redis
1. 初始 redis
- Redis是一个使用C语言编写的,开源的高性能非关系型(NoSQL)的键值对数据库。
- Redis中存储的是键值对,值的类型有5种:string(字符串)、hash(哈希)、list(列表)、set(集合)、zset(有序集合)。
- Redis将所有数据都存放在内存中,所以读写性能非常好,Redis每秒可以处理超过10万次读写操作,是已知性能最快的Key-Value DB。因此Redis被广泛应用于缓存方向。
- Redis还可以将内存的数据利用快照和日志的形式进行持久化。
- Redis 也经常用来做分布式锁。
- 缓存
- 分布式锁
- 计数器
- 保存 token
- 消息队列
- 延迟队列
1. 安装 redis
1. windows 安装
官网:https://redis.io/
参考:https://blog.csdn.net/qq_40220309/article/details/125185615
2. linux 安装
linux 包下载:https://download.redis.io/releases/
安装过程:
# 1. 创建 redis 文件夹
cd /opt
mkdir redis
cd /redis
# 1. 下载
wget https://download.redis.io/releases/redis-7.4.7.tar.gz
# 2. 解压
tar -xzvf redis-7.4.7.tar.gz
cd redis-7.4.7/
# 3. 安装
make
make install
- 修改配置
vim redis.conf
常用配置项:
bind 127.0.0.1 # 绑定地址(0.0.0.0 允许远程访问)
protected-mode no # 关闭保护模式(用于远程访问)
requirepass yourpassword # 设置密码
daemonize yes # 后台运行
dir /var/lib/redis # 数据目录
- 尝试启动
cd /src
./redis-server ../redis.conf
- 尝试连接
# 客户端连接
./redis-cli -h 8.152.213.210 -p 6379
# 输入密码
8.152.213.210:6379> Auth 1234
- 创建服务
cd /etc/systemd/system
vim redis.service
[Unit] Description=Redis In-Memory Data Store After=network.target [Service] Type=forking User=root ExecStart=/opt/redis/redis-7.4.7/src/redis-server /opt/redis/redis-7.4.7/redis.conf ExecStop=/opt/redis/redis-7.4.7/src/redis-cli shutdown Restart=always PIDFile=/var/run/redis/redis-server.pid [Install] WantedBy=multi-user.target
这里参考服务创建:https://www.cnblogs.com/cnff/p/19166112#3-linux-服务
2. 五种基本数据类型
Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
参考菜鸟教程:https://www.runoob.com/redis/redis-tutorial.html
3. 三种衍生数据结构
- bitmaps:bitmaps 为一个以位为单位的数组,数组的每个单元只能存储 0 和 1。
- HyperLogLog:并不是一种数据结构,而是一种算法,可以利用极小的内存空间完成独立总数的统计。
- Geo:可以用于存储经纬度、计算两地之间的距离、范围计算等。其底层实现是 zset。
参考文档:https://www.cnblogs.com/rjzheng/p/9883375.html
4. reids 数据库
1. 登录
redis 登录:主机 + 密码
redis-cli -h
-p
如果有密码,需要通过验证:
auth "password"
2. 切换数据库
redis 一共有编号 0-15 的 16 个数据库,默认是 0。

通过 select 命令切换

3. 清空数据库
清空当前库:
flushdb
清空所有库:
flushall
5. 数据结构
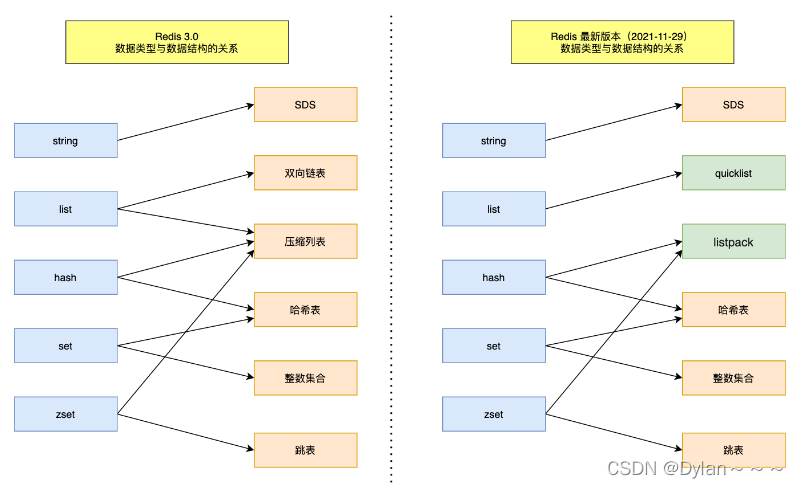
这个略显复杂,这里只是简单了解以下~
1. SDS

相比较与 C 语言的字符串,添加了几个属性:
SDS 结构设计:
len:字符串长度
alloc:分配的空间大小
flags:sds类型(sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64,它们数据结构中的 len 和 alloc 成员变量的数据类型不同)
buf[]:字节数组
总结:
-
1) SDS 不需要用 “\0” 字符来标识字符串结尾了,而是有个专门的 len 成员变量来记录长度,所以可存储包含 “\0” 的数据。但是 SDS 为了兼容部分 C 语言标准库的函数, SDS 字符串结尾还是会加上 “\0” 字符;
-
2)当判断出缓冲区大小不够用时,Redis 会自动将扩大 SDS 的空间大小(小于 1MB 翻倍扩容,大于 1MB 按 1MB 扩容),以满足修改所需的大小;
-
3)节省内存空间:SDS 结构中有个 flags 成员变量,表示的是 SDS 类型;
redis一共设计了 5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64;
这 5 种类型的主要区别就在于,它们数据结构中的 len 和 alloc 成员变量的数据类型不同。
之所以 SDS 设计不同类型的结构体,是为了能灵活保存不同大小的字符串,从而有效节省内存空间
2. 链表
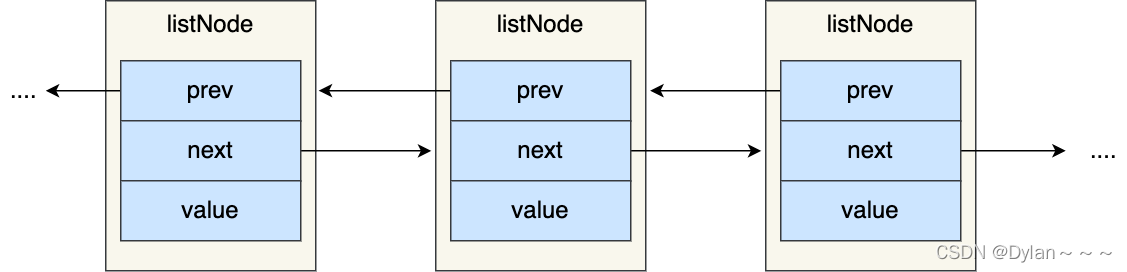
链表的优势:
- a、listNode 链表节点的结构里带有 prev 和 next 指针,获取某个节点的前置节点或后置节点的时间复杂度只需O(1),而且这两个指针都可以指向 NULL,所以链表是无环链表;
