


根据前两天的学习,对Python有了一点小小的认识,目前兴趣指数仍为5颗星,哈哈,所以周六到晚上8点钟,还是坚持学习了新内容,以下为新内容的总结:
给自己的博客书写定个规矩,一级标题用标题2大小,依次类推逐渐减小;
一级标题用“一”、二级标题用“(一)”、三级标题用“1”、四级标题用“(1)”、五级标题用“①”、六级标题用“1)”...
重新学习一下数据类型和运算符。
一、运算符
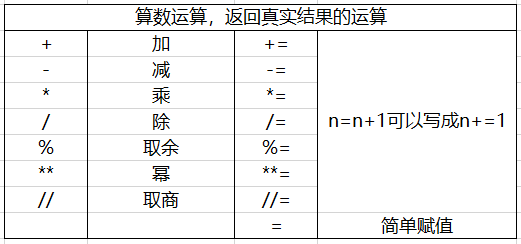
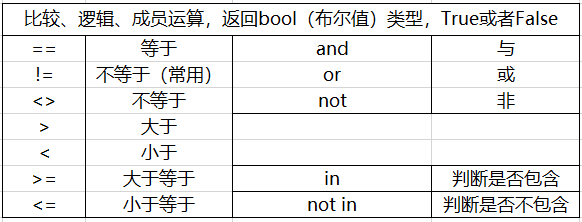
需要注意的事情:
(一)Python中判断运算的用法
name_01="小果子"#定义name_01为字符串类型; v="小"in name_01#判断“小”是否在name_01中,我觉得Python这个功能实在是不能在方便了。 print(v)#输出结果为True
(二)运算的优先级问题
1、有括号的先算括号内的内容;
2、逻辑运算顺序:无括号的,按顺序执行,从前往后运算。
jieguo_1=2>1 and "小" not in "果果" or 1+1>3#共3个part,第一个是2>1,为True,第二个"小" not in "果果"也为True,后面的不在执行 print(jieguo_1)#输出为True # 执行到哪里,需要看逻辑运算及其前后的bool值 # True or ==>True # True and ==>继续走 # False or ==>继续走 # False and ==>False
二、数据类型
(一)数字
在Python中,和其他程序最大的进步就是没有长短整型的分类了,不管数字有多大,统称int,具体能装多大数,看系统能力了,64位系统是32位系统的2倍。
下面是数字类型的一些常用方法及属性
1、转换到数字类型的函数,int(num,base=none);
将字符串或者其他形式的数字转换到数字类型,有些特殊的情况,比如超出范围等情况不做探究;默认要转换的数字/字符串为10进制,如果是其他进制,需要在base=none中声明。
a="111" #定义a为字符串类型。 v=int(a,base=2)#定义v为数字类型,int()将a转换为了10进制的数字类型,base=2表示要转换的a为2进制数字。 print(v)#输出结果为7
报错的使用方法
#第一种常用情况 a="3b" v=int(a) #执行中,系统会判断,在10进制情况下是没有b的,无法转换,报错 print(v) #第二种常用情况 a="3+6" v=int(a)#无法运算字符串 print(v)
2、数字类型的一些基本属性
num_01=-717521 v_1=num_01.bit_length()#表示数字转换到2进制情况下,至少占用的位数; v_2=num_01.__abs__()#返回绝对值,注意abs前后是两个半角下划线; print(v_1,v_2)#输出结果为20 717521
其他的属性,后续在学习,基本上都是一些数字运算的问题,平常用处不大。
(二)字符串
字符串的属性很多,看的眼花缭乱,通过两天的学习和整理,基本上知道了一些基础的用法,现整理如下:
#属性中的self不用管,不用指定值
#start为闭区间,end为开区间,start≤sub<end,顾首不顾尾
#*args, **kwargs,等为任意的参数
#index()索引,查找位置
#返回的int都是相对于其真实位置(从左边数)
#无数据返回时,会报错。
str="小果果是一只笨蛋"
s1=str.index('果')
s2=str.rindex("果")
print(s1,s2)#输出结果为1 2
#count()查找指定的子序列在str中出现的次数
# 若没找到返回:0
str='小果果是一只狗子'
s=str.count("果")#‘果’在test中出现的次数,输出int值;
print(s)
#format()格式化,将字符串中的占位符(必须是半角的{})替换为指定的值.
#3种方法:1、按默认从左到右的默认顺序传值,2、按指定位置传值,3、按设置参数传值,返回格式化后的字符串
str='my name is {},'
s1=str.format("alex")
v=str.format_map(mapping})#另外一种格式化,括号中的mapping是一个字典对象。
print(s1)
#encode()和decode(),编码和接码属性,后续在研究
s="你好啊小果果"
s1=s.encode("utf-8")#以指定的编码格式对字符串进行编码,并返回编码后的二进制;encode(self, encoding='utf-8', errors='strict')
print(type(s1),s1)
s2=s1.decode("utf-8")
print(type(s2),s2)
#title()将字符串中的所有单词的首字母的替换成大写字母
str='alex jim hhhh'
s1=str.title()
s2=s1.istitle()#是否首字母为大写,且其他字母为小写(一般用于识别标题,对中文感觉没有用啊)
print(s1,s2)#输出Alex Jim Hhhh True
#ljust(),rjust()填充,从左边、右边、两边填充指定的参数,长度为必须参数
str='* 是吗'
s1=str.ljust(10,"你")#返回一个左对齐的字符串,width为长度,fillchar可填写一个str
s2=str.rjust(10,"你")
s3=str.center(10,'你')#sub在指定的width(宽度)中的位置,fillchar可填写一个str(写int报错)
print(s1,s2,s3)
#zfill()填充,按指定长度在字符串的左侧填充"0"补齐,无法填充其他的,不如ljust()好用
str='我是小果果'
s1=str.zfill(20)
print(s1)
#swapcase(),casefold(),capitalize()大小写相关的互换。
s=str.swapcase()#大小写转换
s1=str.casefold()#所有的字符变小写,输出str值
s2=str.capitalize()#首字母大写,其他字母变小写,输出str值,对于英文来说,好处就是统一格式,对中文啥用,目前想不起来
#maketrans(),translate()建立对应关系,并对字符进行对换位置。
old='12345'
new='abcde'
str='真的不错啊12345'
s1=str.maketrans(old,new)#建立对应关系(映射表),字典格式
s2=str.translate(s1)#对上面建立的映射表进行替换(翻译)
print(type(s1),type(s2),s2)#输出<class 'dict'> <class 'str'> 真的不错啊abcde
#expandtabs(),把字符串中的 tab\t、换行\n、转为空格(默认的步长为8,从左边开始执行,无符号不执行)。爬虫的时候可以将格式对齐
s="12345678888\t133"
v=s.expandtabs()
print(type(v),v)#输出<class 'str'> 12345678888 133
######################################
#以下都是is相关的属性,输出bool值
#当前输入是否是数字(适应于文件操作,一、1、①等读写)
s1=str.isdecimal()#是否全是十进制字符,这种方法只存在于unicode对象。
s2=str.isdigit()#是否全是数字
s3=str.isnumeric()#是否全是数字,只针对unicode对象。
#判断是否都是大小写,和转换为大小写
s=str.lower( )#将字符串中的大写字母转换成小写字母
s=str.upper()
s=str.islower()#是否全是小写
s=str.isupper()#是否全是大写
text="zh1en"
v=text.isalnum()#是否是否由字母或数字组成
v=text.isalpha()#是否全为字母或汉字
v=text.isspace()#是否全部都是空格
v=text.isprintable()#打印出来和字符串一样,输出True,包含/t(制表符Tab),/n(换行)等为Flase
v=text.isidentifier()#判断是否是合法标识符,实际上是判断变量名是否合法。
#判断开头(前缀)、结尾(后缀)的字符是否一致
#startswith()#判断字符串是否是以指定字符串开头并返回布尔值
#endswith()
#############重点需要记熟的属性###################
#find() 索引,查找位置
# 返回的int都是相对于其真实位置(从左边数)
# 无数据返回时,返回-1。需要子序列完全匹配
str='小果果是一只狗子'
s1=str.find("果")#看sub的位置,从0开始数,输出int值,find(self, sub, start=None, end=None)
s2=str.rfind('棕色')
print(s1,s2)#输出结果为 1 -1
#strip(),去处左右空格(包括空格,/t,/n,/r)
#若加入参数,则移除指定字符,有限最多匹配。
# 注意删除多个字符时:只要头尾有对应其中的某个字符即删除,不考虑顺序,直到遇到第一个不包含在其中的字符为止
str='**小果果是一只小狗子**'
s1=str.strip('*小子果')#输出 是一只小狗
s2=str.lstrip('*')
s3=str.rstrip('*')
print(s1)
print(s2)
print(s3)
#split(),对字符串进行切片、分割。
#返回值为list列表形式返回
#正则表达式分割,后续学习。
str='**小果果是一只小狗子**'
s3=str.split("小",6)#split(self, sep=None, maxsplit=-1)
s4=str.rsplit()
s5=str.splitlines()#分割,可以加入参数为True、False来决定是否保留换行符
print(type(s3),type(s4),type(s5),s3,s4,s5)
#按从左到右的顺序,对字符串进行分割,返回一个包含3个元素的元组,这个元组中这3个元素分别为:指定分割符,以及以这个分隔符为中心的左右两侧的字符串。
#s1=str.partition()#只能分3份
#s2=str.rpartition()
#replace()替换,将指定的字符串替换成新的字符串,并返回替换后的字符串。可以指定替换的次数,若不指定次数则默认替换全部。
str='**小果果是一只小狗子**'
s1=str.replace('小','chali',1)#参数分别为 被替换,替换,替换次数
print(s1)#输出**chali果果是一只小狗子**
#join()拼接,将字符串中的元素以指定的分隔符进行拼接;join(self, iterable)
str='*'
s1=str.join("你是不是小果果")
print(s1) #你*是*不*是*小*果*果
以上字符串的属性肯定是会忘得,但是在整理的过程中,学习了一些用法和思维方式,也算挺好。
第一周结束语
第一周的学习内容就这么多了,继续加油吧~整个人其实还是好的!
