
etcd的客户端使用及数据备份与恢复
应该是从喜欢里获得力量和快乐
简介:
官网:https://etcd.io/
官方硬件推荐:https://etcd.io/docs/v3.4/op-guide/hardware/
etcd属性:
完全复制:集群中的每个节点都可以使用完整的存档
高可用性:Etcd可用于避免硬件的单点故障或网络问题
一致性:每次读取都会返回跨多主机的最新写入
简单:包括一个定义良好、面向用户的API(gRPC)
安全:实现了带有可选的客户端证书身份验证自动化TLS
快速:每秒10000次次写入的基准速度
可靠:使用Raft算法实现了存储的合理分布Etcd的工作原理
一、Etcd的客户端使用
| etcd1 | 192.168.181.130 | 2G 2C |
| etcd2 | 192.168.181.131 | 2G 2C |
| etcd3 | 192.168.181.132 | 2G 2C |
Etcd配置文件
[root@etcd1 ~]# cat /etc/systemd/system/etcd.service [Unit] Description=Etcd Server After=network.target After=network-online.target Wants=network-online.target Documentation=https://github.com/coreos [Service] Type=notify WorkingDirectory=/var/lib/etcd #数据保存目录 ExecStart=/usr/bin/etcd \ #二进制文件路径 --name=etcd-192.168.181.130 \ #当前node名称 --cert-file=/etc/kubernetes/ssl/etcd.pem \ --key-file=/etc/kubernetes/ssl/etcd-key.pem \ --peer-cert-file=/etc/kubernetes/ssl/etcd.pem \ --peer-key-file=/etc/kubernetes/ssl/etcd-key.pem \ --trusted-ca-file=/etc/kubernetes/ssl/ca.pem \ --peer-trusted-ca-file=/etc/kubernetes/ssl/ca.pem \ --initial-advertise-peer-urls=https://192.168.181.130:2380 \ #通告自己集群的端口 --listen-peer-urls=https://192.168.181.130:2380 \ #集群之间的通讯端口 --listen-client-urls=https://192.168.181.130:2379,http://127.0.0.1:2379 \ #客户端访问地址 --advertise-client-urls=https://192.168.181.130:2379 \ #通告自己客户端的端口 --initial-cluster-token=etcd-cluster-0 \ --initial-cluster=etcd-192.168.181.130=https://192.168.181.130:2380,etcd-192.168.181.131=https://192.168.181.131:2380,etcd-192.168.181.132=https://192.168.181.132:2380 \ #集群所有节点信息 --initial-cluster-state=new \ #新建集群的时候值为new,如果是已存在的集群为existing --data-dir=/var/lib/etcd \ #数据目录路径 --wal-dir= \ --snapshot-count=50000 \ --auto-compaction-retention=1 \ --auto-compaction-mode=periodic \ --max-request-bytes=10485760 \ --quota-backend-bytes=8589934592 Restart=always RestartSec=15 LimitNOFILE=65536 OOMScoreAdjust=-999 [Install] WantedBy=multi-user.target
命令使用:
1.查看 etcd 版本信息
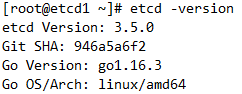
2.查看服务状态
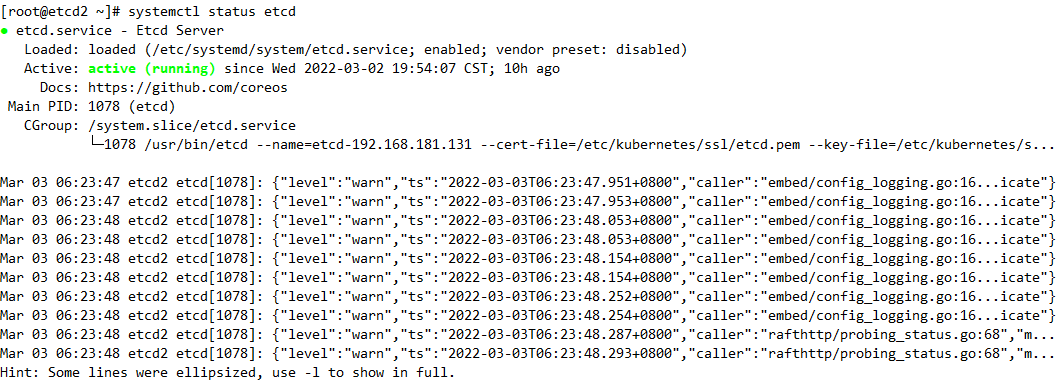
3.查询 etcd 服务列表


false是数据没有同步
健康心跳检测
1.添加环境变量
