
Spark2.4.0源码——RpcEnv
参考《Spark内核设计的艺术:架构设计与实现——耿嘉安》
NettyRpcEnv概述
Spark的NettyRpc环境的一些重要组件:

private[netty] val transportConf = SparkTransportConf.fromSparkConf(...) private val dispatcher: Dispatcher = new Dispatcher(this, numUsableCores) private val streamManager = new NettyStreamManager(this) private val transportContext = new TransportContext(transportConf, new NettyRpcHandler(dispatcher, this, streamManager)) //用于创建TransportClient的工厂类 private val clientFactory = transportContext.createClientFactory(createClientBootstraps()) //volatile 关键字保证变量在多线程之间的可见性 @volatile private var server: TransportServer = _
绪:RpcEndpoint&RpcEndpointRef
RpcEndpoint
RpcEndpoint是对能够处理RPC请求,给某一特定服务提供本地及跨节点调用的RPC组件的抽象,所有运行于RPC框架上的实体都应该继承trait RPCEndpoint。
package org.apache.spark.rpc import org.apache.spark.SparkException //创建RpcEnv的工厂类,必须有一个空构造函数才能通过反射创建 private[spark] trait RpcEnvFactory { def create(config: RpcEnvConfig): RpcEnv } private[spark] trait RpcEndpoint { //当前RpcEndpoint所属的RpcEnv val rpcEnv: RpcEnv //获取RpcEndpoint相关联的RpcEndpointRef final def self: RpcEndpointRef = { require(rpcEnv != null, "rpcEnv has not been initialized") rpcEnv.endpointRef(this) } //接收消息并处理,不回复客户端 def receive: PartialFunction[Any, Unit] = { case _ => throw new SparkException(self + " does not implement 'receive'") } //接收消息并处理,通过RpcCallContext回复客户端 def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = { case _ => context.sendFailure(new SparkException(self + " won't reply anything")) } //onError、onConnected、onDisconnected、onNetworkError、onStart、onStop顾名思义 //用于停止当前RpcEndpoint,注意onStop是trait定义的抽象方法,在停止RpcEndpoint时调用,做一些收尾工作 final def stop(): Unit = { val _self = self if (_self != null) { rpcEnv.stop(_self) } } } //线程安全的、串行处理消息的ThreadSafeRpcEndpoint private[spark] trait ThreadSafeRpcEndpoint extends RpcEndpoint
trait ThreadSafeRpcEndpoint/... extends RpcEndpoint
ThreadSafeRpcEndpoint主要用于消息的串行处理,必须是线程安全的
Master/Worker/HeartbeatReceiver/... extends ThreadSafeRpcEndpoint
RpcEndpointRef
要向一个远端RpcEndpoint发送请求,就必须持有这个RpcEndpoint的远程引用RpcEndpointRef,它是线程安全的。