- b、list 结构因为提供了表头指针 head 和表尾节点 tail,所以获取链表的表头节点和表尾节点的时间复杂度只需O(1);
- c、list 结构因为提供了链表节点数量 len,所以获取链表中的节点数量的时间复杂度只需O(1);
- d、listNode 链表节使用 void* 指针保存节点值,并且可以通过 list 结构的 dup、free、match 函数指针为节点设置该节点类型特定的函数,因此链表节点可以保存各种不同类型的值;
链表的缺陷:
- a、链表每个节点之间的内存都是不连续的,意味着无法很好利用 CPU 缓存。能很好利用 CPU 缓存的数据结构就是数组,因为数组的内存是连续的,这样就可以充分利用 CPU 缓存来加速访问。
- b、还有一点,保存一个链表节点的值都需要一个链表节点结构头的分配,内存开销较大。
注:a、Redis 3.0 的 List 对象在数据量比较少的情况下,会采用「压缩列表」作为底层数据结构的实现,它的优势是节省内存空间,并且是内存紧凑型的数据结构; - b、压缩列表存在性能问题(具体什么问题,下面会说),所以 Redis 在 3.2 版本设计了新的数据结构 quicklist,并将 List 对象的底层数据结构改由 quicklist 实现;
- c、在 Redis 5.0 设计了新的数据结构 listpack,沿用了压缩列表紧凑型的内存布局,最终在最新的 Redis 版本,将 Hash 对象和 Zset 对象的底层数据结构实现之一的压缩列表,替换成由 listpack 实现。
3. 压缩列表
压缩列表的最大特点,就是它被设计成一种内存紧凑型的数据结构,占用一块连续的内存空间,不仅可以利用 CPU 缓存,而且会针对不同长度的数据,进行相应编码,这种方法可以有效地节省内存开销。
Redis 对象(List 对象、Hash 对象、Zset 对象)包含的元素数量较少,或者元素值不大的情况才会使用压缩列表作为底层数据结构。
设计思想是通过时间换空间,而时间的损耗又相对来说比小(小到几乎可以忽略)。
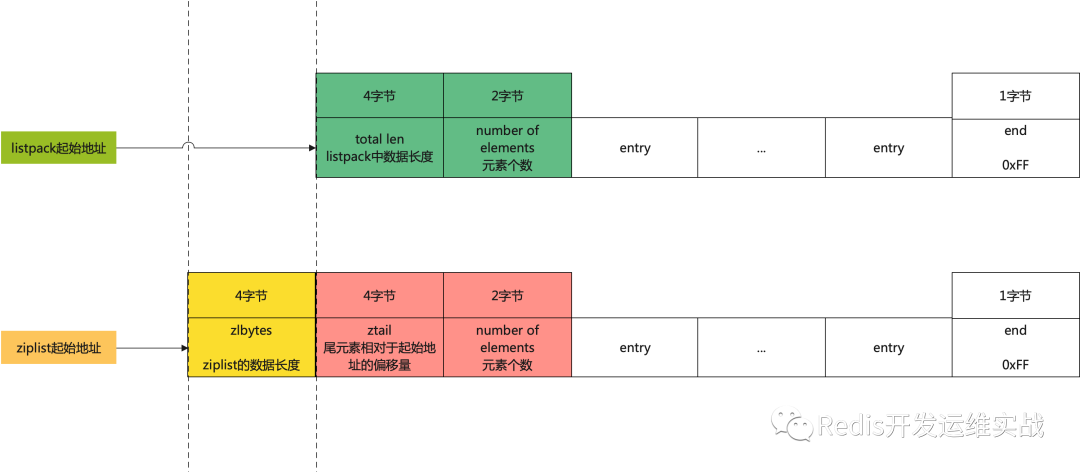
压缩列表的设计:
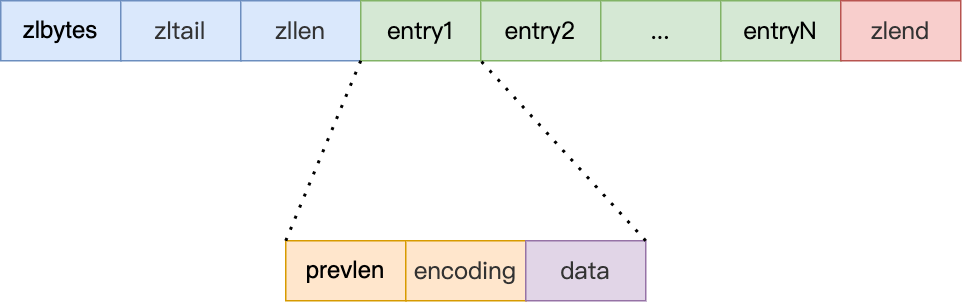
- a、zlbytes,记录整个压缩列表占用对内存字节数;
- b、zltail,记录压缩列表「尾部」节点距离起始地址由多少字节,也就是列表尾的偏移量;
- c、zllen,记录压缩列表包含的节点数量;
- d、zlend,标记压缩列表的结束点,固定值 0xFF(十进制255)。
在压缩列表中,如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段的长度直接定位,复杂度是 O(1)。而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N) 了,因此压缩列表不适合保存过多的元素。
压缩列表节点包含三部分内容:
a. prevlen,记录了「前一个节点」的长度;
b. encoding,记录了当前节点实际数据的类型以及长度;
c. data,记录了当前节点的实际数据;
连锁更新:
压缩列表新增某个元素或修改某个元素时,如果空间不不够,压缩列表占用的内存空间就需要重新分配。而当新插入的元素较大时,可能会导致后续元素的 prevlen 占用空间都发生变化,从而引起「连锁更新」问题,导致每个元素的空间都要重新分配,造成访问压缩列表性能的下降。
总结:
- ziplist是为了尽可能的节省存储空间,将数据进行紧凑的存储
- 修改操作耗费性能:ziplist在内存中是高度紧凑的连续存储,这意味着它对修改并不友好,如果要对ziplist做修改类的操作,那就需重新分配新的内存来存储新的ziplist,代价很大
- 添加和删除 ziplist 节点有可能会引起连锁更新,因此,添加和删除操作的最坏复杂度为 O(N^2),不过,因为连锁更新的出现概率并不高,所以一般可以将添加和删除操作的复杂度视为 O(N) 。
- 列表的节点之间并不是通过指针连接,而是记录上一个节点和本节点长度来寻址,内存占用较低。用当前的地址减去这个长度,就可以很容易的获取到了上一个节点的位置,通过一个一个节点向前回溯,来达到从表尾往表头遍历的操作
- 优点:
节省内存 - 缺点:
不能保存过多的元素,否则性能就会下降
不能保存过大的元素,否则容易导致内存重新分配,甚至引起连锁更新
4. 字典
哈希表(字典)是一种保存键值对(key-value)的数据结构,相当于 java 的 hashMap。
字典又称符号表,关联数组或者映射,是一种用于保存键值对的抽象数据结构。
hash 冲突:
跟 java 的 hashMap 一样,使用链表。
为什么要 rehash:
在key进行哈希计算得到hash值时,可能不同的key会得到相同的hash值,从而出现hash冲突,redis采用链地址法,把数组中同一下index下的所有数据,通过链表的形式进行关联。而redis中查找key的过程为: 首先对key进行hash计算并对数组长度取模得到数据所在的桶,在该桶下遍历链表来查找key。此时查找key的复杂度就取决于链表的长度,如果链表的长度为n,那么复杂度就为o(n),n越大查询效率就会越低。当数据个数越多,哈希表的hash冲突的概率就会越高,导致链表长度越长,查询效率越低,所以要进行rehash。
rehash 触发条件
rehash的触发条件主要跟哈希表的负载因子有关,负载因子的计算公式为:load_factor = ht[0].used / ht[0].size,就是 hash 表中节点数/hash表大小
- 扩容时rehash:当以下条件中的任意一个被满足时, 程序会自动开始对哈希表执行扩容rehash操作
a. 服务器目前没有在执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且哈希表的负载因子大于等于 1;
b. 服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且哈希表的负载因子大于等于 5; - 收缩时rehash:
a. 当哈希表的负载因子小于0.1时,程序自动开始对哈希表执行收缩操作
渐进式 rehash:
Java中的 HashMap 进行 rehash 是一次性完成的,而redis的扩展或收缩哈希表需要将 ht[0]里面的所有键值对 rehash 到 ht[1]里面,但是,这个 rehash 动作并不是一次性、集中式地完成的,而是分多次、渐进式地完成的。这样是为了避免在哈希表里保存的键值对数量很大时, 一次性将这些键值对全部 rehash 到 ht[1] 的话,庞大的计算量(需要重新计算链表在桶中的位置)可能会导致服务器在一段时间内停止服务(redis是单线程的,如果全部移动会引起客户端长时间阻塞不可用)。
因此, 为了避免 rehash 对服务器性能造成影响, 服务器不是一次性将 ht[0]里面的所有键值对全部 rehash 到 ht[1], 而是分多次、渐进式地将 ht[0]里面的键值对慢慢地 rehash 到 ht[1]。以下是哈希表渐进式rehash的详细步骤:
- 为ht[1]分配空间,让dict字典同时持有 ht[0] 和 ht[1] 两个哈希表。
- 在字典中维持一个索引计数器变量rehashidx,初始时值为-1,代表没有rehash操作,当rehash工作正式开始,会将它的值设置为0。
- 在rehash进行期间,每次对字典执行添加、删除、查找或者更新操作时,程序除了执行指定的操作以外,还会顺带将ht[0]哈希表在 rehashidx索引(table[rehashidx]桶上的链表)上的所有键值对rehash到ht[1]上,当rehash工作完成之后,将rehashidx属性的值+1,表示下一次要迁移链表所在桶的位置。
- 随着字典操作的不断执行,最终在某个时间点上,ht[0]的所有桶对应的键值对都会被rehash至ht[1],这时程序将rehashidx属性的值设为-1,表示rehash操作已完成。
渐进式 rehash 的好处在于它采取分而治之的方式, 将 rehash 键值对所需的计算工作均摊到对字典的每个添加、删除、查找和更新操作上, 从而避免了集中式 rehash 而带来的庞大计算量。
5. 整数集合
整数集合是 Set 对象的底层实现之一。当一个 Set 对象只包含整数值元素,并且元素数量不多时,就会使用整数集这个数据结构作为底层实现。
集合中的所有元素都可以转换成整数值,且长度小于512,使用整数集合,否则用哈希表。
整数集合结构定义如下:
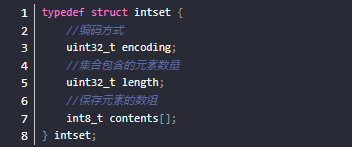
6. 跳表
链表在查找元素的时候,因为需要逐一查找,所以查询效率非常低,时间复杂度是O(N),于是就出现了跳表。跳表是在链表基础上改进过来的,实现了一种「多层」的有序链表,这样的好处是能快读定位数据。

跳表的优点:
跳表可以保证增、删、查等操作时的时间复杂度为O(logN),且维持结构平衡的成本比较低,完全依靠随机。而二叉查找树在多次插入删除后,需要Rebalance来重新调整结构平衡。
跳表的缺点:
跳表占用的空间比较大(多级索引),其实就是一种空间换时间的思想。
跳表的查询:
跳表的查找会从顶层链表的头部元素开始,然后遍历该链表,直到找到元素大于或等于目标元素的节点,如果当前元素正好等于目标,那么就直接返回它。如果当前元素小于目标元素,那么就垂直下降到下一层继续搜索,如果当前元素大于目标或到达链表尾部,则移动到前一个节点的位置,然后垂直下降到下一层。
7. quickList
在 Redis 3.0 之前,List 对象的底层数据结构是双向链表或者压缩列表。然后在 Redis 3.2 的时候,List 对象的底层改由 quicklist 数据结构实现。
其实 quicklist 就是「双向链表 + 压缩列表」组合,因为一个 quicklist 就是一个链表,而链表中的每个元素又是一个压缩列表。
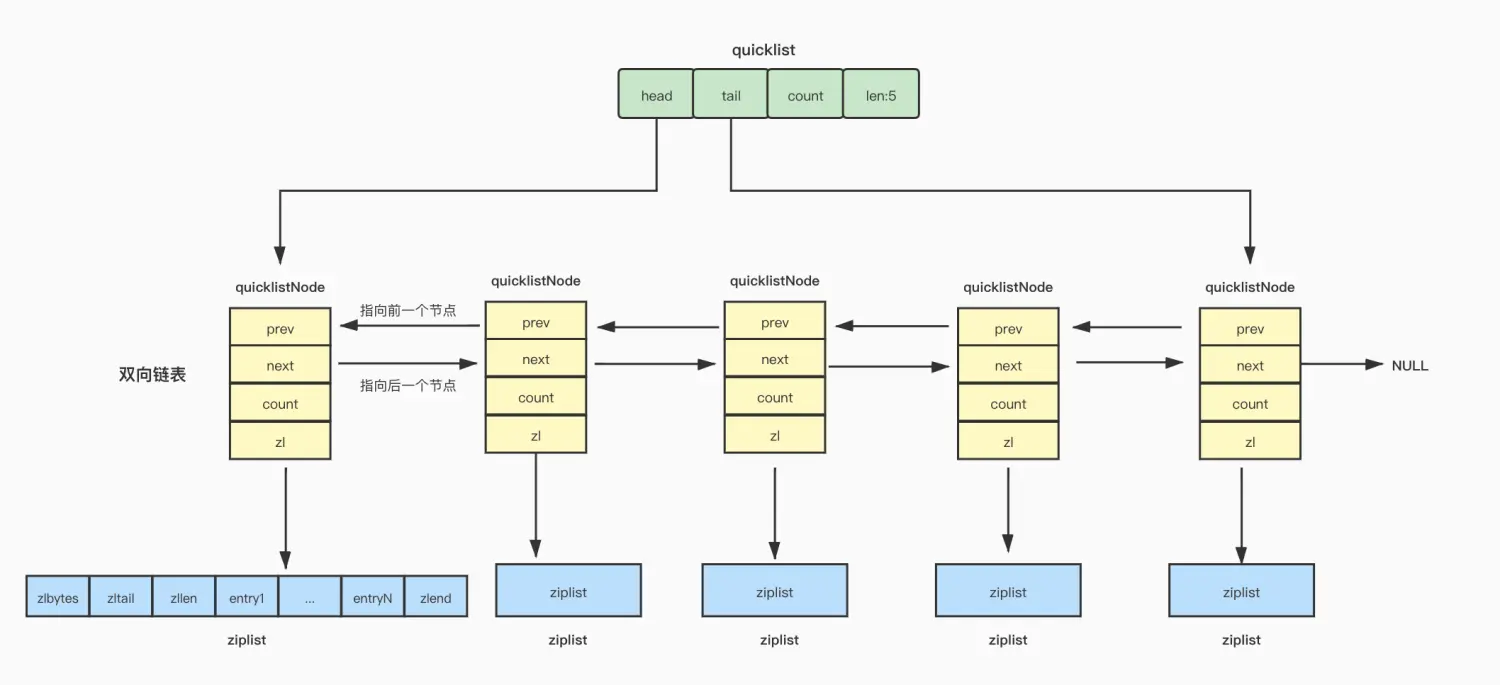
在前面讲压缩列表的时候,我也提到了压缩列表的不足,虽然压缩列表是通过紧凑型的内存布局节省了内存开销,但是因为它的结构设计,如果保存的元素数量增加,或者元素变大了,压缩列表会有「连锁更新」的风险,一旦发生,会造成性能下降。
quicklist 解决办法,通过控制每个链表节点中的压缩列表的大小或者元素个数,来规避连锁更新的问题。因为压缩列表元素越少或越小,连锁更新带来的影响就越小,从而提供了更好的访问性能。
8. listPack
Redis 在 5.0 新设计一个数据结构叫 listpack,目的是替代压缩列表,它最大特点是 listpack 中每个节点不再包含前一个节点的长度了,压缩列表每个节点正因为需要保存前一个节点的长度字段,就会有连锁更新的隐患。
listPack 结构:
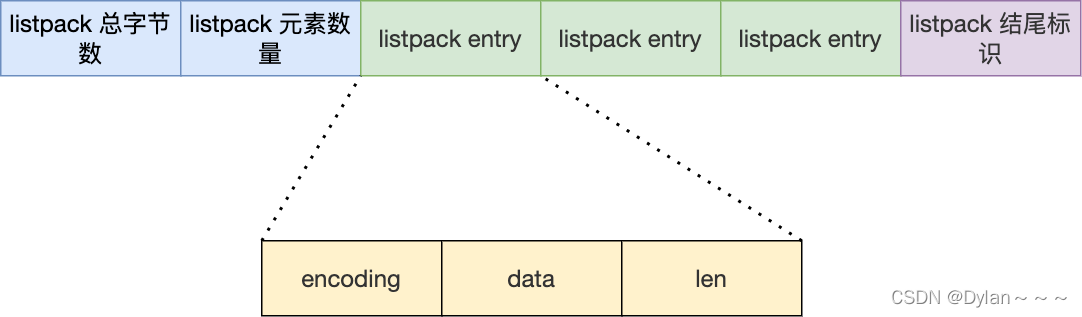
可以看到,listpack 没有压缩列表中记录前一个节点长度的字段了,listpack 只记录当前节点的长度,当我们向 listpack 加入一个新元素的时候,不会影响其他节点的长度字段的变化,从而避免了压缩列表的连锁更新问题。
listPack 和 zipList 整体对比:
6. 发布-订阅
Redis提供了发布订阅功能,可以用于消息的传输,Redis的发布订阅机制包括三个部分,发布者,订阅者和Channel。
发布者和订阅者都是Redis客户端,Channel则为Redis服务器端,发布者将消息发送到某个的频道,订阅了这个频道的订阅者就能接收到这条消息。Redis的这种发布订阅机制与基于主题的发布订阅类似,Channel相当于主题。
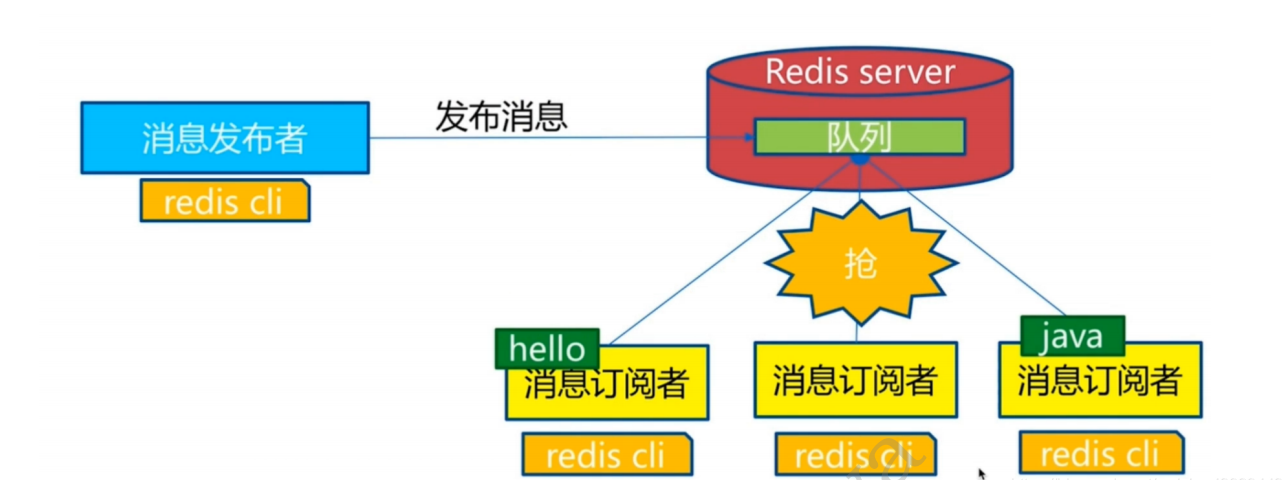
订阅主题:SUBSCRIBE + 频道
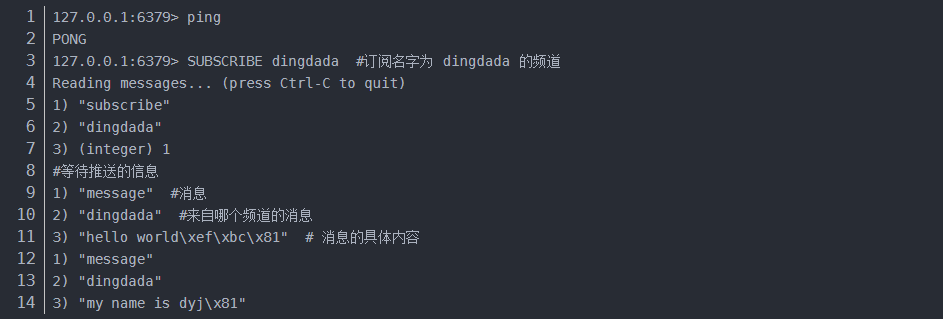
发布消息:PUBLISH + 频道 +消息

退订消息:PUNSUBSCRIBE
指示客户端退订指定模式,若果没有提供模式则退出所有模式。
7. 事务
Redis事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序执行。事务在执行的过程中,不会被其它客户端发送来的命令请求所打断。
Redis事务的主要作用就是串联多个命令防止别的命令插队。
1. 相关命令
Multi:开启事务,输入的命令都会依次进入命令队列中,但不会执行,直到输入Exec后
Exec:Redis会将之前命令队列中的命令依次执行。执行完事务结束
discard:组队过程中可以通过discard来放弃组队
2. 异常
-
组队中某个命令出现了报告错误,执行时整个的所有队列都会被取消
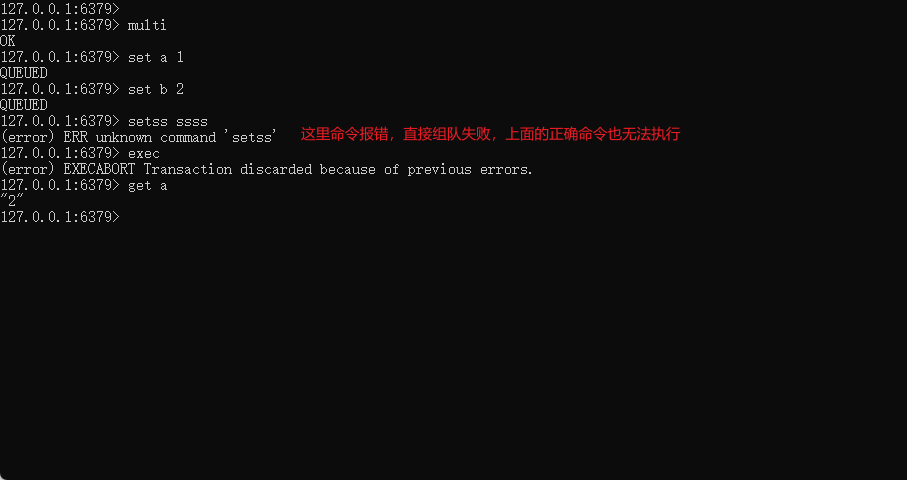
-
如果执行阶段某个命令报出了错误,则只有报错的命令不会被执行,其它命令都会执行,不会回滚:

3. 事务冲突