#export NODE_IPS="192.168.181.130 192.168.181.131 192.168.181.132"
2.添加健康心跳 检测
#for ip in ${NODE_IPS}; do ETCDCTL_API=3 /usr/bin/etcdctl --endpoints=https://${ip}:2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem endpoint health; done
每次循环获取NODE_IPS地址, 根据地址执行endpoint health; 一些证书与私钥

以表格方式显示集群信息
# ETCDCTL_API=3 /usr/bin/etcdctl --write-out=table member list --endpoints=https://192.168.181.130:2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem

以表格方式列出节点详细信息
# for ip in ${NODE_IPS}; do ETCDCTL_API=3 /usr/bin/etcdctl --write-out=table endpoint status --endpoints=https://${ip}:2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem endpoint health; done
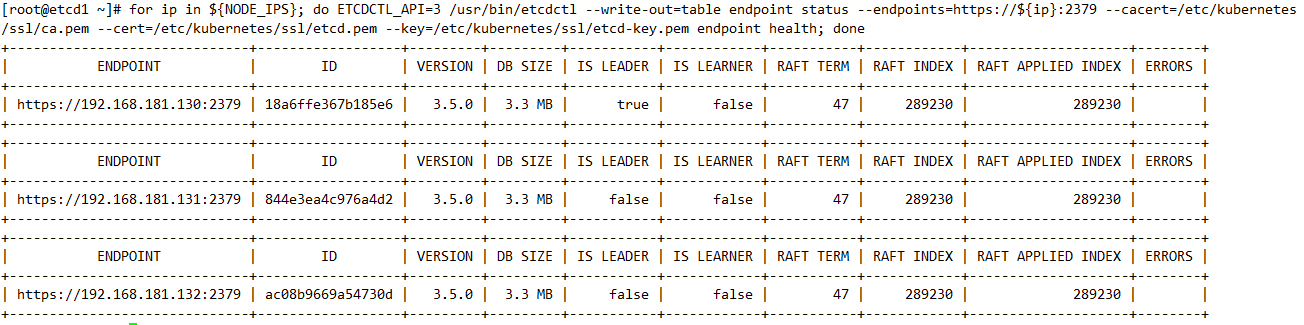
etcd增删改查数据
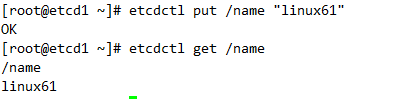
etcd添加数据与查询
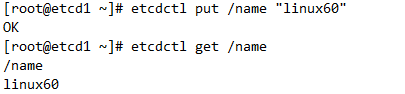
直接覆盖就是改动数据
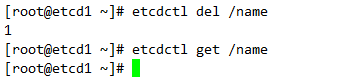
删除数据
二、Etcd数据的备份与恢复
etcd备份到/data/etcd/目录下,目录自创
# etcdctl snapshot save /data/etcd/n60.bak

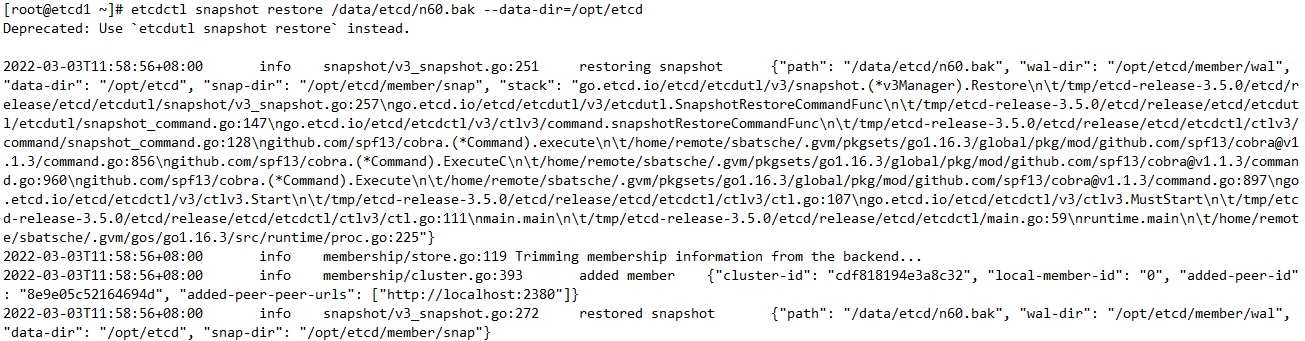
将/data/etcd/n60.bak 数据恢复到 /opt/etcd目录 --data-dir 指定恢复目录
#etcdctl snapshot restore /data/etcd/n60.bak --data-dir=/opt/etcd
备份脚本
[root@etcd1 ~]# vim etcdback.sh
#!/bin/bash source /etc/profile DATE=`date +%Y-%m-%d_%H-%M-%S` ETCDCTL_API=3 /usr/bin/etcdctl snapshot save /data/etcd-backup-dir/etcd-snapshot-${DATE}.db
[root@etcd1 ~]# chmod +x etcdback.sh
[root@etcd1 ~]# ./etcdback.sh

最后将脚本加入crone计划任务
使用kubeasz工具进行Etcd数据备份与恢复演示
master节点操作
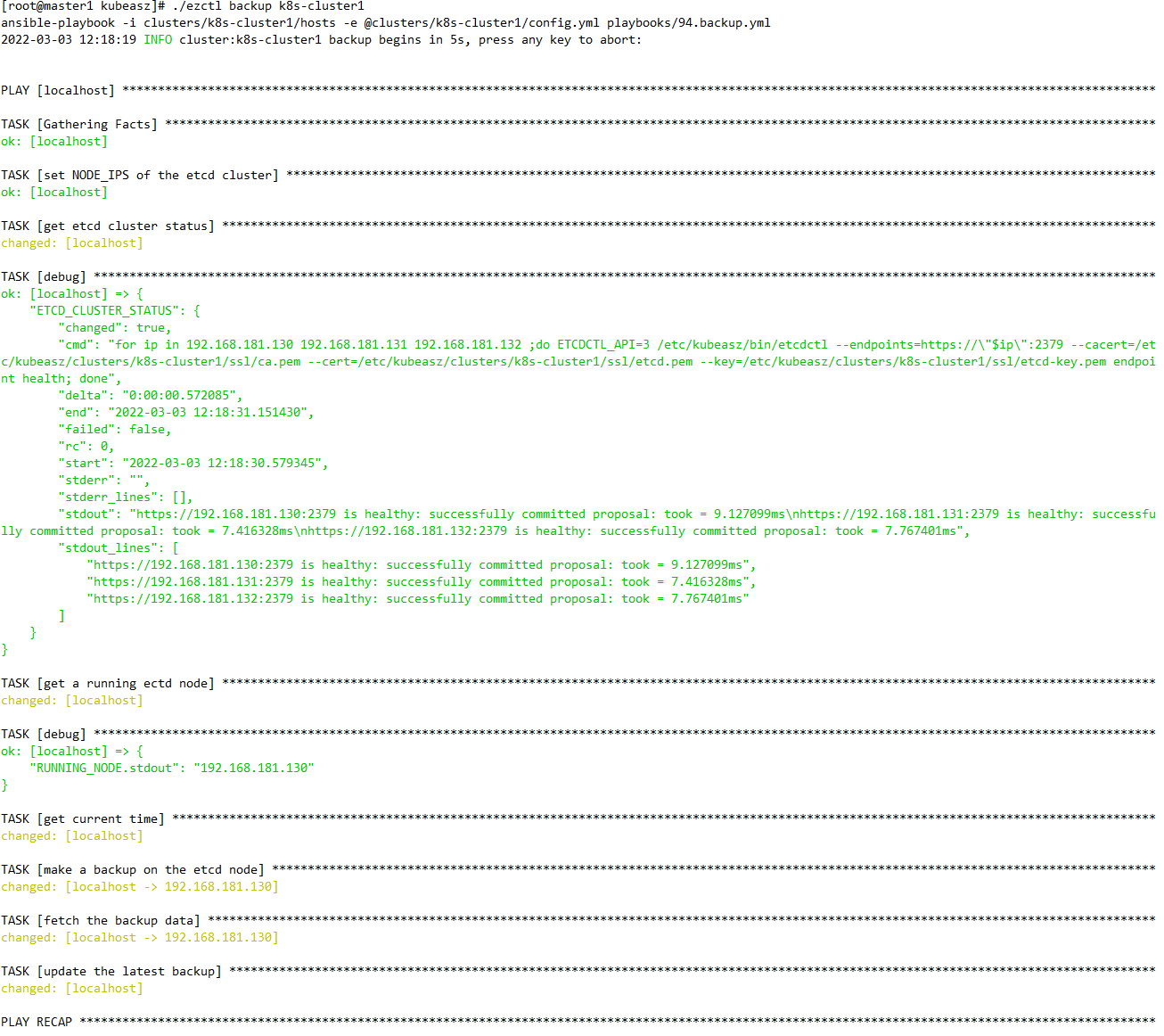
[root@master1 kubeasz]# ./ezctl backup k8s-cluster1

备份数据存放位置

模拟误删pod
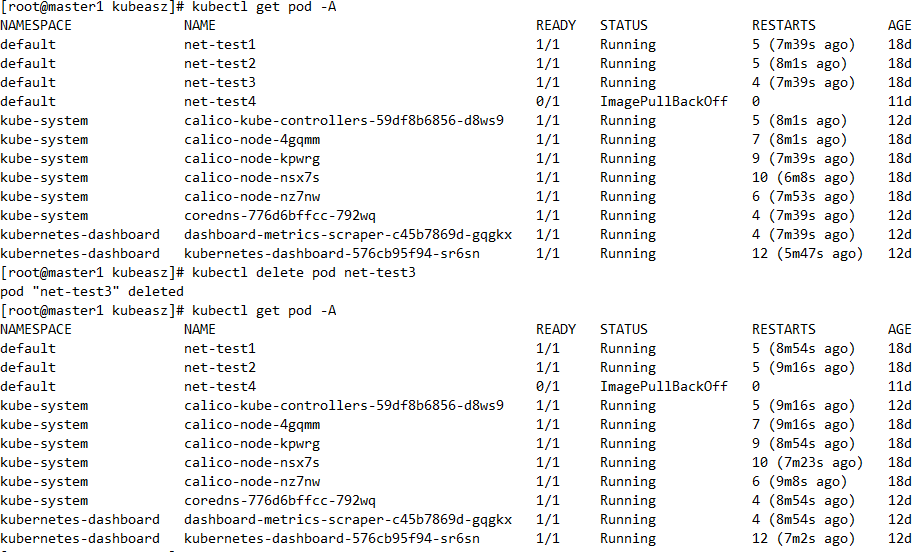
etcd 数据恢复
[root@master1 kubeasz]# ./ezctl restore k8s-cluster1
以下为命令执行过程
ansible-playbook -i clusters/k8s-cluster1/hosts -e @clusters/k8s-cluster1/config.yml playbooks/95.restore.yml
2022-03-03 12:39:07 INFO cluster:k8s-cluster1 restore begins in 5s, press any key to abort:
PLAY [kube_master] ***********************************************************************************************************************************************
TASK [Gathering Facts] *******************************************************************************************************************************************