private[spark] abstract class RpcEndpointRef(conf: SparkConf) extends Serializable with Logging { //rpc最大重连次数,默认3,可使用spark.rpc.numRetries属性配置 private[this] val maxRetries = RpcUtils.numRetries(conf) //rpc每次重连等待的毫秒数,默认3s,可使用spark.rpc.retry.wait属性配置 private[this] val retryWaitMs = RpcUtils.retryWaitMs(conf) //rpc的ask操作默认超时时间,默认120s,可使用spark.rpc.askTimeout(优先级高)/spark.network.timeout属性配置 private[this] val defaultAskTimeout = RpcUtils.askRpcTimeout(conf) //返回当前RpcEndpointRef对应的RpcEndpoint的RPC地址 def address: RpcAddress //返回当前RpcEndpointRef对应的RpcEndpoint的名称 def name: String //发送单向异步的消息到相应的RpcEndpoint.receive。 def send(message: Any): Unit //发送一条消息到相应的RpcEndpoint.receiveAndReply,并在指定的超时内接收处理结果。此方法只发送消息一次,从不重试。 def ask[T: ClassTag](message: Any, timeout: RpcTimeout): Future[T] def ask[T: ClassTag](message: Any): Future[T] = ask(message, defaultAskTimeout) //发送同步请求到相应的RpcEndpoint.receiveAndReply,并在超时时间内等待处理结果,当抛出异常时会请求重试次数以内的重连。 def askSync[T: ClassTag](message: Any): T = askSync(message, defaultAskTimeout) def askSync[T: ClassTag](message: Any, timeout: RpcTimeout): T = { val future = ask[T](message, timeout) timeout.awaitResult(future) } }
消息投递规则:
at-most-once:投递0或1此,消息可能会丢失
at-least-once:潜在地多次投递并保证至少成功一次,消息可能会重复
exactly-once:准确发送一次,消息不会丢失也不会重复
1 TransportConf
RPC传输上下文配置类,用于创建TransportClientFactory和TransportServer。
//通过SparkTransportConf的fromSparkConf方法来构建TransportConf需要三个参数:sparkConf、模块名module和可用内核数 private[netty] val transportConf = SparkTransportConf.fromSparkConf( //先克隆SparkConf并设置节点间取数据的连接数 conf.clone.set("spark.rpc.io.numConnectionsPerPeer", "1"), //设置模块名 "rpc", //Netty传输线程数,如果小于或等于0,线程数就是系统可用处理器的数量,最多为8线程。 conf.getInt("spark.rpc.io.threads", numUsableCores))
2 Dispatcher
Dispatcher负责将消息路由到应该对此消息处理的RpcEndpoint,可以提高NettyRpcEnv对消息的异步处理和并行处理能力。
private val dispatcher: Dispatcher = new Dispatcher(this, numUsableCores)
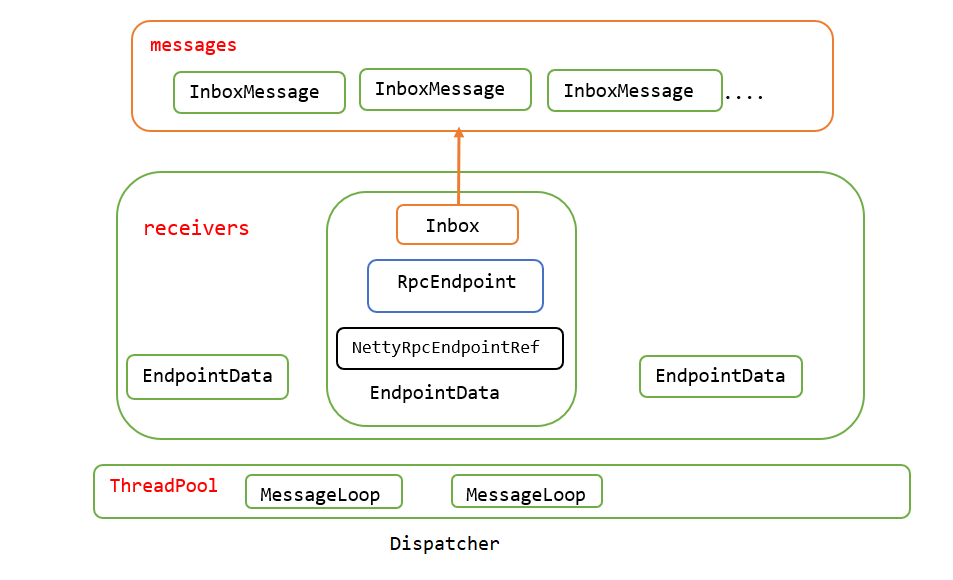
基本概念:
InboxMessage:Inbox盒子内的消息,是一个trait,所有类型的RPC消息都要继承自InboxMessage。
Inbox:端点内的盒子,每个RpcEndpoint都有一个对应的盒子,这个盒子有存储InboxMessage的列表messages,所有的消息都缓存在messages并由RpcEndpoint异步处理。
EndpointData:RPC端点数据,包括RpcEndpoint、NettyRpcEndpointRef和Inbox等属于同一个端点的实例。
endpoints:端点实例RpcEndpoint与EndpointData之间映射关系的缓存。
endpointRefs:端点实例RpcEndpoint与RpcEndpointRef之间映射关系的缓存.
