
封装/继承
封装
一 引入
面向对象编程有三大特性:封装、继承、多态,其中最重要的一个特性就是封装。封装指的是把数据与功能都整合到一起。除此之外,针对封装到对象或者类中的属性,我们还可以严格控制对它们的访问,分两步实现:隐藏与开放接口。
二 隐藏属性
Python的Class机制采用双下划线开头的方式将属性隐藏起来,但其实这仅仅只是一种变形操作,类中所有下划线开头的属性都会在定义阶段,检测语法时自动变成"_类名__属性名" 的形式:
class Foo:
__N = 0 #变形为 _Foo__N
def __init__(self): # 定义函数时,会检测函数语法,所以__开头的属性会变形
self.__x=10 # 变形为self._Foo__x
def __f1(self): # 变形为_Foo__f1
print('__f1 run')
def f2(self): # 定义函数时,会检测函数语法,所以__开头的属性也会变形
self.__f1() # 变形为self.__Foo__f1()
print(Foo.__N) # 报错AttributeError:类Foo没有属性__N
obj = Foo()
print(obj.__x) # 报错AttributeError:对象obj没有属性__x
这种变形需要注意的问题时:
1、在类外部无法直接访问双下划线开头的属性,但知道了类名和属性名就可以拼出名字:_类名__属性,然后就可以访问了,如 Foo . _ A _ _ N,所以说这种操作并没有严格意义上地限制外部访问,仅仅只是一种语法意义上的变形。
Foo.__dict__
obj.__dict__ #? 这里为什么调用对象返回的是10??????
>>>{'_Foo__x': 10}
Foo._Foo__N
>>> 0
obj._Foo__x
>>> 10
obj._Foo__N
>>>0
2、在类内部是可以直接访问双下滑线开头的属性的,比如self.__f1(),因为在类定义阶段类内部双下滑线开头的属性统一发生了变形。
obj.f2()
>>> __f1 run
3、变形操作只在类定义阶段发生一次,在类定义之后的赋值操作,不会变形。
Foo.__M=100
Foo.__dict__
Foo.__M
>>> 100
obj.__y=20
obj.__dict__
>>> {'__y': 20, '_Foo__x': 10}
obj.__y
>>> 20
总结__开头属性的特点:
1、并没有针对属性藏起来,只是变形
2、该变形值在类定义阶段、扫描语法的时候执行,此后__开头的属性都不会变形
三 开放接口
为何要隐藏属性
1、隐藏数据属性为了严格控制类外部访问者对属性的操作
2、隐藏函数属性为了隔离复杂度
定义属性就是为了使用,所以隐藏并不是目的
3.1隐藏数据属性
将数据隐藏起来就限制了类外部对数据的直接操作,然后类内应该提供相应的接口来允许类外部间接地操作数据,接口之上可以附加额外的逻辑来对数据的操作进行严格的控制
class People:
def __init__(self, name, age): # 将名字和年纪都隐藏起来
self.__name = name
self.__age = age
def tell_info(self): # 对外提供访问信息的接口
print('<%s:%s>' % (self.__name, self.__age))
def set_info(self, name, age):
if type(name) is not str:
print('名字必须是字符串')
return
if type(age) is not int:
print('年龄必须是数字')
return
self.__name = name
self.__age = age
obj1 = People('william',18)
obj1.tell_info()
obj1.set_info("矮跟",19) # 调用类里面的功能来修改信息 满足
#接口上附加的逻辑 则完成修改信息
obj1.tell_info()
obj1.set_info(1111,'222') #隐藏数据属性为了严格控制类外部访问者对属性的操作
# 如果不隐藏 那么外部访问者直接赋值之类的 在类内部赋值就会改变数据
obj1.tell_info()
3.2隐藏函数属性
目的是为了隔离复杂度,例如ATM程序的取款功能,该功能有很多其他功能组成,比如插卡、身份认证、输入金额、打印小票、取钱等,而对使用者来说,只需要开发取款这个功能接口即可,其余功能我们都可以隐藏起来
class ATM:
def __card(self): # 插卡
print('插卡')
def __auth(self): # 身份认证
print('用户认证')
def __input(self): # 输入金额
print('输入取款金额')
def __print_bill(self): # 打印小票
print('打印账单')
def __take_money(self): # 取钱
print('取款')
def withdraw(self): # 取款功能
self.__card()
self.__auth()
self.__input()
self.__print_bill()
self.__take_money()
obj = ATM()
obj.withdraw()
>>>
插卡
用户认证
输入取款金额
打印账单
取款
总结隐藏属性与开放接口,本质就是为了明确地区分内外,类内部可以修改封装内的东西而不影响外部调用者的代码;而类外部只需要拿到一个接口,只要接口名、参数不变,则无论设计者如何改变内部实现代码,使用者均无需改变代码。这就提供了一个良好的合作基础,只要接口这个基础约定不变,则代码的修改不足为虑。
四 property
