redux工作流,老师用的那个图其实有问题
推荐这个图
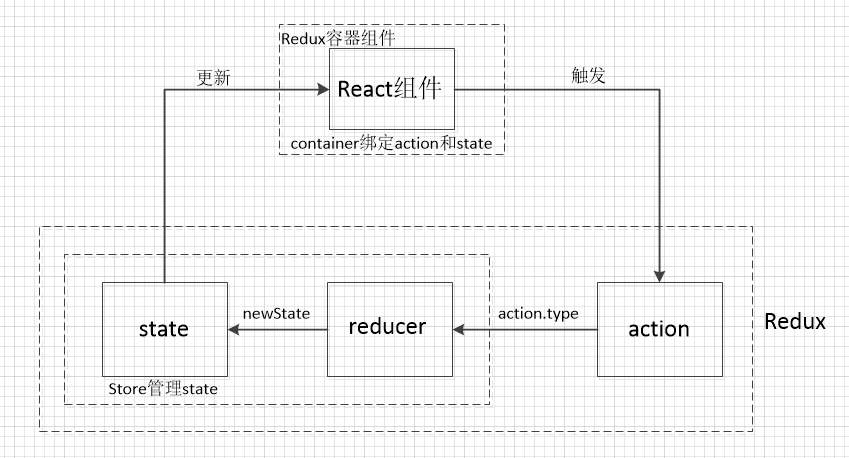
个人认为,store应该包括三个部分,action,reducer,state.
因为,实际的项目中,我们会把这三个部分,都放在store文件夹里
所以,这张图也有问题。
下图不推荐
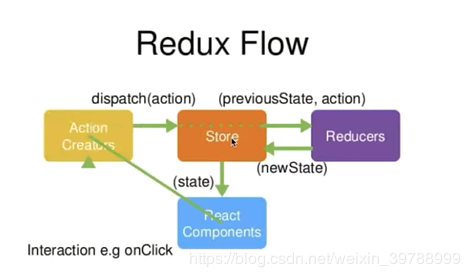
原因是因为
1.老师的的图,会让人误认为,reducer是独立于store而存在的。
2.而且老师用的图,还使用英语来描述,有点坑小白了。
使用redux的步骤
(为了模块化,每个JS文件,都要有export default XXX)
1.新建一个store文件夹,定义一个index.js。在里面创建数据库
使用createStore(reducer)来,创建一个数据库。这个函数,只有一个参数reducer。也说明了,store的更新,只依赖于reducer。
2.在store文件夹,新建reducer,在这里导入共享状态state.js,和action.js。
reducer依赖与prevState和action。这里体现了,reducer根据当前的state和action,产生新的state。
3.在store文件夹里,新建state.js。
新建一些状态,这是数据的核心。定义一些共享的初始值,数据结构,是对象的形式,并需要暴漏出来。有些组件的state不是共享的,就可以直接在组件内部定义了。
4.store文件夹,新建action.js
这里新建一些action。一般是action里,定义好,就直接派发。
第一步,先建数据库,再建他的依赖,在建依赖的依赖。整个过程,有点逆向推导的意思*
组件状态有两种,一个是私有状态,一个是共享状态。私有状态,直接在组件内部定义,共享状态,从redux里先引入store,在获取store里的状态。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号