4.shell编程范例130+
shell脚本130+案例
1、批量修改文件后缀
当前目录下后缀为sh的文件,改为后缀shell。
这里列出两种方法,先看第一种。
方法1:
#!/bin/bash
str=`find ./ -name \*.sh`
for i in $str
do
mv $i ${i%sh}shell
done
思路很简单,用find找到符合的文件,存如数组。然后使用mv修改文件名。
其中${i%sh}shell是修改后缀后的文件名。%是将字符串变量i中sh以及sh右侧的字符全部删除。
也可以这样写,${i%.*}.shell,删除最后一个“.”以及右侧的所有字符。
还有一种直接替换,${i/.sh/.shell/},不过如果文件名中如果还含有“.sh”会出问题,因为他只替换第一个找到的字串,所以不精确。
因为此题后缀替换前后有特殊性,还可以这样写:${i}ell。
方法2:
#!/bin/bash
str=`find ./ -name "f*.sh"`
for i in $str
do
mv $i $( echo $i | sed 's#.sh$#.shell#g' )
done
此方法主要是用了sed命令,原理跟${i/sh/shell/}类似,只不过它指明了替换结尾的字串,能精确匹配要求。
2、找出文件file1中空行并输出行号
分别用三剑客来实现,先看grep
grep -n "^$" 文件名 | cut -d ':' -f1
方法1:
grep -n ^$ file1 | cut -d ':' -f1
再看awk,个人最喜欢awk ^_^
方法2:
awk '{if(length($0)<1) print NR}' file1
这里用了一个内建函数length,获取整行的字节数
最后sed
方法3:
sed -n '/^$/=' file1
3、打印root用户当前目录下可执行文件数
开始想用find解决,find有针对权限的参数-perm。
仔细想想觉得权限的排列组合虽然不算太多,但是用数字不直观,容易乱,还是决定用正则来判断简单。
分四步来处理,第一步:
针对属主是root的文件
第二步:
针对属主不是root,但是组属性与root组相同的文件
第三步:
针对属主不是root,也不同组的文件
最后合并三次的结果进行计算。
-----代码来了-----
#属主是root的可执行文件
find -maxdepth 1 -type f -uid 0 -exec ls -l {} \; |awk '{if($3=="root") print $0}' | egrep "(^-..x|^-..-..-..x|^-..-..x)" >> execlist.txt
#跟root同组的可执行文件
find -maxdepth 1 -type f -exec ls -l {} \; |awk '{if($3!="root" && $4=="root") print $0}'|egrep "(^-..-..-..x|^-..-..x)">> execlist.txt
#不同组的可执行文件
find -maxdepth 1 -type f -exec ls -l {} \; |awk '{if($3!="root" && $4!="root") print $0}'|egrep "^-........x" >> execlist.txt
#排序后排重,计算总数
sort execlist.txt | uniq | wc -l
4、将当前目录下大于10K的文件转移
方法1:用find+循环来实现
#!/bin/bash
fileinfo=`find -maxdepth 1 -type f -size +100k`
#echo ${fileinfo}
for i in $fileinfo;do
#echo ${i}
mv ${i} /tmp
done
此方法思路简单,将文件找到存如数组中,然后使用for in循环每次取出一个执行mv
方法2:用find -exec选项实现
find -maxdepth 1 -type f -size +10k -exec mv {} /tmp \;
此方法利用find的-exec实现,找到一个执行一次mv
注:这里只对当前目录进行了文件移动,子目录没做。
方法3:这次不用find,用ls+awk实现
for fileinfoin `ls -l | awk '$5>10240 {print $9}'`
do
mv $fileinfo /tmp
done
5、把以abc开头的下一行以def结尾的两行替换成douyu
这个有点麻烦,需要关联上下行的两个条件。
方法1:
大致思路如下:
按行读取文件,存入数组。
以循环方式按顺序处理数组中的数据。
循环内判断行是否已abc开头,如果是则将变量存入临时变量,并不做输出处理;如果不是abc开头则直接输出变量内容到文件,进入下次循环
再次循环时,判断上一行是否是abc开头,如果是再判断本次的变量结尾是否是def。
如果条件不满足则先输出上一次循环变量(在临时变量内。)到文件,在输出本次循环的变量,临时变量清空,进入下次循环
如果条件满足,则输出duoyu字串到文件两行。
代码如下:
#!/bin/bash
f1=2
f2=""
f3=""
f4=""
while read line
do
echo $line
if [ $f1 -eq 1 ]; then
#preline header include abc
f1=2
f3=${line: -3}
f3=${f3}x
f4=""
if [ $f3 == "defx" ]; then
#line tail include def
echo "duoyu\n" >> s3.txt
echo "duoyu\n" >> s3.txt
else
echo $f2 >> s3.txt
echo $line >> s3.txt
fi
else
f4=${line:0:3}
f4=x$f4
if [ $f4 == "xabc" ]; then
f2=$line
f1=1
else
echo $line >>s3.txt
fi
fi
done < s1.txt
echo $line
if [ $f1 -eq 1 ]; then
echo $f2 >> s3.txt
f2=""
f1=2
fi
代码简略说明:
f4=${line:0:3}
f4=x$f4
变量f4用于判断头部是否是abc,这里给头部加了一个字母x,为了避免刚好取得的3个字符是纯数字。
变量f3也是类似的思路。
-------------------------------------------------------
上面的代码理由漏洞。
第一个漏洞是对文件输入文件s1.txt和输出王文建s3.txt未做相应处理。
应该在头部先判断s1存在和不存在,并做处理。
对s3.txt直接清空即可。
第二个漏洞是在判断上一个循环变量头部包含abc,本次循环变量未包含def的情况,应对本次循环进行是否头部包含abc的检测,并做处理。
#!/bin/bash
> s3.txt
if [ -f s1.txt ]; then
echo "starting..."
else
echo "error!need s1.txt!"
exit 1
fi
f1=2
f2=""
f3=""
f4=""
while read line
do
echo $line
if [ $f1 -eq 1 ]; then
#preline header include abc
f1=2
f3=${line: -3}
f3=${f3}x
f4=""
if [ $f3 == "defx" ]; then
#line tail include def
echo "duoyu\n" >> s3.txt
echo "duoyu\n" >> s3.txt
else
echo $f2 >> s3.txt
f4=${line:0:3}
f4=x$f4
if [ $f4 == "xabc" ]; then
f2=$line
f1=1
else
echo $line >>s3.txt
fi
fi
else
f4=${line:0:3}
f4=x$f4
if [ $f4 == "xabc" ]; then
f2=$line
f1=1
else
echo $line >>s3.txt
fi
fi
done < s1.txt
echo $line
if [ $f1 -eq 1 ]; then
echo $f2 >> s3.txt
f2=""
f1=2
fi
------------------------------
最后做点优化,有一部分代码是重复的,因此稍作调整可以避免重复代码。但是还要增加一个continue
#!/bin/bash
> s3.txt
if [ -f s1.txt ]; then
echo "starting..."
else
echo "error!need s1.txt!"
exit 1
fi
f1=2
f2=""
f3=""
f4=""
while read line
do
echo $line
if [ $f1 -eq 1 ]; then
#preline header include abc
f1=2
f3=${line: -3}
f3=${f3}x
f4=""
if [ $f3 == "defx" ]; then
#line tail include def
echo "duoyu\n" >> s3.txt
echo "duoyu\n" >> s3.txt
continue;
else
echo $f2 >> s3.txt
fi
fi
f4=${line:0:3}
f4=x$f4
if [ $f4 == "xabc" ]; then
f2=$line
f1=1
else
echo $line >>s3.txt
fi
done < s1.txt
echo $line
if [ $f1 -eq 1 ]; then
echo $f2 >> s3.txt
f2=""
f1=2
fi
方法2:
这个用sed直接实现,方法来自某度
sed '/^abc/{N;/def$/s/.*/douyu/}' s1.txt
方法1和方法2相比方法2比较简洁但是存在瑕疵。如果文件出现如下格式,方法二识别不出来。
abc8888888
abceeeeeeedef
即一行既满足头部abc,也满足尾部def的情况方法2无法识别。
6、读取文件末尾为数字行的末尾数字
以上一题文件s1.txt为源文件
方法1:
awk -F "[^0-9]" '/[0-9]$/{print $NF}' s1.txt
或
awk -v FS="[^0-9]" '/[0-9]$/{print $NF}'
设置分隔符为非数字,对以数字结尾的行输出最后1个字段
方法2:
sed -nr '/[0-9]$/{s/.*[^0-9]([0-9]+)$/\1/;p}'
或
sed -n /[0-9]$/p s1.txt | sed -nr 's/.*[^0-9]([0-9]+)$/\1/g;p'
第一种写法是用了嵌套
方法3:
使用read line循环实现。
此方法不如其他两种方法简洁。主要是想练习几个知识点。
包括:文件存在判断、逐行读取、获取字符串长度、判断是否是数字、终止当前循环和终止本次循环、获取部分字符串
#!/bin/bash
> s4.txt
if [ -f s1.txt ]; then
echo "starting..."
else
echo "error!need s1.txt!"
exit 1
fi
f1=""
f0=""
f2=0
#echo $f0
#exit 0
while read line
do
f0=`echo $line | sed -n '/[0-9]$/p'`
f1=`echo $f0 | awk '{print length($0)}'`
#echo $f1
if [ $f1 -eq 0 ]; then
f1=0
echo "this line is 0"
continue;
fi
#echo "this line is gt 0 ------$f1"
f2=""
j=0
while [ $j -le $f1 ];
do
f2=${line:j}
echo $f2 | grep -q '[^0-9]'
f3=$?
if [ $f3 -ge 1 ]; then
#this is number,output
echo $f2 >>s4.txt
echo $f2
break;
fi
let j=j+1
done
f0=""
done < s1.txt
7、列出以ab或xy开头的用户名
使用三剑客分别实现,先看grep
方法1
egrep "^ab|^xy" /etc/passwd|cut -d: -f1
再看awk
方法2
awk -F ":" '{if(substr($1,1,2) == "ab" || substr($1,1,2) == "xy") print $1}' /etc/passwd
最后是sed
方法3
sed -n '/^ab|^xy/p' /etc/passwd | cut -d: -f1
8、列出当前目录下的所有目录
方法1:
ls -d */
方法2:
ls -F | grep "/$"
方法3:
ls -l | grep "^d"
方法4:
find -type -d -maxdepth 1 -print
9、将文件中按单词出现频率降序排序
文件名:readme简要思路:1.去除标点符号和数字2.以空格为分隔符,按行读取单词,一单词一行输出3.排序4.按单词计算出现次数5.按出现次数排序方法1:sed 's/[0-9.,<>//:()-]/ /g' readme |sed 's/\"//g' | awk '{for (i=1;i<=NF;i++){print $i;}}'|sort -r|uniq -c | sort -nr方法2:使用read line循环,按行处理并输出#!/bin/bash> tmp.txtwhile read linedo echo $line | sed 's/[0-9.,<>//:()-]/ /g' |sed 's/\"//g' | awk '{for (i=1;i<=NF;i++){print $i >> "tmp.txt";}}'done < readmecat tmp.txt | sort |uniq -c |sort -nr
10、已知随机数的md5值,反推原值
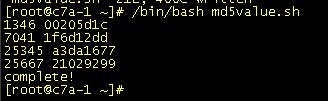
已知下面的字符串是通过RANDOM随机数变量md5sum|cut-c 1-8截取后的结果,反推这些字符串对应的md5sum前的RANDOM对应数字思路:已知random的范围(0-32767),通过遍历讲计算结果截取前8位与目标值做比对。(最差结果全部计算一遍并比对,得到结果)以下代码来自互联网,但做了改进。红色部分是修改修改过的部分。#!/bin/basha=(2102929900205d1ca3da16771f6d12dd)j=0for n in {0..32767} do random=`echo $n | md5sum | cut -c 1-8` for((i=0;i<=${#a[@]};i++)) do if [ "$random" == "${a[i]}" ];then echo "$n" "${a[i]}" let j++ fi done if [ $j -eq ${#a[@]} ]; then echo "complete!" break; fi done改进的部分说明:当4个结果已经对比成功后,之后的计算已经没有意义,应立即结束。
11、打印下面这句话中字母数不大于6的单词
打印下面这句话中字母数不大于6的单词。I am oldboy teacher welcome to oldboy training class.方法1:#!/bin/bashword6="I am oldboy teacher welcome to oldboy training class."echo $word6 | sed 's/\.//g' |awk -F " " '{for(i=1;i<NF;i++){if (length($i)<7) print $i; }}'方法2:#!/bin/bashword6="I am oldboy teacher welcome to oldboy training class."word6a=`echo $word6 | sed 's/\.//g'`for i in $word6ado if [ ${#i} -lt 7 ]; then echo $i fidone方法3:echo "I am oldboy teacher welcome to oldboy training class."|xargs -n1|awk '{if(length<7)print}'这段代码是来自互联网。其缺点是没有处理标点符号。
12、检查192.168.0.0.24网段内存在的IP
代码:#!/bin/baship=192.168.0.for i in {1..255} do ping -c 1 -w 2s $ip$i #-c 设置发送包 数量,-w 等待超时时间 if [ $? -eq 0 ]; then echo "$ip$i is ok" else echo "ip$j is null" fi done
13、分别以脚本传参以及read读入的方式比较大小
以read读入方式实现:#!/bin/bashfunction IsNumber(){ if [ -z $1 ]; then# echo "need var!" return 2 fi echo $1 | grep -q '[^0-9]'af1=$?if [ $af1 -ge 1 ]; then #this is number,output # echo "number" return 0else # echo "not number" return 1fi}read -p "please input a number:" x IsNumber $x #判断第一次输入是否是数字if [ $? -gt 0 ]; then echo "This is not number ,break #1 !" exit 1firead -p "please input another number:" yIsNumber $y #判断第二次输入是否是数字if [ $? -gt 0 ]; then echo "This is not number ,break #2 !" exit 1fiif [ $x -gt $y ]; then echo $x " >" $yelif [ $x -eq $y ]; then echo $x "=" $yelse echo $x "<" $yfi--------------------------以下是从互联网获得代码,与上面的代码功能一致------------------------------------------read -p "Please input two Number: " -a Arr_strecho ${Arr_str[*]} | grep -E "^[0-9 ]{1,}$" &>/dev/null || exit if [ ${#Arr_str[*]} -eq 2 ];then if [ ${Arr_str[0]} -eq ${Arr_str[1]} ];then echo "${Arr_str[0]} == ${Arr_str[1]}" elif [ ${Arr_str[0]} -gt ${Arr_str[1]} ];then echo "${Arr_str[0]} > ${Arr_str[1]}" else echo "${Arr_str[0]} < ${Arr_str[1]}" fi else echo "Please input two Number" fi此段代码read使用了数组接收输入数字,同样做了是否是数字的按断。-------------------------------------------------------------------------------------------------------------------------------------------以传参方式:#!/bin/bashfunction IsNumber(){ if [ -z $1 ]; then# echo "need var!" return 2 fi echo $1 | grep -q '[^0-9]'af1=$?if [ $af1 -ge 1 ]; then #this is number,output # echo "number" return 0else # echo "not number" return 1fi}#判断第一个参数是否存在if [ -z $1 ]; then echo "please number ,break #1 !" exit 1fiIsNumber $1 #判断第一个参数是否是数字if [ $? -gt 0 ]; then echo "This is not number ,break #1 !" exit 1fi#判断第二个参数是否存在if [ -z $2 ]; then echo "please another number ,break #2 !" exit 1fiIsNumber $2 #判断第二个参数是否是数字if [ $? -gt 0 ]; then echo "This is not number ,break #2 !" exit 1fix=$1y=$2if [ $x -gt $y ]; then echo $x " >" $yelif [ $x -eq $y ]; then echo $x "=" $yelse echo $x "<" $yfi--------------------------以下是从互联网获得代码,与上面的代码功能一致------------------------------------------#!/usr/bin/bash echo $1 | grep -E "^[0-9 ]{1,}$" &>/dev/null || exitecho $2 | grep -E "^[0-9 ]{1,}$" &>/dev/null || exit if [ $# -eq 2 ];then if [ $1 -eq $2 ];then echo "$1 == $2" elif [ $1 -gt $2 ];then echo "$1 > $2" else echo "$1 < $2" fi else echo "Please input two Number"fi-------------------------------------------------------------------------------------------------------------------------------------------本文重点总结:1.对输入参数的合理性判断,如是否输入,输入的是否是数字2.封装函数,重复利用代码3.条件语句if ,elif,else的用法4.逻辑条件判断5.read的用法
14、监控web站点目录下所有文件
web站点目录(/var/html/www)方法1:find /var/html/www -type f -name "*.sh"|xargs md5sum > ./a.log#以下是检查代码md5sum -c ./a.log | grep -v "OK"#以上代码来自互联网,略作改进方法2:ls -l /var/html/www > b1.log#以下是检查代码ls -l /var/html/www > b2.logcomm b1.log b2.log -3 |grep ".html"总结:方法1是利用了MD5对每个文件进行计算,然后以此作为基准,每次做相同计算比较差异。如果多出一个文件方法一无法发现。方法2利用文件初始的修改时间以及文件大小作为基准,每次作比较找出差异。如果多出一个文件,方法2可以发现。方法2对于修改间隔小于1分钟且字节数没有变化的无能为力。
15、模拟抓阄
要求:1、执行脚本后,想去的同学输入英文名字全拼,产生随机数01-99之间的数字,数字越大机会越大,前面已经抓到的数字,下次不能在出现相同数字。2、第一个输入名字后,屏幕输出信息,并将名字和数字记录到文件里,程序不能退出继续等待别的学生输入,抓完输入exit退出。3、倒序输出方法1:#!/bin/bash>chioce.txte="exit"x=""while [ $e == "exit" ]; do read -p "please input youname :" x grep "$x" chioce.txt if [ $? -eq 0 ]; then echo "$x already in namelist,can't input again!" continue; fi if [ $x == $e ]; then echo "game over!" e="" break; fi f=1 while [ $f -eq 1 ]; do y=$[RANDOM%99+1] grep "$y" chioce.txt if [ $? -gt 0 ];then f=0 break; fi done echo $y" "$x >> chioce.txt y=0 x="" echo "next input!"donesort -nr chioce.txt方法2:#!/usr/bin/bashdeclare -A arr while truedo [ "$Name" = "quit" ] && break read -p "Please input you name: " Name while true do Num=`echo $(($RANDOM%99+1))` if [[ $Num =~ ${arr[*]} ]];then continue else arr[$Name]=$Num echo "$Name" "$Num" break fi donedonefor j in ${!arr[*]}do echo $j " " ${arr[$j]} >> zhuajiu.txtdone sort -nr -k2 zhuajiu.txt|head -4 |column -t总结:方法1重点是如果重复的名称不会让再次输入一人一次机会,启动前情况目标文件,以确保只保存本次结果。方法2(来自互联网的代码)保证一人一次的方法是如果重复输入,那么第二次输入会覆盖第一次,略有不公平。
16、计算1到100累加之和
方法1:seq 100|awk '{i=i+$1}END{print i}'方法2:#!/bin/bashx=0for ((i=1;i<101;i++));do let x=x+idoneecho $x方法3:echo {1..100} | sed 's/ /+/g'|bc方法4:echo {1..100}| awk -F " " '{for(i=1;i<NF+1;i++){j=j+i;}print j;}'方法5:#!/bin/bashj=0for i in `seq 100` do let j=j+i doneecho $j方法6:(补充)seq 100 |echo $[ $(tr '\n' '+') 0 ]总结:方法1非常简洁,使用END关键字方法2使用了for循环,典型的程序员代码方法3数据源与方法1不同,特点是单行,使用sed转化为数学算式再交给bc命令计算方法4数据源与方法3已知,再awk内循环完成计算并输出方法5数据源与方法1类似方法6数据源与方法1一致,利用tr的字符替换形成加法算式。其还可以改写为如下:seq 100 |echo $(tr '\n' '+') 0 |bc
17、查找到3天前创建的html文件并删除
方法1:find ./ -type f -name "girl1*.html" -mtime -3 | xargs -i rm {};方法2:find ./ -type f -name "girl*.html" -mtime -3 -exec rm -rf {} \;总结:方法1是搜索完成后再执行rm方法2是找到1个就执行一次rm,类似循环-mtime是文件内容修改时间-atime是文件访问时间-ctime是文件属性修改时间
18、通过top获取指定进程cpu、内存等信息
脚本将通过top获取指定运行程序的cpu,内存,进程号,名称信息。按给定时间间隔循环取样,保存于process.txt内参数1是要获取的进程名称参数2是指定间隔时间(秒)代码:#!/bin/bashfunction IsNumber(){ if [ -z $1 ]; then# echo "need var!" return 2 fi echo $1 | grep -q '[^0-9]'af1=$?if [ $af1 -ge 1 ]; then #this is number,output # echo "number" return 0else # echo "not number" return 1fi}> process.txtif [ -z $1 ]; then read -p "please input process name:" x read -p "please input Interval(number):" yelse x=$1 if [ -z $2 ]; then read -p "please input Interval(number):" y else y=$2 fifiIsNumber $yif [ $? -gt 0 ]; then echo "Interval variable is not number ,default will be used !" echo "It is 2s!" y=2fiflag=5while sleep $y do top -d 2 -n 1 | awk -v var1=$x 'NR>6{if($13==var1)print $2 "\t" $10 "\t" $11 "\t" $13}' >> process.txt top -d 2 -n 1 | grep $x flagrun=$? echo flagrun $flag if [ $flagrun -gt 0 ]; then if [ $flag -eq 0 ]; then echo "process still is not running!will stop!"i break; fi echo "process is not running!will try $flag times !" let flag-- fi tail -3 process.txtdone说明:1参数1参数2可以运行脚本时给出,否则代码内按提示输入2.参数2如果输入错误不是数字,则按缺省值2执行3.参数1代表的进程如果检测不到,会提示并尝试5次,仍未检测到则退出运行
19、判断文件是否是设备文件
代码:#!/bin/bash if [ -z $1 ]; then read -p "please input device name:" xelse x=$1fiif [ -b $x -o -c $x ]; then echo "The $x is a device file!"else echo "The $x is not a device file!"fi
20、统计access。log访问ip和url
版权分析apache访问日志,找出访问页面数量在前10位的IP数和访问量前10的urlip统计:awk -F " " '{print $1}' access.log | sort |uniq -c |sort -nr | head -10url统计:awk -F " " '{print $7}' access.log | sort |uniq -c |sort -nr | head -10
21、打印当前sshd的端口和进程id
方法1:ss -lntp | grep “sshd” | head -1 |awk '{print $4 " " $NF}'| awk -F "[: =,]" '{print "port:"$1 " pid:"$6 }'方法2: ss -lntp |grep "sshd" |tail -1 | sed 's/^LI.*\:::[0−9]∗[0−9]∗.*"sshd",pid=[0−9]∗[0−9]∗.*))$/port:\1 pid:\2/g'总结:1.因为有ipV4和ipV6两个地址监听,取一个作为提取样本即可。方法一用了ipV4,方法2用了ipV62.方法1使用awk,其取列非常便利,本例使用多种分隔符,快速获得相关列。3.方法2使用sed,需要正则匹配,比方法1难些。其中取端口号遇到一个小问题,第一个数字方括号后*会无法匹配多个数字。经反复测试,*后面需要加空格。数字后有空格的情况以后要注意这个细节。pid取值数字后面是逗号则*直接可用。
22、获得8位随机数
方法1: top -n 1 -d 1 | md5sum|cksum|cut -c 1-8 或者 top -n 1 -d 1 |cksum|cut -c 1-8结果如下图:方法2:echo $RANDOM |cksum |cut -c 1-8方法3:openssl rand -base64 4 |cksum |cut -c 1-8方法4: date +%N |cut -c 1-8总结:本例原理是获得随机生成的字符串,在通过cksum获得足够位数的数字方法1利用的是系统运行状态是不停变化的特性方法2利用 $RANDOM 这个变量,它可以随机生成 0~32767之间的整数数字方法3利用openssl,这个需要系统必须安装openssl方法4利用date函数输出纳秒获得随机数,也就是利用时间的变化

