程
# p_obj1.start() # 告诉操作系统,去创建一个子进程
# p_obj1.join() # 告诉主进程,等待子进程结束后,再结束
# p_obj1.join() # 告诉主进程,等待子进程结束后,再结束
# p_obj1.join() # 告诉主进程,等待子进程结束后,再结束
# p_obj1.join() # 告诉主进程,等待子进程结束后,再结束
# p_obj1.join() # 告诉主进程,等待子进程结束后,再结束
# p_obj1.join() # 告诉主进程,等待子进程结束后,再结束
# p_obj1.join() # 告诉主进程,等待子进程结束后,再结束
# p_obj1.join() # 告诉主进程,等待子进程结束后,再结束
# p_obj1.join() # 告诉主进程,等待子进程结束后,再结束
# p_obj1.join() # 告诉主进程,等待子进程结束后,再结束
#
# p_obj2 = Process(target=task, args=('sean_sb',))
# p_obj2.start() # 告诉操作系统,去创建一个子进程
# p_obj2.join() # 告诉主进程,等待子进程结束后,再结束
#
# p_obj3 = Process(target=task, args=('大饼_sb',))
# p_obj3.start() # 告诉操作系统,去创建一个子进程
# p_obj3.join() # 告诉主进程,等待子进程结束后,再结束
# print('正在执行当前主进程...')
list1 = []
if __name__ == '__main__':
for line in range(10):
p_obj = Process(target=task, args=('我是进程',))
p_obj.start()
list1.append(p_obj)
for obj in list1:
obj.join()
print('主程序')
第二种实现方式
# 方式二:
from multiprocessing import Process
import time
class MyProcess(Process):
def run(self):
print(f'start...{self.name}的子进程')
time.sleep(3)
print(f'end...{self.name}的子进程')
if __name__ == '__main__':
list1 = []
for line in range(10):
obj = MyProcess()
obj.start()
list1.append(obj)
for obj in list1:
obj.join()
print('主进程...')强调:在Windows操作系统中由于没有fork(linux操作系统中创建进程的机制),在创建子进程的时候会自动 import 启动它的这个文件,而在 import 的时候又执行了整个文件。因此如果将process()直接写在文件中就会无限递归创建子进程报错。所以必须把创建子进程的部分使用if __name **==‘__main**’判断保护起来,import 的时候 ,就不会递归运行了。