# 成人的BMI数值:
# 过轻:低于18.5
# 正常:18.5-23.9
# 过重:24-27
# 肥胖:28-32
# 非常肥胖, 高于32
# 体质指数(BMI)=体重(kg)÷身高^2(m)
# EX:70kg÷(1.75×1.75)=22.86
身高或者体重是不断变化的,因而每次想查看BMI值都需要通过计算机才能得到,但明显BMI听起来更像一个特征而非功能,为此python专门提供了一个装饰器property,可以将类中的函数‘伪装成’ 对象的数据属性,对象在访问该特殊属性时会触发功能的执行,然后将返回值作为本次访问的结果,例如
class People:
def __init__(self,name,weight,height):
self.name = name
self.weight = weight
self.height = height
@property
def bmi(self):
return self.weight/(self.height ** 2)
p1 = People('william',73,1.8)
print(p1.bmi)
使用Property有效保证了属性访问的一致性。另外Property还提供设置和删除属性的功能,如下
class People:
def __init__(self,name):
self.__name = name
@property
def name(self):
return self.__name
@name.setter
def name(self,x):
if type(x) is not str:
raise Exception('名字必须是字符串类型')
self.__name = x
@name.deleter
def name(self):
print('不允许删除')
p1 = People('egon')
print(p1.name)
p1.name = 'williams'
print(p1.name)
del p1.name
egon
williams
不允许删除
通过同一个对象的属性实现多个功能
优化整合后效果如下
class People:
def __init__(self,name):
self.__name = name
def name(self):
return self.__name
def set_name(self,x):
if type(x) is not str:
raise Exception('名字必须是字符串类型')
self.__name = x
def del_name(self):
print('不允许删除')
name = property(name,set_name,del_name) #将多行装饰器改为了一行来完成
p1 = People('egon')
print(p1.name)
p1.name = 'williams'
del p1.name
print(p1.name)
egon
不允许删除
williams
绑定方法与非绑定方法
绑定方法的
特点:绑定给谁就应该由谁来调用,谁来调用就会将自己作为第一个参数传入
非绑定方法
特点:不与类和对象绑定,意味着谁都可以调用,但无论谁来调用就是一个普通函数,没有自动传参的效果
class People:
def __init__(self,name):
self.name = name
# 但凡在类中顶一个函数,默认就是绑定给对象的,应该由对象来调用
# 会将对象当作第一个参数自动传入
def tell(self):
print(self.name)
# 类中定义的函数被classmethod装饰过,就绑定给类,应该由类来调用,
# 类来调用会将类本身当作第一个参数自动传入
@classmethod
def f1(cls):
print(cls)
# 类中定义的函数被staticmethod 装饰过,就成一个非绑定的方法即一个普通函数,谁可以调用
# 但无论谁来调用就是一个普通函数,没有自动传参的效果
@staticmethod
def f2():
pass
# p1 = People('egon')
# p1.tell()
People.f1()
class People:
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
def tell(self):
# 绑定给对象的函数 类可以调 但是是当做普通函数调用
# @classmethod绑定给类的函数 函数也可以调用 但是自动传入的参数是类
继承
一 集成的介绍
继承是创建新类的一种方式
新建的类称为子类
被继承的类称为父类、基类、超类
继承的特点是:子类可以遗传父类的属性
继承是来解决类与类之间冗余问题的
类是解决对象之间冗余问题的
class Parent1: # 定义父类
pass
class Parent2: # 定义父类
pass
class Sub1(Parent1): # 单继承
pass
class Sub2(Parent1,Parent2): # 多继承
pass
通过类的内置属性 __ bases __可以查看类继承的所有父类
print(Sub1.__bases__)
print(Sub2.__bases__)
(<class '__main__.Parent1'>,)
(<class '__main__.Parent1'>, <class '__main__.Parent2'>)
注意:
在python2中有新式类与经典类之分,在python3中全都是新式类
但凡是继承了object类的子类以及该子类的子子孙孙类都是新式类
反之就是经典类
>>> ParentClass1.__bases__
(<class ‘object'>,)
>>> ParentClass2.__bases__