ok: [192.168.181.111]
ok: [192.168.181.110]
TASK [stopping kube_master services] *****************************************************************************************************************************
changed: [192.168.181.110] => (item=kube-apiserver)
changed: [192.168.181.110] => (item=kube-controller-manager)
changed: [192.168.181.110] => (item=kube-scheduler)
changed: [192.168.181.111] => (item=kube-apiserver)
changed: [192.168.181.111] => (item=kube-controller-manager)
changed: [192.168.181.111] => (item=kube-scheduler)
PLAY [kube_master,kube_node] *************************************************************************************************************************************
TASK [Gathering Facts] *******************************************************************************************************************************************
ok: [192.168.181.141]
ok: [192.168.181.140]
TASK [stopping kube_node services] *******************************************************************************************************************************
changed: [192.168.181.111] => (item=kubelet)
changed: [192.168.181.110] => (item=kubelet)
changed: [192.168.181.111] => (item=kube-proxy)
changed: [192.168.181.110] => (item=kube-proxy)
changed: [192.168.181.141] => (item=kubelet)
changed: [192.168.181.140] => (item=kubelet)
changed: [192.168.181.141] => (item=kube-proxy)
changed: [192.168.181.140] => (item=kube-proxy)
PLAY [etcd] ******************************************************************************************************************************************************
TASK [Gathering Facts] *******************************************************************************************************************************************
ok: [192.168.181.130]
ok: [192.168.181.132]
ok: [192.168.181.131]
TASK [cluster-restore : 停止ectd 服务] *******************************************************************************************************************************
changed: [192.168.181.131]