23、获取cpu信息
脚本提取cpu运行信息,使用率超过30%输出警告。#!/bin/bashr=1while [ $r -eq 1 ]; docpuinfo=$(vmstat | tail -1|awk '{print $13 " " $14 " " $15 " " $16}')us=$(echo $cpuinfo | awk '{print $1}')sy=$(echo $cpuinfo | awk '{print $2}')id=$(echo $cpuinfo | awk '{print $3}')wa=$(echo $cpuinfo | awk '{print $4}')t=$(date +%F" "%H:%M:%S)let total=us+syif [ $total -ge 30 ]; then echo $t " cpu alert:"$total >> ./cpualert.logfi echo $t " us:"$us " sy:"$sy " id:"$id " wa:"$wa >> cpuinfo.logsleep 10done总结说明:1.脚本执行后循环往复执行,间隔10秒2.非报警信息和报警信息分别存储3.需要利用vmstat获取cpu信息,脚本未做软件安装包检测。(稍后单独编写这一功能)4.vmstat关于cpu输出说明如下: us: 用户进程执行时间(user time) sy: 系统进程执行时间(system time) id: 空闲时间(包括IO等待时间),中央处理器的空闲时间 。以百分比表示。 wa: 等待IO时间
24、检查软件是否安装
代码:#!/bin/bashif [ -z $1 ]; then echo "neec software name" read -p "please software name:" softnameelse softname=$1fiif [ $(whereis $softname) == $softname":" ]; then echo "$softname is not installed"else echo "sysstat is installed"fi 总结:本例使用whereis来判断软件是否安装。网上有使用rpm来判断的,但是如果是编译安装,那么会检测不到。
25、判断输入参数是ip地址
方法1:#!/bin/bashif [ -z $1 ]; then read -p "please input ip:" xelse x=$1fiecho $xr=0r=$(echo $x| awk -F "." '{if ($1<256 && $1>=0 && $2<256 && $2 >=0 && $3<256 && $3>=0 && $4<256 && $4>=0){print "0"} else {print "1"}}')echo $r方法2(来自互联网): IP=$1 VALID_CHECK=$(echo $IP|awk -F. '$1<=255&&$2<=255&&$3<=255&&$4<=255{print "yes"}') if echo $IP|grep -E "^[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}$">/dev/null; then if [ $VALID_CHECK == "yes" ]; then echo "$IP available." else echo "$IP not available!" fi else echo "Format error!" fi总结:1.IP地址(v4)特征是以“.”为分隔,一共4段,均为0-255之间的数字2.方法1使用awk获取数字并判断数字的属于0-255之间。其对错误的输入,比如负数、小数、字母或其他字符都按错误处理 方法1的awk部分还可以写成如下:awk -F "." '{if ($1>255 || $1<0){print "1"} else if ($2>255 || $2<0){print "1"} else if ($3>255 || $3<0){print "1"}else if ($4>255 || $4<0){print "1"}else {print "0"}}'3.方法2使用awk以“.”为分隔的4段数据做判断小于等于255,配合grep判断其4段数据为4个3位数以内的整数。补充:没想到不到一天有这么多浏览,必须得努力提高质量。今天把方法1修改为一个函数形式,如下:chkip(){ r=$(echo $1 | awk '/[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}/{print "ok"}') echo $r if [ -z $r ]; then r=2 else r=$(echo $1| awk -F "." '{if ($1<256 && $1>=0 && $2<256 && $2 >=0 && $3<256 && $3>=0 && $4<256 && $4>=0){print 0} else {print 1}}') fi return $r}
26、编写一个nginx服务脚本
脚本可以启动服务、关闭服务、重启服务、查看版本、测试配置文件代码:#!/bin/bashscriptname=$(echo $0 | awk -F "/" '{print $2}')function chkservice(){ PORT_C=$(ss -anu |grep -c $2) PS_C=$(ps -ef |grep $1 |grep -vc grep) if [ $PORT_C -eq 0 -o $PS_C -eq 0 ]; then r=1 else r=0 fi return $r} nginxcmd=/usr/local/nginx/sbin/nginxnginxconfopt="/usr/local/nginx/conf/nginx.conf"nginxtestconf=" -t"nginxstopopt=" -s stop"nginxrestartopt=" -s reload"nginxversion=" -v"if [ -z $1 ]; then echo "please input option:start|stop|restart|test|version"; exit 1fiif [ -f $nginxcmd ]; then echo "command ready..."else echo "nginx command is not exit!" exit 1fiif [ -f $nginxconfopt ]; then echo "configure file reday..."else echo "not found $nginxconf" exit 1fichkservice nginx 80r=$?case $1 in start|begin) if [ $r -eq 1 ]; then echo $nginxcmd "-c" $nginxconfopt|bash else echo "nginx servie already run!" fi ;; stop|end) if [ $r -eq 0 ]; then echo $nginxcmd $nginxstopopt|bash else echo "nginx service not found!" fi ;; restart|reload) echo $nginxcmd $nginxrestartopt|bash ;; test) echo $nginxcmd $nginxtestconf|bash ;; version) echo $nginxcmd $nginxversion|bash ;; *) echo "please input option:start|stop|restart|testi|version"; ;;esac
27、检查url
代码如下:chkinst(){if [ -z $1 ]; then echo "neec software name" return 2else softname=$1fix1=$softname":"x2=$(whereis $softname)if [ "$x2" == "$x1" ]; then #echo "$softname is not installed" return 1else #echo "sysstat is installed" return 0fi }check_url() { HTTP_CODE=$(curl -o /dev/null --connect-timeout 3 -s -w "%{http_code}" $1) if [ $HTTP_CODE -ne 200 ]; then # echo "Warning: $1 Access failure!" r=1 else # echo "url is right!" r=0 fi return $r}check_url2() {if ! wget -T 10 --tries=1 --spider $1 >/dev/null 2>&1; then #-T超时时间,--tries尝试1次,--spider爬虫模式 # echo "Warning: $1 Access failure!" r=1 else r=0 fi return $r}chk_url(){ chkinst curl x1=$?#echo $x1 if [ $x1 -eq 0 ]; then check_url $1 r=$? else chkinst wget x2=$?#echo $x2 if [ $x2 -eq 0 ]; then check_url2 $1 r=$? else r=3 fi fi return $r}#以下是代码执行获得url检测结果chk_url www.baidu.comecho $? #结果输出0,代表正常chk_url xxx.baidu.com #结果输出1,代表url不正常总结说明:本例编写了4个函数,分别是chkinst()、check_url()、check_url2()、chk_url()chkinst()是检查软件是否安装check_url()是使用curl检查url,源码来自互联网check_url2()是使用wget检查url,源码来自互联网chk_url()是的作用是封装整合,它先检查curl是否安装,如果安装了则调用check_url来检测url;否则检查wget是否安装,如果是则调用check_url2()检测url;否则返回非零值并退出函数。
28、生成随机8位字串
方法1:date +%N | md5sum | cut -c 1-8方法2:top -d 1 -n 1 | md5sum | cut -c 1-8方法3:echo $RANDOM | md5sum | cut -c 1-8方法4:openssl rand base64 4 | md5sum | cut -c 1-8本例跟二十二的随机数类似,不做更多说明
29、大小写字母转换
方法1:大写转小写x="flowFee" echo $x | tr 'A-Z' 'a-z'小写转大写echo $x | tr 'a-z' 'A-Z'方法2:小写转大写echo $x | tr '[:lower:]' '[:upper:]' 小写转大写echo $x | tr '[:upper:]' '[:lower:]'方法3:小写转大写echo "this a test" | sed y/abcdefghijklmnopqrstuvwxyz/ABCDEFGHIJKLMNOPQRSTUVWXYZ/大写转小写echo "this a test" | sed y/ABCDEFGHIJKLMNOPQRSTUVWXYZ//abcdefghijklmnopqrstuvwxyz总结:类似的功能可以实现任意对应字符相互转换,可以实现简单的密码加密和解密功能。方法4:(补)文件1.txt内容转小写字母到1a.txtdd if=1.txt of=1a.txt conv=lcase 文件1.txt内容转大写字母到1a.txtdd if=1.txt of=1a.txt conv=Ucase
30、去除字符串中多余的 空格
去除字符串中多余的 空格,多个空格合并为1个方法1:echo "1 2 3 4 5" | sed 's/ */ /g'方法2:echo "1 2 3 4 5" | tr -s " "
31、删除字符串中的字母或数字
删除字母方法1:echo "a1b2c3d4f5" | tr -d 'a-z'方法2:echo "a1b2c3d4f5" | sed 's/[a-z]*//g'方法3:echo "a1b2c3d4f5" | tr -d -c '[0-9]'这个方法利用tr -c删除补集的功能,如有其他字符泽不能用这个方法
32、生成文件名包含当天日期
生成文件规则如下:以大写T开头+当天日子+后缀(.log)代码如下:方法1:touch T( d a t e + 方 法 2 : t o u c h T (date +%F).log 方法2: touch T(date+方法2:touchT(date +%Y%m%d).log注:1.方法1日期含有“-”作为分隔符,方法2没有日期分隔符2.另外touch命令也可以使用echo “” > 这一命令代替
33、把一个文本文件行和列转置
即行变为列,列变为行。每行的列以空格分隔,且每行列数相等例如:源文件log5.txt内容no name age sexx1 alice 21 fx2 jack 30 mx3 tom 22 mx4 xxx 19 f代码如下:方法1:#!/bin/basha=1while read linedo var=($line) x=${#var[*]} for ((j=0;j<x;j++));do echo ${var[$j]} >> ${j}.txt done let a=a+1 done < log5.txtfor ((m=0;m<x;m++));do cat "${m}.txt" | tr "\n" " " echo -e "\n"done执行结果:no x1 x2 x3 x4 name alice jack tom xxx age 21 30 22 19 sex f m m f 总结:基本思路是按行读取内容,每列按顺序存入有序号的文件中。循环结束,同列内容已经存入形同文件。再进行一次循环,按顺序读取文件,并将文件内容转化为1行输出,最后添加换行符。循环将文件顺序输出。本例用到了循环、数组、分解字符串等技巧。今天状态欠佳,代码写的时间长也并非最佳方案。失败的一天。后补:输出部分还可以按如下方法实现:方法1a:combine="paste -d \" \" "for ((m=0;m<x;m++));do combine=$combine" "${m}.txtdoneecho $combine |bash这里用了之前的技巧中没有使用过的paste命令方法1b:awk也可以实现,不过只能同时操作2个文件,所以还需耍个小技巧。cat 0.txt > t1.txtfor ((m=1;m<x;m++));do let n=m+1 awk 'NR==FNR{a[NR]=$0}NR>FNR{print a[FNR],$0}' t${m}.txt ${m}.txt > t${n}.txtdonecat t${n}.txtawk将两个文件顺序处理,处理第一个文件时将每一行写入a数组,处理第二个文件时NR会大于FNR,此时打印数组a和第二个文件的当前行。因为文件行数一样,所以达成预定效果。方法2:来自互联网的代码,使用awk完成awk '{ for (i=1;i<=NF;i++){ if (NR==1){ res[i]=$i } else{ res[i]=res[i]" "$i } }}END{ for(j=1;j<=NF;j++){ print res[j] }}' log5.txt说明:当处理第一行时用数组存储每一个列值;从第二行开始,列值追加在数组后,中间加空格。方法3:依旧使用循环,但不使用文件仅使用变量实现#!/bin/basha=1while read linedo var=($line) x=${#var[*]} if [ $a -eq 0 ];then var1=($line) else for ((j=0;j<x;j++));do# echo $j var1[j]=${var1[j]}" "${var[$j]} done fi let a=a+1 done < log5.txt#t=$(cat log5.txt |wc -l )#echo $tfor ((m=0;m<x;m++));do echo ${var1[m]}done
34、只输出文件第5行
文件名为t.txt方法1:sed -n '5p' t.xtx方法2:awk 'NR==5{print $0}' t.txt方法3: head -5 t.txt |tail -1方法4:i=1while read line;doif [ $i -eq 5 ]; then echo $line break;let i=i+1done < t.txt方法5:sed -n '5m5p' t.txt本例比较简单。不同的方考察各命令的熟悉程度以及思考方向。
35、模拟爬虫获取页面中的文章链接
以某博客https://blog.51cto.com/oldboy为目标进行抓取为了稳定数据源,先使用curl将抓取目标页面存于本地curl -s https://blog.51cto.com/oldboy -o oldboy.html代码: 总结:基本思路就是分析页面内容的特征。改页面文章列表部分内容如下:这里只打算获得文章发布时间、文章标题以及链接。发布时间行找出特征字符串,clase="time f1"其后的第4-5行是标题和链接。这里偷了个懒直接获得发布时间行以及之后的5行内容。单独去抓标题和链接的行也是可以。比如:grep -A 1 -E "^.*class=\"tit\"" oldboy.html