(<class 'object'>,)
因而在Python3中统一都是新式类,关于经典类与新式类的区别,我们稍后讨论
提示:object类提供了一些常用内置方法的实现,如用来在打印对象时返回字符串的内置方法__str_
二 继承与抽象
要找出类与类之间的继承关系,需要先抽象,再继承。抽象即总结相似之处,总结对象之间的相似之处得到类,总结类与类之间的相似之处就可以得到父类,如图所示
基于上图我们可以看出类与类之间的继承指的是什么’是’什么的关系(比如人类,猪类,猴类都是动物类)。子类可以继承/遗传父类所有的属性,因而继承可以用来解决类与类之间的代码重用性问题。比如我们按照定义Student类的方式再定义一个Teacher类
class Teacher:
school='清华大学'
def __init__(self,name,sex,age):
self.name=name
self.sex=sex
self.age=age
def teach(self):
print('%s is teaching' %self.name)
类Teacher与Student之间存在重复的代码,老师与学生都是人类,所以我们可以得出如下继承关系,实现代码重用
class People:
school='清华大学'
def __init__(self,name,sex,age):
self.name=name
self.sex=sex
self.age=age
class Student(People):
def choose(self):
print('%s is choosing a course' %self.name)
class Teacher(People):
def teach(self):
print('%s is teaching' %self.name)
Teacher类内并没有定义__init__方法,但是会从父类中找到__init__,因而仍然可以正常实例化,如下
>>> teacher1=Teacher('lili','male',18)
>>> teacher1.school,teacher1.name,teacher1.sex,teacher1.age
('清华大学', 'lili', 'male', 18)
三 属性查找
#示例1
class Bar:
def f1(self):
print('Bar.f1')
def f2(self):
print('Bar.f2')
self.f1() # self.f1() ←← 注意变形前后状态 变形在下面示例二↓
# 属性查找先从对象 再当前类 然后再父类
# 这一步相当于是 obj.f1() 要开始查找 但并不是就近查找是从头查找
class Foo(Bar):
def f1(self):
print('Foo.f1')
obj = Foo()
obj.f2()
#obj.f1()
逻辑解析1
#示例2
class Bar:
def __f1(self): # 变形 _Bar__f1
print('Bar.f1')
def f2(self):
print('Bar.f2')
self.__f1() # self._Bar__f1() 这次变形 不单单是视觉上的__f1()而是变成了 _Bar__f1()这就是为什么明明应该从开始查 看起来开始的类Foo明明有__f1却走到了父类里面查
千万不要误解成和示例一查找逻辑改变 这次变成了就近查找其实不是的 还是按照一开始的逻辑查找
没查找到的原因是因为变形不单单是视觉上变形的那么简单
class Foo(Bar):
def __f1(self): # 变形 _Foo__f1
print('Foo.f1')
obj = Foo()
obj.f2()
obj.__f1()
# 会报错 属性被隐藏后外部访问不到 能查找到形式只能是obj._Foo__f1 或者 obj._Bar__f1
obj._Bar__f1()
print(obj._Bar__f1) #bound method 绑定的函数内存地址加括号就会运行
逻辑解析2
四 继承的实现原理
4.1 菱形问题
菱形继承 /死亡钻石:一个子类继承的多条分支最终汇聚一个非object的类上
大多数面向对象语言都不支持多继承,而在Python中,一个子类是可以同时继承多个父类的,这固然可以带来一个子类可以对多个不同父类加以重用的好处,但也有可能引发著名的 Diamond problem菱形问题(或称钻石问题,有时候也被称为“死亡钻石”),菱形其实就是对下面这种继承结构的形象比喻
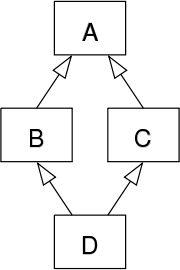
A类在顶部,B类和C类分别位于其下方,D类在底部将两者连接在一起形成菱形。
这种继承结构下导致的问题称之为菱形问题:如果A中有一个方法,B和/或C都重写了该方法,而D没有重写它,那么D继承的是哪个版本的方法:B的还是C的?如下所示
class A(object):
def test(self):
print('from A')
class B(A):
def test(self):
print('from B')
class C(A):
def test(self):
print('from C')
class D(B,C):
pass
obj = D()
obj.test() # 结果为:from B
要想搞明白obj.test()是如何找到方法test的,需要了解python的继承实现原理
4.2 继承原理
python到底是如何实现继承的呢? 对于你定义的每一个类,Python都会计算出一个方法解析顺序(MRO)列表,该MRO列表就是一个简单的所有基类的线性顺序列表,如下
>>> D.mro() # 新式类内置了mro方法可以查看线性列表的内容,经典类没有该内置该方法
