
CS107笔记
CS107笔记
概述 : CS10是斯坦福的计算机组成原理课程,网上有对应的课程链接 CS107 此为本人自学此课程的总结 当然大部分都是课件里面有的,拿出来分享一下,共同学习 下面进入正题
Lecture 1(第一节课 后面省略)
本节课程计划
- CS107课程政策
- Unix和命令行
- C入门
CS107课程政策
什么是CS107
- C++和java语言背后是如何表示数据的
- 编程结构如何以位和字节编码
- 如何有效的操作和管理内存
- 使用C语言
- 编程风格与软件开发实践
学习目标
CS107的目标是让学生掌握
- 用复杂的内存和指针编写C程序
- C程序地址空间和编译/运行行为的精确模型
取得能力
- 将C转换为/从程序集转换
- 编写尊重计算机算法局限性的程序
- 识别瓶颈并提高运行时性能
- 在Unix开发环境中有效地工作
接触到
- 对计算机体系结构基础的有效理解
课程概述
- 位和字节-计算机如何表示整数?
- 字符和C字符串-计算机如何表示和操作更复杂的数据,如文本?
- 指针、堆栈和堆——如何有效地管理程序中的所有类型的内存?
- 泛型-我们如何使用我们的内存和数据表示的知识来编写可以处理任何数据类型的代码?
- 汇编——计算机如何解释和执行C程序?
- 堆分配器-像malloc和free这样的核心内存分配操作是如何工作的?
另外,它推荐了一本书
《计算机系统:程序员的视角》,Bryant&O'Hallaron著,第3版
其他的都是有关作业什么的方案 ,我们无法按照他的方案进行,也无法获取他们的作业,省略
Unix和命令行
什么是Unix
-
Unix:软件开发中常用的一组标准和工具。
-
macOS和Linux是建立在Unix之上的操作系统
-
您可以使用命令行(“终端”)导航Unix系统
-
每个Unix系统使用相同的工具和命令工作
什么是命令行
命令行是一个基于文本的界面(即终端界面)来导航计算机,而不是图形用户界面(GUI)。
简单的说开始我们常说的黑框框
插一句 因为我害怕给遗漏掉什么东西,所以会比较长甚至啰嗦。大家碰到自己已经了解或明白的地方自行跳过 感谢
命令行进而图形化用户界面的区别
就像GUI文件浏览器界面一样,终端界面
*
-
在任何时间显示计算机上的特定位置
-
允许您进入文件夹和退出文件夹
-
允许您创建新文件和编辑文件
-
允许您执行程序
为什么使用Unix
您可以使用相同的工具和命令导航几乎任何设备:
服务器
笔记本电脑和台式机
嵌入式设备(树莓皮等)
移动设备(Android等)
软件工程师经常使用:
Web开发:在服务器上运行服务器和Web工具
机器学习:在服务器上处理数据,运行算法
系统:编写操作系统、网络代码和嵌入式软件
移动开发:运行工具、管理库
还有更多…
我们将使用Unix和命令行来实现和执行我们的程序
上面是课件对此的描述 说白了就是应用范围广
介绍几个常用的命令
cd–更改目录(…)
ls–列出目录内容
mkdir–生成目录
emacs–打开文本编辑器
rm–删除文件或文件夹
man- 查看手册
这里多少几句
cd 可以理解为进入目录
cd + 目录名
cd ../ 进入上一级目录
ls 就是显示当前目录下的文件当然包括目录
ls -a 显示所有文件 包括隐藏文件
mkdir +目录名 (结对路径或相对路径)
emacs 需要你下载对应软件 更具体的自行搜索
rm +文件名 删除文件
rm -r +文件夹名 删除目录及目录下的所有文件
man 后面要节参数 例如 man -a 等等,太多了自行搜索即可
命令还有很多 就不多说了 网上都可以找得到
C入门
略过 这部分内容主要说
- C的产生 发展
- C和C++的比较
- C的优势
- Hello world 程序
这里就不说了 可以去课件了解一下
Lecture 1课件
提取密码 8rdo
链接失效记得提醒我
Lecture 2
本节课程计划
- 比特与字节
- 十六进制
- 整数表示法
- 无符号整数
- 有符号整数
- 溢流
- 转换类型和合并类型
比特和字节
- 了解十进制和二进制
- 计算机是以0 1 为单位的,计算机上所有的数据,文件都是二进制表示的 一个二进制为为一个比特位 。一个字节=八个比特位
- 熟练进行十进制和二进制之间的转换(转换方法不止一种,看自己)
- 了解基数的概念 二进制的基数是2,十进制的基数是10
- 一个字节所能表示的数 最大为 255 最小为0
- 乘以基数和除以基数的运算
十六进制
- 我们在处理32位,64位的数据是 为了方便要用到,当然好多地方
- 了解十六进制的基数是16 以及各数对应的数字或字母
- 十进制 二进制 十六进制中 对于0-15 之间的对应关系
- 对于各进制的数我们为了便于区分 二进制前有0b 十进制省略 十六进制用0x
- 熟练进行十六进制和二进制和十进制之间的转换
整数表示法
整数有分有符号和无符号以及浮点数
本节先了解一下计算机上的32位和64位,以及在这两种环境下各类型的数据分别占多少空间
32位
| C Declaration | Size (Bytes) |
|---|---|
| int | 4 |
| double | 8 |
| float | 4 |
| char | 1 |
| char * | 4 |
| short | 2 |
| long | 4 |
64位
| C Declaration | Size (Bytes) |
|---|---|
| int | 4 |
| double | 8 |
| float | 4 |
| char | 1 |
| char * | 8 |
| short | 2 |
| long | 8 |
至于为什么,我把原文的翻译放在这里
21世纪初:大多数计算机是32位的。这意味着指针是4个字节(32位)。
32位指针存储从0到232-1的内存地址,相当于232字节的可寻址内存。这相当于4GB,这意味着32位计算机最多可以有4GB内存(RAM)!
正因为如此,计算机转换到64位。这意味着数据类型被放大了;程序中的指针现在是64位。
64位指针存储从0到264-1的内存地址,相当于264字节的可寻址内存。这相当于16EB,这意味着64位计算机最多可以有102410241024GB的内存(RAM)!
有链接,自己看就好了 ,了解即可
无符号整数
0或正整数
范围 0--2的n次方减一 (n为二进制位数,即位的数目)
无符号整形的表示是呈圈形的
以四位二进制表示为例
1111:15 此数加一为0
图片的话更形象 课件里面有
有符号整数
简单点一个公式
一个整数的负数表示=其正整数的二进制表示取反加一
例如1:0001
-1 : 1111
| Decimal | Positive | Negative |
|---|---|---|
| 0 | 0000 | 0000 |
| 1 | 0001 | 1111 |
| 2 | 0010 | 1110 |
| 3 | 0011 | 1101 |
| 4 | 0100 | 1100 |
| 5 | 0101 | 1011 |
| 6 | 0110 | 1010 |
| 7 | 0111 | 1001 |
| 8 | #### | 1000 |
附一句 以四位二进制为例
其表示范围(有符号整型)-8~7
理解为 -(2的(4-1)次方)--2的(4-1)次方-1
前面的4换成n 就是n位二进制所能表示的有符号整数范围
总结 有符号整数 表示
正: 直接转换就好 (原码)
负: 补码(对应正数的二进制表示反码加一)
0 全是0
这样利于进行加减运算 具体的演示 见课件
溢出
溢出则“绕圈” 按照课件上图示的那样 ,这里就不上图了
例如 四位二进制有符号整数
圈为 07(-8)(-1)0;
端点处的0连接起来 即为圈
其他的数据类型 例如 char
其对应的ASC码也遵循此规则 只不过 显示的时候是其对应的字符表示
对于溢出现象 课件有更为详细的介绍以及案例,有时间的可以去了解一下
转换类型和合并类型
占位符
%d 有符号32位int
%u 无符号32位int
%x 16进制表示的32位int
用于在printf中表示要输出的类型
这种占位符 还有很多种
自行搜索 因为这属于C语言的内容
提一个问题
int v = -12345;
unsigned int uv = v;
printf("v = %d, uv = %u\n", v, uv);
输出: "v = -12345, uv = 4294954951".
这是为什么呢
另外补充一点
在进行 无符号整型和有符号整型的大小比较时
C讲两数均转换为无符号整形进行比较
类型转换
有时 我们会对两个不同类型的数进行比较
此时,系统会将两数均转换为较大的类型 进而进行比较
这里说一下 我们不能将较大的数据类型转换为小的类型 ,但反之是可行的
那么 转换是怎样进行的呢
无符号 前面补0
有符号 前面补符号位
有时候我们也会将大类型转化为小类型
此时会将数据的长度进行折断
忽视高位(左边)
这段内容课件上有配套练习题 建议去看一下
sizeof 运算符
该运算符接受一个变量类型,并返回其大小 单位为字节
//示例
long int_size_bytes=sizeof(int);//4
long short_size_bytes=sizeof(short);//2
long char_size_bytes=sizeof(char);//1
lecyture 3
此节主要是位运算的介绍
补充一句 计算机中所有数据等 全是用01表示
先介绍一下ASC码
ASCII是从普通字符(字母、符号等)到位表示(字符)的编码
所有大写字母和所有小写字母都按顺序表示!
更具体的自行百度
位运算符
有哪些: &, |, ~, ^,
介绍
- & 同时为1 结果为1
- | 只要有一个为1 结果就是1
- ~ 原来是1变为0 原来是0变为1 (取反)
- ^ 二者不同(一0一1) 结果为1 否则为0
-- 学过离散数学会更好
应用 见课件
比如
如何分离某位
如何修改指定为
如何求位的交集 并集
如何翻转 指定位或所有位
左移运算符
所谓左移运算符: <<
就是将该数在内存中的二进制表示向左移动
用新的最高位去取代最高位 低位用0替换
例如 00110111 << 2 返回 11011100
左移简单点 ,重点是右移
右移运算符
移动很简单 但是用什么来填充移掉的位置呢
用0 ??
0是不行的
x=-2;//1111 1111 1111 1110
x>>=1;//0111 1111 1111 1111
printf(“%d\n”,x);//32767!
多余的例子就不举了
OK 我们现在看解决方案
我们用符号位进行填充
例1
x=2;//0000 0000 0000 0010
x>=1;//0000 0000 0000 0001
printf(“%d\n”,x);//1
例2
x = -2; // 1111 1111 1111 1110
x >>= 1; // 1111 1111 1111 1111
printf("%d\n", x); // -1!
这样就不会找成符号错乱等问题
总而言之
右移 有两种
- 逻辑右移 用0 补充
- 算术右移 用符号位(高阶有效位)补充
一般使用场景
无符号数字使用逻辑右移进行右移。
有符号数字使用算术右移进行右移。
补充
从技术上讲,C标准并没有精确地定义有符号整数的右移是逻辑的还是算术的。
但是 几乎所有的编译器/机器都使用算术,
还有一点 1<<2+3<<4
例如上面的这种运算
要注意!!
加法和减法的优先级高于移位!
等效为 1<<(2+3)<<4
其余注意点
如果你想要一个二进制位前32位全为1的长整型
long num = 1 << 32;
这样是不对的
默认情况下,1是一个int,并且不能将int移位32,因为它只有32位。必须指定希望1为long。
所以要用
long num==1L<<32;
OK 本课结束
Lecture 4 C Strings
显而易见 本节主要结束字符串
问题 计算机如何表示复杂数据 例如 文本
先看大纲
字符
串
常用字符串操作
比较
复制
串联
子字符串
字符 (char)
C语言将每个字符表示为一个整数 起名为ASCII值
ASCII的一般规则
大写字母按顺序编号
小写字母按顺序编号
数字按顺序编号
小写字母比大写字母多32个
举几个例子
char uppercaseA='A';//实际上是65
char lowercaseA='a';//实际上是97
char zeroDigit='0';//实际为48
bool areEqual = 'A' == 'A'; // true
bool earlierLetter = 'f' < 'c'; // false
char uppercaseB = 'A' + 1;
int diff = 'c' - 'a'; // 2
int numLettersInAlphabet = 'z' – 'a' + 1;
// or
int numLettersInAlphabet = 'Z' – 'A' + 1;
通用函数
一般位于 ctype.h 库中
| Function | Description(说明) |
|---|---|
| isalpha(ch) | 如果ch是'a'到'z'或'A'到'Z' 返回true |
| islower(ch) | 如果ch是'a'到'z' 返回true |
| isupper(ch) | 如果ch是'A'到'Z' 返回true |
| isspace(ch) | 如果ch是空格、制表符、换行符等,返回true |
| isdigit(ch) | 如果ch是'0'到'z'或'A'到'9',返回true |
| toupper(ch) | 返回ch对应的大写字母 |
| tolower(ch) | 返回ch对应的小写字母 |
注意
这些方法至是返回一个字符 不会修改现有字符
示例
bool isLetter = isalpha('A'); // true
bool capital = isupper('f'); // false
char uppercaseB = toupper('b');
bool isADigit = isdigit('4'); // true
字符串
C语言中没有字符串的变量类型,他是由有特殊符号的字符数组来表示的 '\0'
在数组中始终要有它的位置
C语言提供了计算字符串长度的函数
int length=strlen(myStr);//例如13
如果要用这个值要记得保存
当字符串作为参数传入函数中时 , C传递的是字符串的首地址
对于传递过去的首地址 我们可以像使用字符数组一样使用它
str[0] = 'c'; // modifies original string!
printf("%s\n", str); // prints cello
常用的string.h函数
| Function | Description(说明) |
|---|---|
| strlen(str) | 返回字符串分(不包括终止字符) |
| strcmp(str1, str2), strncmp(str1, str2, n) | 比较两个字符串,如果str1大于str2返回1,如果str小于str2,返回-1,相等返回0,n表示最多在n个字符后停止比较 |
| strchr(str, ch),strrchr(str, ch) | 字符查找,strchr 返回str中第一个指向ch字符出现的位置,strrchr 则是返回最后一个,没有找到返回null |
| strstr(haystack, needle) | 字符串搜索,返回一个指针,指向haystack中第一次出现needle的开始,如果在haystack中没有找到needle,则返回NULL |
| strcpy(dst, src),strncpy(dst, src, n) | 字符串拷贝将src中的字符串拷贝到dst中,包括终止符,strncpy最多在拷贝n个字符之后停止,并且不添加null终止字符。 |
| strcat(dst, src),strncat(dst, src, n) | 字符串连接,一个是全部链接,另一个strncat是最多连接n个字符之后停止连接 总是会在结尾添加终止符 |
| strspn(str, accept),strcspn(str, reject) | strspn 返回一个长度n,该长度表示在str的前n个字符在accept中都能找到,setcspn也返回一个长度,该长度表示在str中前n个字符在accept中都找不到 |
很多字符串函数都假定你给的字符串是符合规范的(有终止符)
不能用<,>,== 等这些符号对字符串进行比较 ,这样比较,其实比较的是地址
不能 用等号来进行字符串的拷贝 这样拷贝的是地址
关于字符串的拷贝这里提供一个例子
char str1[6];
strcpy(str1, "hello");
char str2[6];
strcpy(str2, str1);
str2[0] = 'c';
printf("%s", str1); // hello
printf("%s", str2); // cello
同时在进行字符串拷贝的时候,我们必须确保目标地址有足够的空间
例如
char str2[6];//空间不足!
strcpy(strpy,“你好,世界!”);//覆盖其他内存!