36、输出字符串第5个字符以及之后的字符
字符串:12345abcdefg代码:方法1:echo "12345abcdefg" | cut -c 5-方法2:#!/bin/basha="12345abcdefg"echo ${a:4}方法2的还可以改为如下:#!/bin/basha="12345abcdefg"let b=${#a}-5echo ${a:4:${b}}echo ${b}方法3:echo "12345abcdefg" | awk '{print substr($0,5)}'方法4:echo "12345abcdefg" | sed 's/^.....∗$.∗$/\1/g'或 echo "12345abcdefg" | sed 's/........//g'
37、显示主机的主要信息
编写脚本/root/bin/systeminfo.sh,显示当前主机系统信息,包括主机名,IPv4地址,操作系统版本,内核版本, CPU型号,内存大小,硬盘大小。代码如下:#!/bin/bash#hostnamemyhostname=$(hostname)echo "Host Name:" $myhostname#ip address$IP=$(ip addr |grep -A 2 -E "^2: "| tail -1|tr -s " "|awk -F "[/ ]+" '{print $3}')#osOSname=$(cat /etc/centos-release)echo "OS Name: " $OSname#coreCoreversion=$(uname -r)echo "Core Version:" $Coreversion#cpucpumodel=$(lscpu |grep "Model name" | awk -F ":" '{print $2}' | tr -s " ")echo "CPU model: " $cpumodel#memmemsize=$(free -h | awk 'NR==2{print $2}')echo "Memory Size: " $memsize#hard diskdisksize=$(cat /proc/partitions | awk 'NR==3{print $3}')echo "HardDisk Size: " $disksize总结:本例看着挺热闹,其实超简单。无非就是考察获取各个信息的命令。涉及的命令如下:主机名:hostname;其实用uname也可以,使用uname -a列出所有主机信息,主机名在第二列IPv4地址:代码中用的是ip addr;老版本系统一般用ifconfig 之前谢过获取IP地址的例子,这里用了不同的技巧,有兴趣可以看看前例。操作系统:直接读取/etc/centos-release文件,如果是Debian系统读取 /etc/debian_version;Debian的uname -a命令也可以。内核系统:uname -rcpu型号:lscpu命令;直接读取/proc/cpuinfo文件也可以内存:free -h命令;直接读取/proc/meminfo也可以硬盘:读取直接/proc/partitions文件(因为我只有一块硬盘,这里偷懒了,应该判断一下有几块硬盘);df 命令也可以,不过需要自己计算一下。

38、计算一个文件中空行数量
方法1:grep -E ^$ 1.txt | wc -lgrep '^$' 1.txt | wc -l方法2:file="1.txt"sed -n '/^$/p' 1.txt | wc -l方法3:awk '/^$/' 1.txt | wc -l或者awk '/^$/{print $0}' 1.txt | wc -l或者awk '$0~/^$/{print $0}' 1.txt | wc -lawk 三种写法效果一样。总结:本例关键是正则表达式对空行判断的写法。
39、统计当前目录下一级子目录数量
方法1:ls -al |grep -E "^d" |grep -v "\.$" |wc -l方法2:find -maxdepth 1 -type d |grep -v "^.$"如果统计到2级目录-maxdepth参数修改为2
40、编写一个修改用户密码的脚本
脚本提示输入用户名,和密码。如果用户存在则提示用户输入密码(密码要求重复输入2次一致密码)#!/bin/bashflag=1while [ $flag -eq 1 ];doread -p "please input name:" Tusernameckusername=$(grep "${Tusername}:" /etc/passwd | wc -l)if [ $ckusername -eq 0 ]; then echo $Tusername " was not found!"else break;fidonewhile [ $flag -eq 1 ];do read -s -p "please input password:" p1 read -s -p "please input password again:" p2 if [ $p1 == $p2 ];then break; else echo "first input and sencond input are not same" fidoneecho $p1 | passwd allenle --stdin总结:一个passwd接受标准输入修改密码的技巧另外就是read输入和while循环的使用,这个之前的例子出现过
41、列出当前用户最近使用最多的10个命令
代码:history | awk '{print $2}'|sort|uniq -c|sort -rn |head -10
42、显示正连接本主机的每个远 程主机的IPv4地址和连接数
显示正连接本主机的每个远 程主机的IPv4地址和连接数,并按连接数从大到小排序代码ss -nt | tr -s " "|grep -v "::ffff"|grep -v "Local"|awk -F "[ :]+" '{print $4}'| sort -n | uniq -c
43、用户登录管理(禁止或恢复登录)
脚本接受参数,恢复或者禁止指定用户登录代码:#!/bin/bashif [ -z $1 ]; then echo "please input e or d.e is enable,d is disable!" exit 1elif [ $1 == "e" ] || [ $1 == "d" ]; then act=$1else echo "input error!please input e or d.e is enable,d is disable!" echo $1 exit 1fiif [ -z $2 ]; then echo "please input one username" exit 1else username=$2fij=$(grep ${username}":" /etc/passwd|wc -l)u=$(egrep "^${username}:" /etc/passwd|cut -d ":" -f3)#echo $u#exit 0if [ $j -eq 0 ]; then echo "user not exist!" exit 1else if [ $u -eq 0 ]; then echo "please input another username!" exit 1 else if [ $act == "d" ]; then echo $username " can not login" usermod -s /usr/sbin/nologin $username elif [ $act == "e" ]; then echo $username "can login" usermod -s /bin/bash $username fi fifi
44、判断文本行中有电话号码
文本中合理的电话号码格式如下:987-123-4567123 456 7890(123) 456-7890代码:方法1:sed -n '/[1-9][0-9][0-9][- )][ ]*[1-9][0-9][0-9][- ][0-9][0-9][0-9][0-9]/p' phone.txt 方法2:grep -E "[1-9][0-9]{2}[- )]{1,2}[1-9][0-9]{2}[- ][0-9]{4}" phone.txt 方法3:awk '/[1-9][0-9]{2}[- )]{1,2}[1-9][0-9]{2}[- ][0-9]{4}/' phone.txt
45、检查输入串的合法性
要求:由大小写字母、数字组成,无标点、特殊符号、空格方法1:echo "edafa32324A " | grep -E "^[a-zA-Z0-9]$"方法2:echo "edafa32324A" | sed -n '/^[a-zA-Z0-9]*$/p'方法3:echo "edafa3232 4A" | awk '/^[a-zA-Z0-9]*$/'
46、删除文件指定行和行部分内容
把一个文档前五行中包含字母的行删掉,同时删除6到10行包含的所有字母测试文件内容类似:1fffff222222234545-=-934aaaAa555555~#$%6dfd4447545454dfsdf88888889999999A10erewr11gdfgfd8881256456dgfd代码:方法1:#!/bin/bashsum=$(cat ./txt/delchar.txt | wc -l)echo total:${sum}head -5 ./txt/delchar.txt | sed '/[a-zA-Z]/d' > ./txt/delchar1.txthead -10 ./txt/delchar.txt | tail -5 | sed 's/[a-zA-Z]//g' >> ./txt/delchar1.txtlet lastpart=sum-10tail -${lastpart} ./txt/delchar.txt >> ./txt/delchar1.txt 方法2:#!/bin/bash> ./txt/delchar2.txti=1while read linedoif [ $i -le 5 ]; then echo $line |sed '/[a-zA-Z]/d' >> ./txt/delchar2.txtelif [ $i -le 10 ] && [ $i -gt 5 ]; then echo $line echo $line |sed 's/[a-zA-Z]//g' >> ./txt/delchar2.txtelse echo $line >> ./txt/delchar2.txtfilet i=i+1done < ./txt/delchar.txt
47、用shell打印示例语句中字母数小于6的单词
用shell打印示例语句中字母数小于6的单词Bash also interprets a number of multi-character代码:echo "Bash also interprets a number of multi-character" | awk '{for(i=1;i<=NF;i++){if(length($i)<6){print $i}}}'
48、屏蔽请求量异常的IP
根据web访问日志,封禁请求量异常的IP,如IP在半小时后恢复正常,则解除封禁规则:之前1分钟内访问的ip次数大于100时禁止访问;30分钟后解封代码: #!/bin/bashgrep $(date -d "1 minute ago" +%d/%b/%Y:%H:%M) /usr/local/nginx/logs/access.log | awk {'print $1'} |sort|uniq -c| awk '{if($1>100){print $2}}' > "iplist.txt"while read line;do iptables -I INPUT -p tcp -s $line -j DROP echo $(date +%s) " " $line >> "disiplist.txt"done < iplist.txt#以下是解封n=$(date +%s)icount=0while read line;do t=$(echo $line | cut -d " " -f1) ip=$(echo $line | cut -d " " -f2) echo $ip let x=n-t if [ $x -gt 1800 ]; then es=$(iptables -L INPUT --line-numbers | grep $ip | wc -l) if [ $es -gt 0 ]; then en=$(iptables -L INPUT --line-numbers | grep $ip | head -1| cut -d " " -f1) echo $en iptables -D INPUT $en let ii=ii+1 fi fidone < disiplist.txt#echo $ii if [ $ii -gt 0 ]; then sed -i "1,${ii}d" disiplist.txtfi
49、画一个菱形