[<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
python会在MRO列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止。 而这个MRO列表的构造是通过一个C3线性化算法来实现的。我们不去深究这个算法的数学原理,它实际上就是合并所有父类的MRO列表并遵循如下三条准则:
1.子类会先于父类被检查
2.多个父类会根据它们在列表中的顺序被检查
3.如果对下一个类存在两个合法的选择,选择第一个父类
所以obj.test()的查找顺序是,先从对象obj本身的属性里找方法test,没有找到,则参照属性查找的发起者(即obj)所处类D的MRO列表来依次检索,首先在类D中未找到,然后再B中找到方法test
ps:
1.由对象发起的属性查找,会从对象自身的属性里检索,没有则会按照对象的类.mro()规定的顺序依次找下去,
2.由类发起的属性查找,会按照当前类.mro()规定的顺序依次找下去,
4.3 深度优先和广度优先
参照下述代码,多继承结构为非菱形结构,此时,会按照先找B这一条分支,然后再找C这一条分支,最后找D这一条分支的顺序直到找到我们想要的属性
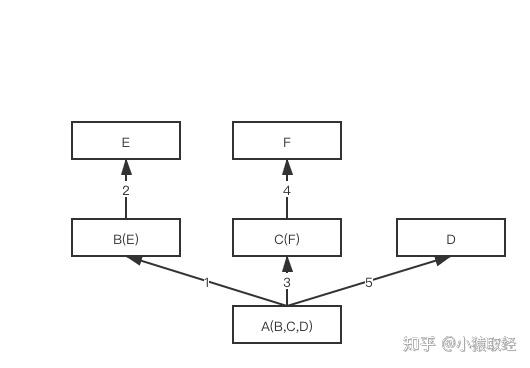
class E:
def test(self):
print('from E')
class F:
def test(self):
print('from F')
class B(E):
def test(self):
print('from B')
class C(F):
def test(self):
print('from C')
class D:
def test(self):
print('from D')
class A(B, C, D):
# def test(self):
# print('from A')
pass
print(A.mro())
'''
[<class '__main__.A'>, <class '__main__.B'>, <class '__main__.E'>, <class '__main__.C'>, <class '__main__.F'>, <class '__main__.D'>, <class 'object'>]
'''
obj = A()
obj.test() # 结果为:from B
# 可依次注释上述类中的方法test来进行验证
如果继承关系为菱形结构,那么经典类与新式类会有不同MRO,分别对应属性的两种查找方式:深度优先和广度优先
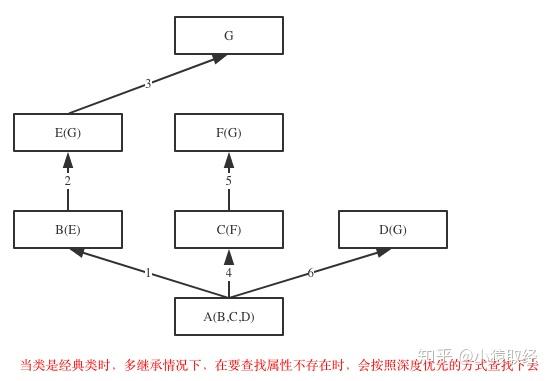
class G: # 在python2中,未继承object的类及其子类,都是经典类
def test(self):
print('from G')
class E(G):
def test(self):
print('from E')
class F(G):
def test(self):
print('from F')
class B(E):
def test(self):
print('from B')
class C(F):
def test(self):
print('from C')
class D(G):
def test(self):
print('from D')
class A(B,C,D):
# def test(self):
# print('from A')
pass
obj = A()
obj.test() # 如上图,查找顺序为:obj->A->B->E->G->C->F->D->object
# 可依次注释上述类中的方法test来进行验证,注意请在python2.x中进行测试
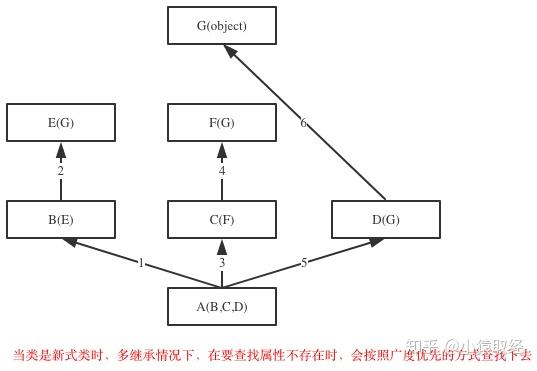
class G(object):
def test(self):
print('from G')
class E(G):
def test(self):
print('from E')
class F(G):
def test(self):
print('from F')
class B(E):
def test(self):
print('from B')
class C(F):
def test(self):
print('from C')
class D(G):
def test(self):
print('from D')
class A(B,C,D):
# def test(self):
# print('from A')
pass
obj = A()
obj.test() # 如上图,查找顺序为:obj->A->B->E->C->F->D->G->object
# 可依次注释上述类中的方法test来进行验证
4.4 python Mixins机制
一个子类可以同时继承多个父类,这样的设计常被人诟病,一来它有可能导致可恶的菱形问题,二来在人的世界观里继承应该是个”is-a”关系。 比如轿车类之所以可以继承交通工具类,是因为基于人的世界观,我们可以说:轿车是一个(“is-a”)交通工具,而在人的世界观里,一个物品不可能是多种不同的东西,因此多重继承在人的世界观里是说不通的,它仅仅只是代码层面的逻辑。不过有没有这种情况,一个类的确是需要继承多个类呢?
答案是有,我们还是拿交通工具来举例子:
民航飞机、直升飞机、轿车都是一个(is-a)交通工具,前两者都有一个功能是飞行fly,但是轿车没有,所以如下所示我们把飞行功能放到交通工具这个父类中是不合理的
class Vehicle: # 交通工具
def fly(self):
'''
飞行功能相应的代码
'''
print("I am flying")
