处理器执行流水线优化之多Warp切换
处理器的执行流水线通常分为5个阶段,分别为:取指、译码、访存、执行和写回。这里的访存指的是访问寄存器。
假设每个阶段只占用一个时钟周期,那么这个5级流水线的处理器每个时钟周期可以执行一条指令。如下图,
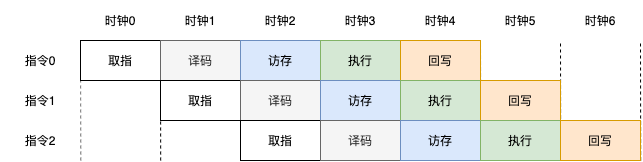
如果前一条指令的目的寄存器是当前指令的源寄存器,如:
add r2, r0, r1 // r0 + r1 -> r2
add r4, r2, r3 // r2 + r3 -> r4
那么,在前一条指令执行完成后将结果写回时,下一条指令不需要再访问寄存器文件,而可以直接使用上一条指令的执行结果,这个过程叫数据前送(data forwarding)。如下图,
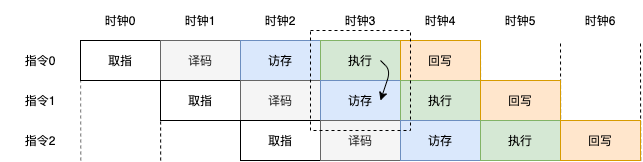
图中,指令0的执行结果在写回的同时,连同指令1的其他寄存器数据一同给到指令1的执行阶段,而指令1不需要再去寄存器文件中读取指令0的目的寄存器所指向的数据。
我们再看另外一种情况:当执行不能够一个时钟周期执行完成,而需要三个时钟周期。如下图,
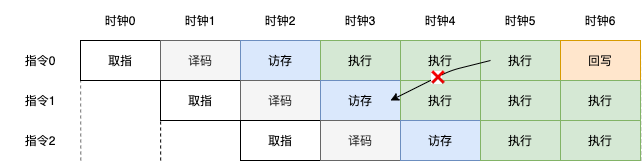
此时,如果仍然是每个时钟周期取一条新的指令来执行,那么数据前送将无法实现。
为了让数据前送仍然可行,一种做法是每三个时钟周期取一条指令。如下图,
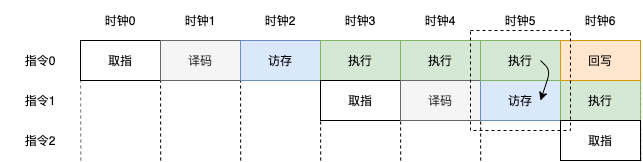
但这时流水线的执行效率降低。
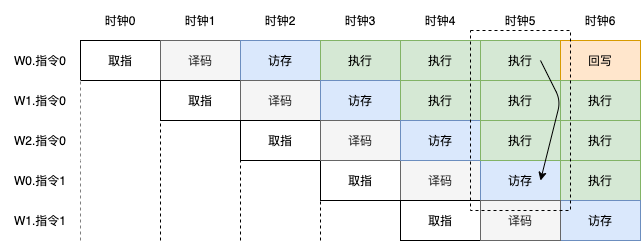
为了提高处理器的执行效率,我们需要想办法填充那些空闲的时钟周期。在SIMT处理器中,可以让其他Warp的指令来填充那些空闲的时钟周期,以提升处理器的执行效率。如下图,

 浙公网安备 33010602011771号
浙公网安备 33010602011771号