代码:#!/bin/bashsource ./afunction.sh#i定义菱形最宽部分为7个字符i=7j=1#is2是自定义函数,用于判断奇数偶数is2 $im=$?if [ $m -eq 1 ] && [ $i -gt 1 ]; then let x=$i-1 let y=$x/2 while [ $j -le $i ]; do line="" k=1 is2 $j n=$? if [ $n -eq 0 ]; then echo " " echo " " else let kk=($i-$j)/2 let kkk=$kk+$j while [ $k -le $i ];do if [ $k -le $kk ]; then echo -n " " elif [ $k -gt $kk ] && [ $k -le $kkk ]; then echo -n "x" else echo -n " " fi let k=k+1 done #echo '\n' fi let j=j+1 donefiecho " "echo " "#以下是画下半部分let j=$i-2while [ $j -ge 1 ]; do line="" k=1 is2 $j n=$? if [ $n -eq 0 ]; then echo " " echo " " else let kk=($i-$j)/2 let kkk=$kk+$j while [ $k -le $i ];do if [ $k -le $kk ]; then echo -n " " elif [ $k -gt $kk ] && [ $k -le $kkk ]; then echo -n "x" else echo -n " " fi let k=k+1 done #echo '\n' fi let j=j-1doneecho " "
50、打印100以内被3整除的数
打印100以内被3整除的数输出要求每行输出9个数,每行每列对齐代码:#!/bin/bash#设定被除数是3i=3#设定一个变量记录行输出列的数量,等于10时换行,重置为1j=1while [ $i -le 100 ]; do if [ $(($i%3)) -eq 0 ]; then if [ $i -lt 10 ]; then echo -n "0" fi echo -n $i echo -n " " let j=j+1 fi if [ $j -eq 10 ]; then j=1 echo " " fi let i=i+1doneecho " "
51、打印100以内的素数
输出100以内的素数每行输出5个代码:#!/bin/bashi=2j=2k=1while [ $i -le 100 ]; do while [ $j -le $i ]; do if [ $(($i%$j)) -eq 0 ] && [ $j -lt $i ] ; then break; elif [ $(($i%$j)) -eq 0 ] && [ $j -eq $i ] ; then if [ $i -lt 10 ]; then echo -n "0" fi echo -n $i echo -n " " let k=k+1 fi let j=j+1 if [ $k -eq 5 ]; then k=1 echo " " fi done j=2 let i=i+1doneecho " "总结:本例与之前的一例类似,但逻辑有变化。是找出不能被自身和1整除的数
52、输出文件每行第10个字符之后不包含51的行
文件内容:1234567890xy51dd1234567890xy52dd123456789510xy53dd1234567890xy51dd1234567890xy15dd1234567890xy51dd1234517890xy22dd123456ss7890xy51dd方法1:grep -v ".\{10\}51" ./txt/x1.log方法2:sed '/^.\{10\}.*51.*$/d' ./txt/x1.log 方法3:awk '$0 !~/.{10}.+51/' ./txt/x1.log 本例依然是对三剑客用法的练习。
53、测试“/root/docker/nginx”及其父目录是否存在
代码:#!/bin/bashdir=$1dir1=${dir%/*}if [ -d $dir1 ]; then echo $dir1 " Yes #1 " if [ -d $dir ]; then echo $dir " Yes #2" else echo $dir " No #2" fielse echo $dir1 " No #1 "fi
54、测试某文件是否有执行权限
测试/etc/profile和/root/t1.sh是否有执行权限代码:方法1:#!/bin/bashif [ -x /etc/profile ]; then echo " Yes x mode - /etc/profile"else echo " No x mode - /etc/profile"fi if [ -x ./t1.sh ]; then echo " Yes x mode - t1.sh "else echo " No x mode - t1.sh!!!"fi结果如下图:方法2:#!/bin/bashx1=$(ls -l /etc/profile | awk '{print $1}'|grep "x"|wc -l)if [ $x1 -gt 0 ]; then echo "Yes x modx - /etc/profile"else echo "No x modx - /etc/profile"fi x2=$(ls -l /root/t1.sh | awk '{print $1}'|grep "x"|wc -l)if [ $x2 -gt 0 ]; then echo " Yes x modx - /root/t1.sh"else echo "No x modx - /root/t1.sh"fi总结:方法1利用shell的“-x”逻辑判断方法确定文件存在且执行方法1利用ls -l命令输出关于权限的内容进行判断。虽然未进行判断文件是否存在,但输出的错误提示被awk截取第一字段内容不包含x,所以判断结果也是正确的。

