PCM数据解析
音频基础知识
声音的本质是空气压力差造成的空气振动,振动产生的声波可以在介质中快速传播,当声波到达接收端时(比如:人耳、话筒),引起相应的振动,最终被听到。
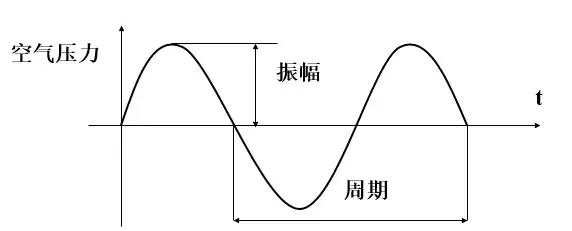
声音有两个基本属性:频率与振幅。声音的振幅就是音量,频率的高低就是音调,频率的单位是赫兹(Hz)。
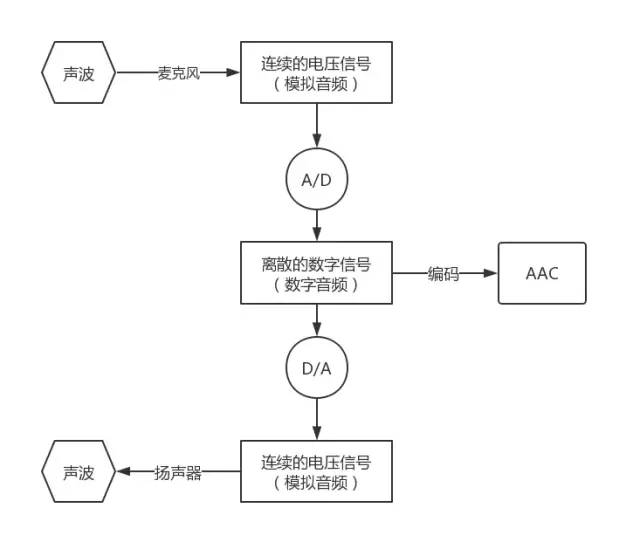
当声波传递到话筒时,话筒里的碳膜会随着声音一起振动,而碳膜下面是一个电极,碳膜振动时会触碰电极,接触时间的长短跟振动幅度有关(即:声音响度),这样就完成了声音信号到电压信号的转换。后面经过电路放大后,就得到了模拟音频信号。
模拟音频:用连续的电流或电压表示的音频信号,在时间和振幅上是连续。过去记录的声音都是模拟音频,比如:机械录音(以留声机、机械唱片为代表)、磁性录音(以磁带录音为代表)等模拟录音方式。
计算机不能直接处理连续的模拟信号,所以需要进行A/D转换,以一定的频率对模拟信号进行采样(就是获取一定时间间隔的波形振幅值,采样后模拟出的波形与原始波形之间的误差称为采样噪音),然后再进行量化和存储,就得到了数字音频。
数字音频:通过采样和量化获得的离散的、数字化的音频信号,即:计算机可以处理的二进制的音频数据。
相反的,当通过扬声器播放声音时,计算机内部的数字信号通过D/A转换,还原成了强弱不同的电压信号。这种强弱变化的电压会推动扬声器的振动单元产生震动,就产生了声音。整个流程可以用下图来表示:
PCM元数据
最常见的A/D转换是通过脉冲编码调制 PCM (Pulse Code Modulation)。要将连续的电压信号转换为PCM,需要进行采样和量化,我们一般从如下几个维度描述PCM:
-
采样频率(Sampling Rate):单位时间内采集的样本数,即:采样周期的倒数,指两个采样之间的时间间隔。采样频率越高,声音质量越好,但同时占用的带宽越大。一般情况下,22KHz相当于普通FM的音质,44KHz相当于CD音质,目前的常用采样频率都不超过48KHz。
-
采样位数:表示一个样本的二进制位数,即:每个采样点用多少比特表示。计算机中音频的量化深度一般为4、8、16、32位(bit)等。例如:采样位数为8 bit时,每个采样点可以表示256个不同的采样值,而采样位数为16 bit时,每个采样点可以表示65536个不同的采样值。采样位数的大小影响声音的质量,采样位数越多,量化后的波形越接近原始波形,声音的质量越高,而需要的存储空间也越多;位数越少,声音的质量越低,需要的存储空间越少。一般情况下,CD音质的采样位数是16 bit,移动通信是8 bit。
-
声道数:记录声音时,如果每次生成一个声波数据,称为单声道;每次生成两个声波数据,称为双声道(立体声)。单声道的声音只能使用一个喇叭发声,双声道的PCM可以使两个喇叭同时发声(一般左右声道有分工),更能感受到空间效果。
-
时长:采样时长,数字音频文件大小(Byte) = 采样频率(Hz)× 采样时长(S)×(采样位数 / 8)× 声道数(单声道为1,立体声为2)
采样点数据有有符号和无符号之分,比如:8 bit的样本数据,有符号的范围是-128 ~ 127,无符号的范围是0 ~ 255。大多数PCM样本使用整形表示,但是在一些对精度要求比较高的场景,可以使用浮点类型表示PCM样本数据。
下面看一个具体的采样示例:
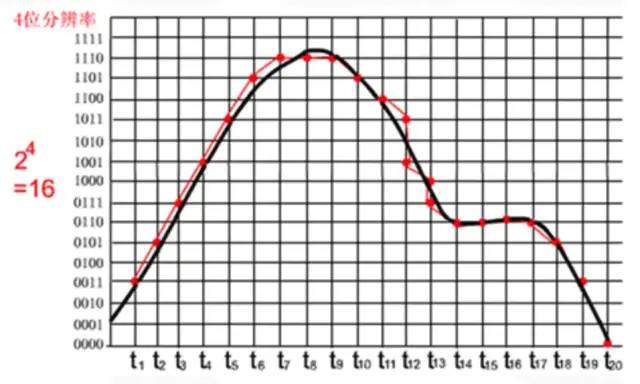
其中,黑色曲线表示要采集的声音波形,红色曲线表示采样量化后的PCM数据波形。上图中,采样位数是4 bit,每个红点对应一个Pcm采样数据,很明显:
-
采样频率越高,x轴采样点越密集,声音越接近原始数据。
-
采样位数越高,y轴量化越精确,声音越接近原始数据。
PCM数据存储
接下来看下PCM数据存储方式,如果是单声道音频,采样数据按照时间的先后顺序依次存储,如果是双声道音频,则按照LRLRLR方式存储,每个采样点的存储方式还与机器大小端有关。大端模式如下图所示:

Pcm文件没有头部信息,全部是采样量化后的未压缩音频数据。
PCM音量计算
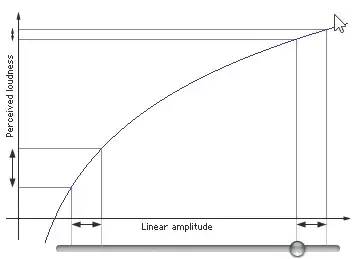
我们一般用分贝(db)描述声音响度。声学领域中,分贝的定义是声源功率与基准声源功率比值的对数乘以20的数值。根据人耳的特性,我们对声音的大小感知呈对数关系,而不是线性关系。
人类的听觉反应是基于声音的相对变化而非绝对变化。对数函数正好能模仿人耳对声音的反应。所以用分贝描述声音强度更符合人类对声音强度的感知。
如下图所示,横轴表示PCM采样值,纵轴表示人耳感知到的音量,图中截取了两块横轴变化相同的区域,但是人耳感觉到的音量变化是不一样的。
在较安静的左侧,感觉到的音量变化较大;在叫喧嚣的右侧,人耳感觉到的音量变化较小。
具体来说,分贝计算公式如下所示:
其中,表示两个采样值的比值。在计算某个采样值的分贝时,直接把当成最小采样值1处理就可以了。所以如果采样位数是16 bit,那么无符号情况下,最大分贝是:
有符号情况下,最大分贝是:
OK,了解了PCM格式和db计算方式之后,我们看下从音频文件提取db值的整体流程:


上述代码是通过MediaExtractor和MediaCodec解码音视频的标准流程,已经添加了详细的注释,我们看下基于PCM计算db的具体函数:
通过上述代码,我们可以基于解码出的PCM,计算出对应的db值,但是这种方式存在一个最大的缺点就是耗时严重,一个5分钟的音频,需要二三十秒,甚至更长,这完全是无法忍受的。我们不得不寻求更高效的解决方案。
跨平台
除了Android和iOS平台的多媒体框架,我们还可以基于FFmpeg实现跨平台的PCM数据提取。
FFmpeg是一个开源的跨平台多媒体框架,关于FFmpeg的介绍,网上的资料很多,这里就不再赘述了。
通过FFmpeg解码本地音视频文件,还是比较简单的,整体流程如下所示:
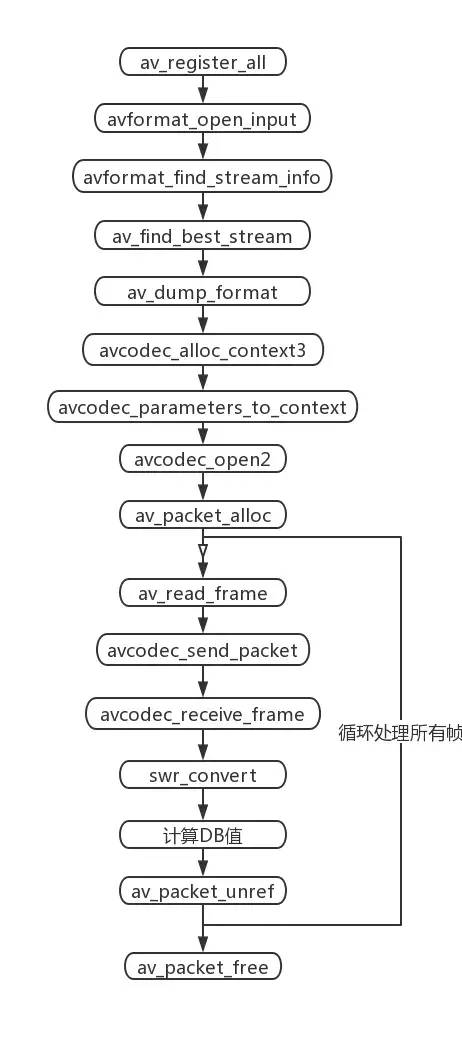
-
首先注册所有的解封装和封装格式
(av_register_all)。 -
接着打开本地文件,获取音频流信息(
avformat_open_input -> av_dump_format)。 -
其次创建解码音频流的解码上下文,并设置解码参数
(avcodec_alloc_context3 -> avcodec_open2)。 -
然后从本地文件读取音频裸流帧AVPacket,然后交给解码器解码,最后从解码器获取PCM原始数据帧AVFrame(
av_packet_alloc -> avcodec_receive_frame)。 -
因为FFmpeg解码出的PCM数据存储格式有很多种,所以我们会统一重采样到
AV_SAMPLE_FMT_S16P格式(swr_convert)。 -
最后针对重采样后的PCM数据计算出分贝值,并且释放各种资源。
不同于MediaCodec解码出的PCM是按照LRLRLR方式存储,FFmpeg解码出的PCM存储格式更加丰富,如下所示:
-
enum AVSampleFormat {
-
AV_SAMPLE_FMT_NONE = -1,
-
AV_SAMPLE_FMT_U8, ///< unsigned 8 bits