watchkey [key ……]:在执行multi之前,先执行watch key1 [key2],可以监视一个或多个key,如果在事务执行之前这个(或这些)key被其它命令所改动,那么事务将被打断。
unwatch:取消watch命令对所有key的监视,
如果在执行watch命令之后,EXEC命令或DISCARD命令先被执行了的话,那么久不需要再执行UNWATCH了,如果在执行watch命令之后,EXEC命令或DISCARD命令先被执行了的话,那么久不需要再执行UNWATCH了

4. 总结
-
单独的隔离操作
事务中的所有命令都会序列化、按顺序地执行,事务在执行过程中,不会被其它客户端发送来的命令请求所打断 -
没有隔离级别的概念
队列中的命令没有提交之前都不会实际被执行,因为事务提交前任何指令都不会被实际执行 -
不保证原子性
事务中如果有一条命令执行失败,其它命令仍会执行,没有回滚
8. 持久化
Redis 是内存型数据库,为了之后重用数据(比如重启机器、机器故障之后回复数据),或者是为了防止系统故障而将数据备份到一个远程位置,需要将内存中的数据持久化到硬盘上。
Redis提供了RDB(快照)和AOF(只追加文件)两种持久化方式,默认是只开启RDB。
Redis的持久化机制有两种,第一种是快照,第二种是AOF日志。快照是一次全量备份AOF日志是连续的增量备份。快照是内存数据的二进制序列化形式,在存储上非常紧凑,而AOF日志记录的是内存数据修改的指令记录文本。AOF日志在长期的运行过程中会变的无比庞大,数据库重启时需要加载AOF日志进行指令重放,这个时间就会无比漫长。所以需要定期进行AOF重写,给AOF日志进行瘦身。
1. RDB
RDB(Redis DataBase)是Redis默认的持久化方式。RDB持久化的方式是:按照一定的时间规律将(某个时间点的)内存的数据以快照(快照是数据存储的某一时刻的状态记录)的形式保存到硬盘中,对应产生的数据文件为dump.rdb(二进制文件)。可以通过配置文件(redis.conf,在Windows系统上是redis.windows.conf)中的save参数来定义快照的周期。
Redis可以通过创建快照来获得存储在内存里面的数据在某个时间点上的副本。Redis创建快照之后,可以对快照进行备份,可以将快照复制到其他服务器从而创建具有相同数据的服务器副本(Redis主从结构,主要用来提高Redis性能),还可以将快照留在原地以便重启服务器的时候使用。
RDB的持久化方式会丢失部分更新数据
RDB的三种主要触发机制:
1. save
redis 127.0.0.1:6379> SAVE
OK
由于save命令是同步命令,会占用Redis的主进程。若Redis数据非常多时,save命令执行速度会非常慢,并且该命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止。因此很少在生产环境直接使用SAVE 命令,可以使用BGSAVE 命令代替。如果在BGSAVE命令的保存数据的子进程发生错误的时,用 SAVE命令保存最新的数据是最后的手段
2. bgsave
127.0.0.1:6379> BGSAVE
Background saving started
127.0.0.1:6379> LASTSAVE
(integer) 1632563411
Redis使用Linux系统的fock()生成一个子进程来将DB数据保存到磁盘,主进程继续提供服务以供客户端调用。如果操作成功,可以通过客户端命令LASTSAVE来检查操作结果。
3. 自动生成 RDB
除了手动执行save和bgsave命令实现RDB持久化以外,Redis还提供了自动自动生成RDB的方式。
你可以通过配置文件 redis.conf 对 Redis 进行设置, 让它在“N秒内数据集至少有M个key改动”这一条件被满足时, 自动进行数据集保存操作(其实Redis本身也是这样做的)
#在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
save 900 1
#在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
save 300 10
#在60秒(1分钟)之后,如果至少有10000个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
save 60 10000
RDB的优缺点
1、RDB的优点
1)RDB文件是紧凑的二进制文件(一个文件dump.rdb),比较适合做冷备,全量复制的场景,方便持久化;
2) 相对于AOF持久化机制来说,直接基于RDB数据文件来重启和恢复Redis进程,更加快速;
3)RDB对Redis对外提供的读写服务,影响非常小,可以让Redis保持高性能,因为Redis主进程只需要fork一个子进程,让子进程执行磁盘IO操作来进行RDB持久化即可。
2、RDB的缺点
1)如果想要在Redis故障时,尽可能少的丢失数据,那么RDB没有AOF好。一般来说,RDB数据快照文件,都是每隔5分钟,或者更长时间生成一次,这个时候就得接受一旦Redis进程宕机,那么会丢失最近5分钟的数据。
2)RDB每次在fork子进程来执行RDB快照数据文件生成的时候,如果数据文件特别大,可能会导致对客户端提供的服务暂停数毫秒,或者甚至数秒;
3)RDB无法实现实时或者秒级持久化。
2. AOF
- AOF持久化:将写命令添加到AOF文件(Append Only File)的末尾。
- 与RDB持久化通过保存数据库中键值对来保存数据库的状态不同,AOF持久化是通过保存Redis服务器所执行的写命令来记录数据库的状态。当重启Redis会重新将持久化的日志中文件恢复数据。
- 与快照持久化相比,AOF持久化 的实时性更好,因此已成为主流的持久化方案。
- 开启AOF功能需要设置配置:appendonly yes,默认不开启。AOF文件名通过appendfilename设置,默认文件名是appendonly.aof。
- 当两种方式同时开启时,数据恢复Redis会优先选择AOF恢复。
工作流程:
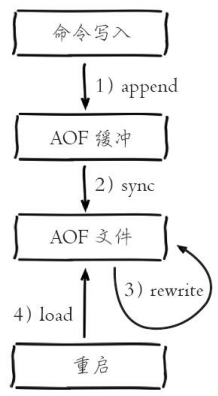
AOF的工作流程操作:命令写入(append)、文件同步(sync)、文件重写(rewrite)、重启加载(load)
- 所有的写入命令会追加到aof_buf(缓冲区)中。
- AOF缓冲区根据对应的策略向硬盘做同步操作。