changed: [192.168.181.132]
changed: [192.168.181.130]
TASK [cluster-restore : 清除etcd 数据目录] *****************************************************************************************************************************
changed: [192.168.181.130]
changed: [192.168.181.131]
changed: [192.168.181.132]
TASK [cluster-restore : 生成备份目录] **********************************************************************************************************************************
ok: [192.168.181.130]
changed: [192.168.181.131]
changed: [192.168.181.132]
TASK [cluster-restore : 准备指定的备份etcd 数据] **************************************************************************************************************************
changed: [192.168.181.131]
changed: [192.168.181.130]
changed: [192.168.181.132]
TASK [cluster-restore : 清理上次备份恢复数据] ******************************************************************************************************************************
ok: [192.168.181.130]
ok: [192.168.181.131]
ok: [192.168.181.132]
TASK [cluster-restore : etcd 数据恢复] *******************************************************************************************************************************
changed: [192.168.181.130]
changed: [192.168.181.131]
changed: [192.168.181.132]
TASK [cluster-restore : 恢复数据至etcd 数据目录] **************************************************************************************************************************
changed: [192.168.181.130]
changed: [192.168.181.131]
changed: [192.168.181.132]
TASK [cluster-restore : 重启etcd 服务] *******************************************************************************************************************************
changed: [192.168.181.131]
changed: [192.168.181.132]
changed: [192.168.181.130]
TASK [cluster-restore : 以轮询的方式等待服务同步完成] **************************************************************************************************************************
changed: [192.168.181.131]
changed: [192.168.181.130]
changed: [192.168.181.132]
PLAY [kube_master] ***********************************************************************************************************************************************