写入超过内存边界称为“缓冲区溢出”。它可以允许安全漏洞!
还有规定数量的拷贝
// copying "hello"
char str2[5];
strncpy(str2, "hello, world!", 5); // doesn’t copy '\0'!
当我们的字符串没有空终止符时,我们将无法分辨字符串的结尾在哪里,可能会继续在其他内存地址中进行读取
一般情况下,我们可以自行添加一个空终止符
//复制“你好”
char str2[6];//字符串和“\0”的空间
strncpy(str2,“你好,世界!”,5);//不复制'\0'!
str2[5]='\0';//添加空终止字符
加一个小题
int main(int argc, char *argv[]) {
char str[9];
strcpy(str, "Hi earth");
str[2] = '\0';
printf("str = %s, len = %lu\n",
str, strlen(str));
return 0;
}
会输出什么???
不能使用+连接字符串 ,它实际上的是地址
要使用 strcat
特别注意的是 无论是strcat 还是strncat都会去掉旧的空终止符
添加上新的空终止符
举个课件上的例子
char str1[13]; // enough space for strings + '\0'
strcpy(str1, "hello ");
strcat(str1, "world!"); // removes old '\0', adds new '\0' at end
printf("%s", str1); // hello world!
你还可以通过自己创建一个char* 指向字符串的某个地址 进而获得其子串
还是课件上的一个例子
char chars[8];
strcpy(chars, "racecar");
char *str1 = chars;
char *str2 = chars + 4;
printf("%s\n", str1); // racecar
printf("%s\n", str2); // car
另外 虽然我们对指针进行了移动
但还是指向相同的字符串
char chars[8];
strcpy(chars, "racecar");
char *str1 = chars;
char *str2 = chars + 4;
str2[0] = 'f';
printf("%s %s\n", chars, str1); // racefar racefar
printf("%s\n", str2); // far
我们可以通过char* 指向任何一个字符 ,并对其进行重新赋值,而char[]是不可以的
例子
char myString[6];
strcpy(myString, "Hello");
myString = "Another string"; // not allowed!
再加一个关于子串的例子
// Want just "race"
char str1[8];
strcpy(str1, "racecar");
char str2[5];
strncpy(str2, str1, 4);
str2[4] = '\0';
printf("%s\n", str1); // racecar
printf("%s\n", str2); // race
还可以通过指针运算来获得子串
// Want just "ace"
char str1[8];
strcpy(str1, "racecar");
char str2[4];
strncpy(str2, str1 + 1, 3);
str2[3] = '\0';
printf("%s\n", str1); // racecar
printf("%s\n", str2); // ace
OK 本课结束
Lecture 5 More C Strings
显然 本节介绍更多关于字符串的内容
字符串搜索
示例 1
char daisy[6];
strcpy(daisy, "Daisy");
char *letterA = strchr(daisy, 'a');
printf("%s\n", daisy); // Daisy
printf("%s\n", letterA); // aisy
这里用到了strchr 函数 前面有介绍
示例 2
char daisy[10];
strcpy(daisy, "Daisy Dog");
char *substr = strstr(daisy, "Dog");
printf("%s\n", daisy); // Daisy Dog
printf("%s\n", substr); // Dog
这里用到了strstr函数
示例 4
char daisy[10];
strcpy(daisy, "Daisy Dog");
int spanLength = strspn(daisy, "aDeoi"); // 3
这里用到了 strspn函数
示例 5
char daisy[10];
strcpy(daisy, "Daisy Dog");
int spanLength = strcspn(daisy, "driso"); // 2
这里是用到了 strcspn函数
强调一点 不可以用sizeof 求字符串的长度
字符串作为参数
在以字符串为参数进行传递时 , C语言传递的是地址 以char* 的形式传递
所以 在编写形参时 char n[] 和 char *n 是一个意思
字符串数组
直接点就是指针数组
定义方式
char *stringArray[5]; // 存储五个char *
也可以用
char *stringArray[] = {
"Hello",
"Hi",
"Hey there"
};
这种方式来定义
我们可以用括号[]对字符串进行访问
printf("%s\n", stringArray[0]);
打印字符串数组中的第一个数组
当我们将字符串数组当做参数进行传递时
C语言自动转换为双重指针(char **) 进而进行传递
课件上面有一个关于字符串指针
另外课件上提到了一个关于追踪内存读取的工具 Valgrind
感兴趣的可以去试一试
指针
指针 就是指存储内存地址的变量
大小为8个字节
后续的堆分配内存还要用到相关内容
先来理解一下内存
内存 简单说就是一个超级大的字节数组
每个字节都对应一个唯一的地址
通常情况下用十六进制表示
通过指针我们可以在别的函数中修改接受到的参数
例
void myFunc(int& num) {
num = 3;
}
int main(int argc, char *argv[]) {
int x = 2;
myFunc(x);
printf("%d", x); // 3!
...
}
面对复杂的数据传参 指针可以很大的提高效率 ,而且还可以对其进行一定的修改
C语言 传值传地址
还要提一下 * 运算符 &运算符 简单的说就是取地址
例如
int x=1;
int *y=&x;//定义一个指针 赋值为x的地址
int z=*y;// 将y存储的地址对应的值拿出来赋给z 因为y存储的是x的地址 相当于 int z=x;
多提两嘴 指针的应用很多
例如
通过对指针的偏移量获取子串
还有要注意的就是
1.我们不能对创建的字符数组进行赋值,因为它不说指针,当然他在传参过程中是转换为指针进而进行传递的
2.
对于我们通过char ="***" 进行赋值得到的字符串是不能被改变的 因为它位于计算机的一个特殊的位置,不可改变
更多指针应用的详细图解等 见课件
字符串在内存中
其实有点点上面都有提到
这里总结一下字符串在内存中的一些要点
- 如果我们是通过char[] 的形式创建的字符串 ,那么我们是可以对其进行那个改变的,它位于电脑的堆栈空间中
- 对于已经创建的字符数组 我们不能对数组名进行重新赋值 ,它只能对其分配得到的内存块进行引用,同时字符数组的大小一经创建就是确定的了,不可进行修改
- 在以字符数组为参数进行传参时,是自动转换为字符指针进行传递的
- 我们用char* 创建的字符串是不可修改的,他存放于数据段中
- char* 是可以重新赋值的
- 可以通过对指针添加偏移量获得子串
- 对于通过字符串指针就行的字符修改 是持久的,可以保持到函数调度外
OK 本节结束
Lecture 6
More Pointers and Arrays
看标题就应该清楚这节的主要内容了
---- 更多关于指针和数组的内容
思考一个问题,我们如和在内存中管理所有类型的内存?????
指针和参数
在重提一下
指针----存储内存地址的变量,大小8个字节(忘记的往回看)
指针的好多内容前面已经说过了,重复是就略过了
C语言传递参数的方式
一般情况下就是拷贝一个副本
通常情况下 ,如果你正在进行某些操作,同时,并不关心对传入数据进行的任何更改,可以传递数据本身
反之如果我们想要修改某部分内容,那么应该传递其地址,这样可以对其进行持久性的修改
如果我们的参数是一个地址 ,那么当我们取值的时候 ,实际上是先到达其指定的地址,然后将地址内的内容取出
其实 char* 真正意义上是指向单个字符的指针,
不过我们通常是让他后面跟着一堆字符,然后以一个\0为终止标志 进行表示字符串的
如果我们在函数调用中修改了字符串的部分内容,那么,这些修改将持续到函数调用以外
在字符串作为参数时
- 如果传递的是char* 拷贝其指向的地址
- 如果传递的是字符数组传递字符数组中首元素地址
简单说 ::
- 不关心修改 随便传
- 想要修改 传地址
双重指针
有时,我们想要修改的是指针本身 ,而非 他说指向的数据
这时,我们就要用到双重指针了,也就是指向指针的指针
这里有一个具体的流程实例 (见课件 )
内存中的数组
数组的内存地址是连续的
声明数组后 堆栈上分配连续的内存空间
, 数组是存储在堆栈上的
数组变量引用指定的内存块,数组不能进行重新分配
数组创建后,大小不可改变
数组作为参数时,会传递首元素地址
所以,在函数中,我们不能用sizeof获取 数组的长度,他其实是一个指针
void myFunc(char *myStr) {
int size = sizeof(myStr); // 8
}
int main(int argc, char *argv[]) {
char str[3];
strcpy(str, "hi");
int size = sizeof(str); // 3
myFunc(str);
...
}
(sizeof 返回数组的长度或者指针的8 )
我们可以使用一个指针等于一个数组,让指针指向其首元素地址
int main(int argc, char *argv[]) {
char str[3];
strcpy(str, "hi");
char *ptr = str;
...
}
我们也可以创建一个指针数组,将多个字符串组合到一块
指针运算
先看一个例子
char *str = "apple"; // e.g. 0xff0
char *str1 = str + 1; // e.g. 0xff1
char *str3 = str + 3; // e.g. 0xff3
printf("%s", str); // apple
printf("%s", str1); // pple
printf("%s", str3); // le
注意 指针运算 不是以字节为单位的
而是 其所指向的数据类型的大小
// nums 指向一个int数组
int *nums = … // e.g. 0xff0
int *nums1 = nums + 1; // e.g. 0xff4
int *nums3 = nums + 3; // e.g. 0xffc
printf("%d", *nums); // 52
printf("%d", *nums1); // 23
* 取消引用
例
char *str = "apple"; // e.g. 0xff0
// both of these add two places to str,
// and then dereference to get the char there.
// E.g. get memory at 0xff2.
char thirdLetter = str[2]; // 'p'
char thirdLetter = *(str + 2); // 'p' 课件上的示例
两个指针的运算结果 返回的不是字节差
例如
// nums points to an int array
int *nums = … // e.g. 0xff0
int *nums3 = nums + 3; // e.g. 0xffc
int diff = nums3 - nums; // 3
这里的3的意思是这两个指针偏移了三个单位(其所指向的数据类型)
关于为什么指针在运算时知道自己应该偏移几个字节 ,
这里直接看课件上给定解释吧
At compile time, C can figure out the sizes of different data types, and the sizes of what they point to.
For this reason, when the program runs, it knows the correct number of bytes to address or add/subtract for each data type.