55、使用高斯算法计算累加之和
高斯算法如下:#/bin/bashsource ./afunction.shif [ -z $1 ]; then echo "please input number !Now will be exit!" exit 1fix=$1IsNumber $xr=$?if [ $r -gt 0 ]; then echo "please input number !Now will be exit!!" exit 1fiis2 $xy=$?if [ $y -eq 0 ];then m=0 k=0else m=1 k=xfilet n=(x-m)/2let sum=(x-m+1)*n+kecho $xecho $necho "Result : " $sum
56、统计/etc下*.conf文件大小总和
/etc下后缀为conf的文件,大小总和代码:方法1:find /etc -name "*.conf" -exec ls -l {} \; | awk '{i=i+$5}END{print i}'方法2:find /etc -name "*.conf" -exec ls -l {} \; | awk '{print $5}'| echo $[$(tr '\n' '+')0]方法3:find /etc -name "*.conf" -exec ls -l {} \; | awk '{print $5}'|echo $[$(sed 's/^.∗.∗$/\1+/g') 0]
57、打印乘法口诀表
代码:#!/bin/bashfor i in {1..9}do j=1 while [ $j -le $i ];do let x=j*i echo -ne $j "*" $i "=" $x "\t" let j=j+1 done echo " "done
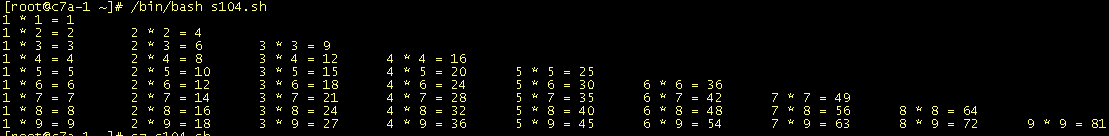
另一种写法(内循环固定9次,判断内循环数小于等于外循环数才执行计算和输出)#!/bin/bash#99乘法表for i in {1..9}do for j in {1..9} do if [ $j -le $i ]; then echo -ne "$j*$i=" echo -ne $(($i*$j))"\t" fi done echo " "done
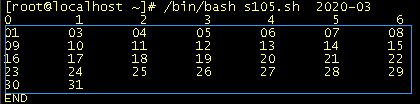
58、打印任意月的日历
输入参数如:2020-03输出2020年3月的日历。第一行为周,第二行开始为日期代码:#!/bin/bashecho -e "0 \t 1 \t 2 \t 3 \t 4 \t 5 \t 6 \t"i=0ds=1inputvar=$1d=$inputvar"-01"dd=$(date -d $d +%w)ddx=$(date -d $d +%d)mm=$(date -d $d +%m) if [ $i -lt $dd ]; then while [ $i -lt $dd ]; do echo -en " \t" let i=i+1 donefij=$ddwhile [ $j -lt 7 ]; do echo -en $ddx "\t" let j=j+1 let ds=ds+1 if [ $j -eq 7 ]; then echo " " j=0 fi mmx=$(date -d "$d $ds day" +%m) if [ $mmx -ne $mm ]; then break; fi ddx=$(date -d "$d $ds day" +%d)doneecho " "echo "END"总结:本例处理格式术除外,重点是date命令的使用
59、计算100以内偶数和(三种算法)
#!/bin/bash#方法1,步进为2,起始位偶数2i=2s=0while [ $i -le 100 ]; do let s=s+i let i=i+2doneecho "This is fisrt ..."echo "Total:"$s#方法2,步进1,需要判断是偶数echo "This is second ..."k=1s2=0for((j=1;j<=100;j++));do k=$((j%2)) if [ $k -eq 0 ]; then let s2=s2+j fidoneecho "Total:"$s2#方法3,类似高斯算法echo "This is third ..."s3=0let k=100/4let s3=(100+2)*kecho "Total:"$s3
60、MySQL备份实例脚本
要求:1.按时备份MySQL指定数据库。2.将备份数据恢复到指定MySQL实例备用3.将备份数据文件压缩,源文件删除4.删除超过10日以上的备份文件(压缩后的)代码:#!/bin/sh#-----startdbuser="bitchicken"dpwd="12345678"dbname="chickens"dbhost="rr-uf6ccxa6393236y3u.mysql.rds.aliyuncs.com"backupdir="/newdisk2" #备份数据文件存放目录time="$(date +"%d-%m-%y-%H")" #获得日期时间字符串,精确到小时weekday=`date +%w`MYSQLDUMP="/usr/bin/mysqldump" #备份命令,全路径GZIP="/bin/gzip" #压缩命令,全路径$MYSQLDUMP -h$dbhost -u$dbuser -p$dpwd $dbname > "$backupdir/$time.$dbname"#--------endfind /newdisk2/chickens -type f -mtime +10 -delete #删除存在超过10天的文件,注意执行路径是备份文件存放目录#Monday to Fridayif [ $weekday -ge 1 ] && [ $weekday -le 5 ];then mysql -uallenle -p1qaz2wsx chickes_report < "$backupdir/$time.$dbname"fi#$Saturdayif [ $weekday -eq 6 ];then mysql -uallenle -p1qaz2wsx chickens0616 < "$backupdir/$time.$dbname"fi#Sundayif [ $weekday -eq 0 ];then mysql -uallenle -p1qaz2wsx chickens0617 < "$backupdir/$time.$dbname"fi#实战中因为数据库命名不是全部都有规则,因此使用了多个if来实现恢复数据到指定数据库GZIP "$backupdir/$time.$dbname" #压缩,如果要分卷压缩,可以使用rar或者zip,这需要单独安装对应软件
61、查看root用户定时任务执行情况
要求:1.输出1天(指定)时间内的数据,比如输入0代表当前(或不带参数),1代表昨天,2代表前天以此类推2.输出数据中心执行的命令和执行次数代码:#!/bin/bashfunction IsNumber(){ if [ -z $1 ]; then# echo "need var!" return 2 fi echo $1 | grep -q '[^0-9]'af1=$?if [ $af1 -ge 1 ]; then #this is number,output # echo "number" return 0else # echo "not number" return 1fi}if [ -z $1 ]; then d=0else d=$1fi IsNumber $dr=$?if [ $r -ne 0 ]; then d=0fiif [ $d -lt 0 ]; then d=0filet ed=-1*d+1xd=$(date -d "$ed day" | awk '{print $2 " " $3}')#echo $xd#exit 0egrep "$xd" "/var/log/cron" |grep "root" | awk '{print $NF}'| grep -v '(root)' | sed 's/)//g'|sort|uniq -c
62、一个二分法的实现
二分法是一种快速收敛的算法。在一个有序数组中,将其分为前后两组,要定位的数现在一组内判断是否在范围内;如果不在范围内,则在另一组进行判断;如果在范围内,再将这组分为2组,分别进行判断以此类推。最终能定位这个数在这个数组内应存在的位置或等值数的位置。下面就是用shell实现的一个例子。传入一个参数,代码内的数组有序,将输出参数在数组内的排序位置。#!/bin/bashk=$1array_var=(1 3 5 7 9 11 13 15 17 19 21 23 25)#echo echo ${#array_var[*]} " " ${array_var[*]}i=${#array_var[*]}#echo $ic=1#f=mt=1s1=0let j=i-1let e1=i-1let x=i/2#echo ${array_var[12]}#exit 0while [ $c -eq 1 ]; do if [ ${array_var[$x]} -eq $k ]; then echo "$x #0" echo $k "is eq " $x " site" break; elif [ ${array_var[$x]} -gt $k ];then e1=$x let y=e1-s1 if [ $y -eq 1 ]; then if [ ${array_var[$s1]} -ge $k ]; then echo ${array_var[$s1]} "--" ${array_var[$e1]} "#1" echo $k "is eq " ${s1} " site" else echo ${array_var[$s1]} "--" ${array_var[$e1]} "#2" echo $k "is eq " ${e1} " site" fi break; fi let x=s1+y/2 #f=l else s1=$x let y=e1-s1 if [ $y -eq 1 ]; then if [ ${array_var[$e1]} -ge $k ]; then echo ${array_var[$s1]} "--" ${array_var[$e1]} "#3" echo $k "is eq " ${e1} " site" else if [ $e1 -eq $j ]; then echo ${array_var[$s1]} "--" ${array_var[$e1]} "#4" echo $k "is more than $i site" else echo ${array_var[$s1]} "--" ${array_var[$e1]} "#5" echo $k "is eq " ${e1} " site" fi fi break; fi let x=s1+y/2 # f=r fi let t=t+1 done
63、冒泡排序
冒泡排序是一种逻辑简单的排序算法。上学的时候作为编程教材。算法描述1.比较相邻的元素。如果第一个比第二个大,就交换它们两个;2.对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;3.针对所有的元素重复以上的步骤,除了最后一个;4.重复步骤1~3,直到排序完成,即不再发生任何位置交换代码:#!/bin/bash#Bubble Sortarr=(22 18 5 11 17 23 50 78 30 61) #定义一个无序的数组arrtotal=${#arr[@]} #获得数组元素数量let lastone=arrtotal-1 #获得数组最大序号echo ${arr[@]} #输出数组,为何结果顺序比较用 echo "--->>>"flag=0 #一个标记,如果发生了顺序交换则复制0,代表需要再进行下一次循环while [ $flag -eq 0 ]; do for((i=0;i<lastone;i++)); do flag=1 s1=$i let s2=i+1 if [ ${arr[$s1]} -gt ${arr[$s2]} ]; then tmp=${arr[$s1]} arr[$s1]=${arr[$s2]} arr[$s2]=$tmp flag=0 fi done let lastone-- if [ $flag -eq 1 ]; then break; #终止循环,排序结束 fidoneecho ${arr[@]} #输出排序后的数组echo "END"
64、插入排序
插入排序(Insertion-Sort)的算法描述是一种简单直观的排序算法。算法描述:1.从第一个元素开始,该元素可以认为已经被排序(即一个有序数组只有一个元素);2.取出下一个元素,在已经排序的元素序列中从后向前扫描;3.如果该元素(已排序)大于新元素,将该元素移到下一位置;4.重复步骤3,直到找到已排序的元素小于或者等于新元素的位置;5.将新元素插入到该位置后;6.重复步骤2~5。代码:#!/bin/bash#insert sortarr=(22 18 5 11 17 23 50 78 30 61)echo ${arr[@]}echo "--->>>"s1=1#echo ${arr[$s1]}#exit 0arrtotal=${#arr[*]}let lastone=arrtotal-1while [ $s1 -le $lastone ]; do let s2=s1-1 s11=${s1} temp=${arr[$s1]}#echo $s1 ":" $s2#echo ${arr[$s1]}#echo ${arr[$s2]}#exit 0 while [ $s2 -ge 0 ]; do # echo $s1 ":"$s2# echo $temp# echo ${arr[$s2]}# echo "-----" if [ $temp -lt ${arr[$s2]} ]; then arr[$s11]=${arr[$s2]} arr[$s2]=$temp s11=$s2 # echo "####"else break; fi let s2=s2-1 done # if [ $s1 -eq 3 ]; then # break; # fi let s1=s1+1doneecho ${arr[@]}echo "END"
65、选择排序
选择排序(Selection-sort)是一种简单直观的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。本例是每次找到最小元素放到左侧。#!/bin/bash#Selection-sortarr=(22 18 5 11 17 23 50 78 30 61)arrtotal=${#arr[@]}let lastone=arrtotal-1echo ${arr[@]}echo "--->>>"i=0while [ $i -lt $arrtotal ] ; do tmpvalue=${arr[$i]}tmpsite=$ilet tmpnext=i+1 for((j=$tmpnext;j<$arrtotal;j++)); do if [ $tmpvalue -gt ${arr[$j]} ]; then tmpvalue=${arr[$j]} tmpsite=$j fidoneif [ $i -ne $tmpsite ];then temp=${arr[$i]} arr[$i]=${arr[$tmpsite]} arr[$tmpsite]=$tempfi let i=i+1doneecho ${arr[@]}echo "END"
66、选择排序改进版
本例对上一篇代码进行了改进。一次循环同时找到最小和最大两个元素放在最左和最右。循环收敛到数组中间位置完成排序。#!/bin/bash#Selection-sort 1arr=(101 0 35 27 90 87 99 51 6 33 37 28 62 90 111 222 333 550 22 18 5 11 17 23 50 78 30 61 9)arrtotal=${#arr[@]}let runend=(arrtotal)/2+1let lastone=arrtotal-1echo ${arr[@]}echo "--->>>"i=0ii=0tmpvaluemax=$arr[0]tmpsitemax=0while [ $i -lt $arrtotal ] ; do tmpvalue=${arr[$i]} tmpsite=$i tmpvaluemax=${arr[$i]} tmpsitemax=$i flagmax=0 let tmpnext=i+1 for((j=$tmpnext;j<$arrtotal;j++)); do if [ $tmpvalue -gt ${arr[$j]} ]; then tmpvalue=${arr[$j]} tmpsite=$j flagmax=1 fi if [ $tmpvaluemax -lt ${arr[$j]} ]; then tmpvaluemax=${arr[$j]} tmpsitemax=$j flagmax=1 fi let ii=ii+1 done #echo "$tmpvaluemax $tmpsitemax $lastone" if [ $i -ne $tmpsite ];then temp=${arr[$i]} arr[$i]=${arr[$tmpsite]} arr[$tmpsite]=$temp fi if [ ${arr[$tmpsitemax]} -gt ${arr[$lastone]} ];then tmpmax=${arr[$lastone]} arr[$lastone]=${arr[$tmpsitemax]} arr[$tmpsitemax]=$tmpmax let arrtotal=arrtotal-1 let lastone=lastone-1 fi let i=i+1 if [ $flagmax -eq 0 ]; then break; fi flagemax=0 if [ $i -gt $runend ]; then # echo $tmpsitemax break; fidoneecho ${arr[@]}echo "run loop:$i $ii"echo $tmpsitemaxecho "END"
67、快速排序
快速排序使用分治法来把一个串(list)分为两个子串(sub-lists)。具体算法描述如下:从数列中挑出一个元素,称为 “基准”(本例中使用了第一个元素作为基准);重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。#!/bin/basharr=(101 0 35 27 87 99 51 6 33 37 28 62 90 111 222 333 550 22 18 5 11 17 23 50 78 30 61)icount=0low0=0arrlen=${#arr[*]}let high0=arrlen-1function getIndex(){ s=$1 e=$2 tmp=${arr[$s]} f=2 while [ $s -lt $e ]; do if [ $f -eq 2 ]; then if [ $tmp -le ${arr[$e]} ]; then let e=e-1 elif [ $tmp -gt ${arr[$e]} ]; then arr[$s]=${arr[$e]} let s=s+1 f=1 fi else if [ $tmp -ge ${arr[$s]} ]; then let s=s+1 elif [ $tmp -lt ${arr[$s]} ]; then arr[$e]=${arr[$s]} let e=e-1 f=2 fi fi done arr[$s]=$tmp return $s}function quicksort(){ r[$icount]=0 low=$1 high=$2 let y0=high-low if [ $y0 -gt 1 ]; then getIndex $low $high x=$? let icount=icount+1 low1=$low let low2=x+1 let high1=x-1 high2=$high0 let y1=high1-low1 let y2=high2-low2 if [ $y1 -gt 1 ]; then quicksort $low1 $high1 elif [ $y1 -eq 1 ]; then tt=${arr[$low1]} ttt=${arr[$high1]} if [ $tt -gt $ttt ]; then arr[$low1]=$ttt arr[$high1]=$tt return 0 fi fi if [ $y2 -gt 0 ]; then quicksort $low2 $high2 elif [ $y2 -eq 1 ]; then tt=${arr[$low2]} ttt=${arr[$high2]} if [ $tt -gt $ttt ]; then arr[$low2]=$ttt arr[$high2]=$tt return 0 fi fi else return 0 fi}echo ${arr[@]}echo "--->>>"quicksort $low0 $high0echo ${arr[@]}echo "END"总结:本例与之前的冒泡排序、插入排序、选择排序不同,其使用递归方式获得所有元素的顺序。递归是本例的重点,也是难点。需要设定合理的终止条件,否则无法得到正确结果。调试过程中也花了很多时间,代码中遗留了一些无用的代码。另一个问题就是函数返回值和参数使用以及应用范围。这里给出本例实践结论:1.主程序中的变量,在函数中可以使用,包括修改2.函数返回值使用$?,使用中每次调用会覆盖前次执行返回值,但递归执行中只要再次调用前取出该值不影响最后结果。3.参数可以是一个变量,变量可以是数组,但本例未这么实用,只是测试可以这么用。
68、希尔排序
希尔排序是简单插入排序的改进版。它与插入排序的不同之处在于,它会优先比较距离较远的元素。希尔排序又叫缩小增量排序。 算法描述先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,具体算法描述:选择一个增量序列t1,t2,…,tk,其中ti>tj,tk=1;按增量序列个数k,对序列进行k 趟排序;每趟排序,根据对应的增量ti,将待排序列分割成若干长度为m 的子序列,分别对各子表进行直接插入排序。仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。#!/bin/bash#insert sort#arr=(22 18 5 11 17 23 50 78 30 61)arr=(101 0 35 27 87 99 51 6 33 37 28 62 90 111 222 33 550 22 18 5 11 17 23 50 78 30 61)echo ${arr[@]}echo "--->>>"ii=0jj=0arrtotal=${#arr[*]}let lastone=arrtotal-1let fstep=arrtotal/2function insertsort(){#需要参数如下:#分组数(循环步长)#数组首坐标#计算最末坐标let ii=ii+1f1=$1step=$2let maxone=(arrtotal/step)-1let maxone=maxone*step+f1let s1=f1+step while [ $s1 -le $maxone ]; do let s2=s1-step s11=${s1} temp=${arr[$s1]} while [ $s2 -ge $f1 ]; do let jj=jj+1 if [ $temp -lt ${arr[$s2]} ]; then arr[$s11]=${arr[$s2]} arr[$s2]=$temp s11=$s2 else break; fi let s2=s2-step done let s1=s1+step done}function shellsort(){ initstep=$1#echo $initstep while [ $initstep -ne 1 ]; do initf0=0echo "step:"$initstep while [ $initf0 -lt $initstep ]; do insertsort $initf0 $initstep let initf0=initf0+1 done let initstep=initstep/2 done insertsort 0 1}shellsort $fstepecho "total insertsort:$ii runloop:$jj"echo ${arr[@]}echo "END"
69、归并排序
归并排序(Merge Sort)归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。 算法描述1.把长度为n的输入序列分成两个长度为n/2的子序列;2.对这两个子序列分别采用归并排序;3.将两个排序好的子序列合并成一个最终的排序序列。代码实例:#!/bin/bash#merge sortarr=(100 99 98 97 20 21 22 23 34 33 32 31 59 58 60 61 11 12 9)echo ${arr[@]}echo "--->>>"let arrtotal=${#arr[*]}let igroup=arrtotal/2let lastone=arrtotal-1echo "lastone:$lastone"function mergeinitsort(){ step=2 i=0 let iend=lastone-1 while [ $i -le $iend ]; do let itmp=lastone-i if [ $itmp -ne 2 ]; then let ii=i+1 if [ ${arr[$i]} -gt ${arr[$ii]} ]; then tmp=${arr[$i]} arr[$i]=${arr[$ii]} arr[$ii]=$tmp fi else let ii=i+1 let iii=i+2 if [ ${arr[$i]} -gt ${arr[$ii]} ]; then tmp=${arr[$i]} arr[$i]=${arr[$ii]} arr[$ii]=$tmp fi if [ ${arr[$i]} -gt ${arr[$iii]} ]; then tmp=${arr[$i]} arr[$i]=${arr[$iii]} arr[$iii]=$tmp fi if [ ${arr[$ii]} -gt ${arr[$iii]} ]; then tmp=${arr[$ii]} arr[$ii]=${arr[$iii]} arr[$iii]=$tmp fi fi let i=i+step done}function mergesort(){ a1=$1 b1=$2 abstep=$3 abstep2=$4 let a1e=a1+abstep-1 let b1e=b1+abstep2-1 while [ $a1 -le $a1e ]; do while [ $b1 -le $b1e ]; do if [ ${arr[$a1]} -le ${arr[$b1]} ]; then break; else abtmp=${arr[$a1]} arr[$a1]=${arr[$b1]} let b11=b1+1 bb11=$b1 while [ $b11 -le $b1e ]; do if [ $abtmp -gt ${arr[$b11]} ]; then arr[$bb11]=${arr[$b11]} arr[$b11]=$abtmp else arr[$bb11]=$abtmp break; fi let b11=b11+1 let bb11=bb11+1 if [ $b11 -gt $lastone ]; then break; fi done fi done let a1=a1+1 done}mergeinitsortecho ${arr[@]}echo "----"xi1=0xstep=2xstep2=2let xj1=xi1+xsteplet xi1e=xi1+xstep-1let xj1e=xj1+xstep-1if [ $xj1e -gt $lastone ]; then xj1e=$lastone let xstep2=xj1e-xj1+1fiwhile [ $xi1 -ge 0 ]; do mergesort $xi1 $xj1 $xstep $xstep2 if [ $xj1e -eq $lastone ]; then break; fi let xi1e=xj1e let xj1=xi1e+1 let xj1e=xj1e+2 let xz=lastone-xj1e let xstep=xstep+2 if [ $xz -eq 1 ]; then xj1e=$lastone let xstep2=xj1e-xj1+1 fidoneecho ${arr[@]}echo "END"
70、统计排序
计数排序不是基于比较的排序算法,其核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。 算法描述找出待排序的数组中最大和最小的元素;统计数组中每个值为i的元素出现的次数,存入数组C的第i项;对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加);反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1。代码:#!/bin/bash#Counting Sortarr=(100 99 97 77 79 80 9 12 22 2 32 35 66 55 51 42 38 37 20 70 109 9)imax=${#arr[@]}echo $imaxecho ${arr[@]}echo "--->>"i=0ivaluemax=${arr[0]}ivaluemin=${arr[0]}while [ $i -lt $imax ]; do if [ ${arr[$i]} -gt $ivaluemax ]; then ivaluemax=${arr[$i]} elif [ ${arr[$i]} -lt $ivaluemin ]; then ivaluemin=${arr[$i]} fi if [ -z karr[${arr[$i]}] ]; then karr[${arr[$i]}]=1 else let karr[${arr[$i]}]=karr[${arr[$i]}]+1 fi let i=i+1donej=0i=0while [ $j -le $ivaluemax ];do if [ -z ${karr[$j]} ] ; then let j=j+1; else while [ ${karr[$j]} -gt 0 ];do Rarr[$i]=$j let karr[$j]=karr[$j]-1 let i=i+1 done let j=j+1 fi doneecho ${Rarr[@]}
71、查找文件,排除部分类型的文件
列出/root下所有文件,但是不要列出后缀为jpg、png、jpeg、gif的文件方法1:find /root -type f ! -name "*.jpg" ! -name "*.png" ! -name "*.jpeg" ! -name "*.gif"方法2:ls -l /root |egrep -v "^d" |grep -v ".jpg" | grep -v ".png" | grep -v ".jpeg" | grep -v "*.gif"
72、打包站点目录下所有文件,但排除attachment
代码:tar zcf me.tar.gz --exclude=attachment ./xyz.abc.com
73、将所有后缀为jpg的文件权限改为600
代码:方法1:find -type f -name "*.jpg" -exec chmod 600 {} \;方法2:chmod 600 *.jpg总结:方法1和方法2有少许区别。方法1可以将当前目录下包含子目录所有“*.jpg”权限修改。方法2则不修改子目录下的“*.jpg”文件权限find有选项maxdepth可以控制执行子目录的深度,下面的命令跟方法2效果一样:find -type f -name "*.jpg" -maxdepth 1 -exec chmod 600 {} \;
74、复制文件到其他主机
复制一个文件nfsclient.sh到主机172.18.117.162的/root目录下scp -P22 nfsclient.sh root@172.18.117.162:/root/使用对端主机必须开启ssh服务,并在防火墙开放端口访问。还有一个方法,就是目标主机运行nfs服务,并开放写权限。
75、查看子目录占用空间大小
代码:du -h --max-depth=1 toutoule.lagougongshe.com
76、查找文件时,排除几种类型文件
代码: find -type f ! -name "*.jpg" ! -name "*.png" ! -name "*.jpeg" ! -name "*.php" ! -name "*.txt" ! -name "*.php5" ! -name "*.asp"使用"!"来排除查找对象
77、搜索文件并将其权限修改为644
方法1:find -type f -name "*.jpg" -exec chmod 644 {} \;方法2:find -type f |xargs chmod 644 使用-exec选项和使用管道+xargs命令在执行上有区别。-exec是边搜索边执行,也就是找到一个执行一个。使用管道+xargs命令搜索到全部结果之后在执行后面的命令。两种方法各有优略。
78、使用awk读取文件并输出低5-15行内容
目标文件名为:sut_sub.txt方法1:awk '{if(NR>=5 && NR <=15){print $0}}' sut_sub.txt方法2:awk ‘NR>=5 && NR <=15{print $0}’ sut_sub.txt方法3:awk -f awkwhile sut_sub.txtawkwhile脚本如下:{ iif(NR<5){ next}else if(NR<=10){ print $0}else{exit}}总结:方法1和方法2基本一致。方法3使用了while和next配合实现。当所有数据读取后,使用exit退出不在读取后面的行。
79、答复网友脚本错误一例