receivers:存储EndpointData的阻塞队列,只有Inbox中有消息的EndpointData才会被放入此队列。
stopped:Dispatcher是否停止的状态。
threadPool:用于对消息进行调度的线程池,里面运行的任务都是MessageLoop。
2.1 Dispatcher注册RpcEndpoint
def registerRpcEndpoint(name: String, endpoint: RpcEndpoint): NettyRpcEndpointRef = { //使用当前RpcEndpoint所在的NettyRpcEnv的地址和RpcEndpoint的名称创建RpcEndpointAddress对象 val addr = RpcEndpointAddress(nettyEnv.address, name) //创建RpcEndpoint的引用对象 val endpointRef = new NettyRpcEndpointRef(nettyEnv.conf, addr, nettyEnv) synchronized { if (stopped) { throw new IllegalStateException("RpcEnv has been stopped") } if (endpoints.putIfAbsent(name, new EndpointData(name, endpoint, endpointRef)) != null) { throw new IllegalArgumentException(s"There is already an RpcEndpoint called $name") } //创建EndpointData并放入endpoints缓存 val data = endpoints.get(name) //将RpcEndpoint与NettyRpcEndpointRef映射关系放入endpointRefs缓存 endpointRefs.put(data.endpoint, data.ref) //将EndpointData放入阻塞队列receivers,由于EndpointData是新建的,内部会新建Inbox并执行Inbox的主构造函数, //向Inbox自身的messages列表中放入OnStart消息,MessageLoop线程会取出此EndpointData并调用当前Inbox的process方法 //处理OnStart消息,启动与此Inbox相关联的Endpoint。 receivers.offer(data) // for the OnStart message } endpointRef }
2.2 Dispatcher的调度原理
private val threadpool: ThreadPoolExecutor = { //获取可用处理器数,numUsableCores是NettyRpcEnv的入参,如果大于0则等于numUsableCores,否则为当前系统可用处理器 val availableCores = if (numUsableCores > 0) numUsableCores else Runtime.getRuntime.availableProcessors() //获取当前线程池的大小,默认为2和可用处理器之间的最大值,可用spark.rpc.netty.dispatcher.numThreads属性配置 val numThreads = nettyEnv.conf.getInt("spark.rpc.netty.dispatcher.numThreads", math.max(2, availableCores)) //创建线程池 val pool = ThreadUtils.newDaemonFixedThreadPool(numThreads, "dispatcher-event-loop") //启动多个线程运行MessageLoop任务 for (i <- 0 until numThreads) { pool.execute(new MessageLoop) } //返回线程池引用 pool } /** Message loop used for dispatching messages. */ private class MessageLoop extends Runnable { override def run(): Unit = { try { while (true) { try { //在阻塞队列中获取EndpointData val data = receivers.take() //如果EndpointData是空数据,则将它重新放回队列并直接返回,这样可以让其他MessageLoop获取到这个空EndpointData并结束线程
//private val PoisonPill = new EndpointData(null,null,null)
if (data == PoisonPill) { // Put PoisonPill back so that other MessageLoops can see it. receivers.offer(PoisonPill) return } //调用inbox的process方法对消息进行处理 data.inbox.process(Dispatcher.this) } catch { case NonFatal(e) => logError(e.getMessage, e) } } } catch { case ie: InterruptedException => // exit } } }
Inbox的process方法:
def process(dispatcher: Dispatcher): Unit = { var message: InboxMessage = null //线程并发检查,如果不允许多线程执行且当前激活线程不为0,直接返回 inbox.synchronized { if (!enableConcurrent && numActiveThreads != 0) { return } //获取消息,如果消息不为空,则当前激活线程+1,否则return返回 message = messages.poll() if (message != null) { numActiveThreads += 1 } else { return } } while (true) { //对匹配执行时可能发生的错误,使用Endpoint的onError方法处理 safelyCall(endpoint) { //匹配不同类型的消息进行处理 message match{...} } //对激活进程数量的控制,如果不允许多线程处理且当前激活进程不为1,当前线程退出,numActiveThreads - 1 //如果message为空,没有消息需要处理,当前线程退出,numActiveThreads - 1 inbox.synchronized { // "enableConcurrent" will be set to false after `onStop` is called, so we should check it // every time. if (!enableConcurrent && numActiveThreads != 1) { // If we are not the only one worker, exit numActiveThreads -= 1 return } message = messages.poll() if (message == null) { numActiveThreads -= 1 return } } } }
2.3 Dispatcher对RpcEndpoint去注册