class CivilAircraft(Vehicle): # 民航飞机
pass
class Helicopter(Vehicle): # 直升飞机
pass
class Car(Vehicle): # 汽车并不会飞,但按照上述继承关系,汽车也能飞了
pass
但是如果民航飞机和直升机都各自写自己的飞行fly方法,又违背了代码尽可能重用的原则(如果以后飞行工具越来越多,那会重复代码将会越来越多)。
怎么办???为了尽可能地重用代码,那就只好在定义出一个飞行器的类,然后让民航飞机和直升飞机同时继承交通工具以及飞行器两个父类,这样就出现了多重继承。这时又违背了继承必须是”is-a”关系。这个难题该怎么解决?
不同的语言给出了不同的方法,让我们先来了解Java的处理方法。Java提供了接口interface功能,来实现多重继承:
// 抽象基类:交通工具类
public abstract class Vehicle {
}
// 接口:飞行器
public interface Flyable {
public void fly();
}
// 类:实现了飞行器接口的类,在该类中实现具体的fly方法,这样下面民航飞机与直升飞机在实现fly时直接重用即可
public class FlyableImpl implements Flyable {
public void fly() {
System.out.println("I am flying");
}
}
// 民航飞机,继承自交通工具类,并实现了飞行器接口
public class CivilAircraft extends Vehicle implements Flyable {
private Flyable flyable;
public CivilAircraft() {
flyable = new FlyableImpl();
}
public void fly() {
flyable.fly();
}
}
// 直升飞机,继承自交通工具类,并实现了飞行器接口
public class Helicopter extends Vehicle implements Flyable {
private Flyable flyable;
public Helicopter() {
flyable = new FlyableImpl();
}
public void fly() {
flyable.fly();
}
}
// 汽车,继承自交通工具类,
public class Car extends Vehicle {
}
现在我们的飞机同时具有了交通工具及飞行器两种属性,而且我们不需要重写飞行器中的飞行方法,同时我们没有破坏单一继承的原则。飞机就是一种交通工具,可飞行的能力是飞机的属性,通过继承接口来获取。
回到主题,Python语言可没有接口功能,但Python提供了Mixins机制,简单来说Mixins机制指的是子类混合(mixin)不同类的功能,而这些类采用统一的命名规范(例如Mixin后缀),以此标识这些类只是用来混合功能的,并不是用来标识子类的从属"is-a"关系的,所以Mixins机制本质仍是多继承,但同样遵守”is-a”关系,如下
class Vehicle: # 交通工具
pass
class FlyableMixin:
def fly(self):
'''
飞行功能相应的代码
'''
print("I am flying")
class CivilAircraft(FlyableMixin, Vehicle): # 民航飞机
pass
class Helicopter(FlyableMixin, Vehicle): # 直升飞机
pass
class Car(Vehicle): # 汽车
pass
# ps: 采用某种规范(如命名规范)来解决具体的问题是python惯用的套路
可以看到,上面的CivilAircraft、Helicopter类实现了多继承,不过它继承的第一个类我们起名为FlyableMixin,而不是Flyable,这个并不影响功能,但是会告诉后来读代码的人,这个类是一个Mixin类,表示混入(mix-in),这种命名方式就是用来明确地告诉别人(python语言惯用的手法),这个类是作为功能添加到子类中,而不是作为父类,它的作用同Java中的接口。所以从含义上理解,CivilAircraft、Helicopter类都只是一个Vehicle,而不是一个飞行器。
使用Mixin类实现多重继承要非常小心
- 首先它必须表示某一种功能,而不是某个物品,python 对于mixin类的命名方式一般以 Mixin, able, ible 为后缀
- 其次它必须责任单一,如果有多个功能,那就写多个Mixin类,一个类可以继承多个Mixin,为了保证遵循继承的“is-a”原则,只能继承一个标识其归属含义的父类
- 然后,它不依赖于子类的实现
- 最后,子类即便没有继承这个Mixin类,也照样可以工作,就是缺少了某个功能。(比如飞机照样可以载客,就是不能飞了)
Mixins是从多个类中重用代码的好方法,但是需要付出相应的代价,我们定义的Minx类越多,子类的代码可读性就会越差,并且更恶心的是,在继承的层级变多时,代码阅读者在定位某一个方法到底在何处调用时会晕头转向,如下
class Displayer:
def display(self, message):
print(message)
class LoggerMixin:
def log(self, message, filename='logfile.txt'):
with open(filename, 'a') as fh:
fh.write(message)
def display(self, message):
super().display(message) # super的用法请参考下一小节