如图是网友发的QQ截图。问题是,运行脚本目的是打包/var/log下所有的后缀log的文件,成功后删除源文件。实际运行结果是,得到的压缩包都是错误的。分析:从脚本看,其过程是通过find获得全部/var/log下后缀log的文件名,以备份目录名、字符串、时间组合备份那文件目标,使用for in读取已经找到的目标文件数组进行打包,使用tar --remove-files实现删除源文件貌似没有什么问题,但是...结果不对那么一定有问题。问题在哪里呢?第一个问题,循环执行打包,那么每次循环都创建打包文件,是不是就覆盖前面的?那么解决方案就是第一个文件归档要进行创建,第二个之后应该是追加。修改后 tar rvPfz ...修改后出现新问题,提示追加模式无法压缩可以采用先打包后压缩的方式。即先tar rvfP ...,完成后再使用gzip压缩(其他压缩软件也可以)
80、统计两个字符串中重复字符个数
两个字符串统计重复字符个数。字符串中可能有重复字符,不进行排重。#!/bin/bash#比较2个字符串中,重复字符数str1="a1b1c2d2ie"str2="x26b7ac1fk"len2=${#str2}let len2--i=0icount=0while [ $i -le $len2 ]; do tmp=${str2:${i}:1} echo $str1 | grep "${tmp}" flag=$? if [ $flag -eq 0 ]; then let icount++ fi echo $i"," $tmp let i++doneecho "重复字符数量:" $icount总结:思路比较简单,将其中一个字符串以每个字符为单位转化为数组,每次取1个与另一个字符串进行正则比较。循环完成所有比较。
81、复制文件问题答疑
问题来自论坛求助,如下图:有网友给出答复如下:eval cp $algo_files /home/data此方法可行。我给出另一种方法如下:order = "cp $algo_files /home/data"echo $order | bash两种方法都可以解决问题,做如下总结:1.eval命令l会对后面的命令进行两遍扫描,如果第一遍扫描后,命令是个普通命令,则执行此命令;如果命令中含有变量的间接引用,则保证间接引用的语义。也就是说,eval命令将会首先扫描命令行进行所有的置换,然后再执行该命令。在本例中就属于有间接引用的情况。2.我给出的方法属于曲线救国。利用管道将echo命令输出的字串当数据源输入给bash命令。bash解析字串命令并执行。

82、彩票选号器
执行脚本带入2个参数,第一个是选号数量,第二个是选号最大数值。例如:生成6个数,最大33,执行如下awk -f awklotto lotto.txt 5 33生成数放入lotto.txt中。awklotto是脚本,内容如下:BEGIN{ t0=ARGV[1] t1=ARGV[2] t2=ARGV[3] srand() i=1 x=int((0.003+rand())*t2) lotto[x]=x print i,":", lotto[x] >> t0 while (i >0) { if (t1==1){ break;} y=int((0.003+rand())*t2) i=i+1 if(y in lotto) { i=i-1 } else { print i,":",y >> t0 lotto[y]=y if(i==t1) { break; } } }}祝大家好运!
88、kill多个同名进程
运行3个同名脚本Cheng.sh使用如下脚本,将

三个Cheng.sh同时kill。代码:ps aux |grep Cheng.sh|grep -v grep|awk '{print $2}'|xargs kill -9如果想保留第一个启动的进程,那么代码改进如下:ps aux |grep Cheng.sh|grep -v grep|awk 'NR>=2{print $2}'|xargs kill -9

同理,也可以保留最后一个启动的进程。代码修改如下:#!/bin/bashps aux |grep Cheng.sh|grep -v grep|awk '{print $2}'> r.txtx=$(cat r.txt | wc -l)cat r.txt | awk -v maxvalue=$x 'NR<maxvalue{print $1}'| xargs kill -9注:基本思路是列出所有进程ID并存储,然后计算进程总数,再执行kill,kill前判断当前数是否小于行数。
89、保存目录下文件以及文件大小
代码:#!/bin/bashlogfilename=/tmp/`date +%F-%H-%M`.logecho $logfilenameexitfor i in `find /root/ -type f`dodu -sh $i > $logfilenamedone代码实现存储在以日期+小时+分钟命名的log文件中.这里使用find命令而不是ls命令.如果不想要子目录中的文件,也可以使用ls命令。
90、统计指定网卡流量
使用sar命令,统计网卡eno2流量.以10次平均值作为统计结果.sar -n DEV 1 10 | grep Average |grep eno2 | awk '{print "\tdevice:",$2,"\t","input:","\t",$5*1000*8,"bps","\n","\tdevice:",$2,"\t","output:","\t",$6*1000*8,"bps"}'

91、ftp下载文件
通过shell脚本连接一个ftp服务器,并下载指定的文件。本例下载文件通过参数传递给脚本。参数是包含目录和文件名。脚本名:ftp.sh#!/bin/bashif [ $# -ne 2 ]; then echo "Usage: $0 ftpIP filename" exit 1fiecho "begin..."dir=$(dirname $2)file=$(basename $2)ftpIP=$1ftp -n -v << EOFopen ${ftpIP}user allenle 123456binary cd ${dir}get "${file}"EOF运行脚本: /bin/bash ftp.sh 192.168.1.245 sources/readme.txt

ftp命令参数:
-n是自动登录-v 显示过程详细信息
92、批量修改文件名
目录下生成若干文件:touch abc{1..5}.html修改abc1.html,abc2.html,abc3.html,abc4.html,abc5.html文件名中的abc为xyz。方法1:使用rename命令这个方法自简单,命令如下:rename 's/abc/xyz/' *.html方法2:使用循环+mv命令#!/bin/bashfor file in $(ls *.html);do mv ${file} $(echo ${file} | sed 's#abc.∗.∗#xyz\1#g')done方法3:使用循环+${变量#}#!/bin/bashfor file in $(ls *.html);do mv ${file} xyz${file#c*.}done注:rename在ubuntu18下可能未安装,可以使用apt-get install rename安装。
93、输出一段连续IP地址
outputIPs.sh代码:#!/bin/bashnum=0for i in $(eval echo $*);do #eval将{1,2}分解为1 2 let num+=1 echo $idone执行:/bin/bash outputIPs 192.168.1.{1..255}

94、搜索文件并统计结果文件大小总合
filesSize.sh代码:#!/bin/bashfind -type f -name "*.log" -exec du -k {} \; | awk 'BEGIN{sum=0}{sum=sum+$1}END{print sum}执行:/bin/bash filesSize.sh
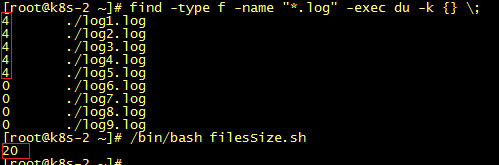
如果仅对当前路径下文件进行搜索,也可以使用ls命令。ls -l *.log | awk 'BEGIN{sum=0}{sum=sum+$5}END{print sum}'执行结果:
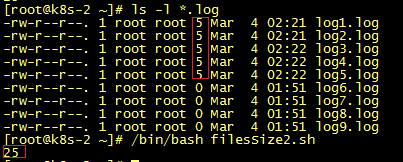
注:ls和find在计算文件大小上有误差,因此统计结果会不同。本例使用的文件均为微小文件,比较明显。
95、扫描主机端口
扫描主机端口是否开放。脚本执行时输入主机名。方法1:#!/bin/bashHOST=$1PORT="22 25 80 8080"for PORT in $PORT; do nc -w 1 $HOST $PORT result=$(echo $?) if [ $result -eq 0 ]; then echo "$PORT open" else echo "$PORT close" fidone方法2:#!/bin/bashHOST=$1PORT="22 25 80 8080"for PORT in $PORT; do if echo &>/dev/null > /dev/tcp/$HOST/$PORT; then echo "$PORT open" else echo "$PORT close" fidone
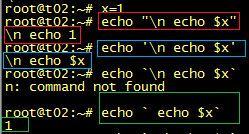
96、shell中的特殊字符“#”
“#”在Shell中有多重用途。1.用于注释注释可以是独立的一行,也可以存在于本行命令之后,与命令最后一个字符要有一个空格。例如:#这是一行注释echo "hello world" #这行输出hello world,注释在本行命令语句之后,中间有一个空格2.“#!”是一个例外如果以“#!”开头的行,不是注释,它表明本脚本使用指定的解释器运行。例如:#!/bin/bash指定脚本使用bash shell解释3.作为一个普通字符如果和转义字符“\”一起使用,那么“#”当做普通字符使用,不代表注释。例如:echo xyz\#命令输出结果:“xyz#”4.与${}结合使用,实现参数替换例如:echo ${PATH#*:}此命令将变量PATH从左侧第一个“:”字符开始左侧部分舍弃。如下图,红框部分被舍弃。echo ${PATH##*:}此命令将变量PATH从左侧最后一个“:”字符开始左侧部分舍弃。如下图,篮框部分之外的部分被舍弃。

5.与单引号和双银行结合使用的效果与单引号和双银行结合使用的效果等同于普通字符例如:echo "xyz #"echo 'xyz #'两个命令输出结果都是:xyz #
97、特殊字符“;”“.”
“;”跟“#”类似,在shell中有多种用途1.在一行中执行多个命令时,作为命令分隔符号例如:echo “123”; echo "456"2.在if分支语句时,if和then使用“;”分割例如:if [ -x "$filename" ] ; then echo "File $filename exists."else echo "File $filename not found."fi3.";;"连续两个分号用于终止“case”选项例如: case "$variable" in abc) echo "This is abc" ;; bcd) echo "This is bcd" ;; esac"."在shell中也有多种用途1.等价于命令source例如:. /etc/profile. #相当于 source /etc/profile2.作为文件名的一部分例如:t.sh.history当“.”作为文件名的第一个字符时,该文件为隐藏文件。将不被ls列出。如果想要列出需要使用ls -a。3.作为正则表达式的一部分用来匹配任何的单个字符。例如: s#\".\"#\"\"#g上例正则是匹配一对冒号,且中间为一个.的字符串,替换为一对冒号。4.当作路径“.”表示当前目录“..”表示上一级目录例如:cd . #进入当前目录cd .. #进入上一级目录cp /etc/profile . #复制文件到当前目录cp /etc/profile ./ #同上cp /etc/profile ../ #复制文件到上一层目录
98、Shell特殊字符“双引号”“单引号”“反引号”
“双引号”-"被双引号包括的字符,某些特殊字符被当作不同字符处理。例如:“#”“\”(转义字符)shell命令,echo、ls等但是如果包含变量,依然可以识别。例如:x=1echo "echo \n $x"输出结果为: echo \n 1“单引号”-'被单引号包括的字符,某些特殊字符被当作不同字符处理。与双引号不同的是,变量也被当作普通字符处理。例如:例如:x=1echo 'echo \n $x'输出结果为: echo \n $x反引号-`被反引号包括的字符,某些特殊字符被当作不同字符处理。它跟双引号一样,可以识别变量,同时还能识别包含的shell命令。例如:x=1echo 'echo \n $x'输出结果为:1
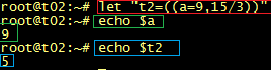
99、Shell特殊字符“,”“\”“/”
逗号-,逗号用在算术操作中,分割个运算式,但是只有最后一项被返回。例如:let "t2=((a=9,15/3))"echo $aecho $t2输出结果:95反斜杠-“\”转义字符,配合普通字符表达特殊含义。例如:\n 代表换行斜杠-"/"斜杠在文件名中出现作为路径分隔符。例如:/etc/profile/etc目录下的profile文件斜杠在算术操作中作为除法操作符。
100、Shell特殊字符“:”“!”“*”
冒号-“:”它的第一个作用是控命令,就是什么都不干。等价于NOP。主要用于占行。例如:if [ 条件 ] ; then:else 命令if它的第二个作用变量取部分字符时用于分隔参数例如:a="allenle"b=${a:0:2}echo $b输出结果为:“al”在配置文件中,冒号用来做分隔符。例如:/etc/passwd叹号-“!”取反操作符,加了这个符号,原命令输出的状态将会变为相反状态。星号-“*”它的第一个作用是万能匹配符号。例如:ls -l f* #输出f开头的所有文件和目录${a#*/} #变量a的左侧第一个“/”及其左侧的所有字符都移除它的第二个作用是数学运算符号。例如:* 代表乘** 代表幂运算
101、Shell特殊字符“?”“$”“{}”
问号-“?”第一个作用是也是匹配字符,跟“*”不一样的是“?”只匹配1个字符。另一个作用就是测试操作。例如:$? 获取文件执行或者命令执行的返回状态值返回0是正常。非零是异常。“$”第一个作用是表示变量。例如:$a 名为a的变量${a} 名为a的变量,大多数情况{}可省略,但是这种写法更加明确,推荐使用。${}配合还可以完成参数替换。配合其他字符,表示特殊参数例如:$@ 表示传递给函数或脚本的所有参数$* 表示传递给函数或脚本的所有参数当 $* 和 $@ 不被双引号" "包围时,它们之间没有任何区别,都是将接收到的每个参数看做一份数据,彼此之间以空格来分隔。但是当它们被双引号" "包含时,就会有区别了:"$*"会将所有的参数从整体上看做一份数据,而不是把每个参数都看做一份数据。"$@"仍然将每个参数都看作一份数据,彼此之间是独立的。进程ID变量.这个进程ID变量.这个变量保存运行脚本进程 ID大括号-"{}"第一个作用是其内逗号分隔的部分,配合括号外的命令完成命令操作。例如:cat {1.txt,2.txt,3.txt } > a123.txt