TASK [starting kube_master services] *****************************************************************************************************************************
changed: [192.168.181.110] => (item=kube-apiserver)
changed: [192.168.181.110] => (item=kube-controller-manager)
changed: [192.168.181.110] => (item=kube-scheduler)
changed: [192.168.181.111] => (item=kube-apiserver)
changed: [192.168.181.111] => (item=kube-controller-manager)
changed: [192.168.181.111] => (item=kube-scheduler)
PLAY [kube_master,kube_node] *************************************************************************************************************************************
TASK [starting kube_node services] *******************************************************************************************************************************
changed: [192.168.181.110] => (item=kubelet)
changed: [192.168.181.111] => (item=kubelet)
changed: [192.168.181.140] => (item=kubelet)
changed: [192.168.181.141] => (item=kubelet)
changed: [192.168.181.111] => (item=kube-proxy)
changed: [192.168.181.110] => (item=kube-proxy)
changed: [192.168.181.140] => (item=kube-proxy)
changed: [192.168.181.141] => (item=kube-proxy)
PLAY RECAP *******************************************************************************************************************************************************
192.168.181.110 : ok=5 changed=4 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
192.168.181.111 : ok=5 changed=4 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
192.168.181.130 : ok=10 changed=7 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
192.168.181.131 : ok=10 changed=8 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
192.168.181.132 : ok=10 changed=8 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
192.168.181.140 : ok=3 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
192.168.181.141 : ok=3 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
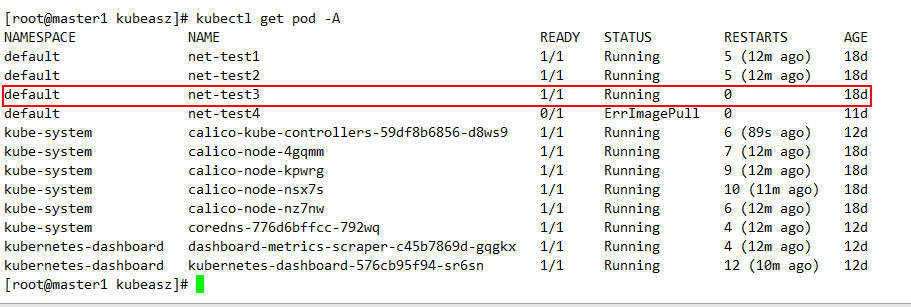
备用有多少pod,就会恢复多少pod,以备份时的数据为准

 浙公网安备 33010602011771号
浙公网安备 33010602011771号