- 随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩的目的。
- 当Redis服务器重启时,可以加载AOF文件进行数据恢复。
AOF的优点:
1、该机制可以带来更高的数据安全性,即数据持久性。Redis中提供了3种同步策略,即每秒同步、每次修改同步和不同步。事实上,每秒同步也是异步完成的,其效率也是非常高的,所差的是一旦系统出现宕机现象,那么这一秒钟之内修改的数据将会丢失。
2、由于该机制对日志文件的写入操作采用的是append模式,因此在写入过程中即使出现宕机现象,也不会破坏日志文件中已经存在的内容。然而如果我们本次操作只是写入了一半数据就出现了系统崩溃问题,不用担心,在Redis下一次启动之前,我们可以通过redis-check-aof工具来帮助我们解决数据一致性的问题。
3、AOF机制的rewrite模式。AOF文件没被rewrite之前(文件过大时会对命令 进行合并重写),可以删除其中的某些命令(比如误操作的 flushall))
AOF的缺点:
1、AOF 文件比 RDB 文件大,且恢复速度慢。
2、数据集大的时候,比 rdb 启动效率低。
3. 混合持久化
Redis4.0开始支持RDB和AOF的混合持久化,该功能通过aof-use-rdb-preamble配置参数控制,yes则表示开启,no表示禁用,默认是禁用的,可通过config set修改。
如果把混合持久化打开,AOF重写的时候就直接把RDB的内容写到AOF文件开头。这样做的好处是可以结合RDB和AOF的优点, 快速加载同时避免丢失过多的数据。
混合持久化:将rdb文件的内容和增量的AOF日志文件存在一起。这里的AOF日志不再是全量的日志,而是自持久化开始到持久化结束的这段时间发生的增量AOF日志
9. 客户端
客户端——即真正的使用者,比如进入redis命令操作有一个redis-cli,这其实就是redis提供的一个基于操作系统(linux、windows)的客户端,此时的使用者是电脑,电脑通过这个客户端可以连接redis并操作redis。同理,在java中如果想要要操作redis同样需要客户端来与redis建立连接。
java 最常用的是 jedis,letture,redisson 三种客户端。
SpringBoot项目用spring-data-redis(redisTemplate)的比较多,其实它主要是封装了jedis和lettuce两个客户端,相当于在它们基础上加了一层门面,低版本使用 jedis,高版本使用 letture
1. Jedis
Jedis是redis老牌的Java客户端,它把Redis的所有命令封装成了Java可直接调用的方法,但它并没有替我们封装一些基于redis的特殊功能,比如分布式锁等。
github 地址:https://github.com/redis/jedis
这玩意封装再 Spring-data-redis 中。
2. Lettuce
Lettuce是一个高级redis客户端,支持高级的redis特性,比如Sentinel、集群、流水线、自动重新连接和redis数据模型等。目前已成为SpringBoot 2.0版本默认的redis客户端。
相比于Jedis,lettuce不仅功能丰富,而且提供了很多新的功能特性,比如异步操作、响应式编程等,同时还解决了Jedis线程不安全的问题。
github 地址:https://github.com/redis/lettuce
这玩意封装再 Spring-data-redis 中。
3. Redisson
Redisson是架设再redis基础上的一个Java驻内存数据网格(In-Memory Data Grid)。它不仅将原生的redis Hash、List、Set、String等数据结构封装为Java里大家熟悉的Map、List、Set、Object Bukcket等数结构,并在此基础上还提供了许多分布式服务,比如分布式锁、分布式对象、分布式集合、分布式调度任务等。
github 地址:https://github.com/redisson/redisson
1. 依赖
redisson 就需要自己导入依赖了:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.21.3</version>
</dependency>
springboot 集成 redisson:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.17.7</version>
</dependency>
redisson 自己配置:https://www.jb51.net/program/316833njy.htm
2. 布隆过滤器
布隆过滤器工作原理:
- 初始化时,位数组的所有位都被设置为0。
- 当要插入一个元素时,使用预先设定好的多个独立、均匀分布的哈希函数对元素进行哈希运算,每个哈希函数都会计算出一个位数组的索引位置。
- 将通过哈希运算得到的每个索引位置的位设置为1。
- 查询一个元素是否存在时,同样用相同的哈希函数对该元素进行运算,并检查对应位数组的位置是否都是1。如果所有位都为1,则认为该元素可能存在于集合中;如果有任何一个位为0,则可以确定该元素肯定不在集合中。
- 由于哈希碰撞的存在,当多位同时为1时,可能出现误报(False Positive),即报告元素可能在集合中,但实际上并未被插入过。但布隆过滤器不会出现漏报(False Negative),即如果布隆过滤器说元素不在集合中,则这个结论是绝对正确的。
@Autowired
private RedissonClient redissonClient;
@RequestMapping("/test")
public void bloomTest(){
//获取一个布隆过滤器
RBloomFilter<Object> mbf = redissonClient.getBloomFilter("myBloomFilter");
//尝试初始化,预计元素 100,允许误判率 0.05
mbf.tryInit(100L, 0.05);
for(int i = 0;i < 1000;i++){
System.out.println(i + ":" + mbf.add(i));
}
System.out.println(mbf.getSize());
}
3. 实现分布式锁
10. 分布式锁
1. 分布式锁的必要条件
实现分布式锁,至少要保证满足以下四个条件:
- 互斥性。在任意时刻,只有一个客户端能持有锁。
- 不会发生死锁。即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁。
- 具有容错性。只要大部分的Redis节点正常运行,客户端就可以加锁和解锁。
- 加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了。
2. 实现分布式锁的方式
分布式锁一般有三种实现方式:
- 数据库乐观锁;
- 基于Redis的分布式锁;
- 基于ZooKeeper的分布式锁。
3. 分布式锁实现小案例
- redisTemplate.opsForValue().setIfAbsent()
public void redisSell(){
//也可以设置过期时间
Boolean redisFlag = redisTemplate.opsForValue().setIfAbsent("redisKey", 1);
try{
if(redisFlag){
if(papers > 0) {
System.out.println("减一" + --papers);
}
}
}finally {
redisTemplate.delete("redisKey");
}
}
利用原生的 setNx 命令,加锁失败返回 false,如果设置过期时间,是非原子性的。如果不设置过期时间,有死锁的问题。
public void redissonSell(){
RLock pz = redisClient.getLock("pz");
try{
boolean b = pz.tryLock(); //抢不到就返回 false,不设置过期时间,有看门狗
// boolean b = pz.tryLock(2, TimeUnit.SECONDS); //抢两秒,抢不到返回 false,不设置过期时间,有看门狗
// boolean b = pz.tryLock(3, 2, TimeUnit.SECONDS); //抢三秒,两秒过期时间,无看门狗
if(b) {
System.out.println(Thread.currentThread().getName() + "在" + LocalDateTime.now().toString() + "时间抢到锁了!!");
Thread.sleep(5000);
}else{
System.out.println(Thread.currentThread().getName()+ "在" + LocalDateTime.now().toString() + ":获取锁失败!!");
}
}catch (InterruptedException e) {
e.printStackTrace();
} finally {
//如果是当前线程持有锁
if(pz.isHeldByCurrentThread()) {
pz.unlock();
}
}
}
@RequestMapping("/redisson/lock")
public void redisson(){
RLock pz = redisClient.getLock("pz");
try {
// pz.lock(); //一直阻塞,直到抢到锁为止
pz.lock(2, TimeUnit.SECONDS); //一直阻塞,两秒过期时间
System.out.println(Thread.currentThread().getName() + "在" + LocalDateTime.now().toString() + "时间抢到锁了!!");
Thread.sleep(5000);
} catch (InterruptedException e) {
System.out.println("-----------");
} finally {
//如果是当前线程持有锁
if(pz.isHeldByCurrentThread()) {
pz.unlock();
}
}
}
public void redissonAsync(){
RLock pz = redisClient.getLock("pz");
try{
RFuture<Void> voidRFuture = pz.lockAsync();
System.out.println(Thread.currentThread().getName() + "在" + LocalDateTime.now().toString() + "不知道加没加到锁!!");
try {
Thread.sleep(2_000);
System.out.println(Thread.currentThread().getName() + "在" + LocalDateTime.now().toString() + "睡眠过了!!");
} catch (InterruptedException e) {
e.printStackTrace();
}
voidRFuture.whenCompleteAsync((aVoid, throwable) -> {
System.out.println(Thread.currentThread().getName() + "在" + LocalDateTime.now().toString() + "执行的操作!!");
try {
Thread.sleep(1_000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}finally {
pz.unlock();
}
}
Redisson 有看门狗机制,如果不设置过期时间,默认有个过期时间,并且在业务执行期间自动续杯,这样最大限度减少死锁的概率。
11. SpringBoot 集成
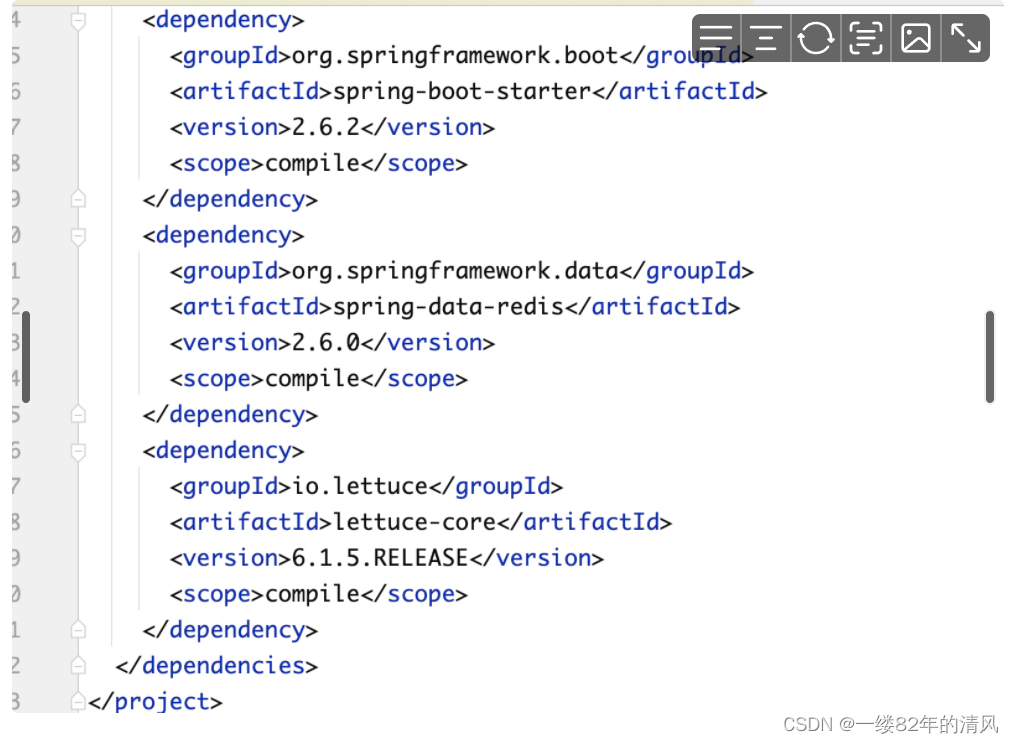
1. 添加依赖
<!-- 集成redis依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
高版本的 SpringBoot 集成的是 lettuce,对标低版本的 jedis。如果想使用 jedis,就需要排除 lettuce 这个依赖,换成 jedis 依赖。
2. 添加配置
最小配置:
spring:
redis:
host: localhost
port: 6379
password: 123456
database: 0
集群:
spring:
redis:
password: 123456
cluster:
nodes: 10.255.144.115:7001,10.255.144.115:7002,10.255.144.115:7003,10.255.144.115:7004,10.255.144.115:7005,10.255.144.115:7006
max-redirects: 3
连接池:
spring:
redis:
host: 10.255.144.111
port: 6379
password: 123456
database: 0
lettuce:
pool:
max-idle: 16
max-active: 32
min-idle: 8
另外需要添加连接池的依赖:
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
3. 项目中使用
package com.lsqingfeng.springboot.controller;
import com.lsqingfeng.springboot.base.Result;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* @className: RedisController
* @description:
* @author: sh.Liu
* @date: 2022-03-08 14:28
*/
@RestController
@RequestMapping("redis")
public class RedisController {
private final RedisTemplate redisTemplate;
public RedisController(RedisTemplate redisTemplate) {
this.redisTemplate = redisTemplate;
}
@GetMapping("save")
public Result save(String key, String value){
redisTemplate.opsForValue().set(key, value);
return Result.success();
}
}
参考
https://cloud.tencent.com/developer/article/1975743
12. 常见问题及优化
1. 缓存穿透
缓存穿透是指缓存和数据库中都没有的数据,导致所有的请求都落到数据库上,造成数据库短时间内承受大量请求而崩掉。
造成缓存穿透的基本原因有两个:
1、自身业务代码或者数据出现问题
2、一些恶意攻击、爬虫等造成大量空命中。
解决方式:
1、缓存空对象
存储层不命中后,仍然将空对象保留到缓存层中,之后再访问这个数据将会从缓存中获取,这样就保护了后端数据源。缓存空数据带来的问题就是缓存中存在更多的键,需要更多的内存空间,如果是攻击导致的问题会更严重。
2、布隆过滤器拦截
在访问缓存层和存储层之前,将存在的key用布隆过滤器提前保存起来,做第一层拦截。如果布隆过滤器认为该用户id不存在,那么就不会访问存储层,在一定程度保护了存储层。
布隆过滤器(Bloom Filter)是一种数据结构,用于快速检查一个元素是否属于某个集合中。它可以快速判断一个元素是否在一个大型集合中,且判断速度很快且不占用太多内存空间。
布隆过滤器的主要原理是使用一组哈希函数,将元素映射成一组位数组中的索引位置。当要检查一个元素是否在集合中时,将该元素进行哈希处理,然后查看哈希值对应的位数组的值是否为1。如果哈希值对应的位数组的值都为1,那么这个元素可能在集合中,否则这个元素肯定不在集合中。
由于哈希函数的映射可能会发生冲突,因此布隆过滤器可能会出现误判,即把不在集合中的元素判断为在集合中。但是,布隆过滤器不会漏判,即不会把在集合中的元素判断为不在集合中
3、接口层增加校验
对接口参数,比如 id < 0 做校验。
2. 缓存雪崩
缓存雪崩是指缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
导致原因:
1、缓存服务器挂了
2、高峰期缓存局部失效
3、热点缓存失效
解决方法:
1、缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
2、添加熔断机制:在缓存失效的情况下,限制对数据库的直接访问,直接返回错误或者默认值,减轻数据库压力。
3、使用多级架构,使用nginx缓存+redis缓存+其他缓存,不同层使用不同的缓存,可靠性更强
4、设置缓存标记,记录缓存数据是否过期,如果过期会触发通知另外的线程在后台去更新实际的key
3. 缓存击穿
缓存击穿是指一个存在的key,在缓存过期的一刻,同时有大量的并发请求访问这个key,这些请求都会直接访问数据库,造成数据库压力剧增。
与缓存雪崩不同的事,缓存击穿指的事某个缓存失效,有大量请求来访问这个缓存。而缓存雪崩则是大面积缓存失效。
解决方案
1、添加互斥锁:当发现缓存过期时,只允许一个请求去访问数据库,其他请求等待结果。请求获得数据后,更新缓存,并释放锁。
2、预加载缓存:在缓存即将过期之前,提前异步加载缓存,避免缓存过期时大量请求同时访问数据库。
3、设置热点数据永不过期。
4. 缓存与数据库同步设计,双写一致性
-
- 时效性比较高,强一致性
RReadWriteLock lock = redissonClient.getReadWriteLock("lock");
lock.readLock();
lock.writeLock();
在读的时候添加共享锁,可以保证读读不互斥,读写互斥。当我们更新数据的时候,添加排他锁,它是读写,读读都互斥,这样就能保证在写数据的同时是不会让其他线程读数据的,避免了脏数据。这里面需要注意的是读方法和写方法上需要使用同一把锁才行。
-
- 讲究并发效率,最终一致性
延迟双删,如果是写操作,我们先把缓存中的数据删除,然后更新数据库,最后再延时删除缓存中的数据,其中这个延时多久不太好确定,在延时的过程中可能会出现脏数据,并不能保证强一致性。
13. 数据过期策略
Redis对数据设置数据的有效时间,数据过期以后,就需要将数据从内存中删除掉。可以按照不同的规则进行删除,这种删除规则就被称之为数据的删除策略(数据过期策略)。
Redis的过期删除策略:惰性删除 + 定期删除两种策略进行配合使用。
1. 惰性删除
设置该key过期时间后,我们不去管它,当需要该key时,我们在检查其是否过期,如果过期,我们就删掉它,反之返回该key。