def stop(rpcEndpointRef: RpcEndpointRef): Unit = { synchronized { if (stopped) { // This endpoint will be stopped by Dispatcher.stop() method. return } unregisterRpcEndpoint(rpcEndpointRef.name) } }
private def unregisterRpcEndpoint(name: String): Unit = { //取出EndpointData val data = endpoints.remove(name) if (data != null) { //调用Inbox的stop方法 data.inbox.stop() //将EndpointData重新放入receivers队列,让MessageLoop线程能读取到Stop状态,进行相应的处理 receivers.offer(data) // for the OnStop message } // Don't clean `endpointRefs` here because it's possible that some messages are being processed // now and they can use `getRpcEndpointRef`. So `endpointRefs` will be cleaned in Inbox via // `removeRpcEndpointRef`. }
/* * 当要移除一个EndpointData时,其Inbox可能正在对消息进行处理,所以调用Inbox的stop方法平滑过渡处理; * 将允许并发运行设置为false,并设置当前Inbox为stopped状态,将当前Inbox所属的EndpointData重新放入receivers, * Inbox.process方法会匹配执行相应的处理,调用Dispatcher.removeRpcEndpointRef方法从endpointRefs缓存中移除当前RpcEndpointRef的映射;
* 在匹配执行OnStop消息的最后,会调用RpcEndpoint的OnStop方法停止RpcEndpoint。 */ def stop(): Unit = inbox.synchronized { // The following codes should be in `synchronized` so that we can make sure "OnStop" is the last // message if (!stopped) { // We should disable concurrent here. Then when RpcEndpoint.onStop is called, it's the only // thread that is processing messages. So `RpcEndpoint.onStop` can release its resources // safely. enableConcurrent = false stopped = true messages.add(OnStop) // Note: The concurrent events in messages will be processed one by one. } }
Dispatcher.stop()方法用来停止Dispatcher,之前的stop(rpcEndpointRef:RpcEndpointRef)用于对RpcEndpoint的去注册。
def stop(): Unit = { synchronized { if (stopped) { return } stopped = true } // Stop all endpoints. This will queue all endpoints for processing by the message loops. //调用unregisterRpcEndpoint方法,对Dispatcher中的所有EndpointData进行去注册,会向endpoints中每个EndpointData中的Inbox中放置 //OnStop消息;最后向receivers中投放PoisonPill,即空EndpointData,以停止所有的MessageLoop线程 endpoints.keySet().asScala.foreach(unregisterRpcEndpoint) // Enqueue a message that tells the message loops to stop. receivers.offer(PoisonPill) threadpool.shutdown() }
2.4 Dispatcher提交消息
/** * 将消息提交给指定的RpcEndpoint * @param endpointName endpoint名称 * @param message 消息类型 * @param callbackIfStopped endpoint为stop状态时的回调函数 */ private def postMessage( endpointName: String, message: InboxMessage, callbackIfStopped: (Exception) => Unit): Unit = { val error = synchronized { //从endpoints缓存获取EndpointData val data = endpoints.get(endpointName) if (stopped) { Some(new RpcEnvStoppedException()) } else if (data == null) { Some(new SparkException(s"Could not find $endpointName.")) } else { //如果endpointData不是停止状态且endpoints缓存中确实有这个EndpointData //调用对应的Inbox.post将消息加入Inbox的消息列表中 data.inbox.post(message) //将EndpointData加入receivers队列,以便MessageLoop线程处理此Inbox中的消息 receivers.offer(data) None } } // We don't need to call `onStop` in the `synchronized` block error.foreach(callbackIfStopped) }
//在Inbox未停止时,将message加入messages缓存 def post(message: InboxMessage): Unit = inbox.synchronized { if (stopped) { // We already put "OnStop" into "messages", so we should drop further messages onDrop(message) } else { messages.add(message) false } }
3 NettyStreamManager
基于ConcurrentHashMap提供NettyRpcEnv的文件流服务,支持普通文件、jar文件及目录的添加缓存和文件流读取,各个Excutor节点可以使用Driver端提供的NettyStreamManager从Driver端下载jar包或文件支持任务的运行。
4 TransportContext
TransportContext内部包含TransportConf和RpcHandler,封装了用于创建TransportClientFactory和TransportServer的上下文信息;TransportClientFactory是创建TransportClient的工厂类,用于创建RPC框架的客户端,transportServer是RPC框架的服务端。
