Warp
我们知道,NVIDIA的GPU中线程调度的基本单位是Warp,一个Warp包含32个线程。
Warp的出现是为了隐藏指令执行的时延。
假设执行指令如下,
add r2, r0, r1 // r0 + r1 -> r2
add r5, r3, r4 // r3 + r4 -> r5
load r6 [r5] // mem[r5] -> r6
mul r8 r6, r7 // r6 * r7 -> r8
我们先看没有Warp时的执行情况(假设load指令执行需要3个时钟),
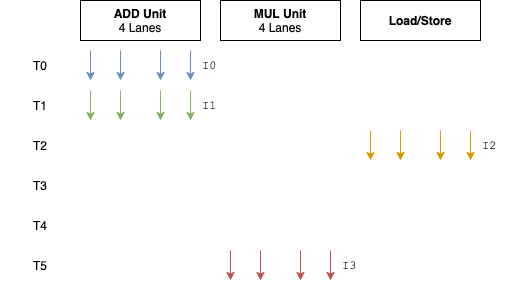
上图中,每个箭头代表一个执行的线程,不同的颜色代表不同的指令。因为ADD Unit有4个通道,也就是说可以同时进行4个加法操作,所以每个时钟周期可以同时完成4个线程的加法操作。我们可以称这样的执行方式为SIMT-4。
可以看到,T3和T4没有可执行的指令,执行流水线中出现“气泡”。
现引入Warp。
Warp0中包含4个线程:线程0、1、2、3;
Warp1中包含4个线程:线程4、5、6、7;
...
如果上面的4条指令来自于顶点着色程序,那么每个线程对应于一个顶点的着色程序。也就是说,如果待渲染的顶点数为8,那么需要创建2个Warp,每个Warp渲染4个顶点(4个线程)。
在Warp0执行到load指令时,切换到Warp1便可以让计算资源尽可能的忙起来,而不像之前每遇到长延时指令时流水线必“卡顿”。
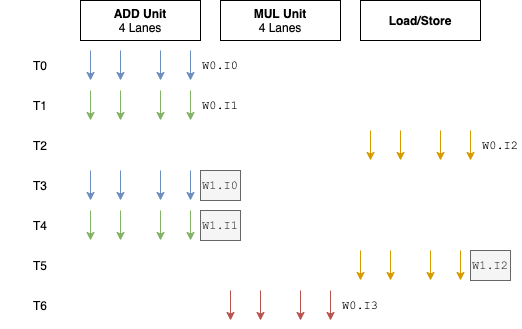
原先T3和T4没有硬件工作,而现在他们执行着Warp1的指令0和指令1.
执行效率得到了提升。
但是,如果执行Warp0的load指令时,发生了Cache Miss而导致3个时钟根本无法取回数据时,仍然会存在气泡存在,而这往往是比较常见的现象,如下图,
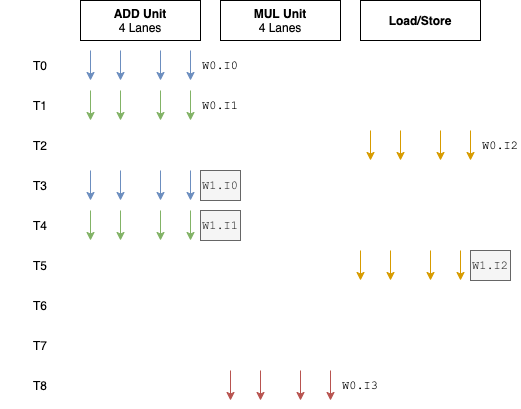
上图虽然只有T6和T7没有硬件工作,但真实的情况是,可能是数百个时钟。
在线程数量足够多的情况下,此时可以继续切换新的Warp来执行,和之前的做法一样。
这里,提供另外一种做法:增加一个Warp中的线程数量。
现在我们如果将一个Warp的线程数量从4提升到8,而硬件资源保持不变,执行情况会是这样,
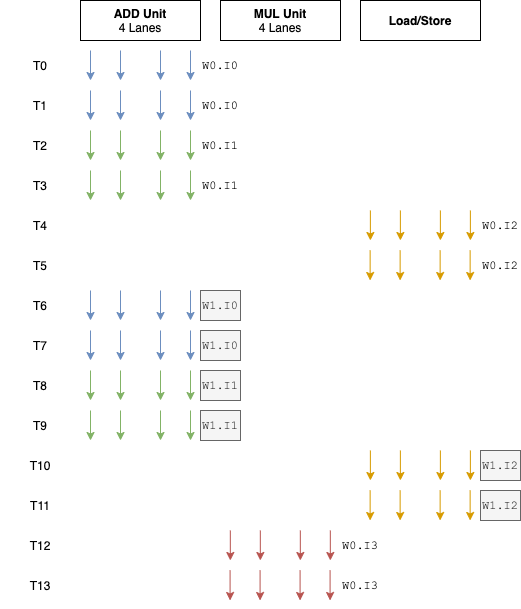
这可以很大程度减少“气泡”出现的概率。
除此之外,还有一个好处是:Warp的后4个线程执行时不再需要取指和译码。如下图,
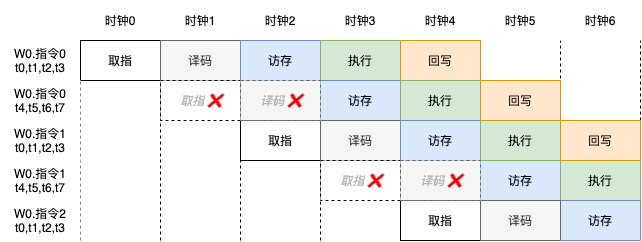