-
AV_SAMPLE_FMT_S16, ///< signed 16 bits
-
AV_SAMPLE_FMT_S32, ///< signed 32 bits
-
AV_SAMPLE_FMT_FLT, ///< float
-
AV_SAMPLE_FMT_DBL, ///< double
-
-
AV_SAMPLE_FMT_U8P, ///< unsigned 8 bits, planar
-
AV_SAMPLE_FMT_S16P, ///< signed 16 bits, planar
-
AV_SAMPLE_FMT_S32P, ///< signed 32 bits, planar
-
AV_SAMPLE_FMT_FLTP, ///< float, planar
-
AV_SAMPLE_FMT_DBLP, ///< double, planar
-
AV_SAMPLE_FMT_S64, ///< signed 64 bits
-
AV_SAMPLE_FMT_S64P, ///< signed 64 bits, planar
-
-
AV_SAMPLE_FMT_NB ///< Number of sample formats. DO NOT USE if linking dynamically
-
};
-
复制代码
除了有有符号和无符号的区别外,还可以是short、float和double类型,采样位数也可以是8 bit、16 bit、32 bit和64 bit。除此之外,即使同样是signed 16 bits,也存在Packed和Planar的区别。
对于双声道音频来说,Packed表示两个声道的数据交错存储,交织在一起,即:LRLRLRLR的存储方式;Planar 表示两个声道分开存储,也就是平铺分开,即:LLLLRRRR的存储方式。
通过MediaCodec解码出的PCM是按照Packed方式存储的,而FFmpeg解码出的PCM则可能是其中的任意一种。
所以为了更好的归一化处理,我们会对FFmpeg解码出的PCM进行重采样,统一采样成AV_SAMPLE_FMT_S16P格式,即:每个采样点是两字节的有符号short类型,并且按照Planar方式存储。
重采样:对PCM数据进行重新采样,可以改变它的声道数、采样率和采样格式。比如:原先的PCM音频数据是2个声道,44100采样率,32 bit单精度型。那么可以重采样成:2个声道,44100采样率,有符号short类型。
关于分贝值的计算,与上述基于Android平台的计算方式基本一致,此处就不再赘述了。
同一首5分钟的歌,通过FFmpeg提取PCM的耗时只有一两秒,提取效率至少提升了10倍以上,基本上与iOS持平,至此终于可以松一口气了。
PCM播放
PCM是原始采样数据,必须指定采样率、声道数和采样位数(大小端)才能播放。通过ffplay播放PCM的命令如下所示:
-
fplay -ar 44100 -channels 2 -f s16le -i test.pcm
-
-
参数说明:
-
1. -ar PCM采样率
-
2. -channels PCM通道数
-
3. -f PCM格式:sample_fmts + le(小端)或者be(大端)
-
sample_fmts可以通过ffplay -sample_fmts来查询
-
复制代码
除此之外,通过Audacity也可以直接播放PCM数据:文件 -> 导入 -> 原始数据,然后选择对应的采样率、声道数、采样位数和大小端就可以播放了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号