self.log(message)
class MySubClass(LoggerMixin, Displayer):
def log(self, message):
super().log(message, filename='subclasslog.txt')
obj = MySubClass()
obj.display("This string will be shown and logged in subclasslog.txt")
# 属性查找的发起者是obj,所以会参照类MySubClass的MRO来检索属性
#[<class '__main__.MySubClass'>, <class '__main__.LoggerMixin'>, <class '__main__.Displayer'>, <class 'object'>]
# 1、首先会去对象obj的类MySubClass找方法display,没有则去类LoggerMixin中找,找到开始执行代码
# 2、执行LoggerMixin的第一行代码:执行super().display(message),参照MySubClass.mro(),super会去下一个类即类Displayer中找,找到display,开始执行代码,打印消息"This string will be shown and logged in subclasslog.txt"
# 3、执行LoggerMixin的第二行代码:self.log(message),self是对象obj,即obj.log(message),属性查找的发起者为obj,所以会按照其类MySubClass.mro(),即MySubClass->LoggerMixin->Displayer->object的顺序查找,在MySubClass中找到方法log,开始执行super().log(message, filename='subclasslog.txt'),super会按照MySubClass.mro()查找下一个类,在类LoggerMixin中找到log方法开始执行,最终将日志写入文件subclasslog.txt
五 派生与方法重用
class Feather:
school = '虹桥校区'
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
def chak(self):
print(self.school,self.__dict__)
class Student(Feather):
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
def choice(self):
print('%s 选课成功' %self.name)
stu1 = Student('william',19,'male')
stu1.chak()
class Teacher(Feather): # 老师的信息有和学生共同的 但是也有不同的
def __init__(self,name,age,gender,level):
self.name = name
self.age = age
self.gender = gender
self.level =level
def score(self):
print('%s正在打分' %self.name)
tea1 = Teacher('egon',19,'male',10)
tea1.chak()
在子类派生的新方法中如何重用父类的功能--------方式1
方式一:指名道姓地运行某一个类的函数 与继承无关
class Feather:
school = '虹桥校区'
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
def chak(self):
print(self.school,self.__dict__)
class Student(Feather):
def choice(self):
print('%s 选课成功' %self.name)
stu1 = Student('william',19,'male')
stu1.chak()
class Teacher(Feather):
def __init__(self,name,age,gender,level): #将共同的从父类中引用过来
Feather.__init__(self,name,age,gender)
self.level = level
def score(self):
print('%s正在打分' %self.name)
tea1 = Teacher('egon',19,'male',10)
tea1.chak()
方式二:super()
super返回一个特殊的对象,该对象会参考发起属性查找的那一个类的Mro列表,去当前类的父类找属性,严格依赖继承。其中这里的广度优先和深度优先会体现在mro列表
class Feather:
school = '虹桥校区'
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
def chak(self):
print(self.school,self.__dict__)
class Teacher(Feather):
def __init__(self,name,age,gender,level):
# Feather.__init__(self,name,age,gender)
super(Teacher, self).__init__(name,age,gender)
self.level = level
def score(self):
print('%s正在打分' %self.name)
tea1 = Teacher('egon',19,'male',10)
tea1.chak()
# super() 返回一个特殊的对象,该对象会参考发起属性查找的那一个类的Mro里诶表,去当前类的
# 类查找属性,严格依赖继承
class A : # [A,object]
def test1(self):
print('from A')
super().test() # 发起者这一步父类按mro顺序是到B了
class B: # [B,object]
def test(self):
print('from B')
class C(A,B): #[C,A,B,object]
pass
obj = C()
obj.test()
print(A.__mro__)
这两种方式的区别是:方式一跟继承没有关系,而方式二的super()是依赖于继承的,并且即使没有直接继承关系,super()仍然会按照mro继续往后查找
六 组合
在一个类中以另外一个类的对象作为数据属性,称为类的组合。组合与继承都是用来解决代码重用性问题。不同的是:继承是一种'是'的关系,比如老师是人、学生是人,当类之间有很多相同的之处,应该使用继承;而组合则是一种'有'的关系,比如老师有生日,学生有课程,当类之间有显著不同,并且较小的类是较大的类所需要的组件时,应该使用组合,如下示例
# 组合: 一个对象的属性值是指向另外一个类的对象
class People:
school = '虹桥校区'
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
class Student(People):
def choice(self):
print('%s选课成功'%self.name)
class Teacher(People):
def __init__(self,name,age,gender,level):
super(Teacher, self).__init__(name,age,gender)
self.level = level
def score(self):
print('%s正在为学生打分' %self.name)
class Course:
def __init__(self,name,price,period):
self.name = name
self.price = price
self.period = period
def tell(self):
print('课程信息<%s:%s:%s>'%(self.name,self.price,self.period))
python = Course('python全栈开发',19800,'6mons')
linux = Course('linux',19000,'5mons')
tea1 = Teacher('egon',18,'male',10)
stu1 = Student('william',19,'male')
# stu1.course =[]
# stu1.course.append(python,linux)
stu1.course=python
#
# for course_obj in stu1.course:
# course_obj.tell()
class Course:
def __init__(self,name,period,price):
self.name=name
self.period=period
self.price=price
def tell_info(self):
print('<%s %s %s>' %(self.name,self.period,self.price))
class Date:
def __init__(self,year,mon,day):
self.year=year
self.mon=mon
self.day=day
def tell_birth(self):
print('<%s-%s-%s>' %(self.year,self.mon,self.day))
class People:
school='清华大学'
def __init__(self,name,sex,age):
self.name=name
self.sex=sex
self.age=age
#Teacher类基于继承来重用People的代码,基于组合来重用Date类和Course类的代码
class Teacher(People): #老师是人
def __init__(self,name,sex,age,title,year,mon,day):
super().__init__(name,age,sex)
self.birth=Date(year,mon,day) #老师有生日
self.courses=[] #老师有课程,可以在实例化后,往该列表中添加Course类的对象
def teach(self):
print('%s is teaching' %self.name)
python=Course('python','3mons',3000.0)
linux=Course('linux','5mons',5000.0)
teacher1=Teacher('lili','female',28,'博士生导师',1990,3,23)
# teacher1有两门课程
teacher1.courses.append(python)
teacher1.courses.append(linux)
# 重用Date类的功能
teacher1.birth.tell_birth()
# 重用Course类的功能
for obj in teacher1.courses:
obj.tell_info()
此时对象teacher1集对象独有的属性、Teacher类中的内容、Course类中的内容于一身(都可以访问到),是一个高度整合的产物