2. 定期删除
每隔一段时间,我们就对一些key进行检查,删除里面过期的key(从一定数量的数据库中取出一定数量的随机key进行检查,并删除其中的过期key)。
14. 数据的淘汰策略
当Redis中的内存不够用时,此时在向Redis中添加新的key,那么Redis就会按照某一种规则将内存中的数据删除掉,这种数据的删除规则被称之为内存的淘汰策略。
共有八种:
noeviction: 不淘汰任何key,但是内存满时不允许写入新数据,默认就是这种策略。
volatile-ttl: 对设置了TTL的key,比较key的剩余TTL值,TTL越小越先被淘汰。
allkeys-random:对全体key ,随机进行淘汰。
volatile-random:对设置了TTL的key ,随机进行淘汰。
allkeys-lru: 对全体key,基于LRU算法进行淘汰。
volatile-lru: 对设置了TTL的key,基于LRU算法进行淘汰。
allkeys-lfu: 对全体key,基于LFU算法进行淘汰。
volatile-lfu: 对设置了TTL的key,基于LFU算法进行淘汰。
15. redis 集群
-
- 主从模式:读写分离
-
- 哨兵模式:master 容灾
-
- cluster 集群:海量数据分片
参考文件:
https://blog.csdn.net/2301_76166241/article/details/140476290,
https://blog.csdn.net/weixin_43888891/article/details/131208398
1. 主从模式
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,可以搭建主从集群,实现读写分离。一般都是一主多从,主节点负责写数据,从节点负责读数据,主节点写入数据之后,需要把数据同步到从节点中
1. 全量同步
- master服务端收到slave的同步命令psync后,判断slave传过来的master_replid是否和master的master_replid一致,如果不一致或者传的是一个空的,就需要进行全量同步
- master开始执行bgsave命令,生成一个RDB文件,生成成功后,给到slave,并且将master_replid和offerset传过去
- slave收到RDB文件后,清空slave自己内存中的数据,然后通过RDB文件重新加载数据
2. 增量同步
- master会判断slave传过来的master_replid是否一致,如果一致,满足条件,进行下一步校验
- 增量同步会根据偏移量offerset和积压缓存数据来判断,增量同步会去积压缓存replication_backlog_buffer获取数据,如果偏移量只差了3条数据,同时在积压缓存里查找得到,就会进行增量同步
2. 哨兵模式
Redis的主从模式是可以解决负载、数据备份等问题,但是,如果master宕机的情况,slave是不会自动升级为master的,必须手动升级,所以就有了哨兵集群的方案,为Redis提供了高可用性,并且提供了检测、通知、自动故障转移、配置提供等功能
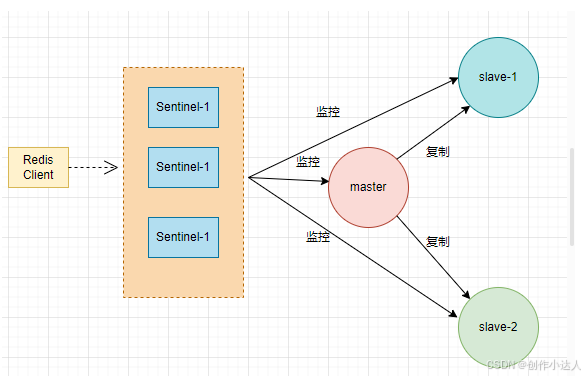
在哨兵模式下,哨兵节点会定期检查主节点和从节点的运行状态。如果发现主节点发生故障,哨兵节点会在从节点中选举出一个新的主节点,并通知其他的从节点和哨兵节点。此外,哨兵节点还可以接收客户端的查询请求,返回当前的主节点信息,从而实现客户端的透明切换。
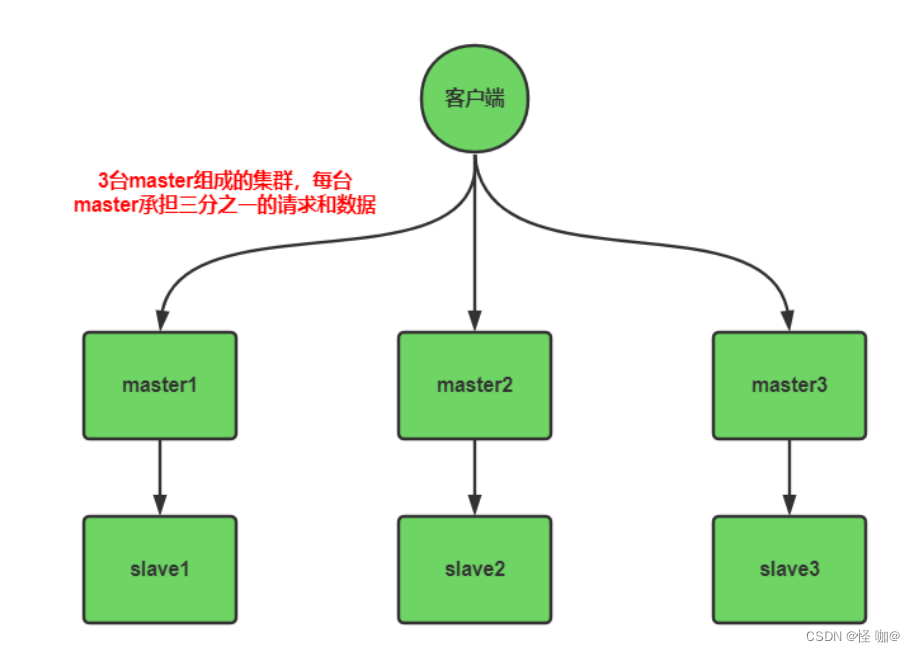
3. Cluster 分片模式
虽然主从+哨兵采用了多节点,但是他们存在的目的主要是解决容灾问题,而并非性能问题。
互联网分布式架构设计,提高系统并发能力的方式,方法论上主要有两种:垂直扩展(Scale Up)与水平扩展(Scale Out)。
垂直扩展:提升单机处理能力。增强单机硬件性能,例如:增加CPU核数如32核,升级更好的网卡如万兆,升级更好的硬盘如SSD,扩充硬盘容量如2T,扩充系统内存如128G;
水平扩展:只要增加服务器数量,就能线性扩充系统性能。水平扩展对系统架构设计是有要求的,如何在架构各层进行可水平扩展的设计,以及互联网公司架构各层常见的水平扩展实践,是本文重点讨论的内容。
redis集群是对redis的水平扩容,即启动N个redis节点,将整个数据分布存储在这个N个节点中,每个节点存储总数据的1/N。
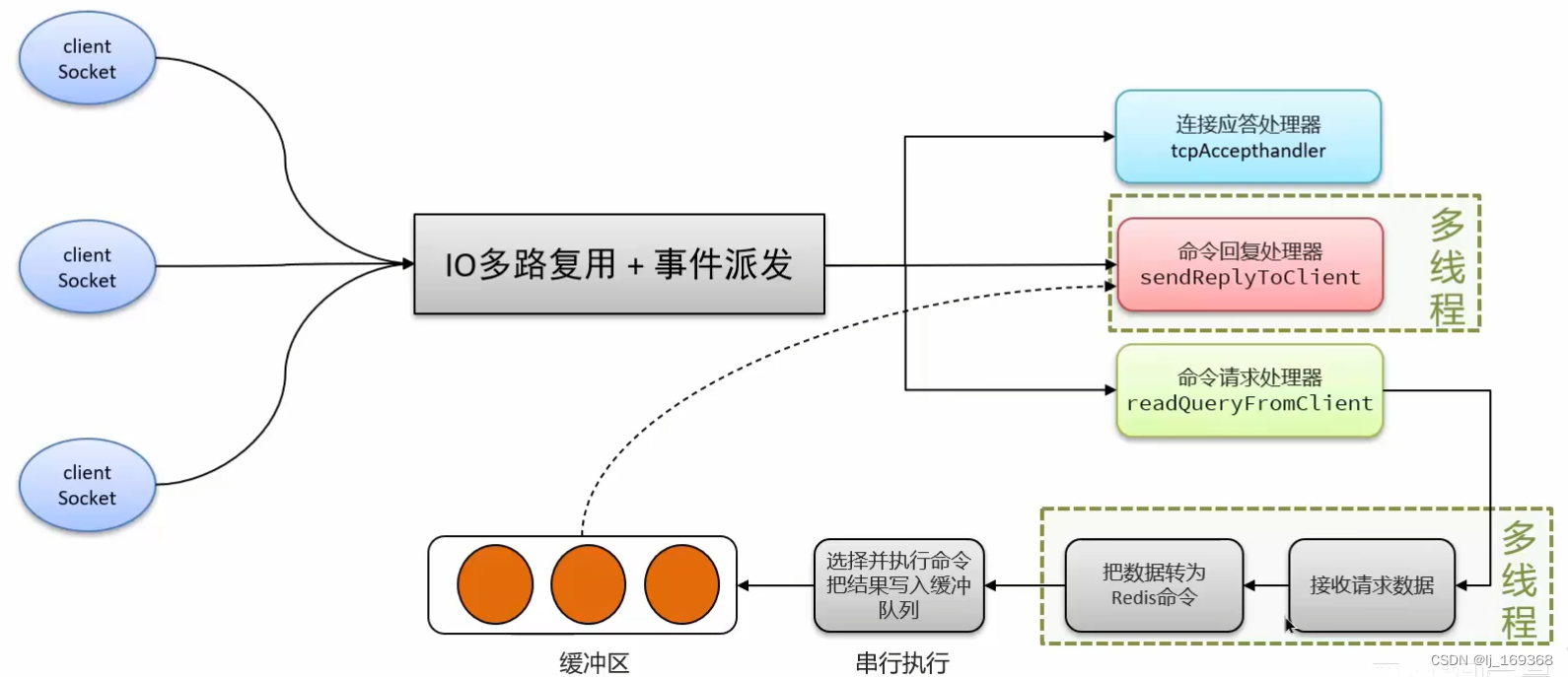
16. redis 单线程,这么快?
-
- Redis是纯内存操作,执行速度非常快
-
- 采用单线程,避免不必要的上下文切换可竞争条件,多线程还要考虑线程安全问题
-
- 使用I/O多路复用模型,非阻塞IO :Redis是纯内存操作,执行速度非常快,它的性能瓶颈是网络延迟而不是执行速度,I/O多路复用模型主要就是实现了高效的网络请求。
17. 可视化工具
AnotherRedisDesktopManager:https://gitee.com/qishibo/AnotherRedisDesktopManager
18. Redis 常用命令
https://blog.csdn.net/m0_74428788/article/details/146439808
参考文献
参考博客:https://blog.csdn.net/m0_37741420/article/details/120471833
windows 安装 redis:https://blog.csdn.net/qq_40220309/article/details/125185615
菜鸟教程:https://www.runoob.com/redis/redis-tutorial.html
20道经典Redis面试题:https://blog.csdn.net/weixin_40205234/article/details/124614720
jedis,luctture, redisson:https://blog.csdn.net/weixin_45433817/article/details/135116224
redis 常用命令:https://blog.csdn.net/Lzy410992/article/details/116094703

 浙公网安备 33010602011771号
浙公网安备 33010602011771号