cp a123.{txt,backup}

代码块被“{}”扩起来的代码,有一定限制作用。在其中间生辰的变量仅在括号中使用。括号内可以使用括号外的变量。在{}结构中代码的I/O重定向。

第一对{},从文件t102.sh读取两行内容第二对(),echo输出的4行内容,写入t102文件
102、特殊字符"[]"和"[[]]"
“[]”第一种作用:表示数组的元素例如:Array[1]=xecho ${Array[1]}第二种作用:在if判断语句中,将条件表达式包括在其中例如:if [ $x -eq 1 ] ; then echo "ok"fi第三种作用:在正则表达式中,当字符匹配的一个范围时,使用其将范围包括其中例如:[a-zA-z] 表示匹配全部英文大小写字母“[[]]”第一种作用:在if判断语句中,将条件表达式包括在其中。双中括号可以放置脚本中许多逻辑错误。例如:if [[ $x -gt 1 && $x -lt 10 ]] ; then echo "ok"fi第二种作用:作为一个单独的元素,并返回一个退出码例如:if [[ $x -gt 1 && $x -lt 10 ]] echo "runing"此时,x值如果为11,那么会输出runing;如果为6,那么会结束执行。第三种作用:支持字符串的模式匹配。例如:[[ hello == hell? ]]此表达式结果为真
103、特殊字符“()”“(())”
“()”第一种作用:初始化数组例如:Array=("a" "b" "c" "d")echo ${Array[3]}输出结果:d第二种作用:命令替换。当发现“$(cmd)”结构,会将cmd执行一次,得到其标准输出再放回原来的命令中。例如:x=$(ls -l)echo $x输出结果:当前目录执行ls -l命令可以运行多个命令,命令之间用“;”分隔“(())”第一种作用:用于重定义变量例如:a=6((a++))echo $a输出结果:7第二种作用:执行“(())”中间包括起来的表达式,甚至三目运算符例如:echo $((16#5f))输出结果95第三种作用:用于算数运算比较,“(())”中间的变量一般不带$,if判断时需要带$例如:for((i=1;i<10;i++))...if (( $a >5)) ; then echo "6 or great"else echo "less 6"fi
105、脚本中的空格小结
1.通过空格可以实现同一行内给多个变量赋值例如:var1=1 var2=2 var3=32.变量中含有空格时,可能输出结果大相径庭例如:x="a b c d f"echo $xecho "$x"如下图1:从结果中看出,第一种形式字符中间不管含有多少个空格,输出时只输出一个空格;第二种形式则是按变量内实际空格数量输出。3.变量赋值时如果有空格例如:var1=1var2= 2var3 =3var4 = 4如下图2:从结果看,第二种形式中,“var2”被当作了命令来执行;第三种形式中,“空格后的数字3”被当作了命令来执行;第四种形式中,“var4”被当作了命令来执行。如果var2是一个合法的命令,那么你会看到错误提示可能是“=2”不合法参数。
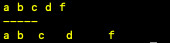
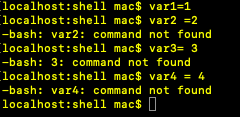
106、变量小结
1.变量赋值 变量赋值使用“=”,“=”左右皆不可以有空格,形式如下: a=1 #赋值1给变量a a=1+2 #赋值1+2的结果给变量a a+=1 b=abc #赋值字符串abc给变量b b=“abc” #赋值字符串abc给变量b b='abc' #赋值字符串abc给变量b c=$(ls) #ls运行结果作为字符串赋值给变量c c=`ls` #ls运行结果作为字符串赋值给变量c for d in 3 4 5 6 do echo $d #将3,4,5,6依次赋值给a后并打印输出 done2.变量的引用echo $a #输出变量a内容echo ${a} #输出变量a内容echo "$a" #输出变量a内容let a=a+1 #算式中,使用let关键词,变量不加$3.变量的类型实际上shell中变量基本可以认为部分类型。或者说只有两种,字符串和数字。如果是只包含数字,那么就可以当作数字类型。例如:a=23345let a=a+1echo $a # 此时变量a是原来的数值家1,输出23346b=${a/23/bb} #把a变量中“23”替换为“bb”echo $b #输出变量b,内容为bb3464.变量的分类按照使用范围分可以分为局部变量和全局变量。局部变量只能在代码块或者是函数中可用。另外一个特殊的就是环境变量。5.外部变量从命令行中传进来的参数。$0代表脚本名字$1代表第一个参数$2代表第二个参数${10}代表第10个参数以此类推
107、复制一个目录下所有文件和文件夹到目标目录
假定源目录是/a,目标目录是/b方法1:cp -a /a/* /b方法2:(cd /a && tar cf - .)| (cd /b && tar xpvf -)简要说明:cd /a && tar cf - . 进入a目录,如果成功tar在当前目录创建文件,直接输出给标准输出| (cd /b && tar xpvf -) 通过管道接收标准输出的内容,进入目录,如果成功,执行tar命令,解包并保留属性,数据来源从辨准输入读取(管道),并输出完整消息到标准输出
108、特殊字符“-”和“+”
1.算术符号例如: let a=5+2-12.重定向“-”有些时候可以起重定向作用。Shell小技巧(一百零七)中方法2中的“-”就是起到了重定向作用。3.特定命令用于打开选项、关闭选项例如:chmod +x t1.sh #给t1.sh文件增加执行权限chmod -x t1.sh #给t1.sh文件移除执行权限4.“-”用于命令选项前缀例如:find . -mtime -1 -type f #查找当前目录下,1天内修改过的文件5.“-”使得shell等待用户输入例如:file -6.和“~”搭配使用,等价路径变量echo ~+ #当前工作目录,相当于pwdecho ~- #z之前的工作目录如下图:7."+"在正则表达式里使用,代表重复前一个字符至少1次

109、组合键总结
Ctl+u 删除光标到行首的所有字符Ctl+c 终止前台工作Ctl+j 换行Ctl+k 删除当前光标到本行尾部的字符Ctl+w 删除当前光标到前边的最近一个空格之间的字符Ctl+d 相当于exit,从当前shell登出Ctl+b 光标后退,只是移动光标不删除字符Ctl+h 删除光标前边的字符,一次操作删除一个Ctl+l 清屏,如果当前行输入了内容,此时使用本组合键,本行未执行的内容不清Ctl+m 跟Ctl+j类似,回车Ctl+s 挂起,输入本组合键后,终端在输入命令不会立即执行,直到输入Ctl+qCtl+q 继续
110、特殊字符“<”、“<<”、“<<<”
shell中“<”是重定向,将从“<”右侧读取的内容输出到“<”左侧。一般形式如下:command < file即将文件内容输出给命令“<<”则是一种特殊的重定向,是输入内容重定向到一个命令或脚本。一般形式如下:command << EOF.........EOF输出结果...例如:
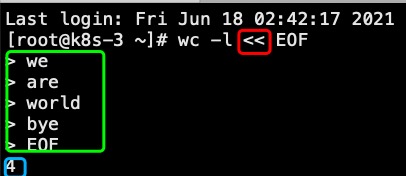
如上图输入4行内容,输出结果是wc统计行数。在实践过程中,以下是一种典型用用形式:sftp username@IPaddress << EOF.........EOF如上代码实现了使用一个脚本通过sftp执行一系列命令的功能。“<<<”同样是一种特殊重定向,但是它的右侧是一个字符串。下面是一个典型例子:passwd --stdin root <<< "123456" 实现了用脚本修改密码(非交互形式修改密码)这个功能的另一种实现是通过管道形式:echo "123456" | passwd --stdin root
111、变量小结(补充)
之前写过一篇关于变量的总结文章,其内容还是有些遗漏,作此篇文章补充。1.关于赋值赋值有一种形式是将一个命令结果赋给变量。例如:a=`ls -l`如果是写在脚本里执行,不会有什么问题。但是如果是直接命令行执行,则有一种特殊情况。即如果包含“!”那么会报错。例如:
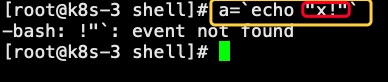
2.关于引用变量引用以下2种形式会略有区别。a=`ls -l`echo $aechoecho "$a"

echo "$a"将会保留空白部分(包括换行)3.关于脚本参数变量下面这个脚本将演示一个技巧args=$#lastarg=${!args}echo $lastarg如果运行脚本没有参数,那么将输出脚本名城;如果参数个数大于0,那么将输出最后一个参数。

通过$#这个参数可以判断脚本运行时的参数数量。除了利用$#,还可以使用如下方式来判断运行脚本是否有参数:if [ -z $1 ] #直接判断是否为空${1:-$DefaultValue} #$DefaultValue是预先设置的缺省值变量,如果$1为空,那么会引用$DefaultValue变量的值通过shift命令,可以让脚本参数位置向左1个位置。即从左向右的参数第2个变成第1个,第3个变成第二个以此类推。而第1个参数原值被销毁。以下一个例子演示命令带参数执行三种效果:v="" #变量为空值command $v $v $v #command命令将不带参数执行command "$v" "$v" "$v" #command命令将带3个参数执行,三个参数为空command "$v $v $v" #command命令将带1个参数执行,参数为两个空格
112、特殊字符“\”-转义小结
在各种编程语言中,一般都存在使用特殊字符组合来表达特殊的含义。其中大部分都适用“\”作为转换字符含义的操作符。Shell中也使用“\”,我们称其为转义。在echo和sed使用的一些转义组合如下:\n 换行\r 回车\t tab制表符\v 垂直tab\xxx 八进制ASCII解码,x代表数字\xyy 十六进制,y代表数字一个八进制例子如下:echo '\t \x42 \t'echo '\x42'
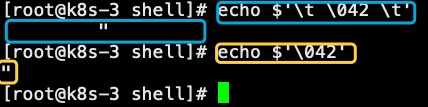
常见的转义组合:\" 双引号\$ $符号\\ \符号下面是一个转义的例子:

本例中,第一种情况(不带引号)转义符号两行命令均有效;第一行转义后与不加转义符号效果一样。第二种情况(单引号)转义符号在两行均未作转义符号使用,直接输出了。第三种情况(双引号)第一行未作转义符号使用,直接输出;第二行转义起作用,输出一个“\”。下一个例子比较有趣:

本例使用了反引号“`”,第一行和第二行最终结果一致,其中第二行第一次echo执行后输出“\z”在第二次echo输出时为“z”。第三行到第六行最终结果一致,第三行和第四行第一次echo前先进行转义,结果都是“\\z”,其中第三行转义1次,第四行转义2次。第五行和第六行第一次echo前先进行转义,结果都是“\\\z”,其中第五行转义2次,第六行转义3次。转义符号如果复制给一个变量,在输出变量值时,按如下形式回报错:v=\echo "$v"转义字符还有一个续行效果,在命令行尾部,如果加上“\”,那么下一行的命令跟本行一起输出执行。例如: ls -l | \grep "mysql"
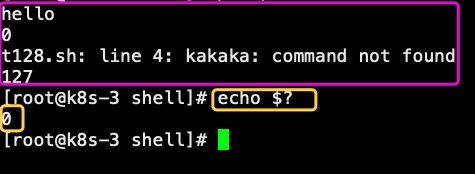
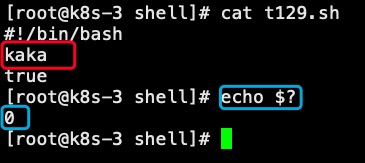
113、退出状态
每个命令都会返回一个退出状态。脚本也一样,也可以在结束的时候返回一个状态值。如果返回值为0,代表成功;返回一个非零值,通常会被认为是一个错误代码。这个非零值错误代码必须是1-255的十进制整数。在shell脚本中,使用命令exit给脚本退出返回一个状态值。格式:exit n (n为0-255)可以根据实际情况返回对应的代码值。一个常见的小技巧,使用脚本中最后一个命令的执行结果作为脚本退出后的执行结果。例如:#!/bin/bashecho helloecho $? #上一个命令返回0,因为执行成功kakakaexit $? #kakaka命令不存在,因此一定是执行失败,返回值非零这里要注意,代码不可写为 echo $? && exit $?因为exit之前的echo $?执行时成功的,所以exit $?会返回0true命令是shell内建命令,作用什么都不敢,脚本结束后返回0如果想返回非零,那么可以“! true”来实现。总结:exit和true命令都可以控制退出时脚本的返回值,但是exit比较灵活,输出的值更丰富。true只能0或者1.

