对于普通的用户来说,我们所认为的上网所做的一切是打开一个web浏览器,输入web地址,并且立即看到请求的内容。幕后的技术正在为我们辛勤的工作,在许多不同的地方发生了许多个过程。很快,几毫秒之间。发生了浏览器和服务器之间的多次往返。
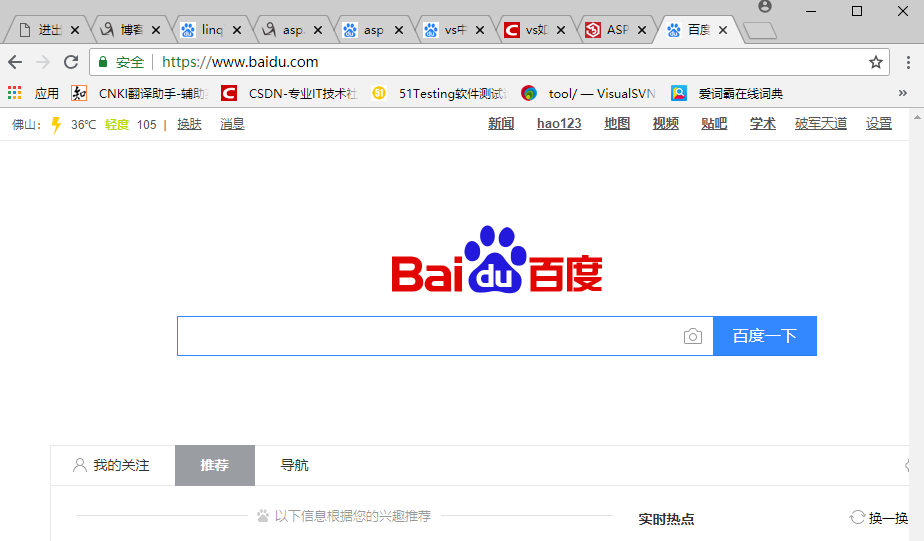
比如想要进行一次百度搜索。在web浏览器和服务器之间的简单过程如下:
-
1 你的web浏览器发出对位于http://www.baidu.com/地址的index.html文件的一个请求。index.html文件不必是地址栏上输入的地址的一部分。
-
2 在接收到对一个具体文件的请求后,Web服务器进程在它的目录中查找具体的文件,并且将该文件的内容发送回Web浏览器。
-
3 Web浏览器接受index.html文件的内容,这是由HTML代码标记的文本,并且根据HTML代码显示内容。我们可以根据检查元素来发现用于百度标识的HTML代码
<img id="s_lg_img_new" class="s_lg_img_gold_showre" src="//www.baidu.com/img/bd_logo1.png?qua=high&where=super" width="270" height="129" usemap="#mp">
-
4 浏览器查看
标记中的src特性以查找源位置 。在百度首页中,图像bd_logo1.png可以在读取HTML文件的相同web地址(www.baidu.com)中找到。
-
5 浏览器请求http://www.baidu.com/img/bd_logo1.png上的文件。
-
6 Web服务器解释该请求,寻求该文件,并且将该文件的内容发送给请求它的浏览器。
-
7 Web浏览器在显示器上显示该图像。
尽管所有的Web浏览器以总体相同的方式处理信息,但是它们之间有些特殊的差异导致在不同的浏览器中显示的结果不总是相同,我们必须要保证自己编写了兼容标准的HTML和CSS。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号