private val transportContext = new TransportContext(transportConf, new NettyRpcHandler(dispatcher, this, streamManager))
创建TransportContext需要两个参数:transportConf和NettyRpcHandler,主要看一下NettyRpcHandler。
private[netty] class NettyRpcHandler( dispatcher: Dispatcher, nettyEnv: NettyRpcEnv, streamManager: StreamManager) extends RpcHandler with Logging { // A variable to track the remote RpcEnv addresses of all clients private val remoteAddresses = new ConcurrentHashMap[RpcAddress, RpcAddress]() //带回调函数的receive方法,调用internalReceive方法将将ByteBuffer类型的消息转化为RequestMessage //最后调用dispatcher.postRemoteMessage将消息投递到Inbox,由RpcEndpoint处理消息并回复客户端 override def receive( client: TransportClient, message: ByteBuffer, callback: RpcResponseCallback): Unit = { val messageToDispatch = internalReceive(client, message) dispatcher.postRemoteMessage(messageToDispatch, callback) } //方法重载,RpcEndpoint处理完消息不会回复客户端 override def receive( client: TransportClient, message: ByteBuffer): Unit = { val messageToDispatch = internalReceive(client, message) dispatcher.postOneWayMessage(messageToDispatch) } //将ByteBuffer类型的消息转化为RequestMessage private def internalReceive(client: TransportClient, message: ByteBuffer): RequestMessage = { //从TransportClient中获取远端地址RpcAddress val addr = client.getChannel().remoteAddress().asInstanceOf[InetSocketAddress] assert(addr != null) val clientAddr = RpcAddress(addr.getHostString, addr.getPort) //封装消息 val requestMessage = RequestMessage(nettyEnv, client, message) //如果没有发送者地址信息,使用从TransportClient获取的远端地址RpcAddress、消息的接收者(RpcEndpoint)、消息内容构造新的消息 if (requestMessage.senderAddress == null) { // Create a new message with the socket address of the client as the sender. new RequestMessage(clientAddr, requestMessage.receiver, requestMessage.content) } else { // The remote RpcEnv listens to some port, we should also fire a RemoteProcessConnected for // the listening address //获取发送者地址信息,将远端地址RpcAddress和发送者地址信息映射关系放入缓存remoteAddresses val remoteEnvAddress = requestMessage.senderAddress if (remoteAddresses.putIfAbsent(clientAddr, remoteEnvAddress) == null) { //向endpoints缓存中的所有EndpointData的Inbox中放入RemoteProcessConnected类型的消息 dispatcher.postToAll(RemoteProcessConnected(remoteEnvAddress)) } requestMessage } } ... //其他类型消息的处理,与receive类似 }
5 客户端发送请求
//用于处理请求超时的调度器 val timeoutScheduler = ThreadUtils.newDaemonSingleThreadScheduledExecutor("netty-rpc-env-timeout") //用于异步处理客户端创建的线程池 private[netty] val clientConnectionExecutor = ThreadUtils.newDaemonCachedThreadPool( "netty-rpc-connection", conf.getInt("spark.rpc.connect.threads", 64)) /** * 缓存远端RPC地址与OutBox的关系 * OutBox与之前的Inbox类似,Outbox是在客户端使用,通过OutboxMessage封装对外发送的消息 * Inbox在服务端使用,通过InboxMessage封装接收的消息。 * outbox内部有messgaes列表存放消息,通过drainOutbox方法循环取出消息并调用sendWith方法处理 * */ private val outboxes = new ConcurrentHashMap[RpcAddress, Outbox]()
篇幅原因到此为止,很多东西还停留在代码层面,有点云里雾里,后面研究其他组件的时候有机会再重读RPC环境的代码吧==!
请求的发送与接收处理流程:
1、通过NettyRpcEndpointRef的send/ask方法向远端节点的RpcEndpoint发送消息,消息会先被封装为OutboxMessage,然后放入远端RpcEndpoint的地址对应的Outbox的messages列表中。
2、Outbox的drainOutbox方法不断从messages列表取出OutboxMessage,并使用内部的TransportClient向远端NettyRpcEnv发送OutboxMessage。
3、发送的请求与在远端RpcEndpoint的TransportServer建立连接,请求先经过RPC管道的处理后由NettyRpcHandler处理,NettyRpcHandler的receive方法会调用Dispatcher的post...方法将消息放入EndpointData内部的Inbox的messges中,最后MessageLoop线程会读取消息并将消息发送给对应的RpcEndpoint处理。

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步