114、关于tests
test命令位于/usr/bin下格式:/usr/bin/test 表达式其执行后返回表达式逻辑结果,即true或false其典型应用是在if分支中使用。例如:if /usr/bin/test -z '$a'另外,使用"[[...]]"替代"[...]"可组织脚本中许多逻辑错误。下面是一种比较简化的形式,可以省略if:a=1b=2["$a" -ne "$b"] && "$a 不等于 $b"本例将输出”1不等于2“"((...))"在今sing数学操作也可以实现test功能。例如:#!/bin/bash(( 5>9 ))echo "$?" #输出1(( 5>2 ))echo "$?" #输出0对文件测试的操作如下:-e 文件存在-a 文件存在,与-e效果一样。但是已经被弃用,推荐不用。-f 文件是一个普通文件,非设备文件或目录-s 文件存在且不为空-d 文件是个目录-b 文件是个快文件-p 文件是个管道-L 文件是个符号链接,软链接-S 是个sock文件-t 关联到一个终端设备的文件描述符-r 文件具有读权限-w 文件具有写权限-x 文件具有执行权限-g 设置了sgid-u 设置suid-k 设置了粘贴位-O 是文件的所有者-G 文件的gid和执行者的gid相同-N 从文件最后被阅读到现在为止,是否被修改。
115、找出所有损坏的链接文件
功能需求:脚本运行,接收参数作为查找路径,路径可以是一个或者多个。如果没有带参数执行,则以当前路径作为查找路径。当前路径下所有文件以及子路径下所有文件判断是否是有效的链接文件,如果是无效的链接文件则输出。代码:#!/bin/bash[ $# -eq 0 ] && directory=`pwd` || directory=$@ #判断是否有参数,没有则获得当前路径。linkchk(){ #检查链接文件的函数,可以递归执行 for element in $1/*;do #列出路径下所有文件(含目录),循环判断 [ ] [ ] done}for directory in $directorys;do if [-d $directory ];then linkchk $directory #调用检查函数,传入查找路径 else echo "$directory is not a directory" echo "Usage:$0 dir1 dir2 ..." fi doneexit 0
115、做比较小结
1.数字比较数字比较比较好理解,基本上就是数值大小比较。比较 操作符:-eq 等于-le 小于等于-ge 大于等于-gt 大于-lt 小于-ne 不等于例如:[ 1 -eq 1 ][ 2-ge 1 ][ 3 -gt 1 ]...其实我们比较熟悉的“>”“<”“>=”“<=”“==”也是可以使用的,不过需要使用“((...))”例如:if (( 2 >= 1 ))if (( 1 == 1 ))if (( 3 > 1))...2.字符串比较字符串比较操作符:= 字符串相等== 字符串相等,与=等价!= 字符串不想等< 小于,比较的是字符串ASCII顺序> 大于,比较的是字符串ASCII顺序-z 字串为“null”,即长度为0-n 字串不为“null”例如:if [[ abc > abcd ]] #false,字符串2多一个字符,值较大if [[ axc > acx ]] #true,x的ascII值大于c的ascII值if [ abc \> abcd ] #false,如果使用“[]”那么需要使用转义字符“\”在比较大小写字母时,推荐使用“[]”,如下:if [ A \> a ] #false,如果使用“[[...]]”结果是错误的
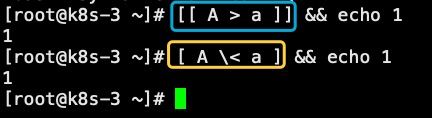
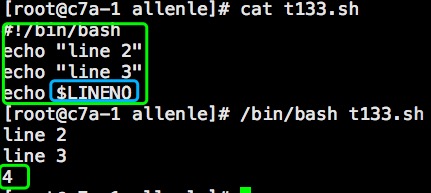
3.文件比较文件比较操作符:-nt 文件1比文件2新-ot 文件1比文件2旧-ef 文件1和文件2都应链接到同一个文件例如:先创建t133.sh,再创建t134.sh

116、字符串测试的一个小问题
上一段代码:#!/bin/bashif [ -n $string1 ];then echo "It is not null."else echo "This is null."fi#exit 0echo "---------------------"string=""if[ -n "$string1"];then echo "it's not null."else echo "This is null."fiecho "********************"if [ -n $string1 ];then echo "It is not null"else echo "This is null."fi
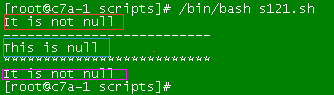
一个未经初始化的变量string1,第一段测试,输出结果:it is not null.
第二段测试,输出结果:This is null
第三段测试,输出结果:It is not null
从结果我们看出,未经初始化的变量,在测试过程中,如果未使用"$strign1"形式引用后判断,那么结果可能是错误的。
117、计算两个数的最大公约数
代码如下:#!/bin/bashgetmaxgy(){ dividend=$1 divisor=$2 remainder=1 until [ "$remainder" -eq 0 ] do let "remainder = $dividend % $divisor" dividend=$divisor divisor=$remainder done }getmaxgy $1 $2echo echo 'max gongyue of $1 and $2 = $dividend';echo 执行结果:
118、shell实现加法的6种形式
代码:#!/bin/bashn=0:$[ n = $n+1 ]echo $nn=$[ $n + 1 ]echo $nn=$(( $n + 1 ))echo $nlet "n++"echo $n(( n++ ))echo $n:$(( n = $n + 1 ))echo $n一共6种可进行数学加法计算形式,利用let关键字、"[ ... ]"、”((...))“另外,Bash中的整形是32位的,范围是-2^31 ~ 2^31-1。Bash不能理解浮点运算,如果需要,可以使用bc命令。
119、混合状态的test
这里给出一个典型的例子,即if语句中多个逻辑条件判断。例1:以下是一种正确的写法:a=24b=47if [ "$a" -eq 24 ] && [ "$b" -eq 47 ]thenecho 1elseecho 2fi运行结果将输出1例2:以下则是错误的写法:a=24b=47if [ "$a" -eq 24 && "$b" -eq 47 ]thenecho 1elseecho 2fi例3:如果希望在一对“[...]”内并列条件,应该按如下格式:if [ "$a" -eq 24 -a "$b" -eq 47 ]thenecho 1elseecho 2fi即用-a(或-o)关联左右两个条件。
120、内部变量1
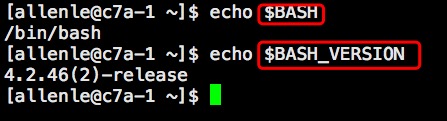
shell有数量众多的内部变量。$BASHBASH的二进制执行文件的位置。$BASH_VERSIONBASH的版本号#echo $BASH/bin/bash#echo $BASH_VERSION4.2.46(2)-release$FUNCANAME //当前函数名字$GROUPS //当前用户所属组$HOME //当前用户的家目录$HOSTNAME //主机名$IFS //内部域分隔符,默认为空白,但是可以修改例如:IFS=:分隔符修改为"."$LINENO //记录这个变量所在行号$OLDPWD //之前的工作目录


121、内部变量2
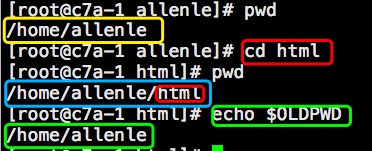
$PIPESTATUS这是个数组变量,将保存最后一个运行的前台管道的退出码。这个退出码和最后一个命令运行的退出码不一定相同。例子:
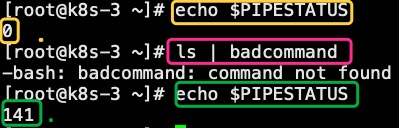
$PIPESTATUS数组的每个成员保存一个管道命令的退出码,${PIPESTATUS[0]}保存第一个管道命令的退出码,${PIPESTATUS[1]}保存第二个管道命令的退出码,以此类推。例子:

第二组命令中,第二个命令执行结果为空,输出退出码1如果是一个错误命令,那么输出如下:
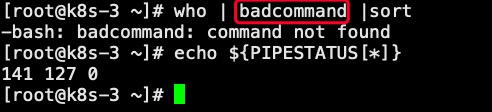
122、内部变量3
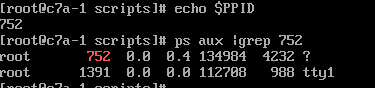
$PPID一个进程的$PPID就是他的父进程的进程id
$PROMPT_COMMAND这个变量保存一个在主提示符($PS1)显示直线需要执行的命令。

$PS1主提示符。$PS2第2提示符,当你需要额外的输入的时候将会显示,默认为">"$PS3第3提示符,在一个select循环中显示$PS4第4提示符,当使用-x选项调用脚本时,这个提示符将出现在每行的输出前面。$PWD当前所在目录,与pwd命令作用相同$REPLYread命令如果没有给变量,则默认输入给$REPLY中。

123、内部变量4
$SECONDE脚本运行的时间。例子:

$SHELLOPTS这是只读变量,不允许修改。变量保存shell允许的选项
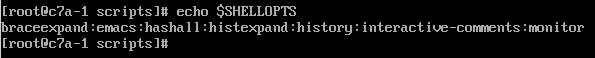
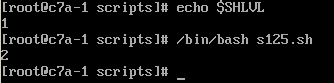
$SHLVL是shell level的缩写,直接意思就是shell层次。如果是命令行,值为1,脚本值为2.
$TMOUT当这个变量值大于0时,那么再过了这个指定的时间之后(即设置了长时间不操作最大时间),shell将执行logout。这个很有用,建议设置600(秒)。可以/etc/profile中设置,也可以在/etc/bashrc中设置。$UID当前用户ID号$0.$1,$2...位置参数,从命令行传递给脚本或者传递给函数,再或布置给一个变量$#命令行货位置参数的个数$*所有的位置参数,被当做一个字符串$@与$*同义,但是每个参数都是一个独立的""引用字串。这就意味着参数被完整传递,没有被解释和扩展

以上效果,是在引用的情况下的结果,如果是非引用情况下,那么跟$@效果一样。

当将IFS改为":"时,非引用如下图:

引用变量效果如下图:

函数的位置参数效果示意图如下图:

124、内部变量5
$_之前执行命令的最后一个参数。

第一条命令“ls -l” 有一个参数“-l”。第二条命令“pwd”不包含参数,$_保存的是命令本身。$?命令,函数或者脚本本身退出的状态。
*
第一个$?输出0,代表脚本之前运行结果状态。第二个$?输出0,代表执行一个pwd运行结果状态。第三个$?输出127,代表运行一个命令不存在。第四个$?输出127,代表运行一个不存在的函数。如果函数x定义放在运行x的前面,则会输出0.$$脚本自身的进程ID
125、操作字符串技巧
1、字符串长度方法1:$(#变量名)方法2:expr length $变量名方法3:expr "$变量名":'.*'例子:

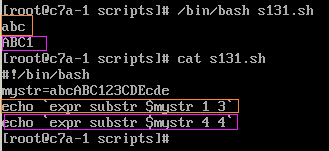
2、匹配字符串并输出所在位置方法1:expr match "$变量名" '正则表达式'方法2:expr "$变量名" : '正则表达式'
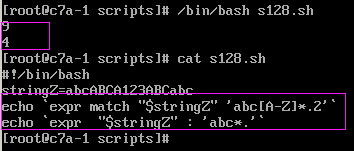
3、匹配字符串第一个字符,返回位置expr index $变量名 字串例子:
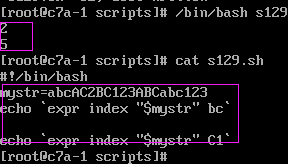
4、提取字符串$(变量名:开始位置)$(变量名:开始位置:长度)例子:

注意:当位置参数是负数的时候,会输出全部字符串。但是,如果冒号后面多输入一个空格,则代表字符串从右侧提取。5、按位置提取字符串内容expr substr $变量名 开始位置 提取字符长度例子:
126、操作字符串技巧(续)
1、1.截掉部分字串截掉左边第一个匹配到的字串${string#匹配字串} #支持正则表达式,string为变量名截掉左边最后一个匹配到的字串${string##匹配字串} #支持正则表达式,string为变量名例子:

例子中,第一条匹配到第一个大写字母A,第二条匹配到最后一个大写字母C截掉右边第一个匹配到的字串${string%匹配字串} #支持正则表达式,string为变量名截掉右边最后一个匹配到的字串${string%匹配字串} #支持正则表达式,string为变量名例子:

第一条将右侧ABCabc截掉第二条将右侧ABC123CDEcdeABCabc截掉2.字符串替换${string/匹配的字符串/用于替换的字符串} #替换第一个匹配到的字符串,string代表变量名${string/匹配的字符串//用于替换的字符串} #替换所有匹配到的字符串,string代表变量名

第一条只替换字串中第一个ABC
第二条替换了字串中所有的ABC
127、操作字符串技巧(再续)
1.变量未初始化时${变量名-缺省值}${变量名:-缺省值}先看例子(图1): 当初始化变量为空,那么形式1输出为空,不会输出设置的缺省值。 当未初始化变量,那么形式1输出缺省值。当未初始化变量或初始化未空,那么形式2输出缺省值。这种方法可以使用在脚本输入变量上,形式如下:${数字:-缺省值}例子:${1:-abc}下面的语法效果跟上面的刚好相反:${变量名+缺省值}${变量名:+缺省值}例子(图2):当变量初始化后,无论是否为空,都输出缺省值。当变量未初始化,则输出为空。


128、declear定义变量详解
定义只读变量语法:declare -r 变量名定义整数型变量语法:declare -i 变量名定义整数型后,该变量可以不使用let关键字,在等式内进行数学计算。例子:

定义数组
语法:
declare -a 数组名
定义函数
语法:
declare -f 函数
这个语法还有个特殊用途,输出之前定义的函数。

如图,使用declare -f输出了f1和f2两个函数的定义。
使用了declare命令,还有一个特殊作用,即限制了变量的作用域。

如图,例子中未使用declare的变量可以在多个函数内使用,使用了declare则只能在本区域内使用。
129、for循环小结
for循环语法:for 变量 in 数组do...done例1:#!/bin/bashfor ado echo $adonenumber="9 7 5 3 1"for i in `echo $number`do echo $idone本例中使用echo输出变量number作为数组,其内容是带有空格分割的一组整数。
运行结果:

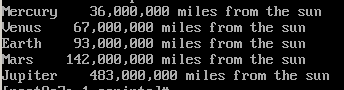
下面这个例子,在前例基础上稍加变化。例2: [root@c7a-1 scripts]# cat s133.sh #!/bin/bash for planet in "Mercury 36" "Venus 67" "Earth 93" "Mars 142" "Jupiter 483"do set -- $planet echo "$1 $2,000,000 miles from the sun"doneexit 0本例在in后面直接跟一组字符串。在循环代码中又对数字符串分解,分解为2各变量,分别输出。
输出结果:
数组中如果使用了通配符,那么会得到有趣的效果。例3:#!/bin/bashechofor file in *do ls $filedoneechosleep 5for file in [s]*dols $filedone本例“*”代表将当前路径下的文件和目录列表作为数组输出。如果前面带有前缀,那么就是以这个前缀开头的文件和目录。
输出结果:

下面这个例子更有趣,代码相当简单,结果出人意料。例4:#!/bin/bashfor ado echo "$a"done例子中for循环结构直接省略了in以及后面的数组。那么执行结果会是什么?
输出结果:
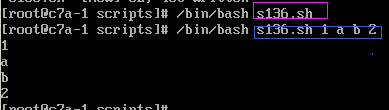
如图代码执行了2次,第一次没有带参数,输出结果为空。第二次带有4个参数,输出结果是依次输出了参数。
从这个结果,总结这个用法就是直接将脚本参数作为数组输出到for循环中。
130、替换脚本传入参数的值
本例以3个参数传入运行,运行中替换掉三个传入参数值。代码:#!/bin/bash#以下输出输入的第1-3个参数echo "first: $1 " echo "second: $2 "echo "third: $3 "set `uname -a`echo $_ #输出最后一个输出值echo "field #1 of 'uname -a' = $1" #查看第一个参数当前值echo "field #2 of 'uname -a' = $2" #查看第二个参数当前值echo "field #3 of 'uname -a' = $3" #查看第三个参数当前值echo $_ #输出最后一个输出值输出结果如下:

