
SQL索引
1.索引是一种B-Tree树结构:
B-Tree树结构可以看成是这样的一种演化:二叉树 =》 平衡二叉树(算法) =》 多路搜索树
这种结构的优势在于:如果B树的所有非叶子结点的左右子树的结点数目均保持差不多(平衡),那么B树的搜索性能逼近二分查找;但它比连续内存空间的二分查找的优点是,改变B树结构(插入与删除结点)不需要移动大段的内存数据,甚至通常是常数开销;
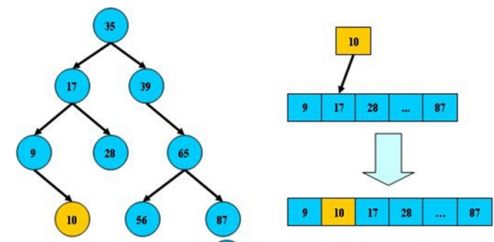
B-树
B-tree,即B树,而不要读成B减树,它是一种多路搜索树(并不是二叉的): 1.定义任意非叶子结点最多只有M个儿子;且M>2; 2.根结点的儿子数为[2, M]; 3.除根结点以外的非叶子结点的儿子数为[M/2, M]; 4.每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字) 5.非叶子结点的关键字个数=指向儿子的指针个数-1; 6.非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1]; 7.非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树; 8.所有叶子结点位于同一层;
如:(M=3)
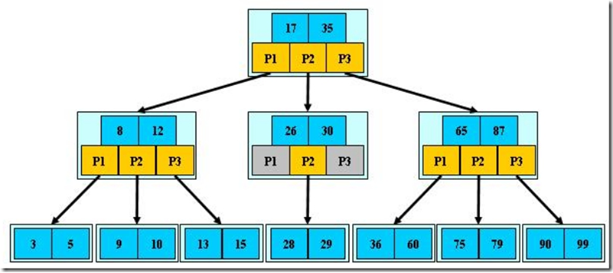
B+树
B+树是B-树的变体,也是一种多路搜索树: 其定义基本与B-树同, 除了: 1.非叶子结点的子树指针与关键字个数相同; 2.非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);(B+是闭区间,也就是包含区间的两端值) 3.为所有叶子结点增加一个链指针; 4.所有关键字都在叶子结点出现;
如:(M=3)
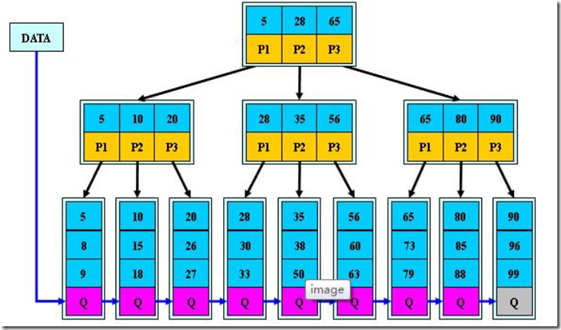
2.聚集索引和非聚集索引:
聚集索引和非聚集索引都采用了B+树的结构,但非聚集索引的叶子层并不与实际的数据页相重叠,而采用叶子层包含一个指向表中的记录在数据页中的指针的方式。 聚集索引和非聚集索引的根本区别是表记录的排列顺序和与索引的排列顺序是否一致,聚集索引表记录的排列顺序与索引的排列顺序一致,优点是查询速度快,
因为一旦具有第一个索引值的纪录被找到,具有连续索引值的记录也一定物理的紧跟其后。 聚集索引的缺点是对表进行修改速度较慢,这是为了保持表中的记录的物理顺序与索引的顺序一致,而把记录插入到数据页的相应位置,
必须在数据页中进行数据重排,降低了执行速度。
非聚集索引指定了表中记录的逻辑顺序,但记录的物理顺序和索引的顺序不一致,聚集索引和非聚集索引都采用了B+树的结构,但非聚集索引的叶子层并不与实际的数据页相重叠,
而采用叶子层包含一个指向表中的记录在数据页中的指针的方式。非聚集索引比聚集索引层次多,添加记录不会引起数据顺序的重组。
SQL创建聚集索引
create clustered index SalesOrderDetail_test_CL
on dbo.SalesOrderDetail_test (SalesOrderDetailID)
go
SQL创建非聚集索引
create index SalesOrderDetail_test_NCL_Price
on dbo.SalesOrderDetail_test (UnitPrice)
go
SQL清空执行计划缓存
DBCC DROPCLEANBUFFERS--清空执行计划缓存
DBCC FREEPROCCACHE--清空数据缓存
3.table scan,index scan以及index seek:
A table scan is where the table is processed row by row from beginning to end. An index scan is where the index is processed row by row from beginning to end. If the index is a clustered index then an index scan is really a table scan.
总结:在sql server中,对表中数据从头到尾一行一行的进行出来就是表扫描。这里的处理我们可以理解为sql中where子句的条件判断。
我们需要遍历表中的每一行,判断是否满足where条件。最简单的table scan是select * from table。
索引扫描就是对索引中的每个节点从头到尾的访问。假设我们的索引是B树结构的,那么index scan就是访问B树中的每一个节点。
假如索引是聚集索引,那么B树索引的叶子节点保存的是数据页中的实际数据。假如索引是非聚集索引,那么B树叶子节点保存的是指向数据页的指针。
附上:SQL执行计划详细分析
4.索引维护:
由于索引是采用 B 树结构存储的,所以对应的索引项并不会被删除,经过一段时间的增删改操作后,数据库中就会出现大量的存储碎片,这和磁盘碎片、内存碎片产生原理是类似的,
这些存储碎片不仅占用了存储空间,而且降低了数据库运行的速度。如果发现索引中存在过多的存储碎片的话就要进行“碎片整理”了,最方便的“碎片整理” 手段就是重建索引,
重建索引会将先前创建的索引删除然后重新创建索引,主流数据库管理系统都提供了重建索引的功能,比如 REINDEX、REBUILD 等,如果使用的数据库管理系统没有提供重建索引的功能,
可以首先用DROP INDEX语句删除索引,然后用ALTER TABLE 语句重新创建索引。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号