这样给取指和译码的优化提供了更多的可能,也就是你可以把取指和译码做的更加复杂,更进一步,可以把指令集设计的更加复杂,当然这并不一定是一个好的选择。
细心的你会发现,在T0时刻,只有ADD Unit工作,而另外两个硬件单元是空闲的,那怎样把他们也尽可能的用起来?
一种做法是每个时钟发射多条指令,也就是指令级并行。常见的做法有VLIW和超标量。
这里介绍另外一种NVIDIA的Fermi GPU的做法:同时发射两个Warp,如下图,
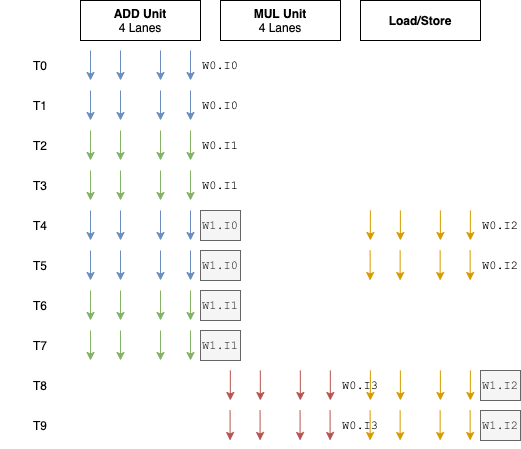
可以看到Warp1的指令0不需要等到T6再执行,在T4的时候就可以开始执行,从而提高了硬件利用率。
那到底Warp中线程数量的设置越大越好还是越小越好?
我们知道,NVIDIA的Warp大小是32个线程,AMD的Wavefront大小是64个线程,ARM的Quad大小是4/8/16个线程。其中Warp、Wavefront、Quad是不同厂商的不同叫法。
当Warp中线程数量设置较小时,可以减小遇到分支指令时的“惩罚”。下面我们介绍为什么。
影响SIMT执行效率的一个重要因素是:分支指令。假设一个包含分支指令的程序如下,
if (i > 0) {
r = a + b;
} else {
a = a + 1;
r = a + c;
}
r = r + 1;
如果Warp中的所有线程都满足i > 0,则分支判断后执行的指令为,
r = a + b;
r = r + 1;
如果Warp中的所有线程都不满足i > 0,则分支判断后执行的指令为,
a = a + 1;
r = a + c;
r = r + 1;
如果Warp中的线程1~10满足i > 0,而线程11~32不满足,那么执行的指令为,
r = a + b; // 线程1~10执行,线程11~32不执行
a = a + 1; // 线程1~10不执行,线程11~32执行
r = a + c; // 线程1~10不执行,线程11~32执行
r = r + 1;
可以看到,当一个Warp中的线程遇到分支指令执行到不同的分支时,执行效率会下降,不同分支中的指令数量较多的情况下效率下降尤其明显。
而当Warp中的线程数量较少时,线程走向不同分支的概率就会下降。
这就解释了为什么当Warp中线程数量设置较小时,可以减小遇到分支指令时的“惩罚”。
但Warp中线程数量设置较小时,会降低芯片面积的利用率。这个问题,读者可以自行思考一下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号