翻译:
在编译时,C可以计算出不同数据类型的大小,以及它们所指向的数据类型的大小 。
因此,当程序运行时,它知道每个数据类型要寻址或加/减的正确字节数。
其他内容 : const, struct and ternary
const
使用const 声明全局常量 这样声明的常量创建后不可修改
例
const double PI = 3.1415;
const int DAYS_IN_WEEK = 7;
int main(int argc, char *argv[]) {
…
if (x == DAYS_IN_WEEK) {
…
}
…
}
使用const标志的数据不能修改
例
char str[6];
strcpy(str, "Hello");
const char *s = str;
// 无法使用s更改它指向的字符
s[0] = 'h';
注意 const 声明的指针 其指向不可修改 ,但其本身可以修改
课件上的一个例子
// This function promises to not change str’s characters
int countUppercase(const char *str) {
int count = 0;
for (int i = 0; i < strlen(str); i++) {
if (isupper(str[i])) {
count++;
}
}
return count;
}
对于不同的变量类型你 const 的解释是不同的
// cannot modify this char
const char c = 'h';
// cannot modify chars pointed to by str
const char *str = …
// cannot modify chars pointed to by *strPtr
const char **strPtr = …
结构体
结构体是定义一组有其他变量类型组成的新的变量类型的方法
这一块比较简单
直接看书上的例子
struct date { // declaring a struct type
int month;
int day; // members of each date structure
};
…
struct date today; // construct structure instances
today.month = 1;
today.day = 28;
struct date new_years_eve = {12, 31}; // shorter initializer syntax
关于 typedef的用法
简单说就是改名 给某个变量类型起个新名字
例子
typedef struct date {
int month;
int day;
} date;
…
date today;
today.month = 1;
today.day = 28;
date new_years_eve = {12, 31};
在结构体作为参数的时候 采用传值的方式 拷贝整个副本
结构体也是存在指针的
例
void advance_day(date *d) {
(*d).day++;
}
int main(int argc, char *argv[]) {
date my_date = {1, 28};
advance_day(&my_date);
printf("%d", my_date.day); // 29
return 0;
}
对于结构体指针的应用 可以使用* 也可以采用另一种方式 ->
void advance_day(date *d) {
d->day++; // equivalent to (*d).day++;
}
int main(int argc, char *argv[]) {
date my_date = {1, 28};
advance_day(&my_date);
printf("%d", my_date.day); // 29
return 0;
}
同时 ,我们自己定义的结构体也是可以作为函数返回值类型的
date create_new_years_date() {
date d = {1, 1};
return d; // or return (date){1, 1};
}
int main(int argc, char *argv[]) {
date my_date = create_new_years_date();
printf("%d", my_date.day); // 1
return 0;
}
对于结构体 ,使用sizeof 返回结构体类型的大小
即所有组成部分的大小和
typedef struct date {
int month;
int day;
} date;
int main(int argc, char *argv[]) {
int size = sizeof(date); // 8
return 0;
}
同时 结构体也是可以像基本类型一样创建数组
typedef struct my_struct {
int x;
char c;
} my_struct;
…
my_struct array_of_structs[5];
需要注意的是 结构体数组 定义之后 要进行初始化 也别说对于有字符串等的情况
对于结构体数组可以一块初始化 ,也可以对于单个字段初始化
同时初始化
typedef struct my_struct {
int x;
char c;
} my_struct;
…
my_struct array_of_structs[5];
array_of_structs[0] = (my_struct){0, 'A'};
逐个初始化
typedef struct my_struct {
int x;
char c;
} my_struct;
…
my_struct array_of_structs[5];
array_of_structs[0].x = 2;
array_of_structs[0].c = 'A';
三目运算符
三目运算符 : 是否为真? 为真取值:为假取值
更具体的代码示例
int x;
if (argc > 1) {
x = 50;
} else {
x = 0;
}
// equivalent to
int x = argc > 1 ? 50 : 0;
OK 本节结束
Lecture 7 堆栈和堆
计划
堆栈
堆栈和内存分配
realloc 重新分配
堆栈
内存布局
堆栈存储 每次函数调用的变量和参数,函数调用使用的堆栈部分在函数返回是释放
函数调用时,堆栈向下增长 ,函数返回时,堆栈 ,向上收缩
更形象堆栈布局图,调用流程图 见课件
注意,每次函数调用都会产生相应的堆栈空间,唯一的属于自己的空间
还有一点就是当一个函数的堆栈空间使用完毕后,C语言不会对其进行清空处理,而是进行标记,标记该空间是可以使用的。 这样可以提高效率
什么是堆栈溢出
堆栈溢出是说您已经使用了所有的堆栈内存,然而,您还在进行堆栈调度。
例如,函数的递归,如果出口安排不合理,或递归次数过多,都会导致堆栈溢出。
堆栈注意事项
对于需要保留的数据,要存储在主函数的堆栈空间上
char *create_string(char ch, int num) {
char new_str[num + 1];
for (int i = 0; i < num; i++) {
new_str[i] = ch;
}
new_str[num] = '\0';
return new_str;
}
int main(int argc, char *argv[]) {
char *str = create_string('a', 4);
printf("%s", str); // want "aaaa"
return 0;
}
例如上面这个代码
它将需要返回的内容存在了堆栈调用时产生的堆栈空间上,在函数返回后,其就可能会被其他东西是有,导致数据丢失,甚至产生致命错误
尽管在短时间内,你的内容不会改变。
但这种代码终究是炸弹般的存在,
假如我们想要一中在函数调用后不会丢失的内存空间
堆和动态内存
除了堆栈之外,还存在一个特殊的内存空间,叫做堆,它需要我们自己进行管理,而且是随着调度向上增长的。
堆是一种动态的内存,在程序的运行过程中,我们可以根据自给的需求,进行内存申请内存释放。
malloc 函数
先看一下函数声明
void *malloc(size_t size);
参数为,所要申请的内存大小,参数返回指向申请得到的内存空间的首地址。
如果没有足够的内存空间,则返回NULL
这样就可以对前面的示例进行修改
得到一个可以放心使用的版本
char *create_string(char ch, int num) {
char *new_str = malloc(sizeof(char) * (num + 1));
for (int i = 0; i < num; i++) {
new_str[i] = ch;
}
new_str[num] = '\0';
return new_str;
}
int main(int argc, char *argv[]) {
char *str = create_string('a', 4);
printf("%s", str); // want "aaaa"
return 0;
}
堆中使用断言
int *array_of_multiples(int mult, int len) {
int *arr = malloc(sizeof(int) * len);
assert(arr != NULL);
for (int i = 0; i < len; i++) {
arr[i] = mult * (i + 1);
}
return arr;
}
这里断言的意思是
如果发生分配错误,malloc 将返回null 此时,我们直接结束程序
因为,内存分配错误是非常严重的
calloc堆分配函数
需要注意的是,calloc在调用时会清空内存,这也是他与malloc的一个重要区别
函数定义
void *calloc(size_t nmemb, size_t size);
注意这里有两个参数,表示申请大小为两数相乘的结果大小的内存空间
课件上的一个应用实例代码
// allocate and zero 20 ints
int *scores = calloc(20, sizeof(int));
// alternate (but slower)
int *scores = malloc(20 * sizeof(int));
for (int i = 0; i < 20; i++) scores[i] = 0;
strdup堆分配函数
函数声明
char *strdup(char *s);
此函数需要我们提供一个字符串 ,返回一个以空终止符结尾的堆分配的字符串,
与malloc相比,不需要我们再去专门复制字符串。
示例
char *str = strdup("Hello, world!"); // on heap
str[0] = 'h';
free清理函数
函数定义
void free(void *ptr);
前面说过,堆分配内存需要我们自己释放
这里就是说的释放方式
在使用时 ,传入要释放的内存的首地址,
char *bytes = malloc(4);
…
free(bytes);
free 的注意事项
对于一个申请得到的内存块,只能释放一次,即使有多个指针指向他
char *bytes = malloc(4);
char *ptr = bytes;
…
free(bytes); //正确
…
free(ptr);//错误
内存释放时,必须释放分配所得的地址,同时也不能只释放其中的一部分
char *bytes = malloc(4);
char *ptr = malloc(10);
…
free(bytes); //正确
…
free(ptr + 1);//错误
内存泄漏
内存泄漏是指,你在堆上申请内存,但是没有及时释放,事实上,你的程序有责任去清理申请的内存
这样就会导致内存耗尽。 进而导致内存泄漏,程序崩溃
其实真正的程序运行中,内存泄漏不常见,
只要你按照要求,及时释放掉无用内存空间,几乎不用担心内存泄漏的发生。
realloc 重新分配
void *realloc(void *ptr, size_t size);
先来看一个示例
char *str = strdup("Hello");
assert(str != NULL);
…
// want to make str longer to hold "Hello world!"
char *addition = " world!";
str = realloc(str, strlen(str) + strlen(addition) + 1);
assert(str != NULL);
strcat(str, addition);
printf("%s", str);
free(str);
realloc 接受一个现有的指针,并将其放大到请求大小。
并返回最新的指针
这个过程: 如果现有的后面剩余的长度够用,直接延长,不够就转移到申请的新的足够大的空间,并释放掉旧的空间。
在以前,只接受malloc返回的指针
同时,我们要确保不要吧指针传递到对分配内存
不要讲指针传递到堆栈内存
(这两句我也不是特别明白,后面要查查资料)
在使用realloc时,我们只需要释放重新分配得到的内存,旧的版本已经被释放了
和上面的例子一样
char *str = strdup("Hello");
assert(str != NULL);
…
// want to make str longer to hold "Hello world!"
char *addition = " world!";
str = realloc(str, strlen(str) + strlen(addition) + 1);
assert(str != NULL);
strcat(str, addition);
printf("%s", str);
free(str);
总结
void *malloc(size_t size);
void *calloc(size_t nmemb, size_t size);
void *realloc(void *ptr, size_t size);
char *strdup(char *s);
void free(void *ptr);
比较这几个函数的异同
堆内存分配保证:
失败时为NULL,因此请使用assert(断言)检查
内存是连续的;申请得到的内存要自行管理;除非调用free,否则不会回收
重新分配保留现有数据,释放旧的,保留新的
calloc zero初始化字节,malloc和realloc不初始化
违法行为:
如果溢出(即访问超出分配的字节)
如果你在free之后使用,或者free在一个位置被调用两次。
如果重新分配/释放非堆地址
堆栈和堆的对比
分配:
堆栈: 快速分配可以特别大,
堆: 可以过大,
灵活程度:
堆栈: 自动分配,释放.一步声明/初始化
堆: 非常灵活,自己觉得何时分配,分配大小,可重新分配调整大小
安全性:
堆栈: 安全性由编译器予以保证
堆: 出现错误的机会很多,低类型安全性,在完成之前忘记分配/释放,分配错误的大小等,内存泄漏
其余方面
堆栈:
不是特别大,总堆栈大小固定,默认8MB
有些不灵活,无法在运行时添加/调整大小,范围由函数的控制流指定
堆: 控制下的作用域可以精确地确定生存期
补充
在一般情况下,除非必要,一般使用堆栈内存
首选堆分配的情况
-
你需要一个非常大的分配,堆栈空间可能不足
-
您需要控制内存的生存期,或者内存必须在函数调用之外保持正常使用
-
您需要在初始分配内存后调整内存大小
由于这节函数有点多,多加几个 ,课程后面练习的代码
strdup的实现
char *myStrdup(char *str) {
char *heapStr = malloc(strlen(str) + 1);
assert(heapStr != NULL);
strcpy(heapStr, str);
return heapStr;
}
对于空间释放的合理位置的选择
待填充代码
char *str = strdup("Hello");
assert(str != NULL);
char *ptr = str + 1;
for (int i = 0; i < 5; i++) {
int *num = malloc(sizeof(int));
assert(num != NULL);
*num = i;
printf("%s %d\n", ptr, *num);
}
printf("%s\n", str);
填充后
char *str = strdup("Hello");
assert(str != NULL);
char *ptr = str + 1;
for (int i = 0; i < 5; i++) {
int *num = malloc(sizeof(int));
assert(num != NULL);
*num = i;
printf("%s %d\n", ptr, *num);
free(num);
}
printf("%s\n", str);
free(str);
OK本节结束
Lecture 8 C语言泛型,void型指针
下先来思考一个问题 : 我们如何编写可以处理任何数据类型的代码
本节内容主要是:
- 学习编写可以处理任何类型数据的代码
- 了解void * 的使用,同时避免出现错误
泛型概述
泛型代码能够减少代码重复,这意味着在出现错误时间,只需要在一个地方进行修改。一般情况下应用于: 函数排序,搜索任意类型的数组,释放内存等等
泛型交换
我们来一个情景再现:
现在,我们要写一个交换int类型数据的函数
void swap_int(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
int main(int argc, char *argv[]) {
int x = 2;
int y = 5;
swap_int(&x, &y);
// want x = 5, y = 2
printf("x = %d, y = %d\n", x, y);
return 0;
}
OK 这是我们的代码
那么现在,我们有不想交换int了 , 我们要交换short
怎么办呢??重写!!
void swap_short(short *a, short *b) {
short temp = *a;
*a = *b;
*b = temp;
}
int main(int argc, char *argv[]) {
short x = 2;
short y = 5;
swap_short(&x, &y);
// want x = 5, y = 2
printf("x = %d, y = %d\n", x, y);
return 0;
}
OK 我们现在发现,我们要交换的其实是字符串
怎么办 ???? 继续重写
void swap_string(char **a, char **b) {
char *temp = *a;
*a = *b;
*b = temp;
}
int main(int argc, char *argv[]) {
char *x = "2";
char *y = "5";
swap_string(&x, &y);
// want x = 5, y = 2
printf("x = %s, y = %s\n", x, y);
return 0;
}
OK 现在问题又来了 ,
我们现在有好多种自定义的结构体要进行交换 。 怎么说 ???
OK现在问题来了。
我们想编写一个函数,能够交换任意类型的两个值
前面我们写的交换全部是同一种模式
- 传递两个指针进入函数。指向要交换的两个值
- 创建临时变量,作为交换媒介
- 进行交换
OK 现在,建模
void swap(pointer to data1, pointer to data2) {
store a copy of data1 in temporary storage
copy data2 to location of data1
copy data in temporary storage to location of data2
}
上面是课件版的模型
OK 先看参数 ,两个指针,不多说
第二行
建立临时空间,存储data1的副本
那么问题哦就来了,不同的数据类型,大小不一样啊,比如,int四个字节,char一个字节,等等 !!
在前面进行拷贝时,C语言自己知道应该拷贝多少字节,因为它知道数据类型。
那么我们的这种泛型要求的是一种++不关心数据类型++制作变量副本,有没有这样的方法呢???
处于这样的目的,我们修改参数类型为void * (不关心类型)
这样,我们就不知道数据类型的大小,所以我们增加一个记录大小的参数
为了过得副本,我们再获得对应大小的内存空间
修改后的代码:
void swap(void *data1ptr, void *data2ptr, size_t nbytes) {
char temp[nbytes];
// store a copy of data1 in temporary storage
temp = *data1ptr; ???
// copy data2 to location of data1
// copy data in temporary storage to location of data2
}
这样就出问题了,我们怎么制作副本,C语言赋值,开玩笑,C语言都不知道什么类型,你怎么赋值
下面就要介绍一个函数了:
memcpy
函数声明:
void *memcpy(void *dest, const void *src, size_t n);
简单说一下该函数的作用,从src指向的地址 向dest指向的地址拷贝
n个字节的内容
memcpy 的参数一定要使用指向要处理的数据的指针,才能正常的进行后续操作,程序才能真正的知道,从哪拷贝,拷贝到那里,拷贝多少内容
menmove
void *memmove(void *dest, const void *src, size_t n);
memmove 和memcpy具有相同的功能,不同的是前者支持重叠区域
该函数的作用是 : 从src指向的地址想dest指向的地址拷贝n个字节的内容 。同时返回dest
例如 :
#include <stdio.h>
#include<string.h>
int main()
{
char a[]="123456789";
memmove(a,a+4,4);
printf("%s\n",a);// 567856789
return 0;
}
再回到泛型
我们在定义指针类型时,不能使用void* 这样C语言不知道自己指向的是什么。
那么,应怎么合理的使用 memcpy 。memmove ,来便于我们编写泛型呢???
void swap(void *data1ptr, void *data2ptr, size_t nbytes) {
char temp[nbytes];
// store a copy of data1 in temporary storage
memcpy(temp, data1ptr, nbytes);
// copy data2 to location of data1
// copy data in temporary storage to location of data2
}
我们可以使用memcpy直接拷贝字节 ,不关心类型, 反正我们已经有了长度
OK ,下面有同样的方法实现数据交换
void swap(void *data1ptr, void *data2ptr, size_t nbytes) {
char temp[nbytes];
// store a copy of data1 in temporary storage
memcpy(temp, data1ptr, nbytes);
// copy data2 to location of data1
memcpy(data1ptr, data2ptr, nbytes);
// copy data in temporary storage to location of data2
memcpy(data2ptr, temp, nbytes);
}
这样就是,我们直接操作内存,不关心数据类型,进行数据交换
。这样我们只需要知道,大小以及位置即可
泛型陷阱
void*
void* 是很危险的,对于任何一种数据类型,例如int ,我们总不能交换半个int吧
所以如果操作稍有不慎就会导致错误
OK,现在 ,梳理几个问题
什么样的变量类型代表“泛型指针”?
我们可以使用哪种变量类型在堆栈上创建特定数量的空间?
我们如何将通用内存从一个位置复制到另一个位置?
memcpy和memmove有什么区别?
C语言中泛型函数的好处是什么?挑战是什么?
这些内容前面都有提过,回忆一下
泛型数组交换
现在,编写一个函数,交换int 数组的首尾
void swap_ends_int(int *arr, size_t nelems) {
int tmp = arr[0];
arr[0] = arr[nelems – 1];
arr[nelems – 1] = tmp;
}
int main(int argc, char *argv[]) {
int nums[] = {5, 2, 3, 4, 1};
size_t nelems = sizeof(nums) / sizeof(nums[0]);
swap_ends_int(nums, nelems);
// want nums[0] = 1, nums[4] = 5
printf("nums[0] = %d, nums[4] = %d\n", nums[0], nums[4]);
return 0;
}
现在,我们是不是可以用到刚才我们编写好的泛型交换函数呢
void swap_ends_int(int *arr, size_t nelems) {
swap(arr, arr + nelems – 1, sizeof(*arr));
}
int main(int argc, char *argv[]) {
int nums[] = {5, 2, 3, 4, 1};
size_t nelems = sizeof(nums) / sizeof(nums[0]);
swap_ends_int(nums, nelems);
// want nums[0] = 1, nums[4] = 5
printf("nums[0] = %d, nums[4] = %d\n", nums[0], nums[4]);
return 0;
}
。
现在吧数据类型变一下试一试:
void swap_ends_int(int *arr, size_t nelems) {
swap(arr, arr + nelems – 1, sizeof(*arr));
}
void swap_ends_short(short *arr, size_t nelems) {
swap(arr, arr + nelems – 1, sizeof(*arr));
}
void swap_ends_string(char **arr, size_t nelems) {
swap(arr, arr + nelems – 1, sizeof(*arr));
}
void swap_ends_float(float *arr, size_t nelems) {
swap(arr, arr + nelems – 1, sizeof(*arr));
}
OK ,现在看这个代码
void swap_ends(void *arr, size_t nelems) {
swap(arr, arr + nelems – 1, sizeof(*arr));
}
思考一下,这个代码是通用的那?? 是否可以正常使用
,不行!!
- 前面有说过,指针的运算偏移量的大小取决于其所指向的数据类型的大小。这里没有类型,怎么运算
- 而且,我没让你也不知道数据类型的大小,后操作也无法进行
所以我们要添加参数,解决上述问题
OK 看修正版
void swap_ends(void *arr, size_t nelems, size_t elem_bytes) {
swap(arr, arr + nelems – 1, elem_bytes);
}
现在还有问题吗??
当然有,偏移量问题
在不同的数据类型下,偏移量的字节大小是不同的。
很明显,这里错了,这里没有类型,
所以我们要知道元素的大小,才能正常使用指针运算,才能完成泛型函数
OK 新版来了
void swap_ends(void *arr, size_t nelems, size_t elem_bytes) {
swap(arr, arr + (nelems – 1) * elem_bytes, elem_bytes);
}
那么问题来了: 前面有说过C语言不能对void* 指针进行运算
怎么解决????
因为我们偏移的是字节量
所以我们用 char *
void swap_ends(void *arr, size_t nelems, size_t elem_bytes) {
swap(arr, (char *)arr + (nelems – 1) * elem_bytes, elem_bytes);
}
OK 这个代码就能够是实现任何数据类型的数组交换
OK 看几个应用示例:
short nums[] = {5, 2, 3, 4, 1};
size_t nelems = sizeof(nums) / sizeof(nums[0]);
swap_ends(nums, nelems, sizeof(nums[0]));
short nums[] = {5, 2, 3, 4, 1};
size_t nelems = sizeof(nums) / sizeof(nums[0]);
swap_ends(nums, nelems, sizeof(nums[0]));
char *strs[] = {"Hi", "Hello", "Howdy"};
size_t nelems = sizeof(strs) / sizeof(strs[0]);
swap_ends(strs, nelems, sizeof(strs[0]));
mystruct structs[] = …;
size_t nelems = …;
swap_ends(structs, nelems, sizeof(structs[0]));
泛型堆栈
OK,现在尝试用泛型实现一个堆栈
先来熟悉一下堆栈
堆栈是表示一堆东西的数据结构。
对象可以被推到堆栈顶部或从堆栈顶部弹出。
只能访问堆栈的顶部;堆栈中的其他对象不可见。
主要业务:
push(value):将元素添加到堆栈顶部
pop():移除并返回堆栈中的顶层元素
peek():返回(但不要移除)堆栈中的顶层元素
一把情况下,C语言使用链表实现堆栈
看一下,一般堆栈的实现
typedef struct int_node {
struct int_node *next;
int data;
} int_node;
typedef struct int_stack {
int nelems;
int_node *top;
} int_stack;
由于我们不知道的数据类型是不确定的,所有我们要做修改
同时,我们需要知道数据类型的字节大小
typedef struct int_node {
struct int_node *next;
void *data;
} int_node;
typedef struct stack {
int nelems;
int elem_size_bytes;
node *top;
} stack;
下面看一般堆栈的功能
int_stack_create():在堆上创建新堆栈并返回指向它的指针
int_stack_push(int_stack*s,int data):将数据推送到堆栈上
int_stack_pop(int_stack*s):弹出并返回最顶层的堆栈元素
int_stack_create
int_stack *int_stack_create() {
int_stack *s = malloc(sizeof(int_stack));
s->nelems = 0;
s->top = NULL;
return s;
}
我们要怎们修改来实现我们的泛型要求呢
stack *stack_create(int elem_size_bytes) {
stack *s = malloc(sizeof(stack));
s->nelems = 0;
s->top = NULL;
s->elem_size_bytes = elem_size_bytes;
return s;
}
OK, 第一个功能实现
int_stack_push
一般实现
void int_stack_push(int_stack *s, int data) {
int_node *new_node = malloc(sizeof(int_node));
new_node->data = data;
new_node->next = s->top;
s->top = new_node;
s->nelems++;
}
由于我们的数据类型是不确定的,所以不能传递数据本身,因为太多变了。
所以传递指针
,同时,我们要自己制作数据的副本,不能直接赋值传递得到的指针
因为,该指针的生命周期我们无法管理,
所以,我们的实现如下
void stack_push(stack *s, const void *data) {
node *new_node = malloc(sizeof(node));
new_node->data = malloc(s->elem_size_bytes);
memcpy(new_node->data, data, s->elem_size_bytes);
new_node->next = s->top;
s->top = new_node;
s->nelems++;
}
int_stack_pop
正常的实现
int int_stack_pop(int_stack *s) {
if (s->nelems == 0) {
error(1, 0, "Cannot pop from empty stack");
}
int_node *n = s->top;
int value = n->data;
s->top = n->next;
free(n);
s->nelems--;
return value;
}
怎么修改?
我们不能直接返回数据 ,因为数据类型不确定
如果传递一个指针回去的话,那么,谁来负责释放它呢??
使用者才不管你那么多,
所以我们要调用者再给我们一个地址,我们传递到那个地址上,这样就没我们的事了,就算需要释放也是使用者的问题了
实现:
void stack_pop(stack *s, void *addr) {
if (s->nelems == 0) {
error(1, 0, "Cannot pop from empty stack");
}
node *n = s->top;
memcpy(addr, n->data, s->elem_size_bytes);
s->top = n->next;
free(n->data);
free(n);
s->nelems--;
}
OK ,我们来使用一下,泛型堆栈
正常的堆栈使用
int_stack *intstack = int_stack_create();
for (int i = 0; i < TEST_STACK_SIZE; i++) {
int_stack_push(intstack, i);
}
由于泛型堆栈不能直接传递数据本身
所以 ,传递地址
stack *intstack = stack_create(sizeof(int));
for (int i = 0; i < TEST_STACK_SIZE; i++) {
stack_push(intstack, &i);
}
对于正常的使用
int_stack *intstack = int_stack_create();
int_stack_push(intstack, 7);
我们都要转换为
stack *intstack = stack_create(sizeof(int));
int num = 7;
stack_push(intstack, &num);
还有 ,在输出元素时, 正常为
// Pop off all elements
while (intstack->nelems > 0) {
printf("%d\n", int_stack_pop(intstack));
}
我们要做修改,因为,我们要传递指针接受数据,进而输出
// Pop off all elements
int popped_int;
while (intstack->nelems > 0) {
int_stack_pop(intstack, &popped_int);
printf("%d\n", popped_int);
}
要点
C语言有一种指针类型,void*
对于void* 的指针,我们不能对其进行取消引用操作和指针运算操作
我们可以使用mencpy, memmove ,直接从内存位置进行拷贝
对于void* 的指针运算,我们一般先将其转换为char*,不过由于类型多变的原因,使用时要多多注意。
OK 本节结束
Lecture 9 C 泛型--函数指针
目前为止的泛型
关于void* 就不多介绍了,以及泛型交换,泛型数组交换,泛型注意事项等的前面都有。 我只写前面没有提到的内容
memset
函数声明
void *memset(void *s, int c, size_t n);
它的作用是将一个指定地址的指定字节数设置为指定值。
带入里面就是说,用c 去填充从s地址开始的m个字节
int counts[5];
memset(counts, 0, 3); // zero out first 3 bytes at counts
memset(counts + 3, 0xff, 4) // set 3rd entry’s bytes to 1s
为什么void * 很强大
- 对于需要接受多种数据类型的函数参数,它需要能够接收不同大小的数据类型。但是指针的大小都是一样的(八个字节),不管他指向的数据类型是什么,都可以通过指针传递。
- 这样就需要我们在定义形参数,设置为指针,但是,不同数据类型的指针定义又不一样,又该怎么办呢。
- void* 就解决了这个问题,它可以指向任何类型,只要在接受到后,强制转换类型即可。
这就显示出了void*的 强大功能。
泛型冒泡排序
现在我们来写一个函数对整型进行排序,我们使用冒泡排序。
原理不对说。
void bubble_sort_int(int *arr, int n) {
while (true) {
bool swapped = false;
for (int i = 1; i < n; i++) {
if (arr[i - 1] > arr[i]) {
swapped = true;
swap_int(&arr[i - 1], &arr[i]);
}
}
if (!swapped) {
return;
}
}
}
现在,能不能把它变成能够给任意数据类型排序的函数呢。
第一步,修改形参。
void bubble_sort(void *arr, int n, int elem_size_bytes) {
while (true) {
bool swapped = false;
for (int i = 1; i < n; i++) {
if (arr[i - 1] > arr[i]) {
swapped = true;
swap(&arr[i - 1], &arr[i], elem_size_bytes);
}
}
if (!swapped) {
return;
}
}
}
前面有关于数组首位的泛型交换函数,现在把它推广到任意第i个位置的交换。
void swap_ends(void *arr, size_t nelems, size_t elem_bytes) {
swap(arr, (char *)arr + (nelems – 1) * elem_bytes, elem_bytes);
}
OK ,修改为
void *ith_elem = (char *)arr + i * elem_bytes;
这样就可以实现第i个的交换。
修正版:
void bubble_sort(void *arr, int n, int elem_size_bytes) {
while (true) {
bool swapped = false;
for (int i = 1; i < n; i++) {
void *p_prev_elem = (char *)arr + (i - 1) * elem_size_bytes;
void *p_curr_elem = (char *)arr + i * elem_size_bytes;
if (*p_prev_elem > *p_curr_elem) {
swapped = true;
swap(p_prev_elem, p_curr_elem, elem_size_bytes);
}
}
if (!swapped) {
return;
}
}
}
发现问题没有????
- 前面说过,不能对void* 进行取消引用。
- void*的指向 不可能一直是int等的这种可以直接用>进行比较的类型。
所以现在遇到一个问题,我们无法对一个不确定的数据类型进行比较,无法比较,我们的代码就不能正常使用。
怎么办???
虽然泛型函数不知道类型,但是身为调用者肯定是知道的对吧。
所以,我们要去问调用者,
函数指针
好的,我们说了,要询问调用者怎么进行数据比较。
那么具体怎么弄??
因为调用者知道数据类型,以及比较方案,那么,我们要调用者给我们一个比较函数。
compare_fn(p_prev_elem, p_curr_elem)
现在有了比较方案,排序函数,怎么去调用这个函数呢???
我们可以搞一个函数指针,调用者吧这个函数作为参数传递给我们。
void bubble_sort(void *arr, int n, int elem_size_bytes,
bool (*compare_fn)(void *a, void *b)) {
while (true) {
bool swapped = false;
for (int i = 1; i < n; i++) {
void *p_prev_elem = (char *)arr + (i - 1) * elem_size_bytes;
void *p_curr_elem = (char *)arr + i * elem_size_bytes;
if (compare_fn(p_prev_elem, p_curr_elem)) {
swapped = true;
swap(p_prev_elem, p_curr_elem, elem_size_bytes);
}
}
if (!swapped) {
return;
}
}
}
下面,怎样声明参数的类型。
通用语法如下
[return type] (*[name])([parameters])
OK 现在来个具体的。
bool (*compare_fn)(void *a, void *b)
上面这个声明一个返回值为bool,名字叫compare_fn,参数为两个void* 的一个函数的函数指针
OK 现在,我们的泛型排序函数就完成了。
void bubble_sort(void *arr, int n, int elem_size_bytes,
bool (*compare_fn)(void *a, void *b)) {
while (true) {
bool swapped = false;
for (int i = 1; i < n; i++) {
void *p_prev_elem = (char *)arr + (i - 1) * elem_size_bytes;
void *p_curr_elem = (char *)arr + i * elem_size_bytes;
if (compare_fn(p_prev_elem, p_curr_elem)) {
swapped = true;
swap(p_prev_elem, p_curr_elem, elem_size_bytes);
}
}
if (!swapped) {
return;
}
}
}
只不过没我们需要调用者给我们一个比较的方法。
看几个应用实例
bool integer_compare(void *ptr1, void *ptr2) {
...
}
int main(int argc, char *argv[]) {
int nums[] = {4, 2, -5, 1, 12, 56};
int nums_count = sizeof(nums) / sizeof(nums[0]);
bubble_sort(nums, nums_count, sizeof(nums[0]), integer_compare);
...
}
bool string_compare(void *ptr1, void *ptr2) {
...
}
int main(int argc, char *argv[]) {
char *classes[] = {"CS106A", "CS106B", "CS107", "CS110"};
int arr_count = sizeof(classes) / sizeof(classes[0]);
bubble_sort(classes, arr_count, sizeof(classes[0]), string_compare);
...
}
在回顾一下,泛型排序的函数声明
void bubble_sort(void *arr, int n, int elem_size_bytes,
bool (*compare_fn)(void *a, void *b))
还有一点就是: 由于我们泛型的数据大小是不确定的,我们要传给比较函数的数据也是不定大小的,
那么,怎么让比较函数可以接收任意大小的数据呢,——-用指针,
因为指针有分类型,多以,用的是void *
而且,由于不同的比较函数,比较的类型不同,同时,我们也不能对void*进行取消引用。
所以,比较函数在接收到void* 后,需对其进行强制类型转换,转换为要比较的类型。
同时,我们的泛型排序函数所接受的比较函数也必须是泛型的,因为要处理任意类型的数据。
例如:
bool integer_compare(void *ptr1, void *ptr2) {
// 1) cast arguments to int *s
int *num1ptr = (int *)ptr1;
int *num2ptr = (int *)ptr2;
// 2) dereference typed points to access values
int num1 = *num1ptr;
int num2 = *num2ptr;
// 3) perform operation
return num1 > num2;
}
也可以这样写:
bool integer_compare(void *ptr1, void *ptr2) {
return *(int *)ptr1 > *(int *)ptr2;
}
许多的C语言的标准库都提供了标准函数,它们一般返回
如果第一个值大于第二个值,返回>0
如果第一个值小于第二个值,返回<0
如果相等,返回0
这与strcmp的返回值格式相同!
例如
int integer_compare(void *ptr1, void *ptr2) {
return *(int *)ptr1 – *(int *)ptr2;
}
这样就可以将泛型排序改写成
void bubble_sort(void *arr, int n, int elem_size_bytes,
int (*compare_fn)(void *a, void *b)) {
while (true) {
bool swapped = false;
for (int i = 1; i < n; i++) {
void *p_prev_elem = (char *)arr + (i - 1) * elem_size_bytes;
void *p_curr_elem = (char *)arr + i * elem_size_bytes;
if (compare_fn(p_prev_elem, p_curr_elem) > 0) {
swapped = true;
swap(p_prev_elem, p_curr_elem, elem_size_bytes);
}
}
if (!swapped) {
return;
}
}
}
现在,我们来写一个,字符串排序时的比较函数,按照字母表的顺序
int string_compare(void *ptr1, void *ptr2) {
// cast arguments and dereference
char *str1 = *(char **)ptr1;
char *str2 = *(char **)ptr2;
// perform operation
return strcmp(str1, str2);
}
函数指针陷阱
由于将函数作为参数传递个函数后,调用时需要传递符合要求的参数,但是如果传递错了怎么办??!!!
泛型打印
泛型有很多用途
例如
比较给定类型的两个元素的函数
打印给定类型的元素的函数
释放与给定类型相关联的内存的函数
等等还有很多
比较
int (*cmp_fn)(void *addr1, void *addr2)
输出
void (*print_fn)(void *addr)
还有更多。。。。
还有一种函数指针的使用方法:
不太好形容,直接看例子好了
int do_something(char *str) {
…
}
int main(int argc, char *argv[]) {
…
int (*func_var)(char *) = do_something;
…
func_var("testing");
return 0;
}
泛型C语言标准库
qsort--
可以对任何类型的数组进行排序!为了做到这一点,需要你提供一个函数,可以比较要求排序的两个元素。
bsearch-–可以使用二进制搜索来搜索任何类型数组中的键!为此,需要提供一个函数,可以比较要求搜索的两个元素。
lfind-–我可以使用线性搜索来搜索任何类型数组中的键!为此,需要提供一个函数,可以比较要求搜索的两个元素。
lsearch--可以使用线性搜索来搜索任何类型数组中的键!如果找不到,也会加上。为了做到这一点,需要提供一个函数,可以比较要求搜索的两个元素。
更具体的英文介绍见课件,我翻译的不太标准
还有好多自己百度
要点
可以将函数做为参数传递给函数,
比较函数比较常用,一般用于比较两个指针所指向的地址处的元素。
在应用泛型数,必须传递指向其所关心的数据类型的指针,因为任何比较函数只对应一个类型。
泛型是使用概述
- 使用memcpy,memmove ,实现数据操作的泛型化。
- 使用函数指针实现逻辑功能通用化。
OK 本节结束
Lecture 10 汇编介绍
接下来的这几节主要学习汇编
- Moving data around : The Lecture (这节课--移动数据 )
- Arithmetic and logical operations : Lecture 11(算术和逻辑运算)
- Control flow : Lecture 12 (控制流)
- Function calls : Lecture 13 (函数调用)
GCC 和 汇编
数据表示
- 整数(无符号整数,有符号整数(补码))
- 字符(ASC码)
- 地址(无符号长整型)
- 集合(数组,结构体。)
GCC
GCC 可以将您的可读代码转换为机器可读指令。
不管是C语言还是其他语言,计算机都是看不懂的,纯正的机器代码全是0和1,但是我们可以以另一种方式去阅读它。称之为汇编。
下面看看汇编是什么样的。
汇编示例
int sum_array(int arr[], int nelems) {
int sum = 0;
for (int i = 0; i < nelems; i++) {
sum += arr[i];
}
return sum;
}
转换为汇编
00000000004005b6 <sum_array>:
4005b6: ba 00 00 00 00 mov $0x0,%edx
4005bb: b8 00 00 00 00 mov $0x0,%eax
4005c0: eb 09 jmp 4005cb <sum_array+0x15>
4005c2: 48 63 ca movslq %edx,%rcx
4005c5: 03 04 8f add (%rdi,%rcx,4),%eax
4005c8: 83 c2 01 add $0x1,%edx
4005cb: 39 f2 cmp %esi,%edx
4005cd: 7c f3 jl 4005c2 <sum_array+0xc>
4005cf: f3 c3 repz retq
这是函数的名称,以及该函数代码开始的内存地址。
00000000004005b6 <sum_array>:
这是每条指令的内存地址,顺序指令在内存中也是顺序的。
4005b6:
4005bb:
4005c0:
4005c2:
4005c5:
4005c8:
4005cb:
4005cd:
4005cf:
这是汇编代码,每个指令都是可读版本。
mov $0x0,%edx
mov $0x0,%eax
jmp 4005cb <sum_array+0x15>
movslq %edx,%rcx
add (%rdi,%rcx,4),%eax
add $0x1,%edx
cmp %esi,%edx
jl 4005c2 <sum_array+0xc>
repz retq
这是机器代码:原始十六进制指令,表示计算机读取的二进制。不同的指令可能具有不同的字节长度。
ba 00 00 00 00
b8 00 00 00 00
eb 09
48 63 ca
03 04 8f
83 c2 01
39 f2
7c f3
f3 c3
每一条指令都有一个操作名称
每个指令还有参数
$[number] 表示一个常熟,或称作立即数。
%[name]表示寄存器,即CPU上的存储位置(例如edx) %edx
寄存器和汇编的抽象等级
汇编抽象
C抽象了机器代码的底层细节,所以我们能够使用变量,和其他更高级的抽象。
不过,汇编代码只有字节,没有变量等等的一些概念,汇编作用于特定的处理器,
他的抽象级别是寄存器。
或者说,它的操作单位是寄存器。
寄存器
什么是寄存器,
寄存器是CPU上的可以快速读写的小型存储区域。
- 寄存器有64位,也就是8字节。
- 一共有16个寄存器。每一个都有唯一的名称
- 寄存器就像处理器的“草稿纸”。正在计算或处理的数据首先移至寄存器。操作在寄存器上执行。
- 寄存器还保存参数和函数的返回值。
- 寄存器非常快!
- 处理器指令主要包括将数据移入/移出寄存器并对其进行算术运算。这是程序必须执行的逻辑级别!
汇编指令就是操作这些寄存器,
例如,在寄存器中加两个数字,将数据从寄存器传输到内存,将数据从内存移到寄存器。等等。
关于计算机的架构,课件上有更形象的配图,
GCC和汇编
GCC将编译你的程序,在堆栈和堆上分配内存,并生成汇编指令以访问这些内存位置并进行计算。
例如 :
C语言
int sum = x + y;
汇编级别将抽象为
Copy x into register 1
Copy y into register 2
Add register 2 to register 1
Write register 1 to memory for sum
这个就不翻译了。
下面将要学习的指令为 x86-64指令集体系结构
该指令集由Intel和AMD处理器使用。
还有许多其他指令集:ARM,MIPS等。
mov 指令
mov 指令将字节从一个位置复制到另一个位置,类似‘=’。
例如
mov src,dst
其中 :
- 只有src可以是立即数,也就是说常数。
- 二者皆可以是寄存器
- 二者最多可以有一个是内存位置。
下面是示例。
mov $0x104,_____
将值0x104复制到某个位置。
mov %rbx,____
将寄存器%rbx中的值复制到某个位置。
mov ____,%rbx
将值从某个来源复制到寄存器%rbx。
mov 0x104,_____
将地址0x104处的值复制到某个目的地
mov _____,0x104
将值从某个来源复制到地址0x104的内存中
课件上的一个练习
以下移动指令(单独执行)的结果是什么?对于这个问题,假设值5存储在地址0x42,而值8存储在%rbx中。
mov $0x42,%rax
mov 0x42,%rax
mov %rbx,0x55
带括号的用法
mov (%rbx),_____
将存储在%rbx存储的地址处的值拷贝到某个目标,
mov _____,(%rbx)
从一个源头往%rbx存储的内存地址处拷贝数据。
mov 0x10(%rax),_________
拷贝%rax存储的地址加上0x10对应的地址处的值拷贝到某个目标处。
mov __________,0x10(%rax)
从某个源头向%rax存储的值加上0x10对应是地址处拷贝数据。
mov (%rax,%rdx),__________
将 %rax和%rdx处存储的值的和所对应的地址处 的值拷贝到目标处。
mov ___________,(%rax,%rdx)
从某个源头向%rax和%rdx处存储的值的和所对应的地址拷贝数据。
mov 0x10(%rax,%rdx),______
将0x10加上寄存器%rax和%rdx中的值之和对应的地址处的值复制到某个目的地。
mov _______,0x10(%rax,%rdx)
从某个源向地址址是(0x10加上寄存器%rax和%rdx中的值之和)的位置拷贝数据。
练习
以下移动指令(单独执行)的结果是什么?对于这个问题,假设值0x11存储在地址0x10C,0xAB存储在地址0x104,0x100存储在寄存器%rax中,0x3存储在%rdx中。
mov $0x42,(%rax)
mov 4(%rax),%rcx
mov 9(%rax,%rdx),%rcx
Imm(rb, ri) is equivalent to address Imm + R[rb] + R[ri]
Imm 正或负或缺失
上面是公式。
rb 如果缺失就当0算。ri也是。
另一个公式。
这个的示例就不给了,自己理解。
Imm(rb,ri,s) is equivalent to… Imm + R[rb] + R[ri]*s
其中 ,Imm为正或负,缺失为0
rb 缺失当0,ri也是。
s必须为1、2、4或8(如果缺少,则=1)
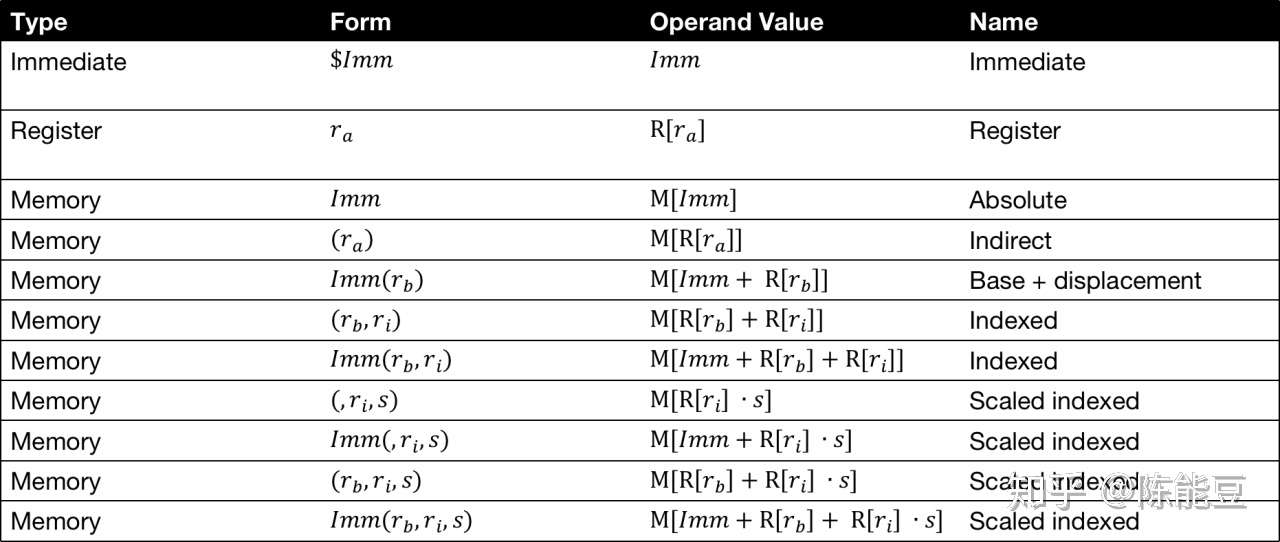
OK 上面是更具体的介绍。
练习
以下移动指令(单独执行)的结果是什么?对于这个问题,假设值0x1存储在寄存器%rcx中,值0x100存储在寄存器%rax中,值0x3存储在寄存器%rdx中,值0x11存储在地址0x10C。
mov $0x42,0xfc(,%rcx,4)
mov (%rax,%rdx,4),%rbx
提示:
公式:
Imm(rb, ri, s) is equivalent to address Imm + R[rb] + R[ri]*s
OK 现在回顾一下
int sum_array(int arr[], int nelems) {
int sum = 0;
for (int i = 0; i < nelems; i++) {
sum += arr[i];
}
return sum;
}
00000000004005b6 <sum_array>:
4005b6: ba 00 00 00 00 mov $0x0,%edx
4005bb: b8 00 00 00 00 mov $0x0,%eax
4005c0: eb 09 jmp 4005cb <sum_array+0x15>
4005c2: 48 63 ca movslq %edx,%rcx
4005c5: 03 04 8f add (%rdi,%rcx,4),%eax
4005c8: 83 c2 01 add $0x1,%edx
4005cb: 39 f2 cmp %esi,%edx
4005cd: 7c f3 jl 4005c2 <sum_array+0xc>
4005cf: f3 c3 repz retq
现在看看能看懂什么???
当然以后还会讲这个例子、
OK 本节结束,下一节,深入了解汇编。。
Lecture 11 汇编:运算和逻辑运算
很显然,本节主要说 在汇编中执行算术运和逻辑运算。
课件里面提供了一些资源:
我就不做翻译了,
Course textbook (reminder: see relevant readings for each lecture on the Schedule page, http://cs107.stanford.edu/schedule.html)
CS107 Assembly Reference Sheet: http://cs107.stanford.edu/resources/x86-64-reference.pdf
CS107 Guide to x86-64: http://cs107.stanford.edu/guide/x86-64.html
原模原样奉上、
截止到目前的mov指令
前面的只是初步介绍这里详细的介绍。
这里对内存位置在复习一下。
后面的表格都是直接上图,简单的英文还是要会的,太复杂的我会翻译
还有对所有格式的介绍
数据和寄存器大小
在汇编中数据大小的表示略有不同。
原文是
A byte is 1 byte.
A word is 2 bytes.
A double word is 4 bytes.
A quad word is 8 bytes.
翻译过来是
一个字节是1个字节。
一个字是2个字节。
双字是4字节。
四字是8字节。
汇编可以使用后缀表示大小
后缀有:
- b表示一个字节
- w表示一个字
- l表示一个双字
- q表示一个四字
更详细内容见下图
有一些寄存器在程序执行过程中有特殊任务
- %rax存储返回值
- %rdi将第一个参数存储到函数中
- %rsi将第二个参数存储到函数中
- %rdx将第三个参数存储到函数中
- %rip存储下一条要执行的指令的地址
- %rsp存储当前栈顶的地址
mov的变形
mov可以添加后缀来表示所要移动的数据的大小。
例如: movb,movw,movl,movq.
这样指令就只会更新指定的寄存器字节或内存位置。
例如: movl 在将数据写入寄存器的同时也会将高四位的字节归零。
练习,给下面的mov添加合适的后缀
mov__ %eax, (%rsp)
mov__ (%rax), %dx
mov__ $0xff, %bl
mov__ (%rsp,%rdx,4),%dl
mov__ (%rdx), %rax
mov__ %dx, (%rax)
答案:
movl %eax, (%rsp)
movw (%rax), %dx
movb $0xff, %bl
movb (%rsp,%rdx,4),%dl
movq (%rdx), %rax
movw %dx, (%rax)
movabsq
movabsq指令常用于写入64位的立即数。
例如
movabsq $0x0011223344556677, %rax
因为,正常情况下,movq只接受32位立即数。
64位的话会被当做一个目的地而非立即数。
movz和movs
这两个指令用于将较小的数据赋给较大的目的地。
movz用零填充剩余的字节
movs通过符号扩展源中最高有效位来填充剩余的字节。
同时,使用时,来源必须是寄存器或内存地址,目的地必须是寄存器。
下面是使用方法总结
lea指令
lea src,dst
lea指令的操作方式与mov类似,区别在于如歌处理src。
mov是操作src地址处的数据,而lea是直接操作src。
同时,他们的目标也就是dst操作是一样的。
操作具体解释
逻辑运算和算术运算
一元指令
效果就不多说了吧。
示例:
incq 16(%rax)
dec %rdx
not %rcx
二元指令
下面的指令要有两个操作数
需要注意的是,两个操作数可以是寄存器或内存,源数也可以是立即数,但是不能都是内存地址。
OK:
看图
示例:
addq %rcx,(%rax)
xorq $16,(%rax, %rdx, 8)
subq %rdx,8(%rax)
大数乘法
如果64位的数相乘会得到128位的结果,但是在x86里面只有64位寄存器。
那怎么办呢??
imul
如果为imul指定两个操作数,它会将乘得的结果截断,直到找到结果合适64
为寄存器。
imul S, D D ← D * S
如果指定一个操作数, 将会用该数乘以%rax。
然后将结果拆分到两个寄存器内,
规则是:
- 高64位放入%rdx。
- 低64位放入%rax。
除法和余数
被除数/除数=商+余数
x86-64支持128位除以64位
格式要求如下
- 被除数的高位64位存在%rdx中,
- 被除数的低位64位存在%rax中。
- 除数是指令的操作数。
- 商存储在%rax中,余数存储在%rdx中。
具体见下图
大多数的除法只支持64位,所以有了cqto指令
cqto指令符号将%rax中的64位值扩展到%rdx,以便达到除法指令的要求,用被除数填充两个寄存器。
如图
位运算指令
具体的看图吧,很好理解
使用示例
shll $3,(%rax)
shrl %cl,(%rax,%rdx,8)
sarl $4,8(%rax)
汇编实例
https://godbolt.org/z/NLYhVf
该网站能够快速查看代码对应的汇编
直接上实例
// Returns the sum of x and the first element in arr
int add_to_first(int x, int arr[]) {
int sum = x;
sum += arr[0];
return sum;
}
----------
add_to_first:
movl %edi, %eax
addl (%rsi), %eax
ret
再来一个
// Returns x/y, stores remainder in location stored in remainder_ptr
long full_divide(long x, long y, long *remainder_ptr) {
long quotient = x / y;
long remainder = x % y;
*remainder_ptr = remainder;
return quotient;
}
-------
full_divide:
movq %rdx, %rcx
movq %rdi, %rax
cqto
idivq %rsi
movq %rdx, (%rcx)
ret
还有由汇编匹配源代码的练习,更多的在课件
OK 本节结束
Lecture 12 汇编:控制流
主要讲程序如何将比较和运算结果存储在条件判断代码中,
以及如何实现判断和循环
汇编执行和%rip
我们知道程序的数据存储在内存或寄存器中,
同时,汇编指令也在内存和寄存器之间来回读写,
而且汇编指令也是存储在内存中的。
但是,谁来控制程序对应指令的执行呢??
程序如何知道下一步要干什么呢??
此时我们需要 程序计数器: %rip
前面有说过:
一些寄存器在程序执行期间承担特殊责任。
%rax存储返回值
%rdi将第一个参数存储到函数中
%rsi将第二个参数存储到函数中
%rdx将第三个参数存储到函数中
%rip存储下一条要执行的指令的地址
%rsp存储当前栈顶的地址
循环。
如何用这种%rip存储下一个指令的方式来执行循环??
调整%rip!
jmp
看一个例子
00000000004004ed <loop>:
4004ed: 55 push %rbp
4004ee: 48 89 e5 mov %rsp,%rbp
4004f1: c7 45 fc 00 00 00 00 movl $0x0,-0x4(%rbp)
4004f8: 83 45 fc 01 addl $0x1,-0x4(%rbp)
4004fc: eb fa jmp 4004f8 <loop+0xb>
这是一个死循环。
类似:
while (true) {…}
jmp是作用是无条件跳转,无须判断直接更改程序计数器(%rip)
使用方式:
jmp 标签(直接跳转)
jmp *操作数(间接跳转)
目的地可以硬编码到指令中(直接跳转):
jmp 404f8<loop+0xb>
跳转到0x404f8处的指令
目标也可以是常用的操作数形式之一(间接跳转):
jmp *%rax #跳转到地址为%rax的指令
jmp [target]
程序碰到上述指令就直接跳转
控制流
怎么进行条件跳转呢??
条件代码
怎么实现??
- 计算结果,
- 根据结果选择a方向,
指令实现包括
一条计算结果,一条条件跳转
例如
cmp S1, S2 // compare two values
je [target] or jne [target] or jl [target] or ... //
解释一下:
je : 表示相等,
jne: 表示不相等,
jl: 表示小于
更多变形请看:
cmp S1,S2
实际上是拿S2 与S1进行比较
示例代码
// Jump if %edi > 2
cmp $2, %edi
jg [target]
// Jump if %edi != 3
cmp $3, %edi
jne [target]
// Jump if %edi == 4
cmp $4, %edi
je [target]
// Jump if %edi <= 1
cmp $1, %edi
jle [target]
程序是如何知道前面比较的结果的呢???
CPU里面有一个特别的寄存器, 叫做条件码。
cmp 通过进行减法运算 然后查看结果并将结果存储在条件代码中。
OK ,什么是条件代码??
最常见的有:
CF:进位标志。最近的操作对最高有效位的产生了进位。用于检测无符号操作的溢出。
零标志:ZF。最近的零操作产生了最新的零。
SF:标志旗。最近的操作产生了一个负值。
OF:溢出标志。最近的一次操作导致了一个2的补码溢出,要么是负的,要么是正的。
设置条件代码
例如:
如果我们计算t=a+b,则条件代码的设置依据:
CF:进位标志(无符号溢出)。(无符号)t<(无符号)a
ZF:零标志(零)。(t==0)
SF:符号标志(负)。(t<0)
OF:溢出标志(有符号溢出)。(a<0==b<0)&&(t<0!=a<0)
cmp指令与减法类似,不过它不存储结果,值设置条件代码,
注意:
CMP S1, S2 S2 – S1
同时cmp也是可以使用后缀的
示例:
// Jump if %edi > 2
// calculates %edi – 2
cmp $2, %edi
jg [target]
// Jump if %edi != 3
// calculates %edi – 3
cmp $3, %edi
jne [target]
// Jump if %edi == 4
// calculates %edi – 4
cmp $4, %edi
je [target]
// Jump if %edi <= 1
// calculates %edi – 1 cmp $1, %edi
jle [target]
再看一下结合了条件代码的各种条件跳转:
还有一个设置条件代码的指令是: TEST
TEST 用于and (&) 也是不存储结果,只设置条件代码。
TEST S1, S2 S2 & S1
在回到前面的指令。
了解程序集如何将比较和运算结果存储在条件代码中
了解程序集如何实现循环和控制流
程序集执行和%rip
控制流力学
条件代码
装配说明
If语句
循环
While循环
For循环
取决于条件代码的其他指令
登记职责
一些寄存器在程序执行期间承担特殊责任。
%rax存储返回值
%rdi将第一个参数存储到函数中
%rsi将第二个参数存储到函数中
%rdx将第三个参数存储到函数中
%rip存储下一条要执行的指令的地址
%rsp存储当前栈顶的地址
更多信息,请参阅参考资料网页上的x86-64指南和参考资料表!
指令只是字节!
程序计数器(PC)在x86-64中称为%rip,它将地址存储在下一条要执行的指令的内存中。
除了普通寄存器外,CPU还具有单位条件代码寄存器。它们存储最新的算术或逻辑运算的结果。
最常见的情况代码:
CF:进位标志。最近的操作产生了对最有效位的执行。用于检测无符号操作的溢出。
零标志:ZF。最近的零操作产生了最新的零操作。
SF:标志旗。最近的操作产生了一个负值。
OF:溢出标志。最近的一次操作导致了一个2的补码溢出,要么是负的,要么是正的。
除了普通寄存器外,CPU还具有单位条件代码寄存器。它们存储最新的算术或逻辑运算的结果。
例:如果我们计算t=a+b,则条件代码的设置依据:
CF:进位标志(无符号溢出)。(无符号)t<(无符号)a
ZF:零标志(零)。(t==0)
SF:符号标志(负)。(t<0)
OF:溢出标志(有符号溢出)。(a<0==b<0)&(t<0!=a<0)
cmp指令与减法指令类似,但它不将结果存储在任何地方。它只是设置条件代码。(注意操作数顺序!)
凸轮轴位置S1,S2 S2–S1
将cmp S1、S2读作“比较S2与S1”。它计算S2–S1并用结果更新条件代码。
条件跳转可以查看条件代码的子集,以便检查它们感兴趣的条件。
测试指令类似于cmp,但用于和。它不在任何地方存储结果(&R)。它只是设置条件代码。
试验S1、S2 S2和S1
酷把戏:如果我们为两个操作数传递相同的值,我们可以使用符号标志和零标志条件代码检查该值的符号!
前面讨论的算术和逻辑指令也更新条件代码。不过lea不更新(它只用于地址计算)。
逻辑运算(xor等)将进位和溢出标志设为零。
移位操作将进位标志设置为移出的最后一位,并将溢出标志设置为零。
由于特殊原因原因,inc和dec设置了溢出和零标志,但是保持进位标志不变。
if语句
练习: 填空
00000000004004d6 <if_then>:
4004d6: cmp $0x6,%edi
4004d9: jne 4004de
4004db: add $0x1,%edi
4004de: lea (%rdi,%rdi,1),%eax
4004e1: retq
int if_then(int param1) {
if ( __________ ) {
_________;
}
return __________;
}
补充完整。
答案:
- param1 == 6
- param1++
- param1 * 2
带有else的:
Test
Jump to else-body if test fails
If-body
Jump to past else-body
Else-body
Past else body
if (arg > 3) {
ret = 10;
} else {
ret = 0;
}
ret++;
对应汇编:
400552 <+0>: cmp $0x3,%edi
400555 <+3>: jle 0x40055e <if_else+12>
400557 <+5>: mov $0xa,%eax
40055c <+10>: jmp 0x400563 <if_else+17>
40055e <+12>: mov $0x0,%eax
400563 <+17>: add $0x1,%eax
OK 这个就不多说了,就是简单的多个地方进行跳转就是了
循环
while循环
示例:
void loop() {
int i = 0;
while (i < 100) {
i++;
}
}
汇编:
0x0000000000400570 <+0>: mov $0x0,%eax
0x0000000000400575 <+5>: jmp 0x40057a <loop+10>
0x0000000000400577 <+7>: add $0x1,%eax
0x000000000040057a <+10>: cmp $0x63,%eax
0x000000000040057d <+13>: jle 0x400577 <loop+7>
0x000000000040057f <+15>: repz retq
for 循环
说明:
for (init; test; update) {
body
}
伪代码:
Init
Jump to test
Body
Update
Test
Jump to body if success
类似于while循环:
init
while(test) {
body
update
}
示例:
int sum_array(int arr[], int nelems) {
int sum = 0;
for (int i = 0; i < nelems; i++) {
sum += arr[i];
}
return sum;
}
00000000004005b6 <sum_array>:
4005b6: mov $0x0,%edx
4005bb<+5>: mov $0x0,%eax
4005c0<+10>: jmp 4005cb <sum_array+21>
4005c2<+12>: movslq %edx,%rcx
4005c5<+15>: add (%rdi,%rcx,4),%eax
4005c8<+18>: add $0x1,%edx
4005cb<+21>: cmp %esi,%edx
4005cd<+23>: jl 4005c2 <sum_array+12>
4005cf<+25>: repz retq
课程还提到了一个交gdb的工具,具体的自己去看
依靠条件代码的其他指令
有三种使用条件代码的常见指令类型:
jmp指令有条件地跳转到另一条指令
set指令有条件地将字节设置为0或1
新版本的mov指令有条件地移动数据
jmp 前面说过了,
set是有条件分设置指定字节为0或1 ,
目标为单字节寄存器,
其他字节不受影响
一般后面有movzbl 进行拓展,将多余字节归零。
例如: C代码为:
int small(int x) {
return x < 16;
}
使用set做到的汇编为:
cmp $0xf,%edi
setle %al
movzbl %al, %eax
retq
具体如图
cmov 条件代码
cmovx src,dst
cmov 有条件的将src中的数据移动到dst中,前者为内存地址或寄存器,后者是寄存器。
一般用于三目运算符: result = test ? then: else;
示例:
int max(int x, int y) {
return x > y ? x : y;
}
用cmov 的实现是:
cmp %edi,%esi
mov %edi, %eax
cmovge %esi, %eax
retq
更所用法如图:
OK 本节结束, 下节 ,汇编的函数调用
Lecture 13 函数调用和运行时的堆栈
再看%rip
%rip 是一个特殊的寄存器,存储下一条要执行的命令。
示例:
void loop() {
int i = 0;
while (i < 100) {
i++;
}
}
对应的汇编:
0x400570 <+0>: b8 00 00 00 00 mov $0x0,%eax
0x400575 <+5>: eb 03 jmp 0x40057a <loop+10>
0x400577 <+7>: 83 c0 01 add $0x1,%eax
0x40057a <+10>: 83 f8 63 cmp $0x63,%eax
0x40057d <+13>: 73 f8 jle 0x400577 <loop+7>
0x40057f <+15>: f3 c3 repz retq
其中从左往右第二列,也就是<+0> 所在列,
该列存储的是没条指令的偏移量,(从0开始的偏移量), 单位是字节,
偏移量右边的一列是机器代码。 不同的指令的字节长度是不同的。
还有一些地方要注意,以第二行为例:
0x400575 <+5>: eb 03 jmp 0x40057a <loop+10>
03 , 说的是相对于%rip要跳转的指令字节数, 当然,如果没有跳跃就是按顺序接着往下走。
0x40057d <+13>: 73 f8 jle 0x400577 <loop+7>
这里的f8也是说的要跳转的字节数, 不过其实这里是-8,因为是补码。
这里也是,如果没有跳跃, 就继续按顺序走。
还有一点
机器指令是存在于主内存中的, %rip只是存储的地址,
函数调用
需要在汇编中进行函数调用,
- 必须将%rip调整到被调用函数的指令,然后在函数中按照顺序继续执行指令。
- 还要进行参数传递, 返回值接收的问题
- 同时还需要满足被调用函数在堆栈上的空间要求
汇编怎样与堆栈进行交互呢???
堆栈
%rsp 是一个特殊的寄存器,存储当前堆栈顶部的地址,
关键在于:
%rsp在函数调用前和函数返回后,必须指向同一个位置, 因为函数调用结束后,堆栈上对应的地址空间会别释放,
push
push 将指定来源的数据推送到堆栈顶部,同时调整%rsp
pushq S
对应操作:
R[%rsp] ⟵ R[%rsp] – 8;
M[R[%rsp]] ⟵ S
对应到汇编就是
subq $8, %rsp
movq S, (%rsp)
pop
pop指令将栈顶的数据弹出,并存储到指定目的地, 并调整%rsp。
当然骂他不会对清出来的空间+进行清空,数据还是那些,只不过是可以再次使用,下次可以直接覆盖。
popq D
对应操作
D ⟵ M[R[%rsp]]
R[%rsp] ⟵ R[%rsp] + 8;
对应汇编:
movq (%rsp), D
addq $8, %rsp
传递控制
由于%rip指向下一个要执行的指令,
想要调用函数,必须要存储下一个调用方(例如:main函数)的指令后继续。
所以:
- 将下一个要执行的指令存放到堆栈上,
- 待调用结束后, 将值放回%rip继续执行。
调用和返回
call指令
call指令将跟在call指令后面的指令地址推送到堆栈上,并将%rip设置为指向指定函数指令的开头。
call Label
call *Operand
ret指令
ret指令从堆栈中取出指令并将其存储到%rip中, 这里说的是指令地址,不要和返回值混淆。
传递数据
传递和返回 。。
计算机有专门的寄存器存储参数和返回值,
要调用函数,我们必须将传递的任何参数放入正确的寄存器中。
(按顺序为%rdi、%rsi、%rdx、%rcx、%r8、%r9)
超出前6个参数的参数将被放入堆栈中
如果函数有返回值的话,就在调用结束后,访问%rax。
本地存储
正常来说,局部变量是存储在堆栈中的,
但是,我们经常看到局部变量直接存储在寄存器中,而不是像预期的那样存储在堆栈中。这是出于优化的原因。
再有:
本地数据必须在内存中有三个常见原因:
- 我们的寄存器用完了
- 在它上面使用了'&'运算符,所以我们必须为它生成一个地址
- 它们是数组或结构(需要使用地址算术)
看一个示例:
long caller() {
long arg1 = 534;
long arg2 = 1057;
long sum = swap_add(&arg1, &arg2);
...
}
caller:
subq $0x10, %rsp // 16 bytes for stack frame
movq $0x216, (%rsp) // store 534 in arg1
movq $0x421, 8(%rsp) // store 1057 in arg2
leaq 8(%rsp), %rsi // compute &arg2 as second arg
movq %rsp, %rdi // compute &arg1 as first arg
call swap_add // call swap_add(&arg1, &arg2)
寄存器限制
需要注意的是: 所有程序和函数只有一个寄存器副本。即寄存器是唯一的。
那么如果: 如果funcA在寄存器%r10中建立一个值,并在中间调用funcB,这也有修改%r10的指令,怎么办?funcA的值将被覆盖!
怎么办呢:
制定一些“规则”,调用者和被调用者在使用寄存器时必须遵守这些规则,这样他们就不会互相干扰。
这些规则定义了两种类型的寄存器:调用者拥有和被调用者拥有,这样就不会出现对同一个寄存器的重复使用。
调用者和被调用者是相对的概念,一个函数既可以是调用者,也可以是被调用者。
对于调用方拥有是寄存器
被调用方必须保存现有值并在使用完毕后还原它。
调用者可以用其存储值,并假设它在函数调用中不被修改。
对于被调用方拥有的寄存器
对于被调用方不需要保存现有值。
调用方的前面存储的值可能被被调用方覆盖!调用方可以考虑在调用函数之前将值保存在其他地方。
第一个汇编程序
看一下刚说到汇编是的第一个汇编程序
int sum_array(int arr[], int nelems) {
int sum = 0;
for (int i = 0; i < nelems; i++) {
sum += arr[i];
}
return sum;
}
00000000004005b6 <sum_array>:
4005b6: ba 00 00 00 00 mov $0x0,%edx
4005bb: b8 00 00 00 00 mov $0x0,%eax
4005c0: eb 09 jmp 4005cb <sum_array+0x15>
4005c2: 48 63 ca movslq %edx,%rcx
4005c5: 03 04 8f add (%rdi,%rcx,4),%eax
4005c8: 83 c2 01 add $0x1,%edx
4005cb: 39 f2 cmp %esi,%edx
4005cd: 7c f3 jl 4005c2 <sum_array+0xc>
4005cf: f3 c3 repz retq
优化
nop指令:
nop/nopl指令的意思是说禁止操作,
就是什么都不做
它的目的是使函数的地址边界对齐,地址边界正好是8的倍数。
mov %ebx,%ebx
在寄存器上的mov指令(寄存器作为目标)会将剩余位清零。
xor %ebx,%ebx
将前32位清零。
更多的关于优化内容见课件及课程网站的上的资料、
Lecture 14 堆管理
主要是malloc, realloc, free等内存分配操作的工作原理
目前为止的堆
当一个程序运行时:
- 创建一个进程
- 设置对应的地址空间或地址段
- 读取文件加载指令, 加载所需数据,按照需求加载对应库。
- 设置堆栈, 保留堆栈段,初始化%rsp, 调用main函数。
- 在C中调用malloc,使用时初始化自身,请求操作系统提供较大的内存空间, 用于分配给对应请求。
堆栈内存在函数调用结束后消失,有gcc在编译时自动管理。
其实堆内存第一直有的, 知道我们不再调用它时,申请和释放的操作主要由C标准库进行管理。 对应函数前面有说,
这节主要是说堆是怎样进行管理的。
什么是堆分配器
堆分配器就是一组函数,
初始化时,向堆分配器分配一块较大的连续内存块的起始地址和大小。
关于堆分配器的实际操作中的过程图见课件,太多了不上传了。
堆分配器的要求和目标
堆分配器必须满足:
- 处理分配和释放任何序列的请求
- 跟踪记录那些内存是已经分配的,那些是可用的,
- 做出决定用那块内存来满足分配请求
- 即刻做出回应,不能拖延。
所以:
- 堆分配器不能预判请求的顺序,更不能保证内个分配请求都伴随着一个匹配的空间。
- 堆分配器将内存区域标记为已分配或可用。它能记住哪个是正确地为客户机提供的内存。
- 堆分配器可以选择使用那一部分内存来满足分配请求, 当然这要考虑很多因素。
- 堆分配器必须对每条分配请求立即做出回应,不能出于任何原因延迟。
同时: 返回的地址是8字节对齐的地址,(是8的倍数)
堆分配器目标
- 最大化吞吐量: 也就是单位时间内能够满足的请求数,
- 最大化内存利用效率: 如何利用有限的堆内存满足请求
利用率
低利用率的原因主要是碎片化,当没有使用是内存无法满足内存请求时,或者由于前面的内存的申请释放导致的内存碎片化,也就是说内存碎片的聚合足够满足请求,而没有单独的一块能够满足的现象。
所以我们期望利用率尽量高,或者说,我们期望最大地址尽量低。
而且由于我们已经完成了分噢诶,所以我们不能再去动这些地址,所以我们不能对碎片进行移动拼接。
碎片化
内部碎片:
分配块大于所需块,收最小快的大小影响。
外部碎片:
没有一块足够大小的内存块来满足分配,即使有足够的聚合内存。
矛盾的堆分配器目标
再看一下堆分配器目标:
- 最大化吞吐量: 也就是单位时间内能够满足的请求数,
- 最大化内存利用效率: 如何利用有限的堆内存满足请求
这显然是两个矛盾的目标。
如果想更好的给予合适的内存块,就必然要消耗更多的时间。
所以吨分配器要协调好两个目标的关系,寻找合适的平衡点,兼顾两个要求。
除了上面说到的这些,还有一些其他的目标或要求:
- 健壮性问题。 (能够处理错误)
- 维护问题 。(是否易于维护)。
等等。。。。
方法0: 通气分配器
如果仅仅考虑吞吐量的问题,完全忽视利用率的问题,那应该怎么做呢???
通气分配器性能:
- 最高吞吐量,超快回复请求。
- 超低利用率。从不复用内存、
通气分配器在使用的过程中对于分配请求,只需要找到下一个可用内存地址,对于空请求则什么也不不做, 对于free请求也什么也不做,每个内存块只使用一次,不用释放,
具体的使用流程图见课件。
摘要
通气分配器是一种比较极端的分配方式, 只考虑吞吐量,完全忽略利用率, 不太可行,
我们要想一想:
- 我们怎么跟踪记录free掉的内存块,
- 怎么选择合适的内存块进行分配呢?
- 分配之后,如何处理剩余的内存空闲部分。
方法1: 隐式自由列表分配法
为了能够提高利用率,我们需要跟踪记录那些块是空闲的,那些是已经使用的,
所以, 我们在每一个内存块前面添加一个头,用来记录可用空间活泼已用大小等这些信息,
当我们要进行分配时,直接查看空闲块,然后进行分配并更新空闲块的头。 这样就好似我们有了一个隐藏的跟踪内存分配情况的列表
头的大小至少应该是八字节。后面会说为什么
怎么用八字节表示使用情况??
因为内存地址是八的倍数。
所以其实8字节低三位是用不到的,所以我可以利用低三位来表示是否空闲。
(例如最后一位1 使用,0 空闲)
隐式空闲列表分配器
怎么选择空闲块用于分配?
- 第一次匹配: 从头检索列表然后选择合适的的空闲块,
- 下一次匹配: 不必从头开始,从上次匹配停止出继续。
- 最佳匹配: 检索每一块,寻找适合的最小的块。
总结
这种方式:对于所有内存块都配上了头,用于记录大小和使用情况, 相当于我们用列表将内存块连接了起来,
这样一来: 提高了利用率,降低了吞吐量。 增加了分配器的设计复杂性。
边缘情况
对于边缘情况怎么处理呢??
- 将其连接到前面的内存块 ,作为内部碎片
- 单独设立空闲块,大小为0字节,作为外部碎片。
回顾几个问题
- 如何跟踪空闲块??
- 如何选择合适的内存块满足请求
- 重新分配后如何处理先前块
- 如何处理示释放请求
聚合问题
当两个空闲块挨着的时候,要不要进行聚合处理???
这是显式分配器要考虑的问题,下面会有。
优化
- 能不能不搜索所有快就获得自由块
- 可否合并相邻自由块以获得较大的自由块。
- 可否在重新分配避免每次都移动数据。
显式自由列表分配器
显式分配器
修改每个头,添加一个指向上一个空闲内存块的指针,和一个指向下一个内存块的指针,
不过。这样是低效的,我们只需要在自由快之间跳转,
由于空闲块的空间是自由的,我们就在空闲块的的有效空间的前16字节存储上述指针。
所以这就要求每个内存块必须足够大。
这是建立在隐式基础上的。
提高了吞吐量, 同时也带来了一些设计上的开销。 以及一些内部碎片。
- 当我们分配一个内存块时, 用链表找到合适的内存块, 然后更新头和链表反映分配大小个表明已被分配。
- 当释放一个块时,就更新链表。
所以: 显式分配器的机制就是:
. 包含大小和分配状态的8字节头
. 自由块的有效空间的前16字节存放指针。指向上一个自由块和下一个自由块。
. 当然这也表明其实显式的链表是可以进行排序的。 也就是可以对自由块排序。
聚合
我们有足够的内存空间满足分配请求,不过我们的空间呗分割成了若干块。
怎么办???
聚合
所以聚合就是合并相邻自由块
怎么操作???
在释放某块时,合并其右侧相邻的自由块即可。
就地重新分配
情况:
- 大小增大,当前块的后面有填充,且空间足够,直接用。 (解释一下没什么是填充,就是位于当前块的后面0多出来的且未使用的没有被独立出来作为单独内存块的空间)
- 大小减小,直接操作即可。
- 大小增大, 当前块不够大,但是相邻块是空闲的,且合并后足够大,合并,然后分配
其余的情况就不属于就地分配的情况了,就要转移数据了。
还有就是上面的情况可以重复
例如: 现有空间不够,加上填充也不够,不过就加上相邻自由块就够了。
还有一种更高级的是: 带有大小桶的显示列表。 只是简单了解即可
本节的好多内容课件上都有具体的流程实例,值得一看。
OK 本节结束
Lecture 15 优化
了解如何优化代码提高运行效率和速度,
了解GCC可执行的优化
什么是优化
优化是使程序在时间个空间上更快更高效的完成任务。
优化是非常必要的。
一般优化工作概括为:
- 如果很少做某些事情,而且只在少量输入上做,那么就用最容易进行编码,理解,调试的方式,
- 如果做的事比较多,或者是消耗资源很多,就要使 Big-O(复杂的) 合理
- GCC优化
- 显式优化
GCC优化
gcc编译器有两个优化级别:
- gcc–O0//大部分只是C的直译
- gcc–O2//启用几乎所有合理的优化
还有其他自定义和更具激进性的优化级别 - -O3//比O2更具攻击性,以大小换速度
- -Os//优化大小
- -Ofast//无视标准遵从性(!!)
更多见链接gcc优化
示例: 矩阵乘法
源代码:
void mmm(double a[][DIM], double b[][DIM], double c[][DIM], int n) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
for (int k = 0; k < n; k++) {
c[i][j] += a[i][k] * b[k][j];
}
}
}
}
-O0的编译方式
./mult // -O0 (no optimization)
matrix multiply 25^2: cycles 0.43M
matrix multiply 50^2: cycles 3.02M
matrix multiply 100^2: cycles 24.82M
-O2的优化方式:
./mult_opt // -O2 (with optimization)
matrix multiply 25^2: cycles 0.13M (opt)
matrix multiply 50^2: cycles 0.66M (opt)
matrix multiply 100^2: cycles 5.55M (opt)
常量折叠
如果可能,常量折叠在编译时预先计算常量
例如:
int seconds = 60 * 60 * 24 * n_days;
再看一个示例:
源代码是:
int fold(int param) {
char arr[5];
int a = 0x107;
int b = a * sizeof(arr);
int c = sqrt(2.0);
return a * param + (a + 0x15 / c + strlen("Hello") * b - 0x37) / 4;
}
-O0的结果是:
0000000000400626 <fold>:
400626: 55 push %rbp
400627: 53 push %rbx
400628: 48 83 ec 08 sub $0x8,%rsp
40062c: 89 fd mov %edi,%ebp
40062e: f2 0f 10 05 da 00 00 movsd 0xda(%rip),%xmm0
400635: 00
400636: e8 d5 fe ff ff callq 400510 <sqrt@plt>
40063b: f2 0f 2c c8 cvttsd2si %xmm0,%ecx
40063f: 69 ed 07 01 00 00 imul $0x107,%ebp,%ebp
400645: b8 15 00 00 00 mov $0x15,%eax
40064a: 99 cltd
40064b: f7 f9 idiv %ecx
40064d: 8d 98 07 01 00 00 lea 0x107(%rax),%ebx
400653: bf 04 07 40 00 mov $0x400704,%edi
400658: e8 93 fe ff ff callq 4004f0 <strlen@plt>
40065d: 48 69 c0 23 05 00 00 imul $0x523,%rax,%rax
400664: 48 63 db movslq %ebx,%rbx
400667: 48 8d 44 18 c9 lea -0x37(%rax,%rbx,1),%rax
40066c: 48 c1 e8 02 shr $0x2,%rax
400670: 01 e8 add %ebp,%eax
400672: 48 83 c4 08 add $0x8,%rsp
400676: 5b pop %rbx
400677: 5d pop %rbp
400678: c3 retq
而 -O2的结果是:
00000000004004f0 <fold>:
4004f0: 69 c7 07 01 00 00 imul $0x107,%edi,%eax
4004f6: 05 a5 06 00 00 add $0x6a5,%eax
4004fb: c3 retq
4004fc: 0f 1f 40 00 nopl 0x0(%rax)
公共子表达式消除
公共子表达式消除通过一次执行并保存结果防止对同一表达式的重复计算.
例如
int a = (param2 + 0x107);
int b = param1 * (param2 + 0x107) + a;
return a * (param2 + 0x107) + b * (param2 + 0x107);
这种优化在-O0d情况下也有。
上述代码编译后是
00000000004004f0 <subexp>:
4004f0: 81 c6 07 01 00 00 add $0x107,%esi
4004f6: 0f af fe imul %esi,%edi
4004f9: 8d 04 77 lea (%rdi,%rsi,2),%eax
4004fc: 0f af c6 imul %esi,%eax
4004ff: c3 retq
死代码消除
死代码消除将删除不起作用的代码
示例:
源代码:
if (param1 < param2 && param1 > param2) {
printf("This test can never be true!\n");
}
// Empty for loop
for (int i = 0; i < 1000; i++);
// If/else that does the same operation in both cases
if (param1 == param2) {
param1++;
} else {
param1++;
}
// If/else that more trickily does the same operation in both cases
if (param1 == 0) {
return 0;
} else {
return param1;
}
-O0的结果的
00000000004004d6 <dead_code>:
4004d6: b8 00 00 00 00 mov $0x0,%eax
4004db: eb 03 jmp 4004e0 <dead_code+0xa>
4004dd: 83 c0 01 add $0x1,%eax
4004e0: 3d e7 03 00 00 cmp $0x3e7,%eax
4004e5: 7e f6 jle 4004dd <dead_code+0x7>
4004e7: 39 f7 cmp %esi,%edi
4004e9: 75 05 jne 4004f0 <dead_code+0x1a>
4004eb: 8d 47 01 lea 0x1(%rdi),%eax
4004ee: eb 03 jmp 4004f3 <dead_code+0x1d>
4004f0: 8d 47 01 lea 0x1(%rdi),%eax
4004f3: f3 c3 repz retq
-O2的结果是:
00000000004004f0 <dead_code>:
4004f0: 8d 47 01 lea 0x1(%rdi),%eax
4004f3: c3 retq
4004f4: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
4004fb: 00 00 00
4004fe: 66 90 xchg %ax,%ax
强度折减
强度折减将“除法”更改为“乘”,将“乘”更改为“加/移”,并将“取模”改为“与” 以避免使用耗费许多周期的指令(乘和除)。
代码运动
如果可以的话代码运动会将代码移出循环
for (int i = 0; i < n; i++) {
sum += arr[i] + foo * (bar + 3);
}
公共子表达式消除处理多次出现的代码, 不过在这里,虽然没有多次出现,不过每次循环都要计算。
尾部递归
尾部递归是GCC识别递归模式的一个例子,这种模式可以更有效地迭代实现。
代码示例是:
long factorial(int n) {
if (n <= 1) {
return 1;
}
else return n * factorial(n - 1);
}
循环展开
循环展开:
每次实际的循环迭代都要做n个循环迭代的工作,这样我们就不用每次都做循环开销(测试和跳转),而只会在第n次循环迭代中产生开销。
代码示例:
for (int i = 0; i <= n - 4; i += 4) {
sum += arr[i];
sum += arr[i + 1];
sum += arr[i + 2];
sum += arr[i + 3];
} // after the loop handle any leftovers
GCC优化的局限性
GCC不能优化所有的东西, 人会比GCC懂的更多
代码:
int char_sum(char *s) {
int sum = 0;
for (size_t i = 0; i < strlen(s); i++) {
sum += s[i];
}
return sum;
}
其中的有哪些地方是可优化的??
strlen 每次循环都会调用 !!
怎么办?? 代码运动会将其拉出循环。
代码2:
void lower1(char *s) {
for (size_t i = 0; i < strlen(s); i++) {
if (s[i] >= 'A' && s[i] <= 'Z') {
s[i] -= ('A' - 'a');
}
}
}
问题也是在strlen。
不过s是变化的, GCC不确定是不是一个常数, 不过我们自己知道长度是不会变化的。
缓存
处理器性能不是限制程序性能的唯一标准, 内存访问更是一个限制。
内存是以级别的形式出现的, 以读取熟读为标准,从非常快(寄存器)到非常慢
(硬盘) 。
其实, 随着数据的使用越来越频繁,它在内存中存在的位置的读取速度也越来越快。
缓存取决于位置
时间位置: 对于同一数据的重复访问往往集中在同一时间段。
空间位置: 相关的数据趋向于在空间内临近。 (就是说刚访问过的数据旁边的数据接下来更可